SWE‑Skills‑Bench: 실제 소프트웨어 개발에서 에이전트 스킬이 미치는 영향 분석
본 논문은 49개의 공개 소프트웨어 엔지니어링(SWE) 스킬을 실제 GitHub 레포지토리와 요구사항 문서에 매핑한 뒤, 스킬을 주입했을 때와 주입하지 않았을 때의 코드 수정·테스트 통과율을 비교한다. 결과는 39개의 스킬이 성능 향상을 전혀 보이지 않았으며, 전체 평균 향상폭은 단 1.2%에 불과함을 보여준다. 토큰 사용량은 스킬에 따라 -78%에서 +451%까지 크게 변동했지만, 성공률에는 큰 영향을 주지 않는다. 의미 있는 개선을 보인 …
저자: Tingxu Han, Yi Zhang, Wei Song
**1. 연구 배경 및 목적**
LLM 기반 에이전트가 소프트웨어 엔지니어링 작업을 자동화하는 사례가 급증하고 있다. 이때 “스킬”(Skill)이라는 구조화된 절차 지식 패키지를 추론 시점에 컨텍스트에 삽입해 모델에게 작업 수행 방법을 제공한다. 기존 연구는 스킬 자체의 효율성을 평가했지만, 실제 프로젝트‑레벨 요구사항을 만족시키는지에 대한 검증은 부족했다. 본 논문은 이러한 격차를 메우기 위해, 실제 GitHub 레포지토리와 명시적 수용 기준을 가진 요구사항 문서를 기반으로 스킬의 **한계점**과 **실제 효용**을 정량화한다.
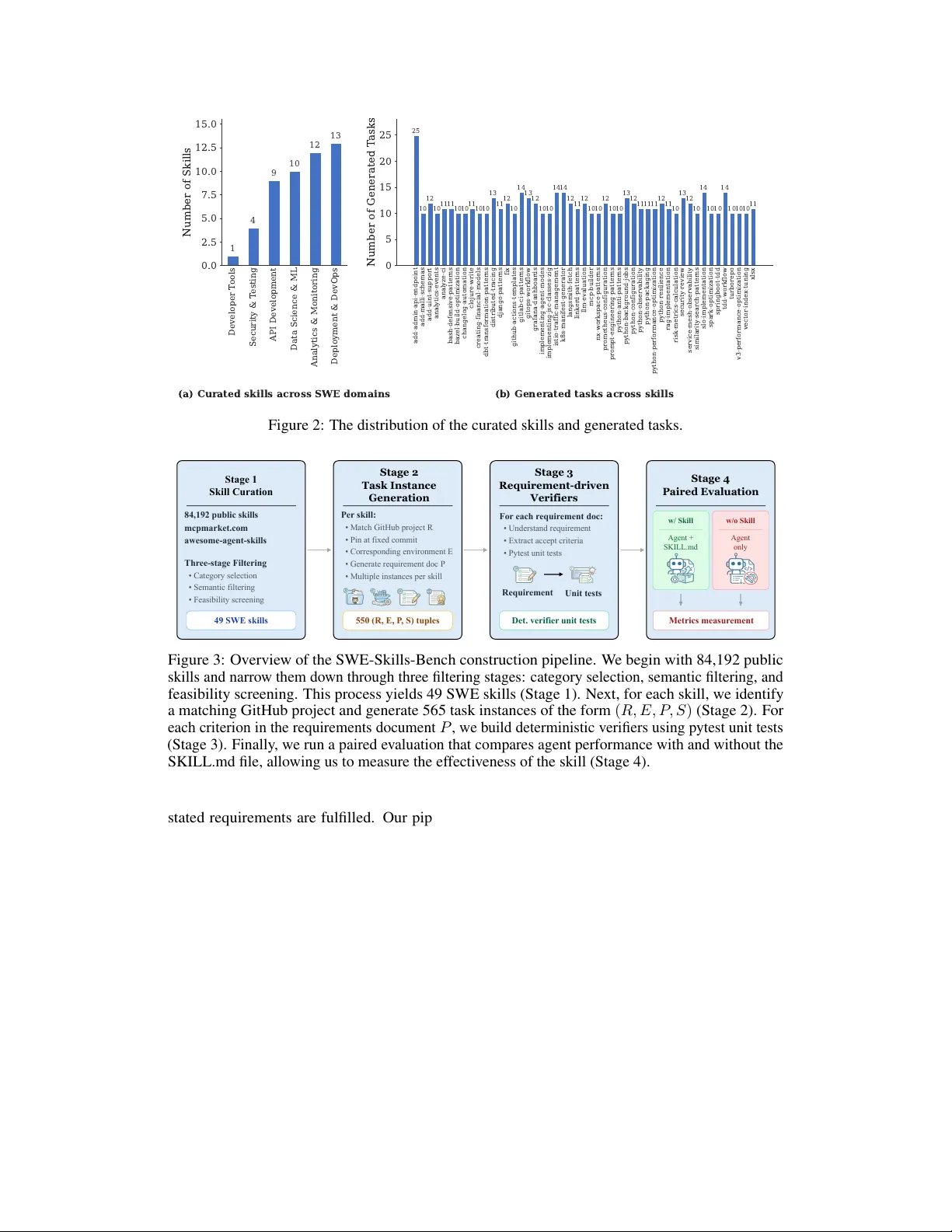
**2. SWE‑Skills‑Bench 설계**
- **스킬 선정**: 84 192개의 공개 스킬을 카테고리(개발 도구, 보안·테스트, API 개발, 데이터·ML, 배포·DevOps, 분석·모니터링)별로 필터링하고, 시맨틱·실현 가능성 검증을 거쳐 49개의 고품질 SWE 스킬을 추출하였다.
- **작업 인스턴스 생성**: 각 스킬당 평균 11개의 작업을 만들었다. 작업은 (레포지토리 R, 고정 커밋, 실행 환경 E, 요구사항 P, 스킬 S) 형태이며, 레포는 Docker 컨테이너에 복제해 재현성을 확보했다. 요구사항 문서는 배경, 핵심 목표, 파일 조작, 수용 기준 네 부분으로 구성돼 명확성을 높였다.
- **요구사항‑구동 검증**: 수용 기준을 자동으로 pytest 테스트로 변환하는 프롬프트를 설계했다. 생성된 테스트는 실제 코드 실행 결과와 비교해 성공 여부를 판단한다. 따라서 LLM‑as‑judge와 같은 주관적 평가를 배제하고, 완전한 **deterministic verification**을 구현했다.
**3. 실험 설정**
에이전트는 Claude Code 모델을 사용했으며, 두 조건을 비교했다. (1) 스킬 파일을 레포 루트에 배치해 에이전트가 자동으로 로드하도록 한 “With‑Skill” 조건, (2) 스킬 파일을 전혀 배치하지 않은 “Without‑Skill” 조건. 각 작업에 대해 에이전트는 요구사항을 읽고, 코드를 수정·추가·구성 파일을 생성해 테스트를 통과하도록 한다. 성능 지표는 테스트 통과율 차이(ΔP), 평균 토큰 사용량(C⁺/C⁻), 토큰 오버헤드 비율(ρ), 비용 효율성(CE)이다.
**4. 주요 결과**
- **대다수 스킬 무효**: 39/49 스킬이 ΔP = 0%를 기록했으며, 전체 평균 ΔP는 +1.2%에 머물렀다. 이는 스킬이 LLM의 자체 코딩 능력을 크게 보강하지 못한다는 것을 의미한다.
- **토큰 비용과 성공률 비연관**: 토큰 오버헤드는 -78%에서 +451%까지 다양했지만, ΔP와는 거의 상관관계가 없었다. 즉, 스킬이 컨텍스트 창을 채우는 방식이 토큰 사용량을 바꾸지만, 실제 코드 품질 향상에는 직결되지 않는다.
- **특정 스킬의 의미 있는 개선**: 금융 위험 모델, 클라우드 네이티브 트래픽 관리, GitLab CI 패턴 등 7개의 특화 스킬은 ΔP가 +10%~+30%까지 상승했다. 이들 스킬은 해당 도메인의 표준 절차와 강력히 연계돼 있어, 에이전트가 “무엇을 해야 하는가”보다 “어떻게 해야 하는가”를 명확히 제공한다.
- **버전·컨텍스트 충돌**: 3개의 스킬은 목표 레포와 버전·구조가 맞지 않아 오히려 ΔP가 -5%~ -10%까지 감소했다. 이는 스킬이 고정된 절차·템플릿을 제공하므로, 프로젝트별 관례와 충돌할 경우 역효과를 낼 수 있음을 보여준다.
**5. 논의 및 시사점**
- **도메인 적합성**: 스킬은 특정 분야에 특화될 때만 효과가 있다. 일반적인 “코드 작성”이나 “테스트 실행” 같은 광범위 스킬은 기존 LLM 능력과 중복돼 효용이 낮다.
- **추상화 수준**: 너무 추상적인 스킬은 구체적인 구현 지시를 제공하지 못하고, 너무 구체적인 스킬은 프로젝트 버전·구조와 충돌한다. 적절한 추상화 레벨(예: 특정 프레임워크·CI 패턴)과 최신 버전 유지가 필요하다.
- **컨텍스트 호환성**: 스킬 파일이 레포에 존재하면 에이전트는 무조건 이를 참고한다. 따라서 스킬이 프로젝트의 기존 관례와 일치하도록 사전 검증이 필요하다.
- **비용‑효율성**: 토큰 오버헤드가 크게 증가해도 성공률이 변하지 않으면 비용 효율성이 떨어진다. 실제 서비스에 스킬을 적용할 때는 토큰 비용과 기대 효과를 정량적으로 평가해야 한다.
**6. 결론 및 향후 연구**
SWE‑Skills‑Bench는 요구사항‑구동, 실행 기반 검증을 통해 스킬의 실제 개발 효용을 정량화한 최초의 벤치마크이다. 실험 결과는 스킬이 **좁은 영역**에서만 의미 있는 성능 향상을 제공하며, 대부분의 경우 토큰 비용만 증가시킨다는 점을 밝혀냈다. 향후 연구는 (1) 스킬 자동 생성·버전 관리 파이프라인, (2) 다중 스킬 조합 효과, (3) 다른 LLM·에이전트 모델에 대한 일반화 검증 등을 통해 스킬 기반 개발 지원 체계를 더욱 정교화할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기