Tagarela - A Portuguese speech dataset from podcasts
Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours o…
Authors: Frederico Santos de Oliveira, Lucas Rafael Stefanel Gris, Alef Iury Siqueira Ferreira
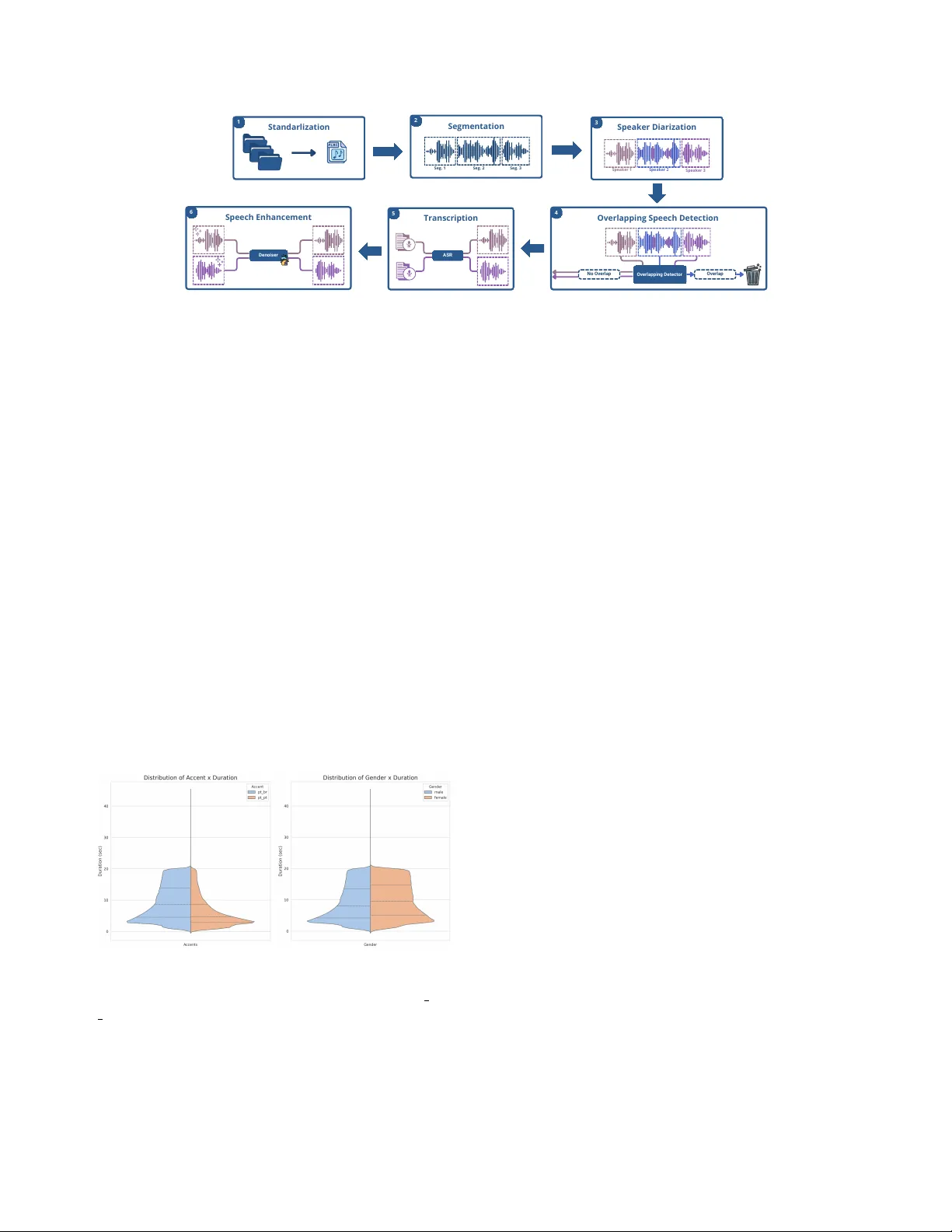
T A GARELA - A POR TUGUESE SPEECH DA T ASET FR OM PODCASTS F r ederico Santos de Oliveira ⋆ Lucas Rafael Stefanel Gris † Alef Iury Siqueira F err eira † Augusto Seben da Rosa ‡ Alexandre Costa Ferro Filho † Edresson Casanov a § Christopher Dane Shulby ¶ Rafael T eixeira Sousa ⋆ Diogo Fernandes Costa Silv a † Anderson da Silv a Soares † Arlindo Rodrigues Galv ˜ ao Filho † ⋆ Federal Uni versity of Mato Grosso (UFMT) † Federal Uni versity of Goias (UFG) ‡ Paulista State Uni versity (UNESP) § NVIDIA ¶ Elsa Speak ABSTRA CT Despite significant adv ances in speech processing, Por- tuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. T o address this gap, we present a new dataset, named T A GARELA, composed of over 8,972 hours of podcast audio, specifically curated for train- ing automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably , its scale riv als English’ s GigaSpeech (10kh), enabling state-of-the-art Portuguese models. T o en- sure data quality , the corpus was subjected to an audio pre- processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were pre viously trained on high-fidelity transcriptions generated by propri- etary APIs, ensuring a high lev el of initial accuracy . Finally , to v alidate the ef fectiv eness of this new resource, we present ASR and TTS models trained exclusi vely on our dataset and ev aluate their performance, demonstrating its potential to dri ve the dev elopment of more robust and natural speech technologies for Portuguese. The dataset is released publicly 1 to foster the dev elopment of robust speech technologies. Index T erms — speech processing, text-to-speech, dataset, automatic-speech-recognition 1. INTR ODUCTION Portuguese ranks among the most widely spoken languages globally , with hundreds of millions of speakers across se veral continents. Despite this global prominence, it remains sig- nificantly under-resourced in the field of speech technology when compared to English. Recent advances in deep learning hav e propelled the fields of Automatic Speech Recognition (ASR) and T ext-to-Speech (TTS), but their progress is funda- mentally driv en by the a v ailability of lar ge-scale, high-quality speech datasets. High-resource languages like English benefit from e xtensiv e corpora such as LibriSpeech (1000 hours) [1], GigaSpeech (10k hours) [2] and Emilia (139k hours) [3], which comprise tens of thousands of hours of transcribed 1 A vailable at https://freds0.github .io/T AGARELA/ audio. This resource gap creates a significant bottleneck that hinders the development of rob ust and natural-sounding speech technologies tailored to the linguistic nuances of Por- tuguese. T o address this disparity , the community has released Portuguese corpora focused on spontaneous speech. Land- mark initiatives include CORAA [4] (290h), NURC-SP [5] (239h), MuPe [6] (365h), and V oxCeleb-PT [7] (18h). Al- though these datasets provide high-quality data crucial for ASR, their spontaneous nature — often characterized by dis- fluencies, background noise, and interruptions — makes them ill-suited for training TTS models, which con ventionally re- quire clean, high-quality audio to achieve natural synthesis. Furthermore, being orders of magnitude smaller than their English counterparts, these corpora limit the performance of data-hungry state-of-the-art models. A significant opportunity to bridge this data gap emerged with the release of the “Cem Mil Podcasts” collection [8], a massi ve corpus of fering over 76,000 hours of div erse, multi-dialect Portuguese audio. Howe ver , the dataset was provided as ra w , unprocessed audio with automatically gen- erated transcripts of v arying quality . The absence of essential pre-processing — speaker diarization, noise reduction, and ov erlapping speech remov al — rendered it impractical for training high-performance ASR and TTS models, which re- quire clean, single-speaker segments. T o unlock this resource, we introduce T A GARELA ( /ta.ga."RE.lA/ ), a large-scale Portuguese speech dataset cu- rated from “Cem Mil Podcasts”. W e dev eloped a pipeline — including standardization, diarization, o verlap detection, and denoising — to transform raw audio into a high-quality cor- pus. For transcription, we employed a bootstrap approach: a 1,000-hour seed corpus, transcribed by commercial ASR, w as used to fine-tune Whisper large-v3 [9], generating pseudo- labels for the remaining data. The corpus comprises two subsets: a full 8,972-hour set with disfluencies for robust ASR, and a 2,800-hour clean-speech subset for speech gener - ation. The main contributions of this work are: (1) the release O v e r l a p p i n g D e t e c t o r O v e r l a p N o O v e r l a p 1 2 3 4 D e n o i s e r A S R 5 6 S t a n d a r l i z a t i o n S e g . 1 S e g . 2 S e g . 3 S e g m e n t a t i o n S p e a k e r D i a r i z a t i o n S p e a k e r 1 S p e a k e r 2 S p e a k e r 3 T r a n s c r i p t i o n S p e e c h E n h a n c e m e n t O v e r l a p p i n g S p e e c h D e t e c t i o n Fig. 1 . Overvie w of the T AGARELA preprocessing pipeline. of T AGARELA, a curated Portuguese speech corpus exceed- ing 8,972 hours for ASR and TTS; (2) a detailed description and e valuation of our multi-stage processing pipeline; and (3) training and e valuation of open-source models exclusi vely on T AGARELA, demonstrating its ef fectiveness. 2. T A GARELA DA T ASET The T A GARELA dataset is a large-scale Portuguese audio corpus deriv ed from the “Cem Mil Podcasts” collection [8] and released exclusi vely for research purposes to address the lack of non-English podcast resources. It consists of roughly 16,806 episodes from 2,094 sho ws, totaling over 8,972 hours of audio. The data includes both Brazilian (8,130 hours) and European Portuguese (842 hours) dialects. In terms of gen- der , 70% of the audio (6,368.34 hours) is attrib uted to male speakers and 30% (2,604.37 hours) to female speakers. The dataset’ s audio segments ha ve an av erage duration of 9.30 ± 5.49 seconds and contain an average of 27.69 ± 17.06 words. Figure 2 presents the distribution of audio duration according to gender and accent. Fig. 2 . V iolin plots showing the distrib ution of audio segment duration in seconds. The left plot compares accents (pt br vs. pt pt), and the right plot compares genders (male vs. female). 3. T A GARELA PIPELINE The creation of the T AGARELA dataset inv olved a multi- stage pipeline designed to ensure high quality and consistency for both ASR and TTS tasks. Each stage was planned to han- dle the challenges inherent to podcast audio, such as multiple speakers, background noise, and the need for accurate, lar ge- scale transcriptions. An overvie w of the pipeline is sho wn in Figure 1, and we detail each component below . 3.1. A udio Standardization and Segmentation All audio files were con verted to a uniform format (FLAC, 16kHz, 16-bit, mono) to ensure training consistency . Long- form recordings were then segmented into 5–20 second clips, with the algorithm prioritizing splits at natural silences to pre- serve speech cohesi veness. 3.2. Diarization and Speaker Separation A common feature in podcasts is the presence of multiple speakers, which poses a challenge for creating clean datasets. T o address this, we applied a diarization process using the pyannote frame work [10]. This stage identifies and labels the speech segments for each speaker individually . By separat- ing the different speak ers, we ensure that each final sample in the dataset contains the v oice of only one person. This step is particularly crucial for training TTS models, which require single-speaker data to generate consistent v oices. 3.3. Overlapping Speech Detection Although diarization separates speakers, some segments may still contain overlapping speech where multiple speakers talk simultaneously . This is highly detrimental to the quality of TTS models. T o mitigate this issue, we trained a dedi- cated classification model based on W a v2vec2-XLS-R [11] to specifically identify these instances. All audio samples that were flagged by the model as containing overlapping speech were subsequently discarded from the dataset, ensuring that the final clips consist of clean, single-speaker utterances. T o ensure the reproducibility of this filtering step, the trained model and its checkpoint are made publicly av ailable for download. 3.4. T wo-Stage Bootstrap T ranscription W e employed a bootstrap strategy for transcription. First, a high-fidelity “seed corpus” of approximately 1000 hours was generated with a commercial ASR service, Elev enLabs Scribe v1 2 , to fine-tune a Whisper lar ge-v3 model for pseudo- labeling. T o filter Whisper’ s potential hallucinations [12], we also trained a W av2v ec2-XLS-R model 3 [13] on the same seed data. W e then calculated the W ord and Character Error Rates (WER/CER) between the outputs of both models, mak- ing it possible to select only samples with a high agreement score to ensure the training dataset’ s quality . 3.5. Quality Enhancement For the final audio enhancement stage, we repurposed a V o- cos vocoder [14] to act as a denoiser . The model was trained specifically for this task on a priv ate dataset, optimizing it to remov e common podcast artifacts like background noise, hiss, and light rev erberation. This process significantly im- prov es the clarity and quality of the finalized segments. T o ensure the reproducibility of this pipeline, we also provide a version of the denoiser trained exclusiv ely on public datasets. 3.6. Speaker and Dialect Labeling T o enrich the dataset, we implemented a multi-stage labeling process. First, gi ven that the original data lacks speaker la- bels, we performed a cluster-based speaker labeling step. W e extracted embeddings for each audio segment using the Red- imNet B6 model [15] and grouped them with the HDBSCAN algorithm [16]. This process was performed independently for each podcast to av oid mer ging speaker identities, result- ing in approximately 13,368 distinct speaker labels. Furthermore, we developed a model to classify each seg- ment’ s dialect as either Brazilian or European Portuguese. This was achie ved by first pre-training a wav2v ec-base model on all segmented audio from our dataset. Subsequently , this model was fine-tuned on a balanced combination of the CORAA, CommonV oice [17], and CML-TTS [18] datasets to create the final accent classifier thus adding v aluable dialectal metadata to the corpus. 4. EXPERIMENTS AND EV ALU A TION In this section, we validate the quality and effecti veness of the T A GARELA dataset by using it to train state-of-the-art models for ASR and TTS. Our goal is to demonstrate that the data curated through our pipeline can produce models with competitiv e or state-of-the-art performance for Portuguese. 4.1. Objective Metrics W e assess audio quality using three objective metrics: Short- T ime Objecti ve Intelligibility (STOI) [19] for speech in- telligibility , the wideband version of Perceptual Evaluation 2 https://elev enlabs.io/docs/models#scribe-v1, run in June 2025. 3 https://huggingface.co/facebook/wa v2vec2-xls-r -1b of Speech Quality (PESQ) [20, 21] for percei ved quality , and Scale-In v ariant Signal-to-Distortion Ratio (SI-SDR) [22] for signal fidelity in decibels (dB). For all metrics, higher values indicate better quality . Since these traditionally re- quire a clean reference signal, we employ the T orchAudio- Squim [23] framework to obtain reference-free estimates. The results are presented in Figure 3. Fig. 3 . V iolin plots showing ST OI, PESQ and SI-SDR. 4.2. Speech Recognition (ASR) Experiments T o e valuate the potential of T A GARELA for ASR tasks, we assessed a diverse set of model architectures covering differ - ent sizes and capabilities, including P arakeet TDT [24, 25], W a v2V ec Lar ge [11], Distil-Whisper [26], Whisper Large V3 [9], and Parakeet v3 [27]. T raining Setup : W e fine-tuned Distil-Whisper, Parakeet TDT v2, and W av2V ec Lar ge using the full 8,972-hour T AGARELA dataset. In contrast, Whisper Large V3 and Parakeet v3 were ev aluated as pre-trained baselines without further training. All experiments were conducted using either NVIDIA A100 or B200 GPUs, subject to av ailability . Evaluation : W e ev aluated model performance on the T AGARELA test set manually transcribed, using WER and CER, calculated after text normalization. Results : As detailed in T able 1, the finetuned Parak eet v2 yielded the best performance on the T AGARELA test set. Achieving a WER of 15.18% and CER of 7.09%, it outper- formed all other models, including W av2V ec Large, Distil- Whisper , and Whisper Large V3, proving to be highly effec- tiv e for Portuguese speech recognition. T able 1 . WER results on the T AGARELA test set. Model WER (%) ↓ CER (%) ↓ Whisper Large V3 20.91 12.42 W av2V ec Large FT 21.85 8.55 Distil-Whisper FT 20.02 11.18 Parakeet v3 23.30 14.86 Parakeet v2 FT 15.18 7.09 4.3. T ext-to-Speech (TTS) Experiments T raining and Evaluation Setup : For the TTS task, we trained the Orpheus-TTS 4 and Chatterbox 5 models using the 2,800- 4 https://github .com/canopyai/Orpheus-TTS 5 https://github .com/resemble-ai/chatterbox hour clean-speech subset of the T A GARELA dataset. W e assessed intelligibility using WER/CER (Whisper Large V3) and per ceptual quality using a Mean Opinion Score (MOS), for which 50 evaluators rated 40 samples. T o ensure a ro- bust ev aluation, we applied a two-stage outlier remo val pro- cess, filtering samples shorter than fi ve seconds, and applying a quartile-based method to remov e statistical outliers. T able 2 . TTS model performance. The values for CER, WER, and MOS are presented as mean ± standard deviation. Model WER (%) ↓ CER (%) ↓ MOS ↑ Chatterbox 0 . 3111 ± 0 . 442 0 . 268 ± 0 . 423 4.176 ± 0.983 Orpheus-TTS 0.095 ± 0.100 0.046 ± 0.051 4 . 155 ± 1 . 001 Ground T ruth 0 . 010 ± 0 . 033 0 . 006 ± 0 . 018 4 . 231 ± 1 . 001 Results and Analysis : As shown in T able 2, Orpheus-TTS achiev ed superior intelligibility (9.5% WER), while Chatter- box attained slightly higher naturalness (MOS 4.176) despite significant errors. This rev eals a trade-off between Orpheus- TTS’ s linguistic precision and Chatterbox’ s focus on prosody . These e xperiments v alidate the T A GARELA dataset’ s critical role in advancing Portuguese TTS. Despite the dataset’ s imperfect text-audio alignment, the results are highly encour - aging and pro vide a solid foundation for de veloping robust, high-quality TTS systems for Portuguese. 5. CONCLUSION T o address the resource gap in Portuguese speech technology , we introduce T A GARELA, a new large-scale dataset with ov er 8,972 hours of podcast audio. W e presented a compre- hensiv e pipeline using diarization, denoising, and a scalable transcription strategy to create a high-quality corpus suitable for both ASR and TTS. The public release of this dataset is a significant contribution, offering the community a resource on a scale previously unav ailable for the Portuguese language. The effecti veness of T AGARELA was v alidated by train- ing ASR and TTS models exclusiv ely on our data, achieving highly competitiv e performance. This confirms the dataset’ s potential to driv e significant advancements in Portuguese speech processing. While there is room for refinements, such as improving text-audio alignment, T A GARELA of- fers a robust foundation for future innov ations. W e believ e this resource will foster the dev elopment of more accurate and natural speech technologies, benefiting millions of Por- tuguese speakers. Acknowledgements: This work has been fully funded by the project Research and Development of Algorithms for Construction of Digital Human T echnological Components supported by the Advanced Knowledge Center in Immersi ve T echnologies (AKCIT), with financial resources from the PPI IoT of the MCTI grant number 057/2023, signed with EM- BRAPII. 6. REFERENCES [1] V assil Panayotov , Guoguo Chen, Daniel Povey , and Sanjee v Khudanpur , “Librispeech: An asr corpus based on public do- main audio books, ” in 2015 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2015, pp. 5206–5210. [2] Haorui He, Zengqiang Shang, Chaoren W ang, Xuyuan Li, Y icheng Gu, Hua Hua, Liwei Liu, Chen Y ang, Jiaqi Li, Peiyang Shi, Y uancheng W ang, Kai Chen, Pengyuan Zhang, and Zhizheng W u, “Emilia: An extensiv e, multilingual, and div erse speech dataset for large-scale speech generation, ” in 2024 IEEE Spoken Language T echnolo gy W orkshop (SLT) , 2024, pp. 885–890. [3] Guoguo Chen, Shuzhou Chai, Guan-Bo W ang, Jiayu Du, W ei- Qiang Zhang, Chao W eng, Dan Su, Daniel Povey , Jan T rmal, Junbo Zhang, Mingjie Jin, Sanjeev Khudanpur, Shinji W atan- abe, Shuaijiang Zhao, W ei Zou, Xiangang Li, Xuchen Y ao, Y ongqing W ang, Zhao Y ou, and Zhiyong Y an, “Gigaspeech: An e volving, multi-domain asr corpus with 10,000 hours of transcribed audio, ” in Interspeec h 2021 . Aug. 2021, inter- speech 2021, ISCA. [4] Arnaldo Candido Junior , Edresson Casanov a, Anderson Soares, Frederico Santos de Oliveira, Lucas Oliveira, Ri- cardo Corso Fernandes Junior , Daniel Peixoto Pinto da Silva, Fernando Gorgulho Fayet, Bruno Baldissera Carlotto, Lucas Rafael Stefanel Gris, and Sandra Maria Alu ´ ısio, “Coraa asr: a large corpus of spontaneous and prepared speech manually validated for speech recognition in brazilian portuguese, ” Lan- guage Resour ces and Evaluation , vol. 57, no. 3, pp. 1139– 1171, 2023. [5] Rodrigo Lima, Sidney Evaldo Leal, Arnaldo Candido Junior, and Sandra Maria Aluisio, “ A large dataset of spontaneous speech with the accent spoken in s ˜ ao paulo for automatic speech recognition ev aluation, ” in Pr oceedings of 34th Brazil- ian Conference on Intelligent Systems (BRA CIS) , 2024. [6] “MuPe life stories dataset: Spontaneous speech in Brazilian Portuguese with a case study ev aluation on ASR bias against speakers groups and topic modeling, ” in Pr oceedings of the 31st International Conference on Computational Linguistics , Owen Rambow , Leo W anner, Marianna Apidianaki, Hend Al- Khalifa, Barbara Di Eugenio, and Stev en Schockaert, Eds., Abu Dhabi, U AE, Jan. 2025, pp. 6076–6087, Association for Computational Linguistics. [7] John Mendonc ¸ a and Isabel T rancoso, “V oxceleb-pt–a dataset for a speech processing course, ” Pr oc. IberSPEECH , vol. 2022, pp. 71–75, 2022. [8] Ekaterina Garmash, Edgar T anaka, Ann Clifton, Joana Cor - reia, Sharmistha Jat, Winstead Zhu, Rosie Jones, and Jussi Karlgren, “Cem mil podcasts: A spoken portuguese docu- ment corpus for multi-modal, multi-lingual and multi-dialect information access research, ” in Experimental IR Meets Mul- tilinguality , Multimodality , and Interaction , Cham, 2023, pp. 48–59, Springer Nature Switzerland. [9] Alec Radford, Jong W ook Kim, T ao Xu, Greg Brockman, Christine McLeavey , and Ilya Sutskev er , “Robust speech recognition via large-scale weak supervision, ” in International confer ence on machine learning . PMLR, 2023, pp. 28492– 28518. [10] Herv ´ e Bredin, Ruiqing Y in, Juan Manuel Coria, Gregory Gelly , Pa vel Korshuno v , Marvin Lavechin, Diego Fustes, Hadrien Titeux, W assim Bouaziz, and Marie-Philippe Gill, “Pyannote.audio: Neural building blocks for speaker diariza- tion, ” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020, pp. 7124–7128. [11] Arun Babu, Changhan W ang, Andros Tjandra, Kushal Lakho- tia, Qiantong Xu, Naman Go yal, Kritika Singh, Patrick von Platen, Y atharth Saraf, Juan Miguel Pino, Alex ei Baevski, Alexis Conneau, and Michael Auli, “XLS-R: Self-supervised cross-lingual speech representation learning at scale, ” in Pr oc. Interspeech 2022 , 2022, pp. 2278–2282. [12] Mateusz Bara ´ nski, Jan Jasi ´ nski, Julitta Bartole wska, Stanisła w Kacprzak, Marcin W itko wski, and Konrad K owalczyk, “Inv es- tigation of whisper asr hallucinations induced by non-speech audio, ” 04 2025, pp. 1–5. [13] Alexis Conneau, Alex ei Baevski, Ronan Collobert, Abdel- rahman Mohamed, and Michael Auli, “Unsupervised cross- lingual representation learning for speech recognition, ” in Pr oc. Interspeech 2021 , 2021, pp. 2426–2430. [14] Hubert Siuzdak, “V ocos: Closing the gap between time- domain and fourier-based neural vocoders for high-quality au- dio synthesis, ” in International Confer ence on Representa- tion Learning , B. Kim, Y . Y ue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., 2024, v ol. 2024, pp. 25719–25733. [15] Iv an Y akovle v , Rostisla v Makarov , Andrei Balykin, Pa vel Malov , Anton Okhotniko v , and Nikita T orgasho v , “Reshape dimensions network for speaker recognition, ” in Interspeech 2024 , 2024, pp. 3235–3239. [16] Claudia Malzer and Marcus Baum, “ A hybrid approach to hi- erarchical density-based cluster selection, ” in 2020 IEEE In- ternational Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI) , 2020, pp. 223–228. [17] Rosana Ardila, Me gan Branson, K elly Davis, Michael Kohler , Josh Meyer , Michael Henretty , Reuben Morais, Lindsay Saun- ders, Francis T yers, and Gregor W eber , “Common voice: A massiv ely-multilingual speech corpus, ” in Proceedings of the T welfth Language Resources and Evaluation Conference , Nicoletta Calzolari, Fr ´ ed ´ eric B ´ echet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hi- toshi Isahara, Bente Maegaard, Joseph Mariani, H ´ el ` ene Mazo, Asuncion Moreno, Jan Odijk, and Stelios Piperidis, Eds., Mar- seille, France, May 2020, pp. 4218–4222, European Language Resources Association. [18] Frederico S Oliveira, Edresson Casanova, Arnaldo Candido Junior , Anderson S Soares, and Arlindo R Galv ˜ ao Filho, “CML-TTS: A multilingual dataset for speech synthesis in low-resource languages, ” in International Conference on T ext, Speech, and Dialogue . Springer , 2023, pp. 188–199. [19] Cees H T aal, Richard C Hendriks, Richard Heusdens, and Jes- per Jensen, “ A short-time objectiv e intelligibility measure for time-frequency weighted noisy speech, ” in 2010 IEEE inter- national confer ence on acoustics, speech and signal process- ing . IEEE, 2010, pp. 4214–4217. [20] Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra, “Perceptual ev aluation of speech quality (pesq)-a new method for speech quality assessment of tele- phone netw orks and codecs, ” in 2001 IEEE international con- fer ence on acoustics, speech, and signal pr ocessing. Pr oceed- ings (Cat. No. 01CH37221) . IEEE, 2001, vol. 2, pp. 749–752. [21] I. Rec, “P .862.2: W ideband extension to recommendation P .862 for the assessment of wideband telephone networks and speech codecs, ” Recommendation P .862.2, International T elecommunication Union, Genev a, Switzerland, 2005. [22] Jonathan Le Roux, Scott W isdom, Hakan Erdogan, and John R Hershey , “Sdr –half-baked or well done?, ” in ICASSP 2019- 2019 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2019, pp. 626–630. [23] Anurag Kumar , Ke T an, Zhaoheng Ni, Pranay Manocha, Xi- aohui Zhang, Ethan Henderson, and Buye Xu, “T orchaudio- squim: Reference-less speech quality and intelligibility mea- sures in torchaudio, ” in ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2023, pp. 1–5. [24] Dima Rekesh, Nithin Rao K oluguri, Samuel Kriman, Somshubra Majumdar , V ahid Noroozi, He Huang, Oleksii Hrinchuk, Krishna Puvv ada, Ankur Kumar , Jagadeesh Balam, and Boris Ginsbur g, “Fast conformer with linearly scalable attention for efficient speech recognition, ” in 2023 IEEE Automatic Speech Recognition and Understanding W orkshop (ASR U) , 2023, pp. 1–8. [25] Hainan Xu, Fei Jia, Somshubra Majumdar , He Huang, Shinji W atanabe, and Boris Ginsburg, “Efficient sequence transduc- tion by jointly predicting tokens and durations, ” in Pr oceed- ings of the 40th International Confer ence on Machine Learn- ing . 2023, ICML ’23, JMLR.or g. [26] Sanchit Gandhi, P atrick V on Platen, and Alexander M Rush, “Distil-whisper: Robust knowledge distillation via large-scale pseudo labelling, ” arXiv pr eprint arXiv:2311.00430 , 2023. [27] Monica Sekoyan, Nithin Rao Koluguri, Nune T adev osyan, Piotr Zelasko, T ravis Bartley , Nikolay Karpov , Jagadeesh Balam, and Boris Ginsburg, “Canary-1b-v2 & parakeet-tdt-0.6 b-v3: Efficient and high-performance models for multilingual asr and ast, ” arXiv pr eprint arXiv:2509.14128 , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment