When Generative Augmentation Hurts: A Benchmark Study of GAN and Diffusion Models for Bias Correction in AI Classification Systems
Generative models are widely used to compensate for class imbalance in AI training pipelines, yet their failure modes under low-data conditions are poorly understood. This paper reports a controlled benchmark comparing three augmentation strategies a…
Authors: Shesh Narayan Gupta, Nik Bear Brown
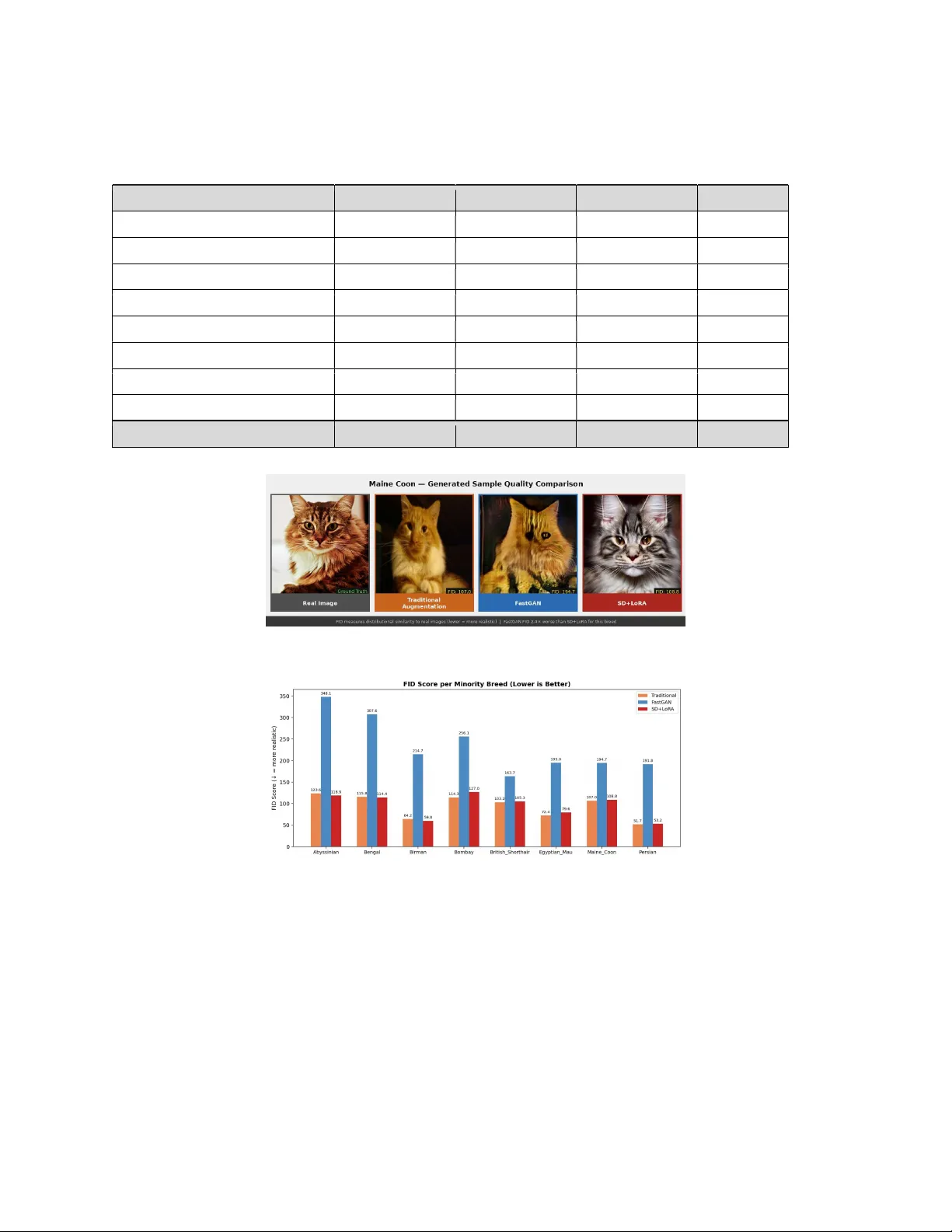
When Gene rative Aug mentation H urts: A Benchmar k Study of GAN and Dif fusion Models for Bias Cor rection in AI C lassification Systems Shesh Narayan Gupta(Corresponding Author ) College o f Engineer ing, Northeastern University, Bo ston, MA 021 15, USA ORCID: 0 000-0001- 8152-2967 Email: gu pta.shes@no rtheastern. edu Nik Bear Brown College o f Engineer ing, Northeastern University, Bo ston, MA 021 15, USA ORCID: 0 000-0001- 6270-7536 Email: ni. brown@n ortheastern.ed u Abstract Generative models are widely used to compensate for class imbalance in AI training pipelines, yet their failure modes under low-data condi tions are poorly understood. This paper reports a cont rolled benchmark comparing thre e augmentation strategies appli ed to a fine -grained a nimal classification task : tr aditional transforms, FastGAN, and Sta ble Diffusion 1.5 fine-tuned with Low-Rank Adaptation (LoRA). Using the Oxford-IIIT Pet Dataset with eight artificially underrepresented breeds, we find that FastGAN augmentation does not merely underperform at very low tr aining set sizes but a cti vely increases classifier bias, with a st atisti cally s ignificant large effect a cr os s three random seeds (bias gap increase: +20.7%, Cohen's d = +5.03, p = 0.013). The effect siz e here is lar ge enough to give confidence in th e direction of the finding des pite the small n umber of s eeds. Featu re embedding analysis using t-distributed Stochastic Neighbor Embedding reveals that FastGAN ima ges for severe-minority breeds form tight is olated clusters outside the real image distribution, a pattern consistent with mode collapse. Stable Diffusion with Low- Rank Adaptation produced the best results overall, a chieving the highest macro F1 (0.9125 plus or m inus 0.0047) and a 13.1% reduction in the bias ga p relative to the unaugmented baseline. The data suggest a sample-size boundary so mewhere between 20 and 50 training i mages per class below which GAN augmentation becomes harmful in this s etting, though further work acr oss a dditional dom ains is needed to establish where that boun dary s its m ore precisely. All expe riments run on a c onsumer-g ra de GPU with 6 to 8 GB of memory, with n o clo ud co mpute required. Keywords: generative data augmentation, class imbal ance, diffusion models, gene ra tive adversa rial networks, minority class bi as 1 Introduction A recur ring problem in applied mac hine learning is that training data rarely re flects the real-world distribution of the categories a m odel is e xpected to handle. When some classes have f ar fewer examples than others, classifiers learn to fav our th e majority and perform poo rly on the rest. This is not a niche issue: it shows up in medical diagnosi s [1], facial re cogni tion systems [2], and fine-grain ed species classification [3], among many other settings. The stand ard engineering response is data augmentati on . For cases where collecting m ore real examples is im pra ctic al or expensive, generative m odels offer an appealing option: train a model on the available minority-class data a nd use it to synthesise additional training examples. The approach has been validated in a number of domains [4, 5], and as generative models have improved, so t oo has interest in applying them to imbalanced datasets. The g enerative mo delling landscape ha s shifted considerably in recent ye ars. Generative Adversarial Networks (GANs), lo ng the default cho ice for image synt hesis, are now routinely ou tperformed on perceptual quality metrics by d iffusion-based models [6, 7]. For a practitioner tr ying to correct class imbalance, thi