현대 최적화 이론으로 밝히는 하이퍼파라미터 스케일링 법칙
본 논문은 Linear Minimization Oracle(LMO) 프레임워크에 기반한 최신 1차 최적화 알고리즘(정규화 SGD, signSGD, Muon 등)의 수렴 상한을 활용해 학습률, 모멘텀, 배치 크기의 전력법칙을 이론적으로 도출한다. 모델 크기를 고정한 상태에서 토큰(또는 연산) 예산에 따라 최적의 하이퍼파라미터 스케일링을 구하고, 기존 경험적 규칙과 일치함을 보이며 특히 모멘텀과 배치 크기의 상호작용이 중요한 역할을 함을 강조한다.
저자: Egor Shulgin, Dimitri von Rütte, Tianyue H. Zhang
본 연구는 대규모 딥러닝 훈련에서 하이퍼파라미터 전이와 스케일링이 차지하는 중요성을 강조하며, 기존 µP와 같은 모델‑크기 전이 방법이 배치 크기·학습 단계·모멘텀에 대한 이론적 근거가 부족함을 지적한다. 이를 보완하고자 저자들은 Linear Minimization Oracle(LMO) 프레임워크를 채택한다. LMO는 정규화된 SGD, signSGD(Adam 근사), Muon(스펙트럼 정규화) 등 현대 최적화 기법을 포괄한다. 핵심 아이디어는 최신 수렴 상한을 “위험(risk)”이라는 프록시 함수로 해석하고, 이 함수를 하이퍼파라미터(η, α, b)와 토큰 예산 T에 대해 최소화함으로써 최적 스케일링을 도출하는 것이다.
먼저, LMO 기반 알고리즘에 대한 일반적인 상한식(Equation 2)을 제시한다. 여기에는 초기 손실 차이 Δ₀, 변동성 σ²/b, Lipschitz 상수 L, 그리고 노름 동등 상수 ρ가 포함된다. 이를 C₁, C₂, C₃이라는 상수로 정리하고, η, α, b, K(또는 T=bK)를 변수로 하는 위험 함수 risk_K와 risk_T를 정의한다. 이후 세 가지 튜닝 시나리오를 차례로 분석한다.
1. **고정 모멘텀, 대규모 horizon**
α를 고정하고 K가 충분히 클 때, 위험 함수는 deterministic term C₁/(ηK)와 변동성 term C₂/√b, 그리고 η에 비례하는 smoothness term C₃η 로 근사된다. 미분을 통해 η* ∝ K⁻¹ᐟ², b*는 K에 독립적이며, 토큰 예산 T 고정 시 η* ∝ b¹ᐟ² T⁻¹ᐟ², b* ∝ T¹ᐟ²가 도출된다. 위험은 T⁻¹ᐟ⁴로 감소한다. 이는 기존 “√b 학습률 스케일링”과 “배치‑스텝 트레이드오프”를 이론적으로 재현한다.
2. **고정 배치, 모멘텀 튜닝**
배치 b를 고정하고 α를 자유롭게 하면 위험 함수는 η와 α에 대해 η* ∝ b¹ᐟ² α¹ᐟ² T⁻¹ᐟ², α* ∝ b·T⁻¹ᐟ² 로 최적화된다. 즉, 배치가 제한된 상황에서도 모멘텀을 감소시키면 변동성 감소 효과를 보완할 수 있다. 이는 “시간 스케일 보존” 논의와 일치한다.
3. **전부 공동 튜닝**
η, α, b를 동시에 최적화하면 복잡한 비선형 시스템을 풀어야 하지만, 대규모 T에 대한 asymptotic 해는 b* ∝ T¹ᐟ⁶, η* ∝ T⁻⁷ᐟ¹², α* ∝ T⁻¹ᐟ³ 로 수렴한다. 위험은 여전히 T⁻¹ᐟ⁴ 수준이다. 흥미롭게도 b* ∝ T¹ᐟ²와 같은 더 급격한 성장도 위험을 동일하게 유지한다는 점에서 여러 “near‑optimal” 스케일링 경로가 존재한다. 다만 ϕ>½ (b ∝ T^{ϕ})인 경우 위험 감소율이 T⁻¹ᐟ⁴보다 느려진다.
논문은 이러한 결과를 기존 SGD와 비교한다. 전통적인 SGD 경계는 변동성 항과 최적화 항이 정확히 상쇄돼 배치 크기가 위험에 거의 영향을 주지 않는다. 반면 LMO 기반 방법은 모멘텀·정규화 효과가 추가 변동성 감소 항을 만들며, 실제 “최적 배치 크기”가 존재한다는 점이 핵심 차이이다.
**실험 검증**
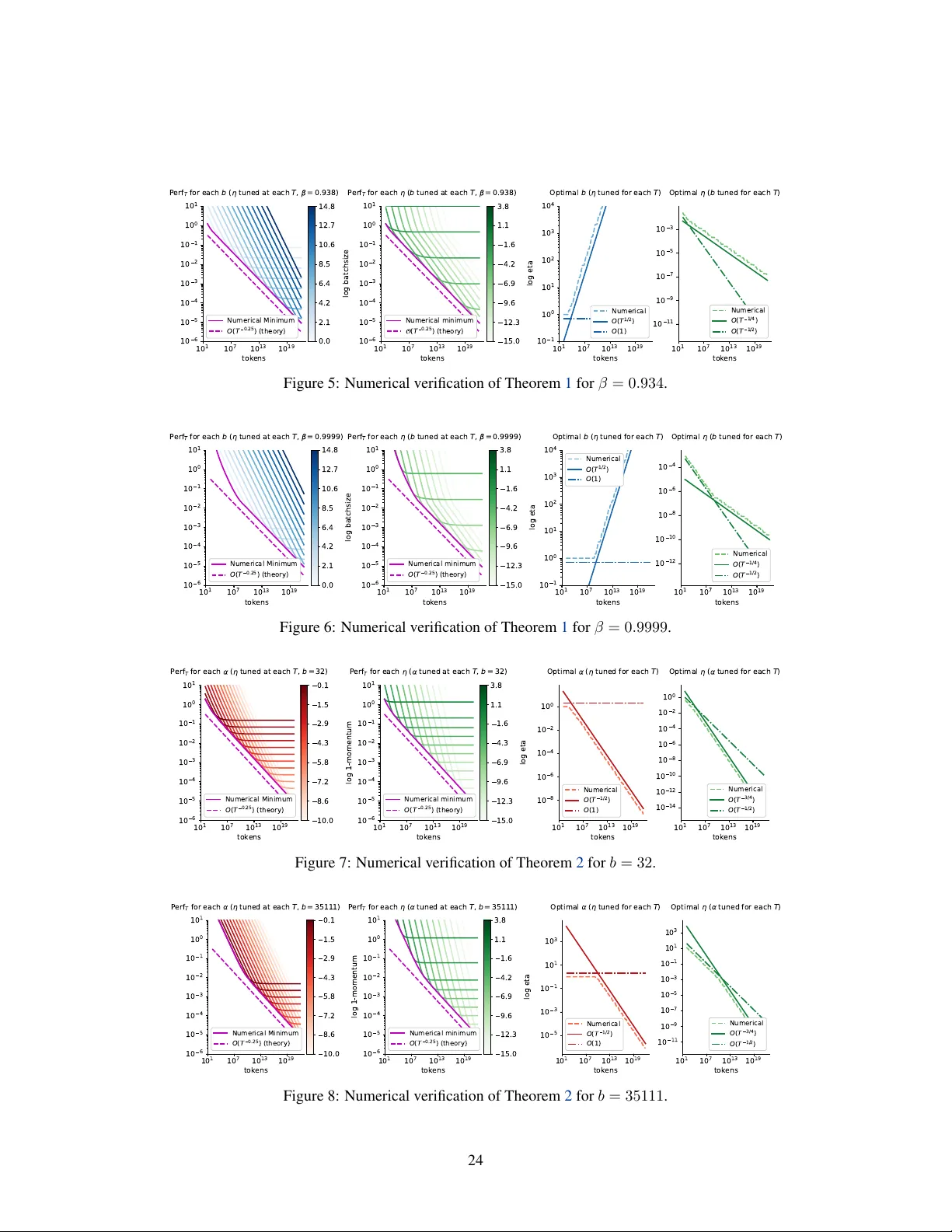
본문 Figure 1·2와 부록 D에서 위험 함수의 최소화 결과를 수치적으로 검증한다. 토큰 예산이 커질수록 η* ∝ T⁻¹ᐟ⁴, b* ∝ T¹ᐟ²(또는 T¹ᐟ⁶) 경향이 관찰되며, 고정 모멘텀 상황에서도 위험 감소가 이론과 일치한다. 추가 실험(Figure 3)에서는 실제 LLM 훈련에 적용했을 때도 비슷한 스케일링이 성능 향상으로 이어짐을 보여준다.
**실용적 시사점**
- 대부분의 파이프라인에서 모멘텀은 0.9~0.99로 고정되므로, 고정 모멘텀 스케일링(η ∝ √b T⁻¹ᐟ²)만 적용해도 충분히 좋은 결과를 얻을 수 있다.
- 배치 크기가 하드웨어 제한에 부딪히는 경우, 모멘텀을 T⁻¹ᐟ³ 정도로 감소시키면 위험을 유지할 수 있다.
- 학습률 스케줄링, 웜업, 가중치 감쇠 등을 포함하면 상수 계수가 변하지만, 지수(−1/4)와 같은 근본적인 스케일링 형태는 유지된다.
**결론**
논문은 “상한 최소화”라는 간단하지만 강력한 방법론을 통해 현대 최적화 알고리즘의 하이퍼파라미터 스케일링을 일관된 이론적 틀 안에 통합한다. 이는 기존 경험적 규칙을 정당화하고, 새로운 설계 공간(특히 모멘텀‑배치 상호작용) 탐색을 가능하게 한다. 향후 연구는 초기화, 변동성 가정, 가중치 감쇠, 학습률 스케줄링 등을 포함한 보다 현실적인 설정으로 확장하는 것이 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기