미래 영향으로 평가하는 LLM 연구 아이디어 검증
본 논문은 LLM이 생성한 연구 아이디어를 실제 미래 논문과 매칭해 인용·학회 가중 점수로 평가하는 시간분할 프레임워크 HindSight를 제안한다. 30개월 간의 후속 논문 풀을 이용해 검증한 결과, 검색 기반 아이디어 생성 시스템이 일반 LLM 기반 베이스라인보다 2.5배 높은 점수를 얻었지만, LLM‑as‑Judge는 두 시스템을 구분하지 못한다. 또한 LLM이 매긴 ‘새로움’ 점수와 HindSight 점수는 음의 상관관계를 보여, LLM…
저자: Bo Jiang
본 논문은 인공지능이 생성한 연구 아이디어를 실제 미래 논문과 매칭해 평가하는 새로운 프레임워크 HindSight를 제안한다. 기존 평가 방법은 LLM‑as‑Judge와 인간 패널에 의존해 주관적 판단에 머물렀으며, 실제 연구 영향과의 연관성을 측정하지 못했다. HindSight는 시간‑스플릿 설계를 도입해 아이디어 생성 시스템이 T 시점 이전(2023‑06)까지의 문헌만을 활용하도록 제한하고, 이후 Δ = 30개월(2023‑06~2025‑12) 동안 발표된 AI/ML 논문 27,589편을 정답 풀로 사용한다.
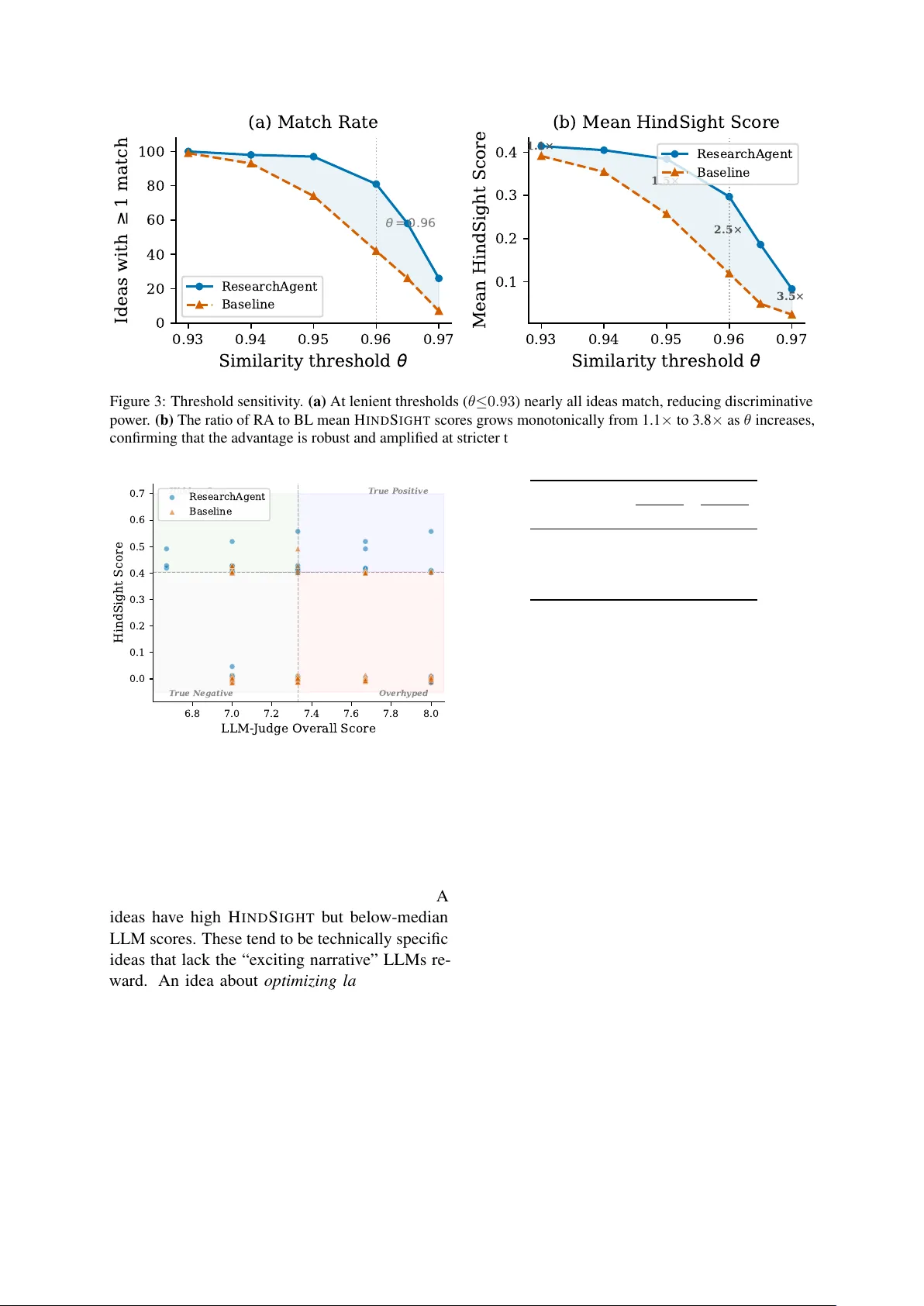
아이디어는 문제 진술과 방법 제안을 결합한 텍스트로 구성되며, SPECTER2를 이용해 768‑차원 임베딩으로 변환한다. 논문 역시 제목과 초록을 결합해 동일한 방식으로 임베딩한다. FAISS 인덱스로 각 아이디어에 대해 상위 K = 20개의 가장 유사한 논문을 검색하고, 코사인 유사도가 θ = 0.96 이상인 경우에만 매치로 인정한다. 매치된 논문 각각은 인용 수와 학회 가중치를 선형 결합한 h(p) = 0.6·norm_cite + 0.4·venue 점수를 부여받으며, 아이디어당 최종 HindSight 점수는 매치된 논문 중 가장 높은 h(p) 값이다. 매치가 없을 경우 점수는 0으로 설정한다.
실험에서는 두 종류의 아이디어 생성 시스템을 비교했다. 첫 번째는 검색 기반 ResearchAgent(RA)으로, 사전 문헌을 검색해 문제와 방법을 도출한다. 두 번째는 동일 LLM을 사용하지만 문헌 검색 없이 직접 아이디어를 생성하는 베이스라인(BL)이다. 각 시스템은 10개 주제당 10개의 아이디어를 생성해 총 200개를 만든다.
HindSight 평가 결과, RA는 81 %의 아이디어가 최소 하나의 매치 논문을 찾았으며 평균 점수 0.297을 기록했다. 반면 BL은 매치율 42 %에 평균 점수 0.119에 머물렀다. Mann‑Whitney U 검정에서 p < 0.001로 유의미한 차이가 나타났다. 반면 LLM‑as‑Judge(다른 모델 Qwen3‑32B 사용)에서는 전체 점수 차이가 0.03점에 불과했고 p = 0.584로 통계적으로 의미가 없었다. LLM‑as‑Judge는 오히려 BL이 ‘새로움’과 ‘예상 영향’에서 더 높은 점수를 주었다.
상관 분석에서는 HindSight 점수와 LLM‑Judge의 ‘새로움’ 사이에 ρ = ‑0.29, p = 0.003의 음의 상관관계가 발견되었다. 즉, LLM이 더 새롭다고 판단한 아이디어일수록 실제 논문과 매치될 가능성이 낮았다. 반면 ‘실현 가능성’과는 ρ = +0.25, p = 0.012의 양의 상관관계가 있었으며, 구체적이고 실현 가능한 아이디어가 실제 연구와 더 잘 일치함을 보여준다.
케이스 스터디에서는 아이디어를 HindSight 점수와 LLM‑Judge 점수의 중앙값을 기준으로 네 사분면으로 나누었다. ‘True Positive’(두 점수 모두 높음)와 ‘Hidden Gem’(HindSight 높고 Judge 낮음) 영역에 RA가 다수 몰렸으며, 특히 ‘Hidden Gem’은 LLM이 과소평가했지만 실제 논문과 높은 유사도를 보인 사례가 많았다. 반면 ‘Overhyped’(Judge 높고 HindSight 낮음) 영역에는 BL이 상대적으로 많이 존재했으며, 이는 추상적이고 과장된 제안이 LLM에게는 매력적으로 보이지만 실제 연구로 이어지지 않음을 의미한다.
논문의 한계로는 (1) HindSight가 매치된 논문에만 점수를 부여하므로, 30개월 내에 발표되지 않은 혁신적인 아이디어는 ‘False Negative’로 처리될 위험이 있다. (2) SPECTER2 임베딩이 주제 수준의 의미는 잘 포착하지만, 새로운 방법론이나 용어에 대한 민감도가 낮아 매치 정확도가 떨어질 수 있다. 향후 교차 인코더 재랭킹, 도메인‑특화 어댑터 적용 등으로 매칭 정밀도를 개선할 필요가 있다.
결론적으로 HindSight는 LLM‑as‑Judge가 제공하는 주관적·신속한 평가와는 별개로, 실제 연구 성과와 직접 연결된 객관적 평가 지표를 제공한다. 이는 아이디어 생성 시스템을 “인상적인 문구”가 아니라 “미래 연구를 선점하는 능력”으로 최적화하도록 유도할 수 있는 중요한 전환점이며, 향후 AI 기반 연구 아이디어 생성 연구에 있어 평가 기준을 재정의할 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기