OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmar…
Authors: Peigen Liu, Rui Ding, Yuren Mao
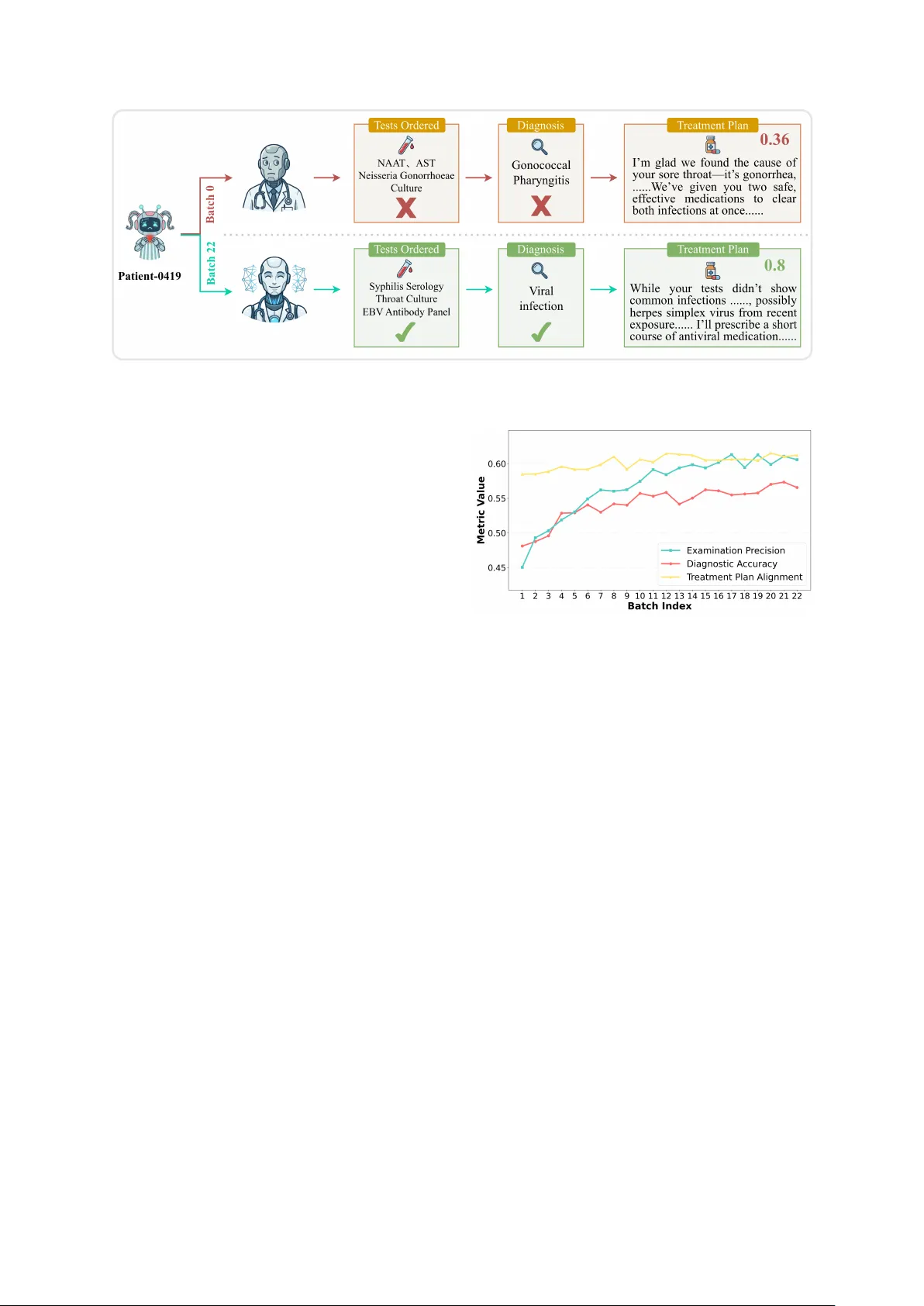
OpenHospital: A Thing-in-itself Ar ena f or Evolving and Benchmarking LLM-based Collectiv e Intelligence Peigen Liu 1 , Rui Ding 1 , Y uren Mao 1 * , Ziyan Jiang 1 , Y uxiang Y e 1 , Y unjun Gao 1 , Y ing Zhang 2 , Renjie Sun 2 , Longbin Lai 3 , Zhengping Qian 4 1 School of Software T echnology , Zhejiang Uni versity 2 Laboratory for Statistical Monitoring and Intelligent Gov ernance of Common Prosperity , Zhejiang Gongshang Uni versity 3 T ongyi Lab, Alibaba Group 4 Alibaba Cloud {peigenliu, rui.ding, yuren.mao}@zju.edu.cn § https://github .com/ZJU-LLMs/Agent-Kernel Abstract Large Language Model (LLM)-based Collec- tiv e Intelligence (CI) presents a promising ap- proach to ov ercoming the data wall and contin- uously boosting the capabilities of LLM agents. Howe ver , there is currently no dedicated arena for ev olving and benchmarking LLM-based CI. T o address this gap, we introduce OpenHospi- tal, an interactiv e arena where physician agents can ev olve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabili- ties and provides rob ust ev aluation metrics for benchmarking both medical proficiency and system efficienc y . Experiments demonstrate the ef fecti veness of OpenHospital in both fos- tering and quantifying CI. 1 Introduction Thing in itself —Immanuel Kant The scaling laws go v erning Large Language Mod- els (LLMs) currently encounter significant limita- tions as high-quality human corpora reach exhaus- tion, termed the data wall . Overcoming this barrier requires Collecti ve Intelligence (CI), wherein multi- agent coordination facilitates continuous interac- tion data synthesis. Ho we ver , transitioning to ward CI demands a paradigm shift in data methodology: progressing from training agents on static, in variant inputs to embedding them within dynamic environ- ments that iterati vely evolv e based upon complex autonomous agent behaviors. This shift echoes a fundamental Kantian di- chotomy between the phenomenon —the object as percei ved—and the noumenon , or the thing-in-itself (das Ding an sich) ( Kant , 1781 ). Existing static * Corresponding author . datasets capture only the phenomenon, restricting agents to a superficial le vel of imitation and rote memorization. For true collecti ve intelligence to emerge, agents must transcend surface-le vel obser - v ations and approximate the noumenal structure of reality through activ e, purposeful engagement. Current research, ho wever , remains largely con- fined to static benchmarks that ev aluate snapshot capabilities, lacking the dynamic arena required for the e volution of collecti ve cognition. T o bridge this gap, we propose OpenHospital , a thing-in-itself arena for the e v olving and bench- marking of LLM-based collectiv e intelligence. OpenHospital introduces a no vel data paradigm termed data-in-agent-self : rather than receiving static inputs (phenomena), physician agents must interact with patient agents—modeled as dynamic entities (noumena)—to elicit clinical information. This interaction forces physicians to integrate med- ical kno wledge and debate treatment options, dri v- ing the emergence of collectiv e intelligence. T o function as a v alid training ground for such intelli- gence, OpenHospital satisfies three critical require- ments: (i) Quantifiable Evolution , utilizing rigor - ous metrics such as Examination Precision, Diag- nostic Accuracy , and T reatment Plan Alignment to track the emer gence of intelligence; (ii) Dynamic Complexity , creating a non-deterministic en viron- ment where patient responses unfold dynamically; and (iii) Collaborative Necessity , establishing sce- narios where rare diseases and comorbidities make agent cooperation indispensable. T o validate the effecti v eness of OpenHospital, we establish a baseline for it using the Agent- K ernel frame work ( Mao et al. , 2025 ). Our experi- ments demonstrate that as case volume increases, physician agents exhibit significant impro v ements 1 across all clinical capability metrics. Furthermore, analysis of the diagnostic process reveals the spon- taneous emergence of sophisticated cooperati v e be- haviors, including peer consultation and consensus- dri ven decision-making. These results validate that OpenHospital functions not only as a rigorous ev al- uation benchmark for agents in changing en viron- ments but also as a potent ev olutionary training ground for genuine collecti ve intelligence. 2 Related W ork LLM-based Multi-Agent Systems W ith the de- velopment of large language models (LLMs), LLM- based multi-agent systems (LLM-MAS) ha ve pro- gressed, contributing to the study of collectiv e intel- ligence. Existing works generally fall into tw o cat- egories: T ask-Oriented and Simulation-Oriented. In task-oriented domains, LLM-based multi-agent systems are applied to fields like softw are engineer - ing( Hong et al. , 2024 ; W u et al. , 2023 ; Qian et al. , 2023 ), scientific research( Gottweis et al. , 2025 ; Ghafarollahi and Buehler , 2024 ; Su et al. , 2025 ), and embodied AI( Mandi et al. , 2023 ; Y u et al. , 2025a ). In simulation-oriented tasks, following the pioneering work of Stanford Smallville( Park et al. , 2023 ), man y studies ha ve emer ged in fields like social( Park et al. , 2023 ; Mao et al. , 2025 ; Piao et al. , 2025 ), narrati v e( Huot et al. , 2025 ; Y u et al. , 2025b ), economic( Li et al. , 2024 ; Lin et al. , 2025 ; Sashihara et al. , 2025 ) and other professional simu- lations( Zhang et al. , 2025 ; Bougie and W atanabe , 2025 ). While these works emphasize the construc- tion of robust static MAS, they provide a limited perspecti ve on the dynamic processes, which en- able the system to iterati vely refine agent behaviors and achie ve emer gent intelligence. T o address this issue, this work introduces a training ground that is measurably e v olv able, dynamically comple x, and inherently collaborative, specifically designed to dri ve agent e volution. Benchmarks for LLM-based Multi-Agent Sys- tems As MAS research gro ws, man y benchmarks hav e emerged to e v aluate their performance. These benchmarks use various scenarios and metrics and generally fall into two categories: Role-playing and T ask-dri ven. Role-playing focuses on social interactions, and T ask-driven focuses on task com- pletion. In role-playing, benchmarks cover fields like social simulation( Zhou et al. , 2024 ; Park et al. , 2023 ; Piao et al. , 2025 ), competition and coop- eration( Zhu et al. , 2025 ). In task-dri ven scenar- ios, benchmarks focus on specific applications like software engineering( Jimenez et al. , 2024 ; Gol- nari et al. , 2026 ), scientific research( Chen et al. , 2025 ), and mathematical reasoning( Gao et al. , 2024 ). Howe v er , some benchmarks rely on static datasets. As a result, they cannot ev aluate ho w agents react in dynamic en vironments. Although some studies ha ve started to address this issue, their e v aluation processes are still limited, relying heav- ily on subjecti ve LLM-based scoring or in volving only highly restricted, human-defined dynamics. Furthermore, their assessment metrics are not com- prehensi ve enough. The y validate the entire pro- cess based only on the final result, which is not enough for complex simulations. T o bridge this gap, we adopt clinical diagnosis—a knowledge- intensi ve, collaborati ve, and objecti v ely e v aluable scenario—as a dynamic testbed for tracking agent e volution. Multi-Agent Systems f or Healthcare Recent research has increasingly focused on simulating clinical diagnosis scenarios. For instance, Agent Hospital( Li et al. , 2025 ) pioneered the closed-loop simulation of real hospital workflows and has been deployed. While Agent Clinic( Schmidgall et al. , 2025 ) focuses on performance e v aluation in com- plex en vironments. MedAgentSim( Almansoori et al. , 2025 ) uses features like multi-turn doctor - patient dialogues to create more realistic simula- tions. Ho we ver , most pre vious studies focused on "textbook" cases with clear symptoms and easy di- agnoses. T o address this, we created a new dataset featuring comorbidities and long-tail diseases to increase realism and challenge for agents. These cases are highly complex and often require con- sultations across dif ferent medical departments. Therefore, unlike pre vious work, our approach en- courages frequent collaboration and consultation between agents. 3 Construction of Patient Agents T o effecti v ely stimulate LLM-based collecti ve in- telligence within the OpenHospital arena, the con- struction of patient agents requires a rigorous bal- ance between clinical v alidity and realistic human v ariability . W e define and implement four indis- pensable pillars for realistic patients simulation in healthcare: Clinical Corr ectness , Persona Di ver - sity , Linguistic Fluency , and Behavioral Realism . This section details the systematic construction of these agents and the v alidation metrics emplo yed 2 to verify their practical ef fectiveness. 3.1 Clinical Correctness Clinical correctness mandates that patient agents strictly adhere to established medical knowledge, ensuring that synthesized symptoms, disease pro- gressions, and clinical histories are logically coher- ent and physiologically plausible. T o achieve such medical rigor , we de velop a multi-stage data synthesis pipeline powered by DeepSeek-v3.1 model ( DeepSeek-AI et al. , 2024 ). The process begins with the curation of an authori- tati ve kno wledge base encompassing 583 distinct diseases and 467 binary comorbidities across 19 clinical departments. Utilizing these resources, the pipeline synthesizes comprehensiv e patient data comprising three core components: patient ontol- ogy , examination reports , and gr ound-truth diag- noses . Here, the ontology serv es as a structured domain conceptualization ( Ghanadbashi and Gol- payegani , 2024 ), incorporating real-w orld clinical schemas to represent both disease dimensions and persona attributes. Within the synthesis stage, to address the hallucinations inherent in single-pass generation, we implement a multi-step refinement frame work. Rather than generating records in a single ex ecution, this framew ork iterati v ely models patient attributes under epidemiological constraints, strictly enforcing logical consistency between pre- senting symptoms, diagnostic findings, and final diagnoses to guarantee medical plausibility . T o v alidate clinical correctness, we design the targeted e valuation of the agents’ data foundations: • Q: How clinically r eliable is the static data backing the agents? W e utilize an LLM-as-a- judge system (po wered by GPT -5.2 ( OpenAI , 2025 )) to assess the internal consistency of the synthesized records. The ev aluation focuses on the causal alignment between symptoms and diagnoses, the temporal progression of pa- tient histories, and the safety of implied clini- cal pathways. As shown in T able 1 , the static data achie ve an average medical consistency score of 4.4113 (on a 1–5 scale), confirming a robust internal logic that respects medical common sense. 3.2 Persona Di versity Persona div ersity is defined as the inherent v ari- ance in demographic backgrounds, psychological traits, and behavioral patterns among the simulated Metric Score Self-BLEU4 0.4111 TF-IDF Di versity 0.8727 Perplexity 5.7501 Medical Consistency 4.4113 T able 1: Evaluation results of the synthesized static patient data. patient population, ensuring a heterogeneous and realistic en vironment for robust agent e v aluation. T o realize this div ersity , we construct a com- prehensi ve persona seed library by e xtracting and cleaning non-sensiti ve attrib utes related to person- alities from publicly a vailable persona datasets ( Ge et al. , 2025 ). These structured attributes serve as controllable inputs alongside the medical kno wl- edge base, which ensures that the synthesized pa- tient records maintain reasonable diversity . During the agent role-playing phase, these specific demo- graphic and psychosocial characteristics are dynam- ically injected via prompt engineering to natively modulate the agents’ tone, vocab ulary , and con ver- sational style. This deliberate inte gration pre vents the patient agents from defaulting to the repetiti ve, template-like communication patterns commonly observed in standard LLM simulations. T o quantify the ef fecti veness of our persona mod- eling, we e v aluate the distinctness of both the static profiles and the dynamic con versational outputs: • Q: Does the synthesized static dataset pr o- vide sufficient demographic and identity variance? W e utilize Self-BLEU4 and TF- IDF di versity metrics to quantify the distinct- ness of the generated patient personas. As sho wn in T able 1 , the static dataset attains an a verage Self-BLEU4 score of 0.4111 and a TF-IDF div ersity score of 0.8727 . These metrics indicate substantial v ariance in patient identities, confirming that our seed library suc- cessfully a voids profile collapse and ensures a broad representational spectrum for e volving. • Q: Do the dynamic patient agents react dif- ferently to the same situation? W e assess interactional div ersity by subjecting all patient agents to a fixed set of standardized clinical inquiries. By calculating diversity metrics grouped by these specific questions, we find that the dynamic responses achie ve an a verage Self-BLEU4 of 0.5916 and a TF-IDF div er - 3 sity score of 0.9005 (see Figure 1 ). These results v alidate that identical clinical inputs yield naturally persona-modulated responses, accurately reflecting the beha vioral v ariance observed in real-w orld patients. Figure 1: Interactional response diversity of patient agents across the fixed question set. 3.3 Linguistic Fluency Linguistic fluency in our work is defined as the lexical richness and semantic coherence of the generated clinical narrati ves, ensuring the medical records produced are both professional and non- stereotypical. T o achieve this, our synthesis pipeline le verages the adv anced natural language generation capabili- ties of DeepSeek-v3.1, guided by persona-specific prompts and grounded in curated medical encyclo- pedias to ensure accurate nomenclature. Rather than merely optimizing for syntactic predictabil- ity , this approach emphasizes the production of di verse, high-fidelity clinical records that reflect the nuances of a real-world patient population. T o ev aluate the linguistic quality of the synthe- sized data, we measure its distributional alignment with professional medical corpora: • Q: How natural and coherent is the medi- cal text across these distinct personas? W e compute the Perplexity (PPL) across the en- tire dataset using the Baichuan-M2-32B ( Dou et al. , 2025 ), a domain-specialized medical model, as an independent e v aluator . In this context, a lo wer PPL indicates that the syn- thetic records align well with the distrib ution of professional clinical texts. The generated records yield an ov erall perplexity score of 5.7501 , demonstrating high linguistic coher- ence and strong alignment with standard clini- cal terminology and grammatical conv entions. 3.4 Beha vioral Realism Behavioral realism denotes the capacity of patient agents to emulate the authentic cognitive and inter - actional constraints of real-world clinical consulta- tions. T o implement this characteristic, we employ a dynamic role-playing architecture designed to mimic actual clinical en vironments. W e establish a strict epistemic boundary of information asymme- try: the patient agent only accesses subjecti ve on- tological information (e.g., experienced symptoms and personal history), while objecti ve diagnoses and examination reports remain hidden. Specifi- cally , synthesized medical histories are stored in a vector database to serv e as the agent’ s semantic memory , which is retrie v ed org anically during the con versation. Crucially , agents are explicitly in- structed to disclose information only in response to targeted inquiries. This constraint prev ents unreal- istic information dumping, thereby compelling the physician agent to demonstrate acti ve and logical diagnostic reasoning. T o validate the interactional fidelity of this ar- chitecture, we assess agent performance within a simulated multi-turn consultation frame work: • Q: How effectively do agents maintain char- acter and context during complex, multi- turn clinical dialogues? W e e v aluate dy- namic response quality using GPT -5.2 as an expert judge, providing it with complete pa- tient data to assess the hidden states of the interactions. Across simulated, non-linear consultations dri ven by physician inquiries, the patient agents achie ve high av erage scores: 4.36/5 for Accuracy , 4.74/5 for Relev ance, and 4.12/5 for Persona Alignment (as illustrated in Figure 2 ). These results confirm that the agents successfully navigate ev olving clini- cal contexts, maintaining strict beha vioral fi- delity and authentic information-sharing pac- ing without breaking character . 4 Benchmarking Agent Evolution T o validate the ef ficacy of the OpenHospital arena in fostering collecti ve intelligence, we establish a comprehensi ve baseline system. In this section, we first introduce a suite of multi-dimensional metrics designed to capture both clinical validity and sys- temic efficienc y . W e then deploy our baseline to 4 Figure 2: Dynamic response quality scores ev aluated by GPT -5.2 across Accuracy , Relev ance, and Persona Alignment. e v aluate these metrics, demonstrating the continu- ous e volution of ph ysician agents. 4.1 Evaluation Metrics W e propose a multi-dimensional ev aluation com- prising Medical Capability , which e v aluates clin- ical validity from examinations to treatment, and System Ef ficienc y , which assesses computational cost. Medical Capability Metrics W e e valuate clini- cal proficiency using three complementary metrics: • Examination Pr ecision assesses the rele- v ance and necessity of ordered tests. Defined as P = | L pred ∩ L g old | / | L pred | , where L pred is the predicted e xamination list and L g old is the standard clinical set, this metric penalizes unnecessary tests while rew arding the prioriti- zation of informati ve e xaminations. • Diagnostic Accuracy measures the correct- ness of the final consensus diagnosis. For - mally , for a case i with ground truth D g old , the score is 1 if the agent’ s diagnosis D ag ent = D g old , and 0 otherwise, capturing the core clinical judgment in dynamic and incomplete information en vironments. • T r eatment Plan Alignment ev aluates ther - apeutic quality against gold-standard guide- lines via an LLM-based ev aluator . Plans are scored across three dimensions—safety , ef- fecti veness, and personalization—providing a holistic vie w of the agents’ therapeutic rea- soning capabilities. System Efficiency Metric Beyond medical capa- bility , we assess the computational cost of system ex ecution using T otal Input T okens . This metric measures the cumulativ e number of input tokens processed across all LLM interactions, including patient simulations, physician reasoning, and auxil- iary e v aluations, ov er the full e xecution w orkflo w . As an end-to-end indicator of prompt-side compu- tational demand, it provides a practical basis for analyzing the trade-of f between task performance and computational ef ficiency in real-w orld deploy- ment settings. The proposed e v aluation metrics balance clinical v alidity with systemic efficienc y to ensure a robust assessment of agent ev olution. By integrating met- rics across the full clinical pathway—examination, diagnosis, and treatment—we transcend the limi- tations of single-dimension accuracy and prevent shortcut reasoning, where correct diagnoses might stem from flawed in vestigati v e processes or unsafe therapeutic plans. Simultaneously , T otal Input T o- kens serves as a critical proxy for computational ov erhead and operational cost. Tracking this metric ensures that performance gains reflect optimized reasoning logic rather than e xhausti v e, inef ficient prompting. T ogether, these multi-dimensional indi- cators provide a rigorous benchmark for the scal- ability and cost-ef fecti veness of collectiv e intelli- gence in real-world healthcare deployments. 4.2 Experimental Setup Datasets The experiment is conducted on a com- prehensi ve dataset comprising 12,000 diverse pa- tient records, which is partitioned into training and test sets at a 9:1 ratio. T o meticulously track the e volutionary trajectory of the system’ s collective in- telligence, the training set is further organized into 22 sequential batches, with each batch containing approximately 500 clinical cases. Baseline Our baseline is constructed utilizing the Agent-K ernel frame work, featuring a multi-agent architecture of 38 physician agents distributed across 19 specialized clinical departments (two physicians per department). These agents oper - ate within a sophisticated action space that encom- passes patient perception, tar geted inquiry , diag- nostic examination, multi-agent consultation, and kno wledge retrie v al, culminating in final treatment formulations. Central to this baseline is a closed- loop reflection mechanism designed to driv e au- tonomous e v olution; after each case, agents en- 5 Figure 3: Diagnostic ev olution of a physician agent across training batches. gage in a multi-dimensional self-critique that syn- thesizes diagnostic accuracy ag ainst ground truth, examination efficienc y , and therapeutic safety to bridge ef ficacy gaps. By integrating these diagnos- tic, in vestig ati ve, and treatment reflections into a unified feedback loop, the agents systematically accumulate clinical experience and optimize their decision-making logic ov er time. Experimental Settings For the experimental im- plementation, both physician and patient agents are po wered by the Qwen/Qwen3-Next-80B-A3B- Instruct model ( Y ang et al. , 2025 ) to ensure high- fidelity interaction and reasoning. 4.3 Evaluation Results of Agent Evolution T o robustly v alidate OpenHospital’ s ef ficacy as an e volutionary arena, we conduct a comprehen- si ve quantitative analysis of the physician agents across 22 iterative training batches. W e e v aluate this ev olution through two distinct but complemen- tary lenses: the enhancement of clinical proficiency and the optimization of computational ef ficiency . Medical Capabilities W e track the performance trajectories of the physician agents throughout the training timeline. As Figure 4 illustrates, the agents exhibit consistent upward trends across all core clinical metrics as they accumulate experience. Most notably , Examination Precision sho ws a sub- stantial gain, rising from 45.05% to 61.31% , indi- cating a marked reduction in e xploratory or redun- dant testing. Concurrently , Diagnostic Accuracy demonstrates strong improv ement, climbing from 48.11% to 57.34% , while T reatment Plan Align- ment sho ws a steady and consistent refinement, increasing from 58.49% to 61.52% . Figure 4: Performance trajectories of clinical capabili- ties across training batches. System Efficiency T o assess the operational cost of this professional gro wth, we track the T otal In- put T okens processed across all interactions. Anal- ysis re veals a progressi ve optimization in computa- tional ef ficiency that directly parallels the clinical improv ements. As illustrated in Figure 5 , the T otal Input T okens consumption per batch declines, drop- ping from an initial 16.04 million tok ens to 14.83 million tokens in the final batches. This down- ward trend is highly significant when paired with the rising clinical metrics: it indicates that through the built-in reflection mechanism, physician agents learn to streamline their diagnostic workflo ws. By eliminating redundant inquiries and focusing on high-yield clinical data, the agents achiev e superior medical outcomes with a reduced computational footprint. 4.4 Case Studies T o provide a concrete example of this professional gro wth and the emergence of collectiv e intelli- gence, we present two distinct case studies. Figure 3 illustrates a specific patient case across the training timeline to demonstrate individual 6 Figure 5: T rend of T otal T oken Consumption across training batches. agent evolution. In Batch 1, the physician agent exhibits a scattered diagnostic approach and orders irrele v ant tests such as NAAT , AST , and Neisseria gonorrhoeae culture , which results in low Ex- amination Precision. This unfocused data gathering ultimately leads to a misdiagnosis of gonococcal pharyngitis and a subsequently ineffecti ve treat- ment plan with a low alignment score. Con- versely , by Batch 22, the same agent demon- strates highly refined clinical judgment. It bypasses redundant tests and directly orders the targeted syphilis serology , throat culture , and EBV antibody panel to achie ve high Examination Pre- cision and accurately diagnose the condition as a viral infection . Accompanying this precise di- agnosis, the agent formulates a treatment plan that sho ws a significant improv ement in clinical align- ment. This qualitative shift perfectly mirrors the quantitati ve impro vements, demonstrating ho w the high-fidelity patient environment effecti vely cat- alyzes the professional e volution of the ph ysician agents. Furthermore, analysis of the diagnostic process re veals the spontaneous emergence of sophisticated cooperati ve beha viors, highlighting the system’ s collecti ve intelligence. Figure 6 presents a com- plex scenario in v olving a patient, Amanda Peter - son, presenting with comorbidities that necessi- tate cross-departmental collaboration. Initially , the physician agent from the Department of Infectious Diseases identifies fev er and dyspnea, correctly sus- pecting infectious endocarditis. Recognizing the limits of its single-domain knowledge, the agent proacti vely initiates a consultation with the Car- diology Department for ur gent cardiac e valuation. The cardiology agent responds with targeted exam- ination recommendations—prioritizing a T ranstho- racic Echocardiogram (TTE) follo wed by a T rans- esophageal Echocardiogram (TEE)—and provides crucial clinical advice re garding subsequent treat- ment precautions. This interaction highlights the collaborati ve necessity intrinsic to OpenHospital, demonstrating ho w agents successfully inte grate di verse medical knowledge and debate treatment options to manage complex cases. Instead of re- lying on isolated reasoning, the agents iterativ ely synthesize a safe, comprehensiv e clinical pathway , v alidating the en vironment as a training ground for genuine collecti ve intelligence. Figure 6: An example of cross-departmental physician consultation. 5 Conclusion OpenHospital serves as a dedicated arena for the emergence and dev elopment of LLM-based Col- lecti ve Intelligence (CI). By enabling autonomous physician-patient interactions, the platform facili- tates the continuous professional ev olution of physi- cian agents through a data-in-agent-self paradigm. Furthermore, it establishes a dual-dimensional as- sessment frame work that ev aluates both medical proficiency and system ef ficienc y , pro viding a com- prehensi ve quantitati ve measure of CI in comple x tasks. Our findings v alidate OpenHospital’ s dual role as both a potent e volutionary training ground for agent gro wth and a rigorous benchmark for quantifying CI in multi-agent systems. Future work will focus on integrating multimodal capabilities and modeling fine-grained temporal disease pro- gression. Limitations Unimodal Constraints and Information Loss A primary limitation of the current OpenHospi- tal is its reliance on a text-only modality . While 7 textual records (e.g., chief complaints, medical his- tory , and lab reports) constitute a significant portion of Electronic Health Records (EHRs), real-world clinical diagnosis is inherently multimodal. Our work currently lacks the capability to process med- ical imaging (such as CT scans, MRIs, or X-rays) or continuous biosignals (e.g., ECG wav eforms). Consequently , this restricts the simulation’ s fidelity in specialties heavily dependent on visual data, such as radiology and dermatology . Future itera- tions will aim to integrate V ision-Language Models (VLMs) to bridge this gap. Simplified clinical abstraction Although Open- Hospital is designed to approximate realistic clini- cal workflo ws—including multi-stage consultation, testing, and collaborati v e decision-making—it re- mains an abstraction of real-world practice. In par- ticular , the benchmark does not model fine-grained temporal progression of disease, e volving symp- toms ov er time, or dynamically changing clinical conditions. As a result, while OpenHospital reflects ke y elements of diagnostic reasoning and team co- ordination, it does not fully reproduce the temporal and operational richness of real clinical care. Ethical Considerations Privacy and Use of Synthetic Data T o strictly uphold data priv acy standards, OpenHospital is con- structed entirely using synthetic data. W e ensure that all patient profiles, medical histories, and dia- logue interactions are generativ ely synthesized, de- void of an y real-world patient records or Protected Health Information (PHI). This design choice elim- inates the risk of data leakage, enabling the Open- Hospital to be openly distributed in full compli- ance with major priv acy regulations, including the Health Insurance Portability and Accountability Act (HIP AA) and the General Data Protection Reg- ulation (GDPR). Clinical Safety and Research Scope It is imper- ati ve to clarify that OpenHospital is a research en vi- ronment designed for e v olving and benchmarking multi-agent systems collectiv e intelligence, not for clinical decision support. W e ur ge future users of this arena to maintain a clear distinction between simulation results and actionable clinical guide- lines, and results obtained within the arena should not be interpreted as v alidated clinical recommen- dations. References Mohammad Almansoori, Komal Kumar , and Hisham Cholakkal. 2025. Self-ev olving multi-agent simula- tions for realistic clinical interactions. In Interna- tional Confer ence on Medical Image Computing and Computer-Assisted Intervention . Nicolas Bougie and Narimasa W atanabe. 2025. Citysim: Modeling urban behaviors and city dynamics with large-scale llm-dri ven agent simulation . Pr eprint , Ziru Chen, Shijie Chen, Y uting Ning, Qianheng Zhang, Boshi W ang, Botao Y u, Y ifei Li, Zeyi Liao, Chen W ei, Zitong Lu, V ishal De y , Mingyi Xue, Frazier N. Baker , Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Y u Su, and Huan Sun. 2025. Scienceagentbench: T o ward rigorous as- sessment of language agents for data-driv en scientific discov ery . Pr eprint , arXi v:2410.05080. DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingx- uan W ang, Bochao W u, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, and 1 oth- ers. 2024. Deepseek-v3 technical report . Pr eprint , Chengfeng Dou, Chong Liu, Fan Y ang, Fei Li, Jiyuan Jia, Mingyang Chen, Qiang Ju, Shuai W ang, Shunya Dang, Tianpeng Li, Xiangrong Zeng, Y ijie Zhou, Chenzheng Zhu, Da Pan, Fei Deng, Guangwei Ai, Guosheng Dong, Hongda Zhang, Jinyang T ai, and 14 others. 2025. Baichuan-m2: Scaling medi- cal capability with large verifier system . Pr eprint , Bofei Gao, Feifan Song, Zhe Y ang, Zefan Cai, Y ibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang T ang, Benyou W ang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Y ichang Zhang, Xuancheng Ren, T ian yu Liu, and Baobao Chang. 2024. Omni-math: A univ er- sal olympiad le vel mathematic benchmark for lar ge language models . Pr eprint , arXi v:2410.07985. T ao Ge, Xin Chan, Xiaoyang W ang, Dian Y u, Haitao Mi, and Dong Y u. 2025. Scaling synthetic data creation with 1,000,000,000 personas . Pr eprint , Alireza Ghafarollahi and Markus J. Buehler . 2024. Sci- agents: Automating scientific discovery through multi-agent intelligent graph reasoning . Preprint , Saeedeh Ghanadbashi and Fatemeh Golpayegani. 2024. Ontology-enhanced decision-making for autonomous agents in dynamic and partially observ able environ- ments . Pr eprint , arXi v:2405.17691. Pareesa Ameneh Golnari, Adarsh Kumarappan, W en W en, Xiaoyu Liu, Gabriel Ryan, Y uting Sun, Shengyu Fu, and Elsie Nallipogu. 2026. De vbench: A realistic, dev eloper-informed benchmark for code generation models . Pr eprint , arXi v:2601.11895. 8 Juraj Gottweis, W ei-Hung W eng, Alexander Daryin, T ao T u, Anil Palepu, Petar Sirkovic, Artiom Myaskovs ky , Felix W eissenberger , Keran Rong, Ryu- taro T anno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, A vinatan Hassidim, Bu- rak Gokturk, Amin V ahdat, Pushmeet Kohli, and 15 others. 2025. T ow ards an ai co-scientist . Pr eprint , Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Y uheng Cheng, Jinlin W ang, Ceyao Zhang, Zili W ang, Ste v en Ka Shing Y au, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin W u, and Jürgen Schmidhuber . 2024. MetaGPT: Meta pro- gramming for a multi-agent collaborative frame work . In International Confer ence on Learning Representa- tions . Fantine Huot, Reinald Kim Amplayo, Jennimaria P alo- maki, Alice Shoshana Jakobovits, Elizabeth Clark, and Mirella Lapata. 2025. Agents’ room: Nar- rativ e generation through multi-step collaboration . Pr eprint , arXi v:2410.02603. Carlos E. Jimenez, John Y ang, Ale xander W ettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language mod- els resolve real-world github issues? Pr eprint , Immanuel Kant. 1781. Critique of Pure Reason . Johann Friedrich Hartknoch, Riga, Russian Empire. Junkai Li, Y unghwei Lai, W eitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu W ang, Peng Li, Y a-Qin Zhang, W eizhi Ma, and Y ang Liu. 2025. Agent hospi- tal: A simulacrum of hospital with e volvable medical agents . Pr eprint , arXi v:2405.02957. Nian Li, Chen Gao, Mingyu Li, Y ong Li, and Qing- min Liao. 2024. Econagent: Large language model- empowered agents for simulating macroeconomic activities . Preprint , arXi v:2310.10436. Jianhao Lin, Lexuan Sun, and Y ixin Y an. 2025. Simu- lating macroeconomic expectations using llm agents . Pr eprint , arXi v:2505.17648. Zhao Mandi, Shreeya Jain, and Shuran Song. 2023. Roco: Dialectic multi-robot collaboration with large language models . Pr eprint , arXi v:2307.04738. Y uren Mao, Peigen Liu, Xinjian W ang, Rui Ding, Jing Miao, Hui Zou, Mingjie Qi, W anxiang Luo, Longbin Lai, Kai W ang, Zhengping Qian, Peilun Y ang, Y un- jun Gao, and Y ing Zhang. 2025. Agent-kernel: A microkernel multi-agent system frame work for adap- tiv e social simulation powered by llms . Preprint , OpenAI. 2025. Gpt-5.2: Advancing reasoning and tool-using large language models. https://openai. com/index/introducing- gpt- 5- 2/ . Accessed 2026. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generativ e agents: Interac- tiv e simulacra of human behavior . Pr eprint , Jinghua Piao, Y uwei Y an, Jun Zhang, Nian Li, Junbo Y an, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Y i W ang, Di Zhou, Chen Gao, Fengli Xu, Fang Zhang, Ke Rong, Jun Su, and Y ong Li. 2025. Agentsociety: Large-scale simulation of llm-dri ven generativ e agents advances understanding of human behaviors and society . Pr eprint , Chen Qian, W ei Liu, Hongzhang Liu, Nuo Chen, Y ufan Dang, Jiahao Li, Cheng Y ang, W eize Chen, Y usheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023. Chatde v: Communica- tiv e agents for software dev elopment . Preprint , Jun Sashihara, Y ukihisa Fujita, Kota Nakamura, Masahiro Kuwahara, and T eruaki Hayashi. 2025. Llm-based multi-agent system for simulating strate- gic and goal-oriented data marketplaces . Preprint , Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffre y Jopling, and Michael Moor . 2025. Agentclinic: a multimodal agent benchmark to ev alu- ate ai in simulated clinical en vironments . Pr eprint , Haoyang Su, Renqi Chen, Shixiang T ang, Zhenfei Y in, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi W u, Hui Li, W anli Ouyang, Philip T orr , Bowen Zhou, and Nan- qing Dong. 2025. Many heads are better than one: Improv ed scientific idea generation by a llm-based multi-agent system . Pr eprint , arXi v:2410.09403. Qingyun W u, Gagan Bansal, Jieyu Zhang, Y iran W u, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan A wadallah, Ryen W White, Doug Burger , and Chi W ang. 2023. Autogen: Enabling next-gen llm ap- plications via multi-agent con versation . Preprint , An Y ang, Baosong Y ang, Binyuan Hui, Bo Zheng, Bowen Zhou, and 1 others. 2025. Qwen3 techni- cal report . Pr eprint , arXi v:2505.09388. Bangguo Y u, Qihao Y uan, Kailai Li, Hamidreza Kasaei, and Ming Cao. 2025a. Co-navgpt: Multi-robot coop- erativ e visual semantic navigation using vision lan- guage models . Pr eprint , arXi v:2310.07937. T ian Y u, Ken Shi, Zixin Zhao, and Gerald Penn. 2025b. Multi-agent based character simulation for story writ- ing . In Pr oceedings of the F ourth W orkshop on Intel- ligent and Interactive Writing Assistants (In2Writing 2025) , pages 87–108, Albuquerque, Ne w Mexico, US. Association for Computational Linguistics. Zheyuan Zhang, Daniel Zhang-Li, Jifan Y u, Linlu Gong, Jinchang Zhou, Zhanxin Hao, Jianxiao Jiang, Jie Cao, 9 Huiqin Liu, Zhiyuan Liu, Lei Hou, and Juanzi Li. 2025. Simulating classroom education with LLM- empowered agents . In Pr oceedings of the 2025 Con- fer ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T ec hnologies (V olume 1: Long P apers) , pages 10364–10379, Albuquerque, Ne w Mexico. As- sociation for Computational Linguistics. Xuhui Zhou, Hao Zhu, Leena Mathur , Ruohong Zhang, Haofei Y u, Zhengyang Qi, Louis-Philippe Morency , Y onatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. 2024. Sotopia: Interactiv e e v aluation for social intelligence in language agents . Pr eprint , Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Y ang, Shuyi Guo, Zhe W ang, Zhenhailong W ang, Cheng Qian, Xiangru T ang, Heng Ji, and Jiaxuan Y ou. 2025. Multiagentbench: Evaluating the col- laboration and competition of llm agents . Pr eprint , 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment