포르투갈어 팟캐스트 음성 데이터셋 TAGARELA 공개
TAGARELA는 8,972시간 규모의 포르투갈어 팟캐스트 음성을 정제·전사한 공개 데이터셋이다. 오디오 표준화·다이어리제이션·중복음성 제거·노이즈 감소 파이프라인을 거쳐 2,800시간의 청정 음성 서브셋을 확보했으며, 1,000시간 시드 코퍼스를 활용한 부트스트랩 전사 방식으로 고품질 텍스트를 얻었다. 이 데이터로 학습한 ASR와 TTS 모델은 각각 15.18% WER, 0.095 CER, MOS 4.18을 기록해 포르투갈어 음성 기술의 성능…
저자: Frederico Santos de Oliveira, Lucas Rafael Stefanel Gris, Alef Iury Siqueira Ferreira
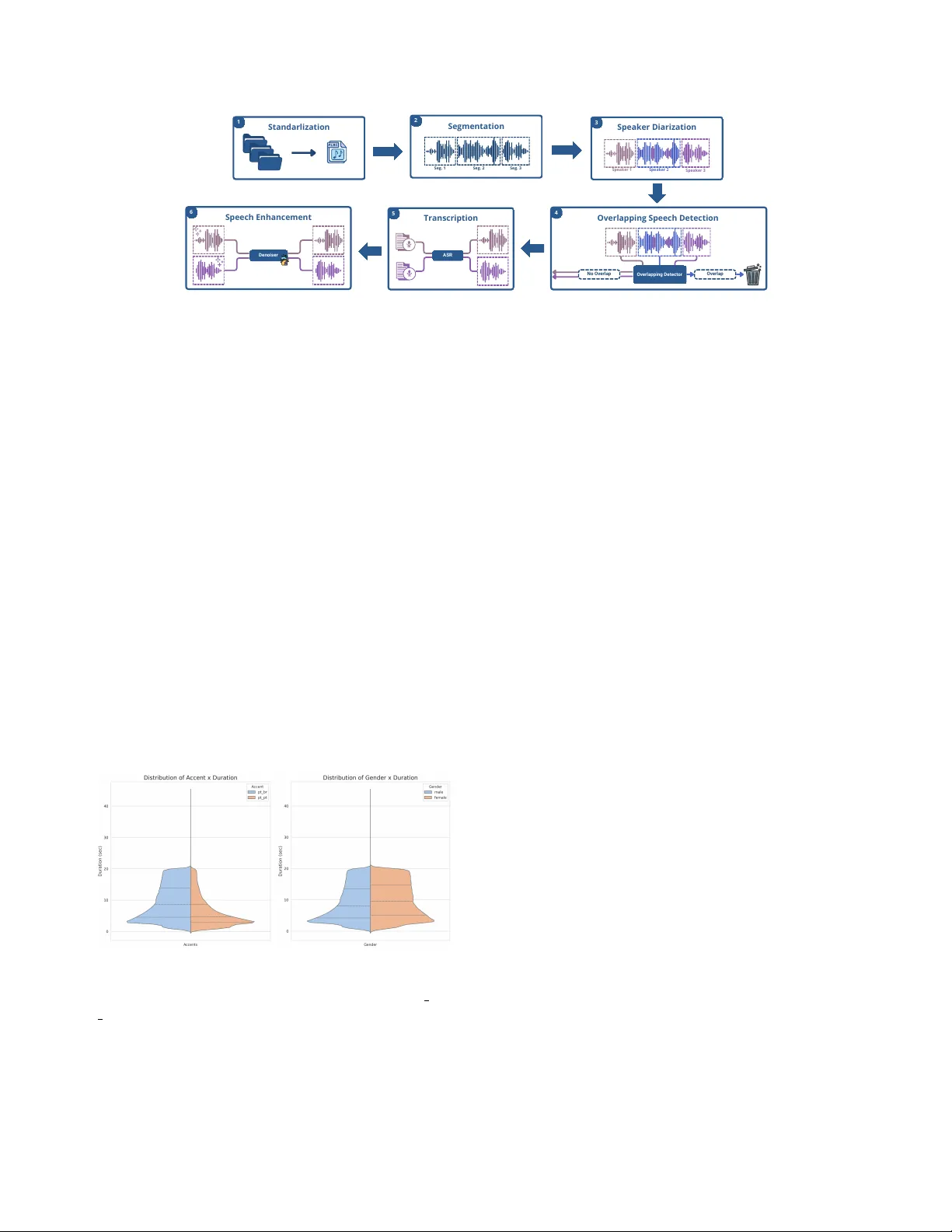
본 논문은 포르투갈어 음성 기술 개발에 필요한 대규모 고품질 데이터가 부족한 현황을 극복하고자, “Cem Mil Podcasts”라는 76,000시간 규모의 원시 팟캐스트 컬렉션을 정제·전사하여 8,972시간에 달하는 TAGARELA 데이터셋을 구축한 과정을 상세히 기술한다.
1. **데이터 규모 및 구성**
- 총 16,806개의 에피소드, 2,094개의 쇼를 포함하며, 브라질 포르투갈어 8,130시간, 유럽 포르투갈어 842시간을 비율적으로 포함.
- 성별 비율은 남성 70%, 여성 30%이며, 평균 세그먼트 길이는 9.30 초(표준편차 5.49 초), 평균 단어 수는 27.69(표준편차 17.06).
2. **전처리 파이프라인**
- **오디오 표준화**: 모든 파일을 16 kHz, 16‑bit, mono FLAC으로 변환하고, 5~20 초 길이의 클립으로 자연 침묵 구간을 기준으로 분할.
- **다이어리제이션**: pyannote.audio 기반 모델로 스피커 구간을 라벨링, 각 클립이 단일 스피커를 포함하도록 분리.
- **오버랩 음성 검출**: wav2vec2‑XLS‑R 기반 이진 분류기를 학습시켜 겹치는 발화를 자동 탐지·제거, 모델 체크포인트 공개.
- **노이즈 감소**: Vocos vocoder를 노이즈 감소 모델로 재학습, 공개용으로는 공개 데이터만 사용한 버전도 제공.
3. **전사 전략**
- 1,000시간 규모의 시드 코퍼스를 ElevenLabs Scribe로 전사 후 Whisper large‑v3에 파인튜닝, 전체 데이터에 대한 의사 라벨 생성.
- 동일 시드 코퍼스로 훈련된 wav2vec2‑XLS‑R와 Whisper 출력 간 WER/CER 일치를 계산, 높은 일치도(예: WER < 10%)를 보이는 샘플만 최종 데이터에 포함.
4. **스피커·방언 라벨링**
- RediNet B6 임베딩을 추출하고 HDBSCAN으로 클러스터링해 약 13,368개의 스피커 라벨을 생성.
- wav2vec‑base 모델을 전체 세그먼트에 사전 학습 후, CORAA, CommonVoice, CML‑TTS 등으로 파인튜닝해 브라질·유럽 방언을 구분하는 분류기 구축.
5. **실험 및 평가**
- **ASR**: 파라킷 v2, Distil‑Whisper, wav2vec Large 등 다양한 모델을 전체 8,972시간 데이터로 파인튜닝. 파라킷 v2가 15.18% WER, 7.09% CER로 최고 성능을 기록, Whisper large‑v3는 20.91% WER.
- **TTS**: 2,800시간 청정 서브셋으로 Orpheus‑TTS와 Chatterbox 학습. Orpheus‑TTS는 0.095% CER(≈9.5% WER)와 MOS 4.155, Chatterbox는 MOS 4.176을 달성, 각각 텍스트 정합성과 자연스러움에서 강점을 보임.
- **음성 품질 지표**: STOI, PESQ, SI‑SDR을 reference‑free 방식으로 측정, 전처리 전후 품질 향상이 시각적으로 확인됨.
6. **결론 및 향후 과제**
- TAGARELA는 포르투갈어 ASR·TTS 모델을 영어 수준에 근접하게 학습시킬 수 있는 규모와 품질을 제공한다는 점에서 중요한 기여를 한다.
- 현재 텍스트‑오디오 정렬 오류와 방언·성별 비율 불균형이 남아 있어, 보다 정밀한 타임스탬프 정렬 및 추가 메타데이터 보강이 필요하다.
- 데이터와 파이프라인 코드는 모두 오픈소스로 공개돼 재현성과 확장성을 보장한다.
전반적으로, 이 연구는 포르투갈어 음성 처리 분야에 있어 대규모 고품질 데이터의 부재라는 병목을 해소하고, 향후 다언어·다방언 모델 개발 및 실제 서비스 적용에 핵심 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기