More Test-Time Compute Can Hurt: Overestimation Bias in LLM Beam Search
Wider beam search should improve LLM reasoning, but when should you stop widening? Prior work on beam width selection has focused on inference efficiency \citep{qin2025dsbd, freitag2017beam}, without analyzing whether wider search can \emph{hurt} out…
Authors: Gal Dalal, Assaf Hallak, Gal Chechik
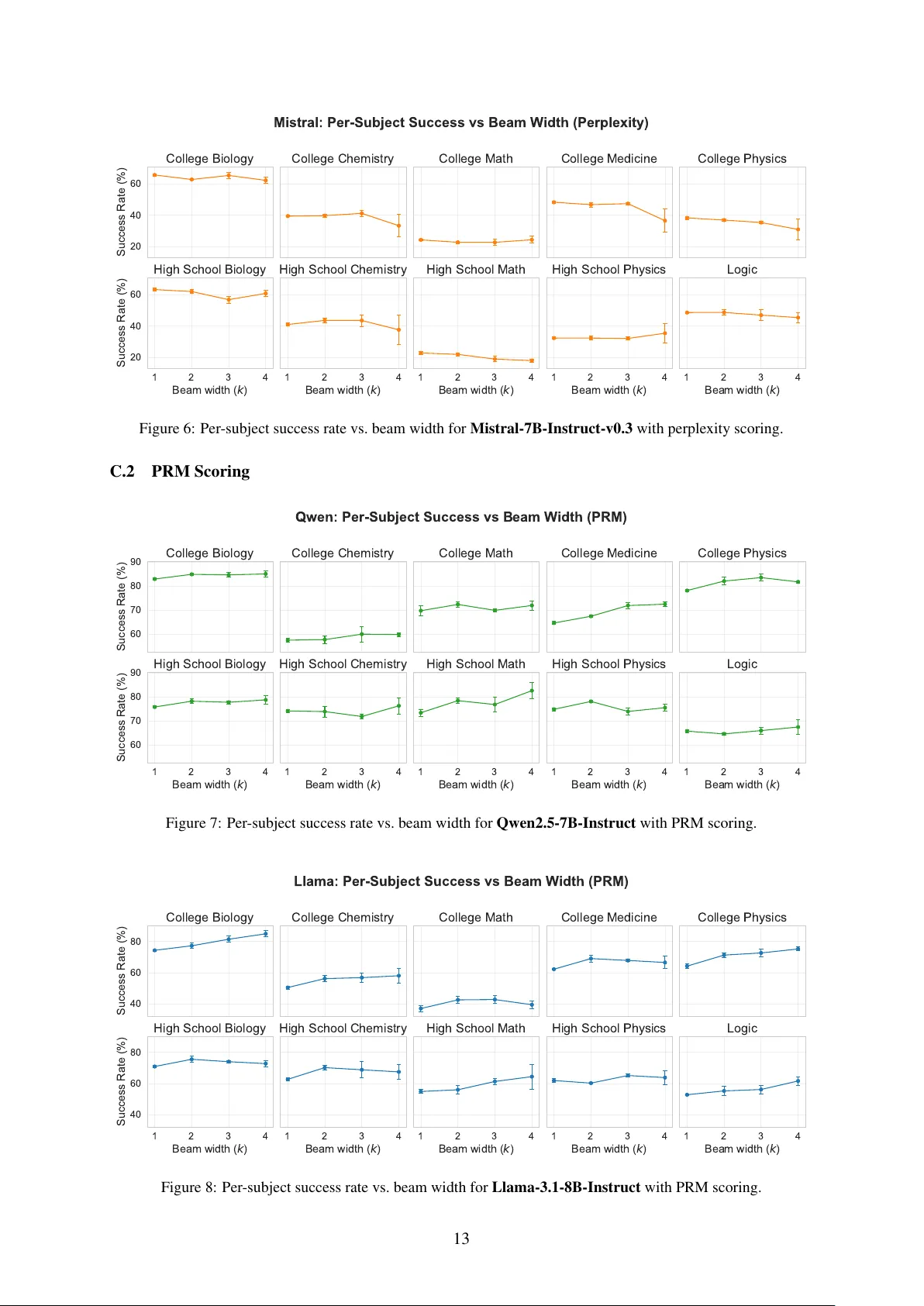
Mor e T est-T ime Compute Can Hurt: Over estimation Bias in LLM Beam Sear ch Gal Dalal 1 * , Assaf Hallak 1 * , Gal Chechik 1,2 , Yftah Ziser 1,3 1 NVIDIA Research, 2 Bar-Ilan Uni versity , 3 Uni versity of Groningen Abstract W ider beam search should improv e LLM rea- soning, but when should you stop widening? Prior work on beam width selection has fo- cused on inference efficienc y ( Qin et al. , 2025 ; Freitag and Al-Onaizan , 2017 ), without ana- lyzing whether wider search can hurt output quality . W e present an analysis, grounded in Extreme V alue Theory , that answers this ques- tion. Beam selection over noisy scorer outputs introduces a systematic ov erestimation bias that grows with the candidate pool size, and we de- riv e a maximum useful beam width ˆ k beyond which search degrades performance. This crit- ical width depends on the signal-to-noise ra- tio of the scorer: ˆ k grows exponentially with (∆ /σ ) 2 , where ∆ > 0 is the quality advantage of correct paths over incorrect ones and σ is the scorer noise. W e validate this theory by comparing perplexity-guided and PRM-guided beam search across three 7B-parameter mod- els and ten domains on MR-BEN (5,975 ques- tions). Perplexity scoring, with its high noise, yields ˆ k = 1 : search provides no benefit at any width tested. PRM scoring, with lower noise, yields ˆ k ≥ 4 , with gains of up to 8.9 percentage points. The same model, the same algorithm, but different scorers place ˆ k at opposite ends of the beam width range. Our analysis identi- fies the scorer’ s signal-to-noise ratio as the key quantity gov erning beam width selection, and we propose diagnostic indicators for choosing the beam width in practice. 1 Introduction Large Language Models (LLMs) have demon- strated remarkable progress on complex reasoning tasks, in large part due to techniques that elicit and le verage step-by-step solutions ( W ei et al. , 2022 ). A major recent thread is pr ocess supervision : in- stead of judging only the final answer , a model (or learned verifier) provides feedback on intermediate * Equal contribution. steps, enabling search and credit assignment ov er reasoning traces. In structured domains such as mathematics, Process Rew ard Models (PRMs) that score each step ha ve prov en particularly effecti ve ( Lightman et al. , 2023 ; Cui et al. , 2025 ). At the same time, there is growing interest in test-time compute scaling —allocating additional inference-time computation to improv e accuracy via sampling and search ( Snell et al. , 2024 ). Com- mon instantiations include best-of- n sampling, reranking, and beam search o ver partial chains of thought. A pervasi ve implicit assumption is that any reasonable scoring signal can driv e such search: generate more candidates, score them, and pick the best. This assumption has not been rigorously e x- amined. A natural candidate for a cheap scoring signal is perplexity , a model’ s measure of predictiv e con- fidence. Se veral intrinsic signals have been pro- posed for self-ev aluation, from entropy-based self- certainty ( Kang et al. , 2025 ) to Mark ovian re ward adjustments ( Ma et al. , 2025 ). W e focus on per- plexity as the most widely used and simplest such signal. It requires no step-le vel training and is av ailable for any autoregressi ve model, making it a representati ve test of whether training-free intrinsic signals can driv e reasoning-time search. If perplex- ity suf ficed, one could av oid the expense of training specialized PRMs. Y et it is unclear whether per- plexity is informati ve enough at the granularity of intermediate reasoning steps, or whether its noise causes search to select fluent but unf aithful steps. A related ov erestimation phenomenon has been observed in model-based reinforcement learning, where tree search with learned value functions can degrade policy performance ( Dalal et al. , 2021 ). Our analysis addresses the distinct setting of LLM beam search, where the scorer is a perplexity model or PRM and the search operates over natural lan- guage reasoning traces. W e show that beam search introduces a systematic ov erestimation bias: an 1 1 2 3 4 B e a m w i d t h ( k ) 67.5 70.0 72.5 75.0 77.5 80.0 82.5 Success Rate (%) Qwen Perplexity (Self-Scored) MathShepherd PRM 1 2 3 4 B e a m w i d t h ( k ) 50 55 60 65 70 Success Rate (%) Llama Perplexity (Self-Scored) MathShepherd PRM 1 2 3 4 B e a m w i d t h ( k ) 35 40 45 50 55 Success Rate (%) Mistral Perplexity (Self-Scored) MathShepherd PRM Perplexity vs PRM Scoring: Effect of beam width Figure 1: Per-model comparison of perplexity (gray) vs. PRM (green) scoring across beam widths. The two scorers place the predicted maximum useful beam width ˆ k at opposite ends of the range: perplexity curves are flat ( ˆ k = 1 ), while PRM curves rise through beam width 4 ( ˆ k ≥ 4 ), illustrating how scorer quality determines the optimal beam width. extreme-v alue effect in which the expected maxi- mum score among incorrect candidates grows with search width. From this we deri ve an e xplicit crite- rion for when search is beneficial and a threshold beyond which widening de grades performance. Our study addresses three questions, each an- swered by a corresponding contribution: 1. What determines the maximum useful beam width? W e de velop a formal analysis based on Extreme V alue Theory showing that beam selection introduces a systematic ov er- estimation bias proportional to scorer noise σ . W e deriv e a predicted maximum useful beam width ˆ k that depends on the scorer’ s signal-to-noise ratio ∆ /σ . Beyond ˆ k , the bias exceeds the quality gap and search degrades performance, a phenomenon we call r ewar d in version . 2. Does scorer quality change the answer? W e v alidate the theory across three model families and ten reasoning domains (Figure 1 ). Per- plexity scoring yields no benefit at an y beam width, while PRM scoring yields meaningful gains, as the theory predicts. 3. How should the beam width be chosen in practice? W e propose a principled approach to beam width selection based on diagnostic indicators such as score mar gins and pilot- run comparisons that signal whether a scorer can support wider search. While prior work adjusts beam width for inference speed ( Qin et al. , 2025 ), our criterion targets output qual- ity . W e also sho w that in vesting in scorer quality is f ar more ef fective than widening the beam. 2 Background and Related W ork 2.1 Beam Width Selection Prior work on beam width selection has fo- cused on inference ef ficiency . Freitag and Al- Onaizan ( 2017 ) introduced adaptiv e pruning strate- gies for neural machine translation, achieving up to 43% speedup without degrading quality . Qin et al. ( 2025 ) proposed Dynamic-W idth Specula- ti ve Beam Decoding, dynamically adjusting beam count to balance latency and quality in LLMs. These approaches treat beam width as an effi- ciency parameter . W e address a complementary question: when does wider search de grade out- put quality? W e show the answer depends on the scorer’ s signal-to-noise ratio and deri ve an e xplicit threshold beyond which additional candidates hurt performance. 2.2 Process Supervision for LLM Reasoning Chain-of-Thought prompting sho wed that step-by- step reasoning improves LLM performance ( W ei et al. , 2022 ; Chen et al. , 2022 ). Process Re ward Models (PRMs) extend this by scoring interme- diate steps ( Lightman et al. , 2023 ; Zheng et al. , 2025 ), with Math-Shepherd ( W ang et al. , 2024 ) reducing annotation costs via Monte Carlo estima- tion. Cobbe et al. ( 2021 ) sho wed that best-of- N selection with a trained verifier matches a 30 × pa- rameter increase. 2 PRMs face re ward hacking and distrib utional shift ( Zheng et al. , 2025 ; Cui et al. , 2025 ). Agrawal et al. ( 2025 ) sho w that PRM false positiv es im- pose an asymptotic ceiling on best-of- N perfor- mance, and Luo et al. ( 2025 ) establish that im- plicit Q-functions learned during fine-tuning pro- duce ov er-optimistic estimates that de grade beam search. Both findings are consistent with the ov er- estimation mechanism we formalize in Section 3 . 2.3 Inference-T ime Search “T est-time compute scaling” allocates additional inference computation to improv e performance ( Snell et al. , 2024 ). W u et al. ( 2025 ) sho w that smaller models with adv anced search achie ve Pareto-optimal cost-performance trade-offs, and Liu et al. ( 2025 ) demonstrate that optimal strategies depend on the policy model, PRM, and problem dif ficulty . The success of models like DeepSeek-R1 ( DeepSeek-AI , 2025 ) further moti vates understand- ing these limits. These studies establish that more search can help, b ut none characterize when it stops helping —the question our analysis addresses. T ree of Thoughts ( Y ao et al. , 2023 ) frames rea- soning as search ov er a tree of partial solutions. Beam search and best-of- N sampling are common strategies in this paradigm ( Xie et al. , 2023 ; Kang et al. , 2025 ), relying on a scoring function such as a PRM or a proxy like perplexity ( Jelinek et al. , 1977 ). 2.4 Over estimation Bias and Reward Over optimization Systematic o verestimation from maximization o ver noisy estimates was first identified by Thrun and Schwartz ( 1993 ) in Q-learning, where function ap- proximation combined with the max operator pro- duces upward bias. Dalal et al. ( 2021 ) extended this to tree search with learned value functions, sho wing that deeper search can degrade polic y per- formance in model-based RL. In the LLM setting, Gao et al. ( 2023 ) demon- strated rew ard ov eroptimization: optimizing against an imperfect reward model via best-of- N sampling degrades true performance past a criti- cal N —a manifestation of Goodhart’ s law . Their experiments represent a depth-1, width- N special case of beam search. The critical N at which per - formance degrades is analogous to ˆ n in our formu- lation, and the degradation is consistent with the ov erestimation mechanism that Lemma 3.1 quanti- fies via Extreme V alue Theory . 3 Theoretical Framework: Over estimation Bias in Beam Selection W e dev elop a formal analysis of why beam search with noisy scorers can de grade performance. The core insight is structural: single-sample decoding returns one draw from the scorer and incurs no se- lection bias, while beam search selects from a pool of n noisy draws, introducing a systematic upward bias in estimated quality that grows with both n and the scorer noise σ . Our analysis identifies a predicted maximum useful candidate pool size ˆ n : increasing the pool up to ˆ n is guaranteed to help, but beyond ˆ n performance may de grade. The pre- dicted beam width ˆ k then follows from ˆ n via the expansion scheme and is not itself the universal quantity . 3.1 Setup and Notation W e analyze beam search at the r easoning-step le vel: each “token” in our search tree is a complete rea- soning step (a paragraph of chain-of-thought), not a single word. This is the granularity used by T ree of Thoughts ( Y ao et al. , 2023 ) and PRM-guided search ( Lightman et al. , 2023 ), unlike classical token-le vel beam search. Consider a single beam selection step. The cur- rent beam of k paths each generates k candidate continuations, producing n = k 2 total candidates. This symmetric construction is a design choice, not a theoretical requirement: tying the expansion fac- tor to the beam width keeps k as the single tuning parameter and matches standard beam search im- plementations. The theory itself operates on the candidate pool size n and applies re gardless of ho w n decomposes into beams and expansions. Each candidate is an independent sample from the language model’ s conditional distrib ution gi ven its parent path, scored in a separate forw ard pass. A scorer assigns each candidate i a score R i modeled as: R i = µ i + ϵ i , (1) where µ i ∈ R is the true quality of path i and ϵ i is scorer noise. Because candidates are sampled and scored independently , the noise terms ϵ 1 , . . . , ϵ n are mutually independent by construction. Beam search selects the candidate with the highest score: i ∗ = arg max i R i . W e use the term “single-sample decoding” rather than “greedy” because all experiments use temper - ature 0.7; beam width 1 simply means no selection 3 step is performed. The structural distinction is be- tween unselected decoding: k = 1 , where the score is a single noisy draw with no selection bias; and beam-selected decoding: k > 1 , where the max- imization over k noisy scores introduces upward bias. 3.2 Assumptions Assumption 1 (Gaussian Homoscedastic Noise) . The scor er noise terms ar e Gaussian with common variance: ϵ i ∼ N (0 , σ 2 ) for all i = 1 , . . . , n . The noise lev el σ is a property of the scorer , not of individual candidates. A high-noise scorer (large σ , e.g. perplexity) assigns scores that are only loosely correlated with true quality; a low-noise scorer (small σ , e.g. a trained PRM) tracks quality more faithfully . The ov erestimation bias arises not from an y asymmetry in noise across candidates, b ut from the structural asymmetry between unselected decoding (one draw , no bias) and beam-selected decoding (maximum of k draws, upward bias). Assumption 2 (T wo-Class Quality) . Among the n candidates, ther e is one correct-type candidate with true quality µ c and n − 1 incorrect-type candidates with common true quality µ w < µ c . Define the quality gap ∆ := µ c − µ w > 0 . This simplification isolates the ef fect of the max- imization and represents the hardest case for beam search: only one candidate is correct, so beam selection must identify it among n − 1 equally plausible alternativ es. If multiple candidates are correct (as often occurs in practice), at least one is more likely to survi ve beam selection, making the analysis strictly more fa vorable. The one-correct- candidate model therefore yields w orst-case guar- antees (see Remark 1 for the precise sense in which the resulting ˆ k is a lower bound on the true safe beam width k ∗ ). 3.3 Over estimation Bias from Beam Selection The beam search selects the candidate with the highest score. When multiple noisy estimates are compared, the maximum is biased upward, a well- kno wn consequence of order statistics. The follow- ing lemma quantifies this for our setting using the Generalized Extreme V alue (GEV) distribution. Lemma 3.1 (Overestimation Bias) . Under Assump- tions 1 and 2 , let n denote the total number of can- didates with n − 1 incorr ect-type candidates. The expected score of the best incorr ect candidate is well-appr oximated by the GEV limit: E max j =1 ,...,n − 1 R j ≈ µ w + B ( σ, n − 1) , (2) wher e the over estimation bias B ( σ, n − 1) for n ≥ 3 is given by σ Φ − 1 1 − 1 n − 1 + γ EM σ GEV ( n − 1) σ (3) with Φ − 1 the standard normal quantile function, γ EM ≈ 0 . 5772 the Euler–Masc her oni constant, and σ GEV ( n − 1) = σ [Φ − 1 (1 − 1 e( n − 1) ) − Φ − 1 (1 − 1 n − 1 )] the GEV scale parameter , where e is Euler’ s number . F or n ≫ 1 , this simplifies to: B ( σ, n − 1) ≈ σ p 2 log ( n − 1) . (4) The corr ect candidate’s expected score is simply E [ R c ] = µ c (no bias, since it is a single draw). Proof outline. The n − 1 incorrect scores are i.i.d. Gaussian draws. By the Fisher–T ippett–Gnedenko theorem, their maximum conv erges to a Gumbel distribution whose location and scale parameters yield the bias term ( 3 ) . The large- n simplifica- tion ( 4 ) follo ws from a standard asymptotic expan- sion of the normal quantile. W e defer the full proof to Appendix A . The key asymmetry is structural, not distribu- tional: the incorrect candidates recei ve a “free bonus” of approximately σ p 2 log ( n − 1) from the maximization, while the single correct candidate does not. Even though all candidates ha ve the same noise σ , beam search has a systematic tendency to prefer incorrect paths when this bonus exceeds the quality gap ∆ . Remark 1 (Conservatism of the bound) . T wo mod- eling choices make our failur e bound pessimistic, and both work in the same dir ection. F irst, we bound whether any incorr ect candidate outscor es the corr ect one ( Pr(max j R j > R c ) ), wher eas beam sear c h r etains the top k candidates and elimi- nates the correct path only when at least k incorr ect candidates outscor e it—a strictly har der condition to satisfy . Second, Assumption 2 posits a single cor - r ect candidate; multiple corr ect paths only incr ease the chance that at least one survives. Because both choices ov erestimate the failur e pr obability , the pr edicted ˆ k is a lo wer bound on the true safe beam width k ∗ : beam sear ch is guaranteed to help for k ≤ ˆ k , and may continue to help be yond. 4 3.4 Sub-Optimal Selection Probability W e now bound the probability that beam search selects a sub-optimal path. Theorem 3.2 (Sub-Optimal Selection Bound) . Un- der Assumptions 1 and 2 , the pr obability that beam sear ch selects an incorr ect candidate over the cor - r ect one is bounded by: Pr max j =1 ,...,n − 1 R j > R c ≤ 1 + ∆ 2 eff 2 σ 2 − 1 , (5) wher e ∆ eff = ∆ − B ( σ, n − 1) is the effective quality gap after accounting for over estimation bias, and we r equir e ∆ eff > 0 . Pr oof. See Appendix B . The bound is go verned by the ef fectiv e signal-to- noise ratio ∆ eff /σ : the true quality gap ∆ , reduced by the overestimation bias B ( σ, n − 1) , relativ e to the scorer noise σ . When scorer noise is high (perplexity), B ( σ, n − 1) is large, shrinking ∆ eff and making sub-optimal selection likely . When scorer noise is low (PRM), B ( σ, n − 1) is small, preserving the true quality gap. By Remark 1 , this bound is pessimistic: the resulting ˆ k is a lower bound on the true safe beam width k ∗ . 3.5 When Does Search Help? A Necessary Condition The follo wing corollary provides a practical crite- rion. Corollary 3.3 (Search Benefit Criterion) . Beam sear ch over n candidates can impr ove over single- sample decoding only if the scor er’ s noise is small enough that the quality gap survives the over esti- mation bias, yielding the appr oximate necessary condition: ∆ ≳ σ p 2 log ( n − 1) . (6) When this condition is violated, the over estimation bias exceeds the quality gap. Beam sear ch then de grades performance by selecting incorrect paths whose scor es have been inflated by the maximiza- tion. Pr oof. From Lemma 3.1 , beam search benefits re- quire ∆ eff = ∆ − B ( σ, n − 1) > 0 . Using the approximation B ( σ, n − 1) ≈ σ p 2 log ( n − 1) yields the condition. In verting the criterion ( 6 ) yields the central ob- ject of this paper: the predicted maximum useful candidate pool size. Corollary 3.4 (Maximum Useful Candidate Pool) . F or a scor er with noise σ and a pr oblem with qual- ity gap ∆ > 0 , the pr edicted maximum number of candidates at which sear ch is e xpected to help is: ˆ n = 1 + exp ∆ 2 2 σ 2 . (7) F or n ≤ ˆ n , the over estimation bias is smaller than the quality gap and sear ch can impr ove over single- sample decoding. F or n > ˆ n , the bias dominates and sear ch is expected to de gr ade performance. Pr oof. The condition ∆ > σ p 2 log ( n − 1) from Corollary 3.3 is equiv alent to n − 1 < exp(∆ 2 / 2 σ 2 ) . The fundamental limit is the candidate pool size ˆ n . The predicted beam width ˆ k depends on how candidates are generated. In our experiments, beam width k produces n = k 2 candidates per selection step (§ 4 ), gi ving ˆ k = ⌊ √ ˆ n ⌋ . Other expansion strategies w ould yield a different mapping from ˆ n to ˆ k . The dependence of ˆ n on the squared signal-to- noise ratio (∆ /σ ) 2 is exponential, which has tw o implications. When the SNR is poor ( ∆ /σ ≪ 1 , as with perplexity), ˆ n collapses to approximately 2, giving ˆ k = 1 : no beam width helps. When the SNR is moderate ( ∆ /σ ≳ 2 . 33 , as may be the case with a trained PRM), ˆ n reaches 16 or higher , gi ving ˆ k ≥ 4 , consistent with our empirical observation that PRM-guided search helps through beam width 4. The exponential sensitivity means that small improv ements in scorer quality can dramatically expand the useful search range. 4 Experiments 4.1 Setup W e ev aluate on MR-BEN ( Zeng et al. , 2024 ): 5,975 questions across 10 subjects spanning math, science, medicine, and logic. W e use three policy models: Qwen2.5-7B-Instruct ( Alibaba Cloud , 2024 ), Llama-3.1-8B-Instruct ( Meta AI , 2024 ), and Mistral-7B-Instruct-v0.3 ( Mistral AI , 2024 ). For scoring, we compare: (1) Per plex- ity : each model self-scores using neg ative log- perplexity of the full reasoning trace, so that higher scores indicate greater confidence; (2) MathShep- herd PRM : math-shepherd-mistral-7b-prm 5 ( W ang et al. , 2024 ), a process rew ard model out- putting step-correctness probabilities. At each depth, beam selection uses only the most recent step’ s score, not a cumulati ve aggreg ate. For per - plexity , this is the negati ve log-perplexity of the entire sequence up to that step. For PRM, this is the correctness probability of the latest step. W e run beam search with beam width k ∈ { 1 , 2 , 3 , 4 } . At each depth, each of the k beams generates k candidate continuations, yielding n = k 2 total candidates from which the top k are se- lected. At k = 1 , the policy produces a single sample per step and no selection is performed; we refer to this as single-sample decoding . The maxi- mum depth is 24 and the temperature is 0.7 for all configurations. W e run 3 seeds per configuration and report means and standard errors. At k =4, a single subject–seed combination requires approx- imately one week of GPU time on a single A100, making beam widths beyond 4 computationally prohibiti ve with our current setup. 4.2 Main Results T ables 1 and 2 present the central comparison. Perplexity-scored beam search provides no ben- efit: Qwen is flat ( ± 0 . 1 points), while Llama and Mistral de grade at wider beams ( − 5.4 and − 3.9 points at k =4), consistent with the o verestimation bias predicted by Lemma 3.1 . The model ranking Qwen > Llama > Mistral is stable across all beam widths, confirming that polic y capability dominates when the re ward signal is unreliable. Standard er- rors also gro w with beam width under perplexity scoring (e.g., Llama: 1.3 at k =1 vs. 3.4 at k =4), reflecting the increasing role of noise-driv en selec- tion at wider beams. Replacing perplexity with PRM scoring, while keeping the model and algorithm identical, trans- forms beam search scaling from flat or negati ve to strongly positive (T able 2 , Figure 1 ). All three models benefit at k =4: Mistral gains +8.9 points (42.3% to 51.2%), Llama gains +6.2 points (59.2% to 65.4%), and Qwen gains +3.4 points (71.7% to 75.1%). The lar gest relativ e gain occurs for the weakest model (Mistral), suggesting PRM-guided search is especially valuable when the policy alone struggles. 4.3 Interpr eting Results Through the Maximum Useful Beam Width Corollary 3.4 predicts a maximum useful beam width ˆ k for each scorer . Our results are consistent with: • Perplexity : ˆ k = 1 for all three models. The pre- dicted candidate pool size ˆ n ≈ 2 means ev en a single incorrect competitor can mislead the scorer , and no tested beam width produces im- prov ement. Llama and Mistral acti vely degrade at wider beams. • PRM : ˆ k ≥ 4 for all three models. All peak at k =4. Qwen and Llama scale monotonically; Mistral dips at k =3 before recovering at k =4, likely reflecting higher v ariance at wider beams rather than a true optimum near k =2. The perplexity and PRM results are not tw o sepa- rate findings; they are two points on the ˆ k contin- uum predicted by a single formula. Figure 2 visu- alizes the contrast: PRM bars rise while perplexity bars are flat or negati ve. Per-subject breakdowns appear in Appendix C . 5 Case Study: Diagnosing Reward In version The aggregate results abo ve show that scorer qual- ity determines beam search effecti veness. This section examines how the failure unfolds at the le vel of indi vidual beam selections. W e trace beam search behavior for Mistral-7B-Instruct-v0.3 on high_school_biology with perple xity scoring, where k =4 scored 59.7% versus 63.0% for single- sample decoding, despite 4 × the search effort (see also Figures 10 and 11 in Appendix E ). 5.1 Reward In version at the T race Level Problem cf68a215 illustrates the mechanism con- cretely . At depth 2, the beam selection log shows: [BEAM_SELECT] depth=2 | candidates=12 top_rewards=[-3.04, -3.05, -3.18, ...] #1: reward=-3.0405 [ANS:C] <- SELECTED #2: reward=-3.0496 [ANS:A] <- REJECTED The correct path (A) w as rejected in fa vor of the in- correct path (C) by a margin of just 0.009. Among 12 candidates, the maximization inflated the score of candidate C by enough to overtak e A—a mi- croscopic margin that a more discriminati ve scorer would not produce. This is not an isolated case. In 25 disagreement cases where k =1 was correct but k =4 was wrong, the k =4 path consistently had a higher re ward, i.e. lo wer perplexity , as shown in T able 3 . The pat- tern is systematic: beam search selects paths that look better to the scorer but are worse in qual- ity , precisely the reward in version predicted by Lemma 3.1 . 6 Model k = 1 k = 2 k = 3 k = 4 ∆ ( k =4 − k =1) Qwen 71.3 ± 1.0 71.1 ± 1.0 71.2 ± 1.1 71.4 ± 1.5 +0.1 Llama 59.7 ± 1.3 58.4 ± 1.5 58.5 ± 2.1 54.3 ± 3.4 − 5.4 Mistral 42.4 ± 1.6 42.0 ± 1.7 41.0 ± 2.1 38.5 ± 2.7 − 3.9 T able 1: Perplexity-scored beam search: Macro success rate (%) by model and beam width. V alues are mean ± standard error across subjects and seeds. Model k = 1 k = 2 k = 3 k = 4 ∆ (best − k =1) Qwen 71.7 ± 1.2 73.8 ± 1.3 73.9 ± 1.4 75.1 ± 1.3 +3.4 Llama 59.2 ± 1.7 63.4 ± 1.8 64.7 ± 1.8 65.4 ± 2.4 +6.2 Mistral 42.3 ± 2.7 50.8 ± 3.3 47.9 ± 3.6 51.2 ± 3.7 +8.9 T able 2: PRM-scored beam search: Macro success rate (%) by model and beam width. V alues are mean ± standard error across subjects and seeds. Problem k = 1 Correct k = 4 Correct cf68a215 − 6 . 71 ✓ − 2 . 84 ✗ c1eacc33 − 4 . 65 ✓ − 2 . 19 ✗ 5c9182fd − 3 . 70 ✓ − 2 . 53 ✗ 681201fd − 4 . 49 ✓ − 2 . 82 ✗ T able 3: Reward in version: k =4 selects higher -scoring but incorrect paths. 5.2 Score Margins as a Diagnostic The trace-lev el analysis abov e re veals why per- plexity scoring fails. Score margins reveal how such failures can be detected without ground-truth labels. Across 2,770 beam selections in this do- main, 44.3% had a re ward mar gin < 0 . 1 between the top two candidates (Figure 3 ), indicating near - random selection. When mar gins are this small, the scorer cannot reliably separate correct from incor - rect paths, and beam selection reduces to a noisy coin flip. This observ ation connects directly to the practi- cal guidance in Section 6 : inspecting score margins on a small pilot run pro vides a cheap diagnostic for whether a scorer can support wider search. Consis- tently small margins signal that the ef fectiv e quality gap ∆ eff is near zero and ˆ k is likely lo w . 6 Discussion 6.1 The Optimal Beam Width as a Design Parameter Our central result, the predicted maximum use- ful beam width ˆ k (Corollary 3.4 ), reframes beam search from a “wider is better” heuristic to a prin- cipled design decision. The ke y insight is that ˆ k depends exponentially on the squared SNR of the scorer: small improvements in scorer quality can dramatically expand the useful beam range, while e ven state-of-the-art scorers hav e a finite ˆ k beyond which additional search is wasted. The single-sample case k =1 follo ws naturally: with no maximization there is no o verestimation bias, and the policy’ s implicit calibration is preserved. 6.2 Practical Guidance The formula ˆ n = 1 + exp(∆ 2 / 2 σ 2 ) characterizes ˆ k in terms of two quantities, the quality gap ∆ and scorer noise σ , that are not directly observable. W e do not claim that ˆ k can be computed exactly from data. Rather , the analysis provides three forms of guidance: 1. Diagnostic indicators. Score margins at beam selection pro vide a qualitati ve signal. If margins are consistently small, as we observe for 44% of perplexity selections, the scorer cannot reli- ably distinguish candidates and ˆ k is likely lo w . The dispersion of scores reflects both genuine quality variation and scorer noise, so it serves as a rough proxy for scorer unreliability rather than an estimate of σ alone. 2. Pilot runs. A practical approach is to compare k =2 against k =1 on a small validation set. If no improv ement is observed, the scorer’ s SNR is too low to support wider search. On problems with ground-truth labels, one can estimate ∆ /σ from the separation between score distributions of correct and incorrect candidates. 7 k = 2 k = 3 k = 4 5 0 5 S u c c e s s R a t e ( % ) f r o m k = 1 Qwen k = 2 k = 3 k = 4 Llama k = 2 k = 3 k = 4 Mistral Perplexity PRM Figure 2: Per-model change from k =1 by scorer . Hatched bars indicate negati ve ∆ . The PRM unlocks search benefits where perplexity cannot. 0.0 0.5 1.0 1.5 2.0 2.5 3.0 R e w a r d M a r g i n ( T o p - 1 T o p - 2 ) 0 200 400 600 800 1000 1200 F r equency Near -random selections Beam Selection Reward Margins Mar gin < 0.1 (44.3% of selections) Figure 3: Rew ard margin distribution for perplexity- scored beam selections. The peak near zero confirms that 44% of selections ha ve negligible mar gins, signal- ing that the scorer cannot support wider search. 3. In vest in the scor er , not the beam width. Since ˆ n gro ws exponentially with (∆ /σ ) 2 , reducing σ is far more ef fecti ve than increasing k . In vest- ing in re ward model quality expands the useful search range, while widening the beam beyond ˆ k activ ely degrades performance. 6.3 T oward Bias-Corrected Beam Search Our theory also suggests a correction that could raise ˆ k : rather than selecting arg max i R i , subtract the estimated overestimation bias from the maxi- mum. Concretely , one could penalize the best-of- n score by B ( ˆ σ , n − 1) , where ˆ σ is estimated on- line from the v ariance of scores across candidates at each selection step. This would effecti vely in- crease ∆ eff , raising ˆ n and thus ˆ k without changing the scorer . W e leave empirical v alidation to future work. 7 Conclusion This study provides a theoretical and empirical an- swer to the question: how wide should you sear ch? Our EVT -based analysis sho ws that beam selection introduces a systematic ov erestimation bias propor- tional to scorer noise, yielding a predicted maxi- mum useful candidate pool ˆ n = 1 + exp(∆ 2 / 2 σ 2 ) and corresponding beam width ˆ k = ⌊ √ ˆ n ⌋ that depend on the scorer’ s signal-to-noise ratio. Be- yond ˆ k , wider search degrades performance. This analysis correctly predicts our empirical findings: perplexity scoring, with ˆ k = 1 , provides zero bene- fit at an y beam width across three models and ten domains, while PRM scoring, with ˆ k ≥ 4 , unlocks meaningful gains of up to 8.9 percentage points. The practical message is that beam width is not a hyperparameter to maximize; it has a theoretically grounded optimum determined by scorer quality . While ∆ and σ are not directly observ able, diagnos- tic indicators such as score margins and pilot-run comparisons can help judge whether a giv en scorer supports wider search. Reproducibility . Our code is publicly a v ailable at [anonymous] , built as a fork of the LLM Rea- soners library ( Hao et al. , 2024 ). Limitations W e note limitations of both the theory and the e x- perimental scope. T wo-class quality model. Assumption 2 collapses candidate quality to a binary cor- rect/incorrect partition with a single gap ∆ . Real candidate pools exhibit a spectrum of quality le vels. As noted in Remark 1 , this makes our bound conservati ve: multiple correct candidates or a quality continuum generally makes beam selection easier , not harder . Scale and beam width range. W e ev aluate only 7B-parameter models and beam widths up to k = 4 . The theory predicts that ˆ k can be much larger for 8 high-SNR scorers. T esting k > 4 and larger models would be needed to empirically locate the turning point for PRM-guided search. W e also use a single temperature of T = 0 . 7 throughout. T emperature af fects candidate div ersity and the effecti ve inde- pendence of the candidate pool, which may modu- late the relationship between n and ov erestimation bias. Intrinsic signal coverage. Among training-free scoring signals, we ev aluate only perplexity . Other intrinsic signals, from entropy-based self-certainty ( Kang et al. , 2025 ) to Marko vian reward adjust- ments ( Ma et al. , 2025 ), may offer better signal-to- noise ratios. Extending the empirical comparison to these alternati ves is a natural ne xt step. Ethical Considerations This work analyzes inference-time search strategies for LLM reasoning. W e do not collect or use per- sonal data, and all e xperiments use publicly av ail- able models and benchmarks. The primary ethical consideration is computational cost: beam search at width k requires O ( k 2 ) scorer ev aluations per step. Our work mitigates this concern by identify- ing when wider search is wasteful, helping av oid unnecessary computation. References Aakriti Agrawal, Souradip Chakraborty , Huazheng Qiu, Sharath Chandra Raparthy , Aditya Raghav , T omek Kaliszewski, Mengdi W ang, Shuai Bai, Jing Shang, Furong Huang, Dinesh Manocha, and Amrit Bedi. 2025. Cut the ov ercredit: Precision first process rew ards for reasoning LLMs. In International Con- fer ence on Learning Representations . Alibaba Cloud. 2024. Qwen2.5-7B-Instruct model card. Hugging Face. J. M. Blair , C. A. Edwards, and J. H. Johnson. 1976. Rational Chebyshe v approximations for the in verse of the error function. Mathematics of Computation , 30(136):827–830. W enhu Chen, Xueguang Ma, Xinyi W ang, and W illiam W Cohen. 2022. Program of thoughts prompting: Disentangling computation from reason- ing for numerical reasoning tasks. arXiv pr eprint arXiv:2211.12588 . Karl Cobbe, V ineet K osaraju, Mohammad Bav arian, Mark Chen, Heew oo Jun, Lukasz Kaiser , Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word prob- lems. arXiv pr eprint arXiv:2110.14168 . Stuart Coles. 2001. An Intr oduction to Statistical Mod- eling of Extr eme V alues . Springer . Ganqu Cui, Lifan Zhang, Bingxiang W ang, Zefan Zhang, Hanbin Liu, Y angyi Pan, Y uqing Li, Qiufeng W ang, Y ang Y ue, Zhiyuan Liu, and Maosong Sun. 2025. PRIME: Process reinforcement through im- plicit rew ards. arXiv preprint . Gal Dalal, Assaf Hallak, Ste ven Dalton, Iuri Frosio, Shie Mannor , and Gal Chechik. 2021. Improve agents without retraining: Parallel tree search with of f-policy correction. Advances in Neural Information Pr ocess- ing Systems , 34. Herbert A. David and Haikady N. Nagaraja. 2003. Or- der Statistics , 3rd edition. John W iley & Sons. DeepSeek-AI. 2025. DeepSeek-R1: Incenti vizing rea- soning capability in LLMs via reinforcement learning. arXiv pr eprint arXiv:2501.12948 . R. A. Fisher and L. H. C. Tippett. 1928. Limiting forms of the frequency distribution of the largest or smallest member of a sample. Mathematical Pr oceedings of the Cambridge Philosophical Society , 24(2):180– 190. Markus Freitag and Y aser Al-Onaizan. 2017. Beam search strategies for neural machine translation. arXiv pr eprint arXiv:1702.01806 . Leo Gao, John Schulman, and Jacob Hilton. 2023. Scal- ing laws for rew ard model overoptimization. In In- ternational Confer ence on Machine Learning . 9 Boris Gnedenko. 1943. Sur la distribution limite du terme maximum d’une série aléatoire. Annals of Mathematics , 44(3):423–453. Shibo Hao, Y i Gu, Haotian Luo, T ianyang Liu, Xiyan Shao, Xinyuan W ang, Shuhua Xie, Haodi Ma, Adithya Sama vedhi, Qiyue Gao, and 1 others. 2024. LLM Reasoners: New e valuation, library , and anal- ysis of step-by-step reasoning with large language models. arXiv pr eprint arXiv:2404.05221 . Frederick Jelinek, Robert L Mercer , Lalit R Bahl, and James K Baker . 1977. Perplexity—a measure of the difficulty of speech recognition tasks. The Journal of the Acoustical Society of America , 62(S1):S63–S63. Zhewei Kang, Xuandong Zhao, and Dawn Song. 2025. Scalable best-of-N selection for large lan- guage models via self-certainty . arXiv pr eprint arXiv:2502.18581 . Hunter Lightman, V ineet K osaraju, Y ura Burda, Harri Edwards, Bowen Baker , T eddy Lee, Jan Leike, John Schulman, Ilya Sutskev er, and Karl Cobbe. 2023. Let’ s verify step by step. arXiv preprint arXiv:2305.20050 . Runze Liu, Junhao Li, Jian Jiao, Xun Y e, Jie W ang, and T ong Zhang. 2025. Can 1b LLM surpass 405b LLM? rethinking compute-optimal test-time scaling. arXiv pr eprint arXiv:2502.06703 . Haotian Luo, Lingkai Li, Guang Y ang, Zhuohua Zhang, Y ue Y ang, and Dawn Song. 2025. Supervised opti- mism correction: Be confident when LLMs are sure. In F indings of the Association for Computational Linguistics: ACL 2025 . Ziyang Ma, Qingyue Y uan, Zhenglin W ang, and Deyu Zhou. 2025. Large language models have intrinsic meta-cognition, b ut need a good lens. In Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Languag e Pr ocessing . Meta AI. 2024. Llama-3.1-8B-Instruct model card. Hugging Face. Mistral AI. 2024. Mistral-7B-Instruct-v0.3 model card. Hugging Face. Zongyue Qin, Zifan He, Neha Prakriya, Jason Cong, and Y izhou Sun. 2025. Dynamic-width speculativ e beam decoding for LLM inference. In Pr oceedings of the AAAI Conference on Artificial Intelligence , volume 39. Charlie Snell, Jaehoon Lee, K elvin Xu, and A viral Ku- mar . 2024. Scaling LLM test-time compute optimally can be more effecti ve than scaling model parameters. arXiv pr eprint arXiv:2408.03314 . Sebastian Thrun and Anton Schwartz. 1993. Issues in using function approximation for reinforcement learning. In Pr oceedings of the F ourth Connectionist Models Summer School . Peiyi W ang, Lei Li, Zhihong Shao, R.X. Xu, Damai Dai, Y ifei Li, Deli Chen, Y u W u, and Zhifang Sui. 2024. Math-shepherd: V erify and reinforce LLMs step- by-step without human annotations. arXiv pr eprint arXiv:2312.08935 . Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Brian Ichter , Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elic- its reasoning in large language models. Advances in Neural Information Pr ocessing Systems , 35:24824– 24837. Y angzhen W u, Zhiqing Sun, Shanda Li, Sean W elleck, and Y iming Y ang. 2025. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. In Interna- tional Confer ence on Learning Representations . Y uxi Xie, Anirudh Goyal, W enyue Zheng, and Min- Y en Kan. 2023. Self-ev aluation guided beam search for reasoning. In Advances in Neural Information Pr ocessing Systems , volume 36. Shunyu Y ao, Dian Y u, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Y uan Cao, and Karthik Narasimhan. 2023. T ree of thoughts: Deliberate problem solving with large language models. Ad- vances in Neural Information Pr ocessing Systems , 36. Zhongshen Zeng, Y inhong Liu, Y ingjia W an, Jingyao Li, Pengguang Chen, Jianbo Dai, Y uxuan Y ao, Rongwu Xu, Zehan Qi, W anru Zhao, Linling Shen, Jianqiao Lu, Haochen T an, Y ukang Chen, Hao Zhang, Zhan Shi, Bailin W ang, Zhijiang Guo, and Jiaya Jia. 2024. MR-Ben: A meta-reasoning benchmark for ev alu- ating system-2 thinking in LLMs. In Advances in Neural Information Pr ocessing Systems , v olume 37. Congmin Zheng, Jihao Huang, Boyuan Chen, Zhihong Shao, Deli Chen, and Zhifang Sui. 2025. A survey of process reward models: From outcome signals to process supervisions for large language models. arXiv pr eprint arXiv:2510.08049 . 10 A Proof of Lemma 3.1 Pr oof. By Assumption 2 , the n − 1 incorrect candidates hav e scores R j = µ w + ϵ j with ϵ j i.i.d. ∼ N (0 , σ 2 ) . By the Fisher–T ippett–Gnedenko theorem ( Fisher and T ippett , 1928 ; Gnedenko , 1943 ; Coles , 2001 ), the maximum of n − 1 i.i.d. Gaussian draws con ver ges to a Gumbel distrib ution. The approximation is tight even for small n , with relativ e error below 2% for n ≥ 4 . The location and scale parameters are µ GEV = µ w + σ Φ − 1 (1 − 1 / ( n − 1)) and σ GEV = σ [Φ − 1 (1 − 1 / (e( n − 1))) − Φ − 1 (1 − 1 / ( n − 1))] . The expectation of the Gumbel distribution is µ GEV + γ EM σ GEV , giving ( 2 ) – ( 3 ) . The approximation ( 4 ) follo ws from Φ − 1 (1 − 1 / ( n − 1)) ≈ p 2 log ( n − 1) − 1 / 2 for large n ( Blair et al. , 1976 ), with the Euler–Mascheroni correction becoming negligible. The correct candidate is a single draw , so E [ R c ] = µ c with no max-induced bias. B Proof of Theorem 3.2 Pr oof. W e bound Pr(max j =1 ,...,n − 1 R j > R c ) where R c = µ c + ϵ c with ϵ c ∼ N (0 , σ 2 ) and max j R j follo ws a GEV distribution as established in Lemma 3.1 . Define Z := max j R j − R c . W e need to bound Pr( Z > 0) . By Lemma 3.1 , max j R j ∼ GEV ( µ GEV , σ GEV , 0) with parameters as specified. Since max j R j and R c are independent, the dif ference Z has: E [ Z ] = ( µ w + B ( σ, n − 1)) − µ c = − ∆ + B ( σ, n − 1) = − ∆ eff , V ar [ Z ] = π 2 6 ( σ GEV ) 2 | {z } variance of max j R j + σ 2 |{z} variance of R c . W e bound V ar [ Z ] from abov e. The variance of the maximum of m i.i.d. N ( µ, σ 2 ) random v ariables is at most σ 2 for all m ≥ 1 (it equals σ 2 when m = 1 and decreases monotonically with m ; see David and Nagaraja 2003 , §5.4). Therefore V ar [ Z ] ≤ σ 2 + σ 2 = 2 σ 2 . Applying the Cantelli inequality (one-sided Chebyshe v): Pr( Z > 0) = Pr( Z − E [ Z ] > ∆ eff ) ≤ V ar [ Z ] V ar [ Z ] + ∆ 2 eff ≤ 2 σ 2 2 σ 2 + ∆ 2 eff = 1 + ∆ 2 eff 2 σ 2 − 1 . The bound is controlled by the squared ratio (∆ eff /σ ) 2 . As n gro ws, the o verestimation bias B ( σ, n − 1) increases, shrinking ∆ eff and driving the bound to ward 1. At n = ˆ n , we hav e ∆ eff = 0 and the bound becomes v acuous, consistent with the criterion in Corollary 3.3 . 11 C Per -Subject Curves by Model C.1 Per plexity Scoring 60 70 80 90 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 60 70 80 90 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Qwen: Per-Subject Success vs Beam W idth (Perplexity) Figure 4: Per-subject success rate vs. beam width for Qwen2.5-7B-Instruct with perplexity scoring. 40 60 80 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 40 60 80 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Llama: Per-Subject Success vs Beam W idth (Perplexity) Figure 5: Per-subject success rate vs. beam width for Llama-3.1-8B-Instruct with perplexity scoring. 12 20 40 60 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 20 40 60 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Mistral: Per-Subject Success vs Beam W idth (Perplexity) Figure 6: Per-subject success rate vs. beam width for Mistral-7B-Instruct-v0.3 with perplexity scoring. C.2 PRM Scoring 60 70 80 90 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 60 70 80 90 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Qwen: Per-Subject Success vs Beam W idth (PRM) Figure 7: Per-subject success rate vs. beam width for Qwen2.5-7B-Instruct with PRM scoring. 40 60 80 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 40 60 80 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Llama: Per-Subject Success vs Beam W idth (PRM) Figure 8: Per-subject success rate vs. beam width for Llama-3.1-8B-Instruct with PRM scoring. 13 20 40 60 Success Rate (%) College Biology College Chemistry College Math College Medicine College Physics 1 2 3 4 B e a m w i d t h ( k ) 20 40 60 Success Rate (%) High School Biology 1 2 3 4 B e a m w i d t h ( k ) High School Chemistry 1 2 3 4 B e a m w i d t h ( k ) High School Math 1 2 3 4 B e a m w i d t h ( k ) High School Physics 1 2 3 4 B e a m w i d t h ( k ) Logic Mistral: Per-Subject Success vs Beam W idth (PRM) Figure 9: Per-subject success rate vs. beam width for Mistral-7B-Instruct-v0.3 with PRM scoring. D Implementation Details • Beam Width : k ∈ { 1 , 2 , 3 , 4 } . • Number of Actions : Equal to beam width. • Maximum Depth : 24 steps. • T emperatur e : 0.7 for all configurations (including k =1). • Reward Aggregation : last : only the most recent step’ s score is used for beam selection. • Perplexity : Computed over the full sequence (prompt + all steps) at each depth. • PRM : math-shepherd-mistral-7b-prm ; uses the correctness probability at the last step tag. All models are loaded from the Hugging Face Hub . Experiments are managed via W eights & Biases. E Additional Case Study Figures k = 1 (gr eedy) k = 4 (sear ch) 50.0 52.5 55.0 57.5 60.0 62.5 65.0 67.5 70.0 A ccuracy (%) 63.0% 59.7% -3.3pp High School Biology : Gr eedy vs. Beam Sear ch (Mistral-7B P olicy & Scor er) Figure 10: Accuracy: single-sample ( k =1) vs. beam ( k =4) on high_school_biology . Beam search underperforms despite ev aluating k 2 = 16 candidates per step. 14 cf68a215 c1eacc33 5c9182fd 681201fd P r oblem ID (truncated) 7 6 5 4 3 2 1 0 Cumulative R ewar d (less negative = higher) -6.71 -4.65 -3.70 -4.49 -2.84 -2.19 -2.53 -2.82 R ewar d Inversion: W r ong P aths Get Higher R ewar ds k = 1 ( C O R R E C T ) k = 4 ( W R O N G ) Figure 11: Reward in v ersion: incorrect paths selected by k =4 hav e higher rewards than correct paths from k =1. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment