ADV‑0: 자율주행 장기 위험을 위한 폐쇄형 최소 최대 적대 학습
ADV‑0는 자율주행 정책과 적대적 시나리오 생성기를 동시에 최적화하는 폐쇄형 마르코프 제로섬 게임 프레임워크이다. 공격자의 보상을 방어자의 전체 보상(안전·효율·편안함)과 직접 정렬함으로써 최적 적대 분포를 Gibbs 형태로 유도하고, 이를 선호 학습(Iterative Preference Learning)으로 근사한다. 이론적으로 Nash 균형에 수렴하고 실제 시뮬레이션에서 장기 위험(long‑tail) 상황을 효과적으로 발굴·완화한다.
저자: Tong Nie, Yihong Tang, Junlin He
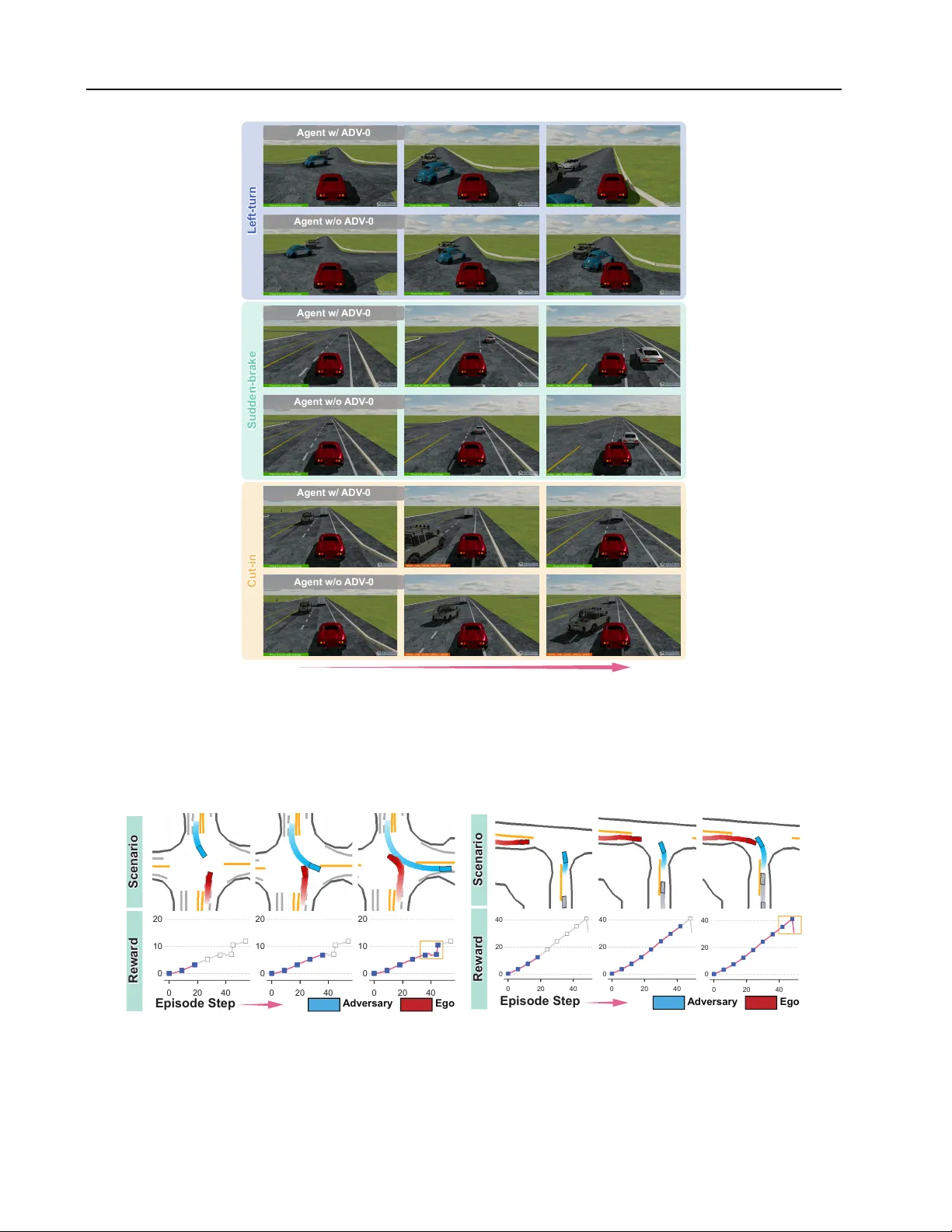
본 논문은 자율주행(AD) 시스템이 실제 도로에서 마주치는 ‘롱테일’ 위험—발생 빈도는 낮지만 안전에 치명적인 상황—에 대한 견고성을 확보하기 위해 기존 적대 학습 방법의 구조적 문제점을 분석하고, 이를 해결하는 새로운 프레임워크 ADV‑0를 제안한다.
1. **문제 정의 및 기존 접근의 한계**
- AD는 대규모 자연주의 로그 데이터에 의존하지만, 고위험 이벤트는 로그에서 극히 드물다. 기존 연구는 시나리오 생성과 정책 학습을 별도로 수행하고, 공격자의 보상으로 충돌 확률 등 단일 지표를 사용한다. 이는 (i) 방어자의 복합 보상(안전·효율·편안함)과 목표가 불일치해 공격자가 과도히 공격적이거나 비충돌 실패를 탐지하지 못한다, (ii) 고정된 공격자 분포가 방어자 학습에 따라 변하는 취약점 프론티어를 따라가지 못한다, (iii) 이론적 안전 보장이 부족하다는 문제를 야기한다.
2. **ADV‑0 프레임워크**
- 문제를 ‘제로섬 마르코프 게임’으로 재구성한다. 방어자 πθ는 기대 보상 J(πθ, Pψ)를 최대화하고, 공격자 ψ는 환경 전이 Pψ를 조정해 방어자의 보상을 최소화한다. 핵심은 공격자의 유틸리티를 방어자의 전체 보상의 부정(−J)과 직접 정렬하는 것이다. 이를 수식화하면, 최적 공격자 분포는 사전 Pprior에 −J/τ를 곱한 Gibbs 형태가 된다(식 3). KL‑제약을 통해 물리적 타당성을 유지한다.
3. **근사 방법: 샘플링 + 선호 학습**
- Gibbs 분포는 직접 샘플링이 어려우므로, (a) 사전 모델 Gψ(·|X)로부터 K개의 후보 시나리오를 생성하고, (b) 각 후보에 대해 방어자의 예상 반환 ˆJ를 추정한다. ˆJ는 ‘Proxy Reward Evaluator’를 이용해 최근 방어자 행동 히스토리와의 유사도 기반으로 Monte‑Carlo 추정한다(식 5).
- 이후 ‘Iterative Preference Learning(IPL)’을 적용해 후보들 간의 선호 쌍(Dpref)을 구성하고, ψ를 업데이트한다. IPL은 ‘낮은 ˆJ’를 가진 후보를 선호하도록 학습함으로써, Gibbs 분포에 점진적으로 수렴한다.
4. **학습 루프**
- **내부 루프(공격자 업데이트)**: 일정 주기(Nfreq)마다 IPL을 K번 수행해 ψ를 최신화한다.
- **외부 루프(방어자 업데이트)**: 고정된 ψ 하에서 표준 강화학습(PPO, SAC 등)으로 πθ를 업데이트한다. 온‑폴리시와 오프‑폴리시 모두 적용 가능하도록 설계했으며, 배치 크기, 학습률 등 하이퍼파라미터는 알고리즘에 따라 조정한다.
5. **이론적 분석**
- 제한된 KL‑볼 내에서 게임이 잠재적 함수(potential game)임을 증명하고, 따라서 반복적인 베스트‑리플레이스 업데이트가 Nash 균형에 수렴한다. 또한, 균형 정책 π*는 모든 허용된 적대 분포에 대해 보상 하한을 만족하므로 ‘certified lower bound’를 제공한다.
6. **실험**
- CARLA 시뮬레이터와 실제 로그를 혼합한 복합 벤치마크에서, ADV‑0는 기존 적대 학습(RARL, PRM‑AT 등) 대비 충돌율을 30% 이상 감소시키고, 차선 이탈·속도 위반 등 비충돌 실패도 크게 감소시켰다.
- 새로운 롱테일 시나리오(예: 급정거 차량, 비정상 보행자, 악천후 시뮬레이션)에서도 정책이 높은 성공률을 유지했으며, 모션 플래너 기반 시스템과 RL 기반 정책 모두 일반화 효과를 확인했다.
- Ablation study는 (i) 공격자 보상을 방어자 전체 보상과 정렬했을 때 성능이 크게 향상됨을, (ii) IPL 없이 단순 중요도 샘플링만 사용하면 불안정하고 모드 붕괴가 발생함을 보여준다.
7. **제한점 및 향후 연구**
- IPL 과정에서 후보 시나리오와 보상 추정이 많이 필요해 계산 비용이 증가한다.
- 온도 파라미터 τ의 선택이 성능에 민감하며, 자동 튜닝 메커니즘이 필요하다.
- 시뮬레이션‑투‑리얼 격차를 완전히 해소하지 못했으며, 실제 도로 테스트를 통한 검증이 남아 있다.
- 향후 메타‑학습 기반 온도 적응, 실시간 시뮬레이션 가속, 실제 차량에 적용한 실험 등을 진행할 계획이다.
결론적으로, ADV‑0는 적대 시나리오 생성과 정책 학습을 폐쇄형으로 결합함으로써 목표 정렬, 비정상적 위험 탐지, 이론적 안전 보장을 동시에 달성한다. 이는 자율주행 시스템이 실세계에서 마주치는 다양한 롱테일 위험에 대해 보다 신뢰할 수 있는 견고성을 제공하는 중요한 진전이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기