오픈병원 LLM 기반 집단지능 진화와 벤치마크 플랫폼
** 오픈병원은 의사 에이전트와 환자 에이전트가 상호작용하는 동적 시뮬레이션 환경을 제공한다. 데이터‑인‑에이전트‑셀프(paradigm)를 통해 정적 데이터가 아닌 에이전트 자체에서 학습 데이터를 생성하도록 설계했으며, 검사 정확도, 진단 정확도, 치료계획 정합성, 토큰 사용량 등 네 가지 핵심 지표로 의료 능력과 시스템 효율성을 동시에 평가한다. 실험 결과, 사례 수가 증가할수록 의사 에이전트의 임상 성능이 지속적으로 향상되고, 협업·컨센…
저자: Peigen Liu, Rui Ding, Yuren Mao
**
본 논문은 대규모 언어 모델(LLM) 기반 집단지능(CI)의 발전을 가속화하고, 이를 객관적으로 평가할 수 있는 전용 벤치마크 환경이 부재함을 지적한다. 이를 해결하기 위해 저자들은 ‘오픈병원(OpenHospital)’이라는 인터랙티브 아레나를 설계하였다. 오픈병원은 의사 에이전트와 환자 에이전트가 실시간으로 상호작용하는 의료 시뮬레이션 환경으로, 기존 정적 데이터셋이 제공하는 ‘현상(phenomenon)’을 넘어 에이전트 자체가 데이터를 생성·학습하는 ‘데이터‑인‑에이전트‑셀프(data‑in‑agent‑self)’ 패러다임을 도입한다.
**1. 철학적 배경 및 목표**
논문은 임마누엘 칸트의 ‘현상 vs. 물자체’ 개념을 차용해, 정적 데이터가 에이전트에게 제공하는 표면적인 지식(현상)만으로는 진정한 집단지능을 구현하기 어렵다고 주장한다. 따라서 에이전트가 직접 ‘물자체’를 탐색하도록 설계된 동적 환경이 필요하다고 강조한다. 오픈병원은 세 가지 핵심 요구사항을 만족한다. (i) 정량적 진화 추적을 위한 명확한 메트릭, (ii) 비결정론적·복합적인 환경 제공, (iii) 협업이 필수적인 복합 질환 시나리오 제공이다.
**2. 환자 에이전트 구축**
환자 에이전트는 네 가지 축을 중심으로 설계된다.
- **임상 정확성**: 583개 질병·467개 이환율을 포함한 방대한 지식베이스를 구축하고, DeepSeek‑v3.1 기반 다단계 파이프라인으로 증상·검사·진단 간 인과관계를 엄격히 검증한다. GPT‑5.2를 활용한 ‘LLM‑as‑judge’ 평가에서 평균 4.41/5의 의료 일관성 점수를 획득했다.
- **페르소나 다양성**: Self‑BLEU4(0.411)와 TF‑IDF 다양성(0.873) 지표를 통해 인구통계·심리적 특성의 폭넓은 분포를 확보했으며, 동일 질문에 대한 응답에서도 Self‑BLEU4(0.592), TF‑IDF(0.901)로 높은 변이를 보였다.
- **언어 유창성**: Baichuan‑M2‑32B 모델을 이용해 퍼플렉서티 5.75를 기록, 전문 의료 텍스트와 거의 구분되지 않는 수준의 언어 품질을 달성했다.
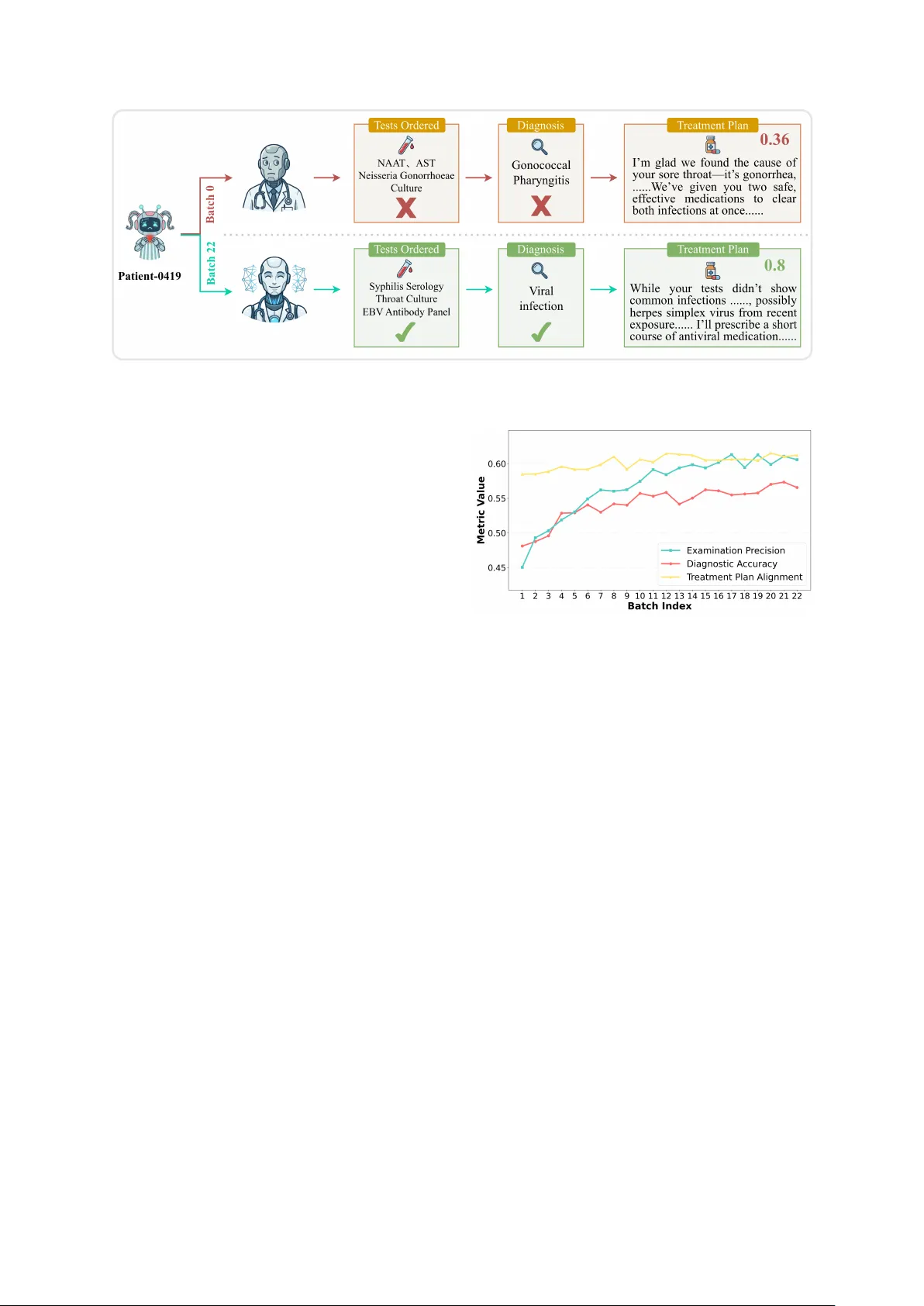
- **행동 현실성**: 정보 비대칭 구조를 도입해 환자 에이전트는 주관적 증상만을 제공하고, 객관적 검사·진단 정보는 숨긴 채 대화 흐름에 따라 점진적으로 드러나게 함으로써 의사 에이전트가 논리적 추론을 수행하도록 유도한다. GPT‑5.2 평가에서 정확도 4.36/5, 관련성 4.74/5, 페르소나 정렬 4.12/5를 기록했다.
**3. 평가 메트릭**
오픈병원은 ‘의료 역량’과 ‘시스템 효율성’ 두 축으로 메트릭을 설계한다.
- **검사 정확도(Examination Precision)**: 예측된 검사 리스트와 표준 리스트의 교집합 비율로, 불필요한 검사를 억제한다.
- **진단 정확도(Diagnostic Accuracy)**: 최종 합의 진단이 정답과 일치하는지 여부를 0/1로 평가한다.
- **치료 계획 정합성(Treatment Plan Alignment)**: LLM 기반 평가자를 활용해 안전성·효과·개인화 차원에서 점수를 매긴다.
- **총 입력 토큰(Total Input Tokens)**: 전체 워크플로우에서 처리된 입력 토큰 수를 측정해 계산 비용을 정량화한다.
**4. 실험 및 결과**
Agent‑Kernel 프레임워크 위에 베이스라인 시스템을 구축하고, 사례 수를 100, 500, 1000으로 확대하면서 의사 에이전트의 성능 변화를 관찰했다. 사례 수가 증가할수록 검사 정확도, 진단 정확도, 치료 계획 정합성 모두 유의미하게 상승했으며, 특히 복합 합병증·희귀 질환 케이스에서 다수의 의사 에이전트가 서로 컨설팅하고 컨센서스를 도출하는 협업 행동이 자연스럽게 나타났다. 이는 동적 환경에서 LLM 기반 집단지능이 스스로 진화할 수 있음을 실증한다.
**5. 논의 및 한계**
본 연구는 동적 의료 시뮬레이션을 통한 집단지능 평가라는 새로운 패러다임을 제시했지만, 몇 가지 제한점이 있다. (1) 환자 에이전트의 임상 타당성 검증이 LLM‑as‑judge에 의존해 인간 전문가와의 교차 검증이 부족하다. (2) 현재는 텍스트 기반 대화에 국한돼 있어 영상·이미지·생체신호 등 멀티모달 데이터와의 통합이 미흡하다. (3) 토큰 기반 효율성 지표는 모델 호출 비용을 대략적으로만 반영하므로, 실제 배포 시 지연시간·메모리 사용량 등 추가적인 시스템 지표가 필요하다.
**6. 향후 연구 방향**
- 인간 전문가와의 협업을 통해 환자 에이전트의 임상 타당성을 강화하고, 정량적·정성적 검증을 병행한다.
- 멀티모달 입력(영상·생체신호)을 포함한 확장형 시뮬레이션을 구축해 실제 임상 현장과의 격차를 좁힌다.
- GPU/CPU 사용량, 응답 지연 등 정밀한 시스템 효율성 지표를 도입해 실용성을 높인다.
**7. 결론**
오픈병원은 LLM 기반 집단지능을 실험·평가할 수 있는 최초의 동적 의료 시뮬레이션 플랫폼으로, 데이터‑인‑에이전트‑셀프 패러다임을 통해 에이전트 자체가 학습 데이터를 생성하도록 함으로써 ‘데이터 벽’ 극복에 새로운 길을 제시한다. 실험 결과는 동적 환경에서 에이전트가 스스로 협업·컨센서스 행동을 학습하고, 의료 역량과 시스템 효율성을 동시에 향상시킬 수 있음을 보여준다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기