SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
Agent skills, structured procedural knowledge packages injected at inference time, are increasingly used to augment LLM agents on software engineering tasks. However, their real utility in end-to-end development settings remains unclear. We present S…
Authors: Tingxu Han, Yi Zhang, Wei Song
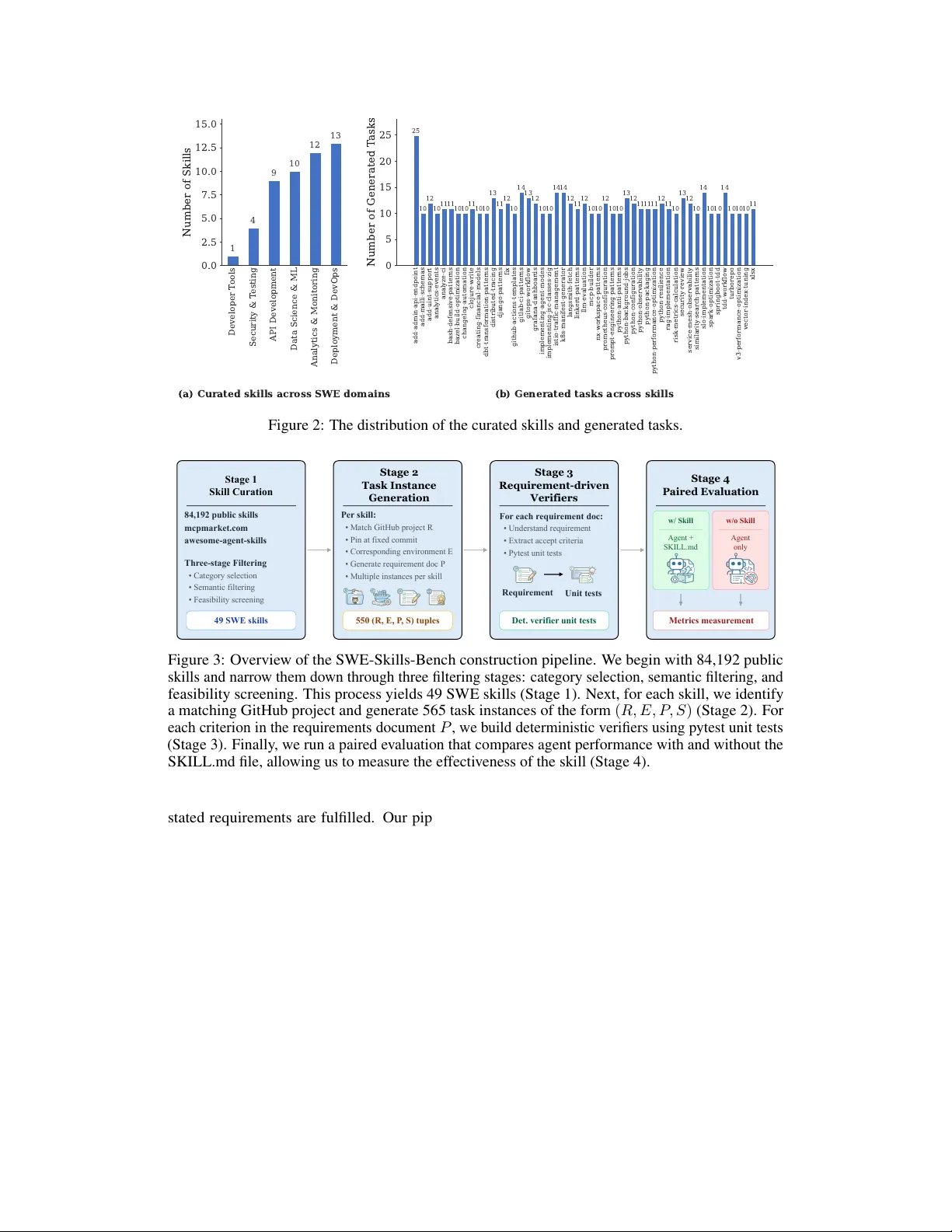
SWE-Skills-Bench: Do Agent Skills Actually Help in Real-W orld Softwar e Engineering? Tingxu Han ∗ Nanjing Univ ersity Mohamed bin Zayed Univ ersity of Artificial Intelligence txhan@smail.nju.edu.cn Y i Zhang South China Univ ersity of T echnology 202330580551@mail.scut.edu.cn W ei Song The Univ ersity of Ne w South W ales wei.song1@unsw.edu.au Chunrong F ang ‡ Nanjing Univ ersity fangchunrong@nju.edu.cn Zhenyu Chen Nanjing Univ ersity zychen@nju.edu.cn Y oucheng Sun Mohamed bin Zayed Univ ersity of Artificial Intelligence youcheng.sun@mbzuai.ac.ae Lijie Hu ‡ Mohamed bin Zayed Univ ersity of Artificial Intelligence lijie.hu@mbzuai.ac.ae Abstract Agent skills, structured procedural knowledge packages injected at inference time, are increasingly used to augment LLM agents on software engineering tasks. Howe v er , their real utility in end-to-end development settings remains unclear . W e present SWE-Skills-Bench , the first requirement-dri ven benchmark that isolates the marginal utility of agent skills in real-world software engineering (SWE). It pairs 49 public SWE skills with authentic GitHub repositories pinned at fixed commits and requirement documents with explicit acceptance criteria, yielding approximately 565 task instances across six SWE subdomains. W e introduce a deterministic verification framework that maps each task’ s acceptance criteria to ex ecution-based tests, enabling controlled paired e valuation with and without the skill. Our results show that skill injection benefits are far more limited than rapid adoption suggests: 39 of 49 skills yield zero pass-rate improvement, and the av erage gain is only +1 . 2% . T ok en ov erhead varies from modest savings to a 451% increase while pass rates remain unchanged. Only se ven specialized skills produce meaningful gains (up to +30% ), while three degrade performance (up to − 10% ) due to version-mismatched guidance conflicting with project context. These findings suggest that agent skills are a narro w intervention whose utility depends strongly on domain fit, abstraction level, and contextual compatibility . SWE-Skills-Bench provides a testbed for ev aluating the design, selection, and deployment of skills in softw are engineering agents. SWE-Skills-Bench is a v ailable at https://github.com/GeniusHTX/SWE- Skills- Bench . * W ork done during a research visit at MBZU AI. ‡ Corresponding Author . Pre-print with preliminary results, work in progress. Preprint. LLM SWE agents with a based LLM Select skill based on the input Wr it e C od e Run T ests Debug Create PR Deploymen t Update the calculate function so it supports add, sub, mul , and div through an op parameter while keeping addition as the default behavior for backward compatibility . SWE Requirement diff --git a/calculator.py b/calculator.py index 7a1c9ab..c42de91 100644 --- a/calculator.py +++ b/calculator.py @@ - 1,5 +1,14 @@ - def calculate(a, b): - return a + b +def calculate(a, b, op="add"): + if op == "add": Output Result s Figure 1: Illustration of how agent skills are used in a software engineering workflow . Given a natural-language requirement, the LLM-based agent selects the most relev ant skill from its skill library , including skills such as writing code, running tests, deb ugging, creating pull requests, and deploying, and injects it into the context window . The agent then ex ecutes a series of SWE actions to produce the final software artifacts (such as code) that fulfill the requirement. 1 Introduction LLM-based agents have been increasingly deployed across a wide range of software engineering (SWE) tasks, from automated code generation and bug fixing [ 1 ] to CI/CD pipeline configuration and infrastructure management [ 2 , 3 ]. Agent Skills are structured markdo wn packages that encode procedural kno wledge,standard operating procedures, code templates, and domain con ventions,for consumption by LLM-based agents [ 4 , 5 , 6 , 7 , 8 ]. At inference time, a skill is simply injected into the agent’ s context window as a reference document. Unlike fine-tuning or retriev al-augmented generation, no model modification or external retrie v al pipeline is required ( Figure 1 illustrates how agent skills work given a software engineering task). The ecosystem has grown explosi v ely: ov er 84,192 skills were created in just 136 days [ 9 ]. Despite this rapid adoption, no existing benchmark ev aluates SWE skills in real-world software dev elopment scenarios. T erminalBench [ 10 ] e valuates CLI tasks in multi-file repositories, but does not include a skill-augmentation condition. HumanEval [ 11 ] and BigCodeBench [ 12 ] target self- contained function completion without multi-file context or skill augmentation. SkillsBench [ 9 ] is the first cross-domain benchmark to ev aluate agent skills as first-class artifacts under paired skill conditions and deterministic v erification. Howe v er , it is not specifically designed for softw are engineering: SWE constitutes only 16 of its 84 tasks, and its primary goal is to measure broad cross-domain skill efficac y rather than requirement satisfaction in real-world dev elopment workflo ws. A principled benchmark for SWE skill utility must answer a decepti v ely simple question: Does the skill help the agent satisfy the task’s r equirements? Software engineering is inherently requirement- driv en [ 13 , 14 , 15 ]: a task succeeds when every acceptance criterion stated in its specification is met, and unit tests serve as the e xecutable encoding of those criteria. W e therefore adopt a requir ement- driven e valuation methodology: each task is anchored to a requirement document that defines scope and acceptance criteria, and deterministic verifiers based on unit tests are systematically deri ved from those criteria, establishing full traceability from requirements to test verdicts. Building on this methodology , we present SWE-Skills-Bench , a benchmark designed to isolate the marginal utility of agent skills for software engineering. W e curate 49 SWE skills from public repositories, pair each with an authentic GitHub project pinned at a fixed commit, and ev aluate under controlled with-skill vs. without-skill conditions. All task instances are verified by deterministic, ex ecution-based checks with no reliance on LLM-as-judge ev aluation. Our main contributions are as follo ws: • Benchmark. W e build SWE-Skills-Bench, a benchmark of 49 real-world SWE skills with ∼ 11 task instances per skill ( ∼ 565 total). T asks are sourced from public skill repositories and e valuated on fixed-commit GitHub projects in containerized en vironments. 2 T able 1: Comparison of SWE-Skills-Bench with existing benchmarks. “Skill Cond. ” indicates whether the benchmark includes agent skills. “Det. V erifier” indicates whether deterministic (non- LLM) verification is included. “SWE-F ocused” indicates whether the benchmark is specifically designed for software engineering tasks. Benchmark Size Skill Cond. Real Projects Det. V erifier SWE-Focused SWE-Bench V erified [ 1 ] 500 None Y es Y es Y es T erminalBench [ 10 ] 200 None Y es Y es Y es HumanEval [ 11 ] 164 None No Partial No SkillsBench [ 9 ] 84 Y es Y es Y es Partial SWE-Skills-Bench 565 Y es Y es Y es Y es • Requirement-dri ven test harness. W e design an automated unit-testing mechanism that translates each SWE requirement into executable test cases, deterministically verifying whether the specified requirement is fulfilled under both with-skill and without-skill conditions. • Empirical findings. 1 Skill injection yields limited marginal gains: 39 of 49 skills produce ∆ P = 0 , and the average pass-rate improvement is a modest +1 . 2% . 2 T oken ov erhead is decoupled from correctness: ev en among skills with zero delta, the token ov erhead ratio ρ ranges from − 78% to +451% , indicating that skills reshape the agent’ s reasoning path without necessarily improving outcomes. 3 A small subset of 7 skills encoding specialized procedural knowledge—financial risk formulas, cloud-native traffic management, and GitLab CI patterns—deliv ers meaningful gains up to +30% . 4 Three skills produce negativ e deltas (up to − 10% ) when their version-specific con ventions conflict with the target project’ s framew ork, demonstrating that skill injection carries a structural risk of context interference. These results establish that SWE skill utility is highly domain-specific and context-dependent, fa v oring targeted skill design o ver blank et adoption. 2 Related Benchmarks & Datasets W e org anize related work into tw o threads: SWE- and Skill-related benchmarks. Generally , SWE- related benchmarks does not include skills in their evaluation, Skill-related benchmarks does focus on SWE tasks. T o the best of our knowledge, we are the first benchmark to ev aluate agent skills in software engineering. T able 1 summarizes the key dif ferences. SWE-related Benchmarks. This line of w ork can be further di vided into SWE real-world bench- marks and code generation benchmarks. SWE real-world benchmarks focus on realistic, project-le vel software engineering tasks with execution-based v erification. SWE-Bench V erified [ 1 ] is a human- v alidated subset of 500 instances from SWE-Bench, dra wn from 12 Python repositories and ev aluated via fail-to-pass tests. T erminalBench [ 10 ] ev aluates agents on 200 realistic CLI tasks in containerized en vironments and provides methodological inspiration for our ev aluation setup. Ho wev er , these benchmarks do not isolate the marginal benefit of injecting procedural skill documents. Code generation benchmarks, in contrast, mainly ev aluate models on self-contained coding problems (often algorithmic or snippet-lev el) without full project context. HumanEv al [ 11 ] comprises 164 hand-crafted programming challenges at the function lev el, and therefore does not capture multi-file reasoning, dependency management, or end-to-end SWE workflo ws. Skills Benchmarks. SkillsBench [ 9 ] takes an important first step toward benchmarking skills as first-class artifacts by comparing agent performance across dif ferent skill conditions. Nev ertheless, it is not SWE-specific: software engineering forms only a limited subset of its task suite, and the benchmark is not designed around the central success criterion in real-world de velopment—whether explicit requirements are satisfied in repository-grounded workflows. Our work addresses this gap by constructing a requirement-dri ven benchmark focused exclusi vely on SWE, where each skill is paired with fixed-commit repositories, explicit requirements, and deterministic ex ecution-based verification. 3 SWE-Skills-Bench Construction Constructing SWE-Skills-Bench requires answering three key questions in sequence: which skills to benchmark, how to pair each skill with authentic task instances, and how to verify that the 3 Developer T ools Security & T esting API Development Data Science & ML Analytics & Monitoring Deployment & DevOps 0.0 2.5 5.0 7.5 10.0 12.5 15.0 Number of Skills 1 4 9 10 12 13 add-admin-api-endpoint add-malli-schemas add-uint-support analytics-events analyze-ci bash-defensive-patterns bazel-build-optimization changelog-automation clojure-write creating-financial-models dbt-transformation-patterns distributed-tracing django-patterns fix github-actions-templates gitlab-ci-patterns gitops-workflow grafana-dashboards implementing-agent-modes implementing-jsc-classes-zig istio-traffic-management k8s-manifest-generator langsmith-fetch linkerd-patterns llm-evaluation mcp-builder nx -workspace-patterns prometheus-configuration prompt-engineering-patterns python-anti-patterns python-background-jobs python-configuration python-observability python-packaging python-performance-optimization python-resilience rag-implementation risk -metrics-calculation security-review service-mesh-observability similarity-search-patterns slo-implementation spark -optimization springboot-tdd tdd-workflow turborepo v3-performance-optimization vector-index -tuning xlsx 0 5 10 15 20 25 Number of Generated T asks 25 10 12 10 11 11 10 10 11 10 10 13 11 12 10 14 13 12 10 10 14 14 12 11 12 10 10 12 10 10 13 12 11 11 11 12 11 10 13 12 10 14 10 10 14 10 10 10 11 (a) Curated skills across SWE domains (b) Generated tasks across skills Figure 2: The distribution of the curated skills and generated tasks. Stage 1 Skill Curation 84,192 public skills mcpmarket.com awesome - agent - skills Three - stag e Filtering • Category select ion • Semantic fi ltering • Feasibility screening 49 SWE skills Stage 2 Task Instan ce Generation Per skill: • Match GitHub pr oject R • Pin at fi xed commit • Corresponding environment E • Generate requirement doc P • Multip le instances per skill 550 (R, E, P , S) tuples Stage 3 Requirement - driven Verifier s For each requ irement doc: • Understand r equirement • Extract accept criteria • P ytest unit tests Det. verifier unit tests Stage 4 Paired Evaluati on Requirement Unit tests w/ Skill Agent + SKILL.md w/o Skill Agent only Metrics measurement Figure 3: Overview of the SWE-Skills-Bench construction pipeline. W e begin with 84,192 public skills and narrow them do wn through three filtering stages: category selection, semantic filtering, and feasibility screening. This process yields 49 SWE skills (Stage 1). Next, for each skill, we identify a matching GitHub project and generate 565 task instances of the form ( R, E , P , S ) (Stage 2). For each criterion in the requirements document P , we build deterministic verifiers using pytest unit tests (Stage 3). Finally , we run a paired e valuation that compares agent performance with and without the SKILL.md file, allowing us to measure the ef fecti v eness of the skill (Stage 4). stated requirements are fulfilled. Our pipeline proceeds in four stages ( Figure 3 ): (1) curating a representativ e set of SWE skills from large public repositories, (2) generating task instances by pairing each skill with a fixed-commit GitHub project and a requirement document, (3) designing deterministic verifiers that are traceable to the acceptance criteria in each requirement document. 3.1 Skill Curation The skill ecosystem is vast (84,192 skills created in 136 days [ 9 ]) but highly heterogeneous in quality , scope, and ev aluability . W e curate a deterministic, unit-testable subset through a three-stage filtering pipeline. First, we scan the mcpmarket category leaderboard and select six of the nine core categories that best align with software-engineering workflo ws and are amenable to unit-test e valuation: Developer T ools, Security & T esting, API Development, Data Science & ML, Deployment & DevOps, and Analytics & Monitoring. Second, we apply semantic filtering to exclude generati ve or subjectiv e skills, retaining only those that target concrete SWE actions such as fix , build , and develop . Third, we exclude candidates whose associated repositories are prohibitiv ely large or incur high en vironment and setup costs. This pipeline yields 49 skills distributed across the six categories: Deployment & De vOps (13), Analytics & Monitoring (12), API De velopment (10), Data Science & ML (9), Security & T esting (4), and Dev eloper T ools (1). Figure 2 (a) illustrates the distribution. 4 Project Matching Skill Placement • Place the skill definition document in the project root. • Agent loads and utilizes the skill. Requirement Authorin g • Generate a na tural- language requirement document. • Independent of skill content. • Identify authentic open - source GitHub project. • Pinned at a fixed commit. Figure 4: The pipeline of task instance generation. 3.2 T ask Instance Generation As sho wn in Figure 4 , for each curated skill s , we construct approximately 10 task instances follo wing a three-step procedure. Project matching . W e identify an authentic, open-source GitHub project whose technology stack aligns with the skill’ s domain. The repository is pinned at a fixed commit to ensure reproducibility . Note that we also create a docker container for running each project. Requirement authoring . Each requirement P is authored to be specific to its target repository and skill-triggering conditions. T o maximize structural clarity and eliminate ambiguity , e very P adheres to a standardized template comprising: (i) Background, providing the necessary task context; (ii) Requirement, defining the core objectiv e; (iii) File Operations, specifying the files to be modified or created; and (iv) Acceptance Criteria, of fering deterministic success metrics. Figure 7 illustrates the prompt utilized to author the requirement and Figure 8 an example of the generated requirement. Skill placement. During the container preparation phase, the system remov es the .claude/skills directory from the repository to eliminate interference from pre-existing skills. The acti vation of skill S is governed by a file-lev el injection mechanism: the skill document S is copied into the ~/.claude directory only when the experimental condition requires its use; otherwise, it is omitted. The agent automatically detects and inte grates any skills present in this en vironment. Importantly , the requirement document P nev er references S , ensuring that the agent’ s behavior is gov erned strictly by the physical presence of the skill configuration. T otally , for each skill, we generate around 10 instances where detailed distributions in Figure 2 (b). 3.3 Requirement-dri ven V erification The core principle of SWE-Skills-Bench is requir ement-driven verification . Rather than relying on subjective judgments, we con vert ev ery acceptance criterion in the requirement document P into objecti ve, deterministic tests, ensuring that each test outcome is directly traceable to a specific requirement. W e provide P (together with repository metadata such as repo path, language, and av ailable test commands) to a fixed “professional test engineer” prompt template, which instructs the model to (i) enumerate testable behaviors from each acceptance criterion, (ii) instantiate representati ve and edge-case scenarios, and (iii) encode them into a deterministic pytest test file with strong discriminativ e po wer (i.e., tests must run the produced code and verify concrete outputs/structures rather than keyword-le v el heuristics). The prompt also enforces structural constraints such as a minimum number of test cases and per-test docstrings. The prompt template is shown in Figure 6 . Concretely , for each instance we create a container from a base image, clone the target repository into the container workspace, and complete en vironment setup. W e then pass the task document (i.e., the requirement document P ) through the abov e prompt template to driv e test generation, and use the task document as the prompt to Claude Code for implementation. 3.4 T ask F ormulation Each task instance is a tuple ( R, E , P , S ) : a GitHub repository R pinned at a fixed commit and the corresponding containerized running en vironment, a natural-language requirement document P that specifies tasks, and optionally a skill document S . The agent (claude code specifically) must produce code changes, configuration files, or ex ecution artifacts that satisfy the requirements in P giv en the code repository R and en vironment E . 5 T able 2: Evaluation results across all 49 skills. Pass + and Pass − denote pass rates with and without skill injection, respectiv ely . ∆ P is the skill utility delta, C + and C − are av erage token costs, ρ is the token ov erhead ratio, and CE is cost efficiency . Best viewed in color . Skills # T asks Pass + Pass − ∆ P C + C − ρ CE add-uint-support 12 100.0% 100.0% 0.0% 880K 414K +112.6% — analytics-events 10 100.0% 100.0% 0.0% 321K 157K +104.6% — analyze-ci 11 100.0% 100.0% 0.0% 66K 74K -10.6% — dbt-transformation-patterns 10 100.0% 100.0% 0.0% 422K 208K +103.2% — gitops-workflow 13 100.0% 100.0% 0.0% 130K 57K +127.1% — grafana-dashboards 12 100.0% 100.0% 0.0% 150K 116K +29.3% — implementing-agent-modes 10 100.0% 100.0% 0.0% 342K 655K -47.8% — k8s-manifest-generator 14 100.0% 100.0% 0.0% 98K 51K +91.2% — langsmith-fetch 12 100.0% 100.0% 0.0% 102K 97K +5.9% — llm-evaluation 12 100.0% 100.0% 0.0% 238K 203K +17.6% — mcp-builder 10 100.0% 100.0% 0.0% 273K 200K +36.1% — nx-workspace-patterns 10 100.0% 100.0% 0.0% 417K 365K +14.5% — prometheus-configuration 12 100.0% 100.0% 0.0% 225K 312K -27.8% — python-anti-patterns 10 100.0% 100.0% 0.0% 274K 490K -44.1% — python-background-jobs 13 100.0% 100.0% 0.0% 839K 249K +236.8% — python-observability 11 100.0% 100.0% 0.0% 271K 105K +157.5% — python-packaging 11 100.0% 100.0% 0.0% 167K 74K +123.9% — python-performance-optimization 11 100.0% 100.0% 0.0% 91K 96K -5.1% — python-resilience 12 100.0% 100.0% 0.0% 119K 529K -77.6% — rag-implementation 11 100.0% 100.0% 0.0% 258K 179K +44.5% — service-mesh-observability 12 100.0% 100.0% 0.0% 733K 133K +450.8% — slo-implementation 14 100.0% 100.0% 0.0% 144K 241K -40.2% — spark-optimization 10 100.0% 100.0% 0.0% 223K 180K +23.9% — v3-performance-optimization 10 100.0% 100.0% 0.0% 237K 544K -56.4% — add-admin-api-endpoint 25 84.0% 84.0% 0.0% 243K 232K +4.4% — add-malli-schemas 10 90.0% 90.0% 0.0% 646K 433K +49.2% — bash-defensive-patterns 11 90.9% 90.9% 0.0% 565K 231K +144.3% — bazel-build-optimization 10 90.0% 90.0% 0.0% 316K 790K -60.0% — changelog-automation 10 70.0% 70.0% 0.0% 128K 274K -53.3% — clojure-write 11 81.8% 81.8% 0.0% 579K 869K -33.4% — creating-financial-models 10 90.0% 90.0% 0.0% 197K 195K +0.7% — fix 12 91.7% 91.7% 0.0% 202K 80K +153.0% — github-actions-templates 10 70.0% 70.0% 0.0% 85K 61K +39.1% — implementing-jsc-classes-zig 10 90.0% 90.0% 0.0% 1.1M 940K +22.0% — python-configuration 12 91.7% 91.7% 0.0% 199K 154K +29.7% — security-review 13 92.3% 92.3% 0.0% 301K 299K +0.9% — turborepo 10 50.0% 50.0% 0.0% 753K 262K +187.9% — vector-index-tuning 10 90.0% 90.0% 0.0% 475K 400K +18.8% — xlsx 11 36.4% 36.4% 0.0% 1.5M 1.8M -18.1% — risk-metrics-calculation 10 100.0% 70.0% +30.0% 507K 778K -34.8% -0.86 gitlab-ci-patterns 14 78.6% 64.3% +14.3% 326K 205K +58.6% 0.24 prompt-engineering-patterns 10 100.0% 90.0% +10.0% 218K 149K +46.4% 0.22 similarity-search-patterns 10 100.0% 90.0% +10.0% 144K 213K -32.4% -0.31 distributed-tracing 13 100.0% 92.3% +7.7% 115K 165K -30.4% -0.25 tdd-workflow 14 28.6% 21.4% +7.1% 148K 83K +78.6% 0.09 istio-traffic-management 14 100.0% 92.9% +7.1% 95K 121K -22.0% -0.32 springboot-tdd 10 70.0% 80.0% -10.0% 236K 374K -36.8% 0.27 linkerd-patterns 11 90.9% 100.0% -9.1% 248K 165K +50.3% -0.18 django-patterns 11 81.8% 90.9% -9.1% 482K 462K +4.2% -2.16 A verage 565 91.0% 89.8% +1.2% 335K 303K +10.5% — In our ev aluation methodology , ev ery acceptance criterion in the requirement document P is mapped to deterministic verifier , establishing full traceability from requirements to test verdicts. 4 Results of SWE-Skills-Bench 4.1 Experimental Setup All experiments run in Docker containers (Ub untu 24.04, CPU-only) with per -task resource limits specified in the task configuration. The agent is Claude Code [ 16 ] with the Claude Haiku 4.5. For each task, we ev aluate it under use-skill or no-skill conditions. In the use-skill condition, SKILL.md 6 is placed in the project root directory . The agent discovers and applies it autonomously without explicit instruction. 4.2 Evaluation Metrics Let T s = { t 1 , . . . , t N } denote the set of N task instances associated with skill s . For each instance t i , let v + i ∈ { 0 , 1 } and v − i ∈ { 0 , 1 } be the binary pass/fail verdicts under the with-skill and without-skill conditions, respecti vely , and let c + i and c − i be the corresponding token costs (total input and output tokens consumed by the agent). • Pass Rate. The primary metric. For each condition: Pass + ( s ) = 1 N N X i =1 v + i , Pass − ( s ) = 1 N N X i =1 v − i (1) • Skill Utility Delta ( ∆ ). Measures the marginal benefit of skill injection: ∆ P ( s ) = P ass + ( s ) − Pass − ( s ) (2) Positi ve ∆ indicates the skill helps, zero indicates irrelev ance, and negati v e ∆ indicates interference. • T oken Cost. The average tok en consumption per condition (with ( + ) or without ( − ) skills): C + ( s ) = 1 N N X i =1 c + i , C − ( s ) = 1 N N X i =1 c − i (3) and the token ov erhead ratio induced by skill injection: ρ ( s ) = C + ( s ) − C − ( s ) C − ( s ) (4) A positiv e ρ indicates that the skill increases token consumption; comparing ρ with ∆ rev eals whether skill-induced gains justify their inference cost. • Cost Efficiency . T o jointly assess performance gains and token overhead, we define the cost efficienc y of a skill as: CE( s ) = ∆ P ( s ) ρ ( s ) , (5) Intuitiv ely , CE( s ) quantifies the success-rate improvement obtained per unit of relative token increase. Larger positiv e v alues indicate greater performance gains per token cost, whereas negativ e values indicate that the skill either de grades performance or incurs disproportionate ov erhead. 4.3 Evaluation Results T able 2 presents the full e valuation results across all 49 skills. At the aggregate le vel, skill injection raises the average pass rate by a modest +1 . 2% (from 89.8% to 91.0%) while increasing av erage token consumption by 10 . 5% . Beneath these averages, howev er , the per-skill behavior is highly heterogeneous. W e structure our analysis around fiv e ke y findings that sho w when skills help, when they are redundant, and when the y activ ely disrupt the agent’ s reasoning. Finding 1: Skill injection yields limited marginal gains on pass rate. For the 49 e v aluated skills, 39 (roughly 80%) produce ∆ P = 0 , meaning that skill injection neither helps nor hurts the agent’ s task-lev el success rate. Among these, 24 skills achieve Pass + = Pass − = 100% , indicating that the base model already possesses suf ficient capability to solve e v ery task instance without any skill guidance. The remaining 15 skills share identical but imperfect pass rates across conditions (e.g., xlsx at 36.4%, turborepo at 50.0%). This suggests that the bottleneck lies not in the absence of domain knowledge, which the skill ostensibly provides, but in deeper capability gaps such as complex multi-step reasoning, unfamiliar API surfaces, or brittle ev aluation harnesses. For these skills, improving pass rates likely requires either fundamentally rethinking the skill content, upgrading the base model, or relaxing ev aluation criteria, rather than simply injecting more contextual guidance. Overall, in software engineering, the average skill utility delta is +1 . 2% , confirming that skill 7 injection is not a univ ersal performance booster but rather a targeted interv ention whose benefits are concentrated in a small subset of skills. Finding 2: T oken ov erhead is decoupled from performance gains. Even when ∆ P = 0 , skills can still have a large impact on inference cost. Within the 24 skills that achiev e perfect pass rates in both conditions, the token overhead ratio ρ ranges from − 77 . 6% ( python-resilience ) to +450 . 8% ( service-mesh-observability ). This spread shows that injecting a skill can change the agent’ s reasoning path without changing the final result. In some cases, it makes the reasoning more efficient, while in others, it lengthens the process with redundant exploration. Of the 24 skills with perfect scores in both conditions, 8 use fewer tokens when the skill is injected ( ρ < − 5% ). The savings are sometimes lar ge, reaching 77 . 6% for python-resilience and 56 . 4% for v3-performance-optimization . This suggests that these skills guide the agent toward a more direct solution path. But more generally , the other 16 skills use more tokens under skill injection ( ρ > +5% ), often by a wide margin. For example, service-mesh-observability incurs a 450 . 8% ov erhead, and python-background-jobs incurs a 236 . 8% ov erhead. Crucially , ρ and ∆ P exhibit no consistent correlation across the full set of 49 skills: several skills with ∆ P > 0 simultaneously reduce token consumption (e.g., risk-metrics-calculation with ρ = − 34 . 8% ), while many ∆ P = 0 skills dramatically increase it. This decoupling implies that the mechanisms by which skills affect reasoning ef ficienc y are largely independent of those that af fect correctness. Finding 3: A small subset of skills delivers meaningful improvements. Sev en skills achiev e ∆ P > 0 , with gains ranging from +7 . 1% to +30 . 0% . The most effecti v e skill, risk-metrics-calculation ( ∆ P = +30 . 0% , ρ = − 34 . 8% ), simultaneously improves cor- rectness and reduces token cost, representing the ideal outcome of skill injection. At the other end, tdd-workflow yields a modest +7 . 1% improv ement at the expense of a 78 . 6% token overhead, resulting in low cost ef ficienc y ( CE = 0 . 09 ). In this scenario, the agent achiev es better performance at the cost of using many more tokens. This is because the skill functions as a checklist. It forces the agent to attend to edge case deliverables that are often overlook ed in the no-skill setting. This added structure can improve correctness by making the agent more likely to cover required but easily missed steps. Howe ver , this added coverage also requires more v erification and follo w-through, so the gains often come with higher token costs. Finding 4: Skills can actively degrade performance through context interference. Three skills exhibit negativ e ∆ P : springboot-tdd ( − 10 . 0% ), linkerd-patterns ( − 9 . 1% ), and django-patterns ( − 9 . 1% ). These regressions point to a structural risk inherent in the skill injec- tion mechanism: the mismatch between the holistic scope of a skill and the focused requirements of individual tasks. Each skill is authored as a comprehensiv e reference for its technical domain, encoding best practices that span architecture, coding con v entions, testing strategies, and error han- dling. When a task exercises only a narro w slice of this kno wledge, the surplus context can interfere with the agent’ s reasoning in sev eral ways. First, the rich set of patterns and strategies described in the skill unnecessarily expands the agent’ s decision space, prompting deliberation over design choices the task does not w arrant. Second, production-grade templates may steer the agent to ward ov er-fitted solutions that rigidly follo w the skill’ s examples rather than adapting to the task’ s actual requirements. Third, the skill text itself competes for the finite context window , displacing tokens that would otherwise be de voted to understanding the task description and the codebase. The linkerd-patterns case illustrates this mechanism as shown in Figure 5 . The task asks the agent to produce a Server CRD and a ServerAuthorization CRD that enforce mTLS identity verification for a gRPC servic e. The skill packages sev en templates co vering the full Link erd stack, installation, namespace injection, service profiles, traffic splitting, serv er authorization, HTTPRoute, and multi-cluster setup. Among them, T emplate 5 demonstrates exactly the two CRDs the task requires, but with different concrete values: it uses API version v1beta1 with proxyProtocol: HTTP/1 , and sho ws multiple authorization modes including both meshTLS and unauthenticated access with CIDR ranges. This near-match triggers se vere conte xt pollution, thereby interfering with the model’ s understanding of the task. W ithout skill injection, the agent reasons from first principles and produces a correct solution: it selects v1beta3 for the Server , sets proxyProtocol: gRPC to match the application, and configures ServerAuthorization with the standard client.meshTLS.serviceAccounts field. W ith the skill injected, T emplate 5 anchors the agent and the errors compound through three stages: 8 Ta s k : Add Linkerd mTLS V erification Example. Create server - policy .yaml containing a Server CRD selecting the server pods and a ServerAuthoriza tion CRD requiring mTLS ident ity . Res trict access to only the client's ServiceAccount i dentity . Skill T emplate 5 (Injected) # Template 5: Server Authorization apiVersion: policy.linkerd.io/v1beta1 kind: Server spec: podSelector : matchLabels : app: {{ .app }} port: {{ .port }} proxyProtocol: HTTP/1 --- meshTLS: serviceAccounts: - name: {{ .sa }} unauthenticated: true networks: - cidr: 10.0.0.0/8 kind: NetworkPolic y (a) Wi thout Skill # Server CRD apiVersion: .../v1beta3 kind: Server metadata: name: mtls - server - grpc spec: podSelector: matchLabels: app: mtls - server port: 9090 proxyProtocol: gRPC # ServerAuthorization CRD client : meshTLS: serviceAccounts: - name: mtls - client (b) Wi th Skill # Server CRD apiVersion: .../v1beta1 kind: Server metadata: name: server spec: podSelector: matchLabels: app: server port: http proxyProtocol: HTTP/1 # ServerAuthorization CRD rules : - metricsServers: - kind: ServiceAccount name: client # Unrequested resource kind: NetworkPolicy ... 1 2 3 1 2 3 Figure 5: Context interference in the linkerd-patterns skill ( ∆ P = − 9 . 1% ). The task requires a Server CRD and a ServerAuthorization CRD enforcing mTLS identity verification for a gRPC service. Left: T emplate 5 from the injected skill, which near-matches the task but encodes different concrete values: API version v1beta1 with proxyProtocol: HTTP/1 , and multiple authorization modes (meshTLS, unauthenticated, and CIDR-based). Center: W ithout the skill, the agent reasons from first principles and produces a correct solution using v1beta3 , gRPC , and standard meshTLS.serviceAccounts . Right: W ith the skill, the agent’ s output degrades through three stages, each traceable to a specific region of the template (matched by circled numbers): 1 Surface anchoring, the agent copies v1beta1 and HTTP/1 verbatim; 2 Hallucination, while reconciling the template’ s mixed authorization modes, the agent fabricates a nonexistent rules/metricsServers field; 3 Concept bleed, the template’ s NetworkPolicy example causes the agent to append an unrequested resource, conflating Linkerd-le vel and K ubernetes-le vel authorization. 1. Surface anchoring. The agent copies the template’ s API version ( v1beta1 ) and protocol ( HTTP/1 ) verbatim instead of adapting them to the task’ s gRPC context. The template’ s concrete values o verride the agent’ s own kno wledge of the correct configuration. 2. Hallucination. While attempting to reconcile the template’ s authorization pattern with the task’ s identity-verification requirement, the agent fabricates a nonexistent rules / metricsServers field in the ServerAuthorization spec—a field that appears in no version of the Linkerd CRD. The cogniti ve load of processing se ven templates simultaneously degrades the agent’ s ability to distinguish valid API fields from plausible-sounding constructs. 3. Concept bleed. The agent appends an unrequested NetworkPolicy resource, conflating T em- plate 5’ s multiple authorization modes (meshTLS identity , unauthenticated access, CIDR-based network rules) with the Kubernetes-nati ve NetworkPolicy API. The skill’ s broad coverage causes concepts from adjacent domains to leak into the solution. This explains the seemingly paradoxical outcome: a skill containing objectively rele vant content nonetheless de grades performance. The practical implication is that skill design should fa vor abstract guidance patterns over concrete, opinionated templates with hard-coded parameter values, as the latter risk anchoring the agent on specifics that may not transfer to the target task. 5 Discussion & Future Dir ections SWE-Skills-Bench is an ongoing ef fort to ward systematically understanding how procedural skill injection affects LLM-based software engineering agents. The results presented in this paper represent a snapshot of a larger , acti vely e v olving research program. While our current findings already reveal sev eral actionable insights, most notably that skill utility is highly domain-specific and that conte xt interference is a tangible risk, the benchmark in its present form cov ers only a fraction of the design space. W e vie w this work as laying the foundation and e valuation methodology; substantial e xtensions along multiple axes are underway and planned. 9 Multi-model e valuation. All e xperiments in this work use a single agent configuration: Claude Code with Claude Haiku 4.5. Skill utility , howe ver , is likely modulated by the base model’ s existing kno wl- edge and reasoning capabilities. A stronger model may already internalize the procedural knowledge encoded in a skill, rendering the skill redundant, while a weaker model may lack the capacity to effecti v ely le verage the injected context. W e plan to ev aluate SWE-Skills-Bench across a div erse set of foundation models—varying in scale, training data composition, and architecture—to disentangle model-intrinsic capability from skill-induced impro vement and to identify which model–skill pairings yield the most fa vorable cost–performance trade-of fs. Diverse agent scaffolds. Beyond the choice of foundation model, the agent scaffold, i.e., the orchestration framew ork that gov erns tool use, planning, and context management, can significantly mediate how a skill is consumed. Different scaffolds may allocate context budgets differently , employ distinct retrie val strate gies for long skill documents, or impose varying le vels of structure on the agent’ s reasoning trace. W e intend to benchmark skill utility across multiple open-source and proprietary agent frame works (e.g., SWE-agent, OpenHands, Aider) to assess whether our findings generalize beyond the specific scaf fold used in this study . Skill design principles. Our analysis of context interference (Finding 4) suggests that the form of a skill, not just its content, plays a critical role in determining utility . Skills that rely on concrete, opinionated templates with hard-coded parameter v alues risk anchoring the agent on specifics that may not transfer to the tar get task, whereas skills that encode abstract guidance patterns may of fer more robust benefits. A promising direction is to study how skill granularity , abstraction lev el, and structural organization (e.g., modular sections vs. monolithic documents) affect downstream performance, with the goal of deriving empirically grounded guidelines for skill authors. Dynamic skill selection and composition. The current ev aluation frame work assumes a one-skill- per-task setting in which the rele v ant skill is pre-placed in the project. In realistic deployments, agents must select from a lar ge skill library or compose multiple skills at inference time. Evaluating skill retrie val accurac y , multi-skill interaction ef fects, and the rob ustness of skill selection under ambiguity constitutes an important extension of our benchmark References [1] Carlos E. Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Ke xin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Confer ence on Learning Repr esentations (ICLR) , 2024. 2 , 3 [2] John Y ang, Akshara Prabhakar , et al. SWE-agent: Agent-computer interfaces enable automated software engineering. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2024. 2 [3] W ei Song, Haonan Zhong, Ziqi Ding, Jingling Xue, and Y uekang Li. Help or hurdle? rethinking model context protocol-augmented lar ge language models. arXiv preprint , 2025. 2 [4] Anthropic. Equipping agents for the real world with agent skills. Anthropic Engineering Blog, 2025. 2025a. 2 [5] Runnan Fang, Y uan Liang, Xiaobin W ang, Jialong W u, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Mem p : Exploring agent procedural memory . arXiv preprint arXiv:2508.06433 , 2025. 2 [6] Guanzhi W ang, Y uqi Xie, Y unfan Jiang, Ajay Mandlekar , Chaowei Xiao, Y uke Zhu, Linxi Fan, and Anima Anandkumar . V oyager: An open-ended embodied agent with large language models. T ransactions on Machine Learning Resear c h , 2024. 2 [7] Lei W ang, Chen Ma, Xue yang Feng, Zeyu Zhang, Hao Y ang, Jingsen Zhang, Zhiyuan Chen, Jiakai T ang, Xu Chen, Y ankai Lin, W ayne Xin Zhao, Zhewei W ei, and Ji-Rong W en. A survey on large language model based autonomous agents. F r ontiers of Computer Science , 18(6):186345, 2024. 2 [8] Renjun Xu and Y ang Y an. Agent skills for large language models: Architecture, acquisition, security , and the path forward. arXiv pr eprint arXiv:2602.12430 , 2026. 2 10 [9] Xiang Li, Y ang Liu, W ei Chen, et al. SkillsBench: Benchmarking how well agent skills w ork across div erse tasks. arXiv preprint , 2026. 2 , 3 , 4 [10] Mark A. Merrill et al. T erminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint , 2026. 2 , 3 [11] Mark Chen et al. Evaluating large language models trained on code. In arXiv preprint arXiv:2107.03374 , 2021. 2 , 3 [12] T erry Y ue Zhuo et al. BigCodeBench: Benchmarking code generation with diverse function calls and complex instructions. In International Conference on Learning Repr esentations (ICLR) , 2025. 2 [13] Ian Sommerville. Softwar e Engineering . Pearson Education, 10th edition, 2015. 2 [14] Pamela Za ve. Classification of research efforts in requirements engineering. ACM Computing Surve ys , 29(4):315–321, 1997. 2 [15] Klaus Pohl. Requir ements Engineering: Fundamentals, Principles, and T echniques . Springer , Heidelberg, 2010. 2 [16] Anthropic. Claude code: An agentic coding tool. GitHub, 2025. 2025b . 6 11 System prompt Yo u are a professional test engineer . Yo u r task is to generate automated test suites tha t evaluate whether an AI Agent has correctly compl eted a given programming task . ## Context An AI Agent is given a programming tas k to complete within a real software environment . After the Agent finishes, th e test suite you generate is executed to automatically determine whether the task was completed correctly . ## Core Principles 1. **Discriminative Power** : Te s t s must reliably distinguish between " genuinely completed" and "superficially plausible" outputs . 2. **Behavioral Ve r i f i c a t i o n * * : Execute the code and verify its actual output — do not rely solely on static checks such as keyword matching or file existence . 3. **Completeness** : Cover all acceptance criteria specified in the task , including boundary conditions and error handling . 4. **N on - Tri vi al Assertions** : Ve r i f y the correctness of values, data structures , and logic — not merely their presence . ## Te s t Design Guidelines ### Required Strategies - **Run and verify** : Execute the Agent's code and check return values , output content, and side ef fects . - **Structural validation** : For generated configs, sche m as, or data files , parse and validate the structure and semantics — not just syntax . - **Edge - case testing** : Include tests for boundary inputs, missing fields , and expected error behaviors . ### Prohibited Patterns - Keyword - only assert i ons (e .g., `assert "keyword" in source_code `) - Overly permis s i ve checks (e .g., `assert len (results) >= 1 `) - File - existence - only checks without content verification - Any assertion that a trivially incorrect output could pass ## Output Requirem ents - Generate ≥ 10 test cases per task, spanning multi ple dif ficulty levels . - Each test must include a docstring explaining what it verifies . - Output only executabl e test code — no explanatory prose . User Prompt Please generate a test suite for the following AI Agent task . ### Ta s k ID { task_id } ### Environment - Project root : { project_root } - Language / Framework : {language} - Av a i l a b l e toolchain : {toolchain} ### Ta s k Description { task_description } ### Acceptance Crite ria { acceptance_criteria } ### Constraints - Per - test timeo ut : {timeout} seconds - Av a i l a b l e tools in the execution environment : { available_tools } Figure 6: The prompt used for requirement-driv en verification generation. 12 # Ta s k Requirement Document Generator — Prompt Te m p l a t e Yo u are a **task re quire men t document generator** . Generate a **T ask Requirement Document** (Markdown) based on the provided {{ info rmation_sources }} and {{ skill_reference }} . The task requirement should represent a realistic {{ task_scope }} within the {{ target_context }} . The generated document must be **self - sufficient** : a {{ task_execu tor }} reading only this document must understand what to build, where to ma ke changes, and what counts as done . ## Core Principles 1. Match the {{ target_context }}'s real **{{ tech_constraints }}** . 2. Stay within th e **pr oblem scope** defined by {{ skill_reference }} . 3. Focus on concrete **objectives, constraints, {{ artifact_location }}s, and verifiable outcomes** . 4. **Do not leak** {{ skill_reference }} methods, best practices, or implementation patterns . ## Information Sources - **Configuration** : id, name, description, ty pe, evaluation config from {{ config_source }} - **Skill Refer ence** : {{{ skill_reference }} full content} - **T ask Te m p l a t e * * : {{{ task_te mplate }} full content } ## Requir ed Sections | Section | Purpose | | --- | --- | | Background | Context a {{ task_e xecutor }} needs | | {{ artifact_section_name }} | Concret e {{ artifact_type }} paths to create/modify | | Requirements | Behavior, constraint s , edge cases — **not** solutions | | Acceptance Criter ia | Observable, verifiable "done" conditions | ## Specificity Rules - Name exact {{ domain_specif ics }} whenever part of the goal . - Name exact {{ artifact_t ype }} paths — avoid vague entries like "{{ vague_example }}" . - Name important edge cases, validation ru les, and failure mo des . ## Anti - Patterns - ✗ Rewriting {{ skill_reference }} steps/patterns into the task requirement . - ✗ Guiding language ("recommended to use", "suggest adopting") . - ✗ Va g u e {{ artifact_type }} locations or validation criteria . - ✗ Te c h n o l o g y stack mismat ching the {{ target_context }} . ## Self - Check - [ ] {{ task_executor }} can complete without hidden knowledge . - [ ] Every {{ artifact _t ype }} entry is concrete and {{ path_format }} . - [ ] Acceptance Criteria are outcome - based . - [ ] No {{ skill_reference }} methodology leaked . --- ## Te m p l a t e Va r i a b l e s | Va r i a b l e | Description | Exampl e | | --- | --- | --- | | `{{ task_executor }}` | Who executes the task | agent, developer | | `{{ target_context }}` | Project environment | repository , codebase | | `{{ skill_reference }}` | Knowledge doc (not to leak) | SKILL . md | | `{{ tech_constraints }}` | Te c h n i c a l boundaries | tech stack, testing style | | `{{ artifact_type }}` | Deliver able unit | file, component | | `{{ artifact_section_name }}` | Section header for deliverables | Files to Create/Modify | | `{{ path_format }}` | How paths are expressed | repository - relative | | `{{ domain_specifics }}` | Domai n nouns to be precise about | APIs, schemas, events | | `{{ vague_example }}` | Anti - pattern exam ple | "files under src /" | | `{{ config_source }}` | Configuration origin | benchmark_config . yaml | | `{{ task_scope }}` | What the task represents | development task | | `{{ information_sources }}` | Generator inputs | repo info, eval config | Figure 7: The prompt used for task instance requirement generation. 13 # Ta s k : Extend Unsigned Integer Ty p e Coverage in PyT orch Operators ## Backgroun d The PyT orch codebase (https : // github . com / pytorch / pytorch ) has partial support fo r unsigned integer typ es across its operator library . Several arithmetic and math ematical operators currently lack support for `uint 16 `, `uint 32 `, and `uint 64 ` tensor types . When users pass tensor s of these dtypes to unsupported operators, the runtime raises a dispatch error . The type dispatch infrastructure needs to be extended so th at additional operators can accept unsigned integer inputs . ## Files to Modify - ` aten / src / ATe n /native/ BinaryOps . cpp ` — Dispatch registration for arithmetic ops (add, sub, mu l , floor_divide , remainder) and bitwise ops (and, or, xor , lshift , rshift ) - ` aten / src / ATe n /nativ e/ cpu / Bi naryOpsKernel . cpp ` — CPU kernel implementations for binary operators - ` aten / src / AT e n /native/ Te n s o r C o m p a r e . cpp ` — Dispatch registration for comparison ops (eq, ne, lt , le, gt , ge ) - ` aten / src / ATe n /nativ e/ GcdL cm . cpp ` — GCD operator dispatch and implementation ## Requir ements 1. Operators to support - The implementation MUST explicitly add `uint 16 `, `uint 32 `, and `uint 64 ` support for the following operators (operator names correspond to native AT e n sy m bols and Python API where applicable) : - Arithmetic : `add` ( aten :: add), `sub` ( aten :: sub), ` mul ` ( aten :: mul ) - Integer division / remainder : ` floor_divide ` ( aten :: floor_divide), `remainder` ( aten :: remainder) - Bitwise and shifts : ` bitwise_and ` ( aten :: bitwise_and ), ` bitwise_or ` ( aten :: bitwise_or ), ` bitwise_xor ` ( aten :: bitwise_xor ), ` lshift `/` left_shift ` ( aten ::lshift ), ` rshift`/`right_shift ` ( aten :: rshift ) - GCD : ` gcd ` ( aten :: gcd ) when present in the codebase - Comparisons : `eq`, `ne`, ` lt `, `le`, ` gt `, ` ge ` ( aten :: * comparison ops ) 2. Scope of changes - For each operator above, update both the operator registration/type - dispatch tables and the CPU kernel implementations under ` aten / src / AT e n /native/` so that the operator accepts unsigned intege r tensors without raising dispatch errors . - If a kernel implementation is missing for an unsigned dtype , add an explicit kernel path (reuse signed - integer implementation where semantics match, or add a thin adapter tha t performs identical, dtype - preserving logic) . - Do NOT change operators that are inherently floating - point - only (e .g., `sqrt`, `sin`, `exp`) . 3. Semantics and dtype rules - When all inputs are the same unsigned integer dtype , the operator sh ould preserve that dtype for outputs where that is semantically correct (e .g., `add(uint 32 , uint32 ) -> uint32 `) . - For mix ed - type in puts, follow existing PyT orch promotion rules ; do not introd uce new promotion behavior beyond existing signe d - integer prom otion rules . - Integer division behavior : implement ` floor_divide ` and `remainder` semantics consistent with current PyT orch integer ops (no conversion to floating point ), and ensure results for unsigned inputs match the mathematical remainder/quotient for non - negative integers . 4. Compatibili ty and robustness - Ensure changes compile and pass existing unit tests unrelated to unsigned support . - Provide fallbacks or clear error mes sages for operator combinations that remain unsupported (e .g., mixing unsigned with types that cannot be sensibly combined ). 5. Implementation notes for contributors - Prefer adding dtype coverage via dispatch table entries and small adapters rather than rewriting algorithmic kernels . - Include small unit tests for each operator (see Acceptance Criteria) to validate behavior on sample inputs . ## Expected Function ality - Operators that previously raised dispatch errors for `uint 32 ` or `uint 64 ` tensors now execute successfully and return correct results - The output tensor dtype matches the input tensor dtype when all inputs share the same unsigned type - Operators that only make sense for floating - point types remain unchanged Additionally , the repository should include minimal unit tests that demonstrate correct behavior for each operator listed in the Requirements (examples in Acceptance Criteria) . These tests should validate dtype preservation, numerical correctness for representative values, and reasonable behavior for edge cases (e .g., zero, max - value, boundary shifts ). ## Acceptance Cri teria - The listed operators accept `uint 16 `, `uint 32 `, and `uint 64 ` inputs withou t raising dispatch errors . - Arithmetic, division, remainder, bitwise, GCD, and comparison results are numerically correct for representative unsigned inputs . - When all inputs share the same unsigned dtype , the result keeps that dtype wherever PyT orch's existing promotion rules do not require otherwise . - Edge cases including zero values, maxi mum representable values, and boundary shift counts behave consistently and do not crash . - Floating - point - only operators remain unchanged and unsigned su pport is limited to operators with well - defined integer semantics . Figure 8: An example of the generated requirement in SWE-Skills-Bench. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment