ADV-0: Closed-Loop Min-Max Adversarial Training for Long-Tail Robustness in Autonomous Driving
Deploying autonomous driving systems requires robustness against long-tail scenarios that are rare but safety-critical. While adversarial training offers a promising solution, existing methods typically decouple scenario generation from policy optimi…
Authors: Tong Nie, Yihong Tang, Junlin He
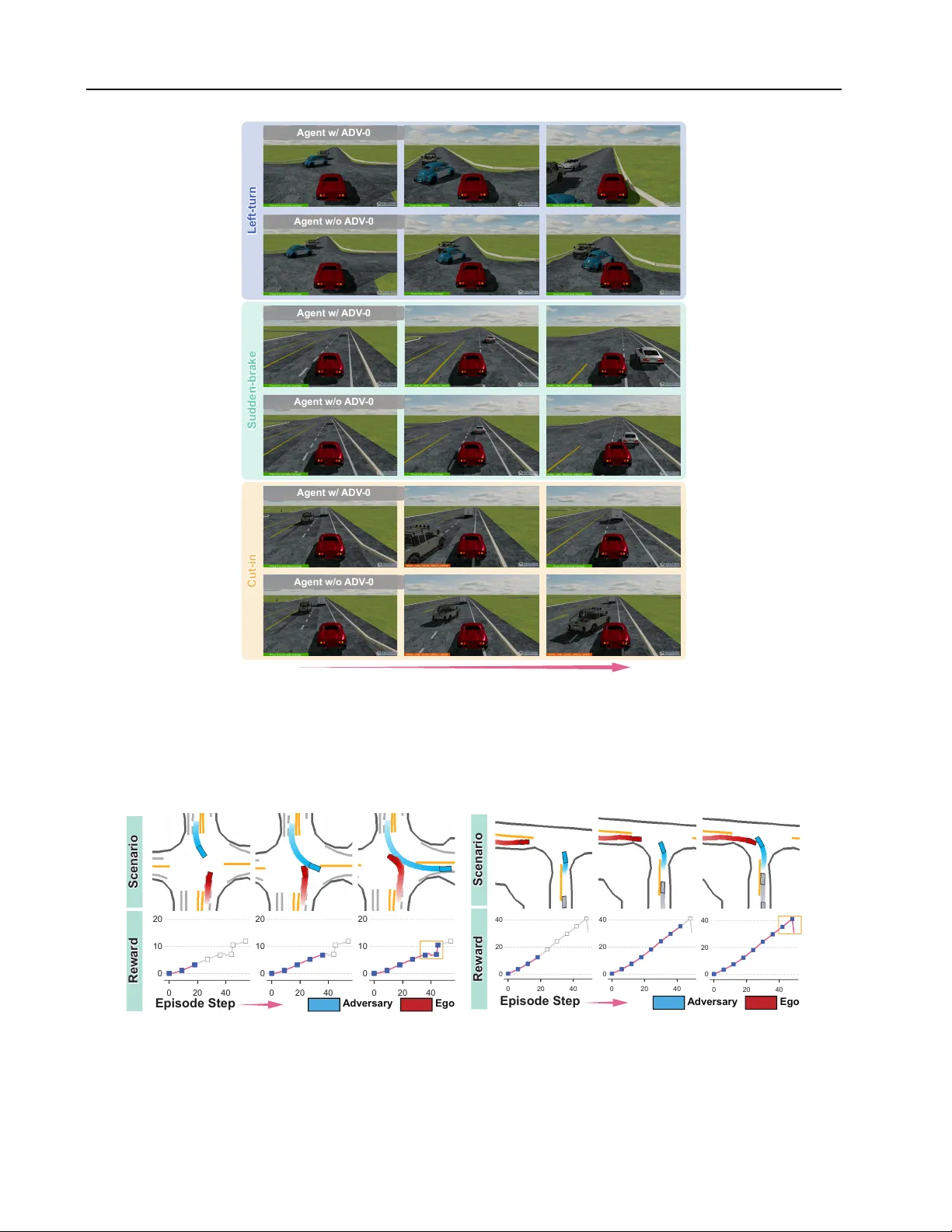
ADV-0 : Closed-Loop Min-Max Adversarial T raining f or Long-T ail Rob ustness in A utonomous Driving T ong Nie 1 2 Y ihong T ang 3 Junlin He 1 Y uewen Mei 2 Jie Sun 2 Lijun Sun 3 W ei Ma 1 Jian Sun 2 Abstract Deploying autonomous dri ving systems requires robustness ag ainst long-tail scenarios that are rare but safety-critical. While adversarial training of- fers a promising solution, e xisting methods typi- cally decouple scenario generation from policy op- timization and rely on heuristic surrog ates. This leads to objecti ve misalignment and fails to cap- ture the shifting failure modes of ev olving poli- cies. This paper presents ADV-0 , a closed-loop min-max optimization frame work that treats the interaction between driving policy (defender) and adversarial agent (attacker) as a zero-sum Marko v game. By aligning the attacker’ s utility directly with the defender’ s objective, we re veal the opti- mal adv ersary distrib ution. T o mak e this tractable, we cast dynamic adversary e v olution as iterativ e preference learning, efficiently approximating this optimum and offering an algorithm-agnostic solu- tion to the game. Theoretically , ADV-0 con ver ges to a Nash Equilibrium and maximizes a certified lower bound on real-world performance. Experi- ments indicate that it ef fectiv ely exposes di verse safety-critical failures and greatly enhances the generalizability of both learned policies and mo- tion planners against unseen long-tail risks. 1. Introduction Deploying autonomous driving (AD) systems in the open world faces a crucial bottleneck: the inability to anticipate and handle long-tail scenarios that are rare but safety-critical. While vast amounts of naturalistic driving data provide a basis for model de v elopment, they are dominated by normal logs, where high-risk e vents lik e aggressiv e cut-ins appear with ne gligible frequency ( Liu & Feng , 2024 ; Xu et al. , 2025b ). The gro wing literature has introduced sampling and generati ve methods to accelerate the discovery of rare e v ents ( Feng et al. , 2023 ; Ding et al. , 2023 ). Howe v er , they are 1 The Hong K ong Polytechnic Uni versity , Hong K ong SAR, China 2 T ongji Uni versity , Shanghai, China 3 McGill Uni ver - sity , Montreal, QC, Canada. Correspondence to: W ei Ma < wei.w .ma@polyu.edu.hk > , Jian Sun < sunjian@tongji.edu.cn > . Pr eprint. Mar ch 17, 2026. often confined to stress testing or performance validation, failing to acti vely tar get long-tail risks. Effecti vely le verag- ing these synthetic data to improve the generalizability of AD policies in the long tail remains an open question. Closed-loop adversarial training of fers an avenue to address this challenge by e xposing the training policy to synthetic risks. This paradigm can naturally be formulated as a min- max bi-le vel optimization problem via a zero-sum Marko v game, in v olving an adversary that generates challenges and a defender that optimizes the policy ( Pinto et al. , 2017 ). De- spite its theoretical ele gance, direct application in AD and robotics has been hindered by nontri vial optimization issues. First, end-to-end solutions via gradient descent are often computationally intractable due to the non-differentiable nature of physical simulators and the difficulty of propa- gating gradients through long-horizon rollouts to provide learning signals. Second, the zero-sum interaction between two players is prone to instability and mode collapse ( Zhang et al. , 2020b ), where the adversary con verges to unrealistic attack patterns, limiting the scalability of this framew ork. T o bypass computational difficulties, e xisting methods typ- ically decouple the min-max objectiv e into separate sub- problems: generating scenarios via fixed priors or heuris- tics, then training the agent against this static distribution ( Zhang et al. , 2023 ; 2024 ; Stoler et al. , 2025 ). Howe ver , this decoupled paradigm introduces notable limitations: (1) Misaligned . It creates a misalignment between the goals of the two players. While the defender optimizes a com- prehensiv e re ward that accounts for safety , ef ficiency , and comfort, the attacker solely targets collisions, relying on heuristic surrogates such as collision probability . First, this discrepancy renders the adversarial objectiv e ill-defined, often resulting in an ov erly aggressiv e attacker that ov er- whelms the defender and destabilizes training ( Zhang et al. , 2020b ). Second, the diver gence in gradient directions pre- vents the attacker from identifying non-collision failures like of f-road violations and providing meaningful learning signals. Thus, the defender can overfit to specific colli- sion modes while remaining vulnerable to broader risks ( V initsky et al. , 2020 ), without acquiring generalized rob ust- ness. (2) Nonstationary . Decoupled methods with fixed attack modes fail to uncover the nonstationary vulnerabil- 1 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving ity frontier—the shifting boundary of scenarios where the current policy remains prone to failure. As the defender ev olves, its f ailure modes shift further into the long-tail dis- tribution, becoming increasingly rare under the initial prior . Fixed adv ersaries with static priors are insufficient to track these shifting weaknesses, leading to fragile generalization in unseen risks. (3) Uncertified . Training against such static priors or heuristics acts as an empirical trial-and-error pro- cess, thus failing to provide theoretical safety guarantees. This lack of certified performance bounds contrasts sharply with the rigorous safety demands of real-world deployment, where agents must generalize to an unbounded variety of unknown long-tail scenarios ( Brunk e et al. , 2022 ). This work re visits the min-max formulation and introduces ADV-0 , a closed-loop policy optimization framework that enables end-to-end training for generalizable adversarial learning. ADV-0 solves the Marko v game by directly align- ing the adversarial utility with the training objecti ve of the defender . T o address the tractability and stability issues, we propose an online iterative preference learning algorithm, casting adversarial e volution as preference optimization. This allows the attacker to continuously track the shifting vulnerability frontier of the improving defender . By cou- pling the e volution, ADV-0 tailors the distribution to wards the long tail of the current players, forcing the defender to learn generalized robustness rather than overfitting to heuris- tics. Importantly , ADV-0 is algorithm-agnostic, applicable to both RL agents and motion planning models, providing a theoretically grounded pathway from adversarial generation to policy impro vement. Our contributions are threefold. • ADV-0 is the first closed-loop training framework for long-tail problems of AD that couples adversarial genera- tion and policy optimization in an end-to-end way . • W e propose a preference-based solution to the zero-sum game, a stable and ef ficient realization supporting on- policy interaction and algorithm-agnostic e volution. • Theoretically , ADV-0 con ver ges to a Nash Equilibrium and maximizes a certified lower bound on real-world per - formances. Empirically , ADV-0 not only exposing di- verse safety-critical e vents b ut also enhances the general- izability of policies against unseen long-tail risks. 2. Preliminary and Pr oblem F ormulation T ask description. W e model the safe AD task as a Marko v Decision Process (MDP), defined by ( S , A , P , R , γ , T ) . Here, S and A denote the state and action spaces. The state s t ∈ S includes raw sensor inputs, high-level com- mands, and kinematic status. The action a t ∈ A represents continuous low-le vel control signals (e.g., steering, accel- eration). The environment dynamics P : S × A → ∆( S ) describe the transition probabilities of the traffic scene. W e initialize scenarios using real-world dri ving logs, where the ego v ehicle is controlled by a policy π θ parameterized by θ . Background traf fic participants are initially go verned by nat- uralistic beha vior priors, such as log-replay or traffic models like the Intelligent Dri v er Model (IDM). The re ward func- tion R ( s, a ) is designed to balance task progress with safety: it encourages route completion and velocity tracking, while imposes heavy penalties for safety violations, such as colli- sions or of f-road events. The goal of the ego agent is to learn an optimal policy π ∗ θ that maximizes the expected cumula- tiv e return J ( π θ ) = E τ ∼ π θ , P [ P T t =0 γ t R ( s t , a t )] within T . Unlike imitation learning which assumes a fixed data distri- bution, we focus on online RL to enable the agent to recover from adversarial perturbations in closed-loop interactions. Min-max f ormulation. Relying solely on naturalistic sce- narios often fails to expose the ego agent to low-probability but high-risk e vents residing in the long tail of the distribu- tion. T o ensure the robustness of the policy against long-tail risks, adversarial training frames the problem as a robust op- timization task via a two-play er zero-sum game between the ego agent and an adversary . Here, the behaviors of background agents are gov erned by a parameterized adver - sarial policy ψ ∈ Ψ that alters the transition dynamics from the naturalistic P to an adversarial P ψ . The robust policy optimization is thus cast as a min-max objectiv e: max θ min ψ ∈ Ψ " J ( π θ , P ψ ) = E τ ∼ ( π θ , P ψ ) [ T X t =0 γ t R ( s t , a t )] # , (1) where Ψ represents the feasible set of adversarial config- urations that remain physically plausible. The outer loop maximizes the ego’ s performance, while the inner loop seeks an adversary that minimizes the current e go’ s re ward. Directly optimizing the bi-level objectiv e via gradient de- scent is often computationally intractable due to the non- differentiable nature of physical simulators and the difficulty of propagating gradients through long-horizon rollouts. Ex- isting methods often decouple Eq. 1 into separate problems: (1) Adversarial gener ation : generating a static set of hard scenarios via surrogate objecti ves J adv (e.g., collision proba- bility); (2) P olicy optimization : then optimizing π θ against this fixed distribution. Ho wev er , this decoupled paradigm introduces objecti ve misalignment and f ails to capture the non-stationary vulnerability frontier of the ev olving policy . 3. The AD V -0 Framework W e introduce ADV-0 , a closed-loop adversarial training framew ork to solve the min-max optimization problem in Eq. 1 . Our approach treats the interaction between the driv- ing agent ( defender ) and the traffic en vironment ( attacker ) as a dynamic zero-sum game : the defender minimizes the expected risk, while the attack er continuously explores the long-tail distribution to identify and e xploit the ego’ s ev olv- ing weaknesses. Due to the nonstationarity of the driving en vironment and the rarity of critical e vents, relying on 2 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving static datasets or heuristic adv ersarial priors is insufficient. Instead, we seek a Nash Equilibrium where the e go policy π θ remains robust to the w orst-case distributions generated by a continuously ev olving adversary policy ψ . At this equilibrium, π θ is theoretically guaranteed to perform well under any other distribution within the trust region. This section details this end-to-end bi-level optimization scheme. Return Est. Policy Gradient Sampling Inner Loop Outer Loop Outer Loop Dist. Match. Solved via IPL Zero-sum Markov Game Attacker ’ s Return Defender ’ s Return Defender ’ s Return F igur e 1. Illustration of the ADV-0 framew ork. It alternates be- tween an Inner Loop where the adversary ψ ev olves via IPL to track the failure frontier , and an Outer Loop where the ego π θ opti- mizes policy gradients against the induced adv ersarial distribution. 3.1. End-to-End Framework f or Min-Max Optimization T o enable tractability and stationarity , we propose an itera- tiv e end-to-end training pipeline inspired by Rob ust Adver - sarial Reinforcement Learning (RARL, Pinto et al. ( 2017 )). The core of ADV-0 lies in efficiently propagating gradients from the ego’ s objectiv e J to the adversary ψ . The training alternates between two phases: (1) an inner loop that up- dates ψ to track the theoretical optimal attack distrib ution; and (2) an outer loop that optimizes the policy π θ against the current induced distribution (Figure 1 ). Inner loop. Formally , let X denote the context (e.g., map topology and initial traffic state) and Y Adv denote the future adversarial trajectories. W e define the critical e vent E as the set of scenarios where the ego’ s performance drops below a safety threshold ϵ : E := { Y Adv | J ( π θ , Y Adv ) ≤ ϵ } . Then the attacker’ s goal is to find an optimal adversarial distribu- tion P adv that maximizes the likelihood of this critical event while constrained within the trust re gion of the naturalistic prior P prior . This is equiv alent to a constrained optimization: max P adv E X ∼D E Y Adv ∼ P adv ( ·| X ) [log P ( E )] , s.t. D KL ( P adv || P prior ) ≤ δ. (2) Directly solving Eq. 2 in volv es optimizing a hard indicator function I ( Y Adv ∈ E ) , suffering from vanishing gradients and ev ent sparsity . T o enable end-to-end gradient optimiza- tion, we relax the hard constraint into a soft ener gy function. W e vie w the ne gativ e return − J ( π θ , Y Adv ) as the unnormal- ized log-likelihood of the critical ev ent. The objective is thus relaxed to maximizing the expected adversarial utility P ( E | Y Adv ) ≈ E Y Adv ∼ P adv − J ( π θ , Y Adv ) within the trust region. By applying Lagrange multipliers, the optima P ∗ adv can be deriv ed in closed form as the Gibbs distribution: P ∗ adv ( Y Adv | X ) | {z } Posterior = 1 Z P prior ( Y Adv | X ) | {z } Traf fic prior exp − J ( π θ , Y Adv ) /τ | {z } Generalized adversarial utility , (3) where Z is the partition function and τ is the temperature. Eq. 3 reveals that the theoretically optimal adversary re- weights the traffic prior based on the generalized adversarial utility (GA U). T raf fic prior ensures plausibility , and GA U is the likelihood that Y Adv causes the current policy π θ to fail. Howe v er , directly sampling from P ∗ adv ( ·| X ) is intractable due to the unknown partition function. ADV-0 solves for this via a two-step approximation: (1) Sampling (Sec. 3.2 ) : W e approximate expectations over P ∗ adv using importance sampling from the current prior; and (2) Learning (Sec. 3.3 ) : W e update the parameterized adversary ψ to approximate the theoretical optimum P ∗ adv via preference learning. Outer loop. W ith the adversary ψ k +1 fixed, the ego up- dates its policy to maximize the expected return under the induced adversarial distrib ution using standard RL methods: θ k +1 ← arg max θ k J ( π k θ , P ψ k +1 ) . (4) Crucially , this general framework is agnostic to the specific RL method used for the ego policy . Since the adversary interacts with the ego solely through generated trajectories, the outer loop supports both on-policy and of f-polic y algo- rithms, by adjusting the synchronization schedule between the two. Moreover , ADV-0 can be applied to π θ either out- puts continuous control signals (e.g., acceleration) or future trajectory plans (e.g., multi-modal trajectories with scores). T raining proceeds by fixing one player while updating the other . This coupled iteration ensures that the attacker dy- namically tracks the defender’ s vulnerability frontier , while the defender learns to generalize against an increasingly sophisticated attacker . See Algorithm 1 for implementation. 3.2. Reward-guided Adversarial Sampling & Alignment T o approximate the optimal distrib ution P ∗ adv without com- putationally expensiv e MCMC, we adopt a generate-and- resample paradigm. Instead of generating trajectories from scratch, we sample from a pretrained multi-modal trajectory generator G ψ that approximates P prior ( ·| X ) . Gi ven a context X , the current G ψ produces K candidates { Y Adv k } K k =1 ∼ G ψ ( ·| X ) with prior probabilities. W e then re-weight these candidate to approximate samples from P ∗ adv using GA U. Direct objective alignment. Prior works ( Zhang et al. , 2022 ; 2023 ) simplify the GA U by assuming a heuristic sur- rogate, e.g., collision probability . Howe ver , this introduces a misalignment: the defender optimizes a comprehensive rew ard (safety , efficienc y , and comfort), while the attacker solely targets collisions. This discrepancy in gradient di- rection prev ents the attacker from identifying non-collision failures (e.g., off-road) and allows the defender to overfit to specific collision modes while remaining vulnerable to other risks. In contrast, ADV-0 directly aligns the GA U 3 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving with the defender’ s objective by setting the ener gy function as the ne gation of the e go’ s cumulative return (Eq. 3 ). By targeting e xactly what the ego optimizes, the attacker offers holistic supervision signals across the entire rew ard space, whether they are safety violations or ef ficiency drops. Algorithm 1 Closed-Loop Min-Max Policy Optimization 1: Input: Initial ego policy π θ , Pretrained adversary prior G ref . 2: Hyperparameters: T emperature τ , Rew ard filters δ, ξ , Learn- ing rates α, η , Frequency N freq , IPL batch size M . 3: Initialize: Adversary G ψ ← G ref , Ego history buf fer H ego ← ∅ , Replay b uffer D (Off-polic y) or Batch buf fer B (On-policy). 4: for timestep t = 1 to T max do 5: // — Phase 1: Adversary Update (Inner Loop) — 6: if t mo d N freq == 0 then 7: for iteration k = 1 to K IPL do 8: Sample context batch { X m } M m =1 . 9: Generate candidates { Y Adv m,j } K j =1 ∼ G ψ ( ·| X m ) , ∀ X m . 10: Calculate { ˆ J ( Y Adv m,j , π θ ) } K j =1 using H ego [ X m ] (Eq. 5 ). 11: Construct preference pairs D pref based on all ˆ J . 12: Update ψ via IPL on D pref (Eq. 8 ). 13: end for 14: end if 15: // — Phase 2: Ego Update (Outer Loop) — 16: Sample new scenario conte xt X . 17: Generate candidates { Y k } ∼ G ψ ( ·| X ) . 18: Select Y adv via softmax sampling (Eq. 6 ). 19: Rollout π θ in en vironment P ψ to get Y Ego . 20: Update history: H ego [ X ] ← FIFO ( H ego ∪ { Y Ego } ) . 21: if Algorithm is On-Policy (e.g., PPO) then 22: Store Y Ego in Batch Buffer B . 23: if B is full then 24: Update θ via Eq. 1 sev eral steps on B , then clear B . 25: end if 26: else if Algorithm is Off-Polic y (e.g., SA C) then 27: Store transitions from Y Ego into Replay Buffer D . 28: Sample mini-batch from D and update θ one step (Eq. 1 ). 29: end if 30: end for Efficient retur n estimation. Evaluating the e xact return E [ J ( π θ , Y Adv k )] for all K candidates via closed-loop simu- lation requires fully rolling out the policy , which is compu- tationally prohibiti ve. T o address this, we propose a Pr oxy Rewar d Evaluator that estimates the expected return using a lightweight function query . Recognizing that the ego’ s response to Y Adv is stochastic (exploration noise) during training, we treat J as a random v ariable. W e maintain a context-a ware dynamic buf fer of the ego’ s recent responses H ego ( X ) = { Y Ego i | X } N i =1 containing the N most recent tra- jectories generated by π θ in context X . For a new context with an empty buf fer , we perform a single warm-up rollout using π θ against the replay log to initialize the buf fer . W e treat H ego as an empirical approximation of the current pol- icy distrib ution. The expected return for a candidate Y Adv k is estimated via Monte Carlo integration against the history: ˆ J ( Y Adv k , π θ ) ≈ 1 N X Y Ego i ∈H ego R proxy ( Y Ego i , Y Adv k ) , (5) where R proxy is a v ectorized function that computes geomet- ric interactions (e.g., progress, collision overlap) between the adversary path and the cached ego paths without step- ping the physics engine. This rule-based proxy provides an efficient and sufficiently accurate gradient direction for ad- versarial sampling (see Section D.2.1 for implementation). T emperatur e-scaled sampling. Finally , to select the ad- versarial trajectory for training, we implement the Gibbs distribution (Eq. 3 ) o ver the finite set of K candidates. The probability of selecting candidate k is giv en by the scaled softmax distribution o ver ne gativ e estimated returns: P ( Y Adv k ) = exp − ˆ J ( Y Adv k , π θ ) /τ P K j =1 exp − ˆ J ( Y Adv j , π θ ) /τ . (6) This serves as an importance sampling step, re-weighting the proposal distribution G ψ tow ards the theoretical opti- mum P ∗ adv (see Appendix B.1 ). τ balances exploration and exploitation: τ → 0 selects the worst case, while larger τ retains div ersity from the prior . It ensures that the defender is exposed to a di verse range of challenging scenarios from the long tail, rather than collapsing into a single worst case. 3.3. Iterative Pr eference Lear ning in the Long T ail While the sampling strategy in Section 3.2 identifies hard cases within the support of G ψ , this fixed proposal bounds its efficacy . As the defender π θ improv es, its weakness shifts into the long tail where the prior G ref has negligible mass. Relying solely on static sampling becomes inefficient. T o track the shifting frontier , we update ψ to match the distribution of the generator G ψ and the optimal target P ∗ adv . Implicit r eward optimization via prefer ences. Formally , our goal is to minimize the KL-div ergence between G ψ and P ∗ adv . Recall the definition in Eq. 3 , we hav e: min ψ D KL ( G ψ || P ∗ adv ) = min ψ E Y ∼G ψ [log G ψ ( Y | X ) / P ∗ adv ( Y | X )] = min ψ E Y ∼G ψ log G ψ ( Y | X ) G ref ( Y | X ) + 1 τ J ( π θ , Y ) + const. ⇐ ⇒ max ψ E Y ∼G ψ − J ( π θ , Y ) − τ D KL ( G ψ ||G ref ) . (7) Eq. 7 re veals a standard RL objective: maximizing the e x- pected adversarial re ward subject to a KL-diver gence con- straint. Howe v er , directly solving it via policy gradient is notoriously unstable in this context due to the high v ariance of gradients. The action space of continuous trajectories is high-dimensional, and the zero-sum interaction often leads to mode collapse. Instead of explicit RL, we cast the prob- lem as preference learning. Following Rafailov et al. ( 2023 ), the optimal policy for the KL-constrained objecti ve satisfies a specific preference ordering, which is equiv alent to opti- mizing an implicit r ewar d . This allows us to update ψ using a supervised loss on preference pairs, bypassing the need for an explicit v alue function or unstable rew ard maximization. 4 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Online iterative e volution. Standard preference learning methods are often offline with static preference datasets. Instead, ADV-0 operates in a nonstationary game where the preference labels depend on e volving players. Therefore, we propose online Iterative Pr efer ence Learning (IPL) in the inner loop. IPL generates preference data on-the-fly , conditioning on the current attacker and labels it using the current defender . This process proceeds on-policy: (1) Sampling : For a gi v en context X , a series of candidates are generated { Y Adv k } K k =1 from the curr ent attacker G ψ . (2) La- beling : Each candidate is ev aluated using the proxy re ward ev aluator ˆ J ( · , π θ ) . Crucially , this ev aluation uses the latest history of the defender . (3) Pairing : A preference dataset D pref is curated by pairing ( Y w , Y l ) from the candidates, where Y w is preferred ov er Y l if ˆ J ( Y w , π θ ) < ˆ J ( Y l , π θ ) . T o prev ent trivial comparisons, we apply a rew ard margin δ and a spatial div ersity filter ξ : D pref = n ( Y w , Y l ) | ˆ J ( Y l ) − ˆ J ( Y w ) > δ ∧ ∥ Y w − Y l ∥ 2 > ξ o . This reduces noise in the proxy , making preferences distinguishable between structurally different attacks. Objective. W e update the adversarial polic y G ψ by min- imizing the neg ativ e log-likelihood of the preferred trajec- tories. T o handle the high v ariance of heterogeneous traffic scenarios without the high cost of a massiv e replay b uffer , we employ a streaming gradient accumulation strategy to stabilize the training. W e process a stream of scenarios se- quentially , accumulating gradients over a mini-batch of M scenarios before performing a parameter update. The loss function L IPL ( G ψ ) for a mini-batch B of generated pairs is: − 1 |B | X ( Y w ,Y l ) ∈B log σ τ log G ψ ( Y w | X ) G ref ( Y w | X ) − log G ψ ( Y l | X ) G ref ( Y l | X ) . (8) This reduces the variance of per -scenario update while main- taining the on-policy nature of data generation. Here, the reference model G ref remains frozen as the pretrained prior . This streaming ev olution ensures that the adversary contin- uously adapts to the defender’ s ev olving capabilities. By pushing the generator’ s distribution to wards the theoretical Gibbs optimum P ∗ adv , the defender is continuously trained against the most pertinent long-tail risks, ef fectiv ely mitigat- ing the distribution shift and forcing rob ust generalization. 3.4. Theoretical Analysis W e provide a theoretical analysis of the con v ergence prop- erties of ADV-0 and establish a generalization bound that certifies the agent’ s performance in real-world long-tail dis- tributions. Deriv ations and proofs are provided in Section B . Con vergence to Nash Equilibrium. The interaction be- tween the defender and the attacker is modeled as a regular - ized zero-sum Marko v game. Building on the finding that optimizing Eq. 8 reco vers the optimal adv ersary solv ed for a Gibbs distrib ution, we prove that iterativ e updates constitute a contraction mapping on the value function space. Theorem 3.1 (Conv ergence to Nash Equilibrium) . The iterative updates in ADV-0 con ver ge to a unique fixed point corr esponding to the Nash Equilibrium ( π ∗ , ψ ∗ ) of the game. This point satisfies the saddle-point inequality J τ ( π , G ψ ∗ ) ≤ J τ ( π ∗ , G ψ ∗ ) ≤ J τ ( π ∗ , G ψ ) for all feasi- ble policies, wher e J τ is the r e gularized objective. Generalization to real-w orld long tail. A core concern is whether robustness against a generated adversary P ψ trans- lates to safety in the real-world long-tail distribution P real . W e model the real dynamics as an unknown distribution lying within the trust region of the traffic prior . W e derive a certified lo wer bound on the expected return by measuring the discrepancy between two induced transition dynamics. Theorem 3.2 (Generalizability) . Let V max be the maxi- mum of the value function, P r eal be the r eal dynamics, and π θ is trained under the adversarial dynamics P ψ induced by G ψ . The performance of π θ under P r eal is bounded by: J ( π θ , P r eal ) ≥ J ( π θ , P ψ ) − γ V max √ 2 1 − γ q E [ D KL ( G ψ ∥G r ef )] . Theorem 3.2 implies that optimizing against the generated adversary maximizes a certified lower bound on the ex- pected return in the real world. The outer loop maximizes the rob ust return J ( π θ , P ψ ) , while the inner loop minimizes the KL-div ergence, ensuring that safety improvements in the adversarial domain transfer to open-world deplo yment. 4. Experiments W e empirically e valuate ADV-0 to answer three core ques- tions: (1) Can ADV-0 generates plausible yet long-tailed scenarios that ef fectiv ely expose the vulnerabilities of dri v- ing agents? (2) Does the training process yield a robust policy that generalizes to diverse adversarial attacks? (3) Can the safety improv ements observed in simulation trans- fer to real-world long-tailed ev ents? All experiments are performed in MetaDriv e simulator based on the WOMD. 4.1. Generating Safety-Critical Scenarios −20 −15 −10 −5 0 Log-Likelihood (LL) 0.0 0.1 0.2 0.3 0.4 Density LL Distribution of Sampled Adversarial Traj. A DV-0 ( μ =-7 . 67) CAT ( μ =- 5. 7 5 ) DenseTNT ( μ =- 4.2 7) F igur e 2. LL distribution of dif- ferent adversarial generators. 50 0.0 2.5 5.0 7.5 10.0 12.5 15.0 TTC (s) 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 Density 0 10 20 30 40 Distance (m) 0.00 0.01 0.02 0.03 0.04 0.05 Replay Policy Log Env ADV Env 50 0.0 2.5 5.0 7.5 10.0 12.5 15.0 TTC (s) 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 0 10 20 30 40 Distance (m) 0.00 0.01 0.02 0.03 0.04 0.05 IDM Policy Density F igur e 3. Scene-lev el distribu- tions of B2B distance and TTC. Main r esults. W e first ev aluate ADV-0 in generating safety-critical scenarios against various ego policies. As presented in T able 1 , ADV-0 consistently outperforms com- peting baselines in exposing system vulnerabilities, espe- 5 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving cially for reactiv e policies such as IDM and RL. A detailed ablation in T able 6 further highlights two findings: (1) The proposed energy-based sampling strategy (Eq. 6 ) is effecti ve compared to the standard logit-based scheme. (2) IPL-based fine-tuning, which is insensitive to RL, further refines the adversary . By fine-tuning the generator against specific ego policies, the adversary learns to exploit specific weaknesses. T able 1. Safety-critical scenario generation . CR denotes the collision rate of the e go in generated scenarios, and ER denotes the ego’ s cumulative return. Ego is controlled by Replay , IDM, and trained PPO policies, respectively . Metrics of ADV-0 are mean values across all training methods. See full results in T able 6 . Adversary Replay IDM RL Agent CR ↑ ER ↓ CR ↑ ER ↓ CR ↑ ER ↓ Replay - - 19.03% 51.75 16.80% 51.65 Heuristic 100.00% 0.00 74.70% 32.12 69.64% 24.90 CA T 90.08% 1.03 43.13% 43.47 36.84% 42.26 KING 23.28% 47.67 24.49% 49.41 21.26% 49.32 AdvT rajOpt 69.64% 3.12 26.92% 45.36 28.95% 45.10 GOOSE 20.46% 48.52 24.48% 49.45 13.88% 51.80 SA GE 74.53% 2.57 36.50% 43.81 35.40% 42.87 SEAL 59.06% 8.58 36.70% 43.75 37.63% 41.99 AD V -0 (ours) 91.10% 0.99 45.83% 40.03 40.68% 39.13 Distribution of the long tail. ADV-0 can navigate the long-tail distribution of scenarios. Figure 2 illustrates the log-likelihood (LL) distrib ution of the sampled adversarial trajectories. Compared to CA T and pretrained prior , the distribution of ADV-0 is shifted towards lower likelihood and exhibits a wider variance. This indicates that it uncovers rare but plausible, behavior-level ev ents that are typically ignored by standard priors. Figure 3 shows the scene-le vel statistics. ADV-0 produces notably lo wer T ime-to-Collision (TTC) and closer Bumper-to-Bumper (B2B) distances com- pared to the naturalistic data. Crucially , this aggressiveness does not compromise physical plausibility . As shown in Figure 9 , ADV-0 maintains a comparable realism penalty . 0 20 40 60 0 20 40 60 0 20 40 60 0 20 40 60 Reward Scenario A d v e r s a r y Eg o Episode Step F igur e 4. Examples of generated reward-reduced adv ersarial sce- narios from ADV-0 . Additional cases are shown in Figure 15 . Beyond collision. ADV-0 directly tar gets the ego’ s return, allowing for the disco very of di verse failure modes be yond crashes. As shown in Figure 4 and Figure 15 , the adversary can force the e go into abnormal beha viors and non-collision failures, such as stalling at intersections or deviating from reference paths. These beha viors result in a drastic drop in accumulated reward (e.g., lack of progress or discomfort penalties) ev en if a collision is av oided, which are critical performance risks often ignored by collision-centric attacks. T able 2. Performance validation of lear ned policies . Results are av eraged across 6 RL methods (GRPO, PPO, PPO-Lag, SA C, SA C- Lag, TD3). This table compares the performances of agents learned by dif ferent adversarial methods and e v aluate on different gener- ated scenarios. Full results are shown in T ables 7 , 8 , 9 , 10 , 11 , 12 . V al. Env . RC ↑ Crash ↓ Re ward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.742 ± 0.011 0.159 ± 0.019 49.56 ± 1.05 0.480 ± 0.013 AD V -0 0.695 ± 0.011 0.289 ± 0.029 44.60 ± 0.83 0.598 ± 0.022 CA T 0.704 ± 0.011 0.271 ± 0.025 45.68 ± 1.16 0.585 ± 0.025 SA GE 0.699 ± 0.013 0.263 ± 0.025 45.19 ± 1.54 0.567 ± 0.028 Heuristic 0.710 ± 0.016 0.217 ± 0.021 45.41 ± 2.08 0.552 ± 0.035 A vg. 0.710 ± 0.012 0.240 ± 0.024 46.09 ± 1.33 0.556 ± 0.027 AD V -0 (w/o IPL) Replay 0.719 ± 0.020 0.167 ± 0.024 46.41 ± 1.97 0.540 ± 0.023 AD V -0 0.664 ± 0.018 0.317 ± 0.030 41.03 ± 1.87 0.657 ± 0.020 CA T 0.677 ± 0.017 0.299 ± 0.035 42.30 ± 1.68 0.643 ± 0.030 SA GE 0.672 ± 0.024 0.270 ± 0.028 42.17 ± 2.38 0.610 ± 0.038 Heuristic 0.679 ± 0.022 0.239 ± 0.041 41.78 ± 2.08 0.612 ± 0.040 A vg. 0.683 ± 0.020 0.258 ± 0.031 42.74 ± 2.00 0.613 ± 0.030 CA T Replay 0.720 ± 0.014 0.183 ± 0.026 46.52 ± 1.15 0.528 ± 0.015 AD V -0 0.660 ± 0.018 0.332 ± 0.043 40.70 ± 0.97 0.660 ± 0.020 CA T 0.667 ± 0.017 0.313 ± 0.032 41.30 ± 1.48 0.652 ± 0.018 SA GE 0.660 ± 0.021 0.307 ± 0.025 41.41 ± 2.09 0.628 ± 0.017 Heuristic 0.676 ± 0.021 0.261 ± 0.034 41.72 ± 1.69 0.605 ± 0.023 A vg. 0.676 ± 0.018 0.279 ± 0.032 42.33 ± 1.47 0.614 ± 0.019 Heuristic Replay 0.682 ± 0.032 0.201 ± 0.018 42.75 ± 3.04 0.592 ± 0.037 AD V -0 0.637 ± 0.047 0.331 ± 0.021 39.09 ± 2.12 0.678 ± 0.028 CA T 0.650 ± 0.021 0.311 ± 0.020 40.11 ± 2.38 0.668 ± 0.033 SA GE 0.642 ± 0.042 0.314 ± 0.019 39.53 ± 2.58 0.658 ± 0.025 Heuristic 0.641 ± 0.030 0.279 ± 0.016 38.81 ± 2.61 0.655 ± 0.028 A vg. 0.650 ± 0.034 0.287 ± 0.019 40.06 ± 2.54 0.649 ± 0.032 Replay Replay 0.692 ± 0.035 0.209 ± 0.030 42.93 ± 1.32 0.588 ± 0.025 AD V -0 0.622 ± 0.038 0.374 ± 0.038 36.80 ± 2.48 0.700 ± 0.020 CA T 0.642 ± 0.040 0.368 ± 0.037 38.26 ± 1.83 0.683 ± 0.030 SA GE 0.625 ± 0.040 0.339 ± 0.040 37.68 ± 1.84 0.660 ± 0.032 Heuristic 0.638 ± 0.031 0.310 ± 0.034 37.80 ± 2.41 0.672 ± 0.015 A vg. 0.644 ± 0.037 0.320 ± 0.036 38.70 ± 1.97 0.661 ± 0.028 4.2. Learning Generalizable Driving P olicies Generalization to unseen adversaries. A core challenge in adversarial RL is overfitting to a specific adversary , which limits generalization to unseen risks. W e conduct a cross- validation where agents trained via different methods are tested across a spectrum of en vironments. T able 2 reports the performance av eraged across six RL algorithms. W e observe that agents trained with ADV-0 (w/ IPL) consis- tently achieve the best results across all metrics. While baselines often perform well against their own attacks, they degrade when applied to unseen adversarial distrib utions. In contrast, ADV-0 maintains consistent generalizability . The comparison between ADV-0 (w/o IPL) and CA T indicates the benefit of directly aligning the GA U with the ego’ s ob- jectiv e. By acti vely exploring the long tail via IPL, ADV-0 enables generalized robustness to handle unseen risks. 6 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Impact of IPL. T o isolate the gain pro vided by IPL, we compare the performance of agents and adversaries trained with and without IPL in T able 3 . The inclusion of IPL in the adversary creates a more challenging environment, e v- idenced by the drop in agent rewards. Howe ver , the agent trained with full ADV-0 becomes more robust when facing the stronger adversary . This confirms that the dynamic ev o- lution of the adversary via IPL forces the defender to cov er broader vulnerabilities. Qualitative evidence of this dynamic ev olution is sho wn in Figure 13 . Finally , we study the sam- ple efficiency and overfitting risks regarding the training budget. As shown in Figure 5 , the gap between training and testing performance narro ws with IPL, indicating that acti ve discov ery of div erse failures ef fectiv ely mitigates the risk of ov erfitting to limited training data. Detailed learning curves and results are provided in Figures 10 - 11 and T ables 7 - 12 . T able 3. Cross-v alidation of ADV-0 . Performances of agents and adversaries with/without IPL. Decrease indicates the percentage change in performance when facing an IPL-enhanced adversary compared to the baseline. Improvement indicates the percentage change when the agent is trained with IPL compared to the other . Agent/Adversary Rew ard ( ↑ ) Adversary (w/o IPL) Adversary (w/ IPL) Decrease Agent w/o IPL 41 . 03 ± 1 . 87 39 . 01 ± 0 . 97 − 4 . 92% Agent w/ IPL 44 . 60 ± 0 . 83 43 . 47 ± 1 . 40 − 2 . 53% Improvement +8 . 70% +11 . 43% Agent/Adversary Cost ( ↓ ) Adversary (w/o IPL) Adversary (w/ IPL) Decrease Agent w/o IPL 0 . 657 ± 0 . 020 0 . 685 ± 0 . 016 +4 . 26% Agent w/ IPL 0 . 598 ± 0 . 022 0 . 615 ± 0 . 025 +2 . 84% Improvement − 8 . 98% − 10 . 22% – 1 3 6 15 40 100 400 # of Training Scenarios 0 20 40 60 80 100 Reward (Adversarial) 1 3 6 15 40 100 400 # of Training Scenarios -0.25 0.00 0.25 0.50 0.75 1.00 1.25 Cost (Adversarial) w/o IPL T rain w/o IPL T est w/ IPL T rain w/ IPL T est F igur e 5. Generalization gap ov er different training b udgets. 4.3. Impro ving Policy Rob ustness in the Long T ail Main results. While ADV-0 has presented robustness against generated adversaries, it is crucial to verify whether this performance generalizes to real-world, naturally oc- curring long-tail events. T o this end, we curate unbiased held-out sets mined from real-world W OMD logs, includ- ing only high-risk scenarios categorized by extreme safety criticality (e.g., critical TTC, PET) and semantic rarity (e.g., rare behaviors). As shown in T able 4 (detailed in T able 15 ), agents trained via ADV-0 demonstrate superior zero-shot robustness compared to baselines. It achie ves the highest safety margins and stability scores, significantly reducing the rates of near misses and RDP violations, indicating that the agent learns to anticipate risks before they become criti- cal, rather than merely reacting to emer gencies. Examples in Figures 6 and 14 further visualize these defensive beha v- iors: ADV-0 agent proacti vely yields to aggressi ve cut-ins and navigates sudden occlusions where baseline agents f ail. Left-turn Sudden-brake Cut-in Agent w/o ADV -0 Agent w/ ADV -0 F igur e 6. V isualization of improved safe dri ving ability after being trained with ADV-0 . More examples are sho wn in Figure 14 . 4.4. Algorithmic Analysis Applications to motion planners. T o sho w the general- ity of ADV-0 , we extend our e v aluation beyond RL agents to two kinds of SO T A learning-based trajectory planners: PlanTF ( Cheng et al. , 2024 ) (multimodal scoring) and SMAR T ( W u et al. , 2024 ) (autore gressiv e generation). As shown in T ables 5 and 13 , adv ersarial fine-tuning via ADV-0 yields consistent improv ements for both architectures. W e further analyze the internal beha vior of the planners using the trajectory-le vel breakdo wn in T able 14 . The results indicate that fine-tuned models learn to prioritize safety con- straints significantly more than pretrained priors. This safety improv ement comes with a trade-off in ef ficiency . Interest- ingly , we observe that the performance of these planners remains slightly lower than RL agents discussed pre viously . W e attribute this to two factors: (1) the cov ariate shift in behavior cloning models ( Karkus et al. , 2025 ), where they struggle to recov er when the adversary forces it into out- of-distribution states; and (2) the latenc y introduced by the re-planning horizon. Unlike end-to-end RL policies that output immediate control actions, they generate a future tra- jectory executed by a controller . This delayed reaction limits the ability to react instantaneously to aggressiv e attacks. Impact of temperature parameter . W e study the sensi- tivity of the sampling temperature τ in Eq. 6 , which mod- ulates the trade-off between adversarial exploitation and exploration. Figure 7 illustrates an obvious trade-off: (1) At extremely low temperatures ( τ → 0 ), the sampling de- generates into a deterministic hard mode. This leads to sub- optimal performance, likely because an ov erly aggressive 7 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving T able 4. Robustness on mined real-world long-tailed sets. A verage agent performance on four long-tail scenario categories filtered by criteria: Critical TTC ( min TTC < 0 . 4 s ), Critical PET ( PET < 1 . 0 s ), Har d Dynamics (Acc. < − 4 . 0 m/s 2 or | Jerk | > 4 . 0 m/s 3 ), and Rar e Cluster (topologically sparse trajectory clusters). Metrics assess av erage Safety Margin (higher v alues indicate earlier risk detection), Stability & Comfort (lower Jerk indicates smoother control), and Defensive Driving , quantified by Near -Miss Rate (proximity without collision) and RDP V iolation (percentage of time requiring deceleration > 6 m/s 2 to av oid collision). Full results are shown in T able 15 . Reactive T raffic Safety Margin Stability & Comfort Defensive Driving A vg Min-TTC ( ↑ ) A vg Min-PET ( ↑ ) Mean Abs Jerk ( ↓ ) 95% Jerk ( ↓ ) Near-Miss Rate ( ↓ ) RDP V iolation Rate ( ↓ ) AD V -0 (w/ IPL) ✓ 0 . 993 ± 0 . 189 1 . 150 ± 0 . 317 1 . 653 ± 0 . 169 5 . 053 ± 0 . 885 63 . 45% ± 4 . 34% 33 . 70% ± 3 . 77% × 1 . 527 ± 0 . 182 1 . 103 ± 0 . 313 1 . 617 ± 0 . 204 5 . 177 ± 0 . 953 60 . 97% ± 3 . 94% 36 . 45% ± 2 . 85% CA T ✓ 0 . 825 ± 0 . 192 1 . 017 ± 0 . 317 1 . 875 ± 0 . 229 5 . 422 ± 0 . 833 83 . 04% ± 5 . 99% 44 . 80% ± 6 . 12% × 1 . 415 ± 0 . 462 0 . 980 ± 0 . 327 1 . 979 ± 0 . 193 6 . 002 ± 0 . 931 75 . 36% ± 7 . 86% 51 . 20% ± 4 . 74% Heuristic ✓ 0 . 864 ± 0 . 200 1 . 150 ± 0 . 467 2 . 129 ± 0 . 237 6 . 542 ± 0 . 942 74 . 46% ± 5 . 98% 48 . 79% ± 3 . 65% × 1 . 601 ± 0 . 538 1 . 093 ± 0 . 450 2 . 199 ± 0 . 218 6 . 778 ± 1 . 066 68 . 82% ± 9 . 05% 52 . 10% ± 1 . 77% Replay ✓ 0 . 587 ± 0 . 185 0 . 683 ± 0 . 217 2 . 779 ± 0 . 431 8 . 265 ± 1 . 718 89 . 53% ± 4 . 30% 69 . 73% ± 5 . 27% × 0 . 978 ± 0 . 462 0 . 730 ± 0 . 233 2 . 720 ± 0 . 383 8 . 104 ± 1 . 537 85 . 13% ± 4 . 58% 68 . 50% ± 4 . 68% T able 5. Application to lear ning-based planners . Performance comparisons of two SO T A trajectory planning models before and after fine-tuning using ADV-0 (GRPO). See T able 13 for details. Model RC ↑ Crash ↓ Reward ↑ Cost ↓ PlanTF 0.628 ± 0.025 0.357 ± 0.031 35.85 ± 2.51 1.04 ± 0.04 + AD V -0 0.674 ± 0.016 0.263 ± 0.025 41.98 ± 1.62 0.77 ± 0.02 Rel. Change +7.46% -26.23% +17.11% -25.68% SMAR T 0.587 ± 0.029 0.396 ± 0.034 32.66 ± 2.85 1.15 ± 0.05 + AD V -0 0.631 ± 0.015 0.305 ± 0.023 37.85 ± 1.70 0.92 ± 0.02 Rel. Change +7.57% -22.88% +15.86% -20.31% attacker ov erwhelms the defender early in training, without learning generalized robustness. (2) Con versely , high values ( τ = 5 . 0 ) reduce the adv ersarial signal, degrading ADV-0 to domain randomization. The attacker fails to consistently expose weaknesses. The results indicate that a moderate value ( τ = 0 . 1 ) achieves the best balance. It introduces sufficient stochasticity to cov er diverse long-tail distribu- tion while maintaining enough focus to prioritize high-risk regions, ef fecti vely forming an automatic regularization. 1e-8 0.1 0.2 0.5 1.0 5.0 Temperature 0.0 0.1 0.2 0.3 0.4 0.5 Crash Rate ADV Scenarios 0.50 0.55 0.60 0.65 0.70 0.75 Route Completion 1e-8 0.1 0.2 0.5 1.0 5.0 Temperature 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 Crash Rate Normal Scenarios 0.55 0.60 0.65 0.70 0.75 Route Completion Crash Rate Route Completion F igur e 7. Impacts of the temperature parameter in sampling. Ablation on retur n estimator . The inner loop relies on the quality of the return estimator ˆ J used to label pref- erences. W e compare our rule-based proxy against three baselines: GTRewar d (oracle simulation), Experience (re- triev al from history), and Rewar dModel (learnable neural network). Figure 8 reports the IPL training curves. Surpris- ingly , the rule-based proxy achiev es low and stable pref- erence loss comparable to the oracle, outperforming other estimators. Figure 12 measures a strong Spearman corre- lation of ρ = 0 . 77 between the proxy estimates and oracle returns. This suggests that the geometric proxy provides a high-fidelity and low-v ariance ranking signal, which is suf- ficient for adversarial sampling. Future work may explore using the Q-network from an Actor -Critic architecture for value estimation to handle more comple x interactions. 0 250k 500k 750k 1000k 1250k 1500k 1750k 2000k Step 0.62 0.64 0.66 0.68 0.70 Preference Loss Experience GTReward Ours RewardModel F igur e 8. Impacts of different rew ard calculator schemes. Heuristic CAT ADV-0 SAGE 0 5 10 15 20 Realism Penalty 14.5 12.1 11.3 4 Heuristic CA T ADV-0 SAGE F igur e 9. Realism penalty value of different adv ersarial methods. 5. Conclusion This paper presents ADV-0 , a closed-loop min-max policy optimization framew ork designed to enhance the robustness of AD models against long-tail risks. By formulating the problem as a zero-sum game and solving it via an alternat- ing end-to-end training pipeline, we bridge the gap between adversarial generation and rob ust policy learning. W e theo- retically prov ed that it conv erges to a Nash Equilibrium and maximizes a certified lower bound. Empirical results sug- gest that ADV-0 not only generates effecti v e safety-critical scenarios but also impro ves the generalizability of both RL agents and motion planners against div erse long-tail risks. Despite the promising results, se veral limitations e xist. (1) The reliance on high-fidelity simulators for online RL train- ing limits scalability . (2) Extending ADV-0 to vision-based sensor inputs may require differentiable neural rendering, which remains a non-trivial challenge. Future work could ex- plore of fline RL techniques ( Karkus et al. , 2025 ) to improve training efficienc y and vision-based adversarial generation. 8 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Impact Statement This paper presents work whose goal is to advance the field of Machine Learning, specifically in the domain of safety-critical autonomous systems. Our research focuses on identifying system vulnerabilities and improving rob ust- ness against rare, long-tail events, which is a prerequisite for the safe large-scale deployment of autonomous v ehicles. By providing a rigorous frame work for generating and miti- gating high-risk scenarios, this work contributes to reducing potential accidents and enhancing public trust in automation technologies. While adv ersarial generation techniques could theoretically be repurposed to identify vulnerabilities for malicious intent, our framew ork is designed as a defensiv e mechanism to patch these flaws before deployment. W e do not identify any specific negati ve ethical consequences or societal risks associated with this research, as the adversarial generation is strictly confined to simulation en vironments for the purpose of system validation and impro vement. References Achiam, J., Held, D., T amar , A., and Abbeel, P . Constrained policy optimization. In International confer ence on ma- chine learning , pp. 22–31. PMLR, 2017. Amirkhani, A., Karimi, M. P ., and Banitalebi-Dehkordi, A. A survey on adversarial attacks and defenses for object detection and their applications in autonomous v ehicles. The V isual Computer , 39(11):5293–5307, 2023. Anzalone, L., Barra, P ., Barra, S., Castiglione, A., and Nappi, M. An end-to-end curriculum learning approach for autonomous driving scenarios. IEEE T ransactions on Intelligent T ransportation Systems , 23(10):19817–19826, 2022. Boloor , A., He, X., Gill, C., V orobeychik, Y ., and Zhang, X. Simple physical adversarial e xamples against end-to-end autonomous driving models. In 2019 IEEE International Confer ence on Embedded Software and Systems (ICESS) , pp. 1–7. IEEE, 2019. Brunke, L., Greeff, M., Hall, A. W ., Y uan, Z., Zhou, S., Panerati, J., and Schoellig, A. P . Safe learning in robotics: From learning-based control to safe reinforce- ment learning. Annual Review of Contr ol, Robotics, and Autonomous Systems , 5(1):411–444, 2022. Chen, J., Y uan, B., and T omizuka, M. Model-free deep reinforcement learning for urban autonomous driving. In 2019 IEEE intelligent transportation systems confer ence (ITSC) , pp. 2765–2771. IEEE, 2019. Chen, K., Sun, W ., Cheng, H., and Zheng, S. Rift: Closed- loop rl fine-tuning for realistic and controllable traffic simulation. arXiv preprint , 2025. Chen, L., W u, P ., Chitta, K., Jaeger , B., Geiger, A., and Li, H. End-to-end autonomous driving: Challenges and frontiers. IEEE T ransactions on P attern Analysis and Machine Intelligence , 2024. Cheng, J., Chen, Y ., Mei, X., Y ang, B., Li, B., and Liu, M. Rethinking imitation-based planners for autonomous driv- ing. In 2024 IEEE International Confer ence on Robotics and Automation (ICRA) , pp. 14123–14130. IEEE, 2024. Deng, Y ., Zhang, T ., Lou, G., Zheng, X., Jin, J., and Han, Q.-L. Deep learning-based autonomous driving systems: A surve y of attacks and defenses. IEEE T ransactions on Industrial Informatics , 17(12):7897–7912, 2021. Ding, W ., Chen, B., Xu, M., and Zhao, D. Learning to collide: An adapti ve safety-critical scenarios generating method. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS) , pp. 2243–2250. IEEE, 2020. Ding, W ., Xu, C., Arief, M., Lin, H., Li, B., and Zhao, D. A survey on safety-critical drivi ng scenario genera- tion—a methodological perspectiv e. IEEE T ransactions on Intelligent T ransportation Systems , 24(7):6971–6988, 2023. Fang, S., Cui, Y ., Liang, H., Lv , C., Hang, P ., and Sun, J. Corevla: A dual-stage end-to-end autonomous driving framew ork for long-tail scenarios via collect-and-refine. arXiv pr eprint arXiv:2509.15968 , 2025. Feng, S., Y an, X., Sun, H., Feng, Y ., and Liu, H. X. Intel- ligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment. Natur e communications , 12(1):748, 2021. Feng, S., Sun, H., Y an, X., Zhu, H., Zou, Z., Shen, S., and Liu, H. X. Dense reinforcement learning for safety validation of autonomous vehicles. Nature , 615(7953): 620–627, 2023. Gu, J., Sun, C., and Zhao, H. Densetnt: End-to-end tra- jectory prediction from dense goal sets. In Pr oceedings of the IEEE/CVF international confer ence on computer vision , pp. 15303–15312, 2021. Guo, D., Y ang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., W ang, P ., Bi, X., et al. Deepseek-r1: In- centi vizing reasoning capability in llms via reinforcement learning. arXiv preprint , 2025. Haarnoja, T ., Zhou, A., Abbeel, P ., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor . In International confer ence on machine learning , pp. 1861–1870. Pmlr, 2018. 9 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Hanselmann, N., Renz, K., Chitta, K., Bhattacharyya, A., and Geiger , A. King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients. In Eur opean Confer ence on Computer V ision , pp. 335–352. Springer , 2022. He, X., Y ang, H., Hu, Z., and Lv , C. Rob ust lane change decision making for autonomous vehicles: An observa- tion adversarial reinforcement learning approach. IEEE T ransactions on Intelligent V ehicles , 8(1):184–193, 2022. Isele, D., Rahimi, R., Cosgun, A., Subramanian, K., and Fujimura, K. Na vigating occluded intersections with autonomous vehicles using deep reinforcement learning. In 2018 IEEE international confer ence on r obotics and automation (ICRA) , pp. 2034–2039. IEEE, 2018. Jiang, B., Chen, S., Zhang, Q., Liu, W ., and W ang, X. Al- phadriv e: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning. arXiv pr eprint arXiv:2503.07608 , 2025. Kamalaruban, P ., Huang, Y .-T ., Hsieh, Y .-P ., Rolland, P ., Shi, C., and Ce vher , V . Robust reinforcement learning via adversarial training with langevin dynamics. Advances in Neural Information Pr ocessing Systems , 33:8127–8138, 2020. Karkus, P ., Igl, M., Chen, Y ., Chitta, K., Packer , J., Douil- lard, B., T ian, R., Naumann, A., Garcia-Cobo, G., T an, S., et al. Beyond behavior cloning in autonomous dri ving: a survey of closed-loop training techniques. A uthor ea Pr eprints , 2025. Kiran, B. R., Sobh, I., T alpaert, V ., Mannion, P ., Al Sal- lab, A. A., Y ogamani, S., and P ´ erez, P . Deep reinforce- ment learning for autonomous dri ving: A survey . IEEE transactions on intelligent tr ansportation systems , 23(6): 4909–4926, 2021. Knox, W . B., Allievi, A., Banzhaf, H., Schmitt, F ., and Stone, P . Reward (mis) design for autonomous dri ving. Artificial Intelligence , 316:103829, 2023. Kuutti, S., F allah, S., and Bowden, R. Training adv ersarial agents to exploit weaknesses in deep control policies. In 2020 IEEE International Confer ence on Robotics and Automation (ICRA) , pp. 108–114. IEEE, 2020. Li, D., Ren, J., W ang, Y ., W en, X., Li, P ., Xu, L., Zhan, K., Xia, Z., Jia, P ., Lang, X., et al. Finetuning generative trajectory model with reinforcement learning from human feedback. arXiv preprint , 2025a. Li, Q., Peng, Z., Feng, L., Zhang, Q., Xue, Z., and Zhou, B. Metadriv e: Composing di verse dri ving scenarios for generalizable reinforcement learning. IEEE transactions on pattern analysis and machine intelligence , 45(3):3461– 3475, 2022. Li, Y ., Tian, M., Zhu, D., Zhu, J., Lin, Z., Xiong, Z., and Zhao, X. Drive-r1: Bridging reasoning and planning in vlms for autonomous dri ving with reinforcement learning. arXiv pr eprint arXiv:2506.18234 , 2025b. Li, Z., Cao, X., Gao, X., T ian, K., W u, K., Anis, M., Zhang, H., Long, K., Jiang, J., Li, X., et al. Simulating the unseen: Crash prediction must learn from what did not happen. arXiv preprint , 2025c. Liu, H. X. and Feng, S. Curse of rarity for autonomous vehicles. natur e communications , 15(1):4808, 2024. Liu, Y ., Peng, Z., Cui, X., and Zhou, B. Adv-bmt: Bidirec- tional motion transformer for safety-critical traffic sce- nario generation. arXiv pr eprint arXiv:2506.09485 , 2025. Luo, Y ., Xu, H., Li, Y ., Tian, Y ., Darrell, T ., and Ma, T . Algorithmic framew ork for model-based deep reinforce- ment learning with theoretical guarantees. arXiv pr eprint arXiv:1807.03858 , 2018. Ma, X., Driggs-Campbell, K., and K ochenderfer , M. J. Im- prov ed robustness and safety for autonomous vehicle control with adversarial reinforcement learning. In 2018 IEEE Intelligent V ehicles Symposium (IV) , pp. 1665–1671. IEEE, 2018. Mei, Y ., Nie, T ., Sun, J., and T ian, Y . Bayesian fault in- jection safety testing for highly automated vehicles with uncertainty . IEEE T ransactions on Intelligent V ehicles , 2024. Mei, Y ., Nie, T ., Sun, J., and T ian, Y . Llm-attack er: En- hancing closed-loop adversarial scenario generation for autonomous dri ving with large language models. arXiv pr eprint arXiv:2501.15850 , 2025. Nie, T ., Mei, Y ., T ang, Y ., He, J., Sun, J., Shi, H., Ma, W ., and Sun, J. Steerable adversarial scenario generation through test-time preference alignment. arXiv preprint arXiv:2509.20102 , 2025. Ouyang, L., W u, J., Jiang, X., Almeida, D., W ainwright, C., Mishkin, P ., Zhang, C., Agarwal, S., Slama, K., Ray , A., et al. T raining language models to follow instructions with human feedback. Advances in neural information pr ocessing systems , 35:27730–27744, 2022. Pan, X., Seita, D., Gao, Y ., and Canny , J. Risk averse robust adv ersarial reinforcement learning. In 2019 Inter- national Confer ence on Robotics and A utomation (ICRA) , pp. 8522–8528. IEEE, 2019. Pinto, L., Da vidson, J., Sukthankar , R., and Gupta, A. Ro- bust adv ersarial reinforcement learning. In International confer ence on machine learning , pp. 2817–2826. PMLR, 2017. 10 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Rafailov , R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimiza- tion: Y our language model is secretly a rew ard model. Advances in neur al information pr ocessing systems , 36: 53728–53741, 2023. Ransiek, J., Plaum, J., Langner , J., and Sax, E. Goose: Goal- conditioned reinforcement learning for safety-critical sce- nario generation. In 2024 IEEE 27th International Con- fer ence on Intelligent T ransportation Systems (ITSC) , pp. 2651–2658. IEEE, 2024. Saxena, D. M., Bae, S., Nakhaei, A., Fujimura, K., and Likhachev , M. Driving in dense traf fic with model-free reinforcement learning. In 2020 IEEE International Con- fer ence on Robotics and Automation (ICRA) , pp. 5385– 5392. IEEE, 2020. Scherrer , B. Approximate policy iteration schemes: A com- parison. In International Conference on Mac hine Learn- ing , pp. 1314–1322. PMLR, 2014. Schulman, J., W olski, F ., Dhariwal, P ., Radford, A., and Klimov , O. Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. Stoler , B., Navarro, I., Francis, J., and Oh, J. Seal: T o- wards safe autonomous driving via skill-enabled ad- versary learning for closed-loop scenario generation. IEEE Robotics and Automation Letters , 10(9):9320–9327, 2025. T ang, Y ., Liao, H., Nie, T ., He, J., Qu, A., Chen, K., Ma, W ., Li, Z., Sun, L., and Xu, C. E3ad: An emotion-aware vision-language-action model for human- centric end-to-end autonomous driving. arXiv preprint arXiv:2512.04733 , 2025. T essler , C., Efroni, Y ., and Mannor , S. Action robust rein- forcement learning and applications in continuous control. In International Confer ence on Machine Learning , pp. 6215–6224. PMLR, 2019. T ian, K., Mao, J., Zhang, Y ., Jiang, J., Zhou, Y ., and Tu, Z. Nuscenes-spatialqa: A spatial understanding and reasoning benchmark for vision-language models in au- tonomous driving. arXiv pr eprint arXiv:2504.03164 , 2025. T ian, R., Li, B., W eng, X., Chen, Y ., Schmerling, E., W ang, Y ., Iv anovic, B., and Pa vone, M. T okenize the world into object-lev el knowledge to address long-tail e vents in autonomous driving. arXiv pr eprint arXiv:2407.00959 , 2024. T oromanof f, M., W irbel, E., and Moutarde, F . End-to-end model-free reinforcement learning for urban driving using implicit affordances. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern recognition , pp. 7153–7162, 2020. T u, J., Ren, M., Mani vasagam, S., Liang, M., Y ang, B., Du, R., Cheng, F ., and Urtasun, R. Physically realizable adversarial examples for lidar object detection. In Pr o- ceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pp. 13716–13725, 2020. T u, J., Li, H., Y an, X., Ren, M., Chen, Y ., Liang, M., Bitar , E., Y umer , E., and Urtasun, R. Exploring adversarial robustness of multi-sensor perception systems in self dri v- ing. arXiv preprint , 2021. T uncali, C. E., Fainekos, G., Ito, H., and Kapinski, J. Simulation-based adversarial test generation for au- tonomous vehicles with machine learning components. In 2018 IEEE intelligent vehicles symposium (IV) , pp. 1555–1562. IEEE, 2018. V initsky , E., Du, Y ., Parvate, K., Jang, K., Abbeel, P ., and Bayen, A. Robust reinforcement learning using adversar- ial populations. arXiv preprint , 2020. W achi, A. Failure-scenario maker for rule-based agent using multi-agent adversarial reinforcement learning and its application to autonomous dri ving. arXiv preprint arXiv:1903.10654 , 2019. W ang, J., Pun, A., T u, J., Maniv asagam, S., Sadat, A., Casas, S., Ren, M., and Urtasun, R. Advsim: Generating safety- critical scenarios for self-driving vehicles. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 9909–9918, 2021. W ang, Y ., Luo, W ., Bai, J., Cao, Y ., Che, T ., Chen, K., Chen, Y ., Diamond, J., Ding, Y ., Ding, W ., et al. Alpamayo-r1: Bridging reasoning and action prediction for generaliz- able autonomous dri ving in the long tail. arXiv preprint arXiv:2511.00088 , 2025a. W ang, Y ., Xing, S., Can, C., Li, R., Hua, H., Tian, K., Mo, Z., Gao, X., W u, K., Zhou, S., et al. Generati ve ai for autonomous dri ving: Frontiers and opportunities. arXiv pr eprint arXiv:2505.08854 , 2025b. W u, W ., Feng, X., Gao, Z., and Kan, Y . Smart: Scalable multi-agent real-time motion generation via next-token prediction. Advances in Neural Information Pr ocessing Systems , 37:114048–114071, 2024. Xing, S., Hua, H., Gao, X., Zhu, S., Li, R., T ian, K., Li, X., Huang, H., Y ang, T ., W ang, Z., et al. Au- totrust: Benchmarking trustworthiness in large vision language models for autonomous driving. arXiv preprint arXiv:2412.15206 , 2024. 11 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Xu, C., Petiushko, A., Zhao, D., and Li, B. Dif fscene: Diffusion-based safety-critical scenario generation for autonomous v ehicles. In Proceedings of the AAAI Confer - ence on Artificial Intelligence , volume 39, pp. 8797–8805, 2025a. Xu, R., Lin, H., Jeon, W ., Feng, H., Zou, Y ., Sun, L., Gor- man, J., T olstaya, E., T ang, S., White, B., et al. W od-e2e: W aymo open dataset for end-to-end driving in challeng- ing long-tail scenarios. arXiv preprint , 2025b. Zhang, H., Chen, H., Xiao, C., Li, B., Liu, M., Boning, D., and Hsieh, C.-J. Robust deep reinforcement learning against adversarial perturbations on state observations. Advances in neur al information pr ocessing systems , 33: 21024–21037, 2020a. Zhang, H., Chen, H., Boning, D., and Hsieh, C.-J. Rob ust reinforcement learning on state observ ations with learned optimal adversary . arXiv preprint , 2021. Zhang, J., Xu, C., and Li, B. Chatscene: Knowledge- enabled safety-critical scenario generation for au- tonomous vehicles. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pp. 15459–15469, 2024. Zhang, K., Hu, B., and Basar, T . On the stability and con- ver gence of robust adv ersarial reinforcement learning: A case study on linear quadratic systems. Advances in Neu- ral Information Processing Systems , 33:22056–22068, 2020b. Zhang, L., Peng, Z., Li, Q., and Zhou, B. Cat: Closed- loop adversarial training for safe end-to-end driving. In Confer ence on Robot Learning , pp. 2357–2372. PMLR, 2023. Zhang, Q., Hu, S., Sun, J., Chen, Q. A., and Mao, Z. M. On adversarial rob ustness of trajectory prediction for au- tonomous vehicles. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pp. 15159–15168, 2022. Zhou, W ., Cao, Z., Xu, Y ., Deng, N., Liu, X., Jiang, K., and Y ang, D. Long-tail prediction uncertainty aware trajectory planning for self-driving vehicles. In 2022 IEEE 25th International Confer ence on Intelligent T ransportation Systems (ITSC) , pp. 1275–1282. IEEE, 2022. 12 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving A ppendix The appendix provides rigorous theoretical foundations, supplementary e xperimental results, and detailed implementation specifications that support the main text. W e organize the contents as follows: Section A discusses related work and positions our work in the literature. Section B presents the complete deri v ations and proofs for the theoretical discussion provided in Section 3.4 . W e include additional qualitativ e visualizations and extended quantitati ve results in Section C to complement the main paper . Finally , Section D details the experimental setups, including the dataset, en vironment, baselines, implementations, and hyperparameters for reproducibility . A. Related W ork This section revie ws the literature relev ant to our approach, with a particular focus on autonomous driving (AD). W e position our work at the intersection of three interlea ving pathways: RL, long-tailed scenario handling, and adversarial learning. Reinfor cement learning. RL has been widely studied in AD to enable closed-loop decision-making and address the cov ariate shift inherent in supervised imitation ( Kiran et al. , 2021 ; Chen et al. , 2024 ; Karkus et al. , 2025 ). T raditional approaches hav e largely focused on motion planning and continuous control using vectorized state representations ( Isele et al. , 2018 ; Saxena et al. , 2020 ), or vision-based end-to-end driving within high-fidelity simulators ( Chen et al. , 2019 ; T oromanof f et al. , 2020 ). These methods typically employ actor -critic algorithms, such as PPO and SA C ( Schulman et al. , 2017 ; Haarnoja et al. , 2018 ), to maximize cumulativ e returns based on handcrafted reward functions. Howe ver , reward specification and v alue estimation in complex driving scenarios remain notoriously difficult ( Knox et al. , 2023 ; Chen et al. , 2024 ). T o address the difficulties, recent research has shifted toward alignment techniques emerging from large language models (LLMs). This includes learning from human preferences or feedback to reco ver re ward functions from demonstrations ( Ouyang et al. , 2022 ). More notably , critic-free methods, such as Direct Preference Optimization (DPO) ( Rafailov et al. , 2023 ) and Group Relati ve Policy Optimization (GRPO) ( Guo et al. , 2025 ), are gaining increasing attention. These methods optimize policies directly against preference data or outcomes across rollouts without training unstable value functions, showing promising results in training end-to-end dri ving autonomy ( Jiang et al. , 2025 ; Li et al. , 2025a ; b ). Long-tailed scenario. Handling long-tailed events remains a longstanding challenge for AD deployment and system trustworthiness ( Feng et al. , 2021 ; Liu & Feng , 2024 ; Xing et al. , 2024 ; Chen et al. , 2024 ; W ang et al. , 2025b ). T o mitigate the scarcity of such data in naturalistic dri ving and provide high-value testing samples, significant ef fort has been dev oted to safety-critical scenario generation ( Ding et al. , 2023 ; Li et al. , 2025c ). Representative approaches range from rule-based ( T uncali et al. , 2018 ; Zhang et al. , 2024 ; Mei et al. , 2024 ), optimization-based ( W ang et al. , 2021 ; Hanselmann et al. , 2022 ; Zhang et al. , 2022 ; 2023 ; Nie et al. , 2025 ; Mei et al. , 2025 ), to learning-based methods ( Ding et al. , 2020 ; Kuutti et al. , 2020 ; Feng et al. , 2023 ; Xu et al. , 2025a ; Liu et al. , 2025 ). Despite their success in identifying failures, ef fecti vely inte grating these adversarial generation pipelines into closed-loop training remains an open question: the primary goal of existing methods is often to stress-test the system rather than to improve it. Con versely , a parallel line of research endeav ors to enhance the robustness of decision-making in rare e vents by designing specialized architectures or le veraging the reasoning capabilities of pretrained LLMs/VLMs ( Zhou et al. , 2022 ; Tian et al. , 2024 ; F ang et al. , 2025 ; T ian et al. , 2025 ; Xu et al. , 2025b ; W ang et al. , 2025a ; T ang et al. , 2025 ). Howe ver , adversarial scenario generation and policy improv ement are seldom unified in a holistic frame work. Consequently , the generalizability of these methods to unseen, open-world long-tailed scenarios remains under-in vestigated. Adversarial lear ning. Adversarial training of fers a principled frame work for impro vement-tar geted generation. In the context of robotics and autonomy , adversarial RL has been e xtensi vely discussed for control tasks in constrained settings ( Pinto et al. , 2017 ; Pan et al. , 2019 ; T essler et al. , 2019 ; Zhang et al. , 2020a ; b ; V initsky et al. , 2020 ; Kamalaruban et al. , 2020 ; Zhang et al. , 2021 ). Howe v er , they typically prioritize theoretical analysis within simplified simulation en vironments with controlled noise, which differs significantly from the complexity of real-world dri ving. Within the AD domain, adv ersarial methods hav e mainly targeted the robustness of perception and detection modules against observ ation perturbations ( Boloor et al. , 2019 ; T u et al. , 2020 ; 2021 ; Deng et al. , 2021 ; He et al. , 2022 ; Amirkhani et al. , 2023 ). In contrast, adversarial training for decision-making, particularly regarding long-tailed scenarios, remains underexplored ( Ma et al. , 2018 ; W achi , 2019 ; Anzalone et al. , 2022 ; Zhang et al. , 2023 ; 2024 ). Even among the fe w works addressing this, the generation and training phases are often decoupled. Crucially , they are typically confined to specific policy types or tested against handcrafted adversarial scenarios, which poses significant challenges to their generalizability across di verse and e v olving corner cases. 13 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving B. Theoretical Analysis B.1. Con vergence Analysis In this section, we provide a theoretical guarantee for the con vergence of the ADV-0 framew ork. W e formulate the interaction between the ego agent π θ and the adversary G ψ as a regularized two-player Zero-Sum Marko v Game (ZSMG). Our analysis proceeds in two steps: (1) W e first prove that the inner loop optimization via IPL is mathematically equi valent to solving for the soft optimal adversarial distrib ution subject to a KL-div ergence constraint (Lemma B.1 ). (2) W e then elaborate that the alternating soft updates of the defender and the attacker constitute a contraction mapping, guaranteeing con vergence to the Nash Equilibrium of the game (Theorem B.3 ). B . 1 . 1 . P R E L I M I NA R I E S : A D V - 0 A S A R E G U L A R I Z E D Z ER O - S U M M A R KOV G A M E Formally , we define the discounted ZSMG between the ego and the adversary by the tuple ( S , A , Y , Π , Ψ , P , R , γ ) , where: • The defender (ego agent) chooses a policy π θ ∈ Π : S → ∆( A ) to maximize its e xpected return. • The attack er (adversary) chooses a generative policy G ψ ∈ Ψ : X → ∆( Y ) to produce adversarial trajectories Y Adv ∈ Y , which in turn perturbs the transition dynamics P ψ . The attacker’ s goal is to minimize the defender’ s return. Let the v alue function V π ,ψ ( s ) represent the expecte d return of the ego agent under the dynamics induced by adversary . The robust optimization objecti ve (Eq. 1 ) with the KL-constraint (Eq. 2 , to maintain naturalistic priors) is formulated as finding the saddle point of the regularized v alue function: max π min G ψ J ( π , G ψ ) := E X " E τ ∼ π , P ψ " T X t =0 γ t R ( s t , a t ) # + τ D KL ( G ψ ( ·| X ) ||G ref ( ·| X )) # , (9) where P ψ denotes the transition dynamics modulated by the adversary’ s trajectory Y ∼ G ψ ( ·| X ) , τ > 0 controls the regularization strength. Note that the adversary seeks to minimize the ego’ s return subject to staying close to the prior G ref . The ultimate goal is to find conv erged policies ( π ∗ , ψ ∗ ) satisfy the saddle-point inequality condition of a Nash Equilibrium: J ( π θ , G ψ ∗ ) ≤ J ( π ∗ , G ψ ∗ ) ≤ J ( π ∗ , G ψ ) , ∀ π θ ∈ Π , G ψ ∈ Ψ , (10) implying that neither the defender nor the attacker can unilaterally improv e their objecti ve. B . 1 . 2 . I N N E R L O O P O P T I M A L I T Y V I A I M P L I C I T R E W A R D W e first analyze the inner loop of Algorithm 1 , where the adv ersary’ s polic y G ψ is updated while the ego polic y π θ is held fixed. The core of the inner loop is the IPL objectiv e. W e will sho w that minimizing the IPL loss (Eq. 8 ) is equiv alent to finding the optimal adversarial polic y that solves the KL-regularized re ward maximization problem. Consider the inner loop objectiv e defined in Eqs. 2 and 7 . For a fixed e go policy π θ , the adversary seeks to find an optimal policy ψ ∗ that maximizes the expected risk (minimizes ego return) while remaining close to the reference prior G ref . Let the rew ard for the adversary be defined as r ( Y ) = − J ( π θ , Y ) . The objective is: max ψ J inner ( G ψ ) = E Y ∼G ψ ( ·| X ) r ( Y ) − τ log G ψ ( Y | X ) G ref ( Y | X ) . (11) Lemma B.1 (Closed-form optimality of the Gibbs adversary) . F or a fixed defender π θ and a r efer ence adversary G r ef , the global optimum G ∗ of the KL-constrained objective in Eq. 11 is given by the Gibbs distrib ution: G ∗ ( Y | X ) = 1 Z ( X ) G r ef ( Y | X ) exp − 1 τ J ( π θ , Y ) , (12) wher e Z ( X ) is the partition function. Furthermore , minimizing the IPL loss L IPL (Eq. 8 ) is equivalent to performing maximum likelihood estimation on this optimal policy G ∗ . 14 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Pr oof. The proof consists of two parts. First, we deriv e the closed-form optimal adversarial policy . Let r ( Y ) = − J ( π θ , Y ) be the rew ard for the adversary . Following the deri vation in Raf ailov et al. ( 2023 ), we express the objectiv e using the Gibbs inequality . The objectiv e can be rewritten as maximizing: J inner ( G ) = E Y ∼G r ( Y ) − τ log G ( Y | X ) G ref ( Y | X ) = τ E Y ∼G log exp( 1 τ r ( Y )) + log G ref ( Y | X ) − log G ( Y | X ) = τ E Y ∼G log G ref ( Y | X ) exp r ( Y ) τ − log G ( Y | X ) . (13) Let Z ( X ) = R G ref ( y | X ) exp( r ( y ) /τ ) dy be the partition function. W e can introduce log Z ( X ) into the expectation: J inner ( G ) = τ E Y ∼G log 1 Z ( X ) G ref ( Y | X ) exp r ( Y ) τ − log G ( Y | X ) + log Z ( X ) = − τ D KL ( G ( ·| X ) ||G ∗ ( ·| X )) + τ log Z ( X ) , (14) where G ∗ ( Y | X ) = 1 Z ( X ) G ref ( Y | X ) exp r ( Y ) τ . Since D KL ≥ 0 , the objectiv e is maximized when G = G ∗ , proving the first part of the lemma. This first confirms that our energy-based posterior sampling samples exactly from the optimal adversarial distrib ution. Howe v er , explicitly e v aluating Z ( X ) is intractable. W e next sho w that minimizing the IPL loss L IPL with respect to ψ is consistent with maximizing the likelihood of the preference data generated by the optimal adversary G ∗ , without the need to estimate the partition function. W e show the equiv alence follo wing Rafailo v et al. ( 2023 ). W e can in vert the optimal polic y equation to rewrite the re ward as: r ( Y ) = τ log G ∗ ( Y | X ) G ref ( Y | X ) + τ log Z ( X ) . (15) Under the Bradley-T erry preference model, the probability that trajectory Y w is preferred ov er Y l (i.e., Y w induces lo wer ego return) is giv en by P ( Y w ≻ Y l ) = σ ( r ( Y w ) − r ( Y l )) . Substituting the reparameterized re ward into this model: P ( Y w ≻ Y l ) = σ τ log G ∗ ( Y w | X ) G ref ( Y w | X ) + τ log Z − τ log G ∗ ( Y l | X ) G ref ( Y l | X ) + τ log Z = σ τ log G ∗ ( Y w | X ) G ref ( Y w | X ) − τ log G ∗ ( Y l | X ) G ref ( Y l | X ) . (16) The partition function Z ( X ) cancels out. The IPL loss (Eq. 8 ) is exactly the negati ve log-likelihood of this probability with the parameterized policy G ψ approximating G ∗ . Thus, minimizing L IPL is equiv alent to fitting the optimal adversarial policy G ∗ consistent with the observed preferences. This prov es that the inner loop of ADV-0 effecti v ely solves the constrained optimization problem in Eq. 2 . B . 1 . 3 . G L O BA L C O N VE R G E N C E T O N A S H E Q U I L I B R I U M Having established in Lemma B.1 that the inner loop via IPL effecti v ely recovers the optimal adv ersarial distribution G ψ ∗ , we now analyze the con vergence of the global alternating optimization. W e show that the entire ADV-0 framew ork can be viewed as optimizing a specific rob ust Bellman Operator , which guarantees con vergence to a unique Nash Equilibrium. Before beginning the formal deri v ation, we first establish the following Lemma: Lemma B.2 (Non-e xpansiv eness of Soft-Min) . Let f τ ( X ) ≜ − τ log E Y [exp( − X ( Y ) /τ )] be the Soft-Min oper ator over a random variable Y with temperatur e τ > 0 . F or any two bounded functions X 1 , X 2 , the following inequality holds: | f τ ( X 1 ) − f τ ( X 2 ) | ≤ max Y | X 1 ( Y ) − X 2 ( Y ) | . (17) Pr oof. Let ∆ = max Y | X 1 ( Y ) − X 2 ( Y ) | . By definition, for all Y , the difference is bounded by: X 2 ( Y ) − ∆ ≤ X 1 ( Y ) ≤ X 2 ( Y ) + ∆ . (18) 15 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Multiplying by − 1 /τ and exponentiating yields: exp − X 2 ( Y ) − ∆ τ ≤ exp − X 1 ( Y ) τ ≤ exp − X 2 ( Y ) + ∆ τ . (19) T aking the expectation E Y preserves the inequality . W e can factor out the constant terms exp( ± ∆ /τ ) : e − ∆ /τ E Y [ e − X 2 ( Y ) /τ ] ≤ E Y [ e − X 1 ( Y ) /τ ] ≤ e ∆ /τ E Y [ e − X 2 ( Y ) /τ ] . (20) Next, we apply the strictly decreasing function − τ log ( · ) to all sides. W e ha ve: − τ log e ∆ /τ E [ e − X 2 /τ ] ≤ − τ log E [ e − X 1 /τ ] ≤ − τ log e − ∆ /τ E [ e − X 2 /τ ] . (21) Using the definition of f τ and expanding the terms: f τ ( X 2 ) − ∆ ≤ f τ ( X 1 ) ≤ f τ ( X 2 ) + ∆ . (22) Subtracting f τ ( X 2 ) from all sides, we obtain: − ∆ ≤ f τ ( X 1 ) − f τ ( X 2 ) ≤ ∆ . (23) This is equiv alent to | f τ ( X 1 ) − f τ ( X 2 ) | ≤ ∆ . Theorem B.3 (Contraction and con ver gence to Nash Equilibrium) . Let V be the space of bounded value functions equipped with the L ∞ -norm. The Soft-Robust Bellman Oper ator T r ob : V → V , defined as: ( T r ob V )( s ) ≜ max a ∈A min G ψ ∈ Ψ R ( s, a ) + γ E Y ∼G ψ s ′ ∼P ( ·| s,a,Y ) [ V ( s ′ )] + τ D KL ( G ψ ||G r ef ) ! , (24) is a γ -contr action mapping. Specifically , for any two value functions V , U ∈ V , the following inequality holds: ∥T r ob V − T r ob U ∥ ∞ ≤ γ ∥ V − U ∥ ∞ . (25) Consequently , the iterative updates in ADV-0 con ver ge to a unique fixed point V ∗ . This fixed point corresponds to the value of the unique Nash Equilibrium ( π ∗ , G ψ ∗ ) of the r e gularized zer o-sum game, satisfying the saddle-point inequality: J τ ( π , G ψ ∗ ) ≤ J τ ( π ∗ , G ψ ∗ ) ≤ J τ ( π ∗ , G ψ ) , ∀ π ∈ Π , ∀G ψ ∈ Ψ , (26) wher e J τ ( π , G ψ ) ≜ E π , G ψ [ P γ t R ( s t , a t )] + τ E π [ P γ t D KL ( G ψ ||G r ef )] is the r e gularized cumulative objective. Pr oof. First, we define the soft-rob ust Bellman operator T rob acting on the value function V ∈ R |S | : ( T rob V )( s ) = max a ∈A min G ψ E Y ∼G ψ R ( s, a ) + γ E s ′ ∼P ( s,a,Y ) [ V ( s ′ )] + τ log G ψ ( Y | X ) G ref ( Y | X ) . (27) This operator represents one step of optimal decision-making by the ego agent against a worst-case adversary that is regular - ized by the KL-di ver gence. Note that the inner minimization in T rob corresponds exactly to the dual of the maximization problem in Lemma B.1 (due to the zero-sum sign flip). Next, let V 1 , V 2 ∈ R |S | be two arbitrary bounded value functions. W e aim to show ∥T rob V 1 − T rob V 2 ∥ ∞ ≤ γ ∥ V 1 − V 2 ∥ ∞ . W e simplify the inner minimization problem. Let Q V ( s, a, Y ) = R ( s, a ) + γ E s ′ ∼P ( ·| s,a,Y ) [ V ( s ′ )] . Using the closed-form solution deri ved in Lemma B.1 , the inner minimization over G ψ is equi valent to a LogSumExp (Soft-Min) function. W e define the smoothed value Ω V ( s, a ) as: Ω V ( s, a ) ≜ min G ψ E Y ∼G ψ Q V ( s, a, Y ) + τ log G ψ ( Y | X ) G ref ( Y | X ) = − τ log E Y ∼G ref exp − Q V ( s, a, Y ) τ . (28) 16 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Thus, the operator simplifies to ( T rob V )( s ) = max a Ω V ( s, a ) . Consider the dif ference for any state s : | ( T rob V 1 )( s ) − ( T rob V 2 )( s ) | = | max a Ω V 1 ( s, a ) − max a Ω V 2 ( s, a ) | ≤ max a | Ω V 1 ( s, a ) − Ω V 2 ( s, a ) | . (29) where Eq. 29 follo ws from the non-e xpansiv eness of the max operator (i.e., | max f − max g | ≤ max | f − g | ). Next, we apply Lemma B.2 to the soft-min term Ω V . By identifying X ( Y ) with Q V ( s, a, Y ) , we obtain: | Ω V 1 ( s, a ) − Ω V 2 ( s, a ) | = − τ log E Y [exp( −Q V 1 ( s, a, Y ) /τ )] E Y [exp( −Q V 2 ( s, a, Y ) /τ )] ≤ max Y − τ − Q V 1 ( s, a, Y ) τ + Q V 2 ( s, a, Y ) τ = max Y |Q V 1 ( s, a, Y ) − Q V 2 ( s, a, Y ) | . (30) Substituting the definition of Q V and expanding the e xpectation: = max Y γ E s ′ ∼P ( ·| s,a,Y ) [ V 1 ( s ′ ) − V 2 ( s ′ )] ≤ γ max Y E s ′ [ | V 1 ( s ′ ) − V 2 ( s ′ ) | ] (Jensen’ s inequality) ≤ γ ∥ V 1 − V 2 ∥ ∞ . (Definition of L ∞ -norm) (31) The last two steps utilize the con vexity of the absolute v alue function and bound the local error by the global supremum norm. Since γ ∈ (0 , 1) , T rob is a γ -contraction mapping. By Banach’ s Fix ed Point Theorem, there exists a unique value V ∗ such that T rob V ∗ = V ∗ . Finally , we connect this to the alternating updates in Algorithm 1 . The algorithm performs generalized policy iteration. The inner loop (IPL) solves for the optimal soft adversary via gradient descent on the KL-regularized objecti ve, ef fecti vely ev aluating Ω V π ( s, a ) . The outer loop performs standard RL optimization on the induced robust value function. T essler et al. ( 2019 ) (Theorem 3) and Scherrer ( 2014 ) demonstrate that soft policy iteration con verges to the optimal value if the policy impro vement step is a contraction. Since T rob is a contraction, the sequence of policies ( π k , ψ k ) generated by ADV-0 con ver ges to the Nash Equilibrium ( π ∗ , ψ ∗ ) where π ∗ is optimal against the worst-case re gularized adversary ψ ∗ . B.2. Generalization Bound and Safety Guarantees In this section, we pro vide a theoretical justification of ADV-0 in its generalizability and safety guarantees. W e aim to answer a fundamental question: Does optimizing the policy against a generated adversarial distribution guarantee performance and safety in the r eal-world long-tail distribution? Different from the pre vious section, we no w model the interaction between the ego polic y π θ and the adversarial en vironment as a problem of policy optimization under dynam ical uncertainty . Our goal is to show that optimizing the policy under the adversarial dynamics P ψ (subject to the KL-constraint in the inner loop) maximizes a certified lower bound on the performance in the target real-world long-tail distrib ution P real , leading to a generalization bound (Theorem B.6 ) and a safety guarantee (Theorem B.8 ). Our analysis builds upon the Simulation Lemma from Luo et al. ( 2018 ) and trust-region bounds from Achiam et al. ( 2017 ). Preliminaries. Simply let M = ( S , A , R , γ ) be the shared components of the MDP . W e consider tw o transition dynamics: • P real ( s ′ | s, a ) : The true, unkno wn long-tail dynamics of the real world. • P ψ ( s ′ | s, a ) : The adversarial dynamics induced by the generator G ψ ( ·| X ) . In our context, the state transition is deterministic giv en the background traffic trajectories. Let Y denote the joint trajectory of background agents. The transition function can be written as s ′ = f ( s, a, Y ) . Thus, the stochasticity in dynamics comes entirely from the distribution of Y . Let V π , P ( s ) = E τ ∼ π , P [ P ∞ t =0 γ t R ( s t , a t ) | s 0 = s ] be the v alue function. The expected return is J ( π , P ) = E s 0 ∼ ρ 0 [ V π , P ( s 0 )] . Similarly , let J C ( π , P ) denote the expected cumulativ e safety cost, where C ( s, a ) ∈ [0 , C max ] is a safety cost function (e.g., collision indicator). W e assume the rew ard is bounded by R max , implying the value function is bounded by V max = R max 1 − γ . 17 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving B . 2 . 1 . D I S C R E PA N C Y U N D E R S H I F T E D DY NA M I C S T o analyze performance generalization, we first quantify the discrepancy in e xpected return resulting from the shift from real dynamics to adversarial dynamics. W e in voke the Simulation Lemma ( Achiam et al. , 2017 ) and adapt here to quantify the gap between the adversarial training en vironment and the real world. Lemma B.4 (V alue difference under dynamics shift) . F or any fixed policy π and two transition dynamics P and P ′ , the differ ence in expected r eturn is: J ( π , P ) − J ( π , P ′ ) = γ ∞ X t =0 γ t E s t ∼ π , P ,a t ∼ π h E s ′ ∼P ( ·| s t ,a t ) [ V π , P ′ ( s ′ )] − E s ′ ∼P ′ ( ·| s t ,a t ) [ V π , P ′ ( s ′ )] i . (32) Pr oof. W e use the telescoping sum technique, following Lemma 4.3 in Luo et al. ( 2018 ), Let V P ′ denote V π , P ′ for brevity . Remind that − V P ′ ( s 0 ) = P ∞ t =0 γ t ( γ V P ′ ( s t +1 ) − V P ′ ( s t )) − lim T →∞ γ T V P ′ ( s T ) , we expand the difference as follo ws: J ( π , P ) − J ( π , P ′ ) = E s 0 [ V π , P ( s 0 ) − V π , P ′ ( s 0 )] = E τ ∼ π , P " ∞ X t =0 γ t R ( s t , a t ) # − E s 0 [ V P ′ ( s 0 )] = E τ ∼ π , P " ∞ X t =0 γ t R ( s t , a t ) + ∞ X t =0 γ t ( γ V P ′ ( s t +1 ) − V P ′ ( s t )) − lim T →∞ γ T V P ′ ( s T ) # = E τ ∼ π , P " ∞ X t =0 γ t R ( s t , a t ) + γ V P ′ ( s t +1 ) − V P ′ ( s t ) # . (33) Recall the Bellman equation for V P ′ is V P ′ ( s ) = E a ∼ π [ R ( s, a ) + γ E s ′ ∼P ′ [ V P ′ ( s ′ )]] . Substituting R ( s t , a t ) = V P ′ ( s t ) − γ E s ′ ∼P ′ ( ·| s t ,a t ) [ V P ′ ( s ′ )] into the summation, the term V P ′ ( s t ) cancels out: J ( π , P ) − J ( π , P ′ ) = E τ ∼ π , P " ∞ X t =0 γ t V P ′ ( s t ) − γ E s ′ ∼P ′ [ V P ′ ( s ′ )] + γ V P ′ ( s t +1 ) − V P ′ ( ·| s t ,a t ) ( s t ) # = E τ ∼ π , P " ∞ X t =0 γ t γ V P ′ ( s t +1 ) − γ E s ′ ∼P ′ ( ·| s t ,a t ) [ V P ′ ( s ′ )] # = ∞ X t =0 γ t +1 E s t ∼ π , P a t ∼ π h E s t +1 ∼P ( ·| s t ,a t ) [ V P ′ ( s t +1 )] − E s ′ ∼P ′ ( ·| s t ,a t ) [ V P ′ ( s ′ )] i . (34) Adjusting the index of summation yields the lemma statement. Lemma B.4 suggests that the performance differences depend on the dif ferences of transition dynamics, but in ADV-0 we optimize G ψ , not P ψ directly . T o fill this gap, we establish the connection between the dynamics div ergence and the generator div ergence in the follo wing lemma. Lemma B.5 (Di ver gence bound of the generator) . Let P and P ′ be the transition dynamics induced by the trajectory generator s G and G ′ , r espectively . Specifically , the next state is obtained by a deterministic simulator s ′ = F ( s, a, Y ) , wher e Y is the adver sarial trajectory sampled fr om the g enerator . F or any value function V π , P ′ bounded by V max = R max 1 − γ , the differ ence in expected next-state value is bounded by the T otal V ariation (TV) diverg ence of the generator s: E s ′ ∼P ( ·| s,a ) [ V π , P ′ ( s ′ )] − E s ′ ∼P ′ ( ·| s,a ) [ V π , P ′ ( s ′ )] ≤ 2 V max · E X [ D TV ( G ( ·| X ) ∥G ′ ( ·| X ))] . (35) Pr oof. W e start by explicitly writing the expectation over the next state s ′ as an expectation o ver the generated trajectories Y , i.e., E s ′ ∼P [ V ( s ′ )] = R G ( Y | X ) · V ( F phy ( s, a, Y )) d Y . Let p ( Y | X ) and q ( Y | X ) denote the probability density functions of the generators G and G ′ conditioned on context X . Since s ′ = F ( s, a, Y ) , the expectation can be rewritten via the change 18 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving of variables: ∆ V = E s ′ ∼P [ V π , P ′ ( s ′ )] − E s ′ ∼P ′ [ V π , P ′ ( s ′ )] = Z p ( Y | X ) V π , P ′ ( F ( s, a, Y )) d Y − Z q ( Y | X ) V π , P ′ ( F ( s, a, Y )) d Y , (36) = Z ( p ( Y | X ) − q ( Y | X )) · V π , P ′ ( F ( s, a, Y )) d Y . (37) Next, we apply the integral form of H ¨ older’ s inequality ( | R f ( x ) g ( x ) dx | ≤ R | f ( x ) || g ( x ) | dx ≤ ∥ f ∥ 1 ∥ g ∥ ∞ ). Here, we treat the probability difference as the measure and the v alue function as the bounded term: ∆ V ≤ Z | p ( Y | X ) − q ( Y | X ) | · V π , P ′ ( F ( s, a, Y )) d Y ≤ Z | p ( Y | X ) − q ( Y | X ) | d Y | {z } ∥ p − q ∥ 1 · sup Y V π , P ′ ( F ( s, a, Y )) | {z } ∥ V ∥ ∞ . (38) W e then use two k ey properties: 1. The L 1 norm of the dif ference between two probability distrib utions is twice the T otal V ariation distance: ∥ p − q ∥ 1 = 2 D TV ( p, q ) . 2. The value function is bounded by the maximum possible cumulati ve return: ∥ V ∥ ∞ ≤ V max = R max / 1 − γ . Substituting these back into the inequality , we obtain: ∆ V ≤ 2 D TV ( G ( ·| X ) ∥G ′ ( ·| X )) · V max . (39) T aking the e xpectation over the context distribution X completes the proof. This lemma serves as a crucial bridge in our analysis: it formally translates the div ergence in the high-le vel trajectory generator space (which we explicitly optimize and constrain via IPL) into the div ergence in the lo w-le vel state transition space, thereby allo wing us to bound the error . B . 2 . 2 . A DV E R S A R I A L G E N E R A L I Z A T I O N B O U N D Finally , we present the main theorem. W e sho w that the policy π θ trained by ADV-0 maximizes a lower bound on the performance in real-world distrib ution. IPL loop enforces a KL-constraint between the adversary G ψ and the prior G ref . Theorem B.6 (Lo wer bound of adversarial generalization) . Let π θ be the policy trained under adversarial dynamics P ψ . The expected r eturn of π θ under the r eal-world dynamics P r eal is lower-bounded by: J ( π θ , P r eal ) ≥ J ( π θ , P ψ ) − γ V max √ 2 1 − γ q E X [ D KL ( G ψ ( ·| X ) ∥G r ef ( ·| X ))] . (40) Pr oof. The proof utilizes the established lemmas above. W e first in voke Lemma B.4 with P = P real and P ′ = P ψ : | J ( π , P real ) − J ( π , P ψ ) | ≤ γ ∞ X t =0 γ t E s t ,a t E s ′ ∼P real [ V π , P ψ ( s ′ )] − E s ′ ∼P ψ [ V π , P ψ ( s ′ )] . (41) Giv en that the reference generator G ref is trained on large-scale naturalistic driving logs (WOMD), we assume that the dynamics induced by G r ef serve as a high-fidelity approximation of the r eal-world dynamics P r eal . Consequently , by applying Lemma B.5 with G ′ = G ref , we bound the inner term: E P real [ V π , P ψ ] − E P ψ [ V π , P ψ ] ≤ 2 V max E X [ D TV ( G ref ( ·| X ) ∥G ψ ( ·| X ))] . (42) Substituting this bound back into the summation and using the geometric series sum P ∞ t =0 γ t = 1 1 − γ : J ( π , P real ) ≥ J ( π , P ψ ) − 2 γ V max 1 − γ E X [ D TV ( G ref ∥G ψ )] . (43) 19 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Finally , we utilize the symmetry of the T otal V ariation distance, i.e., D TV ( P ∥ Q ) = D TV ( Q ∥ P ) , to equate D TV ( G ref ∥G ψ ) = D TV ( G ψ ∥G ref ) . W e then apply Pinsker’ s Inequality D TV ( P ∥ Q ) ≤ q 1 2 D KL ( P ∥ Q ) alongside Jensen’ s inequality E [ √ Z ] ≤ p E [ Z ] : E X [ D TV ( G ref ∥G ψ )] = E X [ D TV ( G ψ ∥G ref )] ≤ r 1 2 E X [ D KL ( G ψ ∥G ref )] . (44) Combining these yields the theorem. Remark B.7 . Theorem B.6 theoretically justifies the objective of ADV-0 . The outer loop maximizes the first term J ( π θ , P ψ ) (robustness), while the IPL inner loop minimizes the second term (generalization gap) by constraining the KL div ergence. Thus, our method effecti vely maximizes a certified lo wer bound on the real-world performance. Crucially , P real here represents any target distribution within the δ -trust region of the prior , specifically including the real-world long-tail scenarios. Since the adversary P ψ is optimized to be the worst-case minimizer within this region, the theorem guarantees that the policy’ s performance on the synthetic adversarial cases serves as a rob ust lower bound for its performance on unseen real-world critical e vents. B . 2 . 3 . S A F E T Y G UA R A N T E E I N T H E L O N G TA I L Finally , we deriv e the formal safety guarantee. W e denote J C ( π , P ) the expected cumulati v e cost (e.g., collision risk). Theorem B.8 (W orst-case safety certificate) . Let C max be the maximum instantaneous cost (upper bound of the per-step cost). If the policy π θ satisfies the safety constraint J C ( π θ , P ψ ) ≤ δ under the adversarial dynamics, then the safety violation in the r eal en vir onment is bounded by: J C ( π θ , P r eal ) ≤ δ + γ C max √ 2 (1 − γ ) 2 q E X [ D KL ( G ψ ( ·| X ) ∥G r ef ( ·| X ))] . (45) Pr oof. The proof follo ws similar logic as Lemma B.4 and Theorem B.6 . W e explicitly e xtend Corollary 2 of Achiam et al. ( 2017 ) (which bounds cost performance under policy shifts) to the setting of adversarial dynamics shifts. Formally , we apply Lemma B.4 to the cost value function V π , P C . J C ( π , P real ) ≤ J C ( π , P ψ ) + | J C ( π , P real ) − J C ( π , P ψ ) | ≤ δ + γ 1 − γ ∞ X t =0 (1 − γ ) γ t E s,a [ E P real [ V C ] − E P ψ [ V C ]] . (46) Using Lemma B.5 with ∥ V C ∥ ∞ ≤ C max 1 − γ : J C ( π , P real ) ≤ δ + γ (1 − γ ) · 2 C max 1 − γ E X [ D TV ( G ref ∥G ψ )] . (47) Applying Pinsker’ s inequality again completes the proof. Remark B.9 . Theorem B.8 pro vides a formal safety certificate. It implies that if ADV-0 successfully trains the agent to be safe ( ≤ δ ) against a worst-case adversary P ψ (which is explicitly designed to maximize risk in Eq. 1 ) that is constrained to be physically plausible, the agent is guaranteed to be safe in the naturalistic environment up to a mar gin controlled by the KL div ergence in IPL. B.3. Discussion on Theoretical Assumptions and Practical Implementation The theoretical results established in Sections B.1 and B.2 pro vide the formal motiv ation for ADV-0 , which characterizes the ideal beha vior of the ZSMG. In practice, our implementation in volv es necessary approximations to ensure computational tractability . Here, we discuss the validity of these principled approximations and how the y connect to the theoretical results. In general, ADV-0 solves the theoretical ZSMG via ef ficient approximations. The theoretical analysis identifies what to optimize (min-max objectiv e with KL regularization) and why (maximizing a lower bound on real-world performance), while the practical implementation provides a tractable how (IPL with finite sampling). 20 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Finite sample approximation of the Gibbs adversary . Lemma B.1 deri ves the optimal adversarial distribution as a Gibbs distribution G ∗ ( Y | X ) ∝ G ref ( Y | X ) exp( − J ( π θ , Y ) /τ ) . In the theoretical analysis, the expectation is taken o ver the entire continuous trajectory space Y . In our implementation (Eq. 6 ), we approximate the intractable partition function Z ( X ) and the expectation E Y ∼G ψ using importance sampling with a finite set of K candidates { Y k } K k =1 sampled from the proposal distribution G ψ . While finite sampling introduces variance, the temperature-scaled softmax sampling serves as a Monte Carlo approximation of the theoretical Boltzmann distrib ution. As the sample size K increases, the empirical distribution con ver ges to the theoretical optimal adversary . Since the backbone generator is designed to capture the multi-modal nature of the traf fic prior . A moderate K (e.g., K = 32 ) ef fecti vely co vers the high-probability modes of the prior support, ensuring that the empirical distribution con verges to wards the theoretical Gibbs distrib ution. Proxy r eward and bias. The inner loop optimization relies on the proxy re ward estimator ˆ J rather than the exact rollout return J . This could introduce bias in the gradient direction. Howe ver , we note that the effecti veness of IPL depends primarily on the r anking accurac y rather than the precision of absolute value . Under the B radley-T erry model, the probability of preference depends on the value difference: P ( Y w ≻ Y l ) = σ ( ˆ J ( Y l ) − ˆ J ( Y w )) . The con ver gence requires that the proxy estimator preserves the relativ e ordinality of the true objective, i.e., J ( Y a ) < J ( Y b ) = ⇒ E [ ˆ J ( Y a )] < E [ ˆ J ( Y b )] . This means that as long as the proxy estimator preserves the relativ e ordering of safety-critical events (e.g., correctly identifying that a collision is worse than a near -miss), the gradient direction for ψ remains consistent with the theoretical objectiv e. T rust region assumption in generalization. Theorem B.6 and B.8 rely on the assumption that the real-world dynamics P real lie within a trust region support of the traffic prior G ref . While this is a strong assumption, it is a necessary condition for data-driv en simulation approaches. This formalizes the requirement that the long tail consists of rare b ut plausible e vents, rather than out-of-domain anomalies. In the context of ADV-0 , this assumption is a constraint enforced by the traffic prior . The term E [ D KL ( G ψ ||G ref )] in the generalization bound directly corresponds to the re gularization term in the IPL loss (Eq. 8 ). By minimizing this KL-div ergence during training, ADV-0 explicitly optimizes the policy to maximize the lo wer bound on performance across the entire δ -neighborhood of the naturalistic prior . This ensures that as long as the real-world long-tail ev ents fall within the physical plausibility modeled by the pretrained generator , the safety guarantees hold. 21 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving C. Supplementary T ables and Figures T able 6. Detailed results of safety-critical scenario generation using ADV-0 . AD V -0 V ariation Replay IDM RL Agent CR ↑ Re ward ↓ CR ↑ Rew ard ↓ CR ↑ Reward ↓ Pretrained (logit-based sampling) 31 . 72% ± 1 . 06% 43 . 31 ± 1 . 10 18 . 84% ± 1 . 48% 50 . 66 ± 2 . 22 12 . 49% ± 1 . 06% 52 . 12 ± 2 . 03 Pretrained (energy-based sampling) 85 . 09% ± 1 . 13% 1 . 89 ± 0 . 20 40 . 14% ± 1 . 06% 45 . 72 ± 0 . 47 36 . 30% ± 0 . 77% 41 . 99 ± 0 . 33 GRPO Finetuned 92 . 61 ± 0 . 62% 0 . 87 ± 0 . 06 46 . 34 ± 0 . 73% 39 . 60 ± 0 . 13 41 . 95 ± 0 . 47% 38 . 45 ± 0 . 42 PPO Finetuned 90 . 93 ± 0 . 69% 1 . 01 ± 0 . 07 45 . 09 ± 0 . 63% 40 . 69 ± 0 . 22 39 . 12 ± 0 . 38% 39 . 63 ± 0 . 43 SA C Finetuned 91 . 88 ± 0 . 86% 1 . 03 ± 0 . 08 46 . 09 ± 0 . 19% 39 . 62 ± 0 . 24 41 . 09 ± 0 . 59% 39 . 17 ± 0 . 48 TD3 Finetuned 89 . 54 ± 0 . 62% 1 . 07 ± 0 . 06 46 . 08 ± 0 . 42% 39 . 38 ± 0 . 11 40 . 35 ± 0 . 84% 39 . 68 ± 0 . 72 PPO-Lag Finetuned 90 . 08 ± 0 . 42% 1 . 01 ± 0 . 07 45 . 74 ± 0 . 22% 40 . 50 ± 0 . 09 41 . 30 ± 0 . 50% 38 . 77 ± 0 . 39 SA C-Lag Finetuned 91 . 54 ± 0 . 24% 0 . 95 ± 0 . 04 45 . 61 ± 0 . 31% 40 . 38 ± 0 . 06 40 . 28 ± 0 . 73% 39 . 07 ± 0 . 37 A vg. 91 . 10 ± 0 . 57 % 0 . 99 ± 0 . 06 45 . 83 ± 0 . 42 % 40 . 03 ± 0 . 14 40 . 68 ± 0 . 59 % 39 . 13 ± 0 . 47 T able 7. Cross-validation performances of dri ving agents learned by GRPO. V al. En v . RC ↑ Crash ↓ Reward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.713 ± 0.016 0.177 ± 0.019 45.55 ± 2.21 0.55 ± 0.01 AD V -0 0.687 ± 0.005 0.273 ± 0.025 42.71 ± 0.98 0.64 ± 0.01 CA T 0.695 ± 0.004 0.250 ± 0.022 44.50 ± 0.63 0.60 ± 0.02 SA GE 0.670 ± 0.015 0.270 ± 0.016 42.49 ± 2.16 0.60 ± 0.02 Rule 0.687 ± 0.007 0.207 ± 0.012 42.87 ± 1.25 0.59 ± 0.02 A vg. 0.690 ± 0.009 0.235 ± 0.019 43.62 ± 1.45 0.60 ± 0.02 AD V -0 (w/o IPL) Replay 0.694 ± 0.027 0.183 ± 0.025 42.20 ± 3.21 0.61 ± 0.04 AD V -0 0.667 ± 0.014 0.280 ± 0.024 40.13 ± 1.55 0.67 ± 0.02 CA T 0.667 ± 0.019 0.267 ± 0.026 39.99 ± 2.01 0.67 ± 0.03 SA GE 0.661 ± 0.028 0.240 ± 0.008 40.28 ± 3.31 0.63 ± 0.04 Heuristic 0.666 ± 0.016 0.217 ± 0.048 39.03 ± 1.62 0.64 ± 0.02 A vg. 0.671 ± 0.021 0.237 ± 0.026 40.33 ± 2.34 0.64 ± 0.03 CA T Replay 0.684 ± 0.015 0.197 ± 0.005 41.33 ± 1.32 0.59 ± 0.02 AD V -0 0.641 ± 0.022 0.293 ± 0.042 37.84 ± 1.29 0.69 ± 0.00 CA T 0.646 ± 0.020 0.280 ± 0.036 38.62 ± 1.36 0.68 ± 0.02 SA GE 0.630 ± 0.024 0.313 ± 0.034 38.17 ± 1.55 0.67 ± 0.01 Heuristic 0.630 ± 0.029 0.273 ± 0.033 36.57 ± 1.75 0.67 ± 0.01 A vg. 0.646 ± 0.022 0.271 ± 0.030 38.51 ± 1.45 0.66 ± 0.01 Heuristic Replay 0.694 ± 0.031 0.190 ± 0.010 41.45 ± 3.01 0.61 ± 0.02 AD V -0 0.682 ± 0.068 0.323 ± 0.009 41.45 ± 2.26 0.67 ± 0.04 CA T 0.684 ± 0.022 0.310 ± 0.021 41.89 ± 2.18 0.68 ± 0.04 SA GE 0.661 ± 0.073 0.357 ± 0.014 40.20 ± 1.98 0.67 ± 0.01 Heuristic 0.674 ± 0.029 0.250 ± 0.013 39.72 ± 1.77 0.66 ± 0.02 A vg. 0.679 ± 0.045 0.286 ± 0.013 40.94 ± 2.24 0.66 ± 0.03 Replay Replay 0.680 ± 0.029 0.180 ± 0.044 39.26 ± 0.90 0.61 ± 0.01 AD V -0 0.635 ± 0.042 0.308 ± 0.050 36.64 ± 3.20 0.69 ± 0.01 CA T 0.645 ± 0.055 0.319 ± 0.038 37.48 ± 1.06 0.66 ± 0.01 SA GE 0.616 ± 0.062 0.319 ± 0.032 35.72 ± 1.25 0.69 ± 0.03 Heuristic 0.637 ± 0.047 0.264 ± 0.047 35.77 ± 3.46 0.69 ± 0.02 A vg. 0.643 ± 0.047 0.278 ± 0.042 36.97 ± 1.97 0.67 ± 0.02 T able 8. Cross-validation performances of dri ving agents learned by PPO. V al. En v . RC ↑ Crash ↓ Reward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.707 ± 0.018 0.193 ± 0.015 45.56 ± 0.87 0.56 ± 0.02 AD V -0 0.681 ± 0.021 0.270 ± 0.019 42.68 ± 0.69 0.62 ± 0.03 CA T 0.690 ± 0.010 0.260 ± 0.029 43.65 ± 1.54 0.60 ± 0.04 SA GE 0.678 ± 0.008 0.268 ± 0.023 43.60 ± 1.37 0.59 ± 0.03 Heuristic 0.676 ± 0.006 0.250 ± 0.016 41.63 ± 1.59 0.61 ± 0.03 A vg. 0.686 ± 0.013 0.248 ± 0.020 43.42 ± 1.21 0.60 ± 0.03 AD V -0 (w/o IPL) Replay 0.696 ± 0.010 0.188 ± 0.018 44.80 ± 1.01 0.59 ± 0.01 AD V -0 0.673 ± 0.006 0.280 ± 0.021 42.10 ± 1.34 0.67 ± 0.01 CA T 0.677 ± 0.009 0.275 ± 0.047 42.62 ± 2.00 0.67 ± 0.01 SA GE 0.670 ± 0.013 0.263 ± 0.013 42.96 ± 1.80 0.63 ± 0.03 Heuristic 0.658 ± 0.002 0.265 ± 0.017 39.65 ± 1.10 0.68 ± 0.02 A vg. 0.675 ± 0.008 0.254 ± 0.023 42.43 ± 1.45 0.65 ± 0.02 CA T Replay 0.717 ± 0.013 0.211 ± 0.041 45.40 ± 1.05 0.57 ± 0.03 AD V -0 0.666 ± 0.023 0.330 ± 0.071 40.52 ± 1.85 0.66 ± 0.03 CA T 0.679 ± 0.021 0.319 ± 0.028 42.29 ± 1.53 0.64 ± 0.01 SA GE 0.653 ± 0.008 0.310 ± 0.010 40.53 ± 0.75 0.65 ± 0.01 Heuristic 0.676 ± 0.012 0.270 ± 0.030 41.49 ± 0.70 0.62 ± 0.01 A vg. 0.678 ± 0.015 0.288 ± 0.036 42.05 ± 1.18 0.63 ± 0.02 Heuristic Replay 0.608 ± 0.038 0.210 ± 0.020 37.08 ± 0.91 0.66 ± 0.02 AD V -0 0.577 ± 0.051 0.303 ± 0.050 33.53 ± 0.80 0.74 ± 0.01 CA T 0.593 ± 0.010 0.278 ± 0.015 35.79 ± 2.10 0.70 ± 0.02 SA GE 0.593 ± 0.008 0.270 ± 0.012 36.02 ± 2.00 0.70 ± 0.02 Heuristic 0.563 ± 0.021 0.289 ± 0.020 31.72 ± 1.77 0.72 ± 0.01 A vg. 0.587 ± 0.026 0.270 ± 0.023 34.83 ± 1.52 0.70 ± 0.02 Replay Replay 0.697 ± 0.052 0.229 ± 0.014 44.26 ± 0.55 0.60 ± 0.02 AD V -0 0.629 ± 0.035 0.420 ± 0.030 38.32 ± 1.33 0.73 ± 0.02 CA T 0.663 ± 0.025 0.380 ± 0.048 41.26 ± 1.67 0.68 ± 0.04 SA GE 0.638 ± 0.020 0.360 ± 0.045 41.01 ± 1.90 0.63 ± 0.03 Heuristic 0.620 ± 0.019 0.381 ± 0.032 36.63 ± 1.00 0.72 ± 0.02 A vg. 0.649 ± 0.030 0.354 ± 0.034 40.30 ± 1.29 0.67 ± 0.03 22 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving T able 9. Cross-validation performances of dri ving agents learned by PPO-Lag. V al. En v . RC ↑ Crash ↓ Reward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.676 ± 0.012 0.142 ± 0.015 44.82 ± 1.20 0.53 ± 0.01 AD V -0 0.626 ± 0.008 0.260 ± 0.027 38.17 ± 0.95 0.67 ± 0.02 CA T 0.647 ± 0.013 0.250 ± 0.027 40.80 ± 1.11 0.64 ± 0.02 SA GE 0.632 ± 0.014 0.271 ± 0.018 39.61 ± 1.83 0.65 ± 0.02 Rule 0.638 ± 0.009 0.256 ± 0.019 38.34 ± 1.55 0.68 ± 0.02 A vg. 0.644 ± 0.011 0.236 ± 0.021 40.35 ± 1.33 0.63 ± 0.02 AD V -0 (w/o IPL) Replay 0.605 ± 0.022 0.178 ± 0.028 33.08 ± 2.55 0.74 ± 0.03 AD V -0 0.603 ± 0.018 0.291 ± 0.030 32.78 ± 1.83 0.74 ± 0.02 CA T 0.603 ± 0.023 0.272 ± 0.035 32.56 ± 2.14 0.74 ± 0.03 SA GE 0.585 ± 0.020 0.260 ± 0.025 31.85 ± 2.84 0.72 ± 0.04 Heuristic 0.593 ± 0.020 0.265 ± 0.040 31.80 ± 1.90 0.76 ± 0.02 A vg. 0.598 ± 0.021 0.253 ± 0.032 32.41 ± 2.25 0.74 ± 0.03 CA T Replay 0.625 ± 0.015 0.190 ± 0.005 36.51 ± 1.30 0.68 ± 0.02 AD V -0 0.599 ± 0.022 0.305 ± 0.042 32.91 ± 1.25 0.75 ± 0.01 CA T 0.608 ± 0.020 0.290 ± 0.035 33.82 ± 1.35 0.73 ± 0.02 SA GE 0.590 ± 0.025 0.316 ± 0.035 33.19 ± 1.50 0.74 ± 0.01 Heuristic 0.604 ± 0.028 0.286 ± 0.033 33.09 ± 1.70 0.71 ± 0.01 A vg. 0.605 ± 0.022 0.277 ± 0.030 33.90 ± 1.42 0.72 ± 0.01 Heuristic Replay 0.630 ± 0.030 0.202 ± 0.010 36.82 ± 3.00 0.69 ± 0.02 AD V -0 0.590 ± 0.065 0.333 ± 0.010 33.52 ± 2.20 0.76 ± 0.04 CA T 0.606 ± 0.022 0.324 ± 0.020 34.27 ± 2.15 0.75 ± 0.04 SA GE 0.586 ± 0.070 0.354 ± 0.015 32.56 ± 2.00 0.76 ± 0.01 Heuristic 0.590 ± 0.029 0.290 ± 0.015 32.80 ± 1.80 0.74 ± 0.02 A vg. 0.600 ± 0.043 0.301 ± 0.014 33.99 ± 2.23 0.74 ± 0.03 Replay Replay 0.620 ± 0.030 0.215 ± 0.045 34.53 ± 0.90 0.70 ± 0.01 AD V -0 0.570 ± 0.040 0.364 ± 0.050 30.20 ± 3.20 0.78 ± 0.01 CA T 0.585 ± 0.055 0.358 ± 0.040 31.53 ± 1.10 0.76 ± 0.01 SA GE 0.565 ± 0.060 0.358 ± 0.035 29.80 ± 1.25 0.78 ± 0.03 Heuristic 0.581 ± 0.045 0.320 ± 0.045 30.50 ± 3.40 0.77 ± 0.02 A vg. 0.584 ± 0.046 0.323 ± 0.043 31.31 ± 1.97 0.76 ± 0.02 T able 10. Cross-validation performances of dri ving agents learned by SA C. V al. En v . RC ↑ Crash ↓ Reward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.781 ± 0.011 0.130 ± 0.016 53.66 ± 1.02 0.41 ± 0.01 AD V -0 0.736 ± 0.011 0.305 ± 0.022 49.70 ± 0.34 0.53 ± 0.01 CA T 0.745 ± 0.013 0.268 ± 0.024 50.48 ± 1.02 0.52 ± 0.03 SA GE 0.745 ± 0.016 0.250 ± 0.025 48.84 ± 1.79 0.51 ± 0.04 Heuristic 0.758 ± 0.031 0.170 ± 0.019 50.48 ± 2.79 0.45 ± 0.06 A vg. 0.753 ± 0.016 0.225 ± 0.021 50.63 ± 1.39 0.48 ± 0.03 AD V -0 (w/o IPL) Replay 0.784 ± 0.020 0.160 ± 0.022 54.40 ± 1.69 0.44 ± 0.03 AD V -0 0.706 ± 0.020 0.307 ± 0.026 45.92 ± 2.59 0.58 ± 0.03 CA T 0.729 ± 0.011 0.287 ± 0.026 47.81 ± 1.48 0.58 ± 0.03 SA GE 0.743 ± 0.027 0.260 ± 0.024 49.35 ± 2.73 0.50 ± 0.05 Heuristic 0.743 ± 0.033 0.203 ± 0.034 48.98 ± 3.48 0.49 ± 0.07 A vg. 0.741 ± 0.022 0.243 ± 0.026 49.29 ± 2.39 0.52 ± 0.04 CA T Replay 0.775 ± 0.013 0.177 ± 0.041 54.06 ± 1.12 0.42 ± 0.00 AD V -0 0.698 ± 0.010 0.353 ± 0.034 45.81 ± 0.57 0.60 ± 0.03 CA T 0.704 ± 0.018 0.327 ± 0.041 45.78 ± 1.55 0.60 ± 0.02 SA GE 0.705 ± 0.025 0.297 ± 0.029 46.65 ± 3.41 0.56 ± 0.03 Heuristic 0.727 ± 0.024 0.247 ± 0.038 47.48 ± 2.57 0.53 ± 0.04 A vg. 0.722 ± 0.018 0.280 ± 0.037 47.96 ± 1.84 0.54 ± 0.02 Heuristic Replay 0.718 ± 0.030 0.200 ± 0.028 47.20 ± 4.13 0.54 ± 0.07 AD V -0 0.665 ± 0.025 0.330 ± 0.025 42.10 ± 2.64 0.63 ± 0.02 CA T 0.672 ± 0.024 0.320 ± 0.022 42.50 ± 2.84 0.64 ± 0.03 SA GE 0.670 ± 0.030 0.295 ± 0.030 42.30 ± 3.77 0.60 ± 0.05 Heuristic 0.678 ± 0.028 0.275 ± 0.015 43.10 ± 4.29 0.61 ± 0.05 A vg. 0.681 ± 0.027 0.284 ± 0.024 43.44 ± 3.53 0.60 ± 0.04 Replay Replay 0.710 ± 0.035 0.217 ± 0.035 45.51 ± 1.30 0.56 ± 0.02 AD V -0 0.625 ± 0.045 0.360 ± 0.046 37.81 ± 2.50 0.67 ± 0.03 CA T 0.652 ± 0.035 0.353 ± 0.041 39.20 ± 2.00 0.66 ± 0.04 SA GE 0.635 ± 0.029 0.332 ± 0.040 38.54 ± 2.10 0.64 ± 0.03 Heuristic 0.638 ± 0.027 0.316 ± 0.035 39.09 ± 2.50 0.65 ± 0.01 A vg. 0.652 ± 0.034 0.316 ± 0.039 40.03 ± 2.08 0.64 ± 0.03 250k 500k 750k 1M 40 45 50 55 Reward Reward (Normal) 250k 500k 750k 1M Step 35 40 45 50 Reward Reward (Adversarial) 250k 500k 750k 1M 0.4 0.5 0.6 Cost Cost (Normal) 250k 500k 750k 1M Step 0.55 0.60 0.65 0.70 0.75 Cost Cost (Adversarial) 250k 500k 750k 1M 0.65 0.70 0.75 0.80 Route Completion Route Completion (Normal) 250k 500k 750k 1M Step 0.55 0.60 0.65 0.70 0.75 Route Completion Route Completion (Adversarial) 250k 500k 750k 1M 0.10 0.15 0.20 0.25 0.30 Crash Rate Crash Rate (Normal) 250k 500k 750k 1M Step 0.3 0.4 0.5 Crash Rate Crash Rate (Adversarial) w/ IPL w/o IPL Replay F igur e 10. Learning curves of TD3. 23 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving T able 11. Cross-validation performances of dri ving agents learned by SA C-Lag. V al. En v . RC ↑ Crash ↓ Rew ard ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.787 ± 0.006 0.127 ± 0.017 54.62 ± 0.26 0.40 ± 0.02 AD V -0 0.729 ± 0.002 0.303 ± 0.042 48.78 ± 0.35 0.54 ± 0.03 CA T 0.725 ± 0.011 0.297 ± 0.019 48.01 ± 1.10 0.57 ± 0.02 SA GE 0.736 ± 0.007 0.250 ± 0.024 48.88 ± 0.58 0.52 ± 0.01 Heuristic 0.742 ± 0.022 0.217 ± 0.045 49.25 ± 2.68 0.49 ± 0.06 A vg. 0.744 ± 0.010 0.239 ± 0.029 49.91 ± 0.99 0.50 ± 0.03 AD V -0 (w/o IPL) Replay 0.776 ± 0.009 0.135 ± 0.025 53.75 ± 1.29 0.42 ± 0.02 AD V -0 0.689 ± 0.004 0.320 ± 0.020 44.41 ± 0.98 0.61 ± 0.01 CA T 0.699 ± 0.002 0.320 ± 0.000 45.36 ± 0.43 0.61 ± 0.03 SA GE 0.707 ± 0.009 0.260 ± 0.030 46.63 ± 0.19 0.56 ± 0.02 Heuristic 0.730 ± 0.013 0.205 ± 0.035 47.97 ± 0.34 0.49 ± 0.03 A vg. 0.720 ± 0.007 0.248 ± 0.022 47.62 ± 0.65 0.54 ± 0.02 CA T Replay 0.765 ± 0.015 0.165 ± 0.036 52.80 ± 1.15 0.43 ± 0.01 AD V -0 0.685 ± 0.012 0.345 ± 0.035 44.55 ± 0.61 0.61 ± 0.03 CA T 0.692 ± 0.018 0.320 ± 0.047 44.78 ± 1.50 0.61 ± 0.02 SA GE 0.695 ± 0.025 0.305 ± 0.033 45.87 ± 3.22 0.57 ± 0.03 Heuristic 0.712 ± 0.024 0.255 ± 0.042 46.50 ± 2.52 0.54 ± 0.04 A vg. 0.710 ± 0.019 0.278 ± 0.039 46.90 ± 1.80 0.55 ± 0.03 Heuristic Replay 0.731 ± 0.030 0.193 ± 0.024 48.36 ± 4.17 0.53 ± 0.07 AD V -0 0.677 ± 0.022 0.320 ± 0.024 43.47 ± 2.58 0.62 ± 0.02 CA T 0.686 ± 0.024 0.313 ± 0.021 43.81 ± 2.86 0.63 ± 0.03 SA GE 0.687 ± 0.027 0.283 ± 0.031 43.61 ± 3.71 0.59 ± 0.05 Heuristic 0.691 ± 0.028 0.267 ± 0.012 44.19 ± 4.19 0.60 ± 0.05 A vg. 0.694 ± 0.026 0.275 ± 0.022 44.69 ± 3.50 0.59 ± 0.04 Heuristic Replay 0.718 ± 0.035 0.205 ± 0.034 46.25 ± 1.25 0.55 ± 0.02 AD V -0 0.635 ± 0.047 0.355 ± 0.045 38.80 ± 2.55 0.66 ± 0.03 CA T 0.665 ± 0.033 0.345 ± 0.040 40.15 ± 2.00 0.65 ± 0.04 SA GE 0.645 ± 0.031 0.325 ± 0.040 39.50 ± 2.11 0.63 ± 0.03 Rule 0.650 ± 0.029 0.305 ± 0.036 39.80 ± 2.54 0.64 ± 0.01 A vg. 0.663 ± 0.035 0.307 ± 0.039 40.90 ± 2.09 0.63 ± 0.03 T able 12. Cross-validation performances of dri ving agents learned by TD3. V al. En v . RC ↑ Crash ↓ Reward ↑ Cost ↓ AD V -0 (w/ IPL) Replay 0.787 ± 0.002 0.187 ± 0.031 53.15 ± 0.76 0.43 ± 0.01 AD V -0 0.711 ± 0.016 0.323 ± 0.038 45.54 ± 1.70 0.59 ± 0.03 CA T 0.724 ± 0.016 0.300 ± 0.029 46.67 ± 1.55 0.58 ± 0.02 SA GE 0.734 ± 0.016 0.267 ± 0.046 47.69 ± 1.52 0.53 ± 0.05 Heuristic 0.757 ± 0.021 0.200 ± 0.014 49.87 ± 2.64 0.49 ± 0.02 A vg. 0.743 ± 0.014 0.255 ± 0.032 48.58 ± 1.63 0.52 ± 0.03 AD V -0 (w/o IPL) Replay 0.761 ± 0.031 0.160 ± 0.024 50.21 ± 2.09 0.44 ± 0.01 AD V -0 0.644 ± 0.046 0.423 ± 0.057 40.86 ± 2.90 0.67 ± 0.03 CA T 0.689 ± 0.036 0.373 ± 0.077 45.46 ± 2.04 0.59 ± 0.05 SA GE 0.669 ± 0.049 0.337 ± 0.068 41.95 ± 3.39 0.62 ± 0.05 Heuristic 0.685 ± 0.046 0.277 ± 0.069 43.25 ± 4.07 0.61 ± 0.08 A vg. 0.690 ± 0.042 0.314 ± 0.059 44.35 ± 2.90 0.59 ± 0.04 CA T Replay 0.755 ± 0.013 0.160 ± 0.029 49.03 ± 0.97 0.48 ± 0.01 AD V -0 0.668 ± 0.017 0.367 ± 0.033 42.60 ± 0.23 0.65 ± 0.02 CA T 0.673 ± 0.006 0.343 ± 0.005 42.46 ± 1.60 0.65 ± 0.02 SA GE 0.687 ± 0.016 0.300 ± 0.008 43.99 ± 2.09 0.58 ± 0.01 Heuristic 0.706 ± 0.009 0.237 ± 0.029 45.21 ± 0.88 0.56 ± 0.03 A vg. 0.698 ± 0.012 0.281 ± 0.021 44.66 ± 1.15 0.58 ± 0.02 Heuristic Replay 0.713 ± 0.030 0.210 ± 0.016 45.57 ± 3.01 0.52 ± 0.02 AD V -0 0.632 ± 0.051 0.380 ± 0.010 40.47 ± 2.24 0.65 ± 0.04 CA T 0.661 ± 0.022 0.320 ± 0.020 42.40 ± 2.18 0.61 ± 0.04 SA GE 0.654 ± 0.045 0.315 ± 0.015 42.51 ± 1.99 0.63 ± 0.01 Heuristic 0.652 ± 0.047 0.305 ± 0.022 41.35 ± 1.85 0.60 ± 0.02 A vg. 0.662 ± 0.039 0.306 ± 0.017 42.46 ± 2.25 0.60 ± 0.03 Replay Replay 0.727 ± 0.026 0.210 ± 0.010 47.77 ± 3.00 0.51 ± 0.07 AD V -0 0.638 ± 0.019 0.435 ± 0.005 39.01 ± 2.08 0.67 ± 0.02 CA T 0.643 ± 0.038 0.455 ± 0.015 39.96 ± 3.15 0.69 ± 0.04 SA GE 0.654 ± 0.035 0.340 ± 0.050 41.54 ± 2.42 0.59 ± 0.04 Heuristic 0.700 ± 0.020 0.280 ± 0.010 45.02 ± 1.55 0.56 ± 0.01 A vg. 0.672 ± 0.028 0.344 ± 0.018 42.66 ± 2.44 0.60 ± 0.04 250k 500k 750k 1M 25 30 35 40 45 Reward Reward (Normal) 250k 500k 750k 1M Step 25 30 35 40 45 Reward Reward (Adversarial) 250k 500k 750k 1M 0.5 0.6 0.7 0.8 Cost Cost (Normal) 250k 500k 750k 1M Step 0.6 0.7 0.8 Cost Cost (Adversarial) 250k 500k 750k 1M 0.50 0.55 0.60 0.65 0.70 Route Completion Route Completion (Normal) 250k 500k 750k 1M Step 0.50 0.55 0.60 0.65 0.70 Route Completion Route Completion (Adversarial) 250k 500k 750k 1M 0.15 0.20 0.25 0.30 0.35 Crash Rate (Normal) 250k 500k 750k 1M Step 0.20 0.25 0.30 0.35 0.40 Crash Rate Crash Rate Crash Rate (Adversarial) w/ IPL w/o IPL Replay F igur e 11. Learning curves of GRPO. 24 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving T able 13. Performance comparison of learning-based planners before and after adversarial fine-tuning using AD V -0 (GRPO). Model Phase V al. En v . RC ↑ Crash ↓ Rew ard ↑ Cost ↓ PlanTF (Pretrained) Replay 0.727 ± 0.021 0.220 ± 0.027 41.53 ± 3.10 0.76 ± 0.03 AD V -0 0.581 ± 0.030 0.420 ± 0.035 32.11 ± 2.54 1.24 ± 0.05 CA T 0.615 ± 0.025 0.385 ± 0.030 35.26 ± 2.16 1.09 ± 0.03 SA GE 0.595 ± 0.028 0.407 ± 0.032 33.80 ± 2.80 1.15 ± 0.04 Heuristic 0.620 ± 0.020 0.352 ± 0.032 36.53 ± 1.97 0.94 ± 0.03 A vg. 0.628 ± 0.025 0.357 ± 0.031 35.85 ± 2.51 1.04 ± 0.04 PlanTF (Fine-tuned) Replay 0.738 ± 0.015 0.199 ± 0.018 46.20 ± 1.88 0.62 ± 0.02 AD V -0 0.655 ± 0.012 0.293 ± 0.022 40.80 ± 1.20 0.85 ± 0.00 CA T 0.668 ± 0.010 0.273 ± 0.020 42.11 ± 1.16 0.78 ± 0.01 SA GE 0.640 ± 0.018 0.305 ± 0.025 39.50 ± 1.56 0.88 ± 0.03 Heuristic 0.671 ± 0.024 0.246 ± 0.038 41.28 ± 2.32 0.72 ± 0.05 A vg. 0.674 ± 0.016 0.263 ± 0.025 41.98 ± 1.62 0.77 ± 0.02 A verage Relativ e Change +7.46% -26.23% +17.11% -25.68% SMAR T (Pretrained) Replay 0.686 ± 0.020 0.255 ± 0.023 38.59 ± 3.51 0.83 ± 0.05 AD V -0 0.540 ± 0.035 0.460 ± 0.049 29.80 ± 2.99 1.35 ± 0.04 CA T 0.565 ± 0.031 0.433 ± 0.033 31.50 ± 2.43 1.23 ± 0.05 SA GE 0.556 ± 0.032 0.448 ± 0.038 30.27 ± 3.10 1.30 ± 0.04 Heuristic 0.586 ± 0.029 0.384 ± 0.026 33.16 ± 2.20 1.05 ± 0.07 A vg. 0.587 ± 0.029 0.396 ± 0.034 32.66 ± 2.85 1.15 ± 0.05 SMAR T (Fine-tuned) Replay 0.705 ± 0.010 0.230 ± 0.026 42.13 ± 2.11 0.77 ± 0.01 AD V -0 0.610 ± 0.018 0.340 ± 0.022 36.51 ± 1.56 0.97 ± 0.02 CA T 0.625 ± 0.012 0.313 ± 0.022 37.82 ± 1.40 0.95 ± 0.03 SA GE 0.595 ± 0.020 0.352 ± 0.028 35.20 ± 1.82 1.05 ± 0.03 Heuristic 0.620 ± 0.016 0.292 ± 0.018 37.57 ± 1.63 0.85 ± 0.03 A vg. 0.631 ± 0.015 0.305 ± 0.023 37.85 ± 1.70 0.92 ± 0.02 A verage Relativ e Change +7.57% -22.88% +15.86% -20.31% 0 50 100 150 Estimated Reward 0 50 100 150 200 Real Return Spearman ρ = 0.77 F igur e 12. V alidation of proxy r eward estimator . Comparison of the estimated returns against the ground-truth. The strong Spearman correlation ( ρ = 0 . 77 ) suggests that our rule-based proxy ef fectiv ely preserves the preference ranking of adv ersarial candidates. −20 −15 −10 −5 0 Log-Likelihood (LL) 0.00 0.05 0.10 0.15 0.20 Density LL Distribution Shift During Training 250 k ( μ =-6 .0 8) 500 k ( μ =-7 .5 7) 7 50 k ( μ =-9 .0 4) 1000 k ( μ =- 10.0 7) F igur e 13. Evolution of the adversary distribution . Likelihood of adversarial trajectories at different training steps. As the ego improv es, the distribution shifts to wards lo wer v alues, suggesting that ADV-0 activ ely identifies nonstationary failure boundary . T able 14. Detailed breakdown of the trajectory-level reward model values . V alues represent the average accumulated discounted rew ard (ov er a 2.0s horizon with discount factor γ = 0 . 99 ) of the best planned trajectory selected by the model across all validation steps. Reward components & weights : Progr ess ( w prog = 1 . 0 , longitudinal advance), Collision ( w coll = 20 . 0 , penalty for overlap with objects), Off-road ( w off = 5 . 0 , penalty for lane deviation), Comfort ( w acc = 0 . 1 , w jerk = 0 . 1 , penalties for harsh dynamics), Speed Efficiency ( w eff = 0 . 2 , penalty for deviating from 10m/s). Note that the negati ve improvement in Speed Efficiency reflects a safety-efficienc y trade-off, where the fine-tuned planner adopts a more conserv ati ve velocity profile to satisfy safety constraints. Method Progr ess Collision Off-road Comfort Speed Eff. T otal Score ( + ) ( - ) ( - ) ( - ) ( - ) PlanTF (Pretrained) 14.17 ± 1.53 -2.85 ± 0.92 -0.12 ± 0.05 -0.34 ± 0.08 -0.54 ± 0.12 10.32 ± 1.79 PlanTF (Fine-tuned) 16.45 ± 0.85 -0.89 ± 0.45 -0.05 ± 0.04 -0.24 ± 0.05 -0.64 ± 0.13 14.63 ± 0.97 Improv ement +16.09% +68.77% +58.33% +29.41% -18.52% +41.76% SMAR T (Pretrained) 13.20 ± 1.80 -3.61 ± 1.11 -0.25 ± 0.08 -1.26 ± 0.25 -0.60 ± 0.15 7.48 ± 2.14 SMAR T (Fine-tuned) 15.10 ± 1.10 -1.75 ± 0.37 -0.17 ± 0.05 -0.92 ± 0.19 -0.65 ± 0.11 11.61 ± 1.18 Improv ement +14.39% +51.52% +32.00% +26.98% -8.33% +55.21% 25 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving T able 15. Full results of quantitati ve ev aluation on the unbiased long-tailed set mined fr om real-world data. The benchmark consists of four long-tail scenario categories filtered by strict physical thresholds: Critical TTC ( min TTC < 0 . 4 s ), Critical PET ( PET < 1 . 0 s ), Har d Dynamics (Longitudinal Acc < − 4 . 0 m/s 2 or | Jerk | > 4 . 0 m/s 3 ), and Rare Cluster (topologically sparse trajectory clusters). Reactive T raffic denotes whether background vehicles utilize IDM/MOBIL policies to interact with the agent ( ✓ ) or strictly follow logged trajectories ( × ). Metrics assess Safety Margin (higher values indicate earlier risk detection), Stability & Comf ort (lower Jerk indicates smoother control), and Defensive Dri ving performance, quantified by Near-Miss Rate (hazardous proximity without collision) and RDP V iolation (percentage of time requiring deceleration > 6 m/s 2 to av oid collision). Scenario Category Per centage Reactive T raffic Safety Margin Stability & Comfort Defensive Driving A vg Min-TTC ( ↑ ) A vg Min-PET ( ↑ ) Mean Abs Jerk ( ↓ ) 95% Jerk ( ↓ ) Near -Miss Rate ( ↓ ) RDP V iolation Rate ( ↓ ) AD V -O (w/ IPL) Critical TTC 7.40% ✓ 0 . 645 ± 0 . 122 1 . 450 ± 0 . 50 1 . 853 ± 0 . 188 5 . 850 ± 1 . 252 65 . 28% ± 1 . 45% 15 . 53% ± 4 . 16% Critical PET 3.40% 0 . 492 ± 0 . 025 1 . 150 ± 0 . 20 1 . 623 ± 0 . 095 5 . 157 ± 0 . 653 74 . 57% ± 5 . 52% 58 . 26% ± 3 . 29% Hard Dynamics 3.20% 0 . 885 ± 0 . 157 N/A 1 . 685 ± 0 . 250 4 . 555 ± 0 . 951 55 . 40% ± 8 . 26% 29 . 54% ± 4 . 80% Rare Cluster 5.20% 1 . 951 ± 0 . 450 0 . 850 ± 0 . 25 1 . 451 ± 0 . 143 4 . 650 ± 0 . 684 58 . 55% ± 2 . 12% 31 . 48% ± 2 . 81% A vg 0 . 993 ± 0 . 189 1 . 150 ± 0 . 317 1 . 653 ± 0 . 169 5 . 053 ± 0 . 885 63 . 45 % ± 4 . 34 % 33 . 70 % ± 3 . 77 % Critical TTC 7.40% × 0 . 658 ± 0 . 130 1 . 410 ± 0 . 48 1 . 812 ± 0 . 165 5 . 784 ± 1 . 102 62 . 15% ± 1 . 32% 14 . 80% ± 3 . 83% Critical PET 3.40% 2 . 550 ± 0 . 036 1 . 080 ± 0 . 22 1 . 651 ± 0 . 117 5 . 923 ± 0 . 823 68 . 40% ± 4 . 86% 65 . 13% ± 2 . 56% Hard Dynamics 3.20% 0 . 850 ± 0 . 140 N/A 1 . 525 ± 0 . 380 4 . 421 ± 1 . 259 58 . 11% ± 7 . 52% 30 . 23% ± 3 . 50% Rare Cluster 5.20% 2 . 051 ± 0 . 422 0 . 820 ± 0 . 24 1 . 480 ± 0 . 155 4 . 580 ± 0 . 626 55 . 23% ± 2 . 05% 35 . 63% ± 1 . 51% A vg 1 . 527 ± 0 . 182 1 . 103 ± 0 . 313 1 . 617 ± 0 . 204 5 . 177 ± 0 . 953 60 . 97 % ± 3 . 94 % 36 . 45 % ± 2 . 85 % CA T Critical TTC 7.40% ✓ 0 . 465 ± 0 . 058 1 . 350 ± 0 . 45 2 . 123 ± 0 . 245 6 . 726 ± 1 . 064 81 . 98% ± 3 . 12% 24 . 46% ± 3 . 47% Critical PET 3.40% 0 . 411 ± 0 . 021 0 . 950 ± 0 . 25 1 . 653 ± 0 . 108 4 . 706 ± 0 . 405 91 . 67% ± 3 . 61% 73 . 20% ± 8 . 84% Hard Dynamics 3.20% 0 . 573 ± 0 . 137 N/A 1 . 889 ± 0 . 271 4 . 985 ± 0 . 706 85 . 42% ± 9 . 55% 41 . 04% ± 7 . 71% Rare Cluster 5.20% 1 . 850 ± 0 . 55 0 . 750 ± 0 . 25 1 . 834 ± 0 . 292 5 . 271 ± 1 . 155 73 . 08% ± 7 . 69% 40 . 48% ± 4 . 46% A vg 0 . 825 ± 0 . 192 1 . 017 ± 0 . 317 1 . 875 ± 0 . 229 5 . 422 ± 0 . 833 83 . 04 % ± 5 . 99 % 44 . 80 % ± 6 . 12 % Critical TTC 7.40% × 0 . 469 ± 0 . 058 1 . 310 ± 0 . 40 2 . 168 ± 0 . 206 6 . 871 ± 1 . 149 81 . 08% ± 4 . 68% 24 . 82% ± 3 . 54% Critical PET 3.40% 2 . 850 ± 1 . 10 0 . 910 ± 0 . 30 1 . 818 ± 0 . 085 5 . 876 ± 0 . 869 75 . 00% ± 12 . 50% 87 . 97% ± 4 . 17% Hard Dynamics 3.20% 0 . 559 ± 0 . 091 N/A 1 . 960 ± 0 . 299 5 . 232 ± 0 . 886 81 . 25% ± 6 . 25% 44 . 03% ± 5 . 88% Rare Cluster 5.20% 1 . 780 ± 0 . 60 0 . 720 ± 0 . 28 1 . 969 ± 0 . 182 6 . 028 ± 0 . 820 64 . 10% ± 8 . 01% 47 . 96% ± 5 . 38% A vg 1 . 415 ± 0 . 462 0 . 980 ± 0 . 327 1 . 979 ± 0 . 193 6 . 002 ± 0 . 931 75 . 36 % ± 7 . 86 % 51 . 20 % ± 4 . 74 % Heuristic Critical TTC 7.40% ✓ 0 . 513 ± 0 . 066 1 . 550 ± 0 . 60 2 . 252 ± 0 . 101 6 . 849 ± 0 . 698 81 . 98% ± 1 . 56% 25 . 73% ± 1 . 89% Critical PET 3.40% 0 . 404 ± 0 . 039 1 . 100 ± 0 . 50 1 . 957 ± 0 . 316 6 . 204 ± 0 . 577 85 . 42% ± 3 . 61% 81 . 71% ± 6 . 07% Hard Dynamics 3.20% 0 . 938 ± 0 . 244 N/A 2 . 151 ± 0 . 308 6 . 353 ± 1 . 384 62 . 50% ± 16 . 54% 41 . 41% ± 5 . 35% Rare Cluster 5.20% 1 . 600 ± 0 . 45 0 . 800 ± 0 . 30 2 . 155 ± 0 . 224 6 . 761 ± 1 . 107 67 . 95% ± 2 . 22% 46 . 31% ± 1 . 31% A vg 0 . 864 ± 0 . 200 1 . 150 ± 0 . 467 2 . 129 ± 0 . 237 6 . 542 ± 0 . 942 74 . 46 % ± 5 . 98 % 48 . 79 % ± 3 . 65 % Critical TTC 7.40% × 0 . 503 ± 0 . 061 1 . 480 ± 0 . 55 2 . 229 ± 0 . 054 6 . 945 ± 0 . 891 79 . 28% ± 4 . 13% 26 . 07% ± 2 . 60% Critical PET 3.40% 3 . 550 ± 1 . 50 1 . 050 ± 0 . 45 2 . 103 ± 0 . 171 6 . 449 ± 0 . 485 75 . 00% ± 12 . 50% 88 . 02% ± 2 . 03% Hard Dynamics 3.20% 0 . 833 ± 0 . 190 N/A 2 . 098 ± 0 . 358 6 . 444 ± 1 . 220 64 . 58% ± 7 . 22% 43 . 71% ± 0 . 52% Rare Cluster 5.20% 1 . 520 ± 0 . 40 0 . 750 ± 0 . 35 2 . 366 ± 0 . 288 7 . 273 ± 1 . 668 56 . 41% ± 12 . 36% 50 . 61% ± 1 . 95% A vg 1 . 601 ± 0 . 538 1 . 093 ± 0 . 450 2 . 199 ± 0 . 218 6 . 778 ± 1 . 066 68 . 82 % ± 9 . 05 % 52 . 10 % ± 1 . 77 % Replay Critical TTC 7.40% ✓ 0 . 355 ± 0 . 045 0 . 950 ± 0 . 35 2 . 855 ± 0 . 359 8 . 553 ± 2 . 101 94 . 28% ± 2 . 51% 55 . 69% ± 6 . 27% Critical PET 3.40% 0 . 282 ± 0 . 015 0 . 650 ± 0 . 15 2 . 555 ± 0 . 427 7 . 857 ± 1 . 259 96 . 86% ± 1 . 56% 92 . 54% ± 1 . 85% Hard Dynamics 3.20% 0 . 453 ± 0 . 124 N/A 2 . 951 ± 0 . 550 8 . 200 ± 1 . 655 85 . 49% ± 9 . 55% 68 . 23% ± 8 . 46% Rare Cluster 5.20% 1 . 257 ± 0 . 555 0 . 450 ± 0 . 15 2 . 753 ± 0 . 387 8 . 450 ± 1 . 858 81 . 50% ± 3 . 59% 62 . 47% ± 4 . 50% A vg 0 . 587 ± 0 . 185 0 . 683 ± 0 . 217 2 . 779 ± 0 . 431 8 . 265 ± 1 . 718 89 . 53 % ± 4 . 30 % 69 . 73 % ± 5 . 27 % Critical TTC 7.40% × 0 . 389 ± 0 . 050 1 . 050 ± 0 . 40 2 . 653 ± 0 . 281 8 . 159 ± 1 . 806 91 . 51% ± 2 . 11% 52 . 45% ± 5 . 58% Critical PET 3.40% 1 . 855 ± 1 . 204 0 . 720 ± 0 . 18 2 . 481 ± 0 . 357 7 . 620 ± 0 . 956 88 . 56% ± 4 . 25% 90 . 18% ± 2 . 11% Hard Dynamics 3.20% 0 . 481 ± 0 . 112 N/A 2 . 825 ± 0 . 485 7 . 950 ± 1 . 458 82 . 15% ± 8 . 81% 65 . 57% ± 7 . 25% Rare Cluster 5.20% 1 . 188 ± 0 . 483 0 . 420 ± 0 . 12 2 . 922 ± 0 . 410 8 . 688 ± 1 . 928 78 . 29% ± 3 . 16% 65 . 82% ± 3 . 80% A vg 0 . 978 ± 0 . 462 0 . 730 ± 0 . 233 2 . 720 ± 0 . 383 8 . 104 ± 1 . 537 85 . 13 % ± 4 . 58 % 68 . 50 % ± 4 . 68 % 26 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Left-turn Sudden-brake Cut-in Agent w/o ADV -0 Agent w/ ADV -0 Agent w/o ADV -0 Agent w/ ADV -0 Agent w/o ADV -0 Agent w/ ADV -0 F igur e 14. Qualitative comparison of improv ed safe driving ability after being trained with ADV-0 . W e showcase three typical safety-critical scenarios generated by the adv ersary: Left-turn, Sudden-brake, and Cut-in. In each column, the bottom ro w (Agent w/o ADV-0 ) shows the baseline agent failing to anticipate the aggressi ve beha vior of the background traf fic, resulting in collisions. In contrast, the top row (Agent w/ ADV-0 ) demonstrates that the agent trained with our frame work learns robust defensi ve behaviors, such as yielding at intersections or decelerating in time, thereby successfully av oiding accidents. 0 20 40 0 20 40 0 20 40 0 20 40 0 20 40 0 20 40 A d v e r s a r y Eg o Episode Step Reward Scenario A d v e r s a r y Eg o Episode Step Reward Scenario 0 20 40 0 10 20 0 20 40 0 10 20 0 20 40 0 10 20 F igur e 15. Additional qualitative examples of reward-reduced adversarial scenarios from ADV-0 . In the first case (left), the adversary interrupts the straight-going e go, forcing it to de viate from the lane centerline to a void a crash; this maneuver halts the ego’ s progress, causing the cumulati ve re ward to stagnate. In the second case (right), a collision occurs near the end of the episode, triggering a sharp drop in the cumulativ e rew ard due to the safety penalty . 27 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving D. Detailed Experimental Setups In this section, we provide a comprehensiv e description of the experimental en vironment, datasets, baseline methods, model implementations, and hyperparameter configurations used in our study . Our experimental design follows the protocols established in prior works ( Zhang et al. , 2023 ; Nie et al. , 2025 ; Stoler et al. , 2025 ) to ensure a fair and rigorous comparison. D.1. En vironment and Dataset W aymo Open Motion Dataset (WOMD). W e utilize the WOMD as the source of real-world traf fic scenarios. WOMD is a large-scale dataset containing diverse and complex urban dri ving en vironments captured in v arious conditions. Each scenario spans 9 seconds and is sampled at 10 Hz, capturing complex interactions between vehicles, pedestrians, and cyclists. Follo wing the standard practices in safety-critical scenario generation, we filter and select a subset of 500 scenarios that in volv e interacti ve and complex beha viors. MetaDrive simulator . All experiments are conducted within the MetaDrive simulator ( Li et al. , 2022 ), a lightweight and efficient platform that supports importing real-world data for closed-loop simulation. MetaDri ve constructs the static map en vironment and replays the background traf fic trajectories based on the WOMD logs. The simulation runs at a frequency of 10 Hz. The observ ation space consists of the ego vehicle’ s kinematic state (velocity , steering, heading), navigation information (relati v e distance and direction to references), and surrounding information (surrounding traf fic, road boundaries, and road lines) encoded as a v ector by a simulated 2D LiD AR with 30 lasers and a 50-meter detection range. The action space consists of low-le v el continuous control signals including steering, brake, and throttle. Reward definition. The ground-truth re ward function for the ego agent is designed to balance safety and progression. It is composed of a dense driving re ward and sparse terminal penalties. Formally , the rew ard function R t at step t is defined as: R t = R driving + R success − P collision − P offroad (48) where R driving = d t − d t − 1 represents the longitudinal progress along the reference route, incenti vizing the agent to mov e tow ard the destination. R success = +10 is a sparse re ward granted upon reaching the destination. Safety penalties are applied for terminal failures: P crash = 10 for collisions with vehicles or objects, and P out = 10 for dri ving out of the dri vable road boundaries. Additionally , a small speed reward of 0 . 1 × v t is added to encourage mov ement. The episode terminates if the agent succeeds, crashes, or leav es the dri vable area. For Lagrangian-based algorithms (e.g., PPO-Lag), we define a binary cost function C t which equals 1 if a safety violation occurs and 0 otherwise. D.2. Detailed Implementation D . 2 . 1 . P ROX Y R E W A R D E S T I M A T O R T o efficiently estimate the ego’ s expected return ˆ J ( Y Adv , π θ ) without ex ecuting computationally expensi ve closed-loop simulations during the inner loop, we implement a vectorized rule-based proxy evaluator . This module calculates the geometric interaction between a candidate adv ersarial trajectory Y Adv and a sampled ego response Y Ego from the cached history buf fer . Let Y Ego = { p ego t , ψ ego t } T t =1 and Y Adv = { p adv t , ψ adv t } T t =1 denote the sequences of position and yaw for the ego and adv ersary , respectively . The proxy reward is calculated by mimicking the scheme in MetaDri ve (Eq. 48 ): Collision detection. W e approximate the vehicle geometry using Oriented Bounding Boxes (OBB) defined by the center position, yaw , length l , and width w . For each timestep t , we compute the four corner coordinates of both vehicles. W e employ the Separating Axis Theorem (SA T) to determine if the two OBBs overlap. A collision penalty r crash is applied if an ov erlap is detected at any timestep, and the e valuation terminates early . Route progress and termination. W e map the ego’ s position to the Frenet frame of the reference lane to obtain the longitudinal coordinate s t and lateral deviation d t . The ev aluation terminates if: (1) Success: the longitudinal progress s t /L total > 0 . 95 , granting a reward r success . (2) Off-r oad: the lateral deviation | d t | > 10 . 0 meters, applying a penalty r offroad . 28 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Dense r eward. If no termination condition is met, a dense dri ving rew ard is accumulated based on the incremental longitu- dinal progress ∆ s t = s t − s t − 1 . The total estimated return is the sum of step-wise rewards and terminal bonuses/penalties: R proxy = T end X t =1 ( λ driv e · ∆ s t ) + I crash · r crash + I success · r success + I offroad · r offroad . (49) Once a terminal condition is met, the summation stops, and the cumulativ e v alue is returned. This geometric calculation is fully vectorized across the batch of candidate trajectories, allowing for rapid ev aluation of potential attacks. In our experiments, we set r success = 10 , r crash = − 10 , r offroad = − 10 , and λ driv e = 1 . 0 . Baseline schemes. For the ablation study in Figure 8 , we compare against: (1) Experience: W e query the ego’ s replay buf fer . If the exact scenario context exists, we use the recorded return; otherwise, we retriev e the return of the nearest neighbor scenario based on trajectory similarity . (2) Rewar dModel: W e train a separate learnable reward model M ( X, Y Ego , Y Adv ) via supervised regression on the historical interaction dataset to predict the scalar return. (3) GTRewar d: W e execute the physics engine in a parallel process to roll out the interaction between π θ and the specific Y Adv to obtain the exact return. While our results suggest that rule-based approach is effecti ve, future work could e xplore integrating v alue function approximations (e.g., Q-networks from Actor -Critic architecture) to estimate returns for more complex re ward functions. Context-aware buffer . As noted in Section 3.2 , the validity of the rule-based proxy estimator relies on the geometric consistency between the adv ersarial candidate Y Adv and the ego response Y Ego . Since dif ferent scenarios possess distinct map topologies and coordinate systems, using a global history b uffer w ould lead to physically meaningless calculations. T o address this, we implement the e go history buf fer H ego as a context-inde xed dictionary , mapping each unique scenario ID to a First-In-First-Out (FIFO) queue of its historical ego trajectories: H ego ( X ) = { Y Ego i | X } N i =1 . This ensures that the geometric interaction R proxy ( Y Ego , Y Adv ) is always computed between trajectories residing in the same spatial environment. A key challenge raised by the dynamic training process is handling ne wly sampled contexts X new that hav e not yet been interacted with by the current ego policy , resulting in an empty buffer H ego ( X new ) = ∅ . T o address this, we employ a warm-up rollout before the inner -loop adversarial update begins for a sampled batch of contexts: (1) W e check the b uffer status for each context X in the batch. (2) If H ego ( X new ) = ∅ , we ex ecute a single inference rollout of the current ego polic y π θ in the simulator . Importantly , this rollout is conducted against the non-adversarial replay log. (3) The resulting trajectory Y Ego ref represents the ego’ s baseline behavior in the absence of attacks and is added to H ego ( X ) . This mechanism ensures that the proxy estimator always has a v alid reference to approximate the e go’ s vulnerability , e ven for unseen scenarios. In addition, the proxy estimator al ways calculates geometric interactions between trajectories sharing the same spatial topology . As the training progresses, new interactions under adversarial perturbations are generated and added to the buf fer , gradually shifting the distribution in H ego ( X ) from naturalistic responses to defensi v e responses against attacks. D . 2 . 2 . E V A L UAT I O N A N D B E N C H M A R K Adversarial scenario generation. W e follow the safety-critical scenario generation ev aluation protocol used in Zhang et al. ( 2023 ). For each scenario, the ev aluation presented in T able 1 and T able 6 follows a two-stage process: (1) The environment is reset with a fix ed seed and the ego agent first interacts with the log-replayed en vironment to generate a reference trajectory; (2) The adversarial generator conditions on the context and the ego’ s reference trajectory to generate adversarial trajectories for one selected adversary (which is marked as Object-of-Interests in WOMD). This trajectory is set as a fixed plan for the adversary traf fic in the simulator . For ADV-0 , we employ a worst-case sampling strategy for e v aluation, setting the sampling temperature τ → 0 (Eq. 6 ) to select the trajectory with the highest estimated adversarial utility from K = 32 candidates. W e test against three kinds of driving policies: a Replay policy that follo ws ground truth logs from WOMD, an IDM policy representing reactive rule-based drivers, and RL agents trained via standard PPO on replay logs. These systems under test ex ecute their control loop in the en vironment. The primary metrics are Collision Rate (CR), defined as the percentage of episodes where the ego collides with the adversary , and Ego’ s Return (ER), the cumulativ e reward achiev ed by the ego. For the baselines adv ersarial generators, we utilize their official implementations but adapt them for our ev aluation en vironment to ensure a fair comparison. All of them follow the same ev aluation procedure. For the realism penalty metric in Figure 9 , we adopt the trajectory-lev el measure from Nie et al. ( 2025 ), which discourages trajectories that are physically implausible or exhibit unnatural dri ving beha vior . 29 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Perf ormance validation of lear ned agents. T o rigorously ev aluate the generalizability of the learned AD policies and compare dif ferent adversarial learning methods, we established a cross-validation protocol where each trained agent is tested against multiple distinct scenario generators. For the e v aluation, we utilized a held-out test set of 100 WOMD scenarios that were not seen during training. W e compared five types of agents: those adversarially trained by ADV-0 (with and without IPL), CAT , Heuristic , and a baseline trained solely on Replay data. All these agents are trained using 400 WOMD scenarios. Each agent was ev aluated in fiv e distinct environments with the held-out test set: Replay , ADV-0 , CAT , SAGE , and Heuristic . Note that since SAGE introduces an additional scenario dif ficulty training curriculum, we exclude it for training methods. For each ev aluation run, we used agents saved at the best validation checkpoints and recorded four metrics: Route Completion (RC), Crash Rate (percentage of episodes ending in collision), Reward (cumulative en vironmental re ward), and Cost (safety violation penalty). T o ensure statistical significance, the reported results in T able 2 are av eraged across 6 different underlying RL algorithms (GRPO, PPO, PPO-Lag, SA C, SAC-Lag, TD3) and multiple random seeds. For the specific cross-v alidation in T able 3 , we utilized the TD3 agent and compared the relati ve performance change when the adversary is enhanced with IPL v ersus a pretrained prior equipped with energy-based sampling (Eq. 6 ). Evaluation in long-tailed scenarios. Generated scenarios from adversarial models can be biased and cause a sim-to-real gap for AD policies. T o ensure an unbiased ev aluation of policy rob ustness, we construct a curated ev aluation set by mining additional 500 held-out scene se gments from the W OMD. These scenarios are not shown in the training set. W e employ strict physical thresholds to identify and cate gorize rare, safety-critical ev ents: (1) Critical TTC : scenarios containing frames where the TTC between the e go and an y object drops belo w 0 . 4 s ; (2) Critical PET : scenarios with a Post-Encroachment T ime (PET) lower than 1.0s, indicating high-risk intersection crossings; (3) Har d Dynamics : scenarios inv olving aggressi ve behaviors, defined by longitudinal deceleration exceeding − 4 . 0 m/s 2 or absolute jerk exceeding 4 . 0 m/s 3 ; and (4) Rare Cluster : scenarios belonging to the two lowest-density clusters identified via K-Means clustering ( k = 10 ) on trajectory features for all interacting objects, including curv ature, v elocity profiles, and displacement. During e valuation, we reproduce these scenarios in the simulator and utilize two traf fic modes: a non-reactive mode where background vehicles follow logged trajectories, and a reactiv e mode where vehicles are controlled by IDM and MOBIL policies to simulate human-like interaction with the agent. In addition to safety margin and stability metrics, we also report Near-Miss Rate , defined as the percentage of episodes where TTC < 1 . 0 s or distance < 0 . 5 m without collision, and RDP V iolation , which measures the frequency of violating the Responsibility-Sensiti ve Safety (RSS) Danger Priority safety distances. D . 2 . 3 . A DA P TA B I L I T Y T O D I FF E R E N T R L A L G O R I T H M S This section elaborates on the implementation details regarding the integration of ADV-0 with v arious RL algorithms, as mentioned in Section 3.1 . W e specifically address the synchronization mechanisms and the specialized credit assignment strategy de veloped for critic-free architectures to ensure stable con vergence in safety-critical tasks. RL algorithms. Our framew ork is designed to be algorithm-agnostic, treating the adversarial generator as a dynamic component of the en vironment dynamics P ψ . Consequently , the ego agent percei ves the generated adv ersarial trajectories simply as state transitions, allowing ADV-0 to support both on-policy and off-polic y algorithms. In our experiments, we instantiate the ego policy using six distinct algorithms, cov ering both on-policy and off-policy paradigms, as well as Lagrangian v ariants for constrained optimization: GRPO, PPO, SA C, TD3, PPO-Lag, and SA C-Lag. The primary distinction in implementation lies in the data collection and update scheduling. For on-policy methods (e.g., PPO, GRPO), the training alternates strictly between the adversary and the defender . In the outer loop, we fix the adversary ψ and collect a batch of trajectories B using the current ego policy π θ . The policy is updated using this batch, which is then discarded to ensure that the policy gradient is estimated using the data distrib ution induced by the current adversary . Conv ersely , for off-policy methods (e.g., SA C, TD3), we maintain a replay buf fer D . While the adversary ψ ev olves periodically , older transitions in D technically become off-dynamics data. T o mitigate the impact of non-stationarity , we employ a sliding windo w approach where the replay b uffer has a limited capacity , ensuring that the v alue function estimation relies predominantly on recent interactions with the current or near -current adv ersary . The adv ersary update frequenc y N freq is tuned such that the of f-polic y agent has sufficient steps to adapt to the current risk distribution before the adversary shifts its strategy . This historical div ersity acts as a natural form of domain randomization, pre venting the ego from o verfitting to specific attack patterns. Credit assignment in critic-free methods. While critic-based methods (e.g., PPO) rely on a value function V ( s ) to reduce variance, critic-free methods like GRPO typically utilize sequence-level outcome supervision. In the training of LLMs, it is common to assign the final reward of a completed sequence to all tokens. Howe ver , we identify that dir ectly 30 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving applying this sequence-level supervision to AD tasks leads to sever e credit assignment issues, particularly when addr essing the long-tail distribution . Our experiments rev ealed that applying standard outcome supervision leads to training instability and policy collapse after certain steps. This occurs because safety-critical failures (e.g., collisions) often happen at the very end ( t = T ) of a long-horizon episode. Assigning a low return to the entire trajectory incorrectly penalizes the correct driving behaviors e xhibited in the early stages of the episode ( t ≪ T ), resulting in high-v ariance gradients that disrupt the fine-tuning phase. On the other hand, implementing standard process supervision (e.g., via Monte Carlo v alue estimation across rollouts ( Guo et al. , 2025 )) would require the physical simulator to support resetting to arbitrary intermediate states to perform multiple forward rollouts from ev ery timestep. In complex high-fidelity simulators, this requirement introduces substantial engineering complexities re garding state serialization and incurs prohibitiv e computational ov erhead. T o resolve this, we propose a step-aligned gr oup advanta ge estimator that provides dense step-le v el supervision without requiring a learned critic or simulator state resets. Specifically , for each update step, we sample a scenario conte xt X and generate a group of G independent episodes ( G = 6 in our experiments) starting from the exact same initial state (achie ved via scenario seeding) but with dif ferent stochastic action realizations. Let τ i = { ( s t , a t , r t ) } T i t =0 denote the i -th transition in the group. W e implement the follo wing modifications to the advantage estimation: 1. Calculating retur ns-to-go: Instead of the total episode return, we calculate the discounted return-to-go R t,i = P T i k = t γ k − t r k,i for each step t in transition i . This ensures that an action is only e valuated based on its consequences. 2. Step-aligned group normalization: W e compute the advantage A t,i by normalizing R t,i against the returns of other trajectories in the same group at the same time step t , which uses the peer group as a dynamic baseline: A t,i = R t,i − µ t σ t + ϵ , where µ t = 1 G G X j =1 R t,j , σ t = v u u t 1 G G X j =1 ( R t,j − µ t ) 2 . (50) 3. Baseline padding: Since episodes have v arying lengths (e.g., due to early termination from crashes), the group size at step t could decrease. T o maintain a low-v ariance baseline, we apply zero-padding to terminated trajectories. If trajectory j ends at T j < t , we set R t,j = 0 . This ensures the baseline µ t is always computed o ver the full group size G , correctly reflecting that surviv al yields higher future returns than termination. 4. Advantage clipping: T o prev ent single outliers such as rare failures from dominating the gradient and destabilizing the policy , we clip the calculated adv antages as: ˆ A t,i = clip ( A t,i , − C, C ) , where C = 5 . 0 . Then Eq. 50 is inte grated into the standard GRPO loss and optimized via mini-batch gradient descent. This modification provides an efficient and low-v ariance gradient signal that correctly attributes failure to specific actions leading up to it, without the instability observed in outcome supervision or e xpensiv e state resetting. D . 2 . 4 . A P P L I C A T I O N T O L E A R N I N G - B A S E D M OT I O N P L A N N I N G M O D E L S In this section, we detail the implementation of applying ADV-0 to fine-tune trajectory planning models. Unlike standard end-to-end RL policies that output control actions directly , motion planners output future trajectories which are then executed by a low-le vel controller . This introduces challenges regarding re-planning and rew ard attribution. T o address this, we decouple the planning e valuation from en vironmental execution, inspired by Chen et al. ( 2025 ). Note that this framew ork can be applied to any RL algorithm, and we adopt GRPO as a demonstration. Model architectur es. T o demonstrate the v ersatility of ADV-0 , we apply it to two representati v e categories of state-of- the-art motion planning models: 1. A utor egressiv e generation (SMAR T ( W u et al. , 2024 )): SMAR T formulates motion generation as a next-tok en prediction task, analogous to LLMs. It discretizes vectorized map data and continuous agent trajectories into sequence tokens, utilizing a decoder -only T ransformer to model spatial-temporal dependencies. By autoregressi vely predicting the next motion token, the model ef fectiv ely captures complex multi-agent interactions and has demonstrated potential for motion generation and planning. 31 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving 2. Multimodal Scoring (PlanTF ( Cheng et al. , 2024 )): PlanTF is a T ransformer-based imitation learning planner designed to address the shortcut learning phenomenon often observed in history-dependent models. It encodes the ego v ehicle’ s current kinematic states, map polylines, and surrounding agents using a specialized attention-based state dropout encoder to mitigate compounding errors. This architecture allows the planner to generate robust closed-loop trajectories by focusing on the causal factors of the current scene rather than overfitting to historical observations. PlanTF has achiev ed state-of-the-art in se veral popular motion planning benchmarks. Follo wing the standard pretrain-then-finetune practice, we first apply imitation learning to train supervised policies by behavior cloning. T o deploy these models in closed-loop simulation, we implement a wrapper policy that executes a re-planning cycle e very N = 10 simulation steps (1.0s). At each cycle, the planner receives the current observ ation and generates a trajectory . A PID controller then tracks this trajectory to produce steering and acceleration commands for the underlying physics engine. W e employ an adv anced PID controller with a dynamic lookahead distance to ensure smooth tracking of the planned path. Fine-tuning planners via ADV-0. Directly applying standard RL algorithms to fine-tune trajectory planners is inef ficient due to the sparsity of re wards relati ve to the high-dimensional output space. In addition, the low-le v el controller ex ecuted during a re-planning horizon increases the difficulty of re ward credit assignment. T o address this, we decouple planning ev aluation from execution and implement a state-wise reward model (SWRM) to provide dense supervision directly on the planned trajectories, following Chen et al. ( 2025 ). W e employ GRPO to fine-tune the planners. The process at each re-planning step t is as follo ws: 1. Generation: The planner generates a group of K candidate trajectories { T 1 , . . . , T K } conditioned on the current state s t . For PlanTF , these are the multimodal outputs; for SMAR T , we sample K sequences via temperature sampling. 2. Evaluation: Instead of rolling out K trajectories in the simulator , we e v aluate them immediately using SWRM. SWRM calculates an instant rew ard r k for each T k based on geometric and kinematic properties ov er a horizon H = 2 . 0 s : r ( T k ) = w prog · ∆ long − w coll · I coll − w road · I off − w comf · Jerk , (51) where weights are set to w coll = 20 . 0 , w road = 5 . 0 . 3. Optimization: W e compute the advantage for each candidate as A k = ( r k − ¯ r ) /σ r , where ¯ r and σ r are the mean and standard de viation of rew ards within the group. The policy is updated to maximize the likelihood of high-adv antage trajectories using the GRPO objectiv e: L GRPO = − 1 K K X k =1 min π θ ( T k | s t ) π old ( T k | s t ) A k , clip π θ ( T k | s t ) π old ( T k | s t ) , 1 − ϵ, 1 + ϵ A k . (52) For PlanTF , we fine-tune the trajectory scoring head and decoder; for SMAR T , we fine-tune the token prediction logits. 4. Execution: The trajectory with the highest SWRM score is selected for ex ecution by the PID controller to advance the en vironment to the next re-planning step. For PlanTF , we fine-tune the trajectory scoring head; for SMAR T , we fine-tune the token prediction head. This approach allows the planner to learn from the adv ersarial scenarios generated by ADV-0 by explicitly penalizing trajectories that the SWRM identifies as risky , without requiring dense en vironmental feedback. Adversarial interaction. The ADV-0 adversary operates in the inner loop as described in the main paper . The adversary generator G ψ creates challenging scenarios based on the planner’ s executed history , and is further updated via IPL. The planner is then fine-tuned via GRPO to propose safer trajectories in response to these generated risks. D.3. Baselines W e compare ADV-0 against a comprehensi ve set of baselines, categorized into adv ersarial scenario generators (methods that create the en vironment) and closed-loop adversarial training frame works (methods that train the e go policy). 32 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving Backbone model. Consistent with prior works ( Zhang et al. , 2023 ; Nie et al. , 2025 ; Stoler et al. , 2025 ), we employ DenseTNT ( Gu et al. , 2021 ) as the backbone motion prediction model for the adversarial generator . DenseTNT is an anchor-free, goal-based motion forecasting model capable of generating multimodal distributions of future trajectories, which is known for its high performance on the WOMD benchmark. W e initialize the generator using the publicly av ailable pretrained checkpoint, ensuring a fair comparison of the generation capabilities. Adversarial generators. T o ev aluate the ef fecti veness of the generated scenarios, we compare ADV-0 against a compre- hensiv e set of adversarial generation methods, cov ering optimization-based, learning-based, and sampling-based paradigms: • Heuristic ( Zhang et al. , 2023 ): A hand-crafted baseline that modifies the trajectory of the background vehicle to intercept the ego v ehicle’ s path using Bezier curve fitting. It heuristically generates aggressiv e cut-ins or emer gency braking maneuvers based on the ego vehicle’ s position. This serves as an oracle method representing worst-case physical attacks. • CA T ( Zhang et al. , 2023 ): A state-of-the-art sampling-based approach that generates adversarial trajectories by resampling from the DenseTNT traf fic prior . It selects trajectories that maximize the posterior probability of collision with the ego v ehicle’ s planned path. • KING ( Hanselmann et al. , 2022 ): A gradient-based approach that perturbs adversarial trajectories by backpropagating through a differentiable kinematic bic ycle model to minimize the distance to the ego v ehicle. • AdvT rajOpt ( Zhang et al. , 2022 ): An optimization-based approach that formulates adversarial generation as a trajectory optimization problem. It employs Projected Gradient Descent (PGD) to iteratively modify trajectory waypoints to induce collisions. • SEAL ( Stoler et al. , 2025 ): A skill-enabled adversary that combines a learned objectiv e function with a reactiv e policy . It utilizes a scoring network to predict collision criticality and ego beha vior de viation. • GOOSE ( Ransiek et al. , 2024 ): A goal-conditioned RL framework. The adversary is modeled as an RL agent that learns to manipulate the control points of Non-Uniform Rational B-Splines (NURBS) to construct safety-critical trajectories. • SA GE ( Nie et al. , 2025 ): A recent preference alignment frame work that fine-tunes motion generation models using pairs of trajectories. It learns to balance adversariality and realism, allowing for test-time steerability via weight interpolation between adversarial and realistic e xpert models. Adversarial training framew orks. T o demonstrate the ef fectiv eness of our closed-loop training pipeline, we compare ADV-0 with the following training paradigms. All methods use the same outer-loop e go policy training structure but dif fer in how the training en vironment is generated and how the inner and outer loops are inte grated: • Replay (w/o Adversary): The ego agent is trained purely on the original log-replay scenarios from W OMD without any adv ersarial modification. This serves as a lo wer bound for performance. • Heuristic training: The ego agent is trained against the Heuristic rule-based generator described abo ve. • CA T : The state-of-the-art closed-loop training framework where the e go agent is trained against the CA T generator . The generator selects adv ersarial trajectories based on collision probability against the latest ego policy b ut does not update its policy via preference learning during the training loop. • AD V -0 w/o IPL: An ablation variant of ADV-0 where IPL is removed and the adversary is not fine-tuned. It relies solely on energy-based sampling from the pretrained backbone. This isolates the contribution of the e volving adv ersary . For fair comparison, all adversarial training methods (CA T , ADV-0 , etc.) utilize the same curriculum learning schedule regarding the frequenc y and intensity of adversarial encounters. Note that we explicitly exclude comparisons with standard adversarial RL frame works, such as RARL ( Pinto et al. , 2017 ; Ma et al. , 2018 ) or observation-based perturbation methods ( T essler et al. , 2019 ; Zhang et al. , 2020a ) due to tw o ke y factors: (1) They primarily focus on perturbations to observations or state vectors. In contrast, ADV -0 targets beha vioral robustness by altering the transition dynamics via trajectory generation. 33 ADV-0 : Closed-Loop Min-Max Adversarial T raining for Long-T ail Robustness in A utonomous Driving (2) Standard adversarial RL models the adversary as an agent with a low-dimensional action space. Our setting in volv es noisy real-world traf fic data and the adversary outputs high-dimensional continuous trajectories. Training a standard RL adversary from scratch to generate effecti v e trajectories in this noisy en vironment is computationally intractable and fails to con ver ge in our preliminary experiments. D.4. Hyper parameters W e provide the detailed hyperparameters used in our experiments to f acilitate reproducibility . T able 16 lists the parameters for the various RL algorithms used to train the ego agent. T able 20 details the hyperparameters for the ADV-0 framew ork, including the IPL fine-tuning process and the min-max training schedule. T able 16. Hyperparameters for different RL algorithms used in the experiments. T able 17. TD3 Hyper -parameter V alue Discount Factor γ 0.99 Batch Size 256 Actor Learning Rate 3e-4 Critic Learning Rate 3e-4 T arget Update τ 0.005 Policy Delay 2 Exploration Noise 0.1 Policy Noise 0.2 Noise Clip 0.5 T able 18. SAC & SA C-Lag Hyper -parameter V alue Discount Factor γ 0.99 Batch Size 256 Learning Rate 3e-4 T arget Update τ 0.005 Entropy α 0.2 (Auto) Cost Coefficient 0.5 SA C-Lag Specific Cost Limit 0.3 Lagrangian LR 5e-2 T able 19. PPO, PPO-Lag & GRPO Hyper -parameter V alue Discount Factor γ 0.99 Batch Size 256 Learning Rate 3e-5 Update T imestep 4096 Epochs per Update 10 Clip Ratio 0.2 GAE Lambda λ 0.95 Entropy Coef ficient 0.01 V alue Coefficient 0.5 Algorithm Specific Cost Limit (PPO-Lag) 0.4 Lagrangian LR (Lag) 5e-2 Group Size (GRPO) 6 KL Beta (GRPO) 0.001 T able 20. Hyperparameters for ADV-0 Framework and IPL Fine-tuning. Module Parameter V alue Backbone (DenseTNT) Hidden Size 128 Sub-graph Depth 3 Global-graph Depth 1 T rajectory Modes ( K ) 32 NMS Threshold 7.2 IPL Fine-tuning Learning Rate 5e-6 T emperature ( τ ) 0.05 Optimizer AdamW Scheduler CosineAnnealing Gradient Accumulation Steps 16 Pairs per Scenario 8 Rew ard Margin 5.0 Spatial Div ersity Threshold 2.0 m Min-Max Schedule (RARL) Adversary Update Frequency Every 5 Ego Updates Adversary T raining Iterations 5 Epochs per Block Adversary T raining Batch Size 32 Scenarios Adversarial Sampling T emperature 0.1 Max T raining T imesteps 1 × 10 6 Opponent T rajectory Candidates 32 Ego History Buffer Length 5 Min Probability (Curriculum) 0.1 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment