Iterative Learning Control-Informed Reinforcement Learning for Batch Process Control
A significant limitation of Deep Reinforcement Learning (DRL) is the stochastic uncertainty in actions generated during exploration-exploitation, which poses substantial safety risks during both training and deployment. In industrial process control,…
Authors: Runze Lin, Ziqi Zhuo, Junghui Chen
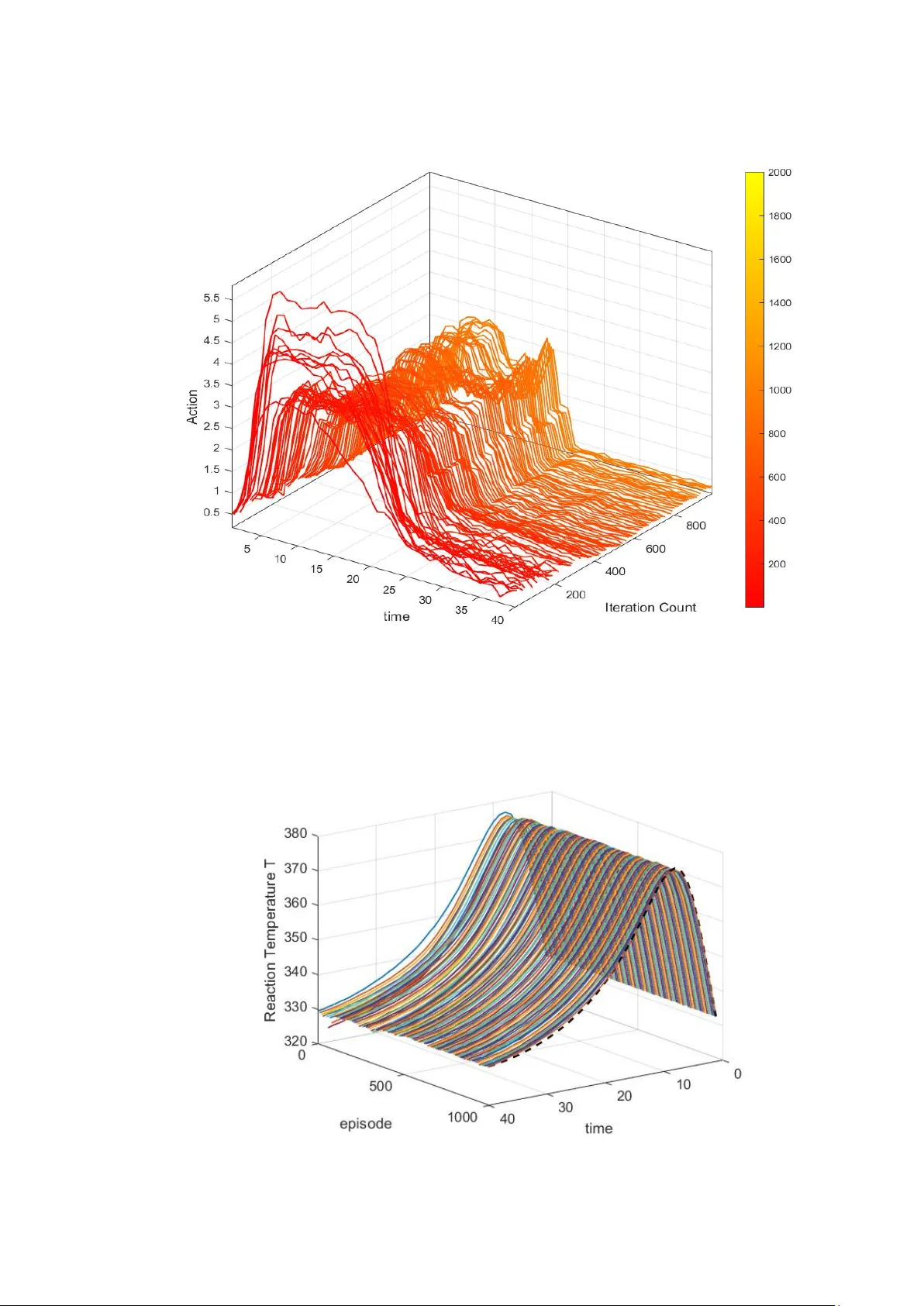
1 / 39 Iterative Learning Contr ol-Informed Reinfor cement Learning for Batch Pr ocess Contr ol Runze Lin 1, , Ziqi Zhuo 1, , Junghui Chen 2,* , Lei Xie 1 ,* , Hongye Su 1 1 State Key La boratory of Industrial Control T echnology , Institute of Cyber-Systems and Control, Zhejiang University , Hangzhou 310027, China 2 Department of Chemical Engineering, Chung-Y uan Christian University , T aoyuan 32023, T aiwan, R.O.C. The two authors contributed equally to this work. * Corresponding authors. Abstract: A significant limitation of Deep Reinforcement Learning (DRL) is the stochastic uncertainty in actions g enerated during exploration-exploitation, which poses substantial safety risks during both training and deployment. In industrial process control, the l ack of formal stability and conver gence guarantees further inhibits adoption of DRL methods by practitioners. Conversely , Iterative Learning Control (ILC) represents a well -established autonomous control methodology for repetitive systems, particularly in batch process optimization. ILC achieves desired control performance through iterative refinement of control laws, either between consecutive b atches or within indi vidual batches, to compensate for both repetitive and non-repetitive dist urbances. This stud y int roduces an Ite rative Learning Control-Informed Reinforcement Learning (IL-CIR L) framework for training DRL controllers in dual-layer batch - to -batch and withi n-batch control architectures for bat ch processes. The proposed method incorporates K alman fil ter -based state estimation within the iterative learning structure to gu ide DRL agents toward control policies that satisfy operational constraints and ensure stability guarantees. This approach enables the systematic design o f DRL controllers for batch processes operating under multiple disturbance conditions. Keywords : Iterative Le arning C ontrol, Reinforcement Learning, Batch Process Control, Deep Reinforcement Learning, Control-Informed Learning, Industrial Process Control 2 / 39 1 Introduction In the process industry , batch manufacturing r epresents a critical production methodology widely deployed across sectors vital to e conomic development and public we lfare, including chemicals, ph armaceuticals, food processing, and materials synthesis [1, 2 ]. These processes constitute essential technical infrastructure for producing high -value-added, multi-variety , small-batch products. Applications such as specialty chemical pre paration, antibiotic manufacturing, functional food processing, and advanced composite material synthesis depend extensively on ba tch processes to meet demanding product specifications and quality requirements. Despite t heir importance, batch process optimization pr esents significant technical challenges. Unlike continuous processes, ba tch systems require control architectures capable of managing non linear dynamics and time -varying behaviors, optimizing production trajectories across successive batches, and maintaining precise trajectory tra cking within individual batches [3]. Consequently , batch process opti mization encompasses two distinct control problems: inter-batch process optimization and intra-batch precision control. Developing robust control strategies that ef fectively handle dist urbances both between batches (batch- to -batch) and within individual batches (wi thin-batch) while ensuring system stability and efficiency across va rying production conditions represents a fundamental c hallenge in this field. T raditional ba tch process control methods, such as Model Predictive Control (MPC) and Iterative Learning Control (ILC), have demonstrated significant effectiveness in industrial applications [4 -13]. MPC optimizes batch proce ss performance by solving model-based optimal control problems; however , its reliance on precise mathematical models limits its applicability to highly nonlinea r or complex systems [14, 15]. Conversely , ILC enhances control performance in repetitive tasks by itera tively learning from previous batch exec utions to mitigate proc ess disturbanc es and conver g e toward de sired trajectories. Nevertheless, conventional ILC approaches exhibit limitations when confronted with dynamic environmental variations or nonlinear stochastic disturbances. Despite the incr easing maturity of ILC theory , control for strongly nonlinear sy stems remains a core bottleneck : existing ILC methods mostly rely on structural assumptions or Lipschitz conditions, making it diffic ult to adapt to complex non linear scenarios without prior information and lacking a universal design framework [16]. W ith the rapid advance ment of machine lea rning a nd artific ial intelligenc e, particular ly reinforcement learning ( RL), data-driven adaptive control methods have garnered significant 3 / 39 attention in batch process optimization [4, 17-24]. RL dynamically optimizes control poli cies through trial-and-error interaction with the environment, demonstrating robustness in unknown or dif ficult- to -model syst ems. However , RL training typically requires extensive random exploration, particularly during early stages, whic h may compromise system stability or pose safety hazards. In process industries, where production environments are inherently complex and potentially hazardous, reliance sol ely on R L exploration mechanisms could result in una cceptable control errors and sa fety concerns. Consequently , developing RL -based batch process control policies that maintain safety guarantees represents a critical research challenge. Bloor e t a l. [25] recently proposed a Control-Informe d Reinfor cement Learning (CIRL) method for chemical p rocesses that integrates the strengths of PID control and deep reinforcement learning (DRL) to enhance control performance, robustness, and sample ef ficiency . This approach represents a customized framework that embeds s pecific controller structures to guide the RL training process. However , their method depe nds on predeter mined neural network architectures (e.g., PID -style neural networks) as the controller structure. While this design is well-suited for scenarios with known controllers, it presents challenges for generaliza tion to broader control applications. In batch processes characterized by significant noise interference, this f ramework may inadequ ately address st ringent control accuracy and stability requirements, as it lacks the capability to dyna mically ada pt the controller ’ s internal structure to miti gate th e amplification ef fects of n oise on derivative operations. T o address the dual chal lenges of safety risks arising from random explo ration in RL agents and the extensive real-world iterations required for conver gence, this paper proposes a control-informed learning and adaptation approach that integra tes ILC with RL, ter med Iterative L earning C ontrol-Informed Reinforcement Learning (IL -CIRL). IL-CIRL leverages domain knowledge of batch process dynamics to guide the R L-based controller ’ s learning process under multiple complex disturbances, including both periodic and non-periodic disturbances as well as continuous dynamic mode transitions in batch processes. By synthesizing ILC principles with RL [26], IL-CIRL transforms RL from a purely exploration- dependent bla ck-box process into a structured learning framework that progressively enhan ces model accuracy and control stability . This approac h enables intelligent optimiza tion control of batch processes while m aintaining safety and stability constraints, thereby establishing a novel paradigm for continuous adaptive optimization control. Specifically , IL -CIRL employs a hierarchical ILC informer based on Kalman filter [26, 27] state estimation within the iterative 4 / 39 learning framework [10, 28] to derive a control law that satisfies system constraints and ensures stability . This control law subsequently guides the learning process of the RL agent. W ithin this hierarchical ILC architecture, the Kalman filter serves a dual p urpose: it provides real-time estimation of process disturbances while simultaneously delivering accurate system state feedback to the RL agent. This dual functionality mitigates safety risks associated with random exploration and enables th e agent to accurately capture process states in complex environments characterized by dynamic behavior , nonlinearity , and varying operating conditions. Furthermore, the ILC-based two-layer hierarchical contr ol strategy systematically guides the RL agent toward asymptotic conver gence while enabling progressive optimization of the control policy . This paper makes the following key contributions: 1. In tegration of ILC and RL for batc h process optimization. The proposed I L-CIRL framework represents a pioneering effort to incorporate control informati on into RL training processes. This integration provides a novel approach to batch process optimization that avoids unsafe exploration while guaranteeing convergence. 