테스트 시간 연산이 해를 끼칠 수 있다: 빔 서치에서의 과대평가 편향
이 논문은 LLM 빔 서치에서 스코어러의 잡음이 클수록 후보 풀을 확대하면 과대평가 편향이 증가해 성능이 악화된다는 이론을 제시한다. 스코어러의 신호‑대‑잡음 비율(Δ/σ)에 따라 최대 유용 빔 폭 ˆk가 결정되며, 퍼플렉시티와 같은 고잡음 스코어러는 ˆk=1(검색 효과 없음)을, PRM과 같은 저잡음 스코어러는 ˆk≥4(성능 향상)를 보인다.
저자: Gal Dalal, Assaf Hallak, Gal Chechik
본 논문은 대형 언어 모델(LLM)의 추론 단계에서 빔 서치를 적용할 때, 스코어러의 잡음 수준에 따라 빔 폭을 확대하는 것이 오히려 성능을 저하시킬 수 있음을 이론과 실험으로 입증한다.
1. **문제 설정 및 배경**
LLM은 단계별 추론(Chain‑of‑Thought)이나 프로세스 감독(Process Supervision) 기법을 통해 복잡한 문제 해결 능력이 향상되었다. 이러한 환경에서 테스트‑시간 연산을 늘려 후보를 많이 생성하고, 스코어러(예: 퍼플렉시티, PRM)로 평가 후 최적 후보를 선택하는 것이 일반적이다. 그러나 기존 연구는 빔 폭을 조정하는 기준을 주로 추론 지연이나 비용에 초점을 맞추었으며, 스코어러의 품질이 낮을 경우 검색이 해를 끼칠 수 있다는 점을 체계적으로 분석하지 않았다.
2. **이론적 프레임워크**
저자들은 각 후보 i에 대해 점수 R_i = μ_i + ε_i (ε_i∼N(0,σ²))를 가정하고, 정확한 후보는 하나, 나머지는 동일한 낮은 품질 μ_w를 가진다고 설정한다(Δ=μ_c−μ_w>0). 빔 서치는 n개의 후보 중 최대 점수를 가진 후보를 선택한다. 극값 이론에 따르면, n−1개의 잘못된 후보 중 최대 점수는 μ_w에 σ√{2 log(n−1)} 정도의 편향을 추가한다. 이를 B(σ,n−1)라 정의하고, 정확한 후보는 잡음이 평균 0이므로 편향이 없다.
3. **핵심 정리와 최대 유용 빔 폭**
- **Lemma 3.1**: 과대평가 편향 B(σ,n−1)≈σ√{2 log(n−1)}.
- **Theorem 3.2**: 잘못된 후보가 선택될 확률은 (1+Δ_eff²/(2σ²))⁻¹, 여기서 Δ_eff=Δ−B.
- **Corollary 3.3**: 빔 서치가 이득을 보려면 Δ≳σ√{2 log(n−1)}.
- **Corollary 3.4**: 최대 유용 후보 수 ˆn=1+exp(Δ²/(2σ²)), 빔 폭 ˆk=⌊√ˆn⌋(본 논문에서는 n=k²).
즉, 스코어러의 신호‑대‑잡음 비율(Δ/σ)이 낮으면 ˆn≈2, ˆk=1이 되어 빔 서치가 전혀 도움이 되지 않는다. 반대로 Δ/σ가 2.33 이상이면 ˆn≥16, ˆk≥4가 가능해 실제 성능 향상이 기대된다.
4. **실험 설계**
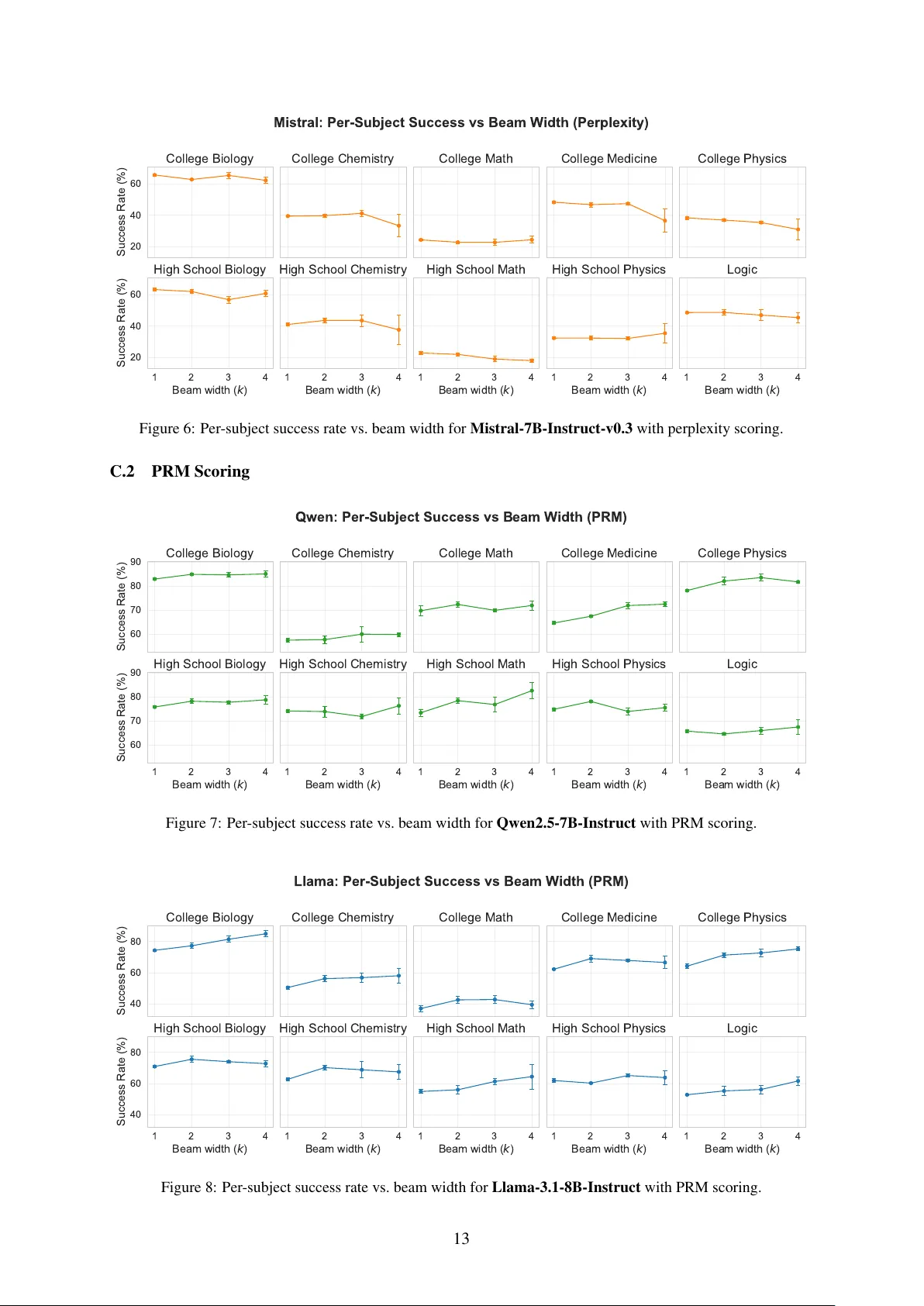
- 모델: 7B 파라미터 규모의 Qwen, Llama, Mistral 세 종류.
- 데이터: MR‑BEN(5,975 질문, 10 도메인).
- 스코어러: (1) 퍼플렉시티(자체 모델이 제공하는 예측 확률 기반), (2) PRM(학습된 프로세스 보상 모델).
- 빔 폭: 1~6까지 테스트, 후보 수는 n=k².
5. **실험 결과**
퍼플렉시티는 σ가 커 B가 크게 발생해 Δ_eff가 거의 0에 가깝다. 모든 빔 폭에서 정확도는 1‑beam과 동일하거나 약간 감소했다(ˆk=1). 반면 PRM은 σ가 작아 B가 작고, Δ_eff>0인 영역이 넓어 4~6 빔 폭에서 정확도가 최대 8.9%p 상승했다. 그래프(Figure 1)는 두 스코어러가 동일 모델·알고리즘에 대해 전혀 다른 ˆk를 보이는 모습을 명확히 보여준다.
6. **실무 적용 방안**
저자들은 스코어러의 σ를 추정하는 방법(예: 초기 파일럿에서 점수 분산 측정)과 Δ를 간접적으로 평가하는 지표(정답과 오답 간 평균 점수 차이)를 제시한다. 이러한 진단을 통해 ˆk를 사전에 결정하고, 스코어러 품질이 충분히 높지 않을 경우 빔 폭을 늘리지 말고 스코어러 자체를 개선(예: PRM 학습)하는 것이 비용 효율적이라고 주장한다.
7. **의의와 한계**
이 논문은 “더 많은 검색이 항상 좋은 결과를 만든다”는 일반적인 믿음에 반해, 스코어러 잡음이 큰 경우 과대평가 편향이 성능을 저하시킬 수 있음을 수학적으로 증명하고, 실제 LLM 추론에 적용 가능한 실험적 검증을 제공한다. 한계로는 두‑클래스 품질 모델(정답 1개, 나머지 동일)과 Gaussian 잡음 가정이 실제 복잡한 상황을 완전히 포괄하지 못한다는 점이다. 또한 후보 생성 방식이 n=k²에 고정돼 있어, 다른 확장 전략에 대한 일반화는 추가 연구가 필요하다.
8. **결론**
스코어러의 신호‑대‑잡음 비율이 빔 서치의 유효 빔 폭을 결정한다는 핵심 메시지를 제시한다. 퍼플렉시티와 같은 고잡음 스코어러는 검색을 전혀 이득으로 만들지 못하지만, PRM과 같은 저잡음 스코어러는 적절히 넓은 빔 폭을 통해 의미 있는 성능 향상을 제공한다. 따라서 실무에서는 스코어러 품질을 먼저 평가하고, 그에 맞는 빔 폭을 선택하거나 스코어러 자체를 개선하는 전략이 권장된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기