대규모 비전‑언어 모델을 위한 병렬 인‑컨텍스트 학습
본 논문은 멀티모달 인‑컨텍스트 학습(MM‑ICL)에서 시연 예시가 길어질수록 발생하는 이차 연산 비용을 완화하기 위해, 시연 컨텍스트를 여러 짧은 청크로 나누어 병렬로 처리하고, 로그잇 수준에서 가중된 전문가 집합(Product‑of‑Experts) 방식으로 결과를 통합하는 Parallel‑ICL 알고리즘을 제안한다. 클러스터링 기반 청크 분할과 질의‑유사도 기반 가중치 부여 전략을 통해 정확도와 효율성 사이의 트레이드오프를 최소화한다. 실험…
저자: Shin'ya Yamaguchi, Daiki Chijiwa, Tamao Sakao
대규모 비전‑언어 모델(LVLM)은 이미지와 텍스트를 동시에 처리할 수 있는 거대 언어 모델에 비전 인코더를 결합한 구조로, 사전 훈련된 멀티모달 데이터에 대해 instruction‑tuning을 수행하면 다양한 시각‑언어 태스크에 대해 zero‑shot 혹은 few‑shot 성능을 보인다. 이러한 모델이 새로운 작업에 빠르게 적응하도록 돕는 방법으로 멀티모달 인‑컨텍스트 학습(MM‑ICL)이 사용된다. MM‑ICL는 사용자가 제공하는 여러 (이미지, 질문, 답변) 시연 예시를 입력 컨텍스트에 삽입하고, 모델이 이를 attention 메커니즘을 통해 조건화함으로써 동적 작업 적응을 가능하게 한다.
하지만 트랜스포머의 self‑attention 연산은 입력 길이에 대해 O(L²) 복잡도를 가지므로, 시연 수가 늘어날수록 토큰 수가 급증한다. 특히 LVLM은 이미지당 수천 개의 비전 토큰을 사용하기 때문에, 8‑shot, 16‑shot, 32‑shot 등 시연이 늘어날수록 전체 토큰 길이가 수만에 달하고, 이는 추론 지연(latency)을 크게 증가시킨다. 기존 연구들은 사전 작업 벡터(task vector)를 추출하거나, 시연을 미리 전처리해 모델 내부에 삽입하는 방식으로 시연 없이 추론을 시도했지만, 이는 대량의 시연이 필요하거나 추가 최적화 단계가 요구돼 MM‑ICL이 추구하는 “즉시, 파라미터 업데이트 없이”라는 장점을 손상시킨다.
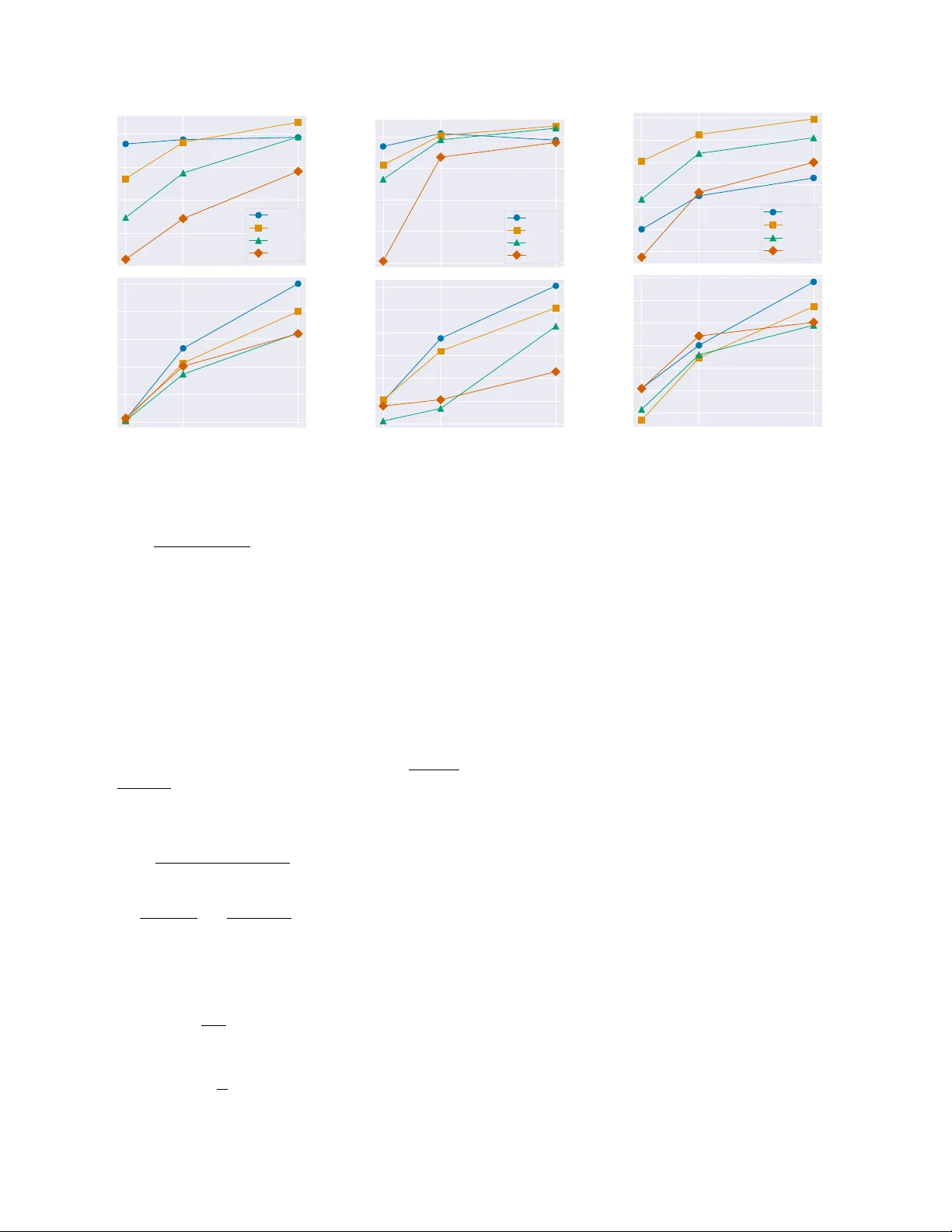
본 논문은 이러한 문제를 해결하기 위해 Parallel‑ICL이라는 새로운 추론 알고리즘을 제안한다. Parallel‑ICL는 두 단계로 구성된다. 첫 번째는 **컨텍스트 청크링(context chunking)** 으로, 전체 시연 집합 E를 K개의 청크 C₁…C_K 로 분할한다. 청크는 시연 간의 상호보완성을 높이기 위해 멀티모달 임베딩 공간에서 클러스터링을 수행해 만든다. 이렇게 하면 각 청크는 서로 다른 특성을 가진 시연들의 집합이 되며, 이론적으로는 ensemble 학습에서 요구되는 “청크 간 다양성”을 확보한다.
두 번째는 **컨텍스트 컴파일링(context compilation)** 으로, 각 청크를 독립적으로 모델에 입력해 로그잇 lₖ(y) 를 얻은 뒤, 가중치 wₖ 를 곱해 합산한다. 가중치는 현재 질의 q와 청크 Cₖ 사이의 멀티모달 유사도(예: 이미지‑텍스트 임베딩 코사인 유사도)를 기반으로 계산한다. 즉, 질의와 더 유사한 청크에 높은 가중치를 부여해 최종 확률을 구성한다. 이 과정은 로그잇 수준에서 수행되며, 가중된 Product‑of‑Experts(PoE) 형태로 표현된다.
수식적으로는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기