s raises a straightforward but una nswer ed question: whi ch fa mily of models is actually better for augmentation, and does the answer change depending on how little data is ava ilable? This paper addresses that ques tion directly. We designed a benchmark ar ound animal breed classification using the Oxford-III T Pet Dataset [8] , with eight breeds artificially r educed t o simulate realistic imbalance. We compared FastGAN [9] and Stable Diffusion 1.5 fine-tuned wi th Lo w-Rank Adaptation (LoRA) [ 10], along with a hybrid condition a nd a traditional augmentation baseline. The core finding is not what we expected: FastGAN aug mentation does not just fail to help when training sets are very small; it makes th ings measurably wor s e, in a statistically significant and mechanistically explainable way. The contributions of this p aper are as follows. First, we provide empirical ev i de nce that GAN-based augmentation can actively increase classifier bias fo r s evere-minority cla sses in this setting, and we explain the mechanism through feature embeddi ng a nalysis. Second, we present a direct head-to-head comparison of FastGAN and Stable Diffusion with Low-Rank Adaptation specifically for minority-class bias correction in fine-grained cla ssification. Third, the data poin t to a sample-size boundary somewhere between 20 and 50 images per c lass below which GAN augmentation becomes harmful, though establishing this threshold more precisely across other domains is left to future work. Fou rth, the entire experimental fra m ework runs on consu mer -grade GPU hardw are and is fully reproducible. This paper extends earlier work by Gu pta and Brown [ 3], which us ed procedurally rendered 3D images fo r bias correction; th e current study asks whether purely generative approaches can achiev e the same goal, and under what conditio ns they fail. 2 Related W ork 2.1 Class Imbalance in AI Systems The problem of imbalanced training d ata has a l ong histor y i n m achine l earning. Torralba and Efros [11] showed early on that sampling biases cause m odels to fail when tested outside their training distribution. In fine-g rained recognition tasks, per-class sample counts c an vary by an o rder of magnitude [12], making th e problem especially acute. Bu olamw ini a nd Gebru [2] br ough t wider attention to the real- world consequences, documenting subst antially higher error rates for darker-skinned females in commercial fa cial analysis s ystems. Buda e t al. [ 22] and He a nd Garcia [23] provide c omprehensive analyses of h ow c lass i mbalance a ffects convolu tional network t raining a nd what resampling s t rategies c an do about it. 2.2 Generative Augmentation Using generative models to s ynthesise training examples for underrepresented classes was first explored in medical imaging. Frid-A dar et al. [4] showed that GAN- generated liver lesion images could improve cl assification perf ormance when real train ing data was scarce. Sub sequent wo rk extended t he idea to dermatology [13], r etinal imaging [14] , and wildlife monitoring [15] . Gupta and Brown [3] demonstrated that pr ocedura lly rendered 3D i mages can correct breed-level bias in animal c lass ifi cation w ithout re quirin g a generative model at all. Diffusion m odel-based augmentation is more recent. Trabucco et al. [16] showed that Stable Diffus ion fine-tuned via DreamBooth could im prove f ew-shot classification accuracy. He et al. [ 17] found t hat diffusion-generated images can match o r exceed GAN ima ges f or augmentation in certain settings. Neither study examined what happens when training sets are ve ry sm all, or whether augmentation can actively harm performance. 2.3 FastGAN FastGAN [9] was designed specifically for the low-data setting. It introduces skip-layer channe l-wise excitation and self-supervised discriminator augmentation, allowing it to produce reasonable ima ges from as few as 100 tr aining examples. Its lig htwe ight a rchitecture tra ins in a ma tter o f hours on a single consumer GPU, which makes it well-suited, at lea st in princip le, to minority-class augmentation scenarios. 2.4 Stable Diffusion and L ow-Rank Adaptation Stable Diffusion [7] moves the diffusion process into the compressed latent space of a variational autoencoder, which cuts computational requirements substantially c ompared to pixel-space diffusion. Low- Rank A daptation [10] i njects trainable low-rank matrices into the attention layers of the model, enabli ng subject-specific f ine-tuning from as f ew as 20 t o 50 refe rence images in under an hour. Together, Stable Diffusion 1.5 with L ow-R ank Adaptat ion represents t he current practical standard for diffusion-based fine- tuning on limited data without large compu te infrastructure. 3 Methodology 3.1 Dataset and Imbalance C onst ru cti on We used the Ox ford-III T P et D ataset [8], which contains 7,349 images across 37 cat and dog breeds. To simulate realistic imbalance, we subsampled eight breeds: three were r educed to 2 0 trainin g images (severe min ority: Abyssinia n, Bengal, B irman) and f ive t o 50 images (moderate minority: Bombay, Br itish Shorthair, Egyptian Mau, Maine Coon, Persian). The re maining 29 breeds kept approximately 155 image s each, giving a maximum-to- minim um im balance ra tio of roughly 8x. The dataset was split 80 /20 into training and te st sets using stratified s ampling before subsampli ng. The test set c ontains only r eal i mages at the original balanced distribution and was held fixed across all conditions. Figures 1 and 2 show the breed distribution before and after imb alance construction. Fig. 1. Per-breed image count in the full Oxford-IIIT Pet dataset. Red b ars indicate minority breeds selected for augmentation . Fig. 2. Training split befo re (left, 1.1x ratio) and after (right, ~8 x ratio) artificial imbalance construction. 3.2 Classifier Architecture All conditions u sed a R esNet-50 [18] p re-trained on I mage N et-1K, with the f inal fully connected l ayer replaced by a l inear layer of dimension 37. The mo del was fine-tuned end-to-end for 50 epochs using Adam [19] with a learning rate o f 1x10^-4, decayed via cosine annealing. T ra ining used random cropping (224x224 from 256x256), r andom horizontal flip, and colour j itter. Batch size was 32. Training was repeated with three rando m seeds: 42, 123, and 456. 3.3 Experimental Conditions Five c ondi ti ons were evaluated. (1) Baseline: real training data only, no augmentation. (2) Tra ditional augmentation: 500 images per minority breed generated via class ical transforms including flips, r otatio ns of plus or min us 20 degr ees, colour jit ter of plus or mi nus 30%, a nd Ga ussian blur. (3 ) F astGAN: 500 FastGAN-generated images per mi nority breed. (4) Stable Diffusion with Low-Rank Adapta tion: 500 generated images per minority breed. (5) Hybrid: 250 FastGAN images plus 250 St able Diffusion with Low-Rank Adaptation images per minority breed. All augme ntation c onditions added exactly 500 synthetic images per minority class. 3.4 Evaluation Metrics Primary metric is macro-averaged F1. We also report minority-class a verage accuracy, majority-class average accuracy, bias gap (majority minus minority accuracy), a nd Bias Reduc tion Index (percentage change in bias gap relative to baseline). Frec het Inception Distance (FID) [20] was co mputed using the standard Ince ption-v3 feature extractor, comparing all 500 generated images against all available held-out real images per br eed. GPU t raining time wa s reco rded for the ge nerative traini ng and image genera tion phases. 4 Augmentation Pipelines 4.1 FastGAN FastGAN [9] was trained independently for each minority breed using only the available r eal training images. We used a generator with five upsampling blocks producing 256x256 images, resized t o 224x224 for classifier training. The discriminator used four strided convolution blocks. Both networks were trained with binary cross-entropy loss (label smoothing 0.9) using Adam with l earning rate 2x10^-4 and beta values of (0.5, 0.999) f or 50,000 iterations with batch size 8. Traini ng required an average of 82.2 GPU-minutes per breed, or 6.9 hours total acr oss all eight b reeds. 4.2 Stable Diffusion 1.5 wi th Low-Rank Adaptation We f ine-tuned Stable Diffusion 1.5 [ 7] on e ach minority br eed u sing Low-Rank Adaptation [10] a ppli ed to the U-Net attention proj ection layers (to_k, t o_q, to_ v, to_out.0) with rank r = 8. All other weights were frozen. Trainin g ran for 1 ,000 steps with batch size 1 a nd gradient accumulation over 4 steps (effective batch size 4), learning rate 1x10^-4 with cosin e annealing. After fine-tuning, 500 im ages pe r breed were generated using 30 DD PM steps with classifier-free guidance scale 7.5, rotating across four prompt templates. The four templates followed t he pattern: "a photo of a [breed name] c at", "a high-quality photograph of a [breed name]", "a close-up photo of a [breed name] cat on a plain background", and "a realistic image of a [breed na me] breed c at". Full p rompt text and g eneration scripts are available in th e repository. Fine-tuning required an a verage of 66.2 GPU-minutes per breed (5.5 ho urs total), making Stable Diffusion with Low-Rank Adaptation 1.24x faster than FastGAN. 4.3 Hybrid Condition The hybrid condition c ombined 250 FastGAN-generated images and 250 Stable Di ffusion with Lo w- Rank Adaptation i mages per minority br eed, d rawn from the sets ge nerated abov e. The rationale was to t est whether the two method s compensate for each o t her' s weaknesses: FastGAN gene ra tes i m ages quick ly but with lower fidelit y, while Stable Diffusion with Low-Rank Adaptation is slower but produces higher- quality out puts. If FastGAN's blurry images add variety while Stable Diffusion w i th Low-Rank Adaptation covers the distribution well, a mix might outperform either alone. No additional generative training was required. Because the hybrid condition re uses already-characterised images, FID sc ores and em bedding analysis are reported for the constituent methods rather than for the hybrid separately. One limitation of FID as the sole image qua lity metric is that it relies on an Inception- v3 feature space trained on ImageNet rather than on pet images. For a fine-grained task where inter-class differences are subtle, this m ay not c apture the quality dimensions that matter most for classifier training. Results should be interpreted w i th tha t in mi nd, and future work sho uld consider supplementary metrics such as Kern el Inception Distance or human pre fere nce as sessments on sampled images. 5 Results 5.1 Baseline Bias Characterisation The baseline classifier a chieved a mea n m acro F1 of 0.9088 (plus or mi nus 0.0023) a cross three random seeds. Minority breeds showed substantially lower average acc uracy ( 81.0% plus or minus 0.6%) compared to majority breeds ( 93.8% plus or m inus 0.1%), giving a me an bias gap of 12.8 plus or minus 0.5 percentage points. 5.2 Overall Comparison Table 1 summarises the prim ary evaluation metrics across all five c onditions. Figure 3 shows macro F1 scores by condition. Table 1. Results across al l five cond itions (mean p lus or minus SD, 3 seeds). High er macro F1 and lower bias g ap indicate better pe rformance. Condition Min. Acc. Macro F1 Bias Gap Maj. Acc. FID Baseline 81.0%±0.6% 0.9088±0.0023 12.8±0.5 pp 93.8%±0.1% N/A Traditional Aug. 79.1%±2.0% 0.9029±0.0046 14.8±2.3 pp 93.9%±0.5% 94.0 FastGAN Aug. 77.8%±0.9% 0.8959±0.0034 15.4±0.8 pp 93.3%±0.1% 234 SD+LoRA Aug. 82.7%±1.6% 0.9125±0.0047 11.1±1.4 pp 93.8%±0.2% 96 Hybrid (GAN+SD) 80.7%±0.4% 0.9064±0.0021 12.9±0.6 pp 93.7%±0.3% N/A Fig. 3. Ma cro F1 score by augmentation condition across five experimental conditions. Stable Diffusion with Low-Rank Adaptation achieved the highest mean m acro F1 (0.9125 plus or m inus 0.0047) and the lowest mean bias gap (11.1 plus or m inus 1 . 4 pp), a 13.1% reduction relative to baseline. Both tra ditional a ugmentation a nd FastGAN widened the bias gap relativ e t o baseline (tra dit ional: 14.8 plus or minus 2.3 pp; Fa stGAN: 15.4 plus or minus 0.8 pp). The standard de viations across seeds were small relative to the effect sizes. 5.3 Per-Class Accuracy Analysis Fig. 4. Minority versus majority breed average accuracy by conditio n. Error bars show SD across 3 seeds. Fig. 5. Per-class a ccuracy heatmap across all conditions (* = minority breed). Stable Diffusion with Low- Rank Adaptation produced the most consistent per-class gains. Representative seed-4 2 values show t he largest i mprovements in Be ngal (+ 10.0 pp), Birman ( +7.5 pp), an d British Shorthair (+12.5 pp). FastGAN reduced accura cy in the three severe-minority breeds, with Birman falling from 47.5% to 30.0 %. Majority-class accuracy stayed broadly stable acros s all conditions. 5.4 Bias Reduction Fig. 6. Bias gap ( majority minus minority accuracy) by condition. Lower values indicate better fairness. Stable Diffusion with Low-Rank Adaptation reduc ed the mean bias gap by 13.1% r elative to baseline (from 12.8 plus or minus 0.5 pp to 11.1 p lus or minus 1.4 pp). The hybrid condition achieved only a marginal 1.0% mean reduction. Tr aditional augmentation and FastGAN increa sed the bias g ap by 15.7 % and 20.7% respectively, and thi s pattern held across all three random seeds. 5.5 Image Quality: FID Sco res Table 2 presents per-breed FID scores. Th e hybrid condition is excl uded as i t dra ws from the t wo constituent methods already reported. Table 2. FID scores per minority breed by method (lo wer scores indica te more realistic im ages). Breed Trad. FID FastGAN FID SD+LoRA FID Real N Abyssinian 123.6 348.1 118.9 20 Bengal 115.8 307.6 114.4 20 Birman 64.2 214.7 59.8 20 Bombay 114.3 256.1 127.0 50 British Shorthair 103.2 163.7 105.3 50 Egyptian Mau 72.4 195.0 79.6 50 Maine Coon 107.0 194.7 108.8 50 Persian 51.7 191.8 53.2 50 Average 94.0 234.0 95.9 -- Fig. 7. Representat ive generated samples for Maine Coon across three metho ds. FastGAN shows characteristic blurrin g and colour artefa cts (FID 194.7). SD+LoRA produces a photorealistic image (F ID 1 08.8). Fig. 8. FID scores per mino rity breed by method. FastGAN scores are consistently higher, particularly for severe-minority breeds (N = 20). Stable Diffusion with Low-R ank Adaptat ion achieved a substantially lower a verage FID (95.9) compared to FastGAN ( 234.0), a difference of 2.4x. The ga p was most pronounced f or severe-minority breeds: Abyssinian (FastGAN 348.1 versus SD+LoRA 118.9) and Bengal (307. 6 versus 114.4). 5.6 Computational Cost All conditions ran within a single working d ay on a co nsumer-grade GPU with 6 to 8 GB of memory. Stable Diffusion with Low-Rank Adaptation (66.2 minutes per breed) was 1.24x faster t han FastGAN (82.2 minutes per breed) for the gener ative tra i ning ph ase. The baseline classifier required 40.5 GP U-minutes. 5.7 Statistical Analysis Table 3 pr esen ts pairwise significance t ests comparing each condition again st the baseline usi ng paire d t-tests across three random seeds. FastGAN degradation was statistically significant with large effect sizes across all primary metrics: macro F1 (d = -9.64, p = 0.004), minority accuracy (d = -6.80, p = 0.007), and bias gap ( d = +5.03, p = 0.013). With only three seeds, a paire d t-test has limited power a nd is sensitive to outliers. What gives confidence in the FastGAN finding is the e ffect size: Cohen' s d values of 5 to 9 are unusually large, meaning t he effect would have t o be implausibly variable across seeds for this result to be a false positive. The bootstrap confidence inter val for the bias gap change (CI [-30.0%, -11.4%]) does not cross zero, which further supports t he reliability of the finding. Stable Diffusion with Low-Rank Ada ptation improvement did not re ach significance with three seeds (p = 0.529), and the bootstrap interval does cross zero (CI [ -1.4%, +25.5%]), so that benefit is treated here as a promising trend requiring more seeds to confirm. Table 3. Pairwise significa nce tests versus b aseline (p aired t-test, n = 3 seeds). La rge effect size de fined as |d| > 0.8. Metric Comparison Mean Diff Cohen's d p-value Sig. Macro F1 Baseline to Tra ditional - 0.0058 - 2.04 0.071 -- Macro F1 Baseline to F astGAN - 0.0128 - 9.64 0.004 Yes Macro F1 Baseline to S D+LoRA +0.0037 +0.44 0.529 -- Macro F1 Baseline to Hybrid - 0.0024 - 1.07 0.204 -- Min. Acc. Baseline to F astGAN - 0.0323 - 6.80 0.007 Yes Min. Acc. Baseline to S D+LoRA +0.0166 +0.62 0.398 -- Bias Gap Baseline to F astGAN +0.0265 +5.03 0.013 Yes Bias Gap Baseline to S D+LoRA - 0.0167 - 0.69 0.354 -- 5.8 Embedding Analysis: Mode Co llapse Evidence To understand why FastGA N harms performance rather than he lping, we extracted 2,048-dimensional feature embeddings fr om the penultimate layer of the baseline ResNet-50 a nd applied t-distributed Stochastic Neighbor Embeddi ng [21] for dimensional it y reduction. Coverage was qua ntified as t he mean nearest-neighbour distance from each s ynthetic point to its nearest real image in embedding space. Fig. 9. t-S NE of ResNet-50 feature embeddings per minority breed. Con vex hulls show distribution coverage. FastGAN (blue triangles) forms tigh t isolated clusters fo r severe-minority breeds (N = 20), indicating mode collapse. SD+LoRA (red diamonds) broadly overlaps the real distrib ution (dark circles). Fig. 10. Emb edding comparison for Abyssinian (N = 20, severe minority). FastGAN mean coverage distance 21.28; SD+LoRA 8.22. Fig. 11. Emb edding comparison for Birman (N = 20, severe minority, FastGAN F ID 214.7). FastGAN embeddings occupy a distinct subspace from real images. For severe-minority breeds (N = 20 ), FastGAN embeddings formed two or three t ight isolated clusters outside the rea l i mage distribution. The mean near est-neighbour cover age d istance for FastGAN ac ross severe-minority breeds (14.68) was sub stantially larger than for Stable Diffusion with Low- Rank Adaptation (8.93). For moderate-minority breeds (N = 50), the pattern was le ss pronounced, pointing to a training-size threshold som ewhere bet ween 20 and 50 images. 6 Discussion 6.1 What the Results Say The most important findi ng i s not that Stable Diffusion with Low-Rank Adaptation outperforms FastGAN -- that i s broa dly consis tent w ith the ge nerat ive mo delling literature. What was not known , and what this study makes clear, is that FastGAN augmentation can actively harm a classifier when tr aining sets are very small. The mech anism is mo de collapse: with on ly 20 training images, FastGAN fails to cove r the real image distribution and instead generates a narrow cluster of visu all y s imilar images that sit outside it. Adding those images to the training set poisons the minority-class signa l rath er than enriching it. Traditional augmentation also widened t he bias gap on average, though the effect was smaller (15. 7%) and less consistent across seeds. This suggests t hat c lassical transforms applied to 20 images simply do not provide enough variety to i mpr ove g eneralisation. Stable Diffusion with Low-Rank Adaptation confirmed the primary hypothesis, achieving the hi ghest mean macro F1 (0.9125 plus or minus 0.0047) and a 13.1% mean reduction in the bias gap. The hybrid condition offered only marginal improvement ove r baseline, which suggests that mix ing high-quali t y diffusion images with low-fidel ity GAN images dilutes rather than compounds the benefit. 6.2 Relationship to Prior Work This paper builds directly on Gupta and Br own [3], which showed that procedurally rendered 3D images can correct breed-level bias in the same Oxford-II IT Pet setting. T hat s tudy require d 3D assets and a rendering pipeline; the p resent work ask s whether pu rely generative a pproaches can do the same job, and whether G AN-based and di ffusion-based methods pe rform equal l y well. The answer , at least in this datase t and domain, is no. Stable Diffusion with Low-Rank Adaptation comes close to th e bias correction achieved in [3], while FastGAN makes things worse. The relative performance of FastGAN and Stable Diffusion with Low- Rank Adaptation is c onsistent with the broader p attern where diffusion models have displaced GANs on perceptual quality [6, 7], and it now extends that picture into the downstream classification setting. The finding that GAN au gmentation can actively hurt ra ther t han mer ely fail to he lp is, to our knowledge, not previously reported in t he generative augmentati on l iterature. Whether this generalises beyond fine-grained pet classificati on is an open que stion. The mechanism, m ode collapse at very low sample counts, is well understood and not specific t o this domain, but the poin t at whic h it k icks in and how severely it affects downstre am performance may well differ across tasks and model architectures. 6.3 Limitations Several limitations s houl d be kept in mi nd whe n reading t his work. The benchmark u ses a single dataset and domain , so t he specific threshold values and magnitude of effects reported here may not tra nsfer directly to medical imaging, remote sensing, or other fine-grained classification tasks. The statistical analysis used three ra ndom seeds: for the FastGAN findings this i s acceptable given the very large e ffect sizes and non- overlapping confidence intervals, but for Stable Diffusi on with Low-Rank Adaptation the benefit remains at t he level of a trend. The augmentation volu m e of 500 images per class was not ablated, and the optimal number may well differ between methods. FID, the sole image quality metric used, relies on an Inception- v3 fe atur e space trained on Ima geNet, which may not capture the subtle inter-class differences that matter most i n fine-grained classification. Hardware constraints prevented evaluation of larger ar chi t ectures such as StyleGAN3 or Stable Diffusion XL. Finally, the sample-size boundary suggested by the data, s omewhere between 20 and 50 im ages , comes f rom comparing two data points rather than a systematic swee p, and should be treated as a hypothesis to test rather than an established rule. 6.4 Future Directions Extending to medical imaging (ISIC skin l esion dataset) and remote sensing (RESIS C45) would te s t whether t he threshold finding generalises across d omains. A systematic ablation across minority class sizes of 10, 20, 50, and 100 i mages would pi n down the thre shol d more precisely. Running f ive or more rando m seeds wou ld provide tighter si gnificance estimates for conditions with smaller effect sizes. Prompt engineering strategies for S table D iffusion w ith Low -Rank Adaptation, including ne gat ive promp ts and breed-specific descriptors, may furthe r improve generation quality. 7 Conclusion This study s et o ut t o determine which generative a ugmentation strategy work s better for correcting class imbalance i n a fine-grained AI classification task under r eal i stic hardware constraints. The answer came with an important c av eat. FastGAN augmentation did not just underperform; it si gnificantly worsened classifier bias for breeds wit h only 20 training images, with a large a nd statistically confirmed effect (Cohen's d = +5.03, p = 0.013). T he effect sizes here are large enough that this result is unlikely t o be a statistical artefact of the small seed coun t. Feature embedding analysis explain s the mechanis m : mo de collapse causes FastGAN to generate images that cluster outside the real distribution, a nd th ose out-of- distribution images degrade the minority-class training signal. Stable Diffusion w it h Low-Rank Adaptation did not show this problem. It p rodu ced the best overal l results in this study (macro F1: 0.9125 plus or minus 0.0047; bias gap reduction: 13.1%) and its generated images covered th e real distribution far more broadly th an FastGAN i n embedding s pace. The data suggest a boundary somewhere between 20 an d 50 training images per class below which GAN augmentatio n becomes harmful, at least in fine-grained classification on this dataset. Whether that boundary shifts in other domains is an open questio n that future work should address d irectly. All experiments are r eproducib le on a consumer-grade GPU wit h 6 t o 8 GB of memor y. Code and generation configurations are avai lable at https: // gi thub.com/SheshNGupta/BiasCorrectionInImage. Statements and Declarations Funding This research did not receive any s pec