From Documents to Spans: Code-Centric Learning for LLM-based ICD Coding
ICD coding is a critical yet challenging task in healthcare. Recently, LLM-based methods demonstrate stronger generalization than discriminative methods in ICD coding. However, fine-tuning LLMs for ICD coding faces three major challenges. First, exis…
Authors: Xu Zhang, Wenxin Ma, Chenxu Wu
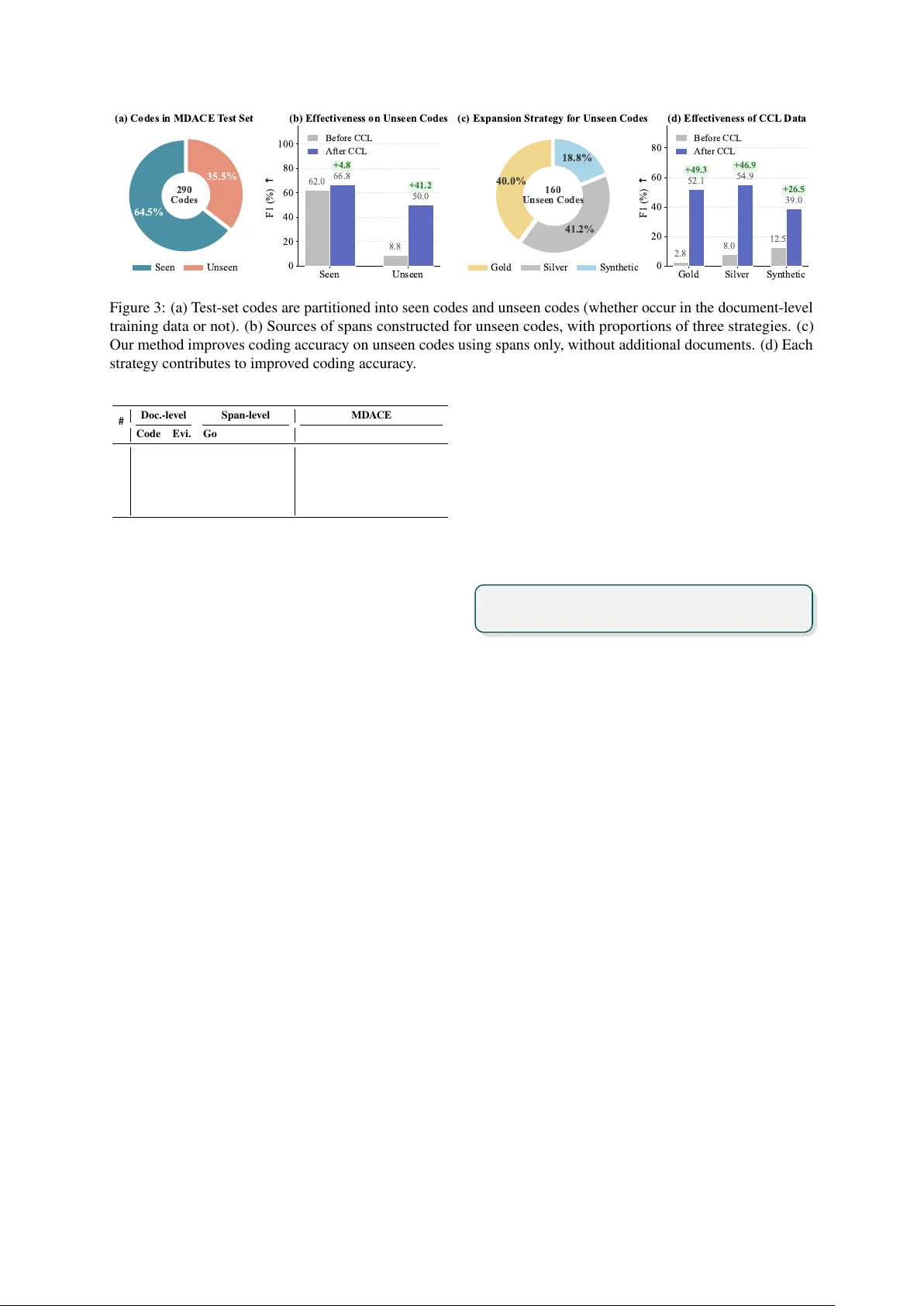
Fr om Documents to Spans: Code-Centric Learning f or LLM-based ICD Coding Xu Zhang 1,2 , W enxin Ma 1,2 , Chenxu W u 1,2 , Rongsheng W ang 1,2 , Kun Zhang 1,2 * , S. K evin Zhou 1,2,3,4 * 1 School of Biomedical Engineering, Di vision of Life Sciences and Medicine, USTC 2 MIRA CLE Center , Suzhou Institute for Advance Research, USTC 3 Jiangsu Provincial K ey Laboratory of Multimodal Digital T win T echnology 4 State K ey Laboratory of Precision and Intelligent Chemistry , USTC xu_zhang@mail.ustc.edu.cn kkzhang@ustc.edu.cn skevinzhou@ustc.edu.cn Abstract ICD coding is a critical yet challenging task in healthcare. Recently , LLM-based methods demonstrate stronger generalization than dis- criminativ e methods in ICD coding. Ho wever , fine-tuning LLMs for ICD coding faces three major challenges. First, existing public ICD coding datasets provide limited cov erage of the ICD code space, restricting a model’ s ability to generalize to unseen codes. Second, nai ve fine-tuning diminishes the interpretability of LLMs, as fe w public datasets contain e xplicit supporting evidence for assigned codes. Third, ICD coding typically inv olves long clinical documents, making fine-tuning LLMs com- putationally expensiv e. T o address these is- sues, we propose Code-Centric Learning, a training frame work that shifts supervision from full clinical documents to scalable, short e vi- dence spans. The key idea of this frame work is that span-lev el learning improves LLMs’ ability to perform document-le vel ICD cod- ing. Our proposed framework consists of a mixed training strategy and code-centric data expansion, which substantially reduces training cost, improv es accuracy on unseen ICD codes and preserves interpretability . Under the same LLM backbone, our method substantially out- performs strong baselines. Notably , our method enables small-scale LLMs to achiev e perfor- mance comparable to much lar ger proprietary models, demonstrating its effecti veness and po- tential for fully automated ICD coding. 1 Introduction ICD codes play a foundational role in medical insur- ance reimbursement and health data analysis. ICD coding, the process of assigning ICD codes to each patient encounter , is a critically important task in modern healthcare systems. Ho wever , manual ICD coding is time-consuming and labor-intensi ve, and e ven experienced human coders frequently make * Corresponding authors …… ~100k Documents LLMs ## Evidence ## Ev i dence … LLMs ## Evidence ## Evidence Code s Spans ## Code ## # Code Co de 3 > … ## Code ## Code ~200 Documents # Evidence …… # Codes …… Evidenc e + Code s (a) T raditional SFT (b) Code - Centric Learning (Ours) Efficiency (Training Time) Generalization (Unseen Acc.) 210h 40h Reduce ~ 80% 8.8% 50.0% Code Cover a ge <10% ~ 100% Interpretability (Evid. Recall) 0% 74.0% Codes (c ) P erforma nce Comparis on Cover more codes Interpretable Efficient Tra d i t i o n a l S F T Code - Cent ric Lear ning (Ou rs) Improved x 5.7 Cover more codes Interpretable Efficient Figure 1: (a) Traditional paradigm relies on lar ge-scale documents for training, which is inef ficient, limited in code coverage, and lacks interpretability . (b) Our method uses only 200 documents to learn evidence- based ICD coding, while lev eraging scalable spans to learn code kno wledge. (c) Our approach hugely im- prov es accuracy on codes unseen in documents, pro- vides interpretable evidence, and reduces training time. errors ( Burns et al. , 2012 ; Horsky et al. , 2018 ; Gan et al. , 2025 ), which has motiv ated extensiv e re- search on automated ICD coding. Early ICD coding approaches adopt discrimina- ti ve models with label attention mechanisms ( Mul- lenbach et al. , 2018 ; Huang et al. , 2022 ; Edin et al. , 2024 ). Recently , LLM-based methods hav e gained attention due to their stronger generalization capa- bilities ( Motzfeldt et al. , 2025 ; Y uan et al. , 2025 ). Among them, training-free approaches ( Li et al. , 2025 ; Motzfeldt et al. , 2025 ) rely on carefully de- signed prompts or workflo ws, and place strong de- 1 mands on the capability of the backbone LLM, often requiring either proprietary models or very large open models. Such models are difficult to adopt in clinical settings due to strict pri vac y con- straints and limited local computing resources. In contrast, fine-tuning methods ( Y uan et al. , 2025 ) enable smaller , locally deployable LLMs to acquire ICD coding capability , making them more practi- cal for real-world healthcare applications. Gi ven clinical notes and a simple task prompt, the LLM is optimized to output ICD codes along with their textual descriptions and outperforms discriminati ve models on out-of-distribution data. Ho we ver , this fine-tuning paradigm entails se v- eral issues: limited code coverage , poor inter - pretability and low training efficiency . First, existing ICD coding datasets cover only a small subset of ICD codes. F or example, ev en MIMIC- IV ( Johnson et al. , 2023 ) includes only about 10% of the 70K ICD-10-CM codes, which severely re- stricts generalization to unseen codes. Second, most ICD coding datasets provide ICD codes with- out supporting evidence; as a result, fine-tuning LLMs on such data encourages direct code predic- tion without explicit e vidence grounding. This not only diminishes interpretability , but also precludes human revie w and correction of the underlying evi- dence, thereby limiting effecti ve human–AI collab- oration. Third, fine-tuning LLMs on long clinical documents is computationally expensi ve, consider- ing the quadratic complexity with respect to input length. Collectiv ely , these challenges limit the ap- plicability of fine-tuning LLMs for ICD coding. T o address the above issues, we propose a nov el training framew ork, Code-Centric Learning (CCL). Unlike traditional paradigms that operate on entire clinical notes, as sho wn in Figure 1 , our method centers on code-specific evidence spans. Intuitively , ICD coding can be decomposed into two sub-tasks: locating e vidence and assigning codes. If an LLM is trained to assign the correct ICD code to an e vi- dence span, it implicitly learns to recognize such e v- idence in a long clinical document. Consequently , strengthening the span-lev el code assignment ca- pability also enhances the model’ s ability to locate and aggregate codeable e vidence and assign codes in a full document. Based on this intuition, CCL consists of two key strategies. First, we adopt a mixed training strat- egy that uses a limited number of documents with annotated e vidence spans, together with a large col- lection of code-related e vidence spans. Compared to direct fine-tuning on public ICD coding datasets, i.e., full clinical notes without evidence annotation, this strategy provides explicit interpretability and reduces computational cost by focusing on short e vidence spans instead of long clinical documents. Second, we propose a code-centric data expan- sion strategy . W e extract code-specific evidence spans from public datasets based on annotated codes, and supplement them using official ICD coding resources. For codes unseen in both official kno wledge bases and public datasets, we retrieve the closest codes and e vidence to synthesize plau- sible e vidence spans, ensuring full ICD code cov- erage. Our proposed training framework enables small-scale LLMs to achie ve performance com- parable to much larger proprietary models, while providing e xplicit interpretability and intervention capability . Our main contributions are summarized as: • W e propose a fine-tuning frame work for LLM- based ICD coding that simultaneously ad- dresses three key limitations: (i) limited code cov erage in public datasets, (ii) the lack of interpretability in standard fine-tuning, and (iii) the lo w training ef ficiency caused by long clinical documents. • W e introduce a novel training frame work con- sisting of a mixed training strategy and a code- centric data expansion strate gy , motiv ated by the central insight that span-level classifica- tion yields transferable gains for document- le vel e vidence extraction. • Our framework enables small LLMs to achie ve performance comparable to much larger proprietary models on both in-domain and out-of-domain datasets, while attaining state-of-the-art results with the same back- bone. It also provides e xplicit interpretability and supports human–AI collaboration. 2 Related W ork 2.1 Discriminative methods Label attention . Discriminativ e models hav e long dominated the ICD coding task via label attention mechanisms ( Mullenbach et al. , 2018 ), learning an independent query vector for each ICD code. The widely adopted models are PLM-ICD ( Huang et al. , 2022 ) and its v ariant PLM-CA ( Edin et al. , 2024 ). 2 Knowledge injection . Building on label attention, se veral studies explore incorporating e xternal ICD- related kno wledge. DKEC ( Ge et al. , 2024 ) apply a graph network to encode kno wledge from multiple sources. Correlation ( Luo et al. , 2024 ) models rela- tionships among ICD codes. MSMN ( Y uan et al. , 2022 ) and MSAM ( Gomes et al. , 2024 ) utilize syn- onyms to learn code representations. GKI-ICD ( Zhang et al. , 2025 ) injects code descriptions, syn- onyms, and hierarchy by synthesizing guidelines. Interpr etability . T raditional discriminative mod- els often lack interpretability . MD A CE ( Cheng et al. , 2023 ) re-annotates a subset of MIMIC- III ( Johnson et al. , 2016 ) and provides expert- annotated evidence spans for ICD assignments. Building on MD ACE, Edin et al. ( 2024 ) applies AttInGrad to map model predictions to evidence spans in the original text. AutoCodeDL ( W u et al. , 2024 ) incorporates dictionary learning to decode dense embeddings into medical concepts. T raining efficiency . Douglas et al. ( 2025 ) pro- poses an entity-based compression method that reduces input te xt length while maintaining com- parable performance, highlighting redundancy of clinical documents. This issue becomes more pro- nounced as backbones shift from BER Ts to LLMs. 2.2 Generative Methods T raining-free methods . Early works explored the use of of f-the-shelf LLMs for ICD coding, design- ing prompts and workflo ws. Boyle et al. ( 2023 ) prompts the LLM to predict ICD codes in a hi- erarchical manner , from chapters and sections to specific codes. MAC ( Li et al. , 2025 ) prompts the LLM to act as different roles, such as a coder and a physician, and perform cross-role verifica- tion. MedCodER ( Baksi et al. , 2025 ) and CLH ( Motzfeldt et al. , 2025 ) adopt multi-stage work- flo ws combining e vidence extraction and candidate retrie v al to address the large ICD code space. Fine-tuning methods . Recently , Y uan et al. ( 2025 ) demonstrates that fine-tuning LLMs is more suit- able for this task than training-free paradigms and proposes a verification module to fix mistakes. Nes- terov et al. ( 2025 ) also validates this conclusion on their proposed Russian ICD coding benchmark. Ho we ver , while these works demonstrate the ne- cessity of fine-tuning LLM for ICD coding, they do not attempt to improv e the fine-tuning paradigm itself to address its inherent limitations. 3 Methodology 3.1 Overview Fine-tuning LLMs for ICD coding is commonly performed at the document le vel ( Y uan et al. , 2025 ). Gi ven a clinical document x and its associated ICD code set C (follo wed by code description), con- ventional document-lev el training can be cast as supervised fine-tuning (SFT): min θ L SFT ( f θ ( x ) , C ) , (1) where the LLM f θ ( · ) maps a long clinical docu- ment to a set of ICD codes under standard next- token prediction. Ho we ver , this paradigm suffers from lo w training ef ficiency , limited code coverage and poor interpretability (see Section 1 ). T o ov ercome these challenges, we propose a code-centric learning framew ork (Figure 2 ). W e perform mixed SFT on two types of instances: (i) a full clinical document, annotated with evidence and ICD codes; (ii) an e vidence span and a single ICD code, which can be formulated as: min θ h L SFT f θ ( x ) , ( E , C ) + L SFT f θ ( e ) , c i , (2) where E denotes e vidence spans supporting anno- tated ICD codes C , e denotes an e vidence span with corresponding ICD code c . The former forces the LLM to extract e vidence before assigning codes, enhancing interpretability , while the latter con- sists of short evidence spans that are easy to ac- quire, which naturally address issues of limited code coverage and training efficiency . Defining ( e, c ) as an e vidence-code pair, ( e, c ) ∼ D , (3) where D is a multi-source kno wledge base. T o ensure full ICD code cov erage, we construct D by integrating three tiers of evidence-code pairs: gold , silver , and synthetic , as: D = D gold ∪ D silver ∪ D syn , (4) in which D gold consists of scarce, authoritativ e e vidence-code pairs from official ICD resources. D silver is mined from public datasets, yielding a larger collection of evidence-code pairs with broader cov erage. For the remaining unseen codes, we construct D syn by synthesizing evidence via LLM, thereby completing cov erage ov er the entire ICD code set. Belo w , we will describe the details of the mixed training strategy for Eq. 2 , and the code-centric data expansion strate gy for Eq. 4 . 3 ## Evidence - Evidence1 - Evidence2 - [Unse en Evide nc e 3 ] …… ## ICD Codes Code 1 Code 2 [Unseen Code 3] …… Mixed T raining Inference Document - level Data ## Evidence [Evidenc e 1] [Evidenc e 2] ...... ## ICD C odes [Code 1] [Code 2] ...... Limited Scalable Unseen Document Chief Comp laint : S /P MVC Right leg and chest pain HISTOR Y OF PRESE NT ILLNESS: …a hig h - speed MVC. ….Tobacco: Sm okes 1 pack… ## Evidence ## Evidence < Evidence3> ## ICD Code ## ICD Code < Code3> Infer … … Adult … high - speed motor vehic le col lisi on … acu te right lower extr emity (3) Syntheti c Pa i rs “Given
, the evidence of its neighbo r is …, plea se infer the evidence for ” (1) Gold Pai r s Code - Centric Data Expansion (2) Silv er Pai r s “Given , pleas e find the evidence.” Knowle dge Base Public Datas et Clinical Text + Code L abels Span - level Data ## Evidence < Evidence3 > ## ICD Code < Code3> ## Evidence < Evidence4 > ## ICD Code < Code4> ## Evidence < Evidence5 > ## ICD Code < Code5> SFT … … Figure 2: Overview of Code-Centric Learning frame work. Under mixed training, document-le vel data enables the LLM to aggreg ate e vidence from the full conte xt and assign multiple ICD codes, while span-le vel data pro vides LLM with code-specific knowledge. Code-centric data expansion le verages LLMs to extract and infer evidence spans for each code from div erse knowledge sources, addressing codes not present in documents. 3.2 Mixed T raining Mixed training combines document-le vel supervi- sion to learn e vidence aggreg ation under full clini- cal context with span-le vel supervision for scalable ICD code kno wledge injection. Document-lev el data refers to medical docu- ments annotated with both ICD codes and support- ing e vidence. This type of data is v ery hard to ob- tain, and therefore e xtremely scarce and valuable. T o our knowledge, MD A CE ( Cheng et al. , 2023 ) is the only av ailable public dataset that contains such kind of data. For each clinical document, we first extract the human-annotated e vidence spans, preserving their original order in the document. W e then order the ICD codes accordingly , and augment them with their textual descriptions from the ICD-10 T abular List. Finally , we con vert text, evidence and codes into instruction-tuning samples using a unified prompt template (Appendix F ). Note that e vidence extraction and code assignment are per- formed jointly within a single generation process, rather than through staged or multi-step pipelines. Span-lev el data refers to evidence–code pairs, where the model takes an evidence span as input, and predicts the corresponding ICD code. Since e v- idence spans are much shorter than full documents, it enables ef ficient training. Such e vidence–code pairs can be obtained from v arious sources. They may originate from human- curated resources or be automatically extracted by LLMs from public ICD coding datasets. Sec- tion 3.3 describes how we systematically e xpand these pairs to increase code cov erage. T raining and inference. W e fine-tune the LLM on mixed document-le vel and span-le vel data, un- der a standard autoregressi ve objecti ve: min θ L SFT ( θ ) = N X i =1 T i X t =1 − log p θ y ( i ) t | x ( i ) , y ( i ) CAD J44.9 − Chronic obstructiv e pulmonary disease, unspecified > COPD D62 − Acute posthemorrhagic anemia > Anemia −−− ### Clinical Note {text} ### ICD−10−CM Codes {diagnosis_codes} ### Evidence Evidence Refinement Y ou are a professional ICD−10−CM coder. Y our task is to update and refine the Evidence Set for the ICD−10−CM code below. Follo w these rules: 1. Only keep the ** most essential ** evidence that clearly supports this code. 2. Y ou may reference the Alphabetic Index terms, b ut you do not need to match them exactly. 3. Use the ** Original Evidence Set ** as the base. − If the MIMIC−IV evidence contains ne w, meaningful, or more specific expressions, add them. − If not, keep the existing e vidence unchanged. 4. Remov e duplicates and unify phrasing into ** clear, concise, canonical ** clinical expressions. 5. Output the ** updated Evidence Set only ** , as a bullet list. No e xplanation. −−− ### ICD−10−CM Code {code} ### Alphabetic Index T erm {alphabetic_index_term} ### Original Evidence Set {evidence_set} ### New Evidence from MIMIC−IV {mimiciv_e vidence} ### Updated Evidence Set − 14 T able 10: Prompt templates used for Code-Centric Data Expansion (Synthetic Pairs) T ask Prompt T emplate Synthesize Evidence Y ou are a professional ICD−10−CM coding and clinical documentation expert. Y our task is to synthesize a focused, audit−defensible list of clinical evidence terms that directly support assignment of the ICD−10−CM code: {code}. Definition of evidence: Evidence refers only to clinical findings or documentation elements that materially support the diagnosis represented by the code. A v ailable references: {reference} Instructions: − Use the parent and sibling codes to understand diagnostic scope. − Infer conservati vely based on ICD−10−CM con ventions and real−world clinical documentation patterns. − Prioritize diagnostic−confirmatory evidence (e.g., imaging findings, explicit diagnoses, anatomical localization). Do NO T include: − Mechanism of injury or accident descriptions − General symptoms or nonspecific complaints − T reatment, procedures, immobilization, or care plans − Encounter setting or workflo w details − Redundant negati ve statements unless required to distinguish code type Unspecified code rule: − If the code is unspecified, do NO T introduce inferred specificity (e.g., displacement, fracture pattern, sev erity). Output constraints: − Consolidate ov erlapping or synonymous terms. − Stop generating new items once additional terms no longer add distinct coding value. Output format: − − ... 15 T able 11: Prompt templates used for Generativ e Baselines Baselines Prompt T emplate CoT Y ou are a clinical coding assistant. Y our task is to analyze the provided clinical note, and then output the corresponding ICD−10−CM codes. ### Clinical Note: {text} Let's think step by step. MA C-coder Y ou are an ICD−10 coder. Y ou assign ICD−10 codes to the discharge summary based on the clinical care that the patients receiv ed. Y ou cite the discharge summary as e vidence when needed. Y ou assign as manyas possible ICD−10 codes and explain the reasons for each code. The discharge summary is: {te xt} MA C-reviewer Y ou are a revie wer. Y ou will check the ICD−10 codes assigned by the coder. Y ou can use the ICD−10 dictionary for guidance. Y our role is to ensure that the assigned ICD−10 codes are correct. Y ou assign all possible ICD−10 codes and explain the reasons for each code. The discharge summary is: {te xt} The ICD−10 codes assigned by the coder are: {coder_pred} MA C-physician Y ou are a physician who treats patients. Y ou striv e to provide the best service to each patient. Y ou document your findings, interventions and results in the discharge summary note. Y ou check all assigned ICD−10 codes and explain the reasons for each code. The discharge summary is: {te xt} The ICD−10 codes assigned by the coder are: {revie wer_pred} MA C-patient Y ou are a patient who receiev ed treatment at the hospital. Y ou cooperate fully with thehealth care system to receiv e the best service possible. Y ou also check the ICD−10 codes to av oid being ov erbilled. Y ou check all assigned ICD−10 codes and explain the reasons for each code. The discharge summary is: {te xt} The ICD−10 codes assigned by the coder are: {revie wer_pred} MA C-adjustor When a patient or a physician has dif ferent thoughts about the ICD−10 codes, you will revie w the discharge summary and the ICD codes assigned by the coder and checked by the re vie wer. Y ou can add, remove the assigned codes to mak e them accurate. Y ou can consult the ICD−10 dictionary for assistance. Y our duty is to ensure that the assigned ICD−10 codes are valid and e xact. Y ou assign all possible ICD−10codes and explain the reasons for each code. The discharge summary is {te xt} The ICD−10 codes assigned by the physician are {physician_pred} The ICD−10 codes assigned by the patient are {patient_pred} The ICD−10 codes assigned by the coder are {coder_pred} The ICD−10 codes checked by the re vie wer are {revie wer_pred} SFT / Code-only Y ou are a clinical coding assistant. Y our task is to analyze the provided clinical note, and then output the corresponding ICD −10−CM codes. ### Clinical Note: {text} 16 T able 12: Prompt templates used for Interpretability Evaluation T ask Prompt T emplate Predicted Evidence Evaluation Y ou are a clinical evidence e valuation expert. Y ou are giv en two unordered sets of clinical e vidence spans. Each line represents one evidence span. Evaluation rules: 1. Count only meaningful clinical evidence spans. − Ignore empty lines, headings, or formatting text. − If the same evidence appears multiple times, count it only once (semantic deduplication). 2. Matching is semantic and lenient: − If a predicted span is more specific but clearly refers to the same clinical finding as a human span, count it as a match. − Minor wording dif ferences do not matter. − Human annotations may be shorter or less specific. − If findings contradict (e.g., different laterality), do NO T count as a match. 3. Matching must be one−to−one. − One predicted span can match at most one human span. − Do not double count matches. − Determine the optimal one−to−one matching that maximizes the number of matches. ### Predicted Evidence: {evidence} ### Human−annotated Evidence: {human_evidence} Output in markdown format e xactly as: − human evidence count: X − predicted evidence count: Y − matched evidence count: Z 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment