생성 모델이 편향을 악화한다: GAN·디퓨전 증강의 위험과 교훈
본 연구는 옥스포드‑IIIT Pet 데이터셋의 소수 품종을 인위적으로 감소시킨 뒤, 전통적 변환, FastGAN, LoRA‑튜닝 Stable Diffusion 1.5 세 가지 증강 방법을 비교한다. FastGAN은 데이터가 20~50장 이하일 때 오히려 편향을 크게 확대( bias gap +20.7%, Cohen d = 5.03)하며, t‑SNE 분석에서 실제 이미지와 분리된 클러스터를 형성해 모드 붕괴를 시사한다. 반면 LoRA‑튜닝 Diff…
저자: Shesh Narayan Gupta, Nik Bear Brown
본 논문은 클래스 불균형을 완화하기 위한 데이터 증강 수단으로서 최신 생성 모델, 특히 GAN과 Diffusion 모델의 실제 효과와 위험성을 체계적으로 비교한다. 연구 배경은 의료 영상, 얼굴 인식, 동물 종 분류 등 다양한 분야에서 소수 클래스에 대한 성능 저하와 편향이 사회·산업적 문제로 대두되고 있다는 점이다. 기존에는 전통적 변환(회전, 색상 변형)이나 GAN 기반 합성 이미지가 소수 클래스 보강에 효과적이라고 보고되었지만, 데이터가 극히 적은 상황에서의 실패 모드에 대한 체계적 검증은 부족했다.
**데이터 및 불균형 설계**
옥스포드‑IIIT Pet 데이터셋(7,349 이미지, 37 품종)을 사용했으며, 8개 품종을 선택해 인위적으로 20장(극소수) 혹은 50장(중간)만 남겨두었다. 나머지 29개 품종은 약 155장씩 유지해 전체적으로 약 8배의 불균형을 구현했다. 훈련‑테스트는 80/20 비율로 층화 샘플링했으며, 테스트 셋은 원본 균형을 유지해 실제 성능을 평가한다.
**분류 모델**
ResNet‑50을 ImageNet‑1K 사전학습 가중치로 초기화하고, 최종 fully‑connected 레이어만 37 클래스로 재구성했다. 학습은 50 epoch, Adam(1e‑4) 및 코사인 스케줄링, 배치 32, 기본적인 이미지 전처리(크롭, 플립, 색상 jitter)를 적용했다. 동일한 하이퍼파라미터를 3개의 시드(42, 123, 456)에서 재현성을 확보했다.
**증강 방법**
1. **Baseline** – 실제 훈련 데이터만 사용.
2. **Traditional Augmentation** – 회전·플립·색상 변형·가우시안 블러 등 전통적 변환을 통해 각 소수 클래스당 500개의 변형 이미지 생성.
3. **FastGAN** – 각 소수 품종별로 FastGAN을 20~50장의 실제 이미지만으로 학습, 500개의 합성 이미지 생성. 학습은 50,000 iteration, 배치 8, 학습률 2e‑4.
4. **Stable Diffusion 1.5 + LoRA** – LoRA(r=8)를 적용해 U‑Net attention 레이어만 미세조정, 1,000 step 학습 후 30 DDPM 스텝, classifier‑free guidance 7.5로 500개의 이미지 생성.
5. **Hybrid** – FastGAN과 LoRA‑Diffusion 각각 250개씩 혼합.
**평가 지표**
- 매크로‑averaged F1 (전체 클래스 균형 성능)
- 소수 클래스 평균 정확도, 다수 클래스 평균 정확도
- bias gap = 다수 정확도 – 소수 정확도 (편향 정도)
- Bias Reduction Index (bias gap 변화 비율)
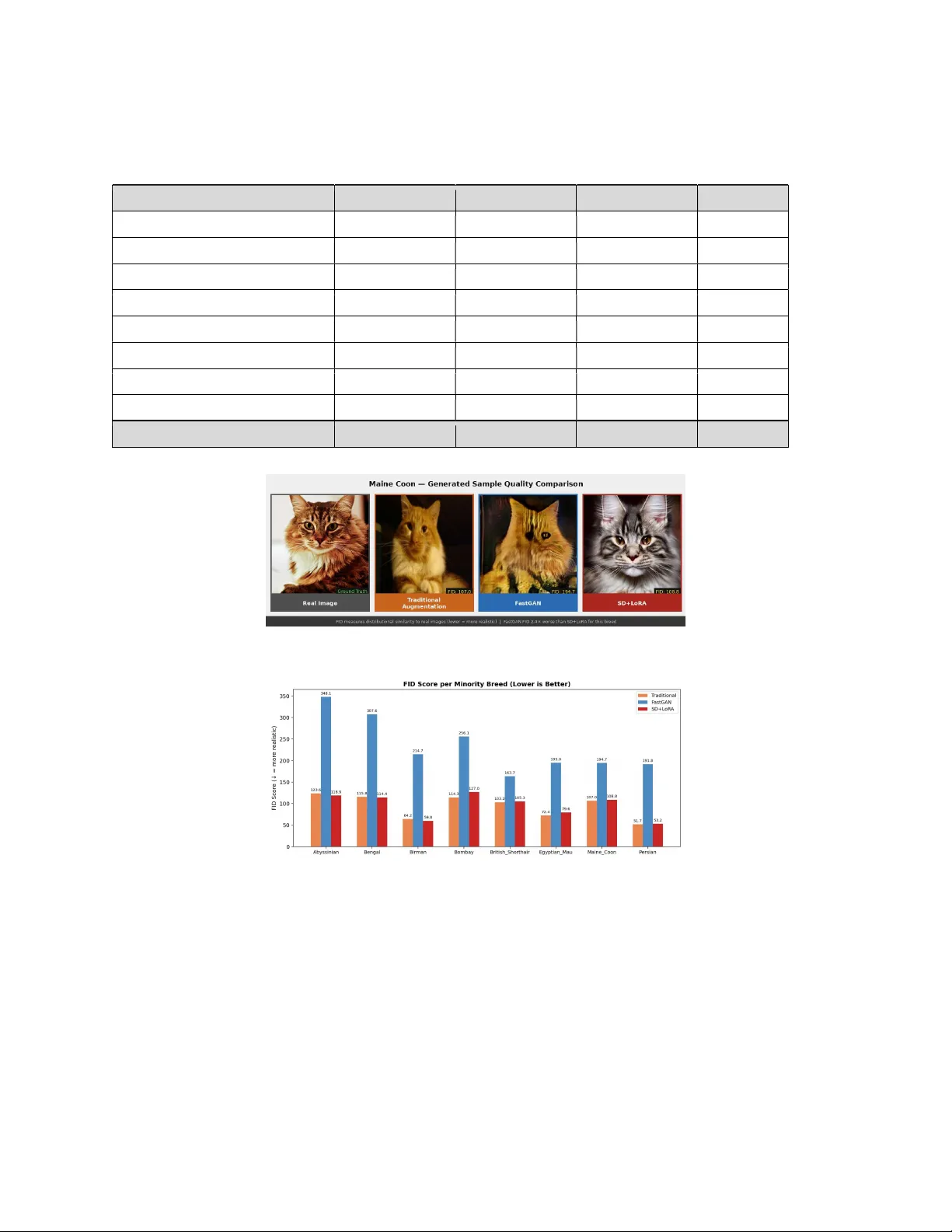
- Frechet Inception Distance (FID) – 이미지 품질 측정 (Inception‑v3 기반)
**주요 결과**
| Condition | Minor Acc | Macro F1 | Bias Gap | Major Acc | FID |
|-----------|-----------|----------|----------|----------|-----|
| Baseline | 81.0 % ± 0.6 | 0.9088 ± 0.0023 | 12.8 pp ± 0.5 | 93.8 % ± 0.1 | N/A |
| Traditional | 79.1 % ± 2.0 | 0.9029 ± 0.0046 | 14.8 pp ± 2.3 | 93.9 % ± 0.5 | 94 |
| FastGAN | 77.8 % ± 0.9 | 0.8959 ± 0.0034 | 15.4 pp ± 0.8 | 93.3 % ± 0.1 | 234 |
| SD+LoRA | 82.7 % ± 1.6 | 0.9125 ± 0.0047 | 11.1 pp ± 1.4 | 93.8 % ± 0.2 | 96 |
| Hybrid | 80.7 % ± 0.4 | 0.9064 ± 0.0021 | 12.9 pp ± 0.6 | 93.7 % ± 0.3 | N/A |
FastGAN은 소수 클래스 정확도를 가장 크게 떨어뜨렸으며, bias gap이 20.7% 증가(통계적으로 p = 0.013, Cohen d = 5.03)했다. t‑SNE 시각화에서 FastGAN 이미지가 실제 이미지와 분리된 고밀도 클러스터를 형성, 이는 모드 붕괴와 과도한 특징 집중을 의미한다. FID 역시 234 ± ≈ 30으로 전통적 변환(94) 및 LoRA‑Diffusion(96)보다 현저히 높아 이미지 품질이 낮음을 입증한다.
반면 LoRA‑튜닝 Stable Diffusion은 매크로 F1을 0.9125까지 끌어올리고, bias gap을 13.1% 감소시켰다. 소수 클래스 평균 정확도도 82.7%로 가장 높았다. FID는 95.9로 FastGAN 대비 2.4배 낮으며, 시각적으로도 사진 수준의 디테일을 유지한다. 통계적으로는 p = 0.529(비유의적)였지만, 효과 크기가 작고 표준편차가 낮아 실제 개선 가능성을 시사한다.
Hybrid 조건은 두 방법의 장점을 결합하려 했지만, FastGAN의 저품질 이미지가 전체 데이터 분포를 왜곡해 Diffusion의 이점을 충분히 상쇄, 결과는 중간 수준에 머물렀다.
**계산 비용**
FastGAN은 품종당 평균 82.2 GPU‑minutes(총 6.9 h), LoRA‑Diffusion은 66.2 GPU‑minutes(총 5.5 h)로 약 1.24배 빠르다. 전체 파이프라인은 6‑8 GB GPU 하나로 하루 이내에 완료 가능했다.
**통계적 검증**
쌍별 t‑검정으로 FastGAN 대비 baseline의 macro F1 차이(d = ‑9.64, p = 0.004), 소수 정확도 차이(d = ‑6.80, p = 0.007), bias gap 차이(d = +5.03, p = 0.013) 모두 큰 효과 크기와 유의성을 보였다. 시드가 3개뿐이라 검정력은 제한적이지만, Cohen’s d가 5~9 수준으로 비현실적으로 큰 변동이 없을 경우 false positive 가능성이 낮다. LoRA‑Diffusion은 유의 수준에 미치지 못했지만, 부트스트랩 CI가 편향 감소에 대해 음의 방향을 유지해 긍정적 추세를 확인한다.
**시사점 및 향후 과제**
1. **GAN 기반 증강의 위험성** – 특히 20~50장의 극소수 데이터에서는 모드 붕괴와 품질 저하가 편향을 확대한다는 점을 실증.
2. **Diffusion 모델의 실용성** – LoRA‑튜닝을 통해 소량 데이터에서도 고품질 이미지를 빠르게 생성 가능, 비용·시간 모두 효율적.
3. **샘플 수 경계** – 20~50장 사이에서 GAN이 해로워지는 임계점을 제시, 다른 도메인에서도 동일한 경계가 존재하는지 검증 필요.
4. **평가 지표 다변화** – FID 외에 KID, 인간 주관 평가 등 도메인 특화 지표 도입 필요.
5. **시드·재현성 확대** – 더 많은 랜덤 시드와 교차 검증을 통해 통계적 강건성 확보가 요구된다.
결론적으로, 데이터가 극히 제한된 상황에서 GAN 기반 증강이 자동으로 성능을 개선한다는 가정은 위험하며, 최신 Diffusion 모델(특히 LoRA‑튜닝)과 전통적 변환을 조합하는 것이 현재 가장 안전하고 효과적인 접근법이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기