i fic grant from funding agenc ies i n the public, c ommercial, or not- for-profit sectors. Competing Interests The authors declare no com peting interests. Author Contributions Shesh Narayan Gupta designed and c onducted all experiments, performed the s tatistical analysis, and wro te the manuscript. Nik Bear Brown supervised the research and reviewed the manuscrip t. Data Availability The synthetic ima ge dataset ( Pet Breed Generative Augmentation Dataset) and all generation configurations are publicly available at https://github.com/SheshNGupta/BiasCorrectionIn Image. The Oxford-IIIT Pe t Dataset is available from https://www .robots.ox.ac.uk/~vgg/data/pets/. Acknowledgements The authors thank O. M. Parkhi, A. Vedaldi, A. Zis serman, and C. V. Jawahar for cr eating and making publicly available the Oxfo rd-IIIT Pet Dataset. References [1] Obermeyer Z, Powers B, Vogeli C, Mullainathan S (2019) Dissecting racial bias in an algorithm used to manage the health of populations. Science 366 (6464):447-453. https://doi.org/10.1126/science.aax23 42 [2] Buolamwini J, Gebru T (2018) G ender shad es: Intersectional accuracy disp arities in commercial gender classification. Proc Mach Learn Res 81:1 -15 [3] Gupta SN, Brown NB (2022) Adjusting for bias with procedural data. arXiv:2204.01108 [unpublished] [4] Frid-Adar M, Klang E , Amitai M, Goldberger J, Greenspan H (2018) Synthetic data aug mentation using GAN for improved liver lesion classification . In: Proc IEEE ISBI, pp 289-293. https://do i.org/10.1109/ISBI.2018.8363576 [5] Yamaguchi S, Kana i S, Eda T (2020) Effective data augmentation with multi-domain learning GANs. In: Proc AAAI 34(04):6566-6574 [6] Dhariwal P, Nich ol A (2021) Diffusion models beat GANs on image synthesis. A dv Neural Inf Process Syst 34:8780-8794 [7] Rombach R, Bl attmann A, Lorenz D, Esser P, Ommer B (2022) High-resolution image sy nthesis with latent diffusion models. In: Proc CVPR, pp 10684- 10695. https://doi.org/10.1109/CVPR52688.2022 .01042 [8] Parkhi OM, Vedald i A, Zisserman A, Jawahar CV (2012) Cats and dogs. In: Proc CVPR, pp 3498-3505. https://doi.org/10 .1109/CVPR.2012.6248092 [9] Liu M, Breuel T , Kautz J (2021) Towards faster and stabilized GAN trainin g for high-fidelity few-shot image synthesis. In: Proc ICLR [10] Hu EJ, Shen Y, Wa llis P et al (2022) LoRA: Low-rank adaptation of large languag e models. In: Proc ICLR [11] Torralba A, Efro s AA (2011) Unbiased look at dataset bias. In: Proc CVPR, pp 1521-1528. https://doi.org/10 .1109/CVPR.2011.5995347 [12] Van Horn G, Mac Aodh a O, Song Y et al (2018) The iNaturalist species classification and detection dataset. In: Proc CVPR, pp 8769-8778 [13] Baur C, Albarqouni S , Navab N (2018) MelanoGANs: High resolution skin lesion synth [unpublished] [14] Maayan A, L afarge MW, Veta M et al (2018) Treating class imbalance in OCT retinal data using generative adversarial networks. In: Proc SPIE Med Imag [15] Tabak M A, Norouzzadeh M S, Wolf son DW et al (2019) Machine learning to classify animal species in camera trap images. Methods Ecol Evol 10 (4):585-590 [16] Tr a bu cco B, Doherty K, Gurinas M, Salakhutdinov R (2023 ) Effective d ata augmentation with diffusion models. arXiv:2302.07944 [unpublish ed] [17] He R, Sun S, Yu X et al (2023) Is synthetic data from generative mode [unpublished] [18] He K, Zhang X, Ren S, Sun J (2016 ) Deep residual learning for image recognition. In: Pro c CVPR, pp 770-778. https://doi.org/10 .1109/CVPR.2016.90 [19] Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: Proc ICLR [20] Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) GANs trained b y a two time-scale update rule converge to a loc al Nash equilibrium. Adv Neural Inf Process Syst 30 [21] van der Maaten L, Hinton G (2008) Visualizing data using t-SNE. J Mach L earn Res 9:2579-2605 [22] Buda M, Maki A, Mazuro wski MA (2018) A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw 1 06:249-259 [23] He H, Garcia EA (2009) Learning from imbalanced data. IEEE Trans Knowl Data Eng 21 (9):1263-1284
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment