Deriving Hyperparameter Scaling Laws via Modern Optimization Theory
Hyperparameter transfer has become an important component of modern large-scale training recipes. Existing methods, such as muP, primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on …
Authors: Egor Shulgin, Dimitri von Rütte, Tianyue H. Zhang
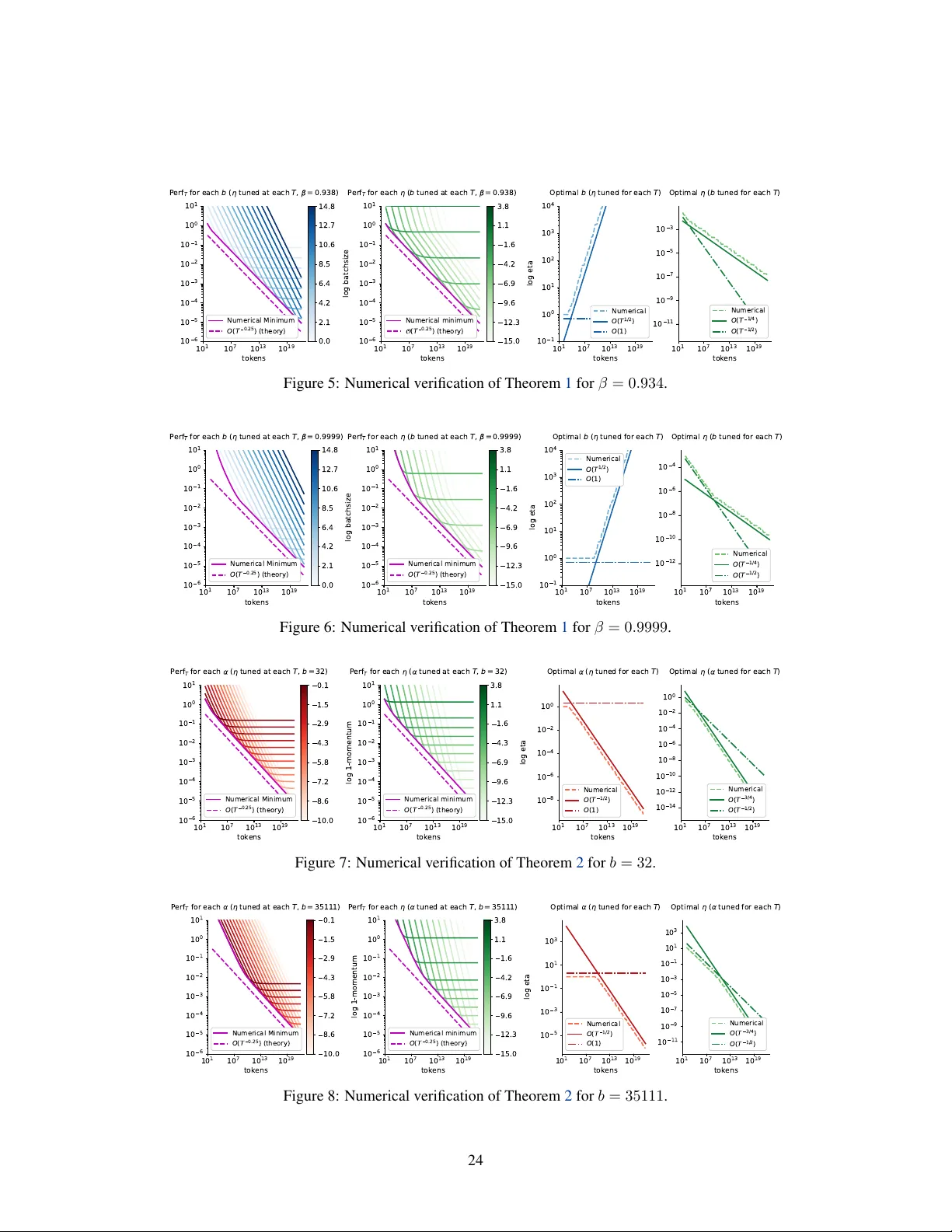
Deriving Hyper parameter Scaling Laws via Moder n Optimization Theory Egor Shulgin † Dimitri von Rütte ‡ Tianyue H. Zhang ¶ ,§ Niccolò Ajroldi § Bernhard Schölk opf §, ‡ Antonio Orvieto § Abstract Hyperparameter transfer has become an important component of modern large- scale training recipes. Existing methods, such as µ P , primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on empirical scaling rules informed by insights from timescale preservation, quadratic proxies, and continuous-time approximations. W e study hyperparameter scaling laws for modern first-order optimizers through the lens of recent conv er- gence bounds for methods based on the Linear Minimization Oracle (LMO), a framew ork that includes normalized SGD, signSGD (approximating Adam), and Muon. Treating bounds in recent literature as a proxy and minimizing them across different tuning re gimes yields closed-form power -law schedules for learning rate, momentum, and batch size as functions of the iteration or token budget. Our analysis, holding model size fixed, reco vers most insights and observations from the literature under a unified and principled perspective, with clear directions open for future research. Our results draw particular attention to the interaction between momentum and batch-size scaling, suggesting that optimal performance may be achiev ed with se veral scaling strate gies. 1 Introduction Scaling has become crucial in modern deep learning, with state-of-the-art performance often dri ven by massi ve compute: Large language models (LLMs) have reached training budgets of 5 × 10 26 FLOPs, with a projected gro wth of 5 × per year [ 16 ]. Given the substantial cost, accurately predicting model performance befor e training begins is of critical importance. Historically , scaling la ws based on empirical observations ha ve been relied upon to predict the final performance for a gi ven model and dataset size, as well as optimality trends in ke y hyperparameters, such as batch size and learning rate [ 28 , 23 , 8 , 24 , 32 ]. Still, training at scale is often more art than science, and many recommendations remain poorly understood or mutually contradictory . Giv en the high cost and practical limitations of deriving empirical scaling rules, hyperparameter transfer informed by theory has become a research area of keen interest, with the most prominent method, µ P [ 51 ], enabling learning rate transfer across model sizes. Ho wev er , these results typically r equir e a fixed batch size, momentum, and training horizon , leading practitioners to revert to em- pirical scaling rules, often guided by quadratic analyses [ 36 ], stochastic dif ferential equation (SDE) approximations [ 34 , 14 ], timescale preservation ar guments [ 35 , 4 ], or norm-based vie ws [ 18 ]. In this theoretical study , inspired by recent empirical work on optimal hyperparameter scaling as the token b udget increases [ 44 , 52 , 37 , 38 ], we reexamine scaling laws using performance bounds from § OpenEuroLLM team at ELLIS Institute Tübingen, MPI-IS, Tübingen AI Center , Tübingen, Germany † King Abdullah Univ ersity of Science and T echnology (KA UST), Thuwal, Saudi Arabia ‡ ETH Zürich, Zürich, Switzerland ¶ Mila, Quebec AI Institute & Univ ersité de Montréal, Quebec, Canada Pr eprint based on a short version published as a confer ence paper at SciF orDL W orkshop, 2nd edition. optimization theory , le veraging recent adv ances that e xtend beyond con vex settings and Euclidean geometry [ 31 ]. Compared to Schaipp et al. [ 42 ] , Bu et al. [ 11 ] , who demonstrate surprising agreement between SGD performance on conv ex problems and LLM training, our LMO framework aligns theory more closely with modern optimization practice, employing Adam [ 30 ] and Muon [ 27 ]. W e study ho w learning rate, batch size, and momentum determine the best achie v able performance across training horizons and compute budgets at a fixed model scale. Our analysis yields explicit scaling predictions for key h yperparameters across training horizons, which have pre viously been observed only empirically or were not moti v ated by a unified, theoretically principled setup. W e note that our methodology might not surprise readers expert in optimization theory , since the idea of minimizing upper bounds with respect to hyperparameters is a crucial step in both conv ex and noncon ve x optimization [ 20 ] and was recently adopted, for instance, to bring about insights into optimal batch sizes for Muon [ 41 ]. Our purpose is to make this methodology accessible to the general public, bring it to its full potential, and study in detail which scaling aspects it can predict. (i) W ith fix ed momentum, we recov er the well-kno wn square-root learning rate scaling with batch size [ 34 , 14 ], as well as the learning rate dependency on the token budget suggested by [ 38 ] and the classical hyperbolic relations between batch size and step count observ ed empirically [ 50 ] and motiv ated by [ 36 ]. Further , in agreement with empirical literature [ 8 , 4 , 50 ], we identify a non-trivial token-optimal batch size scaling [ 4 ], requiring joint learning rate tuning [ 18 ]. Interestingly , our analysis shows that the optimal batch size exceeds 1 only after a momentum-dependent critical token budget is reached. This is in direct contrast to SGD, where performing the same analysis does not yield a nontrivial tok en-optimal batch size. (ii) W e perform the same analysis under a fixed batch size, showing how optimal rates can be recov ered by tuning momentum and learning rate, in agreement with optimization literature [ 15 , 45 ]. Our predictions match those derived from timescale preserv ation arguments [ 35 ] and theoretical insights around speed-matching flows in the SDE literature [ 14 ]. (iii) When tuning all quantities jointly (momentum, learning rate, batch size), man y scaling options become near-optimal, as also suggested by [ 7 ]. W e identify and discuss such scalings. Compared to some e xisting empirical works [ 8 , 50 , 4 ], we find that optimal scaling always implies learning rates that are decreasing as a function of the token budget. Howe ver , we show that specific batch size scaling rules indeed lead to an increasing optimal learning rate as the token b udget grows. On the practical side, our results provide insights along the promising direction of momentum scaling, explored in the contemporary literature [ 35 , 17 ]. On the theoretical side, our work (especially point (iii) abov e) opens up se veral directions for research on scaling theory under modified initialization and gradient noise assumptions (App. C ). More directly , revised rates and insights can be deri ved by incorporating weight decay , learning-rate scheduling, and warmup into our analysis. A note on statistical generalization. Our analysis assumes access to an unbiased stochastic gradient oracle for the population objecti ve. This remo ves finite-sample ef fects by construction, and hence, our results do not cover statistical generalization. In the scaling-law literature for LLMs, this distinction is often not emphasized, reflecting the empirical observ ation that, for small-epoch training, improv ements in optimization efficienc y are strongly correlated with do wnstream performance [ 2 ]. 2 Preliminaries Consider the optimization problem min x ∈ R d f ( x ) , where we assume access to mini-batch estimates g of the gradient ∇ f ( · ) [ 10 ], with f potentially being non-conv ex. Optimizers. Let b ∈ N > 0 be the batch size. W e denote by g b the stochastic gradient of loss f . Fix the stepsize (learning rate) η > 0 and momentum parameter β := 1 − α ∈ [0 , 1) . Following [ 40 ], consider a norm ∥ · ∥ , and the Linear Minimization Oracle (LMO) 1 method 2 : m k +1 = (1 − α ) m k + α g k b , x k +1 = x k + η arg min ∥ d ∥≤ 1 ⟨ m k +1 , d ⟩ . (1) Choosing ∥ · ∥ recov ers: (i) Euclidean ∥ · ∥ = ∥ · ∥ 2 : normalized SGD with momentum; (ii) ∥ · ∥ = ∥ · ∥ ∞ : signSGD with momentum [ 6 ]; (iii) spectral norm: Muon (orthogonalized update) [ 12 , 5 , 27 ]. 1 W ith a slight abuse of notation for arg min denoting any element from the set. 2 Also known as Unconstrained Stochastic Conditional Gradient method [ 19 , 21 , 13 , 25 , 40 ] 2 SignSGD can be easily linked to Adam [ 30 ], both theoretically [ 3 , 5 ] and performance-wise [ 54 , 39 ]. Many works (e.g. µ P deri vations; 51 ) directly deri ve results using this approximation. Con ver gence bounds. Consider a fixed momentum β = 1 − α , batch size b and step size η , and run the algorithm for K iterations. W e assume that (1) the gradient noise variance E ∥ g b − ∇ f ∥ 2 2 is upper bounded by a constant σ 2 /b , (2) the loss f has L -Lipschitz gradients, with respect to the general ∥ · ∥ norm, (3) f is lower bounded by f inf and ∆ 0 = f ( x 0 ) − f inf . Let ∥ · ∥ be an y norm, with dual norm ∥ · ∥ ⋆ , K ovale v [ 31 , Theorem 2 ] prov es that under LMO method (equation 1 ), min 1 ≤ k ≤ K E ∥∇ f ( x k ) ∥ ⋆ ≤ ∆ 0 η K + 2 ρσ α √ bK + 2 ρσ r α b + 7 Lη 2 + 2 Lη α , (2) where ρ ≥ 1 is a norm equiv alence constant (defined from ∥ v ∥ ⋆ ≤ ρ ∥ v ∥ 2 which alw ays holds in finite dimensional spaces), dependent on the chosen norm. The right-hand-side contains: (i) a purely deterministic optimization term ∆ 0 / ( η K ) ; (ii) momentum “b urn-in” / a veraging term 2 ρσ / ( α √ bK ) ; (iii) a noise floor term 2 ρσ p α b ; (iv) smoothness/trust-re gion error terms proportional to η , including an η /α coupling. For the star-con vex case [ 31 ], the gradient norm can be lo wer bounded with functional suboptimality f ( x k ) − f ( x ⋆ ) connecting equation 2 to the loss. W e focus on the LMO/normalized-gradient frame work for two reasons. First, it captures a family of norm-based optimizers directly relev ant to modern practice, ranging from sign-based approximations of Adam to Muon/Scion-style operator-norm updates [ 5 , 27 , 40 , 18 ]. Second, in this frame work momentum plays a provably nontri vial role in non-con ve x stochastic optimization: stochastic normal- ized updates can require a minimal mini-batch size to con verge [ 22 ], whereas adding momentum can remov e this requirement [ 15 ]. By contrast, for v anilla SGD, momentum is not known to improv e the order of worst-case con vergence rates be yond constants [ 33 ]. 3 Derivation of Scaling Laws W e study ho w the bound from equation 2 scales with step size η , momentum 1 − α , batch size b , step count K , and token b udget T : = bK . T o keep expressions compact, define C 1 : = ∆ 0 , C 2 : = 2 ρσ, C 3 : = 4 L. Also note that 7 L 2 η + 2 L α η ≲ C 3 η 1 + 1 α , up to constant factors. Proxy objecti ve. Define the following proxy (the right-hand-side of equation 2 up to constants): risk K ( η , α, b ) : = C 1 1 η K + C 2 √ b · 1+ α 3 / 2 K αK + C 3 η 1 + 1 α , (3) risk T ( η , α, b ) : = risk K b ( η , α, b ) = C 1 b η T + C 2 √ b · b + α 3 / 2 T αT + C 3 η 1 + 1 α . (4) 3.1 Optimization of the Proxy Objecti ve W e first consider a fixed momentum , independent of ( b, η , K ) . In the lar ge-horizon regime α 3 / 2 K ≫ 1 , the burn-in part of the teal term in equation 3 is dominated, and we can use a simplified proxy: risk K ( η , b ) ≈ C 1 1 η K + ˜ C 2 1 √ b + ˜ C 3 η , risk T ( η , b ) ≈ C 1 b η T + ˜ C 2 1 √ b + ˜ C 3 η , (5) where ˜ C 2 : = C 2 √ α and ˜ C 3 : = C 3 1 + 1 α . W e have the follo wing result, proved in Appendix B.1 . Theorem 1 (Fixed momentum, lar ge-horizon proxy) F ix α ∈ (0 , 1] and consider equation 5 . 1. (Iteration scaling .) F or fixed ( K, b ) , with K lar ge, the pr oxy is minimized by η ⋆ K ( b ) ∝ K − 1 / 2 , risk ⋆ K ( b ) ∝ K − 1 / 2 + b − 1 / 2 . (6) Thus at fixed K (ignoring token cost), the optimal learning rate is batch size independent, and incr easing b impr oves the bound. 3 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h b ( t u n e d a t e a c h T , = 0 . 9 9 9 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( b t u n e d a t e a c h T , = 0 . 9 9 9 ) Numerical minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 O p t i m a l b ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 2 1 0 1 0 1 0 8 1 0 6 1 0 4 O p t i m a l ( b t u n e d f o r e a c h T ) Numerical O ( T 1 / 4 ) O ( T 1 / 2 ) 0.0 2.1 4.2 6.4 8.5 10.6 12.7 14.8 log batchsize 15.0 12.3 9.6 6.9 4.2 1.6 1.1 3.8 log eta Figure 1: V erification of Theorem 1 . Sho wn are the trends of equation 4 ( C 1 = C 2 = C 3 = 1 ) under the choice β = 1 − α = 0 . 999 . More α s can be found in App. D . In the two plots on the left, we show in magenta performance at the best value of ( η , b ) for each tok en budget, following O ( T − 1 / 4 ) . Plotted in blue are also performances for a fixed batch size, minimizing o ver η at each token b udget, and in green performances for a fixed learning rate, minimizing b at each token b udget. In the two plots on the right, we sho w ho w the optimal batch size and learning rate scale with tok ens. The trends predicted by Theorem 1 hold after a b urn-in phase, where the optimal batch size is b = 1 . 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 1 0 7 2 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 1 0 7 2 ) Numerical minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 7 1 0 5 1 0 3 1 0 1 1 0 1 1 0 3 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 3 1 0 1 1 1 0 9 1 0 7 1 0 5 1 0 3 1 0 1 1 0 1 1 0 3 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 3 / 4 ) O ( T 1 / 2 ) 10.0 8.6 7.2 5.8 4.3 2.9 1.5 0.1 log 1-momentum 15.0 12.3 9.6 6.9 4.2 1.6 1.1 3.8 log eta Figure 2: Numerical verification of Theorem 2 for b = 1072 . The setting is same as for Figure 1 . 2. (T oken-budget scaling .) F or fixed larg e T , at a fixed batch size b , the optimal learning rate scales as η ⋆ T ( b ) ∝ b 1 / 2 T − 1 / 2 . Moreo ver , the joint minimizer ( η ⋆ T , b ⋆ T ) satisfies b ⋆ T ∝ T 1 / 2 , η ⋆ T ( b ⋆ T ) ∝ ( b ⋆ T ) 1 / 2 T − 1 / 2 ∝ T − 1 / 4 , risk ⋆ T ∝ T − 1 / 4 . (7) In particular , under a fixed token b udget we find a non-trivial token-optimal batc h size. Comparison with SGD. In contrast to LMO-based optimizers, v anilla SGD does not exhibit a non- tri vial token-optimal batch size. Under a fixed token budget T = bK , the classical bounds balance the optimization and v ariance terms so that, after tuning, the resulting performance depends only on T and becomes independent of b . Consequently , batch size mainly trades off v ariance reduction against the number of steps, unlike LMO methods, where additional momentum- and normalization-induced terms break this cancellation and induce a genuine optimal batch-size scaling. Note that equation 6 sho ws that for fixed batc h size b , optimization can saturate. As shown in equa- tion 7 , one can scale b with T to fix this issue. Howe ver , there is another option: as discussed in Cutkosky & Mehta [ 15 ] and Shulgin et al. [ 45 ] – scaling momentum has a similar ef fect. Theorem 2 (Fixed batch size, lar ge horizon proxy) At a fixed batch size b and momentum β = 1 − α , the optimal learning rate scales with T as η ⋆ T ( b, α ) ∝ b 1 / 2 α 1 / 2 T − 1 / 2 . A subsequent minimization w .r .t. α (at a fixed T and b ) then leads to α ⋆ T ( b ) ∝ b · T − 1 / 2 , η ⋆ T ( b ) = η ⋆ T ( b, α ⋆ T ( b )) ∝ b · T − 3 / 4 , risk ⋆ T ∝ T − 1 / 4 . (8) The proof can be found in Appendix B.2 . Our last result considers tuning learning rate, momentum and batch size jointly at a gi ven token budget. The proof, to be found in Appendix B.3 , is substantially more in v olved, since teal term in equation 3 cannot be dropped. 4 Theorem 3 (J ointly tuned ( η , α, b ) under a fixed token budget) F or lar ge T , minimizing equa- tion 4 over η > 0 , α ∈ (0 , 1] , and b ≥ 1 yields the asymptotic scalings b ⋆ T ∝ T 1 / 6 , η ⋆ T ∝ T − 7 / 12 , α ⋆ T ∝ T − 1 / 3 , risk ⋆ T ∝ T − 1 / 4 . (9) Mor eover , these sc hedules ar e consistent with equation 8 after plugging in b = b ⋆ T . The exponent 1/6 should be read as the batch-growth law selected by lower -order terms of the proxy; at leading order, se veral batch-growth paths can remain asymptotically equi valent once ( α, η ) are re-tuned. 3.2 Optimal asymptotics While Theorem 3 giv es the asymptotic minimizer of the exact proxy risk T , all three tuning regimes attain the same risk ⋆ T ∝ T − 1 / 4 rate. The practical question is therefore whether follo wing Theorem 3 materially improv es ov er simpler scaling rules. The answer is negati v e. W e begin with a corollary sho wn in Appendix B.4 . Corollary 1 (Momentum tuning and Batch size constraints) As the token b udget T → ∞ , we have the following pr operties following dir ectly from the pr oofs of Theor ems 1 and 2 . 1. Assume optimal tuning of batch size and learning rate for a fixed arbitrary momentum β = 1 − α . W e have that risk ⋆ T ( α ) ∝ (1 + α ) 1 / 4 T − 1 / 4 . Hence, re-tuning α can only lead to a 2 1 / 4 ≈ 1 . 19 impr ovement in the rate constant. 2. If instead the batch size is capped by har dwar e, b ≤ b max , then optimal tuning of the learning rate at an arbitrary momentum β = 1 − α leads to risk T ∝ α 1 / 2 b − 1 / 2 max – a non-vanishing noise floor . Allowing α to decrease with T (Theor em 2 ) remo ves this floor and r estor es risk ⋆ T ∝ T − 1 / 4 even at fixed batc h size. The corollary shows that if batch-size gro wth is non-problematic, then tuning momentum af fects the rate only marginally . Instead, if there is a limit on the maximum batch size, tuning momentum with the token b udget becomes necessary to achiev e optimality . Next, since both scaling b like T 1 / 6 and T 1 / 2 lead to optimal asymptotics (up to a constant < 1 . 2 ), it is natural to ask whether other batch-size scaling laws can still achieve the optimal rate . The answer is positiv e, with the ca veat that some choices may lead to extremely fast (and likely numerically unstable) scaling of momentum or learning rates. The next result is shown in Appendix B.5 . Corollary 2 (Se veral batch size scalings ar e near -optimal) F or lar ge T , consider minimizing equation 4 under the choice b ( T ) = T ϕ . If ϕ ≤ 1 / 2 , then the choice α ∗ T ( b ) ∝ b ( T ) T − 1 / 2 , η ( T ) ∝ b ( T ) T − 3 / 4 pr oposed in Theor em 2 leads to a rate T − 1 / 4 . If instead ϕ ∈ (1 / 2 , 1) , then the maximum achie vable rate is risk T ∝ b ( T ) 1 / 2 T − 1 / 2 , slower than T − 1 / 4 . Finally , we ask: Why is that minimization of risk T in Theorem 3 predicts such a specific scaling? What is special about it? The answer relies on the particular nature of equation 4 , comprising terms ev olving at dif ferent speeds e ven after optimal tuning: the suboptimality landscape with respect to the variable b , once learning rate and momentum are tuned, is flat, as sho wn in Appendix C.2 . Numerical verification. W e v erify our deri vations numerically 3 in App. D and Figures 1 , 2 in the main te xt. While the scope of this paper is to introduce a new theoretical tool and demonstrate alignment with the literature, we directly verify some of our findings empirically in Figure 3 . 4 Discussion and Connections with the Literature Among our analyses, fixed momentum is the most practically relev ant, as momentum is usually set to a standard value and rarely tuned in modern training pipelines [ 23 , 9 , 44 ], though such practice is 3 W e compute risk T ( C 1 = C 2 = C 3 = 1 ) for η ∈ (10 − 15 , 10 4 ) , b ∈ (1 , 10 15 ) , α ∈ (10 − 10 , 1) , T ∈ (10 2 , 10 22 ) . These are sampled log-uniformly: 100 values are pick ed in the ranges above. 5 Note: higher s ! always diverge η Figure 3: Qualitative empirical support for our analysis. W e perform a constant- η training experiment on a 160 M transformer (PlainLM implementation [ 1 ]), trained with a language modeling objectiv e for up to 5 B tokens from SlimP ajama [ 48 ]. The setup is the same as in Theorem 1 and Figure 1 . With 8% warmup + constant learning rate (Adam betas fixed to (0 . 9 , 0 . 95) ), grid-searching η across batch sizes shows clear structure: (i) at fixed batch size, the optimal η decreases ov er training time (e.g., b = 32 shifts from 0 . 003 to 0 . 001 after 2 . 5 B tokens); (ii) this trend appears similarly for b = 128 , albeit the switching point is not yet reached at 5 B tokens; and (iii) the optimal η increases with batch size (at T = 5 B tokens, η = 0 . 001 at b = 32 , η = 0 . 003 at b = 128 , η = 0 . 01 at b = 512 ). Constant η allows clean finite-time comparisons that re veal both tok en-dependent and batch-dependent optimal η s. slowly changing [ 52 , 38 , 35 ]. On the other hand, batch size is often chosen for hardw are efficienc y and throughput rather than optimization performance. In these settings, our fixed-batch-size scaling laws can pro vide the appropriate theoretical description of achiev able performance (see App. A ). Scaling learning rate with batch size and token transfer at a fixed batch size. Malladi et al. [ 34 ] and Compagnoni et al. [ 14 ] provide theoretical e vidence for the well-known square root scaling law: for adaptiv e methods, at a fixed token budget, scaling b 7→ κb requires η 7→ κ 1 / 2 η . Re- cently , Mlodozeniec et al. [ 38 ] verified this law at scale, and also noted that (at a fix ed batch size) the compute-budget (tok en-horizon) transfer requires scaling the learning rate down as η 7→ η κ − 1 / 2 when the number of training tokens is increased by a factor κ . The same law is discussed by [ 11 ] in the conte xt of con vex problems trained with SGD. W e note that both these tr ends ar e pr edicted by our Theor em 1 : at a giv en token b udget T , the optimal learning rate scales as b 1 / 2 T − 1 / 2 . Further, note that our work dif fers from [ 34 , 14 ] in a crucial way: these works deri ve these scalings by matching statistical properties of the iterates distrib utions (i.e., discard the blue in equation 4 ), b uilding up on the intuition around sharp minima, generalization, and critical batch size [ 29 , 26 , 43 , 47 ]. Our comparisons, though recov ering their scalings as a special case, concern the expected gradient-norm “performance” (which can be connected to the loss) and capture a finite training horizon. Optimal batch size scaling with token budget. Empirically , with fixed momentum, the optimal batch size scaling is found to be anywhere between T 0 . 3271 and T 0 . 8225 (T able 1 , first column), which is reasonably 4 consistent with our result T 1 / 2 . Sev eral works instead discuss the notion of critical batch size: the thr eshold at which further incr easing batch size no longer gives near -linear speedup in optimization steps . Zhang et al. [ 52 ] shows empirically that the critical batch size scales primarily with data size rather than model size. In addition, they sho w theoretically (for SGD on linear regression) that in the bias-dominated, early-training regime, the critical batch size is b = 1 ; as training progresses and v ariance becomes dominant, the critical/ef ficient batch size increases. A similar behavior can also be seen in our Figure 1 for LMOs, where we see that the optimal (not the critical!) batch size ramps up at around 10 9 tokens 5 , and is initially one (see third panel). SGD: optimal batch size and linear learning rate scaling. The framew ork of K ov alev [ 31 ] cov ers normalized steepest descent (LMO) methods, not vanilla SGD. Howe ver , it is possible to extend our methodology to SGD and deri ve scaling results from well-known bounds [ 20 ]. W e present this in App. B.6 : a simple argument yields that at a fixed batch size the optimal learning rate scales as η ⋆ ( b, T ) = bT − 1 / 2 , in perfect agreement with the linear scaling suggestion by Jastrzebski et al. [ 26 ] , Smith et al. [ 47 ] . Next, our results suggest that, in contrast to LMO methods such as Muon or SignSGD with momentum, SGD does not have a non-trivial token-optimal batc h size (gi ven an 4 Note that dif ferences in exact e xponents may arise from the indirect relationship between gradient norm- based metrics and loss. See Appendix C for a simple sensitivity analysis sho wing ho w deviations from the i.i.d. bounded-variance mini-batch model and other constraints can shift the predicted e xponents. 5 The precise value for this phase transition crucially depends on momentum, see App. D , and on the v alues of C 1 , C 2 , C 3 in equation 4 . 6 optimal step size). This is in agreement with recent empirical results, suggesting SGD (in contrast to Adam) always profits from an increased iteration b udget at lo w token count [ 49 , 35 ]. Relation between batch size and step count. Our scaling rules also predict that, under fixed momentum, achieving a certain tar get performance requires both a minimum batch size (Fig. 10 ) and a minimum step count (Fig. 11 ). Indeed, von Rütte et al. [ 50 ] reports a hyperbolic relation between step count and batch size that closely resembles our theoretical results, suggesting this may be a fundamental property of LMO optimizers. W e build on this and derive this hyperbolic r elationship , clear from Figure 4 in App. D . Notably , a similar relation exists for standard SGD, as empirically reported by McCandlish et al. [ 36 ] , where a minimum step count and token b udget are required to achiev e a certain target performance, b ut no minimum batch size requirement exists. 1 0 1 1 0 6 1 0 1 1 1 0 1 6 1 0 2 1 iterations 1 0 0 1 0 2 1 0 4 1 0 6 1 0 8 1 0 1 0 batch size -5.1 -4.5 -3.8 -3.2 -2.6 -1.9 -1.3 -0.7 -0.0 0.6 l o g 1 0 ( p e r f ) Figure 4: Contours of best achie vable performance versus batch size and train- ing iterations for a fixed α and tuned η . Momentum scaling with batch size. A practical imple- mentation of the idea of momentum adaptation as the batch size is scaled appears only in v ery recent work. Marek et al. [ 35 ] propose to scale the β 2 momentum parameter in Adam as follows: b 7→ κb requires β 2 7→ β κ 2 . At the same time, Orvieto & Go wer [ 39 ] , Ferbach et al. [ 17 ] suggest that the choice β 1 = β 2 in Adam leads (after tun- ing) to near-optimal performance, drawing a direct link to SignSGD with momentum parameter β . Our scaling result in Theorem 2 sho ws that, at a fixed token b udget T and a fixed batch size b , the optimal momentum β = 1 − α ≈ 1 − bT − 1 / 2 . Hence, if b is scaled by a factor κ , we get β ≈ 1 − κbT − 1 / 2 . Our result is deeply connected to the strategy by Marek et al. [ 35 ] , indeed note that as T → ∞ we hav e β κ ≈ 1 − bT − 1 / 2 κ = 1 − κbT − 1 / 2 + O T − 1 . A decreasing optimal momentum as the batch size in- creases is also found to be effecti ve by Zhang et al. [ 52 ]. Batch Size Learning Rate Optimizer DeepSeek [ 8 ] b ⋆ ∝ T 0 . 3271 η ⋆ ∝ T − 0 . 1250 AdamW [ 30 ] StepLaw [ 32 ] b ⋆ ∝ T 0 . 571 η ⋆ ∝ N − 0 . 713 T 0 . 307 AdamW [ 30 ] von Rütte et al. [ 50 ] b ⋆ ∝ T 0 . 8225 η ⋆ ∝ T 0 . 2806 LaProp [ 55 ] Filatov et al. [ 18 ] b ⋆ ∝ T 0 . 45 ± 0 . 07 η ⋆ ∝ T − 0 . 28 ± 0 . 07 Scion [ 40 ] T able 1: Empirical batch-size and learning-rate scaling across four representati ve studies. Optimizers and tuning protocols differ across works; the table summarizes the reported exponents rather than a strictly like-for-like comparison. N denotes the number of non-embedding parameters. Learning rate scaling under jointly incr easing batch and token b udget. T o start, we recall (see first paragraph in this section) that our results align with observ ations that, at a fixed batc h size , the optimal learning rate should decrease as the training horizon gro ws (Theorem 1 ; Mlodozeniec et al. [ 38 ] ). Y et, how does the optimal learning rate change as the batc h size is chosen to scale with the token b udget? The results of v on Rütte et al. [ 50 ] and Li et al. [ 32 ] (see T able 1 ) suggest a trend that clashes 6 with our theory: in this setup, the optimal learning rates are found to increase with the token budget at the optimal batch size. Meanwhile, Theorem 1 predicts that if b ∝ T 1 / 2 , then η ⋆ = T − 1 / 4 . Appendix C.3 shows that a positi ve fitted e xponent can arise without contradicting Theorem 1 when one measures η ⋆ along a batch-scaling path b ( T ) (hence K ( T ) = T /b ( T ) ), e.g. when the budget is increased mainly via larger batches (fewer additional steps) or when hyperparameters are transferred across budgets. Further , note that the bound in equation 2 rules out η ⋆ ( T ) → ∞ for the constant-step proxy because of the O ( η ) term, independent of batch size and momentum. 6 Note that the comparison with empirical learning-rate scaling is subtle and influenced by factors such as model size. DeepSeek [ 8 ] reports a decrease in optimal learning rate as the token b udget increases. Ho wev er , since DeepSeek also scales model size with training horizon, this ef fect may largely reflect the lo wer learning rates required by larger models. In contrast, Li et al. [ 32 ] explicitly models the role of model size, and von Rütte et al. [ 50 ] uses µ P initialization to decouple size from learning rate. Both decoupled analyses find a positiv e correlation between the token horizon and the learning rate. 7 Appendix C additionally discusses how de viations from the idealized assumptions behind the proxy (e.g., non- b − 1 / 2 noise scaling, heavy tails, or norm-mismatched variance for LMO methods) can change the predicted exponents. Overall, this points to a clear direction for future in vestigation: determine which part of the remaining mismatch is due to (i) protocol constraints vs. (ii) assumption mismatch vs. (iii) looseness of the bound in equation 2 for modern large model training re gimes. 5 Conclusion W e de veloped an optimization-theoretic frame work for deri ving hyperparameter scaling laws at fixed model size. By treating recent con ver gence bounds for LMO-based methods as a proxy objectiv e, we obtained explicit predictions for ho w learning rate, batch size, and momentum should scale with training horizon and token budget. This perspective recov ers sev eral empirical trends within a unified analysis, including square-root learning-rate scaling with batch size, the emergence of a non-trivial tok en-optimal batch size, and a practical critical-batch-size regime when batch gro wth is constrained. The framew ork also yields principled hyperparameter -transfer rules across training horizons, providing a theoretical complement to empirical scaling la ws. At the same time, our results highlight sev eral limitations and open questions. Our fix ed-momentum analysis relies on lar ge-horizon approximations, and our numerical studies set all constants C i to one. W e assume a constant learning rate, matched initialization, and do not model weight decay . More broadly , some modern empirical protocols report learning-rate trends that are not fully captured by our proxy , especially when both batch size and token budget increase. Resolving whether this gap is driven by protocol constraints, assumption mismatch, or looseness of the bound in modern large-model re gimes remains an important direction for future work. Limitations and future work. Our analysis also calls into question common practices such as fixing batch size purely for throughput or extending training horizons without retuning hyperparameters. Quantifying the inefficiency induced by such choices, and ho w it scales with token budget, is a natural next step. Another important limitation is that we hold model size fixed, lea ving open ho w the optimal schedules interact with N , effecti ve smoothness, gradient noise, and parametrization choices such as µ P . Extending the frame work to include annealing, warmup, weight decay , and a more explicit treatment of optimization and generalization would further narrow the gap between theory and large-scale training practice. Acknowledgments T ianyue H. Zhang, Niccolò Ajroldi, Bernhard Schölkopf, and Antonio Orvieto acknowledge the financial support of the Hector F oundation. T ianyue H. Zhang ackno wledges the support of the Natural Sciences and Engineering Research Council of Canada (NSERC). W e are grateful for the support and great feedback by OpenEuroLLM, in particular by Jörg Franke, Aaron Klein and Da vid Salinas. The work described herein has been supported in part by the EC under the grant No. 101195233: OpenEuroLLM . References [1] Niccolò Ajroldi. plainlm: Language model pretraining in pytorch. https://github.com/ Niccolo- Ajroldi/plainLM , 2024. (Cited on page 6 ) [2] Maksym Andriushchenko, Francesco D’Angelo, Aditya V arre, and Nicolas Flammarion. Why do we need weight decay in modern deep learning?, 2023. (Cited on page 2 ) [3] Lukas Balles and Philipp Hennig. Dissecting adam: The sign, magnitude and v ariance of stochastic gradients. In ICML , 2018. (Cited on page 3 ) [4] Shane Bergsma, Nolan Dey , Gurpreet Gosal, Gavia Gray , Daria Sobolev a, and Joel Hestness. Power lines: Scaling la ws for weight decay and batch size in llm pre-training. arXiv pr eprint arXiv:2505.13738 , 2025. (Cited on pages 1 and 2 ) 8 [5] Jeremy Bernstein and Laker Newhouse. Old optimizer , ne w norm: An anthology . arXiv:2409.20325 , 2024. (Cited on pages 2 and 3 ) [6] Jeremy Bernstein, Y u-Xiang W ang, Kamyar Azizzadenesheli, and Animashree Anandkumar . signsgd: Compressed optimisation for non-con vex problems. In ICML , 2018. (Cited on page 2 ) [7] Louis Bethune, V ictor T urrisi, Bruno Kacper Mlodozeniec, Pau Rodriguez Lopez, Lokesh Boominathan, Nikhil Bhendawade, Amitis Shidani, Joris Pelemans, Theo X Olausson, De- von Hjelm, et al. The design space of tri-modal masked diffusion models. arXiv pr eprint arXiv:2602.21472 , 2026. (Cited on page 2 ) [8] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. DeepSeek LLM: Scaling open-source language models with longtermism. arXiv preprint , 2024. (Cited on pages 1 , 2 , and 7 ) [9] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthon y , Herbie Bradley , Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shiv anshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing lar ge language models across training and scaling. In ICML , 2023. (Cited on page 5 ) [10] Léon Bottou. Large-scale machine learning with stochastic gradient descent. In COMPST A T , 2010. (Cited on page 2 ) [11] Zhiqi Bu, Shiyun Xu, and Jialin Mao. Con vex dominance in deep learning i: A scaling la w of loss and learning rate. arXiv preprint , 2026. (Cited on pages 2 and 6 ) [12] David Carlson, V olkan Ce vher , and Lawrence Carin. Stochastic spectral descent for restricted boltzmann machines. In AIST A TS , 2015. (Cited on page 2 ) [13] Kenneth L Clarkson. Coresets, sparse greedy approximation, and the Frank-W olfe algorithm. A CM T ransactions on Algorithms , 6(4):1–30, 2010. (Cited on page 2 ) [14] Enea Monzio Compagnoni, Tianlin Liu, Rustem Islamov , Frank Norbert Proske, Antonio Orvieto, and Aurelien Lucchi. Adapti ve methods through the lens of sdes: Theoretical insights on the role of noise. , 2024. (Cited on pages 1 , 2 , and 6 ) [15] Ashok Cutkosky and Harsh Mehta. Momentum improves normalized SGD. In ICML , 2020. (Cited on pages 2 , 3 , 4 , and 13 ) [16] Epoch AI. Ke y trends and figures in machine learning, 2023. URL https://epoch.ai/ trends . (Cited on page 1 ) [17] Damien Ferbach, Courtney Paquette, Gauthier Gidel, Katie Everett, and Elliot Paquette. Logarithmic-time schedules for scaling language models with momentum. arXiv preprint arXiv:2602.05298 , 2026. (Cited on pages 2 and 7 ) [18] Oleg Filato v , Jiangtao W ang, Jan Ebert, and Stefan Kesselheim. Optimal scaling needs optimal norm. arXiv preprint , 2025. (Cited on pages 1 , 2 , 3 , and 7 ) [19] Marguerite Frank and Philip W olfe. An algorithm for quadratic programming. Naval Resear ch Logistics Quarterly , 3(1-2):95–110, 1956. (Cited on page 2 ) [20] Guillaume Garrigos and Robert M Gower . Handbook of con ver gence theorems for (stochastic) gradient methods. arXiv preprint , 2023. (Cited on pages 2 , 6 , and 20 ) [21] Elad Hazan. Sparse approximate solutions to semidefinite programs. In Latin American Symposium on Theor etical Informatics , pp. 306–316. Springer , 2008. (Cited on page 2 ) [22] Elad Hazan, Kfir Levy , and Shai Shalev-Shwartz. Beyond con ve xity: Stochastic quasi-conv ex optimization. NeurIPS , 2015. (Cited on page 3 ) [23] Jordan Hoffmann, Sebastian Bor geaud, Arthur Mensch, Elena Buchatskaya, T re vor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes W elbl, Aidan Clark, et al. T raining compute-optimal large language models. , 2022. (Cited on pages 1 and 5 ) 9 [24] Shengding Hu, Y uge T u, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Y ewei Fang, Y uxiang Huang, W eilin Zhao, Xinrong Zhang, Zheng Leng Thai, Kaihuo Zhang, Chongyi W ang, Y uan Y ao, Chen yang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. MiniCPM: Unv eiling the potential of small language models with scalable training strategies. , 2024. (Cited on page 1 ) [25] Martin Jaggi. Re visiting Frank-Wolfe: Projection-free sparse con vex optimization. In Interna- tional Confer ence on Machine Learning , pp. 427–435. PMLR, 2013. (Cited on page 2 ) [26] Stanisław Jastrzebski, Zachary Kenton, De v ansh Arpit, Nicolas Ballas, Asja Fischer , Y oshua Bengio, and Amos Storkey . Three factors influencing minima in sgd. arXiv pr eprint arXiv:1711.04623 , 2017. (Cited on page 6 ) [27] Keller Jordan, Y uchen Jin, Vlado Boza, Y ou Jiacheng, Franz Cecista, Laker Ne whouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon . (Cited on pages 2 and 3 ) [28] Jared Kaplan, Sam McCandlish, T om Henighan, T om B Brown, Benjamin Chess, Rewon Child, Scott Gray , Alec Radford, Jeffre y W u, and Dario Amodei. Scaling laws for neural language models. , 2020. (Cited on page 1 ) [29] Nitish Shirish Keskar , Dheev atsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy , and Ping T ak Peter T ang. On lar ge-batch training for deep learning: Generalization gap and sharp minima. arXiv pr eprint arXiv:1609.04836 , 2016. (Cited on page 6 ) [30] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. (Cited on pages 2 , 3 , and 7 ) [31] Dmitry K ov ale v . Understanding gradient orthogonalization for deep learning via non-Euclidean trust-region optimization. arXiv pr eprint arXiv:2503.12645 , 2025. (Cited on pages 2 , 3 , and 6 ) [32] Houyi Li, W enzhen Zheng, Qiufeng W ang, Hanshan Zhang, Zili W ang, Shijie Xuyang, Y uantao Fan, Zhenyu Ding, Haoying W ang, Ning Ding, Shuigeng Zhou, Xiangyu Zhang, and Daxin Jiang. Predictable scale: P art i, step law – optimal hyperparameter scaling law in large language model pretraining. , 2025. (Cited on pages 1 , 7 , and 23 ) [33] Y anli Liu, Y uan Gao, and W otao Y in. An impro ved analysis of stochastic gradient descent with momentum. Advances in Neural Information Pr ocessing Systems , 33:18261–18271, 2020. (Cited on page 3 ) [34] Sadhika Malladi, Kaifeng L yu, Abhishek P anigrahi, and Sanjee v Arora. On the sdes and scaling rules for adaptiv e gradient algorithms. NeurIPS , 2022. (Cited on pages 1 , 2 , and 6 ) [35] Martin Marek, Sanae Lotfi, Aditya Somasundaram, Andrew Gordon W ilson, and Micah Gold- blum. Small batch size training for language models: When v anilla sgd works, and why gradient accumulation is wasteful. In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems , 2025. (Cited on pages 1 , 2 , 6 , and 7 ) [36] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota T eam. An empirical model of large-batch training. , 2018. (Cited on pages 1 , 2 , 7 , and 13 ) [37] W illiam Merrill, Shane Arora, Dirk Groene veld, and Hannaneh Hajishirzi. Critical batch size re- visited: A simple empirical approach to large-batch language model training. , 2025. (Cited on page 1 ) [38] Bruno Mlodozeniec, Pierre Ablin, Louis Béthune, Dan Busbridge, Michal Klein, Jason Rama- puram, and Marco Cuturi. Completed hyperparameter transfer across modules, width, depth, batch and duration. , 2025. (Cited on pages 1 , 2 , 6 , and 7 ) [39] Antonio Orvieto and Robert M Gower . In search of adam’ s secret sauce. , 2025. (Cited on pages 3 and 7 ) 10 [40] Thomas Pethick, W anyun Xie, Kimon Antonakopoulos, Zhen yu Zhu, Antonio Silveti-Falls, and V olkan Cevher . T raining deep learning models with norm-constrained lmos. arXiv pr eprint arXiv:2502.07529 , 2025. (Cited on pages 2 , 3 , and 7 ) [41] Naoki Sato, Hiroki Nag anuma, and Hideaki Iiduka. Analysis of muon’ s con vergence and critical batch size. arXiv preprint , 2025. (Cited on page 2 ) [42] Fabian Schaipp, Alexander Hägele, Adrien T aylor , Umut Simsekli, and Francis Bach. The surprising agreement between con ve x optimization theory and learning-rate scheduling for lar ge model training. , 2025. (Cited on page 2 ) [43] Christopher J Shallue, Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig, and George E Dahl. Measuring the ef fects of data parallelism on neural network training. Journal of Machine Learning Resear ch , 20(112):1–49, 2019. (Cited on page 6 ) [44] Xian Shuai, Y iding W ang, Y imeng W u, Xin Jiang, and Xiaozhe Ren. Scaling law for language models training considering batch size. arXiv pr eprint arXiv:2412.01505 , 2024. (Cited on pages 1 and 5 ) [45] Egor Shulgin, Sultan AlRashed, Francesco Orabona, and Peter Richtárik. Beyond the ideal: Analyzing the inexact muon update. , 2025. (Cited on pages 2 , 4 , and 13 ) [46] Umut Simsekli, Le vent Sagun, and Mert Gurbuzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. arXiv pr eprint arXiv:1901.06053 , 2019. (Cited on page 22 ) [47] Samuel Smith, Erich Elsen, and Soham De. On the generalization benefit of noise in stochastic gradient descent. In International Confer ence on Machine Learning , pp. 9058–9067. PMLR, 2020. (Cited on page 6 ) [48] Daria Sobolev a, Faisal Al-Khateeb, Robert Myers, Jacob R Steev es, Joel Hestness, and Nolan Dey . Slimpajama: A 627b token cleaned and deduplicated version of redpajama. Blog post , 2023. (Cited on page 6 ) [49] T eodora Sre ´ ckovi ´ c, Jonas Geiping, and Antonio Orvieto. Is your batch size the problem? revisiting the adam-sgd gap in language modeling. arXiv preprint , 2025. (Cited on page 7 ) [50] Dimitri von Rütte, Janis Fluri, Omead Pooladzandi, Bernhard Schölk opf, Thomas Hofmann, and Antonio Orvieto. Scaling behavior of discrete dif fusion language models. , 2025. (Cited on pages 2 , 7 , 23 , and 26 ) [51] Greg Y ang and Etai Littwin. T ensor programs ivb: Adaptive optimization in the infinite-width limit. arXiv preprint , 2023. (Cited on pages 1 and 3 ) [52] Hanlin Zhang, Depen Morw ani, Nikhil Vyas, Jingfeng W u, Difan Zou, Udaya Ghai, Dean Foster , and Sham Kakade. Ho w does critical batch size scale in pre-training? , 2024. (Cited on pages 1 , 6 , and 7 ) [53] Jingzhao Zhang, Sai Praneeth Karimireddy , Andreas V eit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar , and Suvrit Sra. Why are adaptiv e methods good for attention models? In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2020. (Cited on page 22 ) [54] Rosie Zhao, Depen Morwani, David Brandfonbrener , Nikhil Vyas, and Sham Kakade. Decon- structing what makes a good optimizer for language models. , 2024. (Cited on page 3 ) [55] Liu Ziyin, Zhikang T W ang, and Masahito Ueda. Laprop: Separating momentum and adapti vity in adam. arXiv preprint , 2020. (Cited on page 7 ) 11 A P P E N D I X Contents 1 Introduction 1 2 Preliminaries 2 3 Derivation of Scaling Laws 3 3.1 Optimization of the Proxy Objective . . . . . . . . . . . . . . . . . . . . . . . . . 3 3.2 Optimal asymptotics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 4 Discussion and Connections with the Literature 5 5 Conclusion 8 A Budget transfer summary 13 B Pr oofs 14 B.1 Fixed momentum, lar ge budget . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.2 Fixed batch size, lar ge budget . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.3 Full T uning, lar ge budget . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B.4 Should you tune momentum? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 B.5 General power -la w scaling under a fixed b udget . . . . . . . . . . . . . . . . . . . 19 B.6 Analysis of SGD and comparison with LMO methods . . . . . . . . . . . . . . . . 20 C Ho w modified assumptions can change the exponents 21 C.1 Dependency on Initialization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 C.2 Noise Model and Flatness of the Batch size landscape . . . . . . . . . . . . . . . . 21 C.3 Why can empirical fits sho w an optimal learning rate increasing with token b udget? 23 D Additional Plots 24 12 A Budget transfer summary In this section, we giv e a practical summary of the takea ways provided by Theorems 1 , 2 , and 3 . It is often feasible to tune hyperparameters only at a relatively small token budget T 0 , but then one wishes to run a much longer training at T 1 ≫ T 0 . Since the proxy bound risk T in equation 4 depends explicitly on the horizon T = bK , a naiv e reuse of the short-run optimum ( η 0 , α 0 , b 0 ) at T 1 is generally suboptimal. A simple alternati ve is to (i) tune at T 0 (e.g. by grid search) within a chosen hyperparameter family , and (ii) extr apolate the best configuration to T 1 using the power -law scalings suggested by the proxy analysis. W e consider four natural transfer regimes depending on whether batch size b and momentum α are tuned. Regime T uned at T 0 T ransfer rule to T 1 Comments (A) fixed b , fix ed α η b 1 = b 0 , α 1 = α 0 , η 1 = η 0 T 0 T 1 1 / 2 Safest; only rescales stepsize. (B) fixed b , tuned α ( η , α ) b 1 = b 0 , α 1 = α 0 T 0 T 1 1 / 2 , η 1 = η 0 T 0 T 1 3 / 4 Fixed-batch large-horizon scal- ing ( η ∝ K − 3 / 4 , α ∝ K − 1 / 2 ). (C) tuned b , fixed α ( η , b ) α 1 = α 0 , b 1 = b 0 T 1 T 0 1 / 2 , η 1 = η 0 T 0 T 1 1 / 4 T oken-optimal b under fixed α proxy (aggressi ve batch growth). (D) tuned b , tuned α ( η, α, b ) b 1 = b 0 T 1 T 0 1 / 6 , α 1 = α 0 T 0 T 1 1 / 3 , η 1 = η 0 T 0 T 1 7 / 12 Joint token-optimal proxy (burn- in term retained); milder batch growth. T able 2: Budget transfer rules for LMO methods under token b udget T = bK . Here ( η 0 , α 0 , b 0 ) is the best configuration found at T 0 within the chosen regime (e.g. via grid search), and ( η 1 , α 1 , b 1 ) is the extrapolated configuration for T 1 . All scalings are asymptotic and should be combined with feasibility constraints (e.g. b 1 ≥ 1 integer , hardware caps, α 1 ∈ (0 , 1] , and stepsize stability limits). In terms of the more common momentum coefficient β = 1 − α , decreasing α as T grows corresponds to increasing momentum β ↑ 1 . Regime (B) corresponds to the standard fixed-batch lar ge-horizon tuning where the dominant terms of the proxy bound are balanced (see, e.g., [ 15 , 45 ] for related large-horizon momentum scalings). Regimes (C)–(D) additionally allow batch size to change with T , which is what pins down a tok en-optimal b ( T ) . Contrast to SGD . F or non-con ve x Euclidean SGD, the classical bound yields η ⋆ ( T , b ) ∝ b/ √ T (before stability caps), so a simple b udget transfer is η 1 = η 0 b 1 b 0 q T 0 T 1 (and if b 1 = b 0 , then η 1 = η 0 q T 0 T 1 ). In this bound, batch size mainly trades iterations for parallelism [ 36 ], whereas the LMO bound contains additional batch-dependent terms that can induce a non-trivial tok en-optimal b ( T ) . Changing batch size between tuning and the long run. T able 2 assumes the batch size is held fixed between tuning at T 0 and the long run at T 1 . If instead the a v ailable hardware increases and one runs the long run with a larger batch, T able 3 summarizes the corresponding transfer rules (obtained by re-expressing the K -optimal schedules under K ( T ) = T /b ( T ) ). 13 Setting Calibrated in variants at ( T 0 , b 0 ) Extrapolation to ( T 1 , b 1 ) LMO, fixed α (Regime A) c η : = η 0 q T 0 b 0 η 1 = c η q b 1 T 1 = η 0 q b 1 b 0 q T 0 T 1 LMO, tuned α (Regime B) c α : = α 0 √ T 0 b 0 , c η : = η 0 T 3 / 4 0 b 0 α 1 = c α b 1 √ T 1 = α 0 b 1 b 0 q T 0 T 1 η 1 = c η b 1 T 3 / 4 1 = η 0 b 1 b 0 T 0 T 1 3 / 4 SGD c η : = η 0 √ T 0 b 0 η 1 = c η b 1 √ T 1 = η 0 b 1 b 0 q T 0 T 1 T able 3: Budget transfer when batch size changes between short-run tuning at ( T 0 , b 0 ) and long-run training at ( T 1 , b 1 ) . Here ( η 0 , α 0 ) are obtained by tuning at ( T 0 , b 0 ) in the specified setting, and then extrapolated to ( T 1 , b 1 ) . All formulas are asymptotic and should be combined with feasibility constraints (e.g. α 1 ∈ (0 , 1] , integer batch sizes, hardw are limits, and stepsize stability caps). B Proofs W e provide here proofs for the results in Section 3 . B.1 Fixed momentum, large b udget For a fix ed K , risk K ( η , b ) ∼ C 1 1 η K + ˜ C 2 1 √ b + ˜ C 3 η . Minimizing w .r .t. η gives η ⋆ K = s C 1 ˜ C 3 K . Thus risk ⋆ K ∼ 2 s C 1 ˜ C 3 K + ˜ C 2 1 √ b , and the performance therefore improv es with b . b ⋆ K → ∞ . For a fix ed T , risk T ( η , b ) ∼ C 1 b η T + ˜ C 2 1 √ b + ˜ C 3 η . Minimizing w .r .t. η : η ⋆ T ( b ) = s C 1 b ˜ C 3 T . Plugging in and minimizing w .r .t. b yields b ⋆ T = ˜ C 2 2 p C 1 ˜ C 3 √ T , η ⋆ T = C 1 / 4 1 ˜ C 1 / 2 2 √ 2 ˜ C 3 / 4 3 1 T 1 / 4 . Moreov er , risk ⋆ T ∼ 2 √ 2( C 1 ˜ C 3 ) 1 / 4 ˜ C 1 / 2 2 1 T 1 / 4 . B.2 Fixed batch size, large b udget Write risk K in expanded form: risk K ( η , α, b ) = C 1 1 η K + C 2 1 α √ b K + C 2 r α b + C 3 η 1 + α α . 14 In the large-horizon re gime and at the optimizer (where α is small), we consider the leading proxy risk lead K ( η , α, b ) = C 1 1 η K + C 2 r α b + C 3 η α . W e check that this proxy is asymptotically correct at the end of the proof. For fix ed ( α, b ) , minimization w .r .t. η leads to C 1 1 η K + C 3 η α ⇒ η ⋆ ( α, b, K ) = r C 1 α C 3 K . Substituting this giv es min η > 0 risk lead K = 2 r C 1 C 3 K α + C 2 r α b . Next, we minimize w .r .t. α . Let p = 2 q C 1 C 3 K and q = C 2 √ b . Then we minimize p α − 1 / 2 + q α 1 / 2 , whose minimizer is α = p/q , hence α ⋆ K ( b ) = 2 √ C 1 C 3 C 2 √ b √ K . Plugging back yields min α,η risk lead K = 2 √ pq = 2 √ 2 C 1 / 2 2 ( C 1 C 3 ) 1 / 4 1 b 1 / 4 K 1 / 4 . Finally , using η ⋆ ( α, b, K ) = q C 1 α C 3 K with α = α ⋆ K ( b ) giv es η ⋆ K ( b ) = √ 2 C 3 / 4 1 C 1 / 2 2 C 1 / 4 3 b 1 / 4 K 3 / 4 . For b = 1 this reco vers α ∝ K − 1 / 2 and η ∝ K − 3 / 4 . Consistency of dropping lo wer -order terms. At ( η ⋆ K , α ⋆ K ) , the dropped burn-in term scales as C 2 1 α √ b K = O 1 b K 1 / 2 , while the dropped additiv e smoothness term C 3 η scales as O ( b 1 / 4 K − 3 / 4 ) , both lower order than the leading O ( b − 1 / 4 K − 1 / 4 ) term for large K . Remark 4 (Continuum of feasible batch-gro wth paths under Theorem 2) Although Theorem 2 is stated for fixed b , the schedules ar e explicit in b : α ⋆ T ( b ) ∝ bT − 1 / 2 and η ⋆ T ( b ) ∝ bT − 3 / 4 with risk ⋆ T ∝ T − 1 / 4 . Ther efor e, along any path b ( T ) such that α ⋆ T ( b ( T )) ≤ 1 (equivalently b ( T ) ≲ √ T ), one retains the same token exponent T − 1 / 4 , while the induced scalings of α and η depend on the chosen b ( T ) . This “continuum” is br oken (and a specific b ⋆ T is selected) once the burn-in term is r etained, as in Theor em 3 . B.3 Full T uning, large budget The follo wing discussion is self-contained and general enough to also describe the results we presented in simpler settings, as we show after the proof. Con ver gence bound. W e start from the non-con ve x bound (up to uni versal constants) min 1 ≤ k ≤ K E ∥∇ f ( x k ) ∥ ⋆ ≤ ∆ 0 η K + 2 ρσ α √ b K + 2 ρσ r α b + 7 Lη 2 + 2 Lη α | {z } =: U ( α,η ; b,K ) . (10) Here η > 0 is the step size, α ∈ (0 , 1] is the momentum “update” parameter ( β = 1 − α ), b is the batch size, and K is the number of iterations. 15 T oken budget. Fix a total b udget T = bK . Substitute K = T /b into U ( α, η ; b, K ) and define U T ( α, η ; b ) := U ( α, η ; b, T /b ) = b ∆ 0 η T + 2 ρσ √ b αT + 2 ρσ r α b + 7 Lη 2 + 2 Lη α . (11) W e no w minimize equation 11 o ver ( η , α, b ) (treating b as a continuous v ariable; in practice b is an integer and must respect hardware caps). Step 1: minimize ov er η (for fixed α , b ). For fixed ( α, b ) , the η -dependent part of equation 11 is b ∆ 0 T · 1 η + L 7 2 + 2 α η . This function, with respect to η , is easy to minimize. The minimizer is η ⋆ T ( α, b ) = s b ∆ 0 T L 7 2 + 2 α ∝ p b/T , min η > 0 n A η + B η o = 2 √ AB . (12) Plugging equation 12 into equation 11 yields the η -optimized bound min η > 0 U T ( α, η ; b ) = 2 r b ∆ 0 L T 7 2 + 2 α + 2 ρσ √ b αT + 2 ρσ r α b =: Φ T ( α, b ) . (13) Step 2: minimize Φ T ( α, b ) over b (for fixed α ). Let s := √ b > 0 . Then equation 13 can be written as Φ T ( α, b ) = A T ( α ) s + B ( α ) s , (14) where A T ( α ) = 2 r ∆ 0 L T r 7 2 + 2 α + 2 ρσ αT , B ( α ) = 2 ρσ √ α. (15) Since As + B /s is minimized at s ⋆ = p B / A , we obtain q b ⋆ T ( α ) = s B ( α ) A T ( α ) , b ⋆ T ( α ) = B ( α ) A T ( α ) = 2 ρσ √ α 2 q ∆ 0 L T q 7 2 + 2 α + 2 ρσ αT . (16) The corresponding minimized value (for fix ed α ) is min b> 0 Φ T ( α, b ) = 2 p A T ( α ) B ( α ) . (17) Using √ α q 7 2 + 2 α = q 7 2 α + 2 , we can simplify: min b> 0 Φ T ( α, b ) = 4 s ρσ r ∆ 0 L T r 7 2 α + 2 + ( ρσ ) 2 T √ α =: Ψ T ( α ) . (18) Step 3: minimize Ψ T ( α ) over α (exact cubic condition). Because the outer square-root in equation 18 is monotone, minimizing Ψ T ( α ) is equi valent to minimizing the inner expression g T ( α ) := ρσ r ∆ 0 L T r 7 2 α + 2 + ( ρσ ) 2 T √ α . (19) Differentiate: g ′ T ( α ) = ρσ r ∆ 0 L T · 7 2 2 q 7 2 α + 2 − ( ρσ ) 2 T · 1 2 α − 3 / 2 . Setting g ′ T ( α ) = 0 and rearranging gi ves ρσ r ∆ 0 L T · 7 2 q 7 2 α + 2 = ( ρσ ) 2 T α − 3 / 2 . 16 Squaring both sides (valid for α > 0 ) yields the exact cubic : 7 2 2 ∆ 0 L T α 3 − 7 2 ( ρσ ) 2 α − 2( ρσ ) 2 = 0 . (20) This equation has a unique positive real root; denote it by α ⋆ T . Then α ⋆ T is the unique positiv e root of equation 20 , b ⋆ T = b ⋆ T ( α ⋆ T ) from equation 16 , η ⋆ T = η ⋆ T ( α ⋆ T , b ⋆ T ) from equation 12 , K ⋆ T = T b ⋆ T . α ⋆ T = the unique positiv e root of equation 20 , b ⋆ T = b ⋆ T ( α ⋆ T ) from equation 16 , η ⋆ T = η ⋆ T ( α ⋆ T , b ⋆ T ) from equation 12 , K ⋆ T = T /b ⋆ T . Asymptotic scalings for large T . W e no w extract an explicit approximation for α ⋆ T from equa- tion 20 . Write the cubic in the condensed form A T α 3 − B α − C = 0 , A := 7 2 2 ∆ 0 L, B := 7 2 ( ρσ ) 2 , C := 2( ρσ ) 2 . (21) Step (a): identify the correct exponent. Assume α decays polynomially , α ∝ T − p . Then the three terms scale as AT α 3 ∝ T 1 − 3 p , B α ∝ T − p , C ∝ T 0 . T o balance the constant term C with the leading term AT α 3 we require 1 − 3 p = 0 , hence p = 1 3 . This predicts α ⋆ T = Θ( T − 1 / 3 ) . Step (b): compute the leading constant. Set the rescaled variable u := α T 1 / 3 , i.e. α = u T − 1 / 3 . Plugging into equation 21 giv es A T ( u 3 T − 1 ) − B ( uT − 1 / 3 ) − C = 0 ⇐ ⇒ Au 3 − C = B u T − 1 / 3 . As T → ∞ , the right-hand side v anishes, so u con ver ges to the unique positi ve root of Au 3 − C = 0 , i.e. u 0 = ( C / A ) 1 / 3 . Therefore, α ⋆ T ≈ u 0 T − 1 / 3 = C A 1 / 3 T − 1 / 3 = 2( ρσ ) 2 7 2 2 ∆ 0 L ! 1 / 3 T − 1 / 3 = 2 7 2 / 3 ( ρσ ) 2 / 3 (∆ 0 L ) 1 / 3 T − 1 / 3 . (22) First corr ection term. The same rescaling gi ves Au 3 − C = B u T − 1 / 3 , so one may e xpand u = u 0 + u 1 T − 1 / 3 + O ( T − 2 / 3 ) . Keeping the order- T − 1 / 3 terms yields 3 Au 2 0 u 1 = B u 0 , hence u 1 = B 3 Au 0 = B 3 A 2 / 3 C 1 / 3 , and thus α ⋆ T = u 0 T − 1 / 3 + u 1 T − 2 / 3 + O ( T − 1 ) . Step (c): induced batch size and step-size scalings. Using equation 16 and the fact that α ⋆ T → 0 , we hav e 7 2 + 2 α ∼ 2 α , and also the term 2 ρσ αT in A T ( α ) becomes lower order at α = α ⋆ T . A short calculation then yields the scalings b ⋆ T = Θ( T 1 / 6 ) , K ⋆ T = Θ( T 5 / 6 ) , η ⋆ T = Θ( T − 7 / 12 ) , (23) and substituting the optimized parameters back into equation 18 giv es the rate min 1 ≤ k ≤ K ⋆ T E ∥∇ f ( x k ) ∥ ⋆ = O (∆ 0 L ) 1 / 4 √ ρσ T − 1 / 4 . Recovering earlier regimes as special cases. All previously discussed tuning regimes are obtained by r estricting the optimization abov e: • F ixed b (no batch tuning): k eep b fixed in equation 11 and optimize only over ( η , α ) (equiv alently , apply Steps 1 and 3 b ut without Step 2). This reco vers the familiar large- horizon schedules α ∝ K − 1 / 2 and η ∝ K − 3 / 4 (up to b -dependent constants) once one rewrites K = T /b . • F ixed α (no momentum tuning): keep α fixed and optimize o ver ( η , b ) . Then Step 3 is skipped and the minimizer in Step 2 yields the “fixed- α ” token-optimal batch scaling (typically b ⋆ T = Θ( √ T ) in the simplified proxy). • F ixed K : set b = T /K (a re-parameterization) and optimize ov er ( η , α ) . 17 B.4 Should you tune momentum? Our results show that a rate of T − 1 / 4 can be achiev ed both with and without momentum tuning. This naturally raises the question: if we keep α fixed when moving from T 0 to T 1 ≫ T 0 , how far are we from the token-optimal performance that one would obtain by re-tuning the momentum parameter α ? W e develop this in a fe w points, proving Corollary 1 . (1) Perf ormance gap at the proxy lev el is only a constant factor (when b can scale). In the fixed-momentum lar ge-horizon proxy (Eq. (4) in the main text), risk T ( η , b ; α ) ≈ C 1 b η T + ˜ C 2 ( α ) 1 √ b + ˜ C 3 ( α ) η , ˜ C 2 ( α ) = C 2 √ α, ˜ C 3 ( α ) = C 3 1 + 1 α . Optimizing ov er ( η , b ) for fix ed α yields (App. B.1 ): b ⋆ T ( α ) = ˜ C 2 ( α ) 2 q C 1 ˜ C 3 ( α ) √ T , (24) η ⋆ T ( α ) = C 1 / 4 1 ˜ C 2 ( α ) 1 / 2 √ 2 ˜ C 3 ( α ) 3 / 4 T − 1 / 4 , (25) risk ⋆ T ( α ) = 2 √ 2 ( C 1 ˜ C 3 ( α )) 1 / 4 ˜ C 2 ( α ) 1 / 2 T − 1 / 4 . (26) Substituting ˜ C 2 , ˜ C 3 giv es the explicit α -dependence of the constant : risk ⋆ T ( α ) = 2 √ 2 ( C 1 C 3 ) 1 / 4 C 1 / 2 2 (1 + α ) 1 / 4 T − 1 / 4 . (27) Thus, in this proxy re gime, keeping α fixed does not change the e xponent in T (it remains T − 1 / 4 ), and re-tuning α can only improv e the constant factor . In f act, since α ∈ (0 , 1] , one has (1 + α ) 1 / 4 ∈ [1 , 2 1 / 4 ] , so the maximal improv ement from changing a fixed α is at most a factor 2 1 / 4 ≈ 1 . 19 in performance. Equiv alently , since T enters as T − 1 / 4 , this constant-factor improvement corresponds to at most a factor of 2 in token b udget to reach a fixed tar get tolerance ε : T req ( α ; ε ) ∝ (1 + α ) · ε − 4 . For typical momentum v alues (e.g. β = 0 . 9 ⇒ α = 0 . 1 ), this predicts only a mild potential gain in the proxy bound from re-tuning α at larger b udgets. (2) The gap can be huge under a batch-size cap: fixed α causes saturation. The previous conclusion assumes one can scale b with T as in equation 24 . If instead the batch size is capped by hardware, b ≤ b max , then the fixed- α proxy optimized ov er η satisfies min η > 0 risk T ( η , b max ; α ) ≈ 2 s C 1 ˜ C 3 ( α ) b max T + ˜ C 2 ( α ) 1 √ b max . As T → ∞ , the first term vanishes b ut the second term remains: lim inf T →∞ min η > 0 risk T ( η , b max ; α ) ≳ ˜ C 2 ( α ) √ b max = C 2 √ α √ b max . That is, with fixed α and capped batc h size , the pr oxy exhibits a non-vanishing noise floor . By contrast, allowing α to decrease with T (Regime (B) / Theorem 2 in the main text) removes this floor and restores risk ⋆ T ∝ T − 1 / 4 ev en at fixed b . (3) What is left on the table is primarily batch growth (Regime (C) vs (D)). Comparing the token-optimal batch scaling under fixed α (Theorem 1: b ⋆ T ∝ T 1 / 2 ) to the jointly tuned scaling (Theorem 3 : b ⋆ T ∝ T 1 / 6 ) shows that re-tuning α mostly reduces the required batch gro wth with budget. A con venient w ay to quantify this is via the maximal budget that can be run near-optimally under a batch-size cap b ≤ b max : Regime (C): b ⋆ T ∝ T 1 / 2 ⇒ T ≲ Θ( b 2 max ) , Regime (D): b ⋆ T ∝ T 1 / 6 ⇒ T ≲ Θ( b 6 max ) , (up to constant factors hidden in the proxy). Hence, e ven though both re gimes achie ve the same proxy exponent T − 1 / 4 in principle, tuning momentum can dramatically e xtend the range of tok en budg ets that r emain feasible befor e hitting batch-size satur ation. 18 B.5 General power -law scaling under a fixed budget In this section, we prov e Corollary 2 . Recall that under the token (samples) b udget T = bK we can rewrite the bound as U T ( α, η ; b ) := U α, η ; b, T b = b ∆ 0 η T + 2 ρσ √ b αT + 2 ρσ r α b + 7 Lη 2 + 2 Lη α . (28) Po wer -law schedules. Assume that the algorithmic parameters follow po wer laws in T : b ( T ) = Θ( T β ) , α ( T ) = Θ( T − γ ) , η ( T ) = Θ( T − δ ) , (29) with β ∈ [0 , 1] (since 1 ≤ b ≤ T ) and γ , δ ∈ R . Note that her e β is not the momentum parameter! Then the fiv e terms in equation 28 scale as b ∆ 0 η T = Θ T β − 1+ δ = Θ T − (1 − β − δ ) , 2 ρσ √ b αT = Θ T β / 2 − 1+ γ = Θ T − (1 − β / 2 − γ ) , 2 ρσ r α b = Θ T − ( β + γ ) / 2 , 7 Lη 2 = Θ T − δ , 2 Lη α = Θ T − δ + γ = Θ T − ( δ − γ ) . (30) Equiv alently , defining the decay exponents r 1 := 1 − β − δ, r 2 := 1 − β 2 − γ , r 3 := β + γ 2 , r 4 := δ, r 5 := δ − γ , (31) we hav e (up to absolute constants) U T ( α ( T ) , η ( T ); b ( T )) = Θ T − r 1 + T − r 2 + T − r 3 + T − r 4 + T − r 5 = Θ T − min i r i , (32) provided all r i > 0 (i.e., each term decays). Guaranteeing a T − 1 / 4 bound for a prescribed batch scaling . A con venient way to enforce a T − 1 / 4 rate is to equalize the three coupled terms b η T , p α b , η α . Specifically , for any batch schedule b ( T ) satisfying b ( T ) ≤ c √ T ( equiv alently β ≤ 1 2 ) , (33) choose α ( T ) ∝ b ( T ) √ T , η ( T ) ∝ b ( T ) T 3 / 4 . (34) Then b η T = Θ( T − 1 / 4 ) , r α b = Θ( T − 1 / 4 ) , η α = Θ( T − 1 / 4 ) , (35) and the remaining terms satisfy √ b αT = Θ 1 √ bT ≤ Θ( T − 1 / 2 ) , η = Θ b T 3 / 4 ≤ Θ( T − 1 / 4 ) (by equation 33 ). (36) Consequently , U T ( α ( T ) , η ( T ); b ( T )) ≲ C 1 T − 1 / 4 + C 2 ( bT ) − 1 / 2 = O ( T − 1 / 4 ) , (37) for constants C 1 , C 2 depending only on ∆ 0 , L, ρ, σ (and the hidden constants in equation 34 ). Remark (batch-size scaling b = T /K ). If b ( T ) = Θ( T β ) , then K ( T ) = T /b ( T ) = Θ( T 1 − β ) and T /K = b = Θ( T β ) . Condition equation 33 is precisely β ≤ 1 2 (i.e., b cannot gro w faster than √ T ) to maintain the T − 1 / 4 guarantee under power -la w tuning. 19 Aggressi ve batch-size growth: 1 2 < β < 1 . Assume the po wer-la w batch schedule b ( T ) = Θ( T β ) with 1 2 < β < 1 (hence K ( T ) = T /b ( T ) = Θ( T 1 − β ) ). In this regime, the bound cannot in general maintain the T − 1 / 4 decay: the two terms b η T and η already impose a hard rate ceiling. Indeed, writing η ( T ) = Θ( T − δ ) , their decay exponents are r 1 = 1 − β − δ and r 4 = δ , so for any δ , min { r 1 , r 4 } ≤ max δ min { 1 − β − δ, δ } = 1 − β 2 , (38) with equality achiev ed by balancing them at δ ⋆ = 1 − β 2 ⇐ ⇒ η ( T ) = Θ T − (1 − β ) / 2 . (39) T aking, e.g., α ( T ) = Θ(1) and η ( T ) as in equation 39 yields U T α ( T ) , η ( T ); b ( T ) = Θ T − (1 − β ) / 2 , 1 2 < β < 1 , (40) since the remaining terms decay strictly faster: √ b αT = Θ T − (1 − β / 2) , r α b = Θ T − β / 2 , η α = Θ T − (1 − β ) / 2 . Equiv alently , using K ( T ) = T /b ( T ) = Θ( T 1 − β ) , the achiev able rate can be written as Θ T − (1 − β ) / 2 = Θ K − 1 / 2 = Θ r b T ! , (41) highlighting that when b grows f aster than √ T , the bound becomes iteration-limited. B.6 Analysis of SGD and comparison with LMO methods For conte xt, consider standar d Euclidean SGD (not normalized SGD / LMO), x k +1 = x k − η g k b , E [ g k b | x k ] = ∇ f ( x k ) , E ∥ g k b − ∇ f ( x k ) ∥ 2 2 ≤ σ 2 /b, with f being L -smooth in ∥ · ∥ 2 . A classical non-conv ex guarantee (for constant η ≤ 1 /L ) is [ 20 ] 1 K K − 1 X k =0 E ∥∇ f ( x k ) ∥ 2 2 ≲ ∆ 0 η K + Lη σ 2 b . (42) Equiv alently , min 0 ≤ k ≤ K − 1 E ∥∇ f ( x k ) ∥ 2 2 obeys the same RHS up to constants. Fixed K . Optimizing equation 42 ov er η yields η ⋆ ∝ p b/K and min η 1 K K − 1 X k =0 E ∥∇ f ( x k ) ∥ 2 2 ≲ r ∆ 0 Lσ 2 bK . Thus, at a fixed iteration budget K , increasing b improv es the bound (as in man y stochastic methods). Fixed token b udget T = bK . Substituting K = T /b into equation 42 gives 1 K K − 1 X k =0 E ∥∇ f ( x k ) ∥ 2 2 ≲ ∆ 0 b η T + Lη σ 2 b . Optimizing ov er η ( η ⋆ ∝ bT − 1 / 2 ) yields an optimized value min η ∆ 0 b η T + Lη σ 2 b ≲ r ∆ 0 Lσ 2 T , which is independent of b at the lev el of this proxy bound. In other words, under a fixed tok en budget, the classical SGD analysis does not pr edict a non-trivial token-optimal batch size : after optimizing η , b largely trades of f iterations vs. v ariance reduction in a way that cancels. 20 Comparison to LMO. The LMO bound used in the paper (equation 10 ) differs structurally: (i) it controls ∥∇ f ( · ) ∥ ⋆ (not squared), and (ii) it contains additional terms coupling ( η , α ) and mini- batching, including a noise-floor term ∝ σ p α/b and a burn-in / initialization term that can scale as ∝ σ/ ( α √ bK ) under matched stochastic initialization (Appendix C.1 ). As a consequence, • with fixed α , the proxy retains a decreasing-in- b contribution under T = bK (e.g. ∝ 1 / √ b ), leading to a genuinely non-trivial tok en-optimal batch size (Theorem 1 : b ⋆ T ∝ √ T ); • with tuned α , the leading-order cancellation in b under T = bK becomes more similar in spirit to SGD, and b ⋆ ( T ) is pinned only by lo wer-order terms (Theorem 2). C How modified assumptions can change the exponents C.1 Dependency on Initialization Matched initialization and the burn-in term. W e assume matched initialization, namely that the momentum buf fer is initialized from a stochastic mini-batch gradient of the same batch size b as used during training, e.g. m 0 = g 0 b . Under the bounded-variance model, this implies E 0 := E ∥ g 0 b − ∇ f ( x 0 ) ∥ ⋆ ≲ ρσ √ b , and this is exactly what yields the 1 α √ bK “burn-in” dependence in the non-con ve x LMO bound below . If m 0 is not matched, this term changes; see next paragraph. On non-matched initialization. If m 0 is not initialized from a stochastic batch- b gradient, the burn- in term can change from ∝ 1 α √ bK to ∝ E 0 αK with an E 0 that may not decay as 1 / √ b . Under a fixed budget T = bK this changes the √ b/ ( αT ) structure in equation 11 and can alter the tok en-optimal b ( T ) scaling. C.2 Noise Model and Flatness of the Batch size landscape The po wer-la w exponents obtained by optimizing con vergence upper bounds are not uni versal: they are a direct consequence of (i) the functional form of the bound and (ii) ho w the stochastic error term scales with mini-batching, geometry , and moment assumptions. W e record a simple sensitivity analysis that makes the dependence explicit. I. A one-parameter model f or how noise shrinks with batch size. The equation 2 bound assumes a finite-variance (sub-Gaussian/sub-exponential) scaling, where the typical noise magnitude decreases as b − 1 / 2 . T o capture deviations (e.g. correlations or hea vy tails), we introduce a generic exponent q : Assumption 1 (Effective mini-batch noise scaling) Ther e exist q ∈ (0 , 1] and a scale parameter σ q > 0 such that the mini-batc h gradient satisfies E ∥ g b ( x ) − ∇ f ( x ) ∥ ⋆ ≲ σ q b q (uniformly over x ). The bounded-variance/i.i.d. setting corr esponds to q = 1 2 . Correlations or other inefficiencies can lead to q < 1 2 . Under Assumption 1 , the two “noise” terms in the LMO bound scale as 1 αK · σ q b q and √ α · σ q b q , rather than with b − 1 / 2 . 21 II. Why the leading-order bound can become “flat” in b (and when it does not). T o isolate the mechanism, consider the dominant three-term proxy (dropping constants and the burn-in term for the moment) U ( α, η ; b, K ) ≈ ∆ 0 η K + L η α + σ q b q √ α. (43) Optimizing equation 43 ov er η giv es η ⋆ ( α ) ∝ r ∆ 0 α L K , min η > 0 n ∆ 0 η K + L η α o ∝ r ∆ 0 L K · α − 1 / 2 . Then the α -problem becomes c 1 α − 1 / 2 + c 2 ( b ) α 1 / 2 with c 2 ( b ) ∝ σ q /b q , hence α ⋆ ( b, K ) ∝ b q √ K , η ⋆ ( b, K ) ∝ b q / 2 K 3 / 4 , min α,η U ∝ b − q / 2 K 1 / 4 . (44) Now impose a fix ed token b udget T = bK (so K = T /b ). Plugging into equation 44 yields min α,η U ∝ T − 1 / 4 b 1 / 4 − q / 2 . (45) Interpr etation of equation 45 . • If q = 1 2 (bounded v ariance, i.i.d. mini-batching), then 1 / 4 − q / 2 = 0 and the leading-or der dependence on b cancels. This is precisely the “flatness in b ” phenomenon: once η and α are retuned for each b , the dominant term depends primarily on T = bK rather than on b itself. • If q < 1 2 (noise shrinks slower than b − 1 / 2 ), then 1 / 4 − q / 2 > 0 and the leading term incr eases with b ; the token-optimal batch size is pushed to ward the smallest feasible b . • If q > 1 2 (noise shrinks faster than b − 1 / 2 ), then 1 / 4 − q / 2 < 0 and larger batches become beneficial already at leading order . Therefore, the existence (and scaling) of an interior token-optimal batch si ze is not r ob ust : it relies on the finite-v ariance q = 1 2 law , plus lo wer-order terms (e.g. burn-in) that break the leading-order cancellation. This explains why the joint optimum b ⋆ T = Θ( T 1 / 6 ) should not be read as the only viable scaling: for bounded-v ariance noise, many choices of b ( T ) remain near-optimal once α ( T ) is tuned (momentum compensates for smaller batches), and the burn-in term selects b ⋆ T only through lower -order ef fects. III. Hea vy-tailed noise: both the b -law and the T -exponent can change. A common empirical observation in deep learning is that stochastic gradient noise can be hea vy-tailed, often modeled via α -stable laws [ 46 , 53 ]; in such re gimes the variance may be infinite and the classical b − 1 / 2 scaling can fail. In a stylized p -moment model with p ∈ (1 , 2) , a typical scaling for sample averages is noise magnitude ∝ b − (1 − 1 / p ) , i.e. q = 1 − 1 p < 1 2 . Plugging into equation 45 giv es min α,η U ∝ T − 1 / 4 b − 1 / 4+1 / (2 p ) , which increases with b for any p < 2 , again pushing the token-optimal b to ward small batches. Moreov er , under hea vy-tailed noise the optimal con vergence rate in T can itself dif fer from T − 1 / 4 (the finite-v ariance case), and depends on p . This indicates that mismatches between empirical scaling-law fits and finite-v ariance theory can reflect a genuinely different regime rather than just loose constants. IV . “V ariance” in non-Euclidean methods: which norm matters. For LMO/Muon, the stochastic terms are naturally expressed in the dual norm ∥ · ∥ ⋆ . Accordingly , a more intrinsic noise proxy is σ 2 ⋆ := sup x E ∥ g ( x ) − ∇ f ( x ) ∥ 2 ⋆ , rather than an ℓ 2 -v ariance. Using norm compatibility one can always upper bound ∥ v ∥ ⋆ ≤ ρ ∥ v ∥ 2 and therefore σ ⋆ ≤ ρσ 2 , but this can be loose and may hide dimension/model-size dependence in ρ (or in σ ⋆ itself). Hence, changing the noise model from an ℓ 2 vari ance bound to a ∥ · ∥ ⋆ -v ariance bound can change effecti ve constants and, when combined with model-size scaling, can affect fitted e xponents. 22 V . Parameter constraints also change appar ent exponents. All of the above assumes η and α can be freely retuned as T v aries. In practice, hyperparameters are constrained (e.g. α fixed, η capped for stability , discrete grids). Such constraints remove the cancellation behind equation 45 and can lead to dif ferent effecti ve power la ws (e.g. a “critical batch size” be yond which increasing b is harmful because η cannot be increased accordingly). C.3 Why can empirical fits show an optimal lear ning rate increasing with tok en budget? Sev eral empirical works report a one-dimensional fit η ⋆ ( T ) ∝ T q while scaling the token budget via T = bK . In contrast, our proxy bound is multi-variate and depends on ( b, K, α , η ) , so an “ η vs. T ” exponent is not intrinsic : it is conditional on the scaling path T 7→ ( b ( T ) , K ( T ) , α ( T ) , η ( T )) . A protocol identity for effectiv e exponents. Assume that over the (finite) range probed in practice, the tuned constant step size can be approximated by a separable power la w η ⋆ ( b, K ) ∝ b κ K − λ , κ ≥ 0 , λ ≥ 0 . (46) Along any batch-gro wth path b ( T ) ∝ T p (hence K ( T ) = T /b ( T ) ∝ T 1 − p ), equation 46 implies an effective tok en exponent η ⋆ ( T ) ∝ T q eff , q eff = κp − λ (1 − p ) . (47) In particular , q eff > 0 ⇐ ⇒ p > λ κ + λ . (48) Thus, ev en if η ⋆ decreases with the horizon at fixed batch ( λ > 0 ), a positiv e fitted exponent in T can arise if the batch-growth ef fect dominates. Instantiations f or our LMO pr oxy . (i) F ixed momentum pr oxy . Optimizing the proxy ov er η at fixed ( b, K, α ) gi ves η ⋆ ( b, K ) ∝ K − 1 / 2 , i.e. ( κ, λ ) = (0 , 1 2 ) . Hence q eff = − (1 − p ) / 2 ≤ 0 for any p : in the fixed-momentum proxy , η ⋆ ( T ) cannot increase with T . (ii) F ixed- b K -optimal schedules e valuated along T = bK . Minimizing the LMO proxy at fixed b yields (up to constants / lower -order terms) η ⋆ ( b, K ) ∝ b 1 / 4 K − 3 / 4 , α ⋆ ( b, K ) ∝ p b/K . Thus ( κ, λ ) = ( 1 4 , 3 4 ) and equation 47 giv es q eff = p − 3 4 . (49) Therefore, a positiv e fitted exponent is possible under batch-hea vy paths p > 3 / 4 . Ca veat: saturation of α ≤ 1 . The schedule abov e also implies α ⋆ ( T ) ∝ b/ √ T . Along b ( T ) ∝ T p , we hav e α ⋆ ( T ) ∝ T p − 1 / 2 , so for p > 1 / 2 one ev entually reaches a regime where α saturates at 1 , and the effecti ve η scaling transitions away from equation 49 . Connection to empirical scaling laws. This “path-conditioning” mechanism can e xplain why a study may report η ⋆ increasing with T ev en though the globally token-optimal schedules in our analysis yield a decreasing η ⋆ ( T ) . Howe ver , it does not guarantee matching e xponents. F or example, StepLa w reports (at fixed model size) b ⋆ ( T ) ∝ T 0 . 571 and η ⋆ ( T ) ∝ T 0 . 307 [ 32 ], i.e. p ≃ 0 . 571 < 3 / 4 but q ≃ 0 . 307 > 0 [ 32 ]. This cannot be explained by the LMO K -optimal proxy exponent q eff = p − 3 4 unless the ef fectiv e exponents ( κ, λ ) in equation 46 dif fer substantially from ( 1 4 , 3 4 ) , or the proxy assumptions fail. As another reference point, v on Rütte et al. [ 50 ] report b ⋆ ( T ) ∝ T 0 . 8225 and η ⋆ ∝ ( b ⋆ ) 0 . 3412 for dif fusion LMs, implying η ⋆ ( T ) ∝ T 0 . 28 ov er their explored range [ 50 ]. The batch e xponent p > 3 / 4 falls in the batch-heavy regime where positi ve q eff is possible, but the magnitude still differs from the LMO proxy , suggesting additional effects. So p − 3 / 4 is best viewed as one concrete mechanism (under a specific proxy + tuning protocol), not a general prediction for empirical scaling. 23 D Additional Plots Scaling plots. W e provide here complementary figures to those in the main te xt. 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h b ( t u n e d a t e a c h T , = 0 . 9 3 8 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( b t u n e d a t e a c h T , = 0 . 9 3 8 ) Numerical minimum ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 O p t i m a l b ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 1 1 0 9 1 0 7 1 0 5 1 0 3 O p t i m a l ( b t u n e d f o r e a c h T ) Numerical O ( T 1 / 4 ) O ( T 1 / 2 ) 0.0 2.1 4.2 6.4 8.5 10.6 12.7 14.8 log batchsize 15.0 12.3 9.6 6.9 4.2 1.6 1.1 3.8 log eta Figure 5: Numerical verification of Theorem 1 for β = 0 . 934 . 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h b ( t u n e d a t e a c h T , = 0 . 9 9 9 9 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( b t u n e d a t e a c h T , = 0 . 9 9 9 9 ) Numerical minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 O p t i m a l b ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 2 1 0 1 0 1 0 8 1 0 6 1 0 4 O p t i m a l ( b t u n e d f o r e a c h T ) Numerical O ( T 1 / 4 ) O ( T 1 / 2 ) 0.0 2.1 4.2 6.4 8.5 10.6 12.7 14.8 log batchsize 15.0 12.3 9.6 6.9 4.2 1.6 1.1 3.8 log eta Figure 6: Numerical verification of Theorem 1 for β = 0 . 9999 . 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 3 2 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 3 2 ) Numerical minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 8 1 0 6 1 0 4 1 0 2 1 0 0 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 4 1 0 1 2 1 0 1 0 1 0 8 1 0 6 1 0 4 1 0 2 1 0 0 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 3 / 4 ) O ( T 1 / 2 ) 10.0 8.6 7.2 5.8 4.3 2.9 1.5 0.1 log 1-momentum 15.0 12.3 9.6 6.9 4.3 1.6 1.1 3.8 log eta Figure 7: Numerical verification of Theorem 2 for b = 32 . 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 3 5 1 1 1 ) Numerical Minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 P e r f T f o r e a c h ( t u n e d a t e a c h T , b = 3 5 1 1 1 ) Numerical minimum O ( T 0 . 2 5 ) ( t h e o r y ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 5 1 0 3 1 0 1 1 0 1 1 0 3 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 1 / 2 ) O ( 1 ) 1 0 1 1 0 7 1 0 1 3 1 0 1 9 tok ens 1 0 1 1 1 0 9 1 0 7 1 0 5 1 0 3 1 0 1 1 0 1 1 0 3 O p t i m a l ( t u n e d f o r e a c h T ) Numerical O ( T 3 / 4 ) O ( T 1 / 2 ) 10.0 8.6 7.2 5.8 4.3 2.9 1.5 0.1 log 1-momentum 15.0 12.3 9.6 6.9 4.2 1.6 1.1 3.8 log eta Figure 8: Numerical verification of Theorem 2 for b = 35111 . 24 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 1 0 1 perfor mance Numerical O ( T 0 . 2 5 ) 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 0.0 1.1 2.3 3.4 4.5 5.7 6.8 7.9 log batchsize 16.0 14.0 12.0 10.1 8.1 6.1 4.1 2.1 log eta 8.0 6.9 5.7 4.6 3.5 2.3 1.2 0.1 log alpha 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 b m i n i m i z i n g p e r f o r m a n c e Numerical O ( T 1 / 6 ) 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 1 0 1 3 1 0 1 1 1 0 9 1 0 7 1 0 5 1 0 3 m i n i m i z i n g p e r f o r m a n c e Numerical O ( T 7 / 1 2 ) 1 0 2 1 0 6 1 0 1 0 1 0 1 4 1 0 1 8 1 0 2 2 tok ens 1 0 7 1 0 6 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 m i n i m i z i n g p e r f o r m a n c e Numerical O ( T 1 / 3 ) Figure 9: Numerical verification of Theorem 3 . Oscillations are due to the grid search and to similar performance among hyperparameter choices. See Appendix C.2 for further comments. Iso-loss curv es. As shown in Figure 10 , under fixed momentum, achie ving a certain tar get per- formance requires a minimum batch size. W e identify a trend of b ⋆ T ∝ T 1 / 2 as predicted by our theory . The saturation of the near -optimal line in the left panel indicates that, at large token budgets, performance becomes less sensitiv e to batch size scaling when the learning rate η is lower bounded, since smaller momentum requires proportionally smaller η . 1 0 2 1 0 9 1 0 1 6 1 0 2 3 1 0 0 1 0 3 1 0 6 1 0 9 1 0 1 2 batch size = 0 . 0 0 1 4 8 1 0 2 1 0 9 1 0 1 6 1 0 2 3 tok ens = 0 . 0 1 5 2 1 0 2 1 0 9 1 0 1 6 1 0 2 3 = 0 . 1 5 6 5.89 3.90 1.91 0.07 2.06 4.05 6.04 8.03 10.02 12.01 l o g 1 0 ( p e r f ) near optimal batch size b T 1 / 2 Figure 10: Contours of best achie v able performance versus batch size and number of tokens. Fix ed α at dif ferent v alue, tuned η ∈ [1 . 7 e − 6 , 1] . The red curve denotes the near -optimal (99% performance) batch size as a function of the number of tokens. Three r egimes and a hyperbolic ( K, √ b ) tradeoff (iso-performance cur ves). Fix a target lev el ε and let c := ε − const > 0 absorb terms independent of ( b, K ) . Assuming the learning rate is well tuned for each ( b, K ) (i.e., η minimizes the ∆ 0 / ( η K ) + Lη ( 7 2 + 2 α ) part of the bound), the remaining dependence on ( b, K ) can be summarized as u η ( b, K ) ≈ C det √ K + C burn K √ b + C floor √ b , where C det := 2 q ∆ 0 L ( 7 2 + 2 α ) , C burn := 2 ρσ α , C floor := 2 ρσ √ α . Setting u η ( b, K ) = c rev eals three regimes: 1. Iteration-limited ( b → ∞ ) with K min = ( C det /c ) 2 ; 25 2. Batch-limited ( K → ∞ ) with b min = ( C floor /c ) 2 ; 3. An intermediate tradeoff region where the burn-in term dominates, yielding K √ b ≈ C burn /c , i.e. √ b ∝ 1 /K . W e can also rearrange the equation into: c √ K − C det c √ b − C floor + C burn K = C det C floor + C burn K ≈ C det C floor + C burn K 0 where K 0 denotes a representativ e iteration scale used to approximate the slowly v arying 1 /K term. This mirrors the shifted-hyperbola iso-loss la w reported by v on Rütte et al. [ 50 ] (see their Eq. (7)), up to our use of √ b induced by the 1 / √ b noise scaling. When momentum is fixed, and learning rate is tuned, the hyperbolic relationship between batch size and iterations is sho wn in the middle panel of Figure 11 . Note that on the left panel, if α and η can be unrestrictedly tuned, the final performance achiev ed is higher than that of the middle and right panels. This is because a larger batch size requires a much smaller learning rate, which is often not realistic. If the η grid is lo wer bounded, then there is no significant dif ference in the achie vable performance between fixed α (middle) and jointly tuned α (right). 1 0 1 1 0 7 1 0 1 3 1 0 1 9 1 0 0 1 0 3 1 0 6 1 0 9 batch size = 0 . 0 0 3 3 5 1 0 1 1 0 7 1 0 1 3 1 0 1 9 iterations = 0 . 0 3 4 3 1 0 1 1 0 7 1 0 1 3 1 0 1 9 = 0 . 6 2 8 -5.1 -4.3 -3.6 -2.9 -2.2 -1.5 -0.8 -0.1 0.7 1.4 l o g 1 0 ( p e r f ) near optimal batch size Figure 11: Contours of best achiev able performance versus batch size and training iterations. Fixed α at various values, and tuned η ∈ [1 . 07 e − 7 , 1] . The red curve denotes the near-optimal (99% performance) batch size as a function of the number of iterations. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment