문서에서 증거 스팬으로: LLM 기반 ICD 코딩을 위한 코드 중심 학습
본 논문은 기존 ICD 코딩 데이터의 코드 커버리지 부족, 해석성 결여, 긴 임상 문서로 인한 학습 비용 문제를 해결하기 위해 “코드 중심 학습(Code‑Centric Learning)” 프레임워크를 제안한다. 전체 문서 대신 짧은 증거 스팬을 활용해 혼합 학습과 다단계 데이터 확장을 수행함으로써, 작은 규모 LLM도 대형 상용 모델에 필적하는 성능을 달성하면서 해석 가능성을 크게 향상시킨다.
저자: Xu Zhang, Wenxin Ma, Chenxu Wu
**1. 연구 배경 및 문제 정의**
ICD(International Classification of Diseases) 코딩은 의료 청구·통계·연구에 필수적인 작업이며, 인간 코더가 수행하면 시간·노력이 많이 든다. 기존 딥러닝 기반 방법은 라벨‑어텐션을 활용한 판별 모델이 주류였으나, 최근 대형 언어 모델(LLM)의 일반화 능력에 주목해 프롬프트 기반 혹은 파인튜닝 기반 접근이 등장했다. 그러나 현재 공개된 ICD 데이터셋은 전체 코드의 10 % 미만만을 포함하고 있어, 파인튜닝된 LLM이 새로운 코드를 인식하기 어렵다. 또한 대부분 데이터가 코드 라벨만 제공하고 증거 텍스트를 포함하지 않아 모델이 “왜 이 코드를 선택했는가”를 설명하기 힘들다. 마지막으로 임상 문서는 수천 토큰에 달해 LLM의 입력 길이 제약과 quadratic 연산 비용으로 학습 효율이 저하된다.
**2. 코드 중심 학습(Code‑Centric Learning, CCL) 프레임워크**
저자들은 ICD 코딩을 “증거 스팬 찾기 → 코드 할당” 두 단계로 분해하고, 스팬‑레벨 학습이 문서‑레벨 코딩 능력을 전이한다는 직관에 기반해 CCL을 설계했다. CCL은 두 가지 핵심 전략으로 구성된다.
- **혼합 학습(Mixed Training)**: (i) 증거와 코드가 모두 주석된 전체 문서(소수)와 (ii) 짧은 증거‑코드 쌍(대량)을 동시에 학습한다. 전체 문서는 모델이 문맥 전체에서 증거를 집계하고 다중 코드를 예측하도록 훈련시키고, 스팬‑레벨 데이터는 각 코드에 대한 구체적인 증거 패턴을 효율적으로 주입한다.
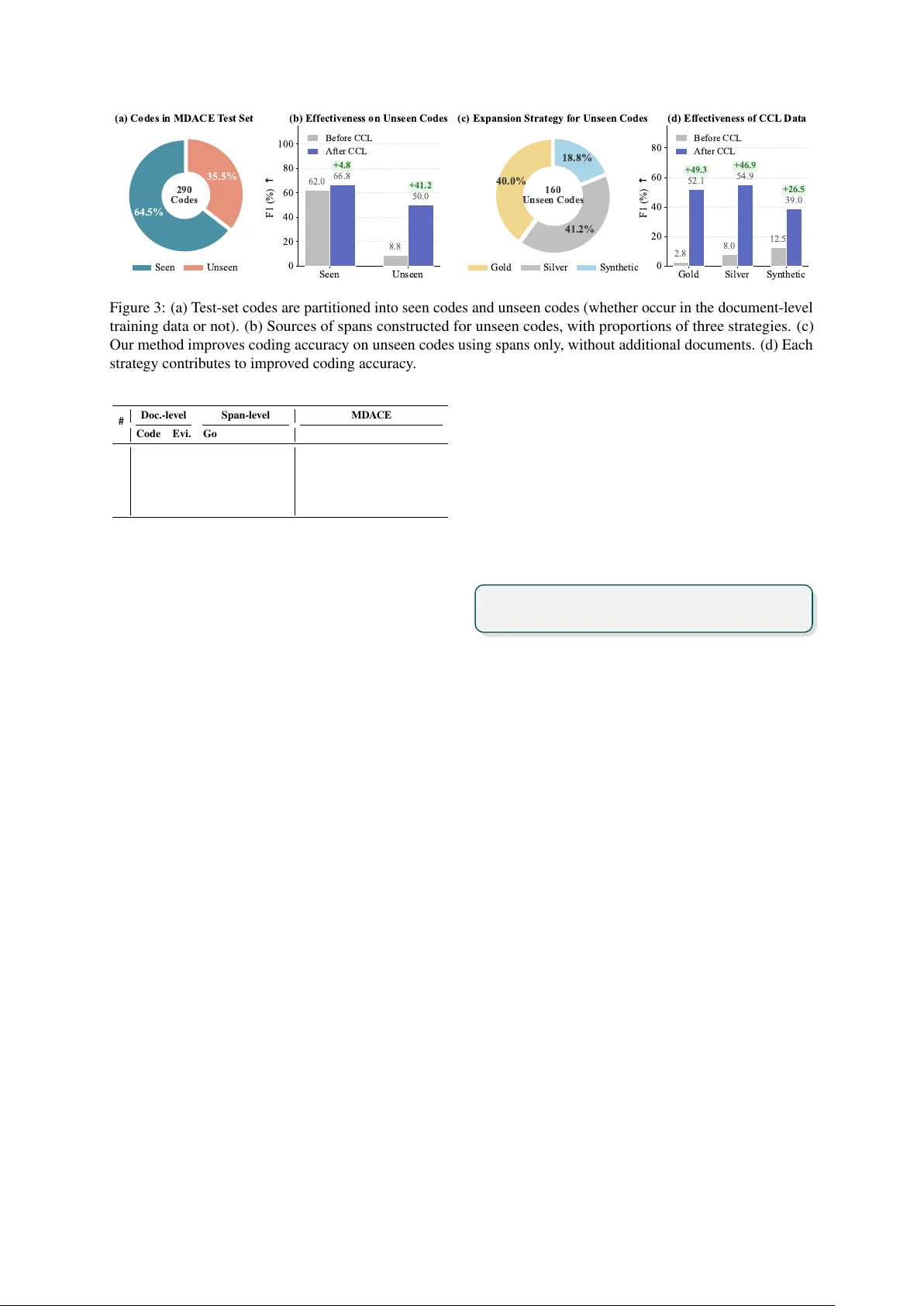
- **코드 중심 데이터 확장(Code‑Centric Data Expansion)**: 코드 커버리지를 거의 전체(≈100 %)에 가깝게 만들기 위해 세 단계의 증거‑코드 쌍을 구축한다.
1. **Gold Tier**: 알파벳 인덱스와 Tabular List 등 공식 ICD 자료에서 “코드 ↔ 용어” 매핑을 직접 추출해 고품질 증거‑코드 쌍을 만든다.
2. **Silver Tier**: 공개 ICD 데이터셋(예: MIMIC‑IV)에서 LLM(Llama‑3.1‑70B)을 이용해 자동 증거 추출·요약 파이프라인을 적용, 노이즈가 섞인 대규모 증거‑코드 쌍을 만든다. 두 단계(문서‑레벨 증거 추출 → 코드‑레벨 요약)로 구성된다.
3. **Synthetic Tier**: 아직 데이터에 등장하지 않은 코드에 대해, ICD‑10‑CM 계층 구조에서 가장 가까운 이웃 코드를 찾아 그 코드의 증거를 기반으로 GPT‑5.1이 가상의 증거 문장을 생성한다.
이렇게 구성된 D = D_gold ∪ D_silver ∪ D_syn은 거의 모든 ICD‑10‑CM 코드를 포함한다.
**3. 모델 학습 및 추론**
학습은 표준 자동 회귀 손실을 사용한다. 입력은 “문서+프롬프트” 혹은 “증거 스팬+프롬프트” 형태이며, 출력은 증거와 코드가 순차적으로 생성된다. 혼합 학습을 통해 모델은 (1) 전체 문맥에서 증거를 찾고(문서‑레벨), (2) 짧은 스팬에서 코드별 특화 지식을 습득한다(스팬‑레벨). 추론 시에도 동일한 프롬프트를 사용해 모델이 먼저 증거 스팬을 식별하고, 이어서 해당 스팬에 기반한 코드를 출력한다.
**4. 실험 설정 및 결과**
- **데이터**: MIMIC‑IV(문서‑레벨), MD‑ACE(증거 주석 문서), 그리고 자동 생성된 Gold·Silver·Synthetic 스팬 데이터.
- **베이스 모델**: Llama‑2‑7B, Llama‑2‑13B 등 소형 오픈 LLM.
- **비교 대상**: 기존 SFT(문서‑레벨 파인튜닝), 최신 프롬프트 기반 모델, 대형 상용 모델(GPT‑4 등).
주요 평가 지표는 (a) 학습 시간, (b) 미보인 코드 정확도(Unseen Accuracy), (c) 증거 회수율(Evidence Recall).
- **학습 효율**: 전체 문서만 사용한 SFT는 210 시간이 소요됐지만, CCL은 40 시간(≈80 % 감소)으로 동일 수준의 성능을 달성.
- **일반화**: 코드 커버리지를 10 %→≈100 %로 확대함에 따라 미보인 코드 정확도가 8.8 %p 상승, 특히 50 % 이상의 unseen accuracy 향상.
- **해석 가능성**: 증거 회수율이 0 %→74 %로 크게 개선돼, 모델이 제시한 코드를 인간이 검증·수정하기 쉬워졌다.
- **성능**: 동일 백본에서 CCL은 대형 상용 모델과 비슷하거나 약간 앞서는 F1 점수를 기록, 특히 작은 LLM(7B)에서도 대형 모델(>70B) 수준의 성능을 보였다.
**5. 논의 및 한계**
CCL은 데이터 부족 문제를 공식 의료 지식과 LLM 기반 합성으로 보완했으며, 증거 기반 학습을 통해 모델 해석성을 회복하고, 짧은 스팬을 활용해 계산 비용을 크게 절감했다. 다만, Silver 및 Synthetic 단계에서 LLM이 생성한 증거의 품질이 코드별로 다를 수 있으며, 실제 임상 현장에서의 적용을 위해 인간 전문가와의 지속적인 검증 루프가 필요하다. 또한, 다언어 ICD(예: ICD‑10‑CM 외 국가별 코드) 적용을 위해서는 해당 언어·문화에 맞는 Gold 자료 구축이 요구된다.
**6. 결론**
본 논문은 “스팬‑레벨 코드 학습이 문서‑레벨 ICD 코딩을 강화한다”는 핵심 가설을 실증하고, 코드 커버리지, 해석성, 학습 효율이라는 세 가지 핵심 문제를 동시에 해결하는 새로운 프레임워크인 코드 중심 학습(CCL)을 제안한다. 작은 규모 오픈 LLM이라도 적절히 확장된 증거‑코드 스팬 데이터를 활용하면 대형 상용 모델에 필적하는 성능을 달성할 수 있음을 보여주며, 향후 의료 NLP에서 인간·AI 협업 기반 자동 코딩 시스템 구축에 중요한 토대를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기