복잡 제약 하 도구 활용 벤치마크 CCTU
CCTU는 12가지 제약을 4가지 차원으로 정리한 taxonomy를 기반으로, 평균 7개의 제약이 포함된 200개의 도구 사용 테스트 케이스를 제공한다. 실행 가능한 제약 검증 모듈을 통해 다턴 인터랙션 중 단계별 위반 여부를 판단하고, 9개의 최신 LLM을 평가한 결과, 모든 제약을 만족하는 모델은 20% 이하의 성공률을 보였다.
저자: Junjie Ye, Guoqiang Zhang, Wenjie Fu
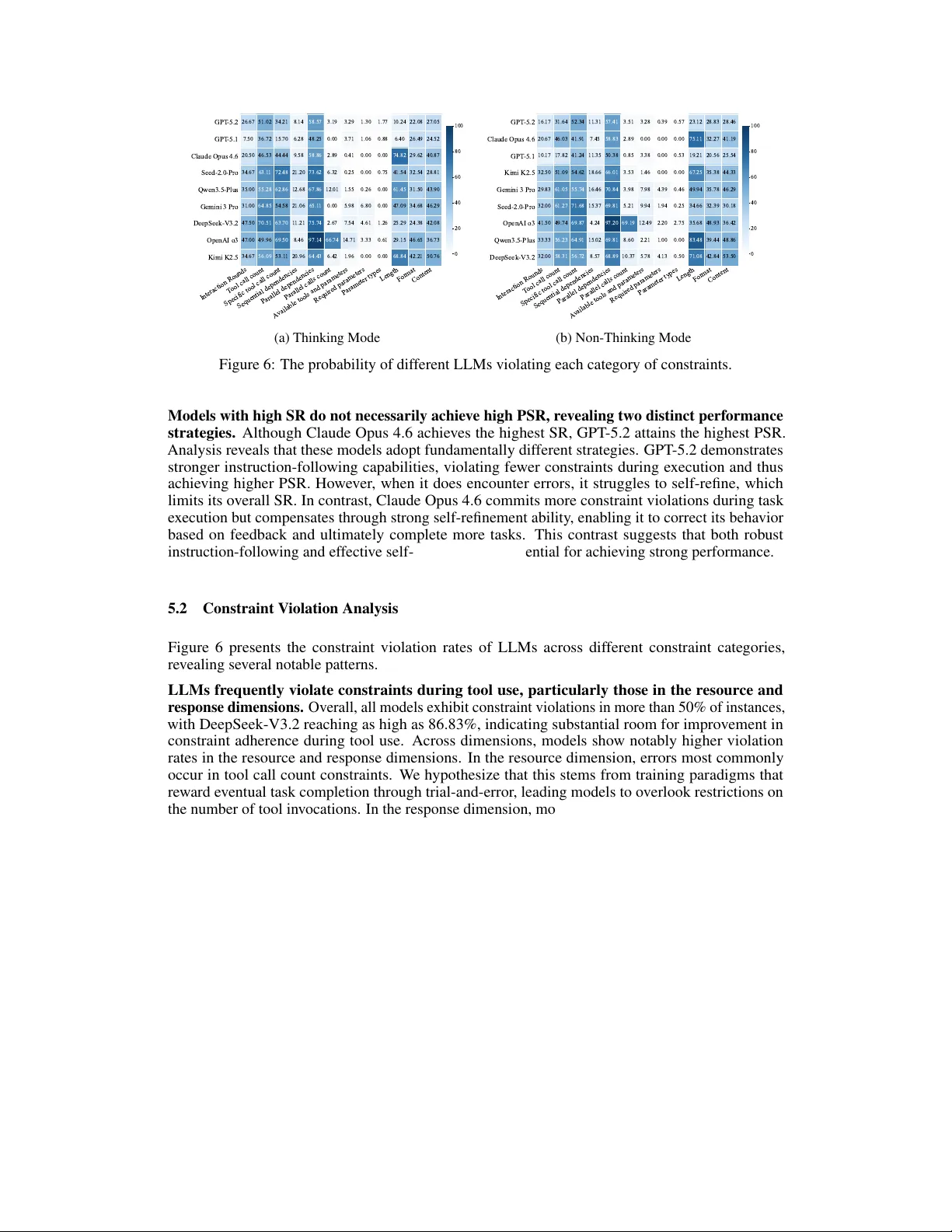
본 연구는 대형 언어 모델(LLM)이 외부 도구를 활용하면서 동시에 다양한 제약 조건을 만족해야 하는 실제 서비스 시나리오를 다루기 위해, 새로운 벤치마크인 CCTU(Complex Constraint Tool Use)를 제안한다. CCTU는 12개의 제약 카테고리를 네 가지 차원(자원, 행동, 툴셋, 응답)으로 조직한 taxonomy를 기반으로 설계되었으며, 각 차원은 구체적인 제약 항목으로 세분화된다. 예를 들어 자원 차원에는 인터랙션 라운드 제한, 툴 호출 횟수 제한, 특정 툴 호출 횟수 제한이 포함되고, 행동 차원에는 순차·병렬 의존성, 병렬 호출 수 제한 등이 있다. 툴셋 차원은 사용 가능한 툴과 파라미터 범위, 필수 파라미터, 파라미터 타입을 검증하며, 응답 차원은 최종 응답의 길이, 포맷(JSON, 표 등), 내용(키워드, 언어 등)을 강제한다.
데이터 구축은 기존 FTRL 데이터셋을 출발점으로 삼아 200개의 테스트 케이스를 생성한다. 각 케이스는 평균 9.26개의 로컬 툴을 포함하고, 자동화된 파이프라인을 통해 제약을 단계적으로 삽입한다. 먼저 정답 트래젝터리를 생성해 기준 솔루션을 확보하고, 이후 LLM을 활용해 제약을 무작위(50% 확률)로 추가한다. 이 과정에서 시나리오 구조에 맞는 제약만 허용하도록 규칙을 두어 논리적 일관성을 유지한다. 삽입된 제약은 LLM 기반 필터링과 수동 검증을 거쳐 충돌이나 비현실적인 설정이 없도록 정제된다. 최종적으로 각 케이스는 평균 7개의 제약이 적용된 4,700 토큰 이상의 프롬프트와 함께 제공된다.
핵심 기술인 제약 검증 모듈은 모델의 각 출력 후 즉시 실행된다. 모듈은 사전에 생성된 검증 코드를 이용해 현재 인터랙션 로그를 분석하고, 제약 위반 여부를 판단한다. 위반이 감지되면 상세 피드백을 생성해 모델에게 전달하고, 모델은 이를 반영해 출력을 수정한다. 이 피드백은 기존 대화 흐름에 삽입되므로 모델의 추론 구조를 변경하지 않는다. 이를 통해 ‘생각(think)’ 모드와 ‘비생각(non‑think)’ 모드 모두에서 동일한 평가 환경을 제공한다.
실험에서는 GPT‑4, Claude, Llama‑2‑70B 등 9개의 최신 LLM을 CCTU에 적용했다. 결과는 모든 제약을 완벽히 만족하는 경우의 성공률이 20% 이하이며, 평균 위반 비율이 50%를 초과함을 보여준다. 특히 자원 차원의 라운드·툴 호출 제한과 응답 차원의 길이·포맷 제약에서 가장 높은 위반률을 기록했다. 모델에게 위반 피드백을 제공하고 자체 수정(self‑refinement)을 유도했지만, 대부분의 모델은 성능 향상이 미미했으며, 이는 현재 LLM이 복합 제약 상황에서 효과적인 자기 교정 능력이 부족함을 의미한다.
논문은 데이터셋, 제약 검증 코드, 평가 스크립트를 공개함으로써 연구 커뮤니티가 복합 제약 하 도구 사용 능력을 체계적으로 측정하고, 제약 인식·자기 교정 메커니즘을 강화하는 연구를 진행할 수 있는 기반을 제공한다. 향후 연구는 제약 종류와 조합을 확대하고, 피드백 기반 학습을 통해 모델의 제약 준수 능력을 향상시키는 방향으로 진행될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기