2. Real-time state estim ation using Kalman filte ring. A Kalman filter-based state estimation method is developed to enable the R L agent to accurately capture process states in dynamic and nonli near environments, th ereby facilitating optimized control strategies. 3. E nhanced robustness through ILC-informed reinforcement learning. By integrating ILC-guided strategies with RL, various disturbances and inherent syst em nonlinearities in batch processes are effectively addressed, l eading to significant improvements in overall optimization and control performance . 4. S afe deployment strategy for real-world implementation. Safety in practical batch process control is ensured through offline pre -training with a hierarchical I LC informer and online safe im plementation based on a w eighted fusion strategy. This approach enables a secure transition to RL-based end- to -end control. The remainder of this paper are structured as follows: Section 2 presents the background, challenges, and problem definition of batch process control, while analyzing and describing the disturbance characteristics of batch pro cesses; S ection 3 details the framework desi gn of the IL-CIRL algorithm, including the ba tch- to -batch and within-batch ILC control laws based on Kalman filters and th e IL -CIRL algorithm process; Section 4 provides the experimental design and results analysis; Section 5 summarizes the k ey contributions of this study and proposes future research directions. 5 / 39 2 Problem statement 2.1 Overview of batch process models Batch processes differ fu ndamentally from continuous chemical processes in that they exhibit distinct multi-phase or multi -stage t ransient characteristics. At th e batch level, these processes display time-varying nonlinear behavior that varies with ope rating conditions. Consequently , conventional state-space models based on linear time-invariant (L TI) systems are inadequate for capturing the dynamic modal behavior of batch processes [29]. This study employs a linear time-varying (L TV) mod el to characterize the process dynamics of a batch process operating along it s entire optimal nominal trajectory . The mod el is expressed as follows: ( 1 ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) k k u k d k k k k k k k t t t t t t t t t t t t t t t + = + + =+ =+ x A x B u B d z F x m y C x n (1) where k denotes the batc h index, and 0: T t I is the time index within the k -th batch, () x n k t x , () u n k t u , () d n k t d , () z n k t z , and () z n k t z respectively represent the system state, control action, process disturbance, observation signal, and product quality at time , () t A , () u t B , () d t B , () t F , and () t C are the time-varying dynamic matrices in the L TV state-space model, () z n k t m and () y n k T n are the measurement noises of the observation variable and quality va riable, respectively , assumed to be white noises , i.e., 2 ( ) ( , ) km N t m0 and 2 ( ) ( , ) kn N T n0 . Product quality in batch process es is typically not measured in real-time. Instead, quality measurements are obtained only after batch completion through laboratory analysis. Consequently , terminal product quality , () k T y , is the more relevant metric for b atch process optimization and control. The corresponding time-varying matrix is denoted as () T C . Given that Eq.(1) still pre sents the syste m in a time-scaled state-space for m, it i s necessary to reformulate the model in to a more compact representation suitable for batch- oriented optimization and control. Specifically , the state-space model ca n be expr essed as follows: 6 / 39 (0) ( ) ( ) k k u k d k k k k k k k TT = + + = + = + x x u d z x m y x n (2) where the system states, inputs, disturbance s, observations, and mea surement noise s are reformulated as one-dimensional vectors representing the entire batch , with their specific definitions given as follows: ( 1 ) ( 2) ( ) , (0) ( 1 ) ( 1 ) , (0) ( 1 ) ( 1 ) , ( 1 ) (2) ( ) , ( 1 ) ( 2) ( ) T T T T k k k k T T T T k k k k T T T T k k k k T T T T k k k k T T T T k k k k T T T T T = =− =− = = x x x x u u u u d d d d z z z z m m m m (3) The Hankel matrices for the system state, system input, and system output, as defined in Eq.(3) , are calculated as follows: ( ) 1 0 (0) ( 1 ) (0) , () diag ( 1 ) ( 2) ( ) , () T i i T T − = = = = A AA A F F F 0 C (4) 11 01 (0) 0 0 ( 1 ) (0) ( 1 ) 0 ( ) (0) ( ) ( 1 ) ( 1 ) (0) ( 1 ) ( 1 ) u uu u TT u u u ii u u u i i T T −− == = − = − B A B B A B A B B (5) 11 12 (0) 0 0 ( 1 ) (0) ( 1 ) 0 ( ) ( 0) ( ) ( 1 ) ( 1 ) (0) ( 1 ) ( 1 ) d dd d TT d d d ii d d d B A B B A i B A i B B T T −− == = − = − (6) T ypically , the economic opti mization objectives for batch processes during o peration c an 7 / 39 be divided int o two components: stage cost and terminal cost, which are calculated as follows: 1 0 ( , ) ( ( ), ( )) ( ( )) T t V l t t Q T − = =+ x u x u y (7) where : xu nn l → represents the o peration al cost incurred at each ti me instant before the completion of the batc h, and : y n Q → denotes the e conomic cost associated with the terminal product quality at the end of the batch. According to the hie rarchical control architecture commonly a dopted in process industries, the optimization control problem fo r batch processes is typically addressed in multiple layers. The upper-layer Real-Time Optimization (R TO) module solves the economic optimization problem while considering constraints such as system dynamics and parameter bounds. The resulting nomi nal optimal trajectory , nom nom ) , ( xu , is then provided as a re ference tr ajectory to lower-layer controller s such as Model Predictive Control (MPC) and Proportional -Integral-Derivative (PID) schemes. In practical implementation, the L TV state-space model described in Eq.(1) is linearized along the reference trajec tory . By using the batch-wise state-space model in Eq.(2) and the economic objective function in Eq. (7), the optimal control law is continuously computed and updated for each batch in accordance with the predefined economic objectives. 2.2 Analysis and description of disturbance characteristics of batch processes T raditional batch process control schemes, such as IL C, are typically designed for scenarios characterized by fixed int er -batch disturbances. These methods utili ze disturbance information from previous batches to itera tively optimize control inputs for subsequent batches. However , when addressing random uncertainties within a batch, it is essential to consider disturbance ch aracteristics along the t emporal axis. Specifically , batch process disturbances c an be classified according to their properties: deterministi c repetitive disturbances, random non -repetitive disturbances , and random variations of deterministic disturbances across adjacent batches. Given that process disturbances comprise both deterministic/repetitive and random/non-repetiti ve components, analyzing the correlation between disturbances and process dynamics is necessary . It is assumed that the disturbances in a batch p rocess consist of a superposition of deterministic and random disturbances, described as follows: k kk =+ d d v (8) where (0) ( 1 ) ( 1 ) T T T T k k k k T = − d d d d represents the di sturbance v ector composed 8 / 39 of process disturbances at all time instants of the - th k batch, (0) ( 1 ) ( 1 ) T T T T k k k k T = − d d d d denotes the unknown deterministic/repetitive component of th e pr ocess disturbance, and (0) ( 1 ) ( 1 ) T T T T k k k k T = − v v v v corresponds to the random or non- repetitive component. The det erministic disturbances across batch es may exhibit slight random variations, and the dist urbances in adj acent batches may also change randomly . This relationship can be described a s follows: 1 kk k + =+ d d w (9) where 1 k + d re presents t he deterministic dist urbance of the next batch, and (0) ( 1 ) ( 1 ) T T T T k k k k T = − w w w w denotes the random varia tion in the deterministic process disturbance between adjacent batches. Both dist urbances 0: 1 ( ), kT tt − wI and 0 : 1 ( ), kT tt − vI in Eqs.(8) and (9) are assumed to be white noises, with distributions denoted by 2 ( ) ~ ( , ) kv tN v0 and 2 ( ) ~ ( , ) kw tN w0 , respectively . 2.3 Reconstructing the batch- to -batch state-space mod el in the batch direction Modeling the state-space formulation across batche s is relatively straightforward. I t simply re quires substituting the disturbance terms from Eq.( 8) into the batc h-wise state-space model given in Eq.(2). Accordingly , the state-space representation for batch k can then be rewritten as follows: (0) ( ) k k k u k d k = + + + x x u d v (10) Similarly , the state-space representation for batch 1 k + can be expressed as: 1 1 1 1 1 (0) ( ) k k k u k d k + + + + + = + + + x x u d v ( 11 ) By applying a dif ference operation to the above state-space models, the incremental state- space representations, the incremental state-space model can be formulated as: 1 1 1 1 ( (0) (0 ) ) ( ) k k u k k k d k k k + + + + = + + − + + − x x u x x w v v (12) Assuming that the initial state fluctuations 1 (0 ) (0) kk + − xx between adjacent batches are random variables, their effect on the state dimini shes over time . Consequently , the third term in Eq.(12) can be neglected, leading to the following simplified expression: 1 1 1 () k k u k d k k k + + + = + + + − x x u w v v (13) This incremental state-space model does not explicitly include the process disturbance k d 9 / 39 from Eq.(2) ; instead, it is reformulated to incor porate the corresponding random variable 11 k k k −− +− w v v . Accordingly , the state-s pace representation for batch k can be rewritten as: 1 1 1 () ( ) ( ) ( ) k k u k d k k k k k k k k k T T T − − − = + + + − = + =+ x x u w v v z x m y C x n (14) 2.4 Reconstructing the within-batch state-space model in the time direction Since batch processes exhibit dynamic chara cteristics in both the batch and time directions, relying solely on the batch-level state-space model described in Eq. (14) may fail to account for transi ent disturbances oc curring wit hin a batch. This oversight could result in control errors that compromise the optimal control performance of subsequent batches. Therefore, it is essential to develop a within-batch state-space model that captures the dynamics along the time direction. T o this end, Eq.(14) m ust be reformulated in a form suitable for within -batch ILC, explicitly representing th e influence o f control signals at each time step on the system state. The state-space model can then be expressed as: 11 1 1 1 00 ( ) ( ) ( )( ( ) ( ) ( )) TT k k u k d k k k ii i i i i i i −− − − − == = + + + − xx Ψ u Ψ w v v (15) where i denotes the time instant within a batch, and the incremental state change between adjacent batches is the superposition of contributions from all ti me instants 0 ,1 , i T = to the system dynamics. If only the contribution s of the control input s up to the current time instant t are conside red, i.e., ( ) ( 1 ) ( 1 ) k k k t t T = + = = − = u u u 0 , the cumulative state response to time t can be defined as ; () hk t x , which is calculated as follows: 11 ; 1 1 1 00 ( ) ( ) ( ) ( ) ( ( ) ( ) ( )) tt h k k u k d k k k ii t i i i i i i −− − − − == = + + + − x x u w v v (16) Similarly , the state of the entire ba tch at time 1 t + can be written as: ; 1 1 1 00 ( 1 ) ( ) ( ) ( )( ( ) ( ) ( )) tt h k k u k d k k k ii t i i i i i i − − − == + = + + + − x x u w v v (17) By taking the difference betwee n Eqs.(16) and ( 17 ), the original batch-wis e state-space model can be reformulated as an incremental state-space representation along the time axis, given by: ; ; 1 1 ( 1 ) ( ) ( ) ( ) ( )( ( ) ( ) ( )) h k h k u k d k k k t t t t t t t t −− + = + + + − x x u w v v (18) 10 / 39 Corresponding to the incrementa l state descripti on of ; () hk t x above, the incremental form of the control trajectory for the entire batch at time t is defined as: ;1 ( ) (0 ) ( 1 ) T T T T T h k k k k Tt t t t − − = + − u u u u 0 0 (19) Accordingly , the incremental forms of the control trajectory at time 1 t + and at the terminal time T can be written as: ;; 1 ( 1 ) ( ) ( ) T T T T T T h k h k k t T t t t t −− + = + u u 0 0 u 0 0 (20) ;; 1 ;; ( ) ( ) ( ) ( 1 ) ( 1 ) ( ) ( ) T h k h k k k k t Tt h k h k T t t t T tt −− = + + − = + u u 0 0 u u u uu (21) where ; () hk t u is defined as ; ( ) [ , ( ) ( 1 ) ( 1 ) ] T T T T T T h k k k k t Tt t t t T − = + − u 0 0 u u u . Consequently , the state prediction from the current time t to the terminal time T can be calculated as follows: 1 ;; ;; ( ) ( ) ( ) ( ) ( ) ( ) T h k h k u k it h k u h k T t i i tt − = = + = + x x u xu (22) 3 Methodology 3.1 Framework for control-informed reinforcement learning in batch processes via iterative learning control T o address the p ractical c hallenges asso ciated with RL -based controllers, inc luding safety hazards arising from random exploration during interaction with industrial plants, and the need for extensive iterations before conver gence, thi s s tudy proposes a n iterative learning control- informed re inforcement learning (I L-CIRL) framework. The goa l of IL-CIRL is to provide an autonomous learning pa radigm that ensures safety and asymptotic conver gence for batch process optimization control. The IL-CIRL framework incorporates a learning g uidance mechanism based on Kalman filter -enhanced ILC. The ILC generates constr aint-compliant control outputs with provable 11 / 39 conver gence guarantees , providing robust supe rvision signals for the RL agent. During the pre-training process, the Kalman filter serves as a dual function: it deli vers progressively refined state estimates of process disturbances to the RL agent while simultaneously providing an optimized dynamic m odel, refined both batch- to -batch and withi n-batch , to the hier archical ILC informer . This archit ecture enables the coordinated iteration betw een high-level tr ajectory optimization and low-level control synthesis, maintaining performance across diverse disturbance categories, including repetitive and non-repetitive uncertainties, as well as deterministic/stochastic variation s. The overall a rchitecture of the IL-CIRL approach is il lustrated in Fig . 1. The IL -CIRL framework comprises two primary components: a hierarchical ILC informer and a DRL a gent. The hierarchical ILC informer employs a cascade control structure to decompose the batch process c ontrol problem into two dimensions: within-batch c ontrol (temporal axis) and ba tch- to -batch control (batch axis). Both sub-ILC informers utilize Kalman filtering to mitigate process disturbances originating from multiple sources. The DRL agent is algorithm -agnostic and can b e implemented using various RL algorithms; in this study , proximal policy optimization (PPO) is utilized. Fig. 1 Overall framework of the proposed IL-CIRL algorithm . It is important to note that IL -CIRL emplo ys distinct objectives and structural configurations for the o ffline pre -training and onli ne fine-tuning phases. During offline pre- 12 / 39 training, the framework emphasizes control-informed policy learning, wherein the hierarchical ILC informer , constructed using a L TV dynamic model, provides reference control trajectories. At this stage, the DRL agent’ s primary objective is to replicate the control actions generated by the informer . Conversely , the onli ne training phase prioritizes safety -guaranteed control - informed adapt ation. In this phase, the DR L agent and hierarchical ILC informer collaboratively generate hybrid control actions, enablin g the DRL agent to p rogressively refine its imi tation-based policy . As training advance s, the weighting assigned to the informer decreases systematically , and control authority gradually transfers to the DRL agent until autonomous operation is achieved. The IL-CIRL framework incorporates ILC and disturbance information into the controller training procedure to guide the RL agent toward safe and progressively converge nt control behaviors during both batch- to -batch (episode-level) and withi n-batch (time-step-level) exploration. The key features of IL-CIRL are as foll ows: 1. Integration of ILC structure. The framework integrates an ILC structure int o the training process, enabling control-informed reinforcement learning fo r batch process optimization. 2. Dual-layer ILC controller design. A Kalman filter-based dual -layer ILC controller operates at both the batch - to -batch and within -batch levels, guaranteeing pro gressive convergence and providing safe ty-assured guida nce for offline pre -training and online execution. 3. Disturbance handling. The fr amework addresses disturbances o f varying characteristics (r epetitive/non-repetitive, deterministic/stochastic) by leveraging Kalman filtering to mitiga te model-plant mi smatch in I LC, thereby transforming the uncertainty-induced perturbation problem into a state estimation problem. 4. Offline pre-training capability. During offline pre-training, the within-batch Kalman filter provides r eal-time state estimation to the RL agent, eliminating the need for direct interaction with the actual industrial proce ss. 5. Adaptive online execution strategy. During online execution, an adaptive weighting strategy is employed whereby the control signal is initially generated jointly by the hierarc hical I LC a nd RL agent. The we ight gra dually shifts toward the RL component as trainin g stabilizes, ultimately yielding a fully RL-based end- to - end controller without compromising safety. 3.2 Control-inform ed policy learning d uring offline pre- training process es 3.2.1 The proposed offline pre-training scheme A primary challenge in applying RL to industrial control systems is its dependence on 13 / 39 stochastic exploration d uring training, which can result in unsafe or unpredictable control actions. In batch proc ess optimization, pa rticularly during early tra ining stages, such beha vior poses significant risks, including proc ess instability and unacceptable operational hazards. T o mitigate these concerns, the IL-CIRL framewor k implements a control-informed policy learning strategy during offline pre-training. This approach leverages the complementary strengths of ILC and RL to establish a safe learning p aradigm that eliminates hazardous exploration prior to deployment in real-world processes. During offline pre -training, the IL-CIRL ag ent operates independently of the actual industrial syst em. Instead, it learns a p reliminary policy within a simulated environment, where ILC-based control information serves as a critical bridge to the previously obtained L TV dynamic model. Specifically , the K alman filter-based control-informed learning mechanism provides the RL agent with a stable, asymptotically conver gent dynamic model for agent-environment interactions. The Kalman filter continuously estimates process disturbances and generates state feedback to align the RL agent’ s actions with those of the hierarchical ILC controller , thereby guiding the pre -trained RL agent’ s act ion output toward optimal performance. This mechanism ef fectively integrates the convergence and stability guarantees of Kalman filter-based ILC into the RL training process. Fig. 2 illustrates how hierarchical ILC functions as an expert controller , providing control information to guide the IL -CIRL ag ent during of fline pre-training. Fig. 2 Schemat ic diagram of control-i nformed policy l earning duri ng off line pre-tr aining processes The primary objective of this control -informed guidance strat egy is to mitigate exploration-related risks by providing accurate syst em dynamics information, thereby establishing a stable pre-training environment for policy optimization. Additionally , the Kalman filter enhances training reliability by iteratively refining the syst em’ s predictive model 14 / 39 to deliver precise state estimates for RL. This approach prevents unstable behaviors arising from model-plant mismatch or process disturbances. Consequ ently , control information enables the RL agent to progressively adapt to actual process dynamics while s teering the policy toward global op timality , ultimately providing robust initialization for subsequent online adaptation. In summ ary , the control-informed policy learning strategy during offline pre-tr aining enhances RL training through two key mechanisms: (1) precise system state estimation via Kalman filtering, which e nables accurate environment modeling, and (2 ) eliminatio n of unsafe exploration through info rmed supervision, which ensures both system sa fety and l earning ef ficiency du ring the pre-training phase. The pseud ocode of the CIRL algorithm during offline training is shown in Algorithm 1. The detailed design schemes are explained in the following subsections. 3.2.2 IL -CIRL agent design (offline pre-training process) This section presents the conceptual design prin ciples of the IL-CIRL agent; detailed network configurations and parameter settings are provided in Section 4. 1) Conceptual overview of the IL-CIRL pre-training procedure The IL-CIRL framework employs a distinctive pre-training approach that differs 15 / 39 fundamentally from c onventional DRL methodologies. T raditional DRL pre-training involves agent interaction with a simulated environmen t prior to transfer or fine-tuning for deployment in real systems [30]. In contrast, the IL-CIRL pre-training phase ope rates without any interaction with the physical plant or process simul ator . Instead, the agent interacts exclusively with the hierarchical IL C informer across both the batch and time axes, which functions on the L TV state-space model of batch pr ocesses derived in Section 2. The hierarchical ILC informer incorporates Kalman filter ing to addre ss the various disturbances described in Section 2.2, transforming the disturbance-compensated control design problem into a state estimation framework. This approach elimi nates the need f or the IL -CIRL agent to dire ctly incorporate disturbance terms as RL states. Th e informer comprises two hierarchical components: a batch- to -batch Kalman filter- based ILC info rmer and a within - batch Kalman filter-based ILC informer . The fo rmer functions as the out er loop in a cascade architecture, transmitting information, including end-of-batch state estimates, to the inner-loop within-batch ILC informer . This hierarchical design e nables the framework to simultaneously manage both deterministic persistent ( batch-wise) and stochastic transient (time-wise) disturbances. Additionally , the Kalman filter supports the informer ’ s prediction model while providing disturbance-filtered state estimates to the IL-CIRL agent, thereby facilitating seamless integration between ILC and control-informed deep reinforcement learning. 2) IL -CIRL agent & proximal policy optimization (PPO) The IL-CIRL algorithm employs the P PO algorithm as its DRL agent for batch process optimization control. PPO is a model -free, on-policy , poli cy-gradient-based DRL algorithm that has gained widespread recognition for its stab ility and robust empirica l performance. The algorithm operates by alternating between data sampling through environmental interactions and optimizing a clipped surrogate objective function via stochastic gra dient descent [31]. By constraining large d eviations between successive policies, which can impede learning, PPO ensures stable policy updates a nd mitigates the instability inher ent in traditional policy gradient methods. Through the introduction of a surrogate objective fun ction that enables mini-batch updates across mul tiple training steps, PPO addresses the challenge of step size selection present in conventional policy gradient algorithms. The PPO-Clip variant constrains the magnitude of policy changes, thereby encouraging the updated policy to remain in proximi ty to it s prede cessor . In PPO-Clip, the policy update is governed by the following objective: 16 / 39 1 , ~ arg max ( , , , ) , k kk sa L s a + = (23) where L is defined as th e surrogate objective function, which depends o n the advantage function ( , ) k A s a : ( | ) ( , , , ) min ( , ), ( , ( , )) , ( | ) k k k k as L s a A s a g A s a as = (24) where ( 1 ) 0 ( , ) ( 1 ) 0. AA g A AA + = − (25) Therefore, the clipping operation se rves as a form of regul arization that mitigates excessive policy updates. The hyper parameter controls the permissible deviation between the old and new policies, ensuring stable and ef fective learning. 3) Basic principles of State, Action, and Reward definition In control th eory and DR L, the te rms “state” and “observation” carry distinct meanings. In control systems, state typically refers to internal system variables, such as the system state () x n k t x in Eq.(1). In contrast, DRL emphasizes obser vations that satisfy the Markov property. Consequently, within the framework of Markov Decision Processes (MDPs), any variable r elevant to the DRL agent ’s decision -making can be interpreted as state, provided it satisfies the Markov property. In the propos ed IL-CIRL algorithm framework, the DRL state is defined as the state variables of the batch process model. This design choice ensures seamless integration, as the hierarchical ILC informer guides both control-informed offline policy learning and safety- guaranteed online adaptation. This unified definition enables the organic integration of the ILC structure and the DR L agent within a cohesive framework. The DRL action corresponds to the control inputs of the batch process, equivalent to the control signal () u n k t u in Eq.(1). Specifically, the stat e represe nts the internal state variables of the batch process, while the action represents the manipulated variables. The reward function settings in IL-CIRL vary between the offline pre -training stage and the online safety adaptation stage. During offline pre-training, IL-CIRL conducts imitation learning based on the hierarchical ILC informer without direct interaction w ith the actual process. The objective is to replicate expert control patterns under Kalman -filtered feedback, thereby inheriting the expert’s convergence and stability characteristics while preventing 17 / 39 unsafe exploration. Consequently, the pre-training reward is designed to quantify the discrepancy between the IL- CIRL agent’s actions and those of the hier archical ILC infor mer. This approach compels the DRL agent to emulate the hierarchical ILC info rmer’s behavior. Through t his control-informed policy learning methodology, expert guidance with guaranteed asymptotic convergence and stability is incorporated into the IL-CIRL pre-training process. The implementation differs from traditional DRL in two key aspects. First, rather than obtaining state feedback directly from the environment or controlled object, IL-CIRL employs within-batch real-time Kalman filtering for state feedback. Second, the cont rol actions generated by DRL are not transmitted directly to the batch process. The IL -CIRL state represents the system state provided by the Kalman filter , and its corresponding action should approximate the hierarchical ILC informer’s behavior. Based on these considerations, the pre-training reward function is designed as: || t ILC RL r u u = − − (26) 3.2.3 Design of batch- to -batch and within-batch hierarchical ILC informer During offline pre-training, the hierarchical ILC functions as the inform er, governing control across both batch- to -batch and within-batch dimensions. Building upon the LTV state- space predi ctive models derived in Sections 2.2 and 2.3, the design principle s of the Kalman filter-based ILC informer are de tailed below. 1) Batch- to -batch Kalman filter-based ILC for batch process control The Kalman filter is empl oyed to iteratively estimate state updates from multiple disturbance sources, based on the batch process state-space model with noise described in Eq. (14) . This approach int egrates process disturbances into the dynamic model, enabling beneficial disturbances to enhance process economy while mitigating adverse effects. Given the posterior state estimates from the previous batch and the observation variables from the current batch, the K alman filter estimates the stat e of the current batch. T he state estimation and error covariance matrix for the c urrent batch a re calculated through the dynamic model of Eq. (14) , with specific formulas provided as follows: | 1 1 | 1 ˆ ˆ k k k k u k − − − = + x x u (27) 18 / 39 | 1 1 | 1 1 | 1 1 1 1 1 1 | 1 ( )( ) 2 0 0 0 2 0 0 0 2 k k k k k TT k k d k k k k k k d wv wv T k k d d w v − − − − − − − − − −− =+ = + + − + − + + = + + P P Q P w v v w v v RR RR P R R (28) where |1 ˆ kk − x represents the state estimation of batch k based on the state observati on of batch 1 k − , 1 | 1 ˆ kk −− x denotes the posterior estimation of the st ate of batch 1 k − when the state observation of batch 1 k − is available, and 1 | 1 kk −− P represents the corresponding state error covariance matrix; ( ) ( ) T w k k tt = R w w and ( ) ( ) T v k k tt = R v v . The residual matrix k e , consisting of the measurement residuals of both the observa tion va riables and the terminal product quality variables, can be computed based on the syst em dynamics, and it s specific expression is given as follows: |1 |1 ˆ ( ) ( ) p kk k kk k k k k q kk k TT − − = = − = − zz e e x L x yy e (29) Define T T T k = L , then the covariance matrix corresponding to k e can be derived from k L and |1 kk − P . The specific expression is given as follows: | 1 | 1 |1 ( ) ( ) 0 0 0 0 00 T kk TT k k k k k k k k k k kk m m T k k k k n TT −− − = + = + =+ mm S L P L R L P L nn R R L P L R (30) where ( ) ( ) T m k k tt = R m m , and ( ) ( ) T n k k tt = R n n . According to the Kalman filter derivation, the optimal Kalman gain k K can be calculated as follows: 1 |1 T k k k k k − − = K P L S (31) Therefore, the updated state estimation and the corresponding error covariance matrix for the batch process can be expressed in the following iterative upda te form: | | 1 ˆ ˆ k k k k k k − =+ x x K e (32) | | 1 () k k k k k k − =− P I K L P (33) 19 / 39 Upon obtaining the posterior state estimation for t he current batch and its corresponding control sequence, the states of subsequent batches can be continuously predicted using the Kalman filter . In conjunction with the batch process optimization control problem defined in Eq.(7), the Kalman filter -based batch- to -batch ILC control design problem can be formulated as follows: 1 1 1 1 | 1 1 | 1 1| 0 1 | | 1 11 1 | 1 | ˆ ˆ min ( , ) ( ( ), ( )) ( ( )) s.t. ˆ ˆ ˆ ˆ () k T k k k k k k k kk t k k k k u k k k k k k k k V l t t Q T T + − + + + + + + = ++ ++ ++ =+ = + = + = u x u x u y x x u u u u yx (34) where the computation of the optimal solution ** 1 | 1 ) ˆ (, k k k ++ xu and its corresponding economic performance index * 1 k V + is achieve d through K alman filtering, the reby eliminating the need for explicit disturbance estimation. The resulting optimal control sequence is applied to the batch process in an open-loop manner , whereas th e batch-wise direction follows a closed-loop iterative process based on ILC. During the batch- to -batch iterative learning process, after the completion of the - t h k batch, the posterior state estimation 1 | 1 ˆ kk ++ x of batch 1 k + is continuously updated according to the Kalman filter desc ribed in Eqs.(32)-( 33 ), t hereby enabling iterative refinement of th e ILC-based optimal control solution in Eq.(34). 2) W ithin-batch Kalman filter -based ILC for batc h process contr ol T o establish the connection between batch- to -batch a nd within-batch IL C, the state response at time 0 t = in Eq.(18) is defined as the sta te of the previous batch in the batch- to -batch ILC method; i. e., ;1 (0) h k k − = xx . This framework enables integration between the two ILC approaches. Specifica lly , batch- to -batch ILC functions analogously to the outer loop of cascade control in conti nuous process control, while within -batch ILC c orresponds to the inner loop. Th e K alman filter employed in batch- to -batch ILC provides the updated state values at time 0 t = for use in within-batch ILC. Similarly , the Kalman filter used in the batch- to -batch ILC method d escribed above can be applied to state estimation in within-batch ILC. The key dist inction lies in the update frequency: batch- to -batch ILC updates the Kalman filter state estimation once per batch, 20 / 39 whereas withi n-batch ILC performs updates at each time step within a batch. For within-batch implementation, the system estimate and error covariance matrix for the entire batch at the current time step can be computed using the dynamic model presented in Eq.(18) as follows: ;; ˆ ˆ ( | 1 ) ( 1 | 1 ) ( 1 ) ( 1 ) h k h k u k t t t t t t − = − − + − − xx Ψ u (35) 1 1 1 1 ( | 1 ) ( 1 | 1 ) ( ) ( 1 | 1 ) ( )( ( ) ( ) ( ) )( ( ) ( ) ( )) ( ) ( 1 | 1 ) ( )( 2 ) ( ) k k k k TT d k k k k k k d T k d w v d t t t t t tt t t t t t t t t t t t t − − − − − = − − + = − − + + − + − = − − + + P P Q P Ψ w v v w v v Ψ P Ψ RR Ψ (36) where ; ˆ ( | 1 ) hk tt − x represents the sta te estimation at time t based on the state observation at time 1 t − , ; ˆ ( 1 | 1 ) hk tt −− x denotes the posterior estimation of the state at time 1 t − when the state observation at time 1 t − is available, and ( 1 | 1 ) k tt −− P is the state error covariance matrix that qua ntifies the estimation accuracy at time 1 t − ; ( ) ( ) T w k k tt = R w w and ( ) ( ) T v k k tt = R v v represent the covariance matrices of the process and me asurement noi se, respectively . The deviation between the actual measured value and the predicted estimation of the observation variable can then be expressed as follows: 1 ˆ ( ) ( ) ( ) ( ) ( | 1 ), () z k k k t T t t t t t t t t −− = − − = e z F H x H 0 0 I 0 0 (37) where () z k t e represents the measurement residual of the observation variable. Define ( ) ( ) ( ) k t t t = L F H , then the covariance matrix of the measurement residual can b e calculated as follows: ( ) ( ) ( | 1 ) ( ) ( ) ( | 1 ) ( ) ( ) ( ) ( ) ( | 1 ) ( ) T k k k k t TT k k k k k T k k k m t t t t t t t t t t t t t t t = − + = − + = − + S L P L R L P L m m L P L R (38) Based on the Kalman filter derivation, the optimal Kalman gain () k t K can be calculated as follows: 1 ( ) ( | 1 ) ( ) ( ) T k k k k t t t t t − =− K P L S (39) Similarly , the updated state estimation of the ba tch proce ss and its associated e rror c ovariance matrix can be expressed in the following iterative update form: ;; ˆ ˆ ( | ) ( | 1 ) ( ) ( ) z h k h k k k t t t t t t = − + x x K e (40) 21 / 39 ( | ) ( ( ) ( ) ) ( | 1 ) k k k k t t t t t t = − − P I K L P (41) Once the posterior estimate of the current state a nd the corresponding control sequence are obtained, the states at subsequent time steps can be continuously predicted using the Kalman filter . It shoul d be noted that since within -batch ILC is implemented on the basis of batch - to - batch ILC, each batch must be initialized at 0 t = using the Kalman filter r esult from the previous batch’ s batch- to -batch ILC, i.e. , 1 (0 | 0) kk − = PP , ; 1 | 1 ˆ ˆ (0 | 0) h k k k −− = xx and ;1 (0) h k k − = uu . Combined with the definition of the batch process optimization control problem described in E q.(7), the withi n-batch ILC control design p roblem based on the Kalman filter can be formulated as follows: ; ;; () 1 ;; 1 ; ; ; ; ˆ min ( ( ), ( )) s.t. ˆ ˆ ( | ) ( | ) ( ) ( ) ( ) ( ) ( ) ˆ ˆ ( | ) ( ) hk k h k h k t T h k h k u k it h k h k h k k h k V T T T t t t i i T t t T t T − =+ = + = + = u xu xx Ψ u u u u y Γ x (42) where the optimal solution * ; () hk t u represents the optimal control sequence from time t to time 1 T − in batch k , and only * () k t u at time t is applied to the batch process during the within-batch closed-loop operation. During the within-batch iterative learning process, upon completion of time step t , the posterior state estimate ; ˆ ( 1 | 1 ) hk tt ++ x at time 1 t + continues to be updated according to the Kalman filtering of Eqs.(40)-(41), ther eby continuous iteration of the ILC optimization control solution given in Eq.(42). Based on the analysis and derivation prese nted above, the batch- to -batch ILC employing a Kalman filter addresses repetitive disturbances along the b atch axis. Subsequently , within - batch ILC further mi tigates non-repetitive dis turbances along the time axis. (Not e: if disturbances in the ti me axis exhibit repetitive behavior , they can be incorporated into the batch- to -batch ILC disturbance f ramework.) This two-tier approach en ables within-batch control to be completed before random disturbances propagate thro ugh the ILC iterative process of subsequent batches. 3.3 Safety-guaranteed control-informed adaptation durin g online tr aining process During the online training stage, the RL agent inte racts with the actual process and refines 22 / 39 its policy based on observed feedback. How ever , the stochastic n ature o f DRL exploration, combined with the comp lex dynamics and inhe rent uncertainties of indust rial systems, can result in initially unstable or uns afe agent actions. T o mitigate this risk, this study proposes a safety-guaranteed control -informed adaptation strategy in which the hierarc hical ILC informer operates in parallel with the RL agent during online implementation and adaptation, as illustrated in Fig. 3. Both components collaborate to generate the final control signal applied to the batch process. This approach mitigates safety hazards during initial exploration while preserving learning efficiency and conver gence. The int egration of Kalman filtering facilitates real-time state estimation , enabling the agent to a ccurately assess process conditions at each training iteration. This real -time state feedback reduces control errors in the IL-CIRL agent arising from model-plant mismatch and ensures progressive policy c onvergence through precise estimation of system dynamics. The pseudocode for the CIRL a lgorithm during online adaptation is presented in Algorithm 2. 23 / 39 Fig. 3 Schemat ic diagram of safety-guar anteed control -inform ed adaptat ion during onli ne training process Following the completion of offline pre -training, the IL-CIRL agent is d eployed for online adaptation with the actual process. During this phase, both the hierarchical IL C controller and the RL agent generate control signals concurrently to mitigate irrati onal behaviors. These signals are integrated through an adaptive weighting mechanism, formulated as follows: ( 1 ) t IL C t t u u a = + − (43) where the weight is used to adjust the control contribution of the DRL policy to the actual batch process. Intuitively , when th e policy output of the RL agent deviates significantly from the “expert-level” control signal provided by the ILC informer , the weight o f the agent’ s action should be reduce d to mitigate irrational or unsafe behaviors. The we ight is updated during online training and adaptation according to following expression: (1 .1 | |) ( 1 ) t ILC au t Kt e K − − − = − (44) In Eq.(43) the first term captures the relationship between the ILC controller and the RL agent. As the performance gap between them decreases, the corresponding weight decays exponentially . The second term serves a s a training-time pena lty to prevent the RL agent from relying excessively on the weight and neglecting its own policy updates. By applying this time -depende nt penalty after assessing the gap, the agent is encouraged to gradually optimize its policy and ultimately operate independently of the ILC controller ’ s assistance. Meanwhile, the RL agent adopts the process variables ˆ x filtered via a Kalman filter as its state represe ntation. Based on this state, the optimization objective and constraints for online training of the agent are for mulated as follows: 24 / 39 ( ) 1 ,, 1 , , , , ˆ ˆ | ( ) | ( ) ˆ ˆ s.t. ( | ) ( | ) ( ) ( ) ( ) ( ) ( ) ˆ ˆ ( | ) ( ) ii i i i i ILC ref T h k h k u k it h k h k h k k h k min u x x x x T t x t t i u i u T u t u t y T t x T − =+ − + − = + = + = (45) In other words, th e IL-C IRL agent fully leverages the Kalman filtered sta te in each training iteration or episode, thereby preventing control anomalies due to model a daptation and enabling ef fective policy optimization. 4 Results and Discussion 4.1 Experimental setup of batch process optimization control 4.1.1 Batch reaction process description T able 1 Param eter setti ng of batch process c hemical reactor Parameters V alues Parameters V alues 1 11 4 0 0 0 L m ol s −− 1 51 1 .8 10 c a l m o l − − 2 51 6 .2 10 s − 2 51 2 .2 5 1 0 ca l m o l − − 1 E 11 5 0 0 0 c al g m ol −− P C 11 1 0 0 0 c al kg K −− 2 E 11 1 0 0 0 0 c a l g m o l −− J C 11 1 0 0 0 c al kg K −− R 11 2 c al m ol K −− 1 0.8kg L − V 1 20 0L J 1 0.8kg L − J V 1 20 0L o A 2 52 5 dm ow h 1 1 2 1 0 8 5 0c al m in K dm − − − In this section, a typical batch reaction process is used to verify th e effectiveness of the proposed IL-CIRL control scheme. A complex batch reaction system with nonlinear dynamic characteristics is considered, which includes two consecutive reactions: 12 A B C kk ⎯ ⎯ → ⎯ ⎯ → . Reaction product B is the targe t product, while reaction product C is a b y -product of batch production. Reactant A is initially added to the reactor . As the reaction proceeds, the syst em releases a lar ge amount of he at. T o maintain the forward progress of the reaction and increase economic benefits, cooli ng water is introdu ced to take aw ay the heat ge nerated during the reaction through a jacket. Specifically , a set of ordinary differential equations (ODEs) is us ed to model thi s nonlinear dynamic exothermic reaction process, and simulations are carried out according to the assume d conditions. T o simplify calculations without losi ng generality , it is 25 / 39 assumed that the reactants are completely mixed in the reaction vessel that has good thermal insulation, and the heat loss is negligible. The physical parameters in the reac tion system are known, as shown in T able 1. Under the above assumptions, the mass balance equations fo r reactant A and tar get product B in this batch process are described by the following ODEs: 2 A 1A dC kC dt =− (46) 2 B 1 A 2 B dC k C k C dt =− (47) where 1 k and 2 k are temperature-related reaction rate constants, ca lculated as follows: 1 / 11 E RT ke − = (48) 2 / 22 E RT ke − = (49) The ener gy balance equations for the reactor and the jacket can be derived as follows: 2 J 12 1 A 2 B P P P Q dT k C k C dt C C V C −− = − − (50) J W0 J J0 J J J J J () dT F Q TT dt V C V = − + (51) The heat exchange between the jacket and the rea ctor can be written as follows : J ow o J () Q h A T T =− (52) In addition, at the initial time step of each batch, the four system states are set as follows: A B J 1 m ol /L , 0m ol /L , 3 23 K C C T T = = = = (53) Reasonable upper and lowe r limits should be provided for the control action. According to the physical constraints of the cooling water flow rate, its operating range is set as: ow 0L /s 1 0L /s F (54) The reaction temp erature, as a key parameter for batch process operation, is limited to the following range based on practical conditions: 2 9 8 K 37 8K T (55) In the experiment, the terminal time of each batch operation is fixed as 1h f T = . T o better simulate the sc enario where real-time product quality is undetectable in actual industrial sites, the concentrations of reactant A ( A C ) and tar get product B ( B C ) can only be obtained at the terminal time; it is assumed that other observation variables can be obt ained online in real time. 26 / 39 4.1.2 Optimization control objectives The entire control system consists of two parts: the R TO steady-state optimization layer and the IL-CIRL control layer . The goal of the R TO layer is to maximize economic benefits and the quality of the final product through the economic opti mization, and t he solved optimal nominal trajectory is tr ansmitted to the IL-CIRL control layer for execution. The economic objective function used in this experiment is calculated as follows: 22 RTO B B,sp ow 0 m in min ( ( ) ) ( ) f TT f i J T C V k t − = = − + CF (56) where B () f T C is the product concentration at the end of the batch, B ,sp C represents the desired tar get product concentration, ow ow ow [ (0) ( )] f TT = − F F F is the cooling water flow rate of the e ntire batch and T is the sampling interval. The first term of the e conomic objective function in E q.(56) is the terminal c ost of batch process op timization control, indicating that the closer the concentration of target product B is to the target value, the higher the economic benefit; the second term represents the operating cost, meaning that the lower the flow rate of cooling water , the better the economic benefit. B, sp 0.58mol/L C = is the target value, and 0 .0 5 k = is the unit cost of the cooling water . Based on the above const raints, by optimizing thi s objective function, the optimal nominal reference trajectory can be obtained, including temperature nom T , concentrations A , nom C and B , nom C , and flow rate ow , nom F . For ILC-based b atch process economic opti mization control, the objective function can directly inherit the economic objective fr om the R TO layer , which is calculated as follows: 1 22 B B, nom B,sp ow ow 0 m in min ( ( ) ( ) ) ( ( ) ( )) f EMP T ff i C J T T C V k t t − = = + − + + C C F F (57) where B () T C and ow F represent t he variation of the c oncentration of product B and the cooling water flow rate, respectively . 4.1.3 IL -CIRL agent & algorithm setting The IL-CIRL algorithm designs the agent framework based on the PPO algorithm. Specifically , the agent consists of two parts: a c ritic network and an actor network, with corresponding parameters set. The critic network takes the actual industrial process variables ˆ x filtered by the Kalman filter as input . Its network structure is compos ed of two fully connected layers, e ach containing 100 neurons and using the T anh activation function. Finally , a fully connected layer outputs results corresponding to the number of act ions. The 27 / 39 input of the actor network is also the aforementioned state input, which is processed through two fully connected layers (each with 100 neu rons and using the T anh activation function); the mean path first pass es through a fully connected layer , then is proce ssed by the T anh activation function and a scaling layer , so that the output range is (0, 10). Du ring pre-training, the action t a (i.e., cooling water flow rate) generated by the actor network does not directly interact with the actual indus trial process but conducts preliminary policy learning updates through a simulated environment. During online training, the action t a generated by the actor network is weight-fused with the action from the ILC controller before interacting with the actual industria l control system. This interaction yields a new state 1 t s + and a calculated reward t r , which are used to iteratively update the control policy . The hyperparameters of IL-CIRL and PPO algo rithms used in both pre -training and online training are shown in T able 2. T able 2. Hyper parameters of IL -CIRL and P PO algori thms Hyperparamet ers V alues critic l earning rate 1e-4 actor learni ng rate 5e-5 number of ep ochs 10 discount factor 0.99 entropy loss weight 0.02 minibatch s ize 64 experience h orizon 2048 clip factor 0.2 4.1.4 State, action, and reward According to the design concept of IL-CIRL des cribed in Section 3 and co mbined with the characteristics of the batch reaction object, the state in M DP is defined as , , , and , which are the reaction tempera ture, jacket temperature, concentration , and concentration respectively . On the other hand, the action in MDP is defined as the control input, specifically the cooling water flow rate, and its value range is between [0,1 0]. In the IL- CIRL framework, the reward function in the pre-training stage takes the output dif ference between the ILC controller and the RL controller as the criterion, and its expression is as follows: || t ILC RL r u u = − − (58) The reward fun ction for online training is divided into continuous reward an d discrete reward. Considering the advantages of hybrid reward signals in the design of setpoint trac king controllers, usually , continuous reward signals can improve the convergence during the 28 / 39 training process, while discrete reward signals help guide the agent towar d s more favorable regions in the state sp ace. Specifically , the total reward is the sum of the continuous reward and the discrete reward, i.e., t c d r r r =+ (59) where is the continuous reward, defined as: | · | c IL C t r u a =− (60) And is the discrete reward, which is related t o the absolute value of the error signal. Therefore, the discrete reward signal aims to drive the RL agent to move stably around the reference trajectory . The settings for discre te rewards in the experiment are given in T able 3. T able 3 Discr ete rewar d settings i n the experiment < 0.05 < 0.1 < 0.5 < 1 < 2 < 3.5 < 5 ≥ 5 300 100 50 0 -5 -20 -50 -100 4.2 Control performance an d convergence o f the Kalman filter-based hierarchical ILC informer First, the steady-state R TO is used to optimize the economic objective fun ction in Eq. (56) , and the optimal nominal reference trajectory of th e batch pro cess is obtained. Since the steady- state optimization of R TO does not consider f ast- changing information such as disturbances, the obtained t rajectory i s only the optimal reference under ideal conditions. T o verify the ef fectiveness of the batch - to -batch and within-batch hierarchical ILC based on the Kalman filter in dealing with multi -source disturbances su ch as deterministic and u ncertain ones, the cooling water temperature in the control layer is changed from the nominal value J0 3 2 3 K T = to the actual value J0 318K T = , i.e., there is an offse t of 5K − in the cooling water inlet temperature. The two ty pes of random disturbances in Eqs .(8)-(9) are set as ~ ( , 0 .3 ) k N v0 and ~ ( , 0 .4 ) k N w0 , respectively; the measurement noises of the observation variable and quality variable in Eq.(2) are set as ( , 0. 0 6 ) k N m0 and ( , 0 .0 0 5 ) k N n0 , respectively . By using the aforementioned batch - to -batch and within-batch ILC algorithm based on Kalman filtering for state estimation and iterative learning, Figs . 4-7 present the dynamic evolution results of the state trajectories of ILC during the iterative learning process as the batch number ch anges, showing the three-dimensional views of the four st ates A C , B C , T 29 / 39 and J T of the b atch process respectively . Fig. 8 presents the evolution result of the action trajectory ow F of ILC during the iterative lea rning process as the batch number changes. According to the experimental results, it can be seen that as the batch proc ess ILC undergoes continuous iterative updates, the syst em states and actions gradually converge to a rela tively small range, whic h indicates that the batch- to -batch and within-batch ILC algorithm ba sed on Kalman filtering can achieve asymptotically conver gent control of the batch process. Fig. 4 3D V isualization of th e iterati ve learning process f or the conce ntration-A trajectory usi ng Kalman filter -based ILC Fig. 5 3D V isualization of th e iterati ve learning process f or the conce ntration-B t rajector y using Kalman filter -based ILC 30 / 39 Fig. 6 3D V isualization of th e iterati ve learning process f or the react ion temperatur e traject ory using Kalman filt er-based ILC Fig. 7 3D V isualization of th e iterati ve learning process f or the jacket temperature t rajectory usi ng Kalman filter -based ILC 31 / 39 Fig. 8 3D V isualization of th e iterati ve learning process f or the acti on trajectory usi ng Kalman fi lter- based ILC 4.3 The pre-training process and convergence of the proposed IL -CIRL algorithm T able 4 Hyperparameters of the IL -CIRL and PPO algorithms Hyperparameters V alues critic learning rate 1e-4 actor learning rate 5e-5 number of epochs 10 discount factor 0.99 entropy loss weight 0.02 minibatch size 64 experience horizon 2048 c lip factor 0.2 After verifying the convergence and safety of the Kalman filter and ILC iterative learning process, the designed ILC control law is used to guide the of fline pre-training of the IL-CIRL controller . It is important to emphasize that the offline pre -training process does not require interaction with the a ctual batch process; instead, it interacts with the K alman filter state estimates and the corresponding ILC control law . S pecifically , the Kalman filter updates the system state estimate at eac h ti me step of the RL training episode, and the latest estimated state is assigned to the RL agent as the state for the next time step. This enables purely offline pre - training without any safety haz ards. Additionally , the core of the IL -CIRL agent is implemented using the classical PPO algorithm, with specific training hyperparameters listed in T able 4. 32 / 39 Figs. 9-10 present 3D visualizations of the iterativ e process of state and a ction trajectories of IL-CIRL during o f fline pre-training. It can be observed that in the initial training episodes, the error between IL-CIRL and the refere nce tra jectory is relatively lar ge. As the Kalman filter ’ s state estimation becomes increasingly accurate and the ILC iterative process achieves asymptotic conver gence, the RL controller obtained by IL-CIRL also tends to conver ge. Fig. 9 3D V isualization of th e iterati ve learning process f or the react ion temperatur e traject ory during offli ne pre-traini ng in the IL- CIRL frame work Fig. 10 3D V isualization of t he iterati ve learning process for the acti on trajectory dur ing of fline pre- training i n the IL-CIRL framework 4.4 The weighted training process and convergence of the proposed IL -CIRL algorithm As outlined in Section 3.2, the offline pre-training process does not involve interaction with the actual variable-mode batch process. In fact, the IL -CIRL agent does not partic ipate in 33 / 39 the control of the batch proce ss during this stage; its sole purpose is to enable the IL -CIRL agent to initially learn f rom the iterative controller , thereby improving th e efficiency of the subsequent weighted trai ning process. In the weighted training pro cess, the control action interacting with the envi ronment is synthesized b y the iterative controller and the IL -CIRL agent according to a weight coefficient. Moreover , the state of the IL -CIRL agent consists of environmental parameter s filtered by the Kalman filter . During training, based on the reward settings, the control policy of the IL-CIRL agent is further r efined. Meanwhile, the weight coef ficient is automatically adjusted to li mit the influence of irrational behaviors of the IL - CIRL agent on the control action, ensuring the saf ety of practical implementation. Figs. 11 -13 present 3D visualizations of the weight variation, action trajectory , and state trajectory of IL- CIRL during the weighted training process. It can be observed that in the initial trai ning episodes, the iterative controller accounts for a large propo rtion of the control action. As the training episodes progress, the weight gradually decreases, and the control performa nce gradually conver ges to be close to the reference trajectory . Fig. 1 1 W eight iteration grap h of the IL-CI RL algorit hm, includi ng the weight t raining pr ocess 34 / 39 Fig. 12 3D V isualization of t he iterati ve learning process for the acti on trajectory i n the IL-CIRL algorithm 35 / 39 Fig. 13 3D V isualization of t he iterati ve learning process for the react ion temperatur e traject ory in the IL- CIRL algorithm 4.5 Comparison of IL -CIRL and original PPO algorithms T able 5 Hyperparameters of IL-CIRL and PPO alg orithms Hyperparamet ers V alues critic learning rate 1e-4 actor learning rate 5e-5 number of epochs 10 discount factor 0.99 entropy loss weight 0.02 minibatch size 64 experience horizon 2048 c lip factor 0.2 Fig. 14 Action iteration graph of the original PPO algorithm T o demonstrate that the RL agent guided by cont rol information exhibits higher safety and training ef ficiency compared to dir ectly trained RL agents, th e iterative learning performance of the IL-CIRL algorithm is compared with that of the classical PPO algorithm (detailed in Section 2). The control curves and control performance changes of the classical PPO algorithm during iteration are shown in Fig. 14 and Fig. 15. Fig. 16 presents the variation curves of the Mean Squared Error (MSE) between the state trajectories of the two algorithms and the re ference trajectory during iteration. It should be noted that all hyperparameters of IL- CIRL and P PO are set identically to ensure a fair comparison, with specific training hyperparameters listed in T able 5. 36 / 39 Fig. 15. Reaction temperature trajectory iteration graph of the original PPO algorithm Fig. 16 Comparison of mean squared error (MSE) betwee n RL and IL-CIRL From the experimental results, it can be observed that the IL-CIRL algorithm achieves relatively good control perf ormance from the initial iteration of online impleme ntation, whereas the original P PO algorithm exhibits poor control performance in the early stages. Furthermore, as the actu al batch process evolves iteratively , the control pe rformance o f PPO never su rpasses that of the proposed IL-CIR L