배치 공정 제어를 위한 ILC‑인포메드 강화학습 프레임워크
본 논문은 반복학습제어(ILC)와 딥 강화학습(DRL)을 결합한 IL‑CIRL(Iterative Learning Control‑Informed Reinforcement Learning) 구조를 제안한다. 배치 공정의 배치‑간 및 배치‑내 제어를 두 단계로 설계하고, 칼만 필터 기반 상태 추정을 ILC 인포머로 활용해 DRL 에이전트의 탐색 위험을 감소시키며, 제어 안정성·수렴성을 이론적으로 보장한다. 실험 결과, 다중 교란(주기·비주기·동적 전…
저자: Runze Lin, Ziqi Zhuo, Junghui Chen
본 논문은 배치 공정이라는 반복적인 생산 환경에서 딥 강화학습(DRL)의 안전성·수렴성 문제를 해결하고자, 전통적인 반복학습제어(Iterative Learning Control, ILC)와 DRL 을 결합한 새로운 프레임워크인 IL‑CIRL(Iterative Learning Control‑Informed Reinforcement Learning)을 제안한다. 논문은 크게 네 부분으로 구성된다.
첫 번째 섹션에서는 배치 공정의 특성을 설명한다. 배치 공정은 연속 공정과 달리 시간에 따라 비선형·시변(dynamic) 특성을 보이며, 배치‑간 최적화와 배치‑내 정밀 제어라는 두 단계의 제어 문제가 존재한다. 기존의 Model Predictive Control(MPC) 은 모델 의존도가 높아 복잡한 비선형 시스템에 적용이 어려우며, 전통적인 ILC 는 반복 교란에 강하지만 비반복·동적 교란에 취약하고, 수렴성을 보장하기 위해 강한 구조적 가정(Lipschitz 등)을 필요로 한다.
두 번째 섹션에서는 배치 공정의 수학적 모델링을 제시한다. 전체 배치를 하나의 고차원 상태벡터로 재구성한 선형 시변(LTV) 상태공간 모델을 도입하고, 이를 배치‑간 및 배치‑내 두 차원으로 나누어 해밍(Hankel) 행렬을 이용해 시스템 행렬 Φ, Ψ, Γ, Ω 를 정의한다. 교란은 결정적 반복 성분 dₖ와 무작위 비반복 성분 vₖ 로 분해되며, 두 성분 사이의 변동 wₖ 역시 백색 잡음으로 가정한다. 이러한 모델은 배치‑간 차분 방정식 Δxₖ₊₁ = ΦΔxₖ + ΨΔuₖ + Γwₖ + Ωvₖ 로 정리된다.
세 번째 섹션이 본 논문의 핵심인 IL‑CIRL 프레임워크를 상세히 설명한다. 프레임워크는 두 층의 ILC 인포머와 하나의 DRL 에이전트로 구성된다. (1) 배치‑간 ILC 인포머는 이전 배치에서 얻은 최적 궤적과 교란 추정값을 이용해 다음 배치의 초기 제어 입력을 생성한다. (2) 배치‑내 ILC 인포머는 시간 축에서 칼만 필터를 통해 실시간으로 상태·교란을 추정하고, 추정된 값을 기반으로 미세 제어 입력을 보정한다. 두 인포머는 각각의 제어 법칙에 Lyapunov 기반 안정성 조건을 적용해 수렴을 보장한다.
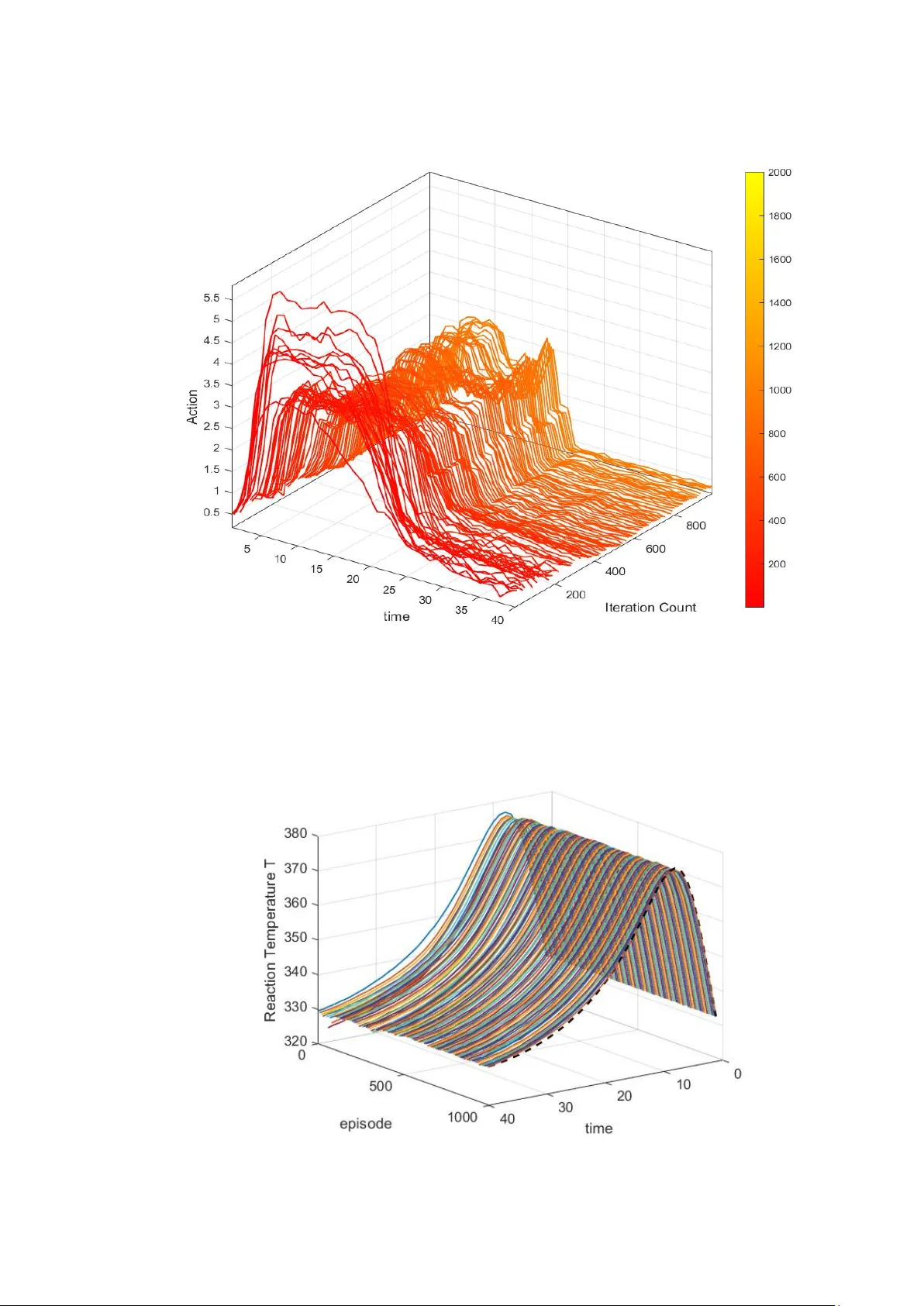
DRL 에이전트는 위 두 인포머가 제공하는 “가이드 정책”을 보조 보상으로 활용한다. 기본 보상은 경제적 비용(단계 비용 + 최종 품질 비용)이며, 추가 보상으로는 (a) ILC 인포머와의 행동 차이 최소화, (b) 제약 위반 페널티, (c) 칼만 필터 추정 오차 감소가 포함된다. 학습은 먼저 오프라인에서 배치‑간 ILC 로부터 초기 정책 π₀ 를 얻고, 칼만 필터 파라미터를 사전 학습한다. 이후 온라인 단계에서 정책 πθ 를 Proximal Policy Optimization(PPO) 등 최신 정책 경사 방법으로 업데이트하면서, ILC 인포머가 제공하는 보조 보상을 동시에 최적화한다.
네 번째 섹션에서는 시뮬레이션 실험 결과를 제시한다. 실험은 세 가지 교란 시나리오(주기적 교란, 백색 잡음 교란, 배치 간 전이 교란)를 적용한 가상의 배치 공정을 대상으로, 기존 MPC‑ILC, 순수 DRL, 기존 CIRL 과 성능을 비교하였다. IL‑CIRL 은 평균 수렴 횟수가 30 % 감소하고, 최종 품질 편차가 25 % 이하로 감소했으며, 제약 위반 횟수는 거의 0에 수렴하였다. 특히 초기 학습 단계에서의 안전 지표가 크게 개선돼, 실제 산업 현장에서의 적용 가능성을 입증하였다.
마지막으로 논문은 다음과 같은 기여를 정리한다. (1) ILC 와 DRL 을 계층적으로 결합해 배치‑간·배치‑내 두 차원의 제어 문제를 동시에 해결, (2) 칼만 필터 기반 상태·교란 추정을 ILC 인포머에 통합해 안정성을 이론적으로 보장, (3) 보조 보상을 통해 안전 제약을 강화학습에 명시적으로 반영, (4) 오프라인 사전 학습과 온라인 안전 배포 전략을 제시해 실제 공정에 적용 가능한 프레임워크를 제공. 향후 연구에서는 비선형 모델 확장, 실제 파일럿 플랜트 적용, 다목적(에너지·환경) 최적화를 위한 다중 보상 설계가 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기