CCTU: A Benchmark for Tool Use under Complex Constraints
Solving problems through tool use under explicit constraints constitutes a highly challenging yet unavoidable scenario for large language models (LLMs), requiring capabilities such as function calling, instruction following, and self-refinement. Howe…
Authors: Junjie Ye, Guoqiang Zhang, Wenjie Fu
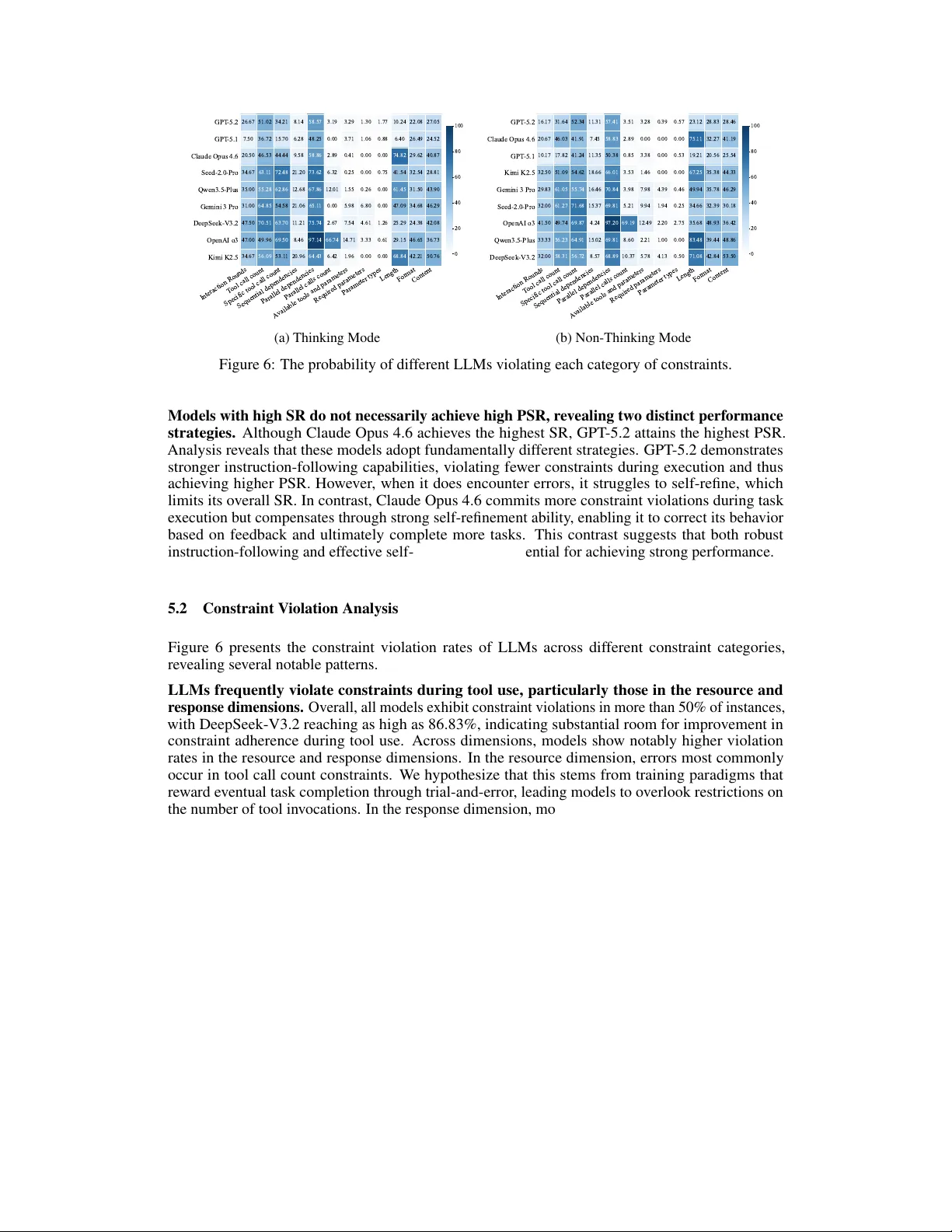
CCTU: A Benchmark f or T ool Use under Complex Constraints Junjie Y e 1 ∗ , Guoqiang Zhang 1 ∗ , W enjie Fu 1 ∗ , T ao Gui 1 , Qi Zhang 1 , Xuanjing Huang 1 1 College of Computer Science and Artificial Intelligence, Fudan Uni versity jjye23@m.fudan.edu.cn Abstract Solving problems through tool use under e xplicit constraints constitutes a highly challenging yet unav oidable scenario for large language models (LLMs), requiring capabilities such as function calling, instruction following, and self-refinement. Howe ver , progress has been hindered by the absence of dedicated e valuations. T o address this, we introduce CCTU , a benchmark for ev aluating LLM tool use under complex constraints. CCTU is grounded in a taxonomy of 12 constraint categories spanning four dimensions (i.e., resource, beha vior , toolset, and response). The benchmark comprises 200 carefully curated and challenging test cases across div erse tool-use scenarios, each in volving an av erage of sev en constraint types and an av erage prompt length e xceeding 4,700 tokens. T o enable reliable ev aluation, we de velop an executable constraint validation module that performs step-le vel validation and enforces compliance during multi-turn interactions between models and their en vironments. W e ev aluate nine state-of-the-art LLMs in both thinking and non-thinking modes. Results indicate that when strict adherence to all constraints is required, no model achiev es a task completion rate abov e 20%. Further analysis rev eals that models violate constraints in over 50% of cases, particularly in the resource and response dimensions. Moreov er , LLMs demonstrate limited capacity for self-refinement even after receiving detailed feedback on constraint violations, highlighting a critical bottleneck in the de velopment of robust tool-use agents. T o facilitate future research, we release the data 2 and code 3 . 1 Introduction Solving problems through tool use under explicit constraints poses a significant challenge for lar ge language models (LLMs) [ 1 ; 6 ; 7 ; 14 ]. As illustrated in Figure 1, such scenarios require models to demonstrate strong function-calling abilities [ 20 ] for accurate tool selection and in vocation, reliable instruction-following skills [ 8 ] to consistently adhere to specified constraints throughout the process, and effecti ve self-refinement mechanisms [ 9 ] to adapt their behavior during dynamic interactions. At the same time, such requirements are unav oidable in practical deployments. For instance, LLMs must operate under constraints such as latency limits [ 36 ], restrictions on tool access frequency [ 19 ], and predefined response formatting rules [17] when using external tools. Existing studies conduct tar geted e valuations of specific aspects of model capability . One line of research examines models’ ability to select and in voke appropriate tools across div erse interaction settings, including single-turn interactions [21; 38], multi-turn dialogues [2; 19], and more comple x ∗ Equal contribution. 2 https://huggingface.co/datasets/Junjie- Ye/CCTU 3 https://github.com/Junjie- Ye/CCTU Preprint. User LLMs To o l s ① Prompt ④ Final Response ② Function Calling ③ T ool Feedback General T ool Use Constrained T ool Use User LLMs To o l s Constrai nt V al i da tion Mod ule ① Constrained Prompt ③ T ool Feedback Figure 1: Comparison between general tool use and constrained tool use. The constrained setting introduces a constraint validation module that performs step-level verification across multi-turn interactions and provides feedback when violations occur . scenarios [ 28 ; 33 ; 34 ]. Another line of work focuses on assessing models’ capacity to generate outputs that comply with comple x instructions. These ev aluations cov er rule-verifiable dimensions [ 16 ; 37 ], as well as more nuanced aspects [ 5 ; 18 ]. Concurrently , a gro wing body of work e xplores self-refinement strategies that enable models to iterati vely impro ve their outputs [9; 23]. Ho wever , these benchmarks ev aluate model capabilities in isolation and do not capture their integrated performance in constrained tool-use scenarios. For instance, a model that can correctly in voke different tools may still fail to consistently adhere to specified constraints, while a model with strong instruction-following ability may struggle to differentiate the functional roles of distinct tools. Moreov er, in dynamic interactiv e settings, whether models can ef fectiv ely self-refine after violating constraints remains underexplored. There is therefore an ur gent need for benchmarks that systematically assess model performance under constrained tool-use conditions. T o address this, we introduce CCTU, a benchmark designed to ev aluate LLM tool use under comple x constraints. T o ensure the div ersity and complexity of constraints in the data, we de velop a taxonomy comprising 12 constraint cate gories across four dimensions (i.e., resource, behavior , toolset, and response). Guided by this taxonomy , we carefully curate 200 challenging test cases co vering di verse tool-use scenarios. T o ensure the validity and consistency of constraint annotations, we apply both LLM-based filtering and manual verification to all instances. Each finalized case in v olves an av erage of seven constraint types, with a verage prompt lengths exceeding 4,700 tokens. Additionally , we dev elop an ex ecutable constraint validation module that performs step-le vel v alidation and enforces compliance during multi-turn interactions between models and their en vironments. W e conduct a comprehensi ve e valuation of nine state-of-the-art LLMs on CCTU, assessing their performance in both thinking and non-thinking modes. Our results indicate the best-performing model achiev es less than 20% task completion rate when strict adherence to all constraints is required, with most models falling below 15%. This highlights sev ere limitations in models’ integrated capabilities under constrained settings. W e further analyze the error distrib ution and find that models violate constraints in ov er 50% of cases, particularly in the resource and response dimensions. Moreover , we observe that LLMs struggle to self-refine based on detailed constraint-violation feedback. This represents a significant bottleneck in dev eloping robust tool-use agents. 2 Related W ork Evaluations f or T ool Use Using tools to solve problems has become a core application of LLMs, spurring extensiv e research on ev aluating tool-use capabilities. These ev aluations span diverse interaction scenarios [ 3 ; 24 ] and are e volving to ward increasingly complex settings such as multi-hop and parallel tasks [ 15 ; 33 ]. They reflect the broader trend of LLM applications expanding from te xt generation to complex, production-oriented tasks [ 10 ; 27 ; 29 ]. Howe ver , most prior work primarily ev aluates whether models e ventually solv e user queries, with limited control o ver the intermediate process and little systematic consideration of constraints go verning tool use. In contrast, our w ork focuses on e valuating tool use under complex constraints, emphasizing whether models can rationally plan action trajectories in accordance with specified restrictions. W e further systematically analyze how dif ferent types of constraints af fect model performance. Evaluations f or Instruction Follo wing Given that LLMs inevitably encounter v arious constraints in practical applications, a substantial body of work has emerged to ev aluate their instruction- follo wing capabilities. Early studies relied on template-based methods to generate simple constrained 2 T able 1: Comparison of different benchmarks across basic information, constraint dimensions, and ev aluated capabilities. Benchmarks Basic Information Constraint Dimensions Evaluated Capabilities #Number A vg. T ools Avg. Len. Precise Eval. Resource Behavior T oolset Response Func. Call. Ins. Follo w. Self-Refine. IFEval [37] 541 0 54 ✓ ✗ ✗ ✗ ✓ ✗ ✓ ✗ IFBench [16] 300 0 90 ✓ ✗ ✗ ✗ ✓ ✗ ✓ ✗ MultiChallenge [5] 273 0 1636 ✗ ✗ ✗ ✗ ✓ ✗ ✓ ✗ BFCL v4 [15] 5088 7.08 1446 ✓ ✗ ✗ ✓ ✓ ✓ ✓ ✗ τ -bench [32] 165 12.36 4245 ✓ ✗ ✗ ✓ ✗ ✓ ✗ ✗ FTRL [34] 200 9.26 3864 ✓ ✗ ✗ ✓ ✗ ✓ ✗ ✗ AGENTIF [17] 707 3.92 2387 ✗ ✗ ✓ ✓ ✓ ✓ ✓ ✗ CCTU (Ours) 200 9.26 4754 ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ instructions and assessed model outputs against these constraints [ 16 ; 31 ; 37 ]. More advanced approaches increased instruction length and complexity , often incorporating LLM-as-a-judge paradigms for ev aluation [ 5 ; 18 ; 35 ]. As LLMs have e volved be yond natural language processing systems, recent research has extended such e valuations to agentic settings [ 17 ]. Ho we ver , these studies primarily assess whether model responses violate explicit constraints embedded in static instructions. In contrast, we dev elop an ex ecutable constraint validation module that conducts step-lev el compliance checks during multi-turn interactions between models and their en vironments. 3 CCTU 3.1 Constraint T axonomy Deriv ed from practical application requirements, we identify 12 representati ve constraints to enable precise ev aluation in tool-use scenarios. Or ganized into four dimensions, these constraints form a structured taxonomy that underpins the construction of div erse and challenging test cases. Resource constraints stem from the dual requirements of ef ficiency and quality . Models must avoid task failure caused by insuf ficient resource utilization while also pre venting inefficiencies arising from excessi ve trial-and-error . These requirements place stringent demands on the model’ s global planning capability . 1) Interaction r ounds limit the total number of exchanges between the model and the environment, requiring the model to produce a final response within the specified bound. Exceeding this limit results in automatic task termination. 2) T ool call count restricts the total number of tool in vocations permitted during task ex ecution. Any in vocation attempt beyond this upper bound is disre garded. 3) Specific tool call count constrains the number of times designated tools may be in voked, emphasizing the need for deliberate planning and ef ficient allocation of these tools. Exceeding the limit renders these tools unav ailable, while other tools remain accessible. Behavior constraints arise from the need to maintain controllability o ver the task ex ecution process, requiring models to follow predefined behavior norms during task completion. Although such constraints restrict the model’ s decision space, they also pro vide structural guidance that facilitates effecti ve task ex ecution. 1) Sequential dependencies gov ern the order of tool inv ocations, often as conditional requirements. For instance, a model may be required to obtain authorization before accessing certain data. Inv ocations that violate these dependencies are rejected, and feedback indicates which preceding tools must be in v oked. 2) Parallel dependencies define conditional relationships between concurrently in voked tools. F or instance, a model may be required to log data while updating it. V iolations of parallel dependencies are similarly rejected, with feedback provided to guide the model. 3) Parallel calls count constrains the allow able range of parallel tool calls during task ex ecution, requiring the model to correctly decompose comple x intentions and distinguish unrelated subtasks. Parallel calls exceeding the upper limit are ignored, while fe wer calls than the lower limit prev ent the model from proactiv ely completing the task. T oolset constraints are fundamental to tool-use scenarios. They define the characteristics and usage specifications of tools through structured documentation. While pre vious work often relied on tool ex ecution outcomes to implicitly enforce these constraints, we perform explicit validations. 1) A vailable tools and parameters restrict the set of tools that the model is permitted to in vok e, as well as the allow able parameter ranges. Any in v ocation beyond this predefined scope is considered a hallucinated call. 2) Required parameters define the mandatory ar guments that must be provided when in v oking a tool. Omission of any required parameter results in in v ocation failure. 3) Parameter types require the model to correctly identify parameter v alue formats and perform appropriate type con versions when necessary . Supplying a v alue of an incorrect type results in in vocation failure. 3 Response constraints stem from requirements concerning the form and structure of model outputs, mandating that final responses adhere to predefined specifications. Responses that violate any constraint must be regenerated. 1) Length restricts the allo wable range of the model’ s final response. 2) Format specifies the presentation style of the final response, such as plain te xt, JSON, or tabular representations. 3) Content imposes specific requirements on elements that must appear in the final response, including designated languages, identifiers, keyw ords, or other prescribed information. 3.2 Benchmark Construction W e construct 200 challenging test cases spanning di verse tool-use scenarios through a systematic pipeline 4 comprising four components: prompt sourcing from an existing dataset, automated constraint integration guided by our taxonomy , executable constraint v alidation for step-level compliance checking, and quality control through manual verification. 5 Prompt Sourcing T o construct div erse test data for tool use under complex constraints, we adopt the FTRL [ 34 ] as our initial dataset. Based on the interrelationships of subqueries, FTRL comprises four categories: single-hop, parallel single-hop, multi-hop, and parallel multi-hop. These categories collecti vely cov er all structural relationships among subqueries, with 50 instances in each category . Each instance e xplicitly specifies the complete set of subqueries it contains, the tools required to resolve them, and the corresponding answers obtainable through correct in v ocation. This design enables straightforward v erification of whether all subqueries hav e been properly addressed. Moreov er , each instance inv olves an a verage of 9.26 locally ex ecutable tools without additional explicit constraints. This setting places substantial demands on models’ function-calling capabilities while also providing a fle xible foundation for systematically incorporating various constraints. Constraint Integration T o integrate our constraints into the initial dataset, we design an automated workflo w that rewrites existing instances in an efficient and controllable manner . The workflow consists of four stages. 1) Refer ence trajectory generation. Directly prompting an LLM to add constraints may introduce unrealistic settings, logical contradictions, or even eliminate v alid solutions. T o mitig ate this risk, we first use of f-the-shelf LLMs to sample one correct solution trajectory for each data point as a reference. 6 Giv en the inherent difficulty of the original dataset [ 34 ], we further improv e sampling effecti veness by providing the model with the remaining set of unsolv ed subqueries for each instance, together with the local tool implementations. Through iterati ve sampling, we obtain a reference trajectory that resolves all subqueries for each instance. W e intentionally retain potential trial-and-error steps within these trajectories to increase di versity during subsequent constraint expansion. 2) Controlled constraint expansion. For each data instance, we iterativ ely introduce constraints using LLMs. T o promote di versity in constraint combinations, we iterate ov er constraint types except those in the T oolset dimension. 7 For each type, we apply a probability of 50% to determine whether it should be added. When selected, the model is guided to incorporate the constraint consistently with the pre-generated reference trajectory . Le veraging the dataset’ s four scenario categories, we impose additional structural rules: sequential dependencies are not added to single-hop or parallel single-hop instances, and parallel dependencies and parallel call count constraints are not introduced in single-hop or multi-hop settings. These restrictions further enhance the rationality of injected constraints. 3) LLM-based filtering. After constraint expansion, we employ LLMs to verify the consistency and feasibility of the modified instances. This step identifies conflicts among constraints and ensures that newly added constraints align with the scenario structure. For instance, setting the interaction round limit to one in a multi-hop scenario would be flagged as unreasonable. If inconsistencies are detected, the process returns to the pre vious stage for correction until verification succeeds. 4) T ask context integration. Since the original dataset contains only user queries, we use LLMs to generate scenario-le vel task contexts for each instance. These contexts provide background descriptions independent of the constraints and are combined with the constrained specifications to form complete and coherent use cases. Constraint V alidation T o enable step-le vel compliance checks during multi-turn interactions, we design a constraint validation module. As illustrated in Figure 1, this module operates after each model output step. It ev aluates whether the model’ s current output satisfies the predefined 4 W e summary the pipeline in Appendix C. 5 Prompts used in the pipeline are provided in Appendix F. 6 W e employ Qwen3-32B [30] in our pipeline due to its strong performance at low computational cost. 7 Constraints in the T oolset dimension are introduced through tool documents in the original dataset. 4 Politics History International Relations Biology Business Arts Military Law T echnology Literature Architecture Culture Environment T ransportation Geography Healthcare Sports Computer Science Mathematics Physics Religion Astronomy Meteorology Geology Agriculture Education Ener gy Chemistry 6 12 18 Figure 2: Distrib ution of CCTU queries across 28 domains. Figure 3: The number of samples associated with each constraint category in CCTU. constraints. If the output is compliant, the module proceeds to trigger corresponding tool inv ocations or conclude the workflow without altering the original execution logic. If a constraint violation is detected, the module returns detailed feedback describing the violation and prompts the model to revise. This feedback is injected into the interaction as either tool or user messages, thereby a voiding the introduction of additional roles and preserving the model’ s original inference configuration. T o implement this module, we use LLMs to pre-generate executable v alidation code for each constraint added to a data instance. The generated code determines whether the model’ s current response satisfies the relev ant constraints by analyzing the accumulated interaction logs. Quality Control T o ensure data quality , we manually verify each constructed data instance and its corresponding constraint v alidation code. 1) Data v erification. Each data instance is first re viewed by a computer science graduate student to identify potential issues, including conflicting constraints, unreasonable constraint settings, and logical inconsistencies. If problems are detected, the instance is manually revised; otherwise, it is retained unchanged. The instance is then e valuated by a second graduate student. The verification process terminates only when tw o consecutiv e annotators agree that the instance is free of issues; otherwise, the instance re-enters the revision cycle until consensus is reached. 2) Code verification. For the finalized data instances, we apply the same v erification workflo w to inspect the corresponding constraint validation code. The process concludes only when two consecuti ve annotators confirm that the code contains no errors. 8 3.3 Data Analysis T o pro vide a more intuiti ve illustration of the dataset quality , we conduct a multi-dimensional analysis, which rev eals four key characteristics: di verse domains, substantial length, complex constraints, and precise ev aluation. T able 1 presents a comparison between CCTU and existing benchmarks. Diverse Domains As described in Section 3.2, our dataset is b uilt upon FTRL and covers four categories of compositional relationships among subqueries, enabling the e valuation of tool use across di verse scenarios. T o further demonstrate this div ersity , we cate gorize the domains represented in the dataset. As shown in Figure 2, the dataset spans 28 distinct domains, including specialized fields such as politics and sports, as well as ev eryday domains such as culture and tourism. This breadth ensures comprehensiv e ev aluation of model performance across v aried contexts, enhancing both its representativ eness and practical relev ance. Complex Constraints Based on the proposed constraint taxonomy , we construct test data for tool use under complex constraints. T o better understand the constraint composition of the dataset, we conduct a statistical analysis of constraint distrib utions. The results in Figure 3 present the number of data instances associated with each constraint type. The results indicate that constraints in the behavior dimension appear in fe wer instances due to their dependence on specific scenario structures, 8 More details for the process are provided in Appendix D. 5 Figure 4: Distribution of the number of constraint categories per sample in CCTU. Figure 5: Distribution of data lengths in CCTU, measured using the Qwen3 tokenizer . whereas constraints in the other three dimensions are present in the majority of the dataset. Notably , ev ery instance simultaneously includes constraints from both the resource and toolset dimensions. Figure 4 further sho ws that each data point contains between 4 and 12 constraint types, with an av erage of 7 constraints per instance. This design highlights the div ersity and complexity of constraint combinations within the dataset. Substantial Length Giv en the substantial performance variation of LLMs across different conte xt lengths [ 11 ], we analyze the length distribution of the constructed dataset. Specifically , we tokenize each instance, including tool descriptions, using the tokenizer of Qwen3 and compute the corresponding token counts. As sho wn in Figure 5, most instances fall within the range of 3,000 to 7,000 tokens, with an average length of 4,754 tokens per instance. Considering that models must further interact with the en vironment through multiple turns during task execution, the effecti ve conte xt length continues to grow as the interaction progresses. These characteristics pose a considerable challenge for current LLMs. Precise Evaluation The accuracy and reliability of e valuation results are crucial indicators of the quality of an ev aluation dataset. On one hand, since all tools in FTRL are locally executable and each subquery is annotated with the corresponding tool response, we can precisely determine whether indi vidual subqueries hav e been successfully resolved. On the other hand, our frame work incorporates an executable constraint v alidation module that performs code-based compliance checks at each interaction step and identifies violated constraints through explicit feedback. T ogether , these two components enable precise e v aluation of a model’ s problem-solving progress, its adherence to imposed constraints, and its ability to perform self-refinement after constraint violations. This design ensures the reliability of the ev aluation results. 4 Experimental Setup 4.1 Models T o accurately capture the current capabilities of LLMs, we select nine top-tier models for ev aluation, including Claude Opus 4.6 [ 1 ], DeepSeek-V3.2 [ 4 ], Gemini 3 Pro [ 6 ], GPT -5.1 [ 12 ], GPT -5.2 [ 14 ], Kimi 2.5 [ 25 ], OpenAI o3 [ 13 ], Qwen3.5-Plus [ 26 ], and Seed-2.0-Pro [ 22 ]. Furthermore, we e valuate each model separately in both thinking and non-thinking modes. 4.2 Metrics Suppose there are N test cases. The i -th test case contains Q i subqueries, where q i,j ∈ { unsolved , solved } indicates whether the j -th subquery is solved. Each test case is associated with C i constraints, and c i,k ∈ { unsatisfied , soft-satisfied , satisfied } denotes the status of the k -th constraint. Here, soft-satisfied indicates that the constraint is initially violated but subsequently refined. W e ev aluate model performance using two metrics. Solve Rate (SR) Follo wing Y e et al. [34] , SR measures whether a model successfully solv es all subqueries while satisfying all constraints (allowing soft satisf action). Formally , SR = 1 N N X i =1 I Q i ^ j =1 q i,j = solved ∧ C i ^ k =1 c i,k ∈ { soft-satisfied , satisfied } ! 6 T able 2: Performance in thinking and non-thinking modes, ranked by o verall PSR score. Standard deviations are sho wn in smaller font at the lower right of each mean. The best result in each column is highlighted in bold . Models Single-Hop Parallel Single-Hop Multi-Hop Parallel Multi-Hop Overall SR PSR SR PSR SR PSR SR PSR SR PSR Thinking Mode GPT -5.2 32.67 1.89 24.67 3.40 24.67 1.89 17.33 0.94 25.33 2.49 20.67 2.49 15.33 0.94 10.00 1.63 24.50 0.82 18.17 1.03 GPT -5.1 25.33 5.25 20.00 7.12 20.67 2.49 16.00 0.00 22.67 1.89 20.67 1.89 22.67 0.94 9.33 2.49 22.83 2.01 16.50 2.83 Claude Opus 4.6 34.67 4.99 10.00 1.63 30.67 2.49 13.33 0.94 38.67 3.40 23.33 1.89 32.67 1.89 12.67 0.94 34.17 2.25 14.83 1.03 Seed-2.0-Pro 22.67 3.77 19.33 4.99 20.67 5.25 12.67 3.40 22.67 0.94 18.67 0.94 15.33 1.89 8.67 2.49 20.33 2.62 14.83 2.87 Qwen3.5-Plus 20.67 4.99 5.33 2.49 23.33 0.94 8.00 1.63 32.00 2.83 21.33 0.94 23.33 1.89 8.00 1.63 24.83 1.03 10.67 1.55 Gemini 3 Pro 23.33 2.49 12.00 3.27 28.00 1.63 16.00 1.63 14.67 0.94 11.33 2.49 11.33 3.40 2.67 0.94 19.33 1.84 10.50 1.08 DeepSeek-V3.2 15.33 1.89 6.67 2.49 22.67 1.89 12.00 1.63 26.00 4.32 16.67 3.40 8.00 1.63 0.67 0.94 18.00 1.08 9.00 0.41 OpenAI o3 22.67 1.89 17.33 1.89 7.33 0.94 4.00 1.63 13.33 0.94 10.00 1.63 4.00 1.63 1.33 0.94 11.83 1.31 8.17 1.03 Kimi K2.5 22.67 3.77 4.67 2.49 26.00 3.27 10.67 3.77 20.00 2.83 10.67 2.49 16.67 4.11 4.67 2.49 21.33 2.05 7.67 1.65 Non-Thinking Mode GPT -5.2 28.00 3.27 24.00 1.63 19.33 0.94 15.33 2.49 17.33 4.11 14.00 4.90 16.67 0.94 10.67 0.94 20.33 0.62 16.00 1.87 Claude Opus 4.6 38.00 1.63 12.00 0.00 29.33 0.94 13.33 0.94 38.00 2.83 23.33 1.89 32.67 0.94 13.33 0.94 34.50 1.08 15.50 0.41 GPT -5.1 22.67 2.49 19.33 0.94 19.33 2.49 16.67 1.89 16.67 2.49 14.00 1.63 14.00 0.00 6.67 3.40 18.17 0.85 14.17 0.62 Kimi K2.5 19.33 3.40 6.67 0.94 29.33 0.94 14.00 0.00 25.33 1.89 15.33 0.94 16.67 0.94 6.67 0.94 22.67 0.85 10.67 0.62 Gemini 3 Pro 22.67 6.60 12.67 4.71 26.67 2.49 14.67 0.94 16.00 3.27 11.33 0.94 10.67 1.89 2.00 1.63 19.00 1.47 10.17 0.85 Seed-2.0-Pro 20.00 2.83 13.33 3.77 20.00 2.83 10.00 1.63 20.00 5.89 13.33 4.99 12.67 0.94 3.33 0.94 18.17 2.87 10.00 1.87 OpenAI o3 24.00 4.90 18.67 2.49 9.33 1.89 4.67 1.89 10.67 2.49 7.33 1.89 2.00 1.63 1.33 0.94 11.50 0.82 8.00 1.08 Qwen3.5-Plus 20.67 2.49 4.00 0.00 20.00 1.63 6.67 2.49 28.67 2.49 14.67 0.94 16.00 1.63 2.67 2.49 21.33 0.85 7.00 1.41 DeepSeek-V3.2 20.00 3.27 6.67 0.94 17.33 0.94 6.00 0.00 20.67 7.54 12.00 3.27 10.00 1.63 1.33 0.94 17.00 2.55 6.50 0.82 Perfect Solv e Rate (PSR) W e introduce PSR as a stricter metric to measure whether a model solves all subqueries without any constraint violations. Formally , PSR = 1 N N X i =1 I Q i ^ j =1 q i,j = solved ∧ C i ^ k =1 c i,k = satisfied ! 4.3 Implementation Details T o faithfully reflect each model’ s inherent capabilities, all models are inv oked via their official API interfaces. Except for toggling between thinking and non-thinking modes, all inference hyperparameters are kept at their default values. T o mitigate sampling-induced v ariability , we conduct three independent runs and report the mean and standard deviation of the results. 5 Experiments 5.1 Main Results T able 2 presents the performance of various LLMs, from which we dra w the following observ ations. CCTU presents substantial challenges f or current LLMs while also clearly differentiating their capabilities. Overall, the PSR of all LLMs remains below 20%, with most models falling below 15%. This indicates that current LLMs struggle to ef fectively use tools under constrained conditions. Moreov er , performance in more complex scenarios is substantially w orse than in simpler ones. For instance, GPT -5.2 achiev es a PSR that is 14.67% lo wer in parallel multi-hop tasks than in single-hop tasks. Although all LLMs perform poorly on CCTU, clear dif ferences still emerge across models. In the thinking mode, the PSR of GPT -5.2 exceeds that of Kimi K2.5 by more than 10%, highlighting notable disparities in the ov erall capabilities of different models. Although most models demonstrate impr oved performance in thinking mode, se veral exceptions are observed. As expected, most models achie ve higher performance in the thinking mode. For instance, Seed-2.0-Pro attains a PSR that is 4.83% higher and an SR that is 2.16% higher in thinking mode than in the non-thinking mode. Ho wever , notable e xceptions are observed for Claude Opus 4.6 and Kimi K2.5. Through careful analysis, we find that this anomaly stems from the models’ tendency to ov erthink in the thinking mode. Specifically , the y sometimes rewrite parameter values specified in the prompt, and during the correction process the y may also modify parameters that are originally correct, causing errors to persist. This issue occurs less frequently in the non-thinking mode. 9 9 Cases are provided in Appendix E. 7 (a) Thinking Mode (b) Non-Thinking Mode Figure 6: The probability of different LLMs violating each cate gory of constraints. Models with high SR do not necessarily achieve high PSR, r evealing tw o distinct performance strategies. Although Claude Opus 4.6 achiev es the highest SR, GPT -5.2 attains the highest PSR. Analysis re veals that these models adopt fundamentally dif ferent strategies. GPT -5.2 demonstrates stronger instruction-following capabilities, violating fe wer constraints during execution and thus achieving higher PSR. Ho wev er , when it does encounter errors, it struggles to self-refine, which limits its ov erall SR. In contrast, Claude Opus 4.6 commits more constraint violations during task ex ecution but compensates through strong self-refinement ability , enabling it to correct its behavior based on feedback and ultimately complete more tasks. This contrast suggests that both rob ust instruction-following and ef fecti ve self-refinement are essential for achie ving strong performance. 5.2 Constraint V iolation Analysis Figure 6 presents the constraint violation rates of LLMs across different constraint categories, rev ealing sev eral notable patterns. LLMs fr equently violate constraints during tool use, particularly those in the r esource and response dimensions. Overall, all models exhibit constraint violations in more than 50% of instances, with DeepSeek-V3.2 reaching as high as 86.83%, indicating substantial room for improvement in constraint adherence during tool use. Across dimensions, models sho w notably higher violation rates in the resource and response dimensions. In the resource dimension, errors most commonly occur in tool call count constraints. W e hypothesize that this stems from training paradigms that rew ard ev entual task completion through trial-and-error , leading models to overlook restrictions on the number of tool in vocations. In the response dimension, models primarily mak e mistakes related to response content. This is largely because models tend to summarize tool outputs in their final responses while failing to preserve k ey elements explicitly required in the original query . Error patterns shift unpredictably between thinking and non-thinking modes. The thinking mode reduces a model’ s violation rate for some constraint types, while increases others. For instance, GPT -5.1 shows a lower violation rate for specific tool call count constraints in the thinking mode but a significantly higher rate for overall tool call count constraints. One possible explanation is that the extended reasoning enables more careful planning for specific tool allocation, yet the additional deliberation leads to more exploratory tool calls overall, exceeding the total inv ocation limit. More broadly , while thinking mode alters the distribution of error types, these shifts do not consistently translate into ov erall performance gains. These findings highlight the need for more effecti ve thinking-mode mechanisms that can simultaneously reduce violations across all dimensions. Although less frequent, hallucinations and missing requir ed parameters remain non-negligible issues. Despite rapid advancements in current LLMs, most models struggle to fully understand the av ailable tools and their parameters, leading to hallucination-related errors. In addition, models sometimes omit required parameters or provide incorrect parameter types during tool calls. Although such errors in the toolset dimension occur less frequently than those in other dimensions, the y directly cause tool in vocation f ailures and therefore remain critical issues that should not be overlooked. 8 (a) Thinking Mode (b) Non-Thinking Mode Figure 7: Self-refinement probability of different LLMs under dif ferent constraint categories. 5.3 LLM Self-Refinement Analysis Figure 7 illustrates the proportion of errors that LLMs successfully correct through self-refinement under different types of constraints, from which we deri ve the follo wing findings. Even with detailed feedback guidance, models exhibit limited self-refinement capability under certain constraints. The constraint validation module provides detailed feedback when models violate constraints and guides them through the refinement process. Overall, Claude Opus 4.6 achie ves the highest correction rate at 65.36%, while the correction rates of other models remain below 60%, with OpenAI o3 reaching only 18.57%. Although correction rates in the T oolset dimension are relativ ely high, some models still fail to reach 100%, indicating limitations in their fundamental function-calling capabilities. Moreov er, substantial room for improv ement remains in both the behavior and response dimensions. Thinking modes enable some models to demonstrate stronger self-refinement capabilities, while degrading the performance of others. Claude Opus 4.6, DeepSeek-V3.2, GPT -5.2, and Qwen3.5-Plus e xhibit noticeably higher correction rates in the thinking mode than in the non-thinking mode. Howe ver , other models sho w no such improv ement, and some ev en display lower correction rates when thinking is enabled. W e attribute this to certain models doubling do wn on incorrect approaches during extended reasoning, which hinders subsequent correction. 10 This observ ation further highlights the importance of well-designed thinking mechanisms. Effective self-refinement alone does not guarantee superior overall performance. DeepSeek-V3.2 achiev es an ov erall correction rate of 52.77% in the thinking mode; howe ver , T able 2 sho ws that its ov erall performance remains relativ ely low . This is primarily due to its higher probability of violating constraints and its comparati vely weaker function-calling capabilities. In contrast, Claude Opus 4.6 benefits from strong function-calling capabilities and a significantly stronger self-refinement ability than other models, resulting in a higher SR. These results indicate that tool use under complex constraints is a challenging task that requires strong ov erall model capabilities. 6 Conclusion In this paper , we introduce CCTU, a benchmark for tool use under complex constraints. CCTU is grounded in a four -dimensional, twelve-cate gory constraint taxonomy . The benchmark comprises 200 carefully curated test cases, and is supported by an ex ecutable constraint validation module that enables step-lev el compliance checking during multi-turn interactions.W e e v aluate nine state-of-the- art LLMs in both thinking and non-thinking modes. Our results highlight the challenges CCTU poses for current models and rev eal notable differences in instruction-follo wing and self-refinement capabilities, providing v aluable insights for advancing LLM de velopment. 10 Cases are provided in Appendix E. 9 References [1] Anthropic. 2026. System card: Claude opus 4.6. [2] Chen Chen, Xinlong Hao, W eiwen Liu, Xu Huang, Xingshan Zeng, Shuai Y u, Dexun Li, Shuai W ang, W einan Gan, Y uefeng Huang, W ulong Liu, Xinzhi W ang, Defu Lian, Baoqun Y in, Y asheng W ang, and W u Liu. 2025. Acebench: Who wins the match point in tool learning? CoRR , abs/2501.12851. [3] Zehui Chen, W eihua Du, W enwei Zhang, Kuikun Liu, Jiangning Liu, Miao Zheng, Jingming Zhuo, Songyang Zhang, Dahua Lin, Kai Chen, and Feng Zhao. 2024. T -ev al: Evaluating the tool utilization capability of large language models step by step. In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P aper s), A CL 2024, Bangkok, Thailand, August 11-16, 2024 , pages 9510–9529. Association for Computational Linguistics. [4] DeepSeek-AI. 2025. Deepseek-v3.2: Pushing the frontier of open lar ge language models. CoRR , abs/2512.02556. [5] Kaustubh Deshpande, V ed Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Y eremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, W illow E. Primack, Summer Y ue, and Chen Xing. 2025. Multichallenge: A realistic multi-turn con v ersation ev aluation benchmark challenging to frontier llms. In F indings of the Association for Computational Linguistics, ACL 2025, V ienna, Austria, July 27 - August 1, 2025 , pages 18632–18702. Association for Computational Linguistics. [6] Google. 2025. Gemini 3 pro model card. [7] Daya Guo, Dejian Y ang, Hao wei Zhang, Junxiao Song, Peiyi W ang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Y u, Y u W u, Z. F . W u, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nat. , 645(8081):633–638. [8] Renze Lou, Kai Zhang, and W enpeng Y in. 2024. Large language model instruction follo wing: A surve y of progresses and challenges. Comput. Linguistics , 50(3):1053–1095. [9] Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wie greffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Y iming Y ang, Shashank Gupta, Bodhisattwa Prasad Majumder , Katherine Hermann, Sean W elleck, Amir Y azdanbakhsh, and Peter Clark. 2023. Self- refine: Iterativ e refinement with self-feedback. In Advances in Neural Information Pr ocessing Systems 36: Annual Confer ence on Neural Information Pr ocessing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 . [10] Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwi vedi-Y u, Asli Celikyilmaz, Edouard Grav e, Y ann LeCun, and Thomas Scialom. 2023. Augmented language models: a surve y. CoRR , abs/2302.07842. [11] Elliot Nelson, Georgios K ollias, P ayel Das, Subhajit Chaudhury , and Soham Dan. 2024. Needle in the haystack for memory based large language models. CoRR , abs/2407.01437. [12] OpenAI. 2025. Gpt-5.1 instant and gpt-5.1 thinking system card addendum. [13] OpenAI. 2025. Openai o3 and o4-mini system card. [14] OpenAI. 2025. Update to gpt-5 system card: Gpt-5.2. [15] Shishir G. Patil, T ianjun Zhang, Xin W ang, and Joseph E. Gonzalez. 2024. Gorilla: Large language model connected with massi ve apis. In Advances in Neural Information Pr ocessing Systems 38: Annual Confer ence on Neural Information Pr ocessing Systems 2024, NeurIPS 2024, V ancouver , BC, Canada, December 10 - 15, 2024 . [16] V alentina Pyatkin, Saumya Malik, V ictoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. 2025. Generalizing verifiable instruction following. CoRR , abs/2507.02833. 10 [17] Y unjia Qi, Hao Peng, Xiaozhi W ang, Amy Xin, Y oufeng Liu, Bin Xu, Lei Hou, and Juanzi Li. 2025. A GENTIF: benchmarking instruction following of lar ge language models in agentic scenarios. CoRR , abs/2505.16944. [18] Y anzhao Qin, T ao Zhang, T ao Zhang, Y anjun Shen, W enjing Luo, Haoze Sun, Y an Zhang, Y ujing Qiao, W eipeng Chen, Zenan Zhou, W entao Zhang, and Bin Cui. 2025. Sysbench: Can llms follow system message? In The Thirteenth International Conference on Learning Repr esentations, ICLR 2025, Singapore , April 24-28, 2025 . OpenRevie w .net. [19] Y ujia Qin, Shihao Liang, Y ining Y e, Kunlun Zhu, Lan Y an, Y axi Lu, Y ankai Lin, Xin Cong, Xiangru T ang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu T ian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. T oolllm: Facilitating lar ge language models to master 16000+ real-world apis. In The T welfth International Conference on Learning Repr esentations, ICLR 2024, V ienna, Austria, May 7-11, 2024 . OpenRe view .net. [20] Changle Qu, Sunhao Dai, Xiaochi W ei, Hengyi Cai, Shuaiqiang W ang, Dawei Y in, Jun Xu, and Ji-Rong W en. 2025. T ool learning with large language models: a survey. F r ontiers Comput. Sci. , 19(8):198343. [21] T imo Schick, Jane Dwiv edi-Y u, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer , Nicola Cancedda, and Thomas Scialom. 2023. T oolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems 36: Annual Confer ence on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 . [22] Bytedance Seed. 2026. Seed2.0 model card: T owards intelligence frontier for real-world complexity. [23] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. 2023. Reflexion: language agents with verbal reinforcement learning. In Advances in Neural Information Pr ocessing Systems 36: Annual Confer ence on Neural Information Pr ocessing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 . [24] Qiaoyu T ang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. 2023. T oolalpaca: Generalized tool learning for language models with 3000 simulated cases. CoRR , abs/2306.05301. [25] Kimi T eam, T ongtong Bai, Y if an Bai, Y iping Bao, S. H. Cai, Y uan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kef an Chen, Liang Chen, Ruijue Chen, Xinhao Chen, and 307 others. 2025. Kimi k2.5: V isual agentic intelligence. CoRR , abs/2602.02276. [26] Qwen T eam. 2026. Qwen3.5: T o wards nati ve multimodal agents. [27] Harsh Tri vedi, T ushar Khot, Mareike Hartmann, Ruskin Manku, V inty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. 2024. Appworld: A controllable world of apps and people for benchmarking interacti ve coding agents. In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers), A CL 2024, Bangkok, Thailand, August 11-16, 2024 , pages 16022– 16076. Association for Computational Linguistics. [28] Y uxin W ang, Y iran Guo, Y ining Zheng, Zhangyue Y in, Shuo Chen, Jie Y ang, Jiajun Chen, Xuanjing Huang, and Xipeng Qiu. 2025. Familytool: A multi-hop personalized tool use benchmark. CoRR , abs/2504.06766. [29] Zhiheng Xi, W enxiang Chen, Xin Guo, W ei He, Y iwen Ding, Boyang Hong, Ming Zhang, Junzhe W ang, Senjie Jin, En yu Zhou, Rui Zheng, Xiaoran Fan, Xiao W ang, Limao Xiong, Y uhao Zhou, W eiran W ang, Changhao Jiang, Y icheng Zou, Xiangyang Liu, and 9 others. 2025. The rise and potential of large language model based agents: a surve y. Sci. China Inf. Sci. , 68(2). 11 [30] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Dayiheng Liu, F an Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, and 40 others. 2025. Qwen3 technical report. CoRR , abs/2505.09388. [31] Shunyu Y ao, Ho ward Chen, Austin W . Hanjie, Runzhe Y ang, and Karthik R. Narasimhan. 2024. COLLIE: systematic construction of constrained text generation tasks. In The T welfth International Confer ence on Learning Representations, ICLR 2024, V ienna, Austria, May 7-11, 2024 . OpenRevie w .net. [32] Shunyu Y ao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. 2025. τ -bench: A benchmark for tool-agent-user interaction in real-world domains. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapor e, April 24-28, 2025 . OpenRevie w .net. [33] Junjie Y e, Zhengyin Du, Xuesong Y ao, W eijian Lin, Y ufei Xu, Zehui Chen, Zaiyuan W ang, Sining Zhu, Zhiheng Xi, Siyu Y uan, T ao Gui, Qi Zhang, Xuanjing Huang, and Jiecao Chen. 2025. T oolhop: A query-driv en benchmark for ev aluating large language models in multi-hop tool use. In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers), A CL 2025, V ienna, Austria, J uly 27 - August 1, 2025 , pages 2995–3021. Association for Computational Linguistics. [34] Junjie Y e, Changhao Jiang, Zhengyin Du, Y ufei Xu, Xuesong Y ao, Zhiheng Xi, Xiaoran Fan, Qi Zhang, Xuanjing Huang, and Jiecao Chen. 2025. Feedback-driv en tool-use improvements in large language models via automated b uild en vironments. CoRR , abs/2508.08791. [35] Hongkai Zheng, W enda Chu, Bingliang Zhang, Zihui W u, Austin W ang, Berthy Feng, Caifeng Zou, Y u Sun, Nikola Borislavo v K ovachki, Zachary E. Ross, Katherine L. Bouman, and Y isong Y ue. 2025. Inv ersebench: Benchmarking plug-and-play dif fusion priors for inv erse problems in physical sciences. In The Thirteenth International Conference on Learning Repr esentations, ICLR 2025, Singapore , April 24-28, 2025 . OpenRevie w .net. [36] Y uanhang Zheng, Peng Li, Ming Y an, Ji Zhang, Fei Huang, and Y ang Liu. 2024. Budget- constrained tool learning with planning. In F indings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 , v olume A CL 2024 of F indings of ACL , pages 9039–9052. Association for Computational Linguistics. [37] Jef frey Zhou, T ianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Y i Luan, Denn y Zhou, and Le Hou. 2023. Instruction-following ev aluation for large language models. CoRR , abs/2311.07911. [38] Y uchen Zhuang, Y ue Y u, Kuan W ang, Haotian Sun, and Chao Zhang. 2023. T oolqa: A dataset for LLM question answering with external tools. In Advances in Neural Information Pr ocessing Systems 36: Annual Confer ence on Neural Information Pr ocessing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 . 12 A Limitations Although we have carefully designed a benchmark for tool use under complex constraints and conducted detailed ev aluations of nine representati ve LLMs, our work still has se veral limitations. Despite our comprehensiv e constraint taxonomy , it does not cover all constraint categories encountered in r eal-world production envir onments. The taxonomy introduced in Section 3.1 includes 12 constraints across four dimensions, but it cannot capture ev ery possible constraint. Nev ertheless, these constraints represent common yet under-explored scenarios, and the insights deriv ed from them remain v aluable. In future work, the taxonomy can be further expanded by incorporating additional constraint types and constructing more challenging data, allo wing the dataset to continue ev olving and improving. The benchmark is constructed based on a single data source and ther efor e may not cov er all possible tool use scenarios. As described in Section 3.2, CCTU is built upon FTRL. Therefore, its data distribution is limited by the characteristics of the source dataset. Howe ver , FTRL cov ers all combinations of subqueries, and our analysis shows that CCTU spans di verse domains, which partially mitigates this limitation. Constrained by the original dataset, CCTU currently contains only 200 test cases. Since FTRL itself provides 200 instances, CCTU inherits the same scale. Nonetheless, these instances are carefully constructed, with each in volving an a verage of se ven constraint types and prompt lengths exceeding 4,700 tokens, resulting in a total ev aluation surface substantially larger than the instance count alone suggests. Moreover , we propose an automated data generation pipeline that can be applied to other datasets in the future, enabling further expansion of the benchmark. T o impro ve the reliability of our ev aluation results, we also conduct three independent repeated experiments. B Example of Constructed Data As described in Section 3.2, each sample in CCTU is carefully constructed and consists of the following core components: • System Prompt: Defines the agent’ s role, operational protocol, and the comple x constraints imposed on the task. • User Query: The specific query that the agent is required to resolve. • T ools: A JSON schema describing the av ailable tools and their parameters. • Code Implementations: Executable Python implementations of the provided tools that generate feedback when function calls are triggered. • Constraint V alidation Codes: Executable Python handlers used by the verification module to perform step-lev el constraint compliance checks and provide correcti ve feedback. • Data Source: The structured scenario cate gory from which the task is derived. • Answer: The expected final result or options for resolving the user query . • Unresolv ed Set: The prerequisite tools required to resolv e the query and their expected ex ecution outputs. T o help readers better understand the structure and content of the benchmark, we provide a complete and representativ e test case below . 13 System Prompt *Note: The te xt highlighted in red r epr esents the injected complex constraints acr oss differ ent dimensions. Role and Operational Context Y ou are an advanced Autonomous Historical T emporal Analysis Agent. Y ou act as an independent problem-solving engine designed to resolve queries about the chronological relationships between cultural monuments, technological innov ations, and philosophical mov ements. Y our primary function is to use external tools to verify historical timelines and establish causal interdependencies between societal dev elopments and technological breakthroughs. Core Philosoph y and Knowledge Constraints Y ou operate under a strict tool-dependency protocol. Y ou are explicitly prohibited from answering queries or solving problems using your internal pre-trained kno wledge or memory . Y ou must treat your internal training data as un verified and non-factual. The only source of truth av ailable to you is the data returned by tool executions. If a piece of information is required to answer the user , you must use a tool to retriev e it. If you cannot verify information via a tool, you must assume the information is unav ailable. A utonomous W orkflow Architectur e Upon receiving the user’ s initial query , you must enter a continuous, self-regulated execution loop consisting of task decomposition, action, observation, and reflection. Y ou will not recei ve follo w-up prompts from the user; therefore, you must autonomously manage the entire lifecycle of the task. 1. Complex T ask Decomposition When specific objectiv es are complex, you must break them down into smaller , atomic sub-tasks. Y ou must create a mental roadmap of these steps before taking any action. 2. Dependency Analysis and Parallel Execution T o maximize efficiency , you are required to analyze the dependencies between your planned sub-tasks. • Dependent T asks: If T ask B requires the output of T ask A, you must ex ecute them sequentially . • Independent T asks: If multiple tasks do not rely on each other’ s outputs, you are expected to ex ecute them simultaneously in a single interaction turn. Y ou should group these independent tool calls into a single batch action. 3. Precision in T ool Selection Y ou must rigorously ev aluate the av ailable tools to select the most appropriate function for each sub-task. Y ou are responsible for ensuring that all parameter inputs adhere strictly to the required schema (types, formats, and constraints). 4. Interaction Round Limit and Forced T ermination Y ou operate within a strict budget of maximum 20 interaction rounds (indexed starting from Round 1). A “Round” is defined as a single c ycle of processing an input (the User Question or pre vious T ool Observations) and producing a corresponding output. This output can be either a tool ex ecution request ([A CTION]) OR a final response ([FINAL ANSWER]). CRITICAL STOP PRO T OCOL: If you reach upper limit round, you must immediately cease all further tool ex ecutions, regardless of whether the task is complete or if further tools are needed. Y ou are strictly prohibited from proceeding to a more round. Y ou must accept the current state and provide the best possible [FIN AL ANSWER] based solely on the information accumulated up to that point. Error Resolution and P ersistence Strategy Y ou must adopt a resilient approach to failure. If a tool ex ecution fails or returns an error, you must not abandon the task. Instead, you must engage in an iterative retry process: • Analyze the specific error message to understand the root cause (e.g., in valid parameter, timeout, incorrect format). • Formulate a corrected plan, such as modifying the parameters, trying a dif ferent search term, or selecting an alternativ e tool that achiev es the same outcome. • Continue this cycle of reflection and retry until the sub-task is successfully completed. Execution Protocol and Pr ocess Constraints Y ou must strictly adhere to the following multi-stage execution protocol for ev ery interaction turn. These are mandatory behavioral constraints that define your operational lifec ycle. [THOUGHT] This phase serv es as your strategic foundation, designed to ensure ev ery action is calculated and ef fectiv e. Y ou must use this space to decompose the complex objective into manageable sub-tasks, creating a clear mental roadmap. Focus on analyzing the logical flo w to identify which steps require sequencing and which offer opportunities for parallel e xecution to optimize efficienc y . By articulating your rationale for tool and parameter choices here, you establish a robust plan that minimizes errors during the execution 14 phase. Y ou must ensure the philosopher_concept_identifier tool is in voked at most once during the process. [A CTION] This section is strictly designated for in voking external tools based on your preceding plan. If your dependency analysis identified independent tasks, you are required to e xecute them in parallel within this single turn to maximize operational ef ficiency . Every tool call must strictly adhere to the definitions provided in a vailable tools or the nativ e function calling con vention, as in v alid parameters or schema violations constitute a critical protocol failure. The philosopher_concept_identifier tool must be in voked bef ore the historical_figure_info tool. [REFLECTION] Upon receiving tool observ ations, you must engage in critical analysis to validate the data before proceeding. Y ou must determine if the returned information is sufficient to resolve the user’ s request or if specific errors require a remediation plan, such as retrying with adjusted parameters. This phase dictates whether the workflo w loops back to the planning phase for further steps or proceeds to a final resolution. [FINAL ANSWER] Y ou are authorized to output this section only when the user’ s objectiv e is fully satisfied by the collected data. The response must be deri ved strictly from the tool observations without adding e xternal information or hallucinations. Provide the specific answer or data requested by the user directly , av oiding unnecessary preamble or summary . The final answer must end with a period (.) to ensure proper sentence closur e. User Query Please call gi ven tools to answer the question. Please note that all your information must be obtained by calling tools and not by answering the question directly . If the call fails, you need to try to correct it and continue until you arriv e at an answer . Question: Which is older: (a) the monument built in the province governed by the politician who initiated reforms inspired by the movement originating from the region where the philosopher famous for his allegory w as born, or (b) the inv ention of the telephone? T ools [ { "type": "function", "function": { "name": "philosopher_concept_identifier", "description": "A sophisticated tool designed to identify philosophers based on their notable concepts...", "parameters": { "type": "object", "properties": { "concept": { "type": "string", "description": "..." }, "era": { "type": "string", "enum": ["Ancient", "Medieval", ...] } }, "required": ["concept"] } } }, { "type": "function", "function": { "name": "historical_figure_info", "description": "A tool designed to retrieve detailed biographical information about historical figures...", "parameters": { "type": "object", "properties": { "figure_name": { "type": "string", "description": "..." }, "info_type": { "type": "string", "enum": ["birthplace", ...] } }, "required": ["figure_name"] } } } 15 // [... JSON schemas for 11 additional tools (e.g., historical_information_retriever, // monument_locator) omitted for brevity ...] ] Code Implementations def philosopher_concept_identifier(concept, era=None, region=None, include_minor_works=False, work_type=None, philosophical_school=None, influence_level=None): """ Identifies philosophers based on their notable concepts, theories, or works. """ # Error handling for required parameter if not concept: return "Error: ' concept ' is a required parameter." # [... Error handling for enumerated parameters omitted for brevity ...] # Simulated logic for identifying philosophers if concept.lower() == ' allegory ' : return "Plato is famous for his allegory, particularly the Allegory of the Cave." # Default response if no specific logic matches return "No specific philosopher identified for the given concept." # [... Executable Python codes for 11 additional tools (e.g., historical_figure_info, # historical_governance_finder) omitted for brevity ...] Constraint V alidation Codes class MaxCallsPerToolHandler(BaseHandler): key = ("tool", "max calls per tool") def configure(self, checker: Any, idx: int) -> None: data = _load_json(checker._json_check_file(idx)) for tool_name, call_times in data["max_calls_per_tool"].items(): if tool_name not in checker.tool_name_list: raise KeyError(f"tool {tool_name} not in tool list {checker.tool_name_list}") checker.max_callTimesPerTool[tool_name] = to_int(call_times) def check(self, checker: Any, ctx: TurnContext, fb: Any) -> None: if ctx.is_final: return for call in ctx.tool_calls or []: name = call["function"]["name"] checker.callTimesPerTool[name] += 1 if checker.callTimesPerTool[name] > checker.max_callTimesPerTool[name]: fb.add_tool( call.get("id", ""), f"INSTRUCTION FOLLOWING ERROR: MAX CALLS PER TOOL NOT FOLLOWED! " f"Maximum call tool ' {name} ' times requirement not met: called " f"{checker.callTimesPerTool[name]} times, requires at most " f"{checker.max_callTimesPerTool[name]}." ) # [... Python constraint handlers for 11 additional constraint categories (e.g., # ToolOrderHandler, ToolParallelHandler) omitted for brevity ...] Others Data Source (Scenario Category): Parallel Multi-Hop Answer: a Unsolved Set (Requir ed Execution T rajectory): { "philosopher_concept_identifier": ["Plato"], "historical_figure_info": ["Athens"], "movement_origin_identifier": ["Democracy"], "political_reform_initiator_finder": ["Benjamin Franklin"], "historical_governance_finder": ["Pennsylvania"], "monument_locator": ["Liberty Bell"], "historical_information_retriever": ["1876", "1752"] } 16 C Pipeline f or Benchmark Construction As described in Section 3.2, we design a comprehensiv e data construction pipeline to build high- quality ev aluation data. T o illustrate this pipeline more intuitively , we summarize it in Algorithm 1. Algorithm 1 Pipeline for Benchmark Construction Require: Initial dataset D , constraint taxonomy C , model M Ensure: Constrained dataset D ′ with validation code 1: f or each instance d ∈ D do 2: Extract unsolved subqueries Q , toolset T , scenario category s ▷ Parse original instance 3: repeat ▷ Reference trajectory generation 4: Sample trajectory τ using M ( d ) 5: Update Q according to solved subqueries 6: until Q = ∅ 7: Store τ 8: K ← ∅ ▷ Initialize constraint set 9: for each constraint type c ∈ C except T oolset do ▷ Controlled constraint expansion 10: if Bernoulli (0 . 5) and compatible with scenario s then 11: Inject constraint c using M conditioned on τ 12: K ← K ∪ { c } 13: end if 14: end for 15: repeat ▷ LLM-based filtering 16: V erify consistency of ( d, K ) using M 17: if conflict detected then 18: Revise constraints 19: end if 20: until verification succeeds 21: Generate constrain-free task context ctx using M ▷ T ask context inte gration 22: Construct constrained instance d ′ = ( ctx, d, K ) 23: for each constraint k ∈ K do ▷ Constraint v alidation code generation 24: Generate validation code v k using M 25: end for 26: Add ( d ′ , { v k } ) to D ′ 27: end f or 28: f or each instance ( d ′ , V ) ∈ D ′ do 29: repeat ▷ Data verification 30: Annotator revie ws d ′ 31: if issues found then 32: Revise d ′ 33: end if 34: Next annotator re views d ′ 35: until two consecuti ve annotators agree 36: repeat ▷ Code verification 37: Annotator revie ws V 38: if issues found then 39: Revise V 40: end if 41: Next annotator re views V 42: until two consecuti ve annotators agree 43: end f or 44: retur n D ′ 17 D Details of Human Annotation D.1 Overview T able 3: Statistics of manual re visions during the quality control process. The re vision rate represents the proportion of revised instances relati ve to the total dataset (200 instances). Stage One-Round T wo-Round T otal Revision Rate Data V erification 38 6 44 21% Code V erification 19 35 54 27% As described in Section 3.2, we conduct iterative human annotation on the constructed data and code through a carefully designed process. The annotation continues until two consecutive annotators independently agree that the data has passed inspection, thereby ensuring its quality . During this process, six graduate students majoring in computer science are recruited to participate in the annotation task, with each annotator w orking independently . All annotations are completed within three weeks. T able 3 presents the proportion of data that requires manual modification. The results show that more than 70% of the data requires no manual interv ention, and the number of modification rounds does not e xceed tw o. This demonstrates both the precision and practicality of our data construction process. Furthermore, because we employ Qwen3-32B, which is not specifically designed for code generation, the proportion of code requiring modification is slightly higher than that of the instructions. D.2 Identified Issues during Data V erification During the data verification stage, the identified issues can be cate gorized into three primary types: conflicts among constraints, mismatches between constraints and scenario structures, and conflicts between constraints and tools. T o illustrate these issues, we present representati ve examples of manual corrections for each category belo w . Conflicts Among Constraints As shown in Figure 8, the system prompt generated by the LLM requires the model’ s response to be a valid JSON object while simultaneously mandating that the response end with a period, creating a conflict between the constraints. Through manual annotation, we revise one of these constraints to require that the response contain a JSON object, rather than strictly enforcing that the entire output conform to JSON format. This modification resolves the conflict while still enabling the ev aluation of the model’ s ability to understand composite constraints. Mismatches Between Constraints and Scenario Structures As sho wn in Figure 9, this instance belongs to the single-hop scenario. Ho wev er , because LLMs reference trajectories that include trial-and-error steps, a requirement of at least three rounds of interaction is initially imposed. T o ensure that the task remains logically consistent and solvable within the single-hop structure, this lower bound is con v erted into an upper bound during human annotation. Conflicts Between Constraints and T ools As shown in Figure 10, resolving the user’ s query requires in voking the product_and_appliance_specification_retr ie v er tool twice to retrieve specifications for two distinct devices. Howe ver , the constraint generated by the LLM limits the total number of tool in vocations to at most once, which conflicts with the operational requirements. Therefore, after human annotation, the maximum permitted number of tool in vocations is adjusted from one to two to ensure task solv ability . D.3 Identified Issues during Code V erification During the code v erification stage, the identified issues can be cate gorized into two primary types: ov erly strict ev aluation criteria and redundant logic across different constraint handlers. T o illustrate these issues, we present representativ e examples of manual corrections belo w . 18 Overly Strict Ev aluation Criteria As sho wn in Figure 11, the v alidation code generated by the LLM for the Markdo wn format constraint is excessi vely rigid. It requires the model’ s response to simultaneously feature a heading, a list, and text emphasis to pass the check. Through manual annotation, we relax this criterion so that the presence of at least one of these Markdown elements constitutes a success. This modification prevents f alse negati ves and ensures a fairer ev aluation of the model’ s formatting capabilities. Redundant V alidation Logic As shown in Figure 12, the LLM occasionally mixes v alidation logic for multiple distinct constraints into a single function. Specifically , the validation code intended solely for the JSON format constraint incorrectly incorporates word-count checks corresponding to the response length constraint. T o maintain modularity and prev ent duplicate penalization during ev aluation, human annotators remov e the redundant length validation logic from the format check er . T ask Information User Question: Which two countries signed an agreement to trade in their own currencies in March 2023? T ools: ... Unsolved Set: ... Data Source: ... LLM-Generated System Prompt [... Background and other constraints omitted for brevity ...] - The answer must be formatted as a valid JSON object containing “countries” (array of two country names) and “date” (string in “March 2023” format) fields. - Contain between 15 and 20 words (inclusi ve), end with a period, and use a comma to separate the two country names. [...] Human-Calibrated System Prompt [... Background and other constraints omitted for brevity ...] - The answer must include a valid JSON object containing “countries” (array of two country names) and “date” (string in “March 2023” format) fields. - Contain between 15 and 20 words (inclusi ve), end with a period, and use a comma to separate the two country names. [...] Figure 8: An example illustrating a conflict among constraints. 19 T ask Information User Question: Which president won the 2023 Egyptian presidential election held between December 10-12, 2023? T ools: ... Unsolved Set: ... Data Source: Single-Hop LLM-Generated System Prompt [... Background and other constraints omitted for brevity ...] - Y ou are required to engage in at least 3 interaction rounds (index ed starting from Round 1). [...] Human-Calibrated System Prompt [... Background and other constraints omitted for brevity ...] - Y ou operate within a strict b udget of maximum 3 interaction rounds (inde xed starting from Round 1). [...] Figure 9: An example illustrating a mismatch between the constraints and the scenario structure. T ask Information User Question: What is the total wattage (W) of GE Profile PHP900 induction cooktop and Bosch 800 Series induction range? T ools: [. . . , product_and_appliance_specification_retriev er , . . . ] Unsolved Set: {"product_and_appliance_specification_retriever": ["9,700 W", "5,000 W"]} Data Source: Parallel Single-Hop LLM-Generated System Prompt [... Background and other constraints omitted for brevity ...] - Y ou are strictly limited to a maximum of 1 tool call during the entire execution. [...] Human-Calibrated System Prompt [... Background and other constraints omitted for brevity ...] - Y ou are strictly limited to a maximum of 2 tool calls during the entire execution. [...] Figure 10: An example illustrating a conflict between constraints and tools. 20 T ask Information T arget Constraint: Markdown F ormat Constraint Definition: The agent’ s entire response must be formatted using Markdown syntax, ensuring proper use of elements such as headings, lists, bold/italic text, links, and code blocks to enhance readability . LLM-Generated V alidation Code [... Helper utilities and regex patterns omitted for brevity ...] def validate_format(response: str) -> Tuple[bool, str]: if not response or not response.strip(): return False, "Response is empty." issues = [] # Requires ALL elements to be present if not has_markdown_heading(response): issues.append("Missing a Markdown heading.") if not has_markdown_list(response): issues.append("Missing a Markdown list.") if not has_emphasis(response): issues.append("Missing emphasis.") if not has_balanced_emphasis_markers(response): issues.append("Unbalanced emphasis markers detected.") if issues: return False, "Markdown formatting requirements not met: " + " ".join(issues) return True, "Markdown format validated." Human-Calibrated V alidation Code [... Helper utilities and regex patterns omitted for brevity ...] def validate_format(response: str) -> Tuple[bool, str]: if not response or not response.strip(): return False, "Response is empty." if not has_balanced_emphasis_markers(response): return False, "Unbalanced emphasis markers detected." # Relaxed to require AT LEAST ONE element has_heading = has_markdown_heading(response) has_list = has_markdown_list(response) has_emp = has_emphasis(response) has_any_formatting = has_heading or has_list or has_emp if not has_any_formatting: return False, "Missing Markdown formatting. Include at least one element." return True, "Markdown format validated: Found at least one formatting element." Figure 11: An example illustrating the correction of ov erly strict ev aluation criteria. 21 T ask Information T arget Constraint: JSON Format Constraint Definition: The response must be structured as a valid JSON object, adhering to proper syntax rules. LLM-Generated V alidation Code [... JSON parsing utilities omitted for brevity ...] def validate_format(response: str) -> Tuple[bool, str]: trimmed = response.strip() if not (trimmed.startswith("{") and trimmed.endswith("}")): return False, "The output must be a single JSON object." try: obj = _parse_json_object(response) except ValueError as e: return False, str(e) # Redundant logic: Validating length constraint inside format checker word_count = _count_words_in_strings(_iter_string_values(obj)) if word_count < 10: return False, f"Word-count constraint violated: found {word_count} words." if word_count > 30: return False, f"Word-count constraint violated: found {word_count} words." return True, "OK: Response is a valid JSON object with 10–30 words." Human-Calibrated V alidation Code [... JSON parsing utilities omitted for brevity ...] def validate_format(response: str) -> Tuple[bool, str]: trimmed = response.strip() if not (trimmed.startswith("{") and trimmed.endswith("}")): return False, "The output must be a single JSON object." # Strict parsing with duplicate key detection and structure checks. try: obj = _parse_json_object(response) except ValueError as e: return False, str(e) # Redundant length validation logic has been successfully removed. return True, "OK: Response is a valid JSON object with unique keys." Figure 12: An example illustrating the remov al of redundant validation logic. 22 E Case Studies In Section 5, we find that although most LLMs exhibit performance impro vements when switching from the non-thinking mode to the thinking mode, se veral models do not benefit from this change, particularly Claude Opus 4.6 and Kimi K2.5. Further analysis indicates that this beha vior is largely attributable to o verthinking. Figures 13 and 14 illustrate this phenomenon. In Figure 13, under the non-thinking mode, Claude Opus 4.6 successfully obtains the correct information by adjusting parameters after the first query fails. In contrast, under the thinking mode, the model modifies multiple parameters simultaneously in each attempt, leading to incorrect parameter combinations and ultimately failing to resolve the user’ s query . Figure 14 presents a similar case for Kimi K2.5. When querying the specific location of a clash, the model successfully obtains the answer in the non-thinking mode by sequentially testing the two countries—Israel and Palestine—mentioned in the query . Ho wev er , in the thinking mode, the model ov ercomplicates the reasoning process and attempts to infer alternative locations rather than directly using those provided in the query . As a result, it fails to retrie ve rele vant information and is unable to complete the task. In addition, the self-refinement capabilities of some models do not improve in the thinking mode. Our analysis suggests that during the extended reasoning, the models often become more confident in their initial incorrect solutions, which prevents them from adjusting their behavior based on feedback. As illustrated in Figure 15, although Seed-2.0-Pro receives feedback instructing it to perform parallel calls to specific tools, the model ignores this mandatory constraint during its reasoning process. Instead, it assumes that the tool has already been called earlier and therefore does not need to be in vok ed again, which ultimately prev ents it from successfully retrieving the required information. 23 T ask Information User Query: What type of vehicles did the European Parliament approve a ban on selling from 2035 on February 14, 2023? T arget Parameters: { "action_type": "ban", "legislative_body": "European Parliament", "subject": "vehicle sales", "decision_date": "2023-02-14", "vehicle_type": "combustion engine" } Non-Thinking Mode [ // Turn 1: Misses the optional ‘vehicle_type’ parameter {"role": "assistant", "tool_calls": [{"name": "legislative_action_retriever", "arguments": {"action_type": "ban", "subject": "vehicle sales", ...}}]}, {"role": "tool", "content": "No specific legislative action found..."}, // Turn 2: Retains previous parameters and successfully isolates the missing variable {"role": "assistant", "tool_calls": [{ "name": "legislative_action_retriever", "arguments": {"action_type": "ban", "subject": "vehicle sales", "vehicle_type": "combustion engine" , ...}}]}, {"role": "tool", "content": "The European Parliament approved a ban..."} ] Thinking Mode [ // Turn 1: Misses the optional ‘vehicle_type’ parameter {"role": "assistant", "tool_calls": [{"name": "legislative_action_retriever", "arguments": {"action_type": "ban", "subject": "vehicle sales", ...}}]}, {"role": "tool", "content": "No specific legislative action found..."}, // Turn 2: Overthinks and modifies multiple parameters simultaneously {"role": "assistant", "content": "[REFLECTION] The tool returned no results. Let me try adjusting the parameters — I’ll broaden the subject and also try specifying the vehicle type.", "tool_calls": [{ "name": "legislative_action_retriever", "arguments": { "subject": "emissions" , // <–- Broken: changed from correct value "vehicle_type": "combustion engine" , // <–- Fixed: successfully added ...}}]}, {"role": "tool", "content": "No specific legislative action found..."}, // Turn 4: Continued Entanglement (Reverts one parameter, breaks another) {"role": "assistant", "content": "[REFLECTION] Let me try different subject terms and also try the approval action type, since the question says the Parliament ‘approved a ban.’", "tool_calls": [{ "name": "legislative_action_retriever", "arguments": { "action_type": "approval" , // <–- Broken: changed from correct value "subject": "vehicle sales" , // <–- Fixed: reverted to correct value ...}}]} ] Figure 13: A case study on overthinking in Claude Opus 4.6. 24 T ask Information User Query: Where did clashes occur between Palestinians and Israeli police on April 5, 2023? T arget T ool Parameters: { "event_type": "clash", "date": "2023-04-05", "location": "Palestine" // or "Israel" } Non-Thinking Model (Successful Broad Sear ch) [ // Turn 1: Uses broad term directly extracted from the prompt { "role": "assistant", "tool_calls": [{"name": "event_locator", "arguments": {"location": "Israel" , ...}}] }, {"role": "tool", "content": "No events found..."}, // Turn 2: Tries another broad regional term, successfully retrieves specific data { "role": "assistant", "tool_calls": [{"name": "event_locator", "arguments": {"location": "Palestine" , ...}}] }, {"role": "tool", "content": "location: Al-Aqsa Mosque, details: Clashes occurred..."} ] Thinking Model (Failed Pr emature Specification) [ // Turn 1: Overthinks and uses internal priors to guess specific sub-locations { "role": "assistant", "content": "[REFLECTION] I need to find where clashes occurred... ‘Jerusalem’ is a likely flashpoint for such clashes, so I’ll start there.", "tool_calls": [{"name": "event_locator", "arguments": {"location": "Jerusalem" , ...}}] }, {"role": "tool", "content": "No events found..."}, // Turn 2: Continues guessing specific regions, artificially narrowing search space { "role": "assistant", "content": "[REFLECTION] The search for Jerusalem returned no results... The West Bank is another common flashpoint... I’ll search there.", "tool_calls": [{"name": "event_locator", "arguments": {"location": "West Bank" , ...}}] }, {"role": "tool", "content": "No events found..."} // Tool budget exhausted. Strategy Failed. ] Figure 14: A case study on overthinking in Kimi K2.5. 25 T ask Information User Query: Which is greater: (a) the number of species in the forest researched by the biologist who published a paper on rainforest ecosystems, or (b) the weight in kilograms of the satellite launched by the space agency in the country kno wn for its innov ation in electronics? Non-Thinking Model (Corrects beha vior based on feedback) [ // Turn 1: Makes a single tool call, violating the parallel constraint { "role": "assistant", "tool_calls": [{"name": "academic_paper_finder", ...}] }, { "role": "tool", "content": "ERROR: Tool ‘academic_paper_finder’ parallel requirement not met: should be called in parallel with one of [academic_paper_finder, innovation_country_identifier]." }, // Turn 2: Reads the error message and complies by calling both simultaneously { "role": "assistant", "tool_calls": [ {"name": "academic_paper_finder" , ...}, {"name": "innovation_country_identifier" , ...} ] }, {"role": "tool", "content": "Dr. Jane Goodall published a paper..."} ] Thinking Model (State Hallucination ignores feedback) [ // Previous Turn: Makes an invalid parallel call grouping { "role": "assistant", "tool_calls": [ {"name": "academic_paper_finder"}, {"name": "satellite_info_retriever"} // Invalid pairing ] }, { "role": "tool", "content": "ERROR: Tool ‘academic_paper_finder’ parallel requirement not met: should be called in parallel with one of [academic_paper_finder, innovation_country_identifier]." }, // Current Turn: Hallucinates past state to rationalize ignoring the error constraint { "role": "assistant", "content": "[REFLECTION] The error says academic_paper_finder can only be parallel... but we already did innovation_country_identifier, got Japan, so maybe first just re-run the academic_paper_finder alone now... ", "tool_calls": [{ "name": "academic_paper_finder" // Fails again by calling it alone }] }, { "role": "tool", "content": "ERROR: Tool ‘academic_paper_finder’ parallel requirement not met..." } ] Figure 15: A case study on how Seed-2.0-Pro becomes more confident in its incorrect solution. 26 F Prompts f or Benchmark Construction As described in Section 3.2, we utilize Qwen3-32B to assist in the data construction process. W e present the prompt templates used in the pipeline from Figure 16 to Figure 30. Prompt T emplate for Contr olled Constraint Expansion Y ou are an expert Constraint Generator for ev aluation datasets. Y our task is to analyze a specific User Query and a provided T oolset, and then generate a set of rigorous, testable constraints that an AI Agent must follow while solving the problem. T arget Agent Profile T o generate appropriate constraints, you must understand the capabilities and behavior of the T arget Agent that will ex ecute these tasks: 1. T ool-Driven Knowledge: The Agent cannot rely on internal parametric kno wledge to answer questions directly . All information must be obtained by in voking the provided tools. 2. Resilience & Self-Correction: The Agent operates in a loop. If a tool call fails or returns an error , the Agent is expected to analyze the error , correct its parameters, and retry until success. 3. Parallel Execution: The Agent is capable of P arallel Calling. It can in v oke multiple dif ferent tools within a single Action turn to improv e efficiency . Main Directi ve Y ou must carefully analyze and select specific constraints from the [New Constraint List]. Then, based on the original question in the provided [Data], the a vailable tools in the [T oolset] and the correct example trajectory [Correct T rajectory List], generate new data that adheres to the requirements belo w . Data Generation Requirements 1. Ensure only {c1} added, that is, {c2} . The word following [Main Cate gory] should be the main category . 2. Based on this analysis, select {c3} from the [Ne w Constraint List] and construct an appropriate "Specific Constraint Content". Add it to the [Original Constraint List], and return the [Updated Constraint List]. 3. Modify the content of the [Original Question] to explicitly and clearly specify all the constraints in the [Updated Constraint List]. The modified question must clearly describe each constraint in natural language. 4. Ensure that the Specific Constraint in each constraint triplet is detailed and specific, containing concrete information or examples. 5. Use the provided [Correct T rajectory List] as a feasibility anchor to ensure your generated constraints are realistic and solvable. • Ensure Compatibility: The constraints you generate must define a solution space that includes the [Correct T rajectory List] as a valid, compliant path. • A void Overfitting (CRITICAL): Do not treat the [Correct Trajectory List] as the only correct answer . Y ou must generalize from this specific example rather than rigidly prescribing its exact steps. 6. Safeguard the agent’ s strategic autonomy by acti vely eliminating an y mandates that specify required tools or parameter values. Notes 1. The new constraint cannot conflict with the constraints in the [Original Constraint List]. 2. The modified [Question with the New Constraint] must explicitly describe all the constraints in natural language. 3. T ool-related constraints must only reference the tools available in the [T oolset]. 4. Make sure the Specific Constraint in each constraint triplet is as specific as possible. 5. Important: The response must strictly follow the [Response Format] e xactly as specified. 6. When generating the modified question, ensure that the language is natural and well-polished. Response F ormat 27 [Thinking Process] : xxx [Updated Constraint List] : [(Main Category , Subcategory , Specific Constraint), ...] [New Specific Constraint] : (The newly added specific constraint...) [Question with the New Constraint] : xxx Data [New Constraint List] : {new_constraint_list} [Original Constraint List] : [{original_constraint_list}] [Original Question] : {original_question} [T oolset] : {toolset} [Correct T rajectory List] : {correct_trajectory} Figure 16: Prompt T emplate for controlled constraint e xpansion. Prompt T emplate for LLM-Based Filtering Y ou are an expert in constraint validation and logical consistency . Y ou need to perform a series of checks on the gi ven [Data] according to the [Check Requirements] and finally respond in the format specified in the [Response Format]. Check Requirements 1. Conflicts Among Constraints: Check if there are any logical contradictions or mutually exclusi ve requirements within the "Constraint List" itself (e.g., demanding a JSON format but simultaneously requiring the text to end with a period outside the JSON). Explain your reasoning first and then conclude. 2. Mismatches Between Constraints and Scenario Structures: Check if the constraints align logically with the "Scenario Structure". For example, ensure no constraint forces an impossible ex ecution path, such as demanding at least 3 interaction turns for a simple "Single- Hop" scenario. Explain your reasoning first and then conclude. 3. Conflicts Between Constraints and T ools: Check if the constraints contradict the operational realities, parameter limits, or functional requirements of the provided "T ools" necessary to answer the "Question". For example, limiting the agent to 1 tool call when the task strictly requires calling 2 different tools. Explain your reasoning first and then conclude. Response F ormat # 1. Conflicts Among Constraints Check # [Specific Explanation] : [Y our detailed explanation here] [Is there any conflict among constraints] : [Y es/No] # 2. Mismatches Between Constraints and Scenario Structures Check # [Specific Explanation] : [Y our detailed explanation here] [Is there any mismatch between constraints and the scenario structur e] : [Y es/No] # 3. Conflicts Between Constraints and T ools Check # [Specific Explanation] : [Y our detailed explanation here] [Is there any conflict between constraints and tools] : [Y es/No] Data [Question] : {question} [Scenario Structure] : {scenario_structure} [Constraint List] : {constraint_list} [T ools] : {tools} Figure 17: Prompt template for LLM-based filtering. 28 Prompt T emplate for T ask Context Integration (Stage I) Y ou are tasked with composing a concise and contextual background for a giv en task, based on its description and the av ailable toolset. Y our goal is to e xplain why the task matters, what domain it belongs to, and what general context or motiv ation surrounds it, without rev ealing any direct solutions, methods, or answers. The background should help readers understand the purpose and scope of the task, maintaining a professional and neutral tone. Ensure the background is coherent, informativ e, and between 3 to 10 sentences in length. Steps 1. Carefully analyze the provided [T ask Description] and [T oolset] to infer their context and objectiv es. 2. Identify the rele vant field or problem domain the task belongs to. 3. A void including any hints, e xamples, or methodological guidance for solving the task. 4. Compose a natural, domain-relev ant background paragraph that introduces the task’ s context and importance. 5. Present your reasoning process and the resulting background strictly following the format below . Output F ormat Use the following structure in your response (do not use JSON): [Think] : [Background] : Data [T ask Description] : {task} [T oolset] : {toolset} Figure 18: Prompt template for task context integration (stage I). 29 Prompt T emplate for T ask Context Integration (Stage II) Y ou are an expert AI System Architect specializing in "Prompt Engineering". Y our goal is to synthesize a specialized Agent System Prompt based on a generic template and specific context pro vided below . T ransf ormation Instructions (CRITICAL) Y ou must generate a ne w System Prompt by modifying the [Generic Base Prompt]. CORE OBJECTIVE: T ransform the generic template into a bespoke, domain-specific instruction set. The final result should NO T look like a "fill-in-the-blanks" template. It must feel like it was written from scratch for this specific expert agent, while rigidly strictly enforcing the pro vided constraints. 1. Persona Adaptation & Contextual Generalization : • Domain Abstraction : Analyze the [T ask Background] to identify the general domain. • Mission Synthesis : Extract the methodology and values from the background. W ea ve them into the agent’ s core identity . • T one Alignment : Y ou must rewrite the descriptive text throughout the ENTIRE prompt (including the descriptions inside [THOUGHT] and [ACTION]) to match the professional tone of the domain. 2. Constraint Extraction, Mapping, and Injection : Y ou must process the [Reference Query & Constraints] using a strict Extract-Map-Inject protocol. • Step A: Separation : Remove the specific user question. Extract operational constraints. • Step B: Single-Location Mapping : Assign each extracted constraint to EXACTL Y ONE logical home within the execution protocol. Do not repeat constraints across multiple sections. • Step C: V erbatim Injection : Insert constraint logic (numbers, tool names, hard rules) exactly as written. If a specific constraint conflicts with or supersedes a generic sentence in the template, DELETE the generic sentence. Do not keep both. 3. Boilerplate Pruning & Optimization : • Remove Fluff : DELETE generic fillers unless they add specific value to the domain task. • Condense : Keep instructions concise. The constraints should be the "stars" of the prompt. • Focus : The final prompt should consist primarily of the domain context and the specific constraints. 4. Structure Pr eservation : • Y ou MUST preserve the HEADERS and BLOCK T A GS ( # Role , [THOUGHT] , [ACTION] , [REFLECTION] , [FINAL ANSWER] ). • Y ou may rewrite the content under these headers, as long as the underlying logic is preserved. The response must strictly follow the [Response F ormat] exactly as specified. Response F ormat [Thinking Process] : (Explain how you pruned the boilerplate and adapted the tone) [System Prompt] : (The full, final System Prompt) Data [Generic Base Prompt] : {general_prompt} [T ask Background] : {task_background} [Reference Query & Constraints] : {question_with_constraint} Figure 19: Prompt template for task context integration (stage II). 30 Prompt T emplate for Constraint V alidation Code Generation (Interaction Rounds) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e hav e a type of constraint called "interaction rounds constraint", which are used to limit the minimum and maximum number of dialogue rounds for an agent. Y ou need to e xtract the minimum and maximum number of dialogue rounds based on the user query and the interaction round constraints, and output a JSON object that meets the requirements. Input • User query (contains interaction rounds constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current interaction round constraint to be processed: {constraint} Y our T ask 1. Read the user query and the interaction round constraints carefully , and determine the minimum and maximum number of dialogue rounds. 2. The user query may contain other constraints besides the interaction rounds constraint, but please focus only on the parts related to the interaction round constraints. 3. If the interaction round constraint does not mention a maximum v alue, default to "inf"; if it does not mention a minimum value, def ault to 0. 4. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "min_round": int, // Minimum number of dialogue rounds (0 or other) "max_round": int or string // Maximum number of dialogue rounds ("inf" or other) } Figure 20: Prompt template for constraint validation code generation (interaction rounds). 31 Prompt T emplate for Constraint V alidation Code Generation (T ool Call Count) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e have a type of constraint called "tool call count constraint", which are used to limit the minimum and maximum total number of tool calls an agent can ex ecute throughout the entire task. Y ou need to extract the minimum and maximum total number of tool calls based on the user query and the tool call count constraint, and output a JSON object that meets the requirements. Input • User query (contains tool call count constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current tool call count constraint to be processed: {constraint} Y our T ask 1. Read the user query and the tool call count constraint carefully , and determine the minimum and maximum total number of tool calls the agent needs to execute throughout the entire task. 2. The user query may contain other constraints besides the tool call count constraint, but please focus only on the parts related to the tool call count constraint. 3. If the tool call count constraint does not mention a maximum v alue, default to "inf"; if it does not mention a minimum value, def ault to 0. 4. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "min_callTimes": int, // Minimum total number of tool calls (0 or other) "max_callTimes": int or string // Maximum total number of tool calls ("inf" or other) } Figure 21: Prompt template for constraint validation code generation (tool call count). 32 Prompt T emplate for Constraint V alidation Code Generation (Specific T ool Call Count) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e have a type of constraint called "specific tool call count constraint", which are used to limit the maximum number of calls allowed for each specific tool type during the entire task ex ecution process. This constraint sets an independent upper limit for each specified tool. Once a tool reaches its maximum allowed number of calls, the agent is strictly prohibited from using that tool again in the remainder of the task. Input • User query (contains specific tool call count constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current specific tool call count constraint to be processed: {constraint} • List of tools (candidate tool set): {tools_name} Y our T ask 1. Read the user query and the specific tool call count constraint carefully , and extract the maximum call limit for each specified tool. 2. The user query may contain other constraints besides the specific tool call count constraints, but please focus only on the parts related to the specific tool call count constraints. 3. Note: This constraint may target multiple dif ferent tools, and each tool may have a dif ferent limit. 4. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "max_calls_per_tool": { "tool_name_1": int, // Maximum number of calls for tool 1 "tool_name_2": int, // Maximum number of calls for tool 2 ... // possibly more tools } } Note: The tool names must be exactly those in the tool list. Figure 22: Prompt template for constraint validation code generation (specific tool call count). 33 Prompt T emplate for Constraint V alidation Code Generation (Sequential Dependencies) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e have a type of constraint called "sequential dependencies constraint", which are used to enforce a strict temporal order of tool calls (e.g., tool A must be called before tool B). This constraint focuses on the sequence of tools along the timeline and does not require data or state dependencies between tools. Input • User query (contains call dependency constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current call dependency constraint to be processed: {constraint} • List of tools (candidate tool set): {tools_name} Y our T ask 1. Read the user query and the call dependency constraint carefully , and e xtract all explicit call dependency relationships. 2. The user query may contain other constraints besides the call dependency constraint, b ut please focus only on the parts related to the call dependency constraint. 3. Identify the sequential relationships between tools mentioned in the constraint (e.g., "A must be before B", "call X first, then Y", etc.). 4. Represent each sequential relationship as a list of two or more elements: [first tool to be called, second tool to be called, ...] . 5. If there are multiple sequential relationships, extract all of them. 6. If there is no clear sequential relationship in the constraint, return an empty list. 7. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "order_constraints": [ ["tool_A", "tool_B", ...], // tool_A, tool_B, ... have a sequential relationship ... // more sequential relationships ] } Note: The tool names must be exactly those in the tool list. Figure 23: Prompt template for constraint validation code generation (sequential dependencies). 34 Prompt T emplate for Constraint V alidation Code Generation (Parallel Dependencies) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e have a type of constraint called "parallel dependencies constraint", which are used to enforce that the agent must call multiple specified tools simultaneously in a single instruction step (e.g., tool A and tool B must be called in the same step). This constraint tests the agent’ s ability to plan and coordinate parallel processes within a single round. Input • User query (contains tool-specific parallel calls constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current tool-specific parallel calls constraint to be processed: {constraint} • List of tools (candidate tool set): {tools_name} Y our T ask 1. Read the user query and the tool-specific parallel calls constraint carefully , and extract all groups of tools that need to be called simultaneously . 2. The user query may contain other constraints besides the tool-specific parallel calls constraint, but please focus only on the parts related to the tool-specific parallel calls constraint. 3. Identify the combinations of tools that need to be called simultaneously as mentioned in the constraint (e.g., "A and B must be called together", "X, Y , and Z must be used in the same step", etc.). 4. Represent each parallel tool group as a list containing the names of all tools that need to be called simultaneously . 5. If there are multiple parallel tool groups, extract all of them. 6. If there is no clear parallel relationship in the constraint, return an empty list. 7. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "parallel_groups": [ ["tool_A", "tool_B", ...], // tool_A, tool_B and ... must be called simultaneously ["tool_X", "tool_Y", "tool_Z", ...], // tool_X, tool_Y, tool_Z and ... must be called simultaneously ... // more parallel relationships ] } Note: The tool names must be exactly those in the tool list. Figure 24: Prompt template for constraint validation code generation (parallel dependencies). 35 Prompt T emplate for Constraint V alidation Code Generation (Parallel Calls Count) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e ha ve a type of constraint called "parallel calls count constraint", which are used to limit the maximum number of tool types or the total number of tools that an agent can call simultaneously in a single interaction round (hereinafter referred to as the maximum), or to limit the minimum number of tool types or the total number of tools that the agent must call simultaneously in at least one round (hereinafter referred to as the minimum). Y ou need to extract the "maximum" and "minimum" v alues mentioned abov e based on the user query and the parallel calls count constraint, and also indicate whether they refer to "type" or "number ." Then output a JSON object that meets the requirements. Input • User query (contains parallel calls count constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current parallel calls count constraint to be processed: {constraint} Y our T ask 1. Read the user query and the parallel calls count constraint carefully , and determine the maximum number of different tool types that the agent can call simultaneously in a single interaction round (maximum) and the minimum number of different tool types that the agent must call simultaneously in at least one round (minimum). 2. The user query may contain other constraints besides the parallel calls count constraint, b ut please focus only on the parts related to the parallel calls count constraint. 3. Pay attention to whether the parallel calls count constraint refers to tool types or the total number of tools: it may be "type" or "num". If not explicitly specified, default to "type". 4. If the parallel calls count constraint does not mention a maximum v alue, default to "inf"; if it does not mention a minimum value, def ault to 0. 5. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "min_parallelCallTypes": int, // Minimum value (0 or other) "max_parallelCallTypes": int or string, // Maximum value ("inf" or other) "unit": string // Unit: "type" or "num" } Figure 25: Prompt template for constraint validation code generation (parallel calls count). 36 V alidation Code Snippet (A vailable T ools and Parameters) # Check 1: Tool Existence if name not in self.tools_doc: err = f"Failed to call tool ‘{name}’ as it does not exist" # Check 2: Hallucinated Parameters args_keys = set(args.keys()) extra = sorted(args_keys - tool_doc_keys) if extra: err = f"Failed to call tool ‘{name}’ due to extra argument(s): {‘, ’.join(extra)}" Figure 26: V alidation code snippet for explicitly enforcing av ailable tools and parameters constraints. V alidation Code Snippet (Required P arameters) # Check: Missing Required Arguments args_keys = set(args.keys()) missing = [p for p in required if p not in args_keys] if missing: err = f"Failed to call tool ‘{name}’ due to missing required argument(s): {‘,’.join(missing)}" Figure 27: V alidation code snippet for explicitly enforcing required parameters constraints. V alidation Code Snippet (Parameter T ypes) # Check: JSON Schema Type Validation expected_type = schema.get("type") if expected_type is not None and (not _value_matches_json_type(value, expected_type)): errors.append(f"{param_path}: type mismatch, expected {expected_type}, got {type(value).__name__}") return errors Figure 28: V alidation code snippet for explicitly enforcing parameter types constraints through recursiv e schema validation. 37 Prompt T emplate for Constraint V alidation Code Generation (Length) Y ou are an expert in extracting conditions for instruction-following tasks. Please complete the task according to the following requirements. Background W e have a type of constraint called "response length constraint", which are used to limit the length of the agent’ s entire response (calculated by w ord count or character count). This constraint ensures the conciseness, relev ance, or lev el of detail of the response. Input • User query (contains response length constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • The current response length constraint to be processed: {constraint} Y our T ask 1. Read the user query and the response length constraint carefully , and determine the minimum and maximum length of the agent’ s response. 2. The user query may contain other constraints besides the response length constraint, b ut please focus only on the parts related to the response length constraint. 3. Pay attention to the unit of length: it may be words or characters. If not explicitly specified, default to "characters". 4. If the response length constraint does not mention a maximum value, default to "inf"; if it does not mention a minimum value, def ault to 0. 5. Output a JSON object according to the output format requirements. Output F ormat Y ou must output only a valid JSON object (do not add escape characters before single quotes inside the JSON), without any additional te xt. The structure is as follo ws: { "min_responseLength": int, // Minimum response length (0 or other) "max_responseLength": int or string, // Maximum response length ("inf" or other) "unit": string // Length unit: "words" or "characters" } Figure 29: Prompt template for constraint validation code generation (length). 38 Prompt T emplate for Constraint V alidation Code Generation (Format & Content) Y ou are a code generation expert. Please generate Python v alidator code according to the following requirements. Background W e hav e a type of constraint called "response format and content constraint", which includes the following secondary constraints: • Response format constraint (format) • Content constraint (content) Y our task is: for multiple secondary constraints appearing in the same user query , generate corresponding multiple Python validator functions at once, one function per constraint. Input • User query (contains response format and content constraint and other constraints): ========================= User Query Start ============================ {user_query} ========================= User Query End ============================ • Summary of the constraint part in the user query: {refine_constraint} • List of secondary constraints to be processed currently . {constraints} Y our T ask 1. Read the user query and the list of response format and content constraint mentioned above, but focus only on the parts related to these response format and content constraint. 2. For each type of response format and content constraint that appears, generate a separate validator function (the function name must strictly follo w the rules below): • format → validate_format(response: str) -> Tuple[bool, str] • content → validate_content(response: str) -> Tuple[bool, str] If a certain type does not appear , there is no need to generate the corresponding function. 3. Each function must: • Recei ve response: str • Return (bool, str) , where the str must be in English and sufficiently detailed so that the agent can correctly modify the output based on it. 4. The code can share auxiliary functions, regular expressions, parsing logic, but different constraints must be distinguished by different functions. 5. Y our code should include necessary imports and comments. 6. Only output the code, do not output any additional e xplanation. Output F ormat Y ou must output only a Python code block (enclosed in triple backticks and python: ```python ), without any e xtra text. The code block should contain necessary imports, optional auxiliary functions, and se veral validate_* functions. Figure 30: Prompt template for constraint validation code generation (format & content). 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment