HindSight: Evaluating LLM-Generated Research Ideas via Future Impact
Evaluating AI-generated research ideas typically relies on LLM judges or human panels -- both subjective and disconnected from actual research impact. We introduce HindSight, a time-split evaluation framework that measures idea quality by matching ge…
Authors: Bo Jiang
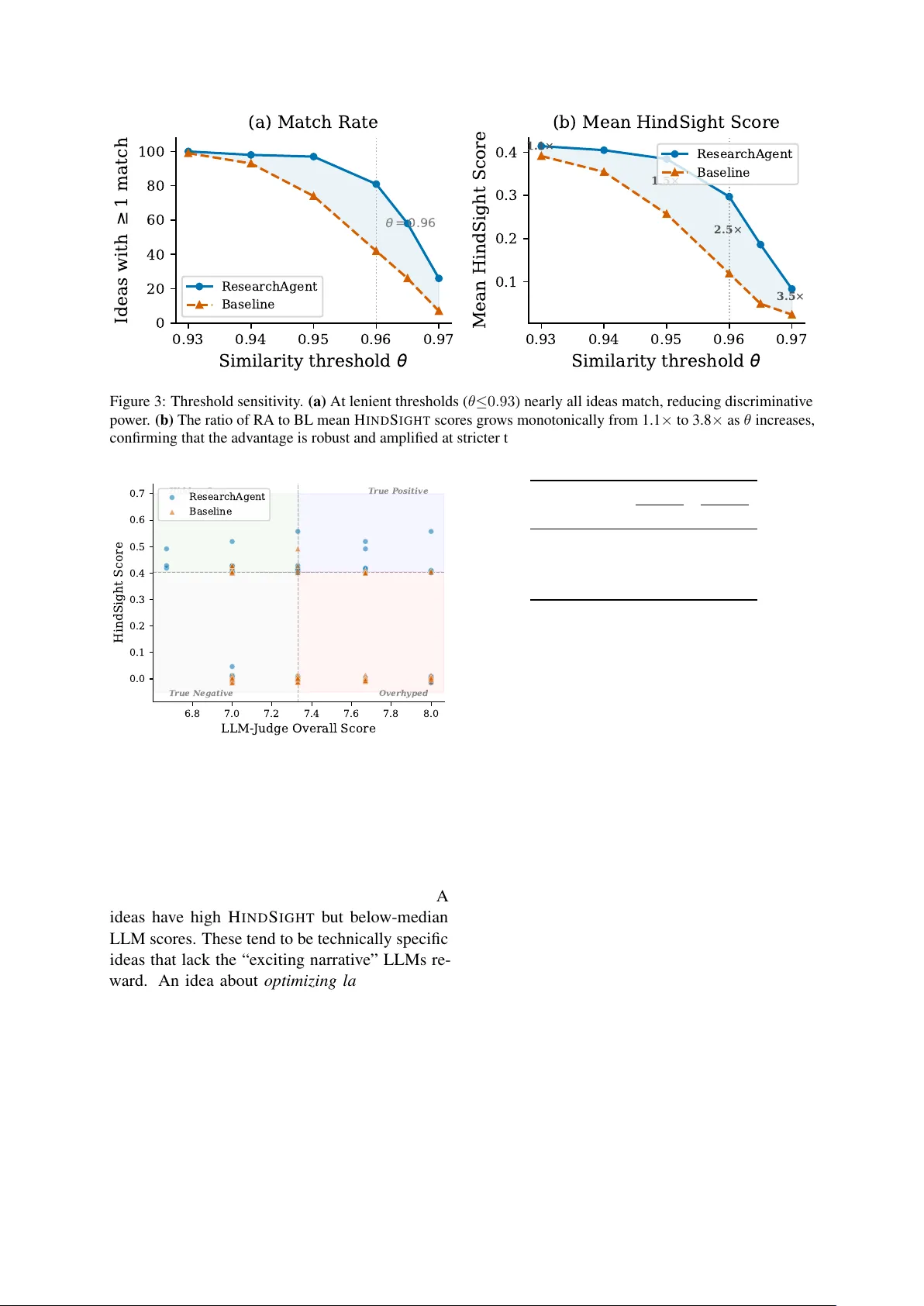
H I N D S I G H T : Evaluating LLM-Generated Research Ideas via Futur e Impact Bo Jiang T emple Uni versity bo.jiang@temple.edu Abstract Evaluating AI-generated research ideas typi- cally relies on LLM judges or human panels— both subjective and disconnected from actual research impact. W e introduce H I N D S I G H T , a time-split ev aluation framew ork that mea- sures idea quality by matching generated ideas against real future publications and scoring them by citation impact and venue acceptance. Using a temporal cutof f T , we restrict an idea generation system to pre- T literature, then ev al- uate its outputs against papers published in the subsequent 30 months. Experiments across 10 AI/ML research topics rev eal a striking discon- nect: LLM-as-Judge finds no significant differ- ence between retrie v al-augmented and v anilla idea generation ( p =0 . 584 ), while H I N D S I G H T show s the retriev al-augmented system produces 2.5 × higher-scoring ideas ( p< 0 . 001 ). More- ov er , H I N D S I G H T scores are negatively cor- related with LLM-judged nov elty ( ρ = − 0 . 29 , p< 0 . 01 ), suggesting that LLMs systematically ov erv alue nov el-sounding ideas that ne ver ma- terialize in real research. 1 Introduction Can AI generate research ideas that actually ma- terialize into published work? Recent systems— ResearchAgent ( Baek et al. , 2025 ), AI Scientist ( Lu et al. , 2024 ), and SciMON ( W ang et al. , 2024 )— demonstrate that lar ge language models can pro- duce coherent research proposals, and a study with 100+ NLP researchers found that LLM-generated ideas are rated as mor e novel than expert-written ones ( Si et al. , 2024 ). But rating an idea as novel is not the same as demonstrating that it anticipates real research. This gap between per ceived qual- ity and actual impact is the central problem we address. Current e v aluation methods are inherently sub- jecti ve: • LLM-as-Judge ( Zheng et al. , 2023 ): scalable but exhibits verbosity bias, self-preference, and poor no velty calibration. Its correlation with real- world impact is unkno wn. • Human ev aluation : expensi v e, slo w , and plagued by low inter-annotator agreement on nov- elty ( Si et al. , 2024 ). Neither approach measures whether a generated idea corresponds to a genuine research direction. W e propose H I N D S I G H T , an ev aluation frame- work that pro vides an objective , impact-grounded signal. The core insight is temporal: by constrain- ing an idea generation system to literature av ail- able before a cutof f T , we can e valuate its outputs against papers published after T . Ideas that closely match high-impact future papers score high; those that match nothing score zero (Figure 1 ). Applying both H I N D S I G H T and LLM-as-Judge to 200 ideas (100 from a retrie val-augmented sys- tem, 100 from a v anilla baseline), we find: 1. LLM-as-Judge sees no difference : the two systems recei ve nearly identical o verall scores ( 7 . 44 vs. 7 . 40 ; p =0 . 584 ). 2. H I N D S I G H T shows a 2.5 × gap : the retrie val- augmented system achieves a mean score of 0 . 297 vs. 0 . 119 ( p< 0 . 001 ). 3. Negative correlation with novelty : ideas rated as more nov el by the LLM are less likely to match real future papers ( ρ = − 0 . 29 , p< 0 . 01 ). These findings suggest that subjective and objectiv e e valuation capture fundamentally dif ferent dimen- sions of idea quality . Our contributions are: 1. H I N D S I G H T , the first time-split, impact-based e valuation frame work for research idea genera- tion (§ 3 ). 2. Empirical e vidence of a systematic disconnect between LLM-as-Judge and objective impact e valuation (§ 5 ). 3. Analysis re vealing that LLM judges o vervalue “nov el-sounding” ideas and underv alue ideas that anticipate real research trends (§ 6 ). 1 2 Related W ork Research Idea Generation. ResearchAgent ( Baek et al. , 2025 ) iterativ ely retrie ves scientific literature to produce research proposals using an LLM backbone for problem identification and method dev elopment. The AI Scientist ( Lu et al. , 2024 ) extends this to a full pipeline—implementing ideas as code and generating complete papers. Sci- MON ( W ang et al. , 2024 ) optimizes for nov elty by contrasting generated ideas against existing work. Si et al. ( 2024 ) conducted a large-scale study find- ing that LLM-generated ideas are rated as more nov el but less feasible than expert ideas. These systems demonstrate increasing sophistication in generation, but e valuation remains the bottleneck. Evaluation Methods. LLM-as-Judge ( Zheng et al. , 2023 ) is the dominant paradigm, with LLMs rating ideas on dimensions like nov elty and impact. Kno wn limitations include verbosity bias, self- enhancement bias, and poor calibration on open- ended judgments. Human e valuation provides a complementary signal but shows high v ariance— Si et al. ( 2024 ) report particularly low inter -annotator agreement on nov elty . Li et al. ( 2024 ) find sig- nificant discrepancies between LLM and human paper revie ws. T o our knowledge, no prior work has proposed an ev aluation frame work grounded in r eal-world r esearc h outcomes . Time-Split Evaluation. Ev aluating predictions against future outcomes is standard in finance (backtesting) and recommender systems (temporal splits). In NLP , temporal splits prev ent data contam- ination in knowledge-intensi ve tasks. H I N D S I G H T applies this principle to research ideas: we treat post- T publications as ground truth for assessing ideas generated with pre- T knowledge. 3 The H I N D S I G H T Framework 3.1 Problem Formulation Let G be an idea generation system with access to literature L T be the gr ound truth pool of papers published after T . The goal is to ev aluate ho w well ideas in I anticipate research in P >T . 3.2 Time-Split Design The cutof f T must satisfy two constraints: (1) the LLM’ s knowledge cutof f falls after T with a safety margin to pre vent information leakage, and (2) the ground truth window [ T , T +∆] is long enough to capture meaningful dev elopments. W e use T = June 2023 with Llama-3.3-70B-Instruct (cut- of f: December 2023), giving a 6-month mar gin and a 30-month ground truth windo w . 3.3 Matching For each idea i , we identify matching papers via semantic similarity: 1. Encode : represent ideas as pr oblem ⊕ method and papers as title ⊕ abstract , where ⊕ is con- catenation with a separator . 2. Retriev e : find the top- K most similar papers from P >T . 3. Filter : retain papers with cosine similarity ≥ θ , forming the match set: M ( i ) = { p ∈ top- K ( P >T , i ) | sim ( i, p ) ≥ θ } (1) 3.4 Impact Scoring Each paper p ∈ P >T recei ves an impact score: h ( p ) = 0 . 6 · ˆ c ( p ) + 0 . 4 · v ( p ) (2) where ˆ c ( p ) is the min-max normalized citation count within P >T , and v ( p ) ∈ { 0 , 1 } indicates publication at a top venue (ICLR, NeurIPS, ICML, A CL, EMNLP , CVPR, or AAAI). The H I N D S I G H T score is the maximum impact among matched papers: H I N D S I G H T ( i ) = max p ∈M ( i ) h ( p ) (3) If M ( i ) = ∅ , then H I N D S I G H T ( i ) = 0 . W e use the maximum rather than av erage because a single high-impact match provides strong evidence that the idea anticipated a significant direction. 4 Experimental Setup 4.1 Ground T ruth Pool W e query the Semantic Scholar API ( Kinney et al. , 2023 ) for AI/ML papers published between June 2023 and December 2025 across 10 research topics (Appendix A ). After deduplication, the pool con- tains 27,589 unique papers with titles, abstracts, citation counts, and venue information. 4.2 Idea Generation Systems ResearchAgent (retriev al-augmented). W e im- plement a simplified two-stage version of Re- searchAgent ( Baek et al. , 2025 ): a ProblemIden- tifier reads a seed paper and surfaces open prob- lems, and a MethodDeveloper proposes a concrete 2 T P r e - T ( b e f o r e J u n e 2 0 2 3 ) P o s t - T ( J u n e 2 0 2 3 D e c . 2 0 2 5 ) P r e - T L i t e r a t u r e Idea Generation (ResearchAgent / Baseline) Generated Ideas ( n = 2 0 0 ) P o s t - T P a p e r s (27,589) SPECTER2 Encoding F AIS S Matching ( s i m ) Impact Scoring HindSight Score Figure 1: The H I N D S I G H T framework. An idea generation system accesses only pre- T literature to produce research ideas. These are encoded alongside post- T papers using SPECTER2, matched via F AISS, and scored by the matched papers’ real-world citation impact and venue prestige. approach. Both stages retrie ve additional pre- T papers via the Semantic Scholar API (restricted to before June 2023). W e select 10 seed papers per topic and generate one idea per seed, yielding 100 ideas . V anilla baseline (no retriev al). The same LLM is prompted with the topic name and a generic instruction to propose a research idea, producing 100 ideas (10 per topic) without literature retriev al. Both systems use Llama-3.3-70B-Instruct ( Grattafiori et al. , 2024 ) serv ed via vLLM ( Kwon et al. , 2023 ). 4.3 Embedding and Matching W e encode all documents using SPECTER2 ( Co- han et al. , 2020 ; Singh et al. , 2023 ), a transformer pre-trained on citation graphs (768-dim CLS em- beddings). Matching uses a F AISS ( Johnson et al. , 2021 ) inner -product index ov er L2-normalized vec- tors (cosine similarity), retrie ving top- K =20 per idea. Threshold calibration. SPECTER2 base pro- duces highly concentrated similarity distrib utions for AI/ML te xt (0.91–0.98 range). W e select θ =0 . 96 through sensiti vity analysis (§ 5.3 ), which provides strong discrimination while retaining enough matches for meaningful analysis. 4.4 LLM-as-Judge All 200 ideas are scored by Qwen3-32B ( Y ang et al. , 2025 ) on four dimensions (1–10): Nov elty , Feasibility , Expected Impact, and Overall quality . Each idea is ev aluated 3 times ( T =0 . 7 ) and scores Metric RA BL ∆ p H I N D S I G H T evaluation Score (mean) 0.297 0.119 +0.178 < 0.001 Score (median) 0.403 0.000 +0.403 — Match rate 81% 42% +39% — A vg. matches 9.0 3.3 +5.7 — LLM-as-J udge evaluation Overall 7.44 7.40 +0.03 0.584 Nov elty 6.68 7.11 − 0.42 < 0.001 Impact 7.87 8.17 − 0.30 < 0.001 Feasibility 7.68 7.09 +0.59 — T able 1: System comparison (RA = ResearchAgent, BL = baseline). Statistical tests: Mann–Whitne y U . H I N D - S I G H T sharply distinguishes the two systems, while LLM-as-Judge Overall does not. av eraged. W e deliberately use a dif ferent model family from the generator to a void self-preference bias. 5 Results 5.1 Main Results T able 1 and Figure 2 present the comparison be- tween the retrie v al-augmented system (RA) and v anilla baseline (BL). The disconnect is stark. H I N D S I G H T re veals that 81% of retrie val-augmented ideas match at least one ground truth paper , compared to only 42% for the baseline, with a 2.5 × higher mean score ( p< 0 . 001 ). LLM-as-Judge, in contrast, finds no significant differ ence in overall quality ( p =0 . 584 ). The per-dimension LLM scores are equally re- vealing: the baseline is rated higher on both no velty ( p< 0 . 001 ) and expected impact ( p< 0 . 001 ). The 3 ResearchAgent Baseline 0.0 0.1 0.2 0.3 0.4 0.5 0.6 HindSight Score *** (a) HindSight Score ResearchAgent Baseline 6.6 6.8 7.0 7.2 7.4 7.6 7.8 8.0 LLM-Judge Overall (1 10) n.s. (b) LLM-Judge Overall Figure 2: Score distributions for both e valuation methods. (a) H I N D S I G H T clearly separates the two systems, with the baseline clustering at zero. (b) LLM-as-Judge Overall scores are nearly identical ( p =0 . 584 ). Diamond markers show means. ResearchAgent Baseline Dimension ρ p ρ p Nov elty − 0.291 0.003 − 0.140 0.164 Feasibility +0.252 0.012 +0.006 0.951 Impact − 0.225 0.025 − 0.150 0.135 Overall − 0.075 0.457 − 0.124 0.219 T able 2: Spearman ρ between H I N D S I G H T and LLM- Judge dimensions. For ResearchAgent, H I N D S I G H T is negatively correlated with novelty and impact but positiv ely correlated with feasibility . All baseline corre- lations are non-significant. only dimension fa voring the retriev al-augmented system is feasibility—consistent with its ideas be- ing more grounded in specific literature. 5.2 Correlation Analysis T able 2 reports Spearman correlations ( Spearman , 1904 ) between H I N D S I G H T scores and each LLM- Judge dimension. The most striking pattern is the negative corre- lation with no velty ( ρ = − 0 . 29 , p =0 . 003 ): ideas the LLM rates as more original are less likely to match real future work. This suggests LLMs con- fuse surface-lev el originality (“novel-sounding”) with genuinely anticipatory thinking (aligned with actual research trajectories). The positiv e correlation with feasibility ( ρ = + 0 . 25 , p =0 . 012 ) is intuiti ve: practically grounded ideas more closely resemble real research. The negati ve correlation with LLM-judged impact ( ρ = − 0 . 22 , p =0 . 025 ) further underscores the disconnect—percei ved ambition and actual impact point in opposite directions. For the baseline, all correlations are non- significant, likely reflecting a more homogeneous set of ideas with less quality v ariation. 5.3 Threshold Sensitivity The similarity threshold θ is a ke y parameter . Fig- ure 3 sho ws that the retriev al-augmented system’ s adv antage is robust across the full range tested. At lenient thresholds ( θ ≤ 0 . 93 ), almost all ideas match, collapsing the distinction. As θ increases, the gap widens: the RA/BL ratio of mean scores gro ws from 1.1 × at θ =0 . 93 to 3.8 × at θ =0 . 965 . W e select θ =0 . 96 as the operating point because it provides strong discrimination (81% vs. 42% match rate) while retaining enough matches for statistical analysis. 6 Case Study T o understand why H I N D S I G H T and LLM-as-Judge disagree, we classify each idea into one of four quadrants based on whether its H I N D S I G H T score and LLM-Judge Overall score e xceed their respec- ti ve medians (Figure 4 , T able 3 ). T rue P ositives (RA: 17, BL: 6). The retriev al- augmented system produces nearly 3 × more true positi ves. These ideas are technically concrete and well-grounded. For example, an RA idea propos- ing a multimodal adapter fr amework for contr ol- lable text-to-ima ge diffusion matched IP-Adapter (1,397 citations) with similarity 0.977 and recei ved a Judge score of 7.67—v alidated by both metrics. 4 0.93 0.94 0.95 0.96 0.97 S i m i l a r i t y t h r e s h o l d 0 20 40 60 80 100 I d e a s w i t h 1 m a t c h = 0 . 9 6 (a) Match R ate ResearchAgent Baseline 0.93 0.94 0.95 0.96 0.97 S i m i l a r i t y t h r e s h o l d 0.1 0.2 0.3 0.4 Mean HindSight Score 1 . 1 × 1 . 5 × 2 . 5 × 3 . 5 × (b) Mean HindSight Score ResearchAgent Baseline Figure 3: Threshold sensitivity . (a) At lenient thresholds ( θ ≤ 0 . 93 ) nearly all ideas match, reducing discriminati ve power . (b) The ratio of RA to BL mean H I N D S I G H T scores grows monotonically from 1.1 × to 3.8 × as θ increases, confirming that the advantage is rob ust and amplified at stricter thresholds. Dotted lines mark θ =0 . 96 . 6.8 7.0 7.2 7.4 7.6 7.8 8.0 LLM-Judge Overall Score 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 HindSight Score Hidden Gem T rue P ositive T rue Negative Overhyped ResearchAgent Baseline Figure 4: Each idea plotted by LLM-Judge Overall ( x ) and H I N D S I G H T score ( y ). Dashed lines mark the medians used for quadrant classification. Retrie val- augmented ideas (blue) concentrate in the upper quad- rants; baseline ideas (orange) cluster at y =0 . Hidden Gems (RA: 23, BL: 13). 23% of RA ideas hav e high H I N D S I G H T but below-median LLM scores. These tend to be technically specific ideas that lack the “e xciting narrativ e” LLMs re- ward. An idea about optimizing latent diffusion via cascaded ar chitectur es and knowledge distilla- tion scored only 7.33 from the judge but matched a real paper on self-cascade diffusion models (53 citations). The LLM penalized it for perceiv ed in- crementality , yet it anticipated a concrete research direction. Overh yped (RA: 26, BL: 34). Ideas that score well subjecti vely but zero on H I N D S I G H T . These are characteristically grand but vague : proposals RA BL Category n % n % T rue Positive 17 17 6 6 Hidden Gem 23 23 13 13 Overhyped 26 26 34 34 T rue Negativ e 34 34 47 47 T able 3: Quadrant distribution. T rue P ositive : high on both. Hidden Gem : high H I N D S I G H T , lo w Judge (LLM underrates). Overhyped : low H I N D S I G H T , high Judge (LLM ov errates). T rue Negative : low on both. for “holistic frame works” or “unified approaches” that sound ambitious b ut are too abstract to match any specific paper . A baseline idea propos- ing a game-theoretic frame work for alignment in multi-agent systems recei ved 8.0/10 b ut matched nothing—too broad to constitute a publishable con- tribution. The baseline has more ov erhyped ideas (34% vs. 26%), confirming that without retriev al grounding, the model produces more speculative ideas that score well subjecti vely . T rue Negatives (RA: 34, BL: 47). W eak ideas correctly identified by both methods. The base- line’ s larger share (47% vs. 34%) reflects that ideas without literature context are more often weak across both measures. 6.1 Interpr etation The case study re veals a systematic pattern: LLM judges rew ard novelty of framing ov er anticipa- tion of real impact . Ambitious, broadly-stated ideas score well but rarely correspond to specific research that gets published. Meanwhile, techni- 5 cally grounded ideas—often enabled by literature retrie val—may appear incremental to an LLM but prov e forward-looking. This explains the ne gativ e ρ with nov elty: the most “novel” ideas (by LLM standards) tend to be the most speculati ve. 7 Discussion Complementary ev aluation. Our results do not render LLM-as-Judge useless—it captures dimen- sions (clarity , ambition, coherence) that H I N D - S I G H T cannot. Rather , the two approaches are complementary: LLM-as-Judge for fast screening, H I N D S I G H T for objecti ve v alidation when ground truth is av ailable. W e recommend future work re- port both. Implications f or idea generation. If LLM judges consistently fail to distinguish retriev al- augmented from vanilla generation, then optimiz- ing idea gener ation systems against LLM judge scor es may be misguided —it could push systems to- ward producing impressiv e-sounding but ultimately v acuous ideas. H I N D S I G H T provides an alternati ve optimization target grounded in real impact. Conf ormity bias. H I N D S I G H T rewards match- ing published work, potentially underv aluing truly re volutionary ideas that open entirely new direc- tions. W e vie w this as an acceptable trade-off: the frame work measures anticipation of r eal r esear ch tr ends , which is meaningful ev en if incomplete. F alse negatives. A zero H I N D S I G H T score does not mean an idea is bad—it may simply not have been pursued within the 30-month windo w , or the rele vant papers may lie outside our 10-topic pool. Embedding limitations. SPECTER2 captures semantic similarity at the topic le vel but may miss structural or methodological no velty expressed in dif ferent terminology . T ask-specific adapter heads ( Singh et al. , 2023 ) or cross-encoder reranking could improv e matching precision. 8 Conclusion W e introduced H I N D S I G H T , a time-split e valua- tion framew ork that measures research idea quality against real future publications. Our experiments expose a fundamental disconnect: LLM judges see no difference between retrie val-augmented and v anilla idea generation, while H I N D S I G H T rev eals a 2.5 × gap. The negati ve correlation between H I N D S I G H T and LLM-judged nov elty suggests that language models rew ard “novel-sounding” framing ov er genuinely anticipatory thinking. As AI idea generation systems grow more capable, grounding ev aluation in real-world outcomes— rather than subjecti ve impressions—will be essen- tial. Limitations • Scale. W e ev aluate 200 ideas across 10 topics. Larger experiments with more systems would strengthen the findings. • Single embedding model. SPECTER2 base without adapter heads may miss nuanced matches. Cross-encoder reranking or ensembles could improv e precision. • Ground truth completeness. Our pool of 27,589 papers does not cov er all AI/ML research. Ideas matching uncovered papers receiv e false- zero scores. • Threshold sensitivity . While θ =0 . 96 was cali- brated empirically and results are robust (§ 5.3 ), absolute scores depend on this choice. • Conf ormity bias. H I N D S I G H T re wards proxim- ity to published work, potentially undervaluing genuinely nov el ideas not yet explored. • Single judge model. W e use Qwen3-32B as the sole judge; other models may yield dif ferent patterns. References Jinheon Baek, Sujin Jang, Y ongfei Huang, and Sung Ju Hwang. 2025. Researchagent: Iterati ve research idea generation ov er scientific literature with large lan- guage models. In Pr oceedings of the 2025 Confer- ence of the North American Chapter of the Associa- tion for Computational Linguistics (N AA CL) . Arman Cohan, Serge y Feldman, Iz Beltagy , Doug Downe y , and Daniel W eld. 2020. SPECTER: Document-lev el representation learning using citation-informed transformers. arXiv preprint arXiv:2004.07180 . Aaron Grattafiori and 1 others. 2024. The Llama 3 herd of models. arXiv preprint . Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-scale similarity search with GPUs. IEEE T ransactions on Big Data , 7(3):535–547. Rodney Kinney , Chloe Anastasiades, Russell Authur, Iz Belber , Jonathan Berber , Eli Borkenhagen, and 1 others. 2023. The Semantic Scholar open data plat- form. In Pr oceedings of the 61st Annual Meeting of the Association for Computational Linguistics: Sys- tem Demonstrations . 6 W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Y ing Sheng, Lianmin Zheng, Cody Hao Y u, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Ef- ficient memory management for large language model serving with PagedAttention. arXiv pr eprint arXiv:2309.06180 . W eixin Li, Y iran Peng, Meng Zhang, Liqun Ding, Han Hu, and Li Shen. 2024. Can large language models provide useful feedback on research papers? A large-scale empirical analysis. arXiv pr eprint arXiv:2310.01783 . Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob F oer- ster , Jeff Clune, and David Ha. 2024. The AI scien- tist: T owards fully automated open-ended scientific discov ery . arXiv preprint . Chenglei Si, Diyi Y ang, and T atsunori Hashimoto. 2024. Can LLMs generate novel research ideas? A large- scale human study with 100+ NLP researchers. arXiv pr eprint arXiv:2409.04109 . Amanpreet Singh, Mike D’Arc y , Arman Cohan, Doug Downe y , and Serge y Feldman. 2023. SciRepEval: A multi-format benchmark for scientific document representations. arXiv preprint . Charles Spearman. 1904. The proof and measurement of association between tw o things. The American Journal of Psyc hology , 15(1):72–101. Qingyun W ang, Doug Do wney , Heng Ji, and T om Hope. 2024. SciMON: Scientific inspiration machines opti- mized for nov elty . arXiv pr eprint arXiv:2305.14259 . An Y ang and 1 others. 2025. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 . Lianmin Zheng, W ei-Lin Chiang, Y ing Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, and 1 others. 2023. Judging LLM-as-a-judge with MT -Bench and chatbot arena. In Advances in Neural Information Pr ocessing Systems . A Research T opics The 10 topics used in our e xperiments: (1) Align- ment & Safety , (2) Chain-of-Thought Reason- ing, (3) Dif fusion Models, (4) Ef ficient Inference, (5) Hallucination Mitigation, (6) In-Context Learn- ing, (7) Instruction T uning & RLHF , (8) LLM Agents, (9) Multimodal LLMs, (10) Retriev al- Augmented Generation. Each topic was selected to hav e significant pre- T literature ( ≥ 50 papers) and substantial post- T de velopments ( ≥ 100 papers in the ground truth pool). B LLM-as-Judge Prompt The system prompt instructs the judge to e valu- ate each idea on four dimensions (1–10): No velty (originality beyond incremental e xtensions), F ea- sibility (practicality with current tools and data), Expected Impact (significance if successful), and Overall quality . The judge responds in JSON with integer scores and a brief rationale. Each idea re- cei ves 3 independent ev aluations (temperature 0.7), with scores av eraged. C Impact Score Details Impact scores in the ground truth pool range from 0 to 1, with a mean of 0.03 and median of 0.006 (heavily right-skewed due to power -law citation distributions). Papers published at the 7 top venues ( v ( p )=1 ) account for approximately 8% of the pool. The 0.6/0.4 weighting between citations and venue was chosen to balance quantitativ e impact with peer-re view quality signal. D Correlation Heatmap Figure 5 visualizes the Spearman correlations from T able 2 . The ne gativ e correlations for ResearchA- gent (blue cells) and the absence of significant correlations for the baseline (near -white cells) are clearly visible. ResearchAgent Baseline Novelty F easibility Impact Overall -0.29** -0.14 +0.25* +0.01 -0.22* -0.15 -0.08 -0.12 S p e a r m a n : H i n d S i g h t v s L L M - J u d g e 0.4 0.2 0.0 0.2 0.4 Figure 5: Spearman ρ between H I N D S I G H T and LLM- Judge dimensions. Stars denote significance: * p< 0 . 05 , ** p< 0 . 01 , *** p< 0 . 001 . 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment