Parallel In-context Learning for Large Vision Language Models
Large vision-language models (LVLMs) employ multi-modal in-context learning (MM-ICL) to adapt to new tasks by leveraging demonstration examples. While increasing the number of demonstrations boosts performance, they incur significant inference latenc…
Authors: Shin'ya Yamaguchi, Daiki Chijiwa, Tamao Sakao
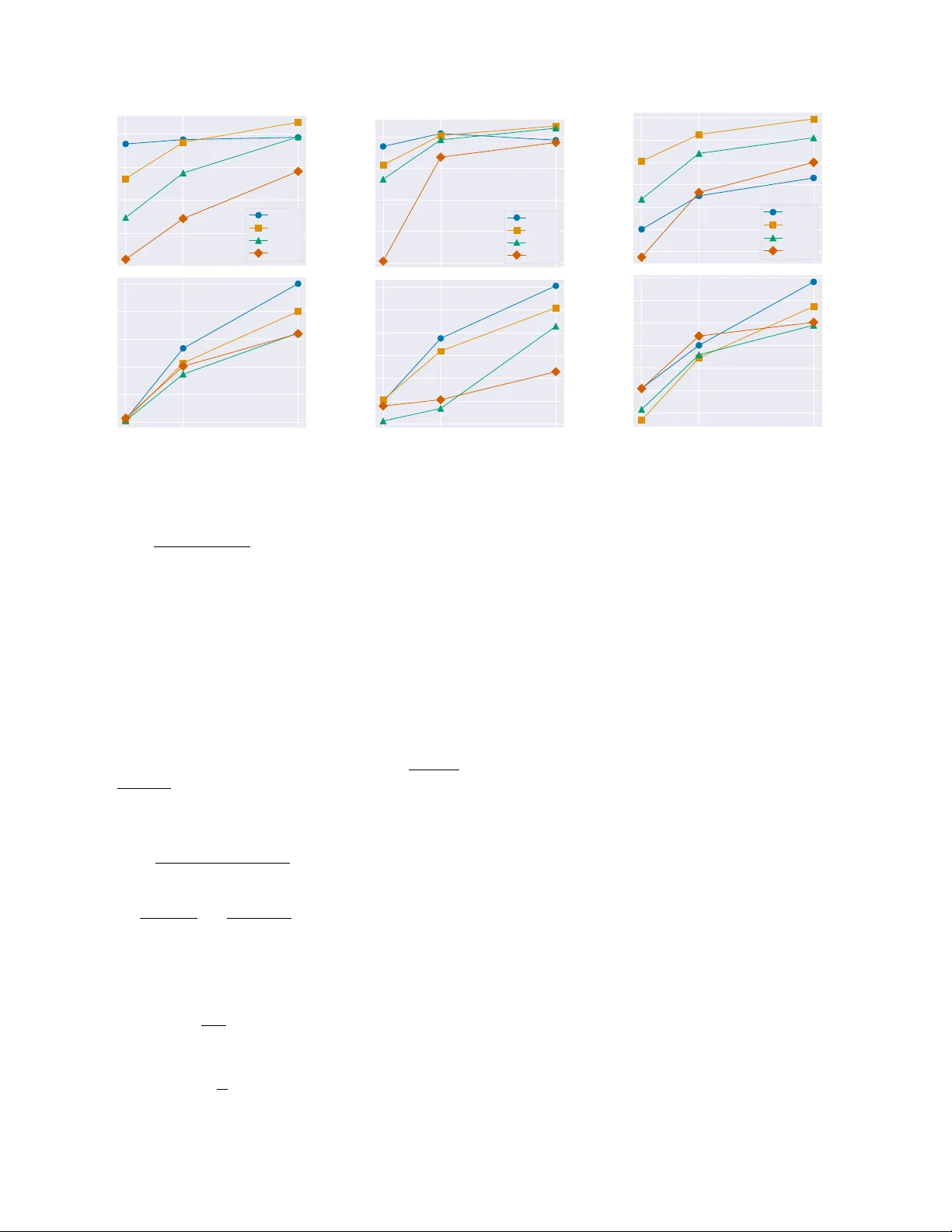
Parallel In-context Lear ning f or Large V ision Language Models Shin’ya Y amaguchi * NTT Daiki Chijiwa NTT T amao Sakao NTT T aku Hasegaw a NTT Abstract Lar ge vision-languag e models (L VLMs) employ multi-modal in-context learning (MM-ICL) to adapt to new tasks by lever - aging demonstration e xamples. While incr easing the number of demonstrations boosts performance, the y incur significant infer ence latency due to the quadratic computational cost of T ransformer attention with r espect to the conte xt length. T o addr ess this trade-of f, we pr opose P ar allel In-Context Learning (P arallel-ICL), a plug-and-play infer ence algo- rithm. P arallel-ICL partitions the long demonstr ation con- text into multiple shorter , manageable chunks. It pr ocesses these chunks in parallel and inte grates their pr edictions at the logit level, using a weighted Pr oduct-of-Experts (P oE) ensemble to appr oximate the full-context output. Guided by ensemble learning theory , we intr oduce principled strate gies for P arallel-ICL: (i) clustering-based context chunking to maximize inter-c hunk diversity and (ii) similarity-based con- text compilation to weight pr edictions by query r elevance . Extensive experiments on VQA, ima ge captioning, and classi- fication benchmarks demonstrate that P arallel-ICL achieves performance comparable to full-conte xt MM-ICL, while sig- nificantly impr oving inference speed. Our work offer s an effective solution to the accuracy-ef ficiency trade-of f in MM- ICL, enabling dynamic task adaptation with substantially r educed infer ence overhead. 1. Introduction Large vision-language models (L VLMs) are text-generativ e models that integrate pre-trained lar ge language models (LLMs) with vision encoders, processing both te xt and im- age inputs [ 1 , 2 , 4 , 15 , 33 , 50 , 51 ]. Through instruction tun- ing on extensi ve text-image datasets, L VLMs hav e demon- strated remarkable success in solving general and comple x multi-modal reasoning tasks specified by users [ 33 , 34 ]. T o fully lev erage the generalizability of these models on un- seen tasks, multi-modal in-context learning (MM-ICL, [ 65 ]) has emerged as a crucial paradigm [ 62 ]. Similar to ICL * Corresponding author . shinya.yamaguchi@ntt.com LVLM Full Demo Context Chunk 1 Chunk K ⋮ ⋮ Logit 1 Logit K ⋮ ⋮ Output Context Chunking Context Compilation MM-ICL (32-shot) Parallel-IC L (2-chunk) Parallel-IC L (4-chunk) 0 20 40 60 MI-Bench-ICL 58.90 63.40 59.00 MM-ICL (32-shot) Parallel-IC L (2-chunk) Parallel-IC L (4-chunk) 0 . 0 0 . 5 1 . 0 1 . 5 Relative Speedup 1.00 1.17 1.34 Figure 1. Parallel-ICL. Instead of using a full demonstration con- text, we propose partitioning it into smaller chunk contexts (conte xt chunking) and then integrating the logits from the chunk ed conte xts to output (conte xt compilation) for efficient inference in multi- modal in-context learning (MM-ICL) by large vision-language models (L VLMs). Parallel-ICL enhances inference speed while maintaining competitiv e performance to the original MM-ICL. in LLMs [ 7 ], MM-ICL conditions the L VLM’ s decoding on multiple demonstration examples, each consisting of an image-text pair input and its corresponding output, in- terleav ed with the input query . This contextual guidance enables the L VLM to comprehend the task at hand, allow- ing it to dynamically adapt to nov el tasks and achie ve im- pressiv e performance during inference without requiring any parameter updates [ 2 , 18 , 49 ]. While the performance gains from MM-ICL typically scale with the number of demonstrations [ 5 , 45 , 62 , 68 ], this presents a significant challenge: most L VLMs are b uilt upon T ransformer architec- tures, which incur a computational cost that scales quadrat- ically with respect to the length of the input context in the worst case [ 52 ]. As a result, increasing the number of demon- strations dramatically drops inference speed in exchange for accuracy , as shown in T able 1 . This issue is particularly se vere for MM-ICL, as L VLMs often represent images using many visual tok ens to capture fine-grained details [ 29 , 30 ], exacerbating the inference o verhead associated with longer contexts. T o reduce the inference cost, prior work has focused on approximating MM-ICL without demonstrations at inference time. One prominent approach in volves e xtracting a task vec- tor from the intermediate activ ations of the model by process- 1 ing a large set of demonstrations in advance [ 21 , 26 , 44 , 67 ]. Howe ver , this method often requires hundreds of demonstra- tions to achiev e performance comparable to that of few-shot MM-ICL, and incurs additional optimization to construct the vectors. These limitations deviate from the primary goal of MM-ICL, i.e., dynamic and ef fortless adaptation to ne w tasks, and impose additional burdens on the user be yond in- ference. This leads us to our primary research question: Can we ef ficiently appr oximate long-context MM-ICL at infer ence time without any additional bur dens? The major cause of inef fi ciency in MM-ICL is the long se- quential demonstration context. Howe ver , individual demon- strations, i.e., a tuple of (image, question, answer), are often independent and do not strictly need to be processed as a single series. Based on this observation, we propose Par - allel In-context Learning (Parallel-ICL), a novel, efficient, and plug-and-play inference algorithm for MM-ICL. The core idea is twofold: (i) context chunking , where the long demonstration context is partitioned into multiple shorter , manageable chunks, and (ii) context compilation , where pre- dictions from each chunk are inte grated to approximate the full-context prediction. W e formulate this idea as a weighted Product-of-Experts (PoE) ensemble [ 22 ], approximating the full-context distrib ution p ( y |C , x, t ) as Q K k =1 p ( y | C k , x, t ) w i , where C = { C 1 , . . . , C K } , C k is the k -th chunk, x and t are the input image and query text, and w k is the weight for the k -th chunk. By the parallel batch-wise computation, Parallel-ICL ef fecti vely ensembles task-specific kno wledge from demonstrations with lower ov erhead than computing the full context at once. Inspired by the theoretical principles of ensemble methods in machine learning [ 6 , 43 , 66 ], particularly those related to Fano’ s inequality [ 17 ], we propose principled chunking and compilation strate gies designed to maximize the ensemble’ s effecti veness. Our strategies are based on two ke y factors: inter-chunk di versity and query rele vance. For chunking, we le verage a clustering algorithm to partition the demonstrations. This strategy aims to maximize the div ersity among chunks, which is theoretically required for a small prediction error in the ensemble. For compilation, we assign higher weights to the predictiv e distributions of chunks that exhibit greater similarity to the input query . This is expected to enhance the final ensemble prediction. W e conduct extensiv e experiments on v arious bench- marks, including image captioning, classification, and visual question answering (VQA), using several state-of-the-art L VLMs, such as LLaV A-O V [ 29 ], Qwen2.5-VL [ 4 ], and InternVL3.5 [ 54 ]. Our results demonstrate that the ICL ca- pability of L VLMs emerges e ven when using an ensemble of next-token predictions with short conte xt chunks, yield- ing strong accuracy at low latency . Intriguingly , in se veral cases, we observe that Parallel-ICL can outperform the full- context MM-ICL in accuracy . This suggests that ensembling chunked conte xts may mitigate the so-called “lost in the middle” [ 36 ], which is information loss in MM-ICL when dealing with very long contexts. Furthermore, we observe that the predictive distribution produced by Parallel-ICL yields high inter -chunk div ersity and query rele vance, v ali- dating the efficac y of our proposed chunking and compila- tion strategies. W e believe that our work not only achie ves a better accuracy-efficienc y trade-off b ut also introduces a new paradigm that inte grates information from multiple and div erse contexts. This could enable complex multi-modal reasoning ev en beyond the training time conte xt lengths. 2. Related W ork Large V ision Language Models (L VLMs). L VLMs are text-generati ve models integrating a pre-trained large lan- guage model (LLM) and a visual encoder via a projec- tor to translate visual features into LLM’ s token embed- dings [ 1 , 2 , 4 , 15 , 33 , 50 , 51 ]. This integration is of- ten achiev ed via visual instruction tuning [ 33 ], which fine-tunes the models on diverse multi-modal tasks, in- cluding image captioning, VQA, object detection, and OCR [ 4 , 30 , 34 , 39 , 60 ]. Recent L VLMs have also ev olved to process multiple (interlea ved) images and video by scal- ing the model parameters, datasets, and the number of vi- sual tokens for visual instruction tuning [ 11 , 30 ]. Similar to LLMs, L VLMs possess zero-shot capability for unseen tasks given by users’ input prompts [ 1 , 33 ] and can solve the tasks through the contextual guidance, such as chain-of- thought prompting [ 20 , 41 , 42 , 58 , 64 ] and in-context learn- ing [ 2 , 28 , 47 , 65 ]. In this paper , we assume that L VLMs are trained with instruction tuning that enables in-context learning for unseen multi-modal tasks. Multi-modal In-context Learning (MM-ICL). In-conte xt learning (ICL, [ 7 ]) is an adaptation paradigm for LLMs on unseen tasks, defined by user instructions and multiple demonstrations (input-output pairs) [ 14 , 56 ]. L VLMs in- herit the ICL capability and sho w remarkable performance in multi-modal reasoning tasks [ 28 , 65 ], especially out-of- distribution tasks [ 62 ]. W e refer to this capability for multi- modal tasks as multi-modal ICL (MM-ICL). F or MM-ICL, sev eral studies [ 5 , 10 , 45 ] have re vealed important demon- stration properties, such as their size, selection strategy , and order . Since longer demonstration contexts degrade infer- ence speed, these studies hav e also proposed empirical meth- ods for constructing ef fecti ve input prompts based on demon- stration search algorithms with query similarity [ 5 , 45 ]. These techniques are also applicable in our method, as the problem setting is compatible with the original MM-ICL. Efficient Inference f or MM-ICL. T o reduce the inference ov erhead of MM-ICL, Peng et al. [ 44 ] and Jiang et al. [ 26 ] hav e lev eraged task vectors [ 21 ] extracted from intermedi- ate activ ation outputs of Transformers to internally mimic MM-ICL without using demonstrations at inference time. 2 Demo 1 Demo 2 Demo 𝑁 ⋮ Multi - modal Fea ture Space Chunk 1 Chunk 2 Chunk 3 Chunk 𝐾 ⋮ LVLM Logit 1 Logit 2 Logit 3 Logit 𝐾 ⋮ Query 𝑤 ! 𝑤 " 𝑤 # 𝑤 $ × × × × ⋮ Similarity - based Weights ∑ Output Figure 2. Pipeline of Parallel-ICL . W e cluster demonstrations in a multi-modal feature space and utilize each cluster as chunks (conte xt chunking). Then, we process chunk-wise contexts with L VLMs and weight their outputs (logits) based on query-chunk similarity , composing an ensemble for the final prediction as PoE (context compilation). This can be computed by the weighted sum of outputs at the logit lev el. In principle, they first detect attention heads where the out- puts should be replaced by task vectors via optimizations or heuristics, and then compute task vectors from many demon- strations. Finally , L VLMs output tokens by replacing the acti vation v ectors with the task v ectors. While these methods can omit demonstrations from input conte xts and speed up inference, the y require a large number of demonstrations and per-task optimizations be yond inference, compromising the flexibility and dynamic nature of the original MM-ICL. In contrast, our method is designed in a plug-and-play manner and can be dynamically performed without requiring any additional datasets or optimizations. Efficient Inference f or General L VLMs. Efficient L VLM inference is a primary concern, as an image often requires thousands of tokens to be represented in L VLMs [ 4 ]. In this context, the current mainstream can be roughly cate gorized into two directions: (i) pruning or merging unimportant to- kens or KV cache entries to reduce redundancy [ 3 , 8 , 9 , 37 , 57 , 59 , 63 ], and (ii) redesigning model architectures for more ef ficient inference [ 19 , 23 , 25 , 31 , 61 ]. Our research can also be vie wed as one approach for ef ficient L VLM inference, but it differs in that our method is specifically tailored for MM- ICL. Furthermore, our method is applicable in a plug-and- play manner and is lar gely orthogonal to these general ef fi- ciency methods, allo wing it to be easily combined with them. 3. Preliminaries W e briefly introduce formulations of decoding and multi- modal in-context learning (MM-ICL) with large vision lan- guage models (L VLMs). W e also demonstrate our motiva- tion regarding the accurac y-ef ficiency trade-of f in MM-ICL through preliminary experiments. 3.1. Decoding in Large V ision Language Models Consider an auto-regressi ve L VLM parameterized by θ , which is trained on large-scale datasets to accept both im- ages and texts as input for its backbone LLM. Giv en an input image x and query text t , the probability for yielding the output token sequence y = ( y 1 , . . . , y L ) ∈ V L is defined as p θ ( y | x, t ) = L Y i =1 p θ ( y i | y H ( y ) − I ( o , y ) − 1 log 2 |V | , (7) wher e H is entr opy and I ( o , y ) is defined as follows: I ( o , y ) := I relev − I redun , (8) I relev := K X i =1 I ( o i ; y ) , (9) I redun := I multi ( o | y ) − I multi ( o ) , (10) 4 I ( o ; y ) is mutual information between o and y , and I multi ( · ) is called mutual information, which gener alizes mutual in- formation for multiple variables. This theorem indicates that the lo wer bound can be decom- posed by the rele vance term I relev and the redundancy term I redun since H ( y ) and log 2 |V | are constants. Intuiti vely , I relev represents the total correlation between the ground truth y and each model’ s output o i , i.e., the accuracy of each model’ s prediction. Meanwhile, I redun can be seen as the indicator of the diversity of the predictions gi ven by o as the subtraction in Eq. ( 10 ) represents the amount of duplicated information among o = { o 1 , . . . , o K } . In summary , this theorem implies that an effecti ve ensemble requires (i) high relev ance (i.e., larger I relev , meaning each model’ s output o i is highly correlated with the ground truth y , and (ii) high div ersity (smaller I redun ), meaning the information shared among models o is minimized. According to this theoretical observ ation, (i) selecting chunks based on diversity , and (ii) weighting chunk-wise predictions { p θ ( y | C k , x, t ) } K k =1 based on task-relevance are important to improve the performance of Parallel-ICL. T o achiev e these properties, we design (i) context chunking to maximize the div ersity of chunk-wise predictions and (ii) context compilation to prioritize the task-relev ant predictions. Since the bounds in Eq. ( 7 ) are not computable prior to inference (i.e., before observing y ), we present practical strategies in the rest of this section. 5.3. Algorithm Algorithm 1 shows the o verall procedures of P arallel-ICL. Context Chunking. T o ensure the div ersity of chunk-wise predictions by p ( y |C k , x, t ) , we partition the demonstrations E into K subsets such that each chunk C k represents a dif- ferent type of task. Concretely , we perform k-means cluster- ing [ 38 , 40 ] on the demonstration feature ψ ( x, t ) giv en by a multi-modal feature extractor ψ (e.g., CLIP [ 12 , 46 ]) by solving the following: arg min C = { C 1 ,...,C K } K X k =1 | C k | X j =1 ∥ ψ ( x j , t j ) − ¯ ψ k ∥ 2 2 , (11) ψ ( x, t ) := [ ψ img ( x ) , ψ txt ( t )] (12) ¯ ψ k = 1 | C k | | C k | X j =1 ψ ( x j , t j ) , (13) where ψ img and ψ txt are the vision and text encoders of ψ . That is, we expect to increase the relativ e div ersity among chunk-wise predictions by constructing each chunk with sim- ilar demonstrations via clustering. Empirically , we confirm that this context chunking with multi-modal features im- prov es task accuracy and di versity more than other features (i.e., image-/text-only features), as sho wn in Section 6.4 . Context Compilation. T o amplify the task-relev ance of chunk-wise predictions, we compute a PoE weight w k in Eq. ( 3 ) according to the similarity between the task defined by the query question t and the task defined by questions { t 1 , . . . , t | C k | } in a demonstration chunk C k : w k = exp( s k ) P j ∈{ 1 ,...,K } exp( s j ) (14) s k = 1 | C k | | C k | X j =1 ⟨ ψ ( x, t ) , ψ ( x j , t j ) ⟩ ∥ ψ ( x, t ) ∥ 2 ∥ ψ ( x j , t j ) ∥ 2 (15) Through this weight computation, we aim to enlar ge the ov erall task-relev ance of predictions by prioritizing more task-related predictions in the compilation process. 6. Experiments W e ev aluate our Parallel-ICL through (i) a proof-of-concept by varying the demonstration number N and chunk number K , (ii) the inference performance of accurac y and speed across a wide range of benchmarks, and (iii) the analysis, including ablation studies of Parallel-ICL. 6.1. Settings Models. W e used publicly av ailable L VLMs on Hugging- Face [ 55 ]: LLaV A-O V -7B [ 29 ], Qwen-2.5-VL-7B [ 4 ], and InternVL3.5 (8B, 14B, 38B) [ 54 ]. Baselines. W e compare Parallel-ICL with two primary plug-and-play methods that do not require additional optimization and architecture-dependent implementations, including MM-ICL : the standard full conte xt inference (equiv alent to our method with K = 1 ), and DivPrune [ 3 ]: a state-of-the-art visual token pruning method. As DivPrune was not originally designed for MM-ICL, we adapt its core principle to select a subset of demonstrations based on div ersity , providing a strong baseline for efficient ICL. Benchmark Datasets. W e used four div erse multi-modal benchmark datasets in various tasks and domains as fol- lows. MI-Bench-ICL is a specialized benchmark for MM- ICL, composed of closed-ended VQA (C-VQA), open-ended VQA (O-VQA), VQA with error-prone fine-grained vi- sual features (Hallucination), and demo-based task learn- ing (Demo). W e primarily used the Demo partition for our proof-of-concept and detailed analysis because it is suitable for examining the ICL capability yielded from demonstra- tions. GQA [ 24 ] is a general VQA dataset that contains various questions re garding object/attribute recognition, spa- tial reasoning, and logical reasoning; we used balanced partitions for testing. T extVQA [ 48 ] is a VQA specialized for reading texts in images with OCR tokens giv en by exter - nal models. Through T extVQA, we e valuate the capability to le verage OCR tokens to accurately answer questions via 5 30 40 50 60 Accuracy (%) K = 1 K = 2 K = 4 K = 8 8 16 32 Demonstration Shot N 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 Latency (sec) (a) LLaV A-O V -7B 20 30 40 50 60 Accuracy (%) K = 1 K = 2 K = 4 K = 8 8 16 32 Demonstration Shot N 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 Latency (sec) (b) Qwen2.5-VL-7B 70 72 74 76 78 80 82 Accuracy (%) K = 1 K = 2 K = 4 K = 8 8 16 32 Demonstration Shot N 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 4 . 5 Latency (sec) (c) InternVL3.5-8B Figure 3. Perf ormance trend of Parallel-ICL . Parallel-ICL ( K > 1) consistently reduces latency across models. Notably , at N = 32 , K = 2 and K = 4 can outperform full-context MM-ICL ( K = 1 ) in accuracy , potentially alleviating the “lost in the middle” problem [ 36 ]. MM-ICL. COCO Caption [ 32 ] is a representati ve image cap- tioning dataset. W e tested COCO Caption without specific instructions, i.e., t j = ∅ , and aimed to make models learn how to generate captions from giv en demonstration images. Except for MI-Bench-ICL, we construct demonstrations for MM-ICL by randomly sampling tuples of (image, question, answer) from the training set. For MI-Bench-ICL, GQA, and T extVQA, we report accuracy when exact matching outputs with the ground-truth labels. For COCO Caption, we report the CIDEr score [ 53 ]. Evaluation Metrics. In addition to task performance scores for each dataset, we report results in sev eral notable ev alu- ation metrics. T o ev aluate inference speed, we use Latency and Speedup metrics, where Latency measures the av erage inference time in seconds to respond to a single query and Speedup represents the relati ve impro vement ratio of Latenc y compared to the MM-ICL baseline with the same number of shots. Approximation Ratio is the relati ve benchmark performance ratio compared to the original MM-ICL, re- ported as the average of the ratio for each benchmark perfor- mance. Di versity and Rele vance are the metrics for ev aluat- ing whether our method aligns with its theoretical motiv ation (Section 5.2 ). W e define proxy metrics for inter-chunk di- versity and query rele vance based on the KL-di ver gence as Div ersity := 1 LK L X l =1 K X i =1 K X j =1 ,j = i D KL ( p i ∥ p j ) , (16) Relev ance := 1 L L X l =1 exp( − β D KL ( p E ∥ p C )) , (17) where D KL ( · ) is KL-div ergence, p i = p θ ( y l | y 100%) compared to full-context MM-ICL. Combining P arallel-ICL with DivPrune yields an e xcellent accuracy-ef ficiency trade-of f. Latency Speedup Appr ox. Ratio MI-Bench-ICL GQA T extVQA COCO Caption C-VQA O-VQA Hall. Demo LLaV A-OV -7B MM-ICL (32-shot) 9.662 1.000 × 100.00% 65.20 61.60 79.20 58.90 68.79 73.86 99.63 DivPrune (32 → 16-shot) 5.065 1.908 × 99.63% 63.80 61.00 77.50 61.70 67.99 73.60 99.74 DivPrune (32 → 8-shot) 2.834 3.410 × 94.39% 50.90 61.70 79.70 60.60 64.89 70.86 90.08 Parallel-ICL (32-shot, 2-chunk) 6.673 1.448 × 100.72 % 63.30 61.30 78.60 63.40 68.87 74.36 101.01 Parallel-ICL (32-shot, 4-chunk) 5.428 1.780 × 96.51% 43.60 61.80 80.70 61.00 67.80 76.38 100.20 Parallel-ICL + Di vPrune (32 → 16-shot, 2-chunk) 3.486 2.772 × 100.66% 62.90 61.70 78.90 63.50 68.21 74.40 100.89 Qwen2.5-VL-7B MM-ICL (32-shot) 2.441 1.000 × 100.00% 65.20 61.60 79.20 58.90 88.02 84.28 74.83 DivPrune (32 → 16-shot) 1.219 2.002 × 92.52% 66.60 60.00 75.40 51.60 69.73 82.64 67.76 DivPrune (32 → 8-shot) 0.847 2.883 × 78.58% 59.00 55.10 73.40 42.80 48.78 75.22 48.04 Parallel-ICL (32-shot, 2-chunk) 2.115 1.154 × 98.95% 63.30 61.30 78.60 63.40 84.29 84.38 71.39 Parallel-ICL (32-shot, 4-chunk) 1.642 1.486 × 89.84% 52.80 61.80 80.70 62.70 65.83 79.06 60.80 Parallel-ICL + Di vPrune (32 → 16-shot, 2-chunk) 0.814 2.998 × 101.90 % 68.70 62.80 81.60 72.60 82.63 84.38 69.04 InternVL3.5-8B MM-ICL (32-shot) 7.558 1.000 × 100.00% 84.00 61.30 85.50 76.60 94.94 70.12 89.28 DivPrune (32 → 16-shot) 3.840 1.968 × 102.02% 84.80 62.50 84.80 80.70 91.44 78.18 90.66 DivPrune (32 → 8-shot) 2.083 3.628 × 94.77% 74.40 59.70 86.30 70.60 90.87 60.00 90.47 Parallel-ICL (32-shot, 2-chunk) 5.790 1.305 × 102.61 % 81.50 61.60 85.80 81.90 94.83 78.68 92.10 Parallel-ICL (32-shot, 4-chunk) 5.061 1.494 × 101.87% 77.70 62.20 86.70 80.20 92.73 80.70 92.03 Parallel-ICL + Di vPrune (32 → 16-shot, 2-chunk) 2.967 2.548 × 102.18% 79.50 62.20 85.70 81.90 94.50 78.62 91.58 0 . 4 0 . 6 0 . 8 1 . 0 1 . 2 1 . 4 Diversity × 10 − 2 0 . 5 0 . 6 0 . 7 0 . 8 Relevance 2 4 8 2 4 8 2 4 8 8-Shot 16-Shot 32-Shot Figure 4. Diversity-Relev ance T radeoff (chunk number K in marker) . Increasing the number of chunks impro ves inter -chunk div ersity but decreases the task relev ance. This trade-off can be balanced by selecting an appropriate K . ICL ( K > 1 ) consistently demonstrates strong ICL capabil- ity , with accuracy scaling with N , The accuracy difference between MM-ICL (1-chunk) and Parallel-ICL diminishes as the demonstration shot increases and the chunk number decreases. Intriguingly , for all L VLMs at N = 32 , Parallel- ICL with K = 2 or K = 4 consistently outperforms the full-context MM-ICL. This suggests a remarkable secondary benefit: partitioning the context may mitigate the “lost in the middle” phenomenon [ 5 , 36 ], where models struggle to utilize information b uried deep within a long context. By processing shorter and focused chunks, P arallel-ICL appears better able to lev erage all demonstrations. For the chunk number K , a larger K tends to yield a lesser approximation of task accuracy for each N . This can be due to the tradeof f between the div ersity and rele vance of the predictiv e distrib utions composed by Eq. ( 4 ) . As discussed in Section 5.2 , both div ersity and relev ance can contribute to the generalization of ensemble predictions. In Parallel- ICL, increasing the number of chunks improv es the div ersity , while it degrades the rele v ance as the number of demonstra- tions included in each chunk context decreases, as shown in Figure 4 . Therefore, we recommend selecting an appropriate K that strikes a balance between di versity and rele vance. Inference Latency . Secondly , the bottom rows of Figure 3 show that Parallel-ICL succeeds in reducing the inference latency in almost all cases. The speedup was particularly significant in large demonstration shots, e.g., 1 . 32 × at N = 32 on LLaV A-O V -7B. Ho wev er , we found that using a larger K does not necessarily improve latency , particularly for smaller N , e.g., ( N , K ) = (8 , 8) . This is because each chunked context contains an input image x and query text t as defined in Eq. ( 4 ) , and these ov erheads may outweigh the reduction in latency achie ved by parallel inference. This highlights a trade-off: while large K values are ef fective for large N , the ov erhead can outweigh the benefit for small N . This limitation can be managed by selecting K based on N . In summary , we observed that Parallel-ICL can achie ve competitiv e task accuracy while boosting inference speed under some conditions regarding N and K , demonstrating a positiv e answer to our primary research question. 6.3. Perf ormance on Multiple Benchmarks W e examine the practicality of P arallel-ICL through v ari- ous types of multi-modal benchmarks. T able 2 summarizes the av eraged inference speed and task performance for each 7 T able 3. Ablation study on MI-Bench-ICL (Demo) with LLaV A- O V -7B . Our principled components, k-means-based chunking (vs. random) and similarity-based compilation (vs. uniform), are both crucial for accuracy by impro ving div ersity and relev ance. Method Accuracy Latency Diversity ( × 10 − 2 ) ↑ Relevance ↑ MM-ICL 58.90 3.479 N/A 1.000 Parallel-ICL 63.40 2.999 0.378 0.854 w/ random chunking 59.30 2.853 0.247 0.801 w/ uniform compilation 60.00 2.846 0.378 0.777 w/ textual task features 58.90 2.853 0.273 0.786 w/ visual task features 58.20 2.936 0.310 0.778 benchmark on multiple L VLMs. As baselines, we also list the results on MM-ICL and DivPrune [ 3 ]. Our Parallel-ICL achiev es up to 1.78 × faster inference while maintaining or exceeding the full-context accuracy (Approx. Ratio 96- 102% across models). Although the demonstration reduction by DivPrune largely speeds up inference, it tends to sig- nificantly degrade task performance compared to MM-ICL. In contrast, Parallel-ICL can achie ve higher performance when the number of demonstrations per chunk matches that of DivPrune, indicating that the performance of ICL with reduced sample size has limitations, and Parallel-ICL po- tentially ov ercomes these limitations while benefiting from speed improv ements. More importantly , T able 2 shows that Parallel-ICL is orthogonal to demonstration reduction meth- ods. The Parallel-ICL + Di vPrune setting achieves the best ov erall accuracy-ef ficiency trade-off (e.g., 3.0 × speedup with 102% accurac y on Qwen2.5), demonstrating its fle xibil- ity . These results suggest that P arallel-ICL is an independent and fundamental paradigm with practicality , enabling co- ev olution with future improvements in MM-ICL to achie ve further performance enhancements and speedups. 6.4. Ablation Study W e show ablation studies that replace each component of Parallel-ICL in conte xt chunking, context compilation, and features used for task representations. Instead of k-means- based chunking by Eq. ( 11 ) , we applied random chunking, which selects demonstrations by sampling from a uniform distribution. For context compilation alternative, we used uniform compilation, ensembling chunk-wise distrib utions with uniform averaged weights. W e also tried text-only and visual-only features as the task representations for both context chunking and compilation. T able 3 shows the results on MI-Bench-ICL (Demo) with LLaV A-O V -7B. Regarding the chunking and compilation algorithm, replacing them with random chunking and uni- form compilation l argely dropped the div ersity and rele vance scores, respectively . These results ensure the design valid- ity of Parallel-ICL, i.e., enlarging inter-chunk diversity by k-means clustering with Eq. ( 11 ) and the task rele v ance by similarity-based weights Eq. ( 14 ) . For the task representa- tions, Parallel-ICL with the multi-modal features by Eq. ( 12 ) achie ved the best performance compared to ones with the uni- T able 4. Model scalability of Parallel-ICL on MI-Bench-ICL (Demo) . Parallel-ICL consistently improves speed and maintains or enhances the accuracy of MM-ICL, demonstrating its effecti veness across different model scales. Model Method Accuracy Latency Speedup InternVL3.5-8B MM-ICL (32-shot) 76.60 4.402 1.000 × Parallel-ICL (32-shot, 2-chunk) 81.90 3.785 1.163 × Parallel-ICL (32-shot, 4-chunk) 80.20 3.338 1.319 × InternVL3.5-14B MM-ICL (32-shot) 83.00 6.425 1.000 × Parallel-ICL (32-shot, 2-chunk) 84.30 5.435 1.182 × Parallel-ICL (32-shot, 4-chunk) 84.30 4.722 1.361 × InternVL3.5-38B MM-ICL (32-shot) 86.40 20.29 1.000 × Parallel-ICL (32-shot, 2-chunk) 87.00 17.56 1.155 × Parallel-ICL (32-shot, 4-chunk) 87.40 15.30 1.326 × modal textual and visual features. This is consistent with the findings in previous studies, where multi-modal features are more suitable for the task representations [ 2 , 5 , 45 ]. Remark- ably , all of the alternati ves for P arallel-ICL slightly reduce latency , indicating that the context chunking and compilation can improv e performance with little sacrifice to efficienc y . 6.5. Model Size Scalability Here, we demonstrate the scalability of Parallel-ICL regard- ing L VLM’ s model sizes. T o this end, we used the 8B, 14B, and 38B models of InternVL3.5. T able 4 shows the results. For all model sizes, Parallel-ICL stably impro ved the infer - ence speed while maintaining or improving the task accuracy . This indicates that Parallel-ICL is a flexible inference frame- work that works with v arious model sizes. 7. Conclusion W e propose P arallel-ICL, a plug-and-play inference algo- rithm that improv es the accuracy-latenc y trade-of f in MM- ICL for L VLMs. Our method partitions the demonstration context into chunks (conte xt chunking) and processes them in parallel, integrating predictions at the logit le vel (con- text compilation). This principled approach is guided by ensemble learning principles, utilizing clustering to maxi- mize div ersity and query similarity for weighted compilation. Experiments sho w that Parallel-ICL significantly impro ves inference speed (up to 1.78 × ) while achieving task perfor - mance that is comparable to, or e ven surpasses, that of full- context MM-ICL. W e identify two primary limitations: (i) a query processing ov erhead that can negate speedups when the number of demonstrations ( N ) is low and the number of chunks ( K ) is high, and (ii) K itself is a crucial hyper- parameter that balances the trade-off between inter-chunk div ersity and query relevance, requiring careful selection. Despite these considerations, Parallel-ICL of fers a practical and ef fectiv e solution to the MM-ICL ef ficiency challenge. It also introduces a new paradigm for inte grating multiple, di- verse conte xts, potentially enabling more comple x reasoning beyond fix ed context lengths. 8 References [1] Josh Achiam, Ste ven Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint , 2023. 1 , 2 [2] Jean-Baptiste Alayrac, Jeff Donahue, P auline Luc, Antoine Miech, Iain Barr , Y ana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. In Advances in neural information processing systems, 2022. 1 , 2 , 8 [3] Saeed Ranjbar Alv ar , Gursimran Singh, Mohammad Akbari, and Y ong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. In Proceedings of the Computer V ision and Pattern Recognition Conference , 2025. 3 , 5 , 8 [4] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025. 1 , 2 , 3 , 5 [5] Folco Bertini Baldassini, Mustafa Shukor , Matthieu Cord, Laure Soulier , and Benjamin Piwowarski. What makes multimodal in-context learning work? In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition (CVPR) W orkshops , pages 1539–1550, 2024. 1 , 2 , 7 , 8 [6] Gavin Bro wn. An information theoretic perspecti ve on multi- ple classifier systems. In International W orkshop on Multiple Classifier Systems, pages 344–353. Springer , 2009. 2 , 4 [7] T om Brown, Benjamin Mann, Nick Ryder , Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry , Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger , T om Henighan, Rew on Child, Aditya Ramesh, Daniel Ziegler , Jef- frey W u, Clemens Winter , Chris Hesse, Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gray , Benjamin Chess, Jack Clark, Christopher Berner , Sam McCandlish, Alec Radford, Ilya Sutske ver , and Dario Amodei. Language models are few- shot learners. In Advances in Neural Information Processing Systems, 2020. 1 , 2 , 3 [8] Jieneng Chen, Luoxin Y e, Ju He, Zhao-Y ang W ang, Daniel Khashabi, and Alan Y uille. Ef ficient large multi-modal mod- els via visual context compression. In Advances in Neural Information Processing Systems, 2024. 3 [9] Liang Chen, Haozhe Zhao, T ianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer V ision, 2024. 3 [10] Shuo Chen, Zhen Han, Bailan He, Jianzhe Liu, Mark Buckley , Y ao Qin, Philip T orr, V olker Tresp, and Jindong Gu. Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF W inter Conference on Applications of Computer V ision (W A CV) , pages 6000– 6010. IEEE, 2025. 2 [11] Zhe Chen, Jiannan W u, W enhai W ang, W eijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Intern vl: Scaling up vision founda- tion models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024. 2 [12] Mehdi Cherti, Romain Beaumont, Ross W ightman, Mitchell W ortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuh- mann, Ludwig Schmidt, and Jenia Jitsev . Reproducible scaling laws for contrastiv e language-image learning. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition, pages 2818–2829, 2023. 5 [13] Daiki Chijiwa, T aku Hase gaw a, K yosuke Nishida, Shin’ya Y a- maguchi, T omoya Ohba, T amao Sakao, and Susumu T akeuchi. Lossless vocab ulary reduction for auto-regressi ve language models. arXiv preprint arXi v:2510.08102, 2025. 4 [14] Aakanksha Chowdhery , Sharan Narang, Jacob De vlin, Maarten Bosma, Gaura v Mishra, Adam Roberts, Paul Barham, Hyung W on Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research , 24(240):1–113, 2023. 2 [15] W enliang Dai, Junnan Li, Dongxu Li, Anthony T iong, Junqi Zhao, W eisheng W ang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: T owards general-purpose vision-language models with instruction tuning. In Advances in neural information processing systems, 2023. 1 , 2 [16] T ri Dao. Flashattention-2: Faster attention with better paral- lelism and work partitioning. In International Conference on Learning Representations, 2024. 4 [17] Robert M Fano and Da vid Hawkins. Transmission of infor - mation: A statistical theory of communications. American Journal of Physics, 29(11):793–794, 1961. 2 , 4 [18] Artyom Gadetsky , Andrei Atanov , Y ulun Jiang, Zhitong Gao, Ghazal Hosseini Mighan, Amir Zamir, and Maria Br- bic. Large (vision) language models are unsupervised in- context learners. In International Conference on Learning Representations, 2025. 1 [19] Mukul Gagrani, Raghavv Goel, W onseok Jeon, Jun young Park, M ingu Lee, and Christopher Lott. On speculati ve decod- ing for multimodal large language models. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition (CVPR) W orkshops, 2024. 3 [20] Jun Gao, Y ongqi Li, Ziqiang Cao, and W enjie Li. Interleav ed- modal chain-of-thought. In Proceedings of the Computer V ision and Pattern Recognition Conference, 2025. 2 [21] Roee Hendel, Mor Gev a, and Amir Globerson. In-conte xt learning creates task vectors. In Empirical Methods in Natural Language Processing, 2023. 2 [22] Geoffre y E Hinton. Training products of experts by mini- mizing contrastive diver gence. Neural computation , 14(8): 1771–1800, 2002. 2 , 4 [23] W enxuan Huang, Zijie Zhai, Y unhang Shen, Shaosheng Cao, Fei Zhao, Xiangfeng Xu, Zheyu Y e, Y ao Hu, and Shaohui Lin. Dynamic-llava: Efficient multimodal large language models via dynamic vision-language context sparsification. In International Conference on Learning Representations , 2025. 3 9 [24] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and composi- tional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2019. 5 [25] Y icheng Ji, Jun Zhang, Heming Xia, Jinpeng Chen, Lidan Shou, Gang Chen, and Huan Li. Specvlm: Enhancing specula- tiv e decoding of video llms via verifier-guided tok en pruning. In The 2025 Conference on Empirical Methods in Natural Language Processing, 2025. 3 [26] Y uchu Jiang, Jiale Fu, Chenduo Hao, Xinting Hu, Y ingzhe Peng, Xin Geng, and Xu Y ang. Mimic in-context learn- ing for multimodal tasks. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , 2025. 2 [27] Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural computation , 6(2): 181–214, 1994. 4 [28] Hugo Laurençon, Lucile Saulnier , Léo Tronchon, Stas Bek- man, Amanpreet Singh, Anton Lozhkov , Thomas W ang, Sid- dharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents. In Advances in Neural Information Processing Systems, 2023. 2 [29] Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y anwei Li, Zi- wei Liu, et al. Llav a-onevision: Easy visual task transfer . arXiv preprint arXi v:2408.03326, 2024. 1 , 2 , 4 , 5 [30] Feng Li, Renrui Zhang, Hao Zhang, Y uanhan Zhang, Bo Li, W ei Li, Zejun Ma, and Chunyuan Li. Llav a-next-interlea ve: T ackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXi v:2407.07895, 2024. 1 , 2 [31] Y inan Liang, Ziwei W ang, Xiuwei Xu, Jie Zhou, and Ji- wen Lu. Efficientlla va: Generalizable auto-pruning for large vision-language models. In Proceedings of the Computer V ision and Pattern Recognition Conference, 2025. 3 [32] Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Dev a Ramanan, Piotr Dollár , and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer V ision . Springer , 2014. 6 [33] Haotian Liu, Chunyuan Li, Qingyang W u, and Y ong Jae Lee. V isual instruction tuning. In Advances in Neural Information Processing Systems, 2023. 1 , 2 [34] Haotian Liu, Chunyuan Li, Y uheng Li, and Y ong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition, 2024. 1 , 2 [35] Haowei Liu, Xi Zhang, Haiyang Xu, Y aya Shi, Chaoya Jiang, Ming Y an, Ji Zhang, Fei Huang, Chunfeng Y uan, Bing Li, et al. Mibench: Evaluating multimodal lar ge language models ov er multiple images. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , 2024. 4 , 6 [36] Nelson F Liu, Ke vin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long con- texts. T ransactions of the Association for Computational Linguistics, 12:157–173, 2024. 2 , 6 , 7 [37] Zuyan Liu, Benlin Liu, Jiahui W ang, Y uhao Dong, Guangyi Chen, Y ongming Rao, Ranjay Krishna, and Jiwen Lu. Effi- cient inference of vision instruction-following models with elastic cache. In European Conference on Computer V ision , pages 54–69, 2024. 3 [38] Stuart Lloyd. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137, 1982. 5 [39] Haoyu Lu, W en Liu, Bo Zhang, Bingxuan W ang, Kai Dong, Bo Liu, Jingxiang Sun, T ongzheng Ren, Zhuoshu Li, Hao Y ang, et al. Deepseek-vl: to wards real-world vision-language understanding. arXiv preprint arXi v:2403.05525, 2024. 2 [40] James MacQueen. Some methods for classification and anal- ysis of multiv ariate observations [c]. In Proc of Berkeley Symposium on Mathematical Statistics & Probability , pages 281–297, 1965. 5 [41] Chancharik Mitra, Brandon Huang, T rev or Darrell, and Roei Herzig. Compositional chain-of-thought prompting for large multimodal models. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , 2024. 2 [42] Debjyoti Mondal, Suraj Modi, Subhadarshi Panda, Rit- uraj Singh, and Godawari Sudhakar Rao. Kam-cot: Knowledge augmented multimodal chain-of-thoughts rea- soning. In Proceedings of the AAAI conference on artificial intelligence, 2024. 2 [43] T erufumi Morishita, Gaku Morio, Shota Horiguchi, Hiroaki Ozaki, and Nobuo Nukag a. Rethinking fano’ s inequality in ensemble learning. In International Conference on Machine Learning. PMLR, 2022. 2 , 4 [44] Y ingzhe Peng, chenduo hao, Xinting Hu, Jiawei Peng, Xin Geng, and Xu Y ang. LIVE: Learnable in-context vector for visual question answering. In Advances in neural information processing systems, 2024. 2 [45] Libo Qin, Qiguang Chen, Hao Fei, Zhi Chen, Min Li, and W anxiang Che. What factors affect multi-modal in-context learning? an in-depth exploration. In Advances in Neural Information Processing Systems, 2024. 1 , 2 , 8 [46] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language su- pervision. In International conference on machine learning . PMLR, 2021. 5 [47] Mustafa Shukor , Alexandre Rame, Corentin Dancette, and Matthieu Cord. Beyond task performance: ev aluating and reducing the flaws of large multimodal models with in- context-learning. In International Conference on Learning Representations, 2024. 2 [48] Amanpreet Singh, V iv ek Natarajan, Meet Shah, Y u Jiang, Xin- lei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. T owards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019. 5 [49] Quan Sun, Y ufeng Cui, Xiaosong Zhang, Fan Zhang, Qiy- ing Y u, Y ueze W ang, Y ongming Rao, Jingjing Liu, T iejun 10 Huang, and Xinlong W ang. Generati ve multimodal models are in-conte xt learners. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , 2024. 1 [50] Gemma T eam, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino V ieillard, Ramona Merhej, Sarah Perrin, T a- tiana Matejovicov a, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint , 2025. 1 , 2 [51] Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Es- lami, Oriol V inyals, and Felix Hill. Multimodal few-shot learning with frozen language models. In Advances in Neural Information Processing Systems, 2021. 1 , 2 [52] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, 2017. 1 [53] Ramakrishna V edantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalu- ation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 6 [54] W eiyun W ang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang W ei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility , reasoning, and efficienc y . arXiv preprint arXi v:2508.18265, 2025. 2 , 5 [55] Thomas W olf, L ysandre Debut, V ictor Sanh, Julien Chau- mond, Clement Delangue, Anthony Moi, Pierric Cistac, T im Rault, Rémi Louf, Mor gan Funto wicz, et al. Huggingface’ s transformers: State-of-the-art natural language processing. arXiv preprint arXi v:1910.03771, 2019. 5 [56] Y angzhen W u, Zhiqing Sun, Shanda Li, Sean W elleck, and Y iming Y ang. Scaling inference computation: Compute- optimal inference for problem-solving with language models. In The 4th W orkshop on Mathematical Reasoning and AI at NeurIPS’24, 2024. 2 [57] Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Y uhang Zang, Y uhang Cao, Conghui He, Jiaqi W ang, Feng Wu, et al. Conical visual concentration for efficient large vision-language models. In Proceedings of the Computer V ision and Pattern Recognition Conference, 2025. 3 [58] Guowei Xu, Peng Jin, Ziang W u, Hao Li, Y ibing Song, Lichao Sun, and Li Y uan. Llav a-cot: Let vision language mod- els reason step-by-step. In Proceedings of the International Conference on Computer V ision, 2025. 2 [59] Chenyu Y ang, Xuan Dong, Xizhou Zhu, W eijie Su, Jiahao W ang, Hao Tian, Zhe Chen, W enhai W ang, Lewei Lu, and Jifeng Dai. Pvc: Progressi ve visual token compression for unified image and video processing in large vision-language models. In Proceedings of the Computer V ision and Pattern Recognition Conference, 2025. 3 [60] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, W enqi Shao, W enwei Zhang, Y u Liu, Kai Chen, and Ping Luo. Gpt4roi: Instruction tuning large language model on re gion- of-interest. In European conference on computer vision , 2024. 2 [61] Shaolei Zhang, Qingkai Fang, Zhe Y ang, and Y ang Feng. Llav a-mini: Efficient image and video large multimodal mod- els with one vision token. In International Conference on Learning Representations, 2025. 3 [62] Xingxuan Zhang, Jiansheng Li, W enjing Chu, Renzhe Xu, Y uqing Y ang, Shikai Guan, Jiazheng Xu, Liping Jing, Peng Cui, et al. On the out-of-distrib ution generalization of large multimodal models. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , 2025. 1 , 2 , 3 [63] Y uan Zhang, Chun-Kai Fan, Junpeng Ma, W enzhao Zheng, T ao Huang, Kuan Cheng, Denis A Gudovskiy , T omoyuki Okuno, Y ohei Nakata, Kurt Keutzer , et al. Sparsevlm: V i- sual token sparsification for ef ficient vision-language model inference. In International Conference on Machine Learning , 2025. 3 [64] Zhuosheng Zhang, Aston Zhang, Mu Li, hai zhao, George Karypis, and Alex Smola. Multimodal chain-of-thought reasoning in language models. T ransactions on Machine Learning Research, 2024. 2 [65] Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng W ang, W enjuan Han, and Baobao Chang. Mmicl: Empowering vision-language model with multi-modal in-context learning. In International Conference on Learning Representations, 2024. 1 , 2 , 3 [66] Zhi-Hua Zhou and Nan Li. Multi-information ensemble div ersity . In International W orkshop on Multiple Classifier Systems, pages 134–144. Springer , 2010. 2 , 4 [67] Y ufan Zhuang, Chandan Singh, Liyuan Liu, Jingbo Shang, and Jianfeng Gao. V ector-ICL: In-conte xt learning with con- tinuous vector representations. In International Conference on Learning Representations, 2025. 2 [68] Y ongshuo Zong, Ondrej Bohdal, and Timothy Hospedales. Vl-icl bench: The devil in the details of multimodal in- context learning. In The Thirteenth International Conference on Learning Representations, 2025. 1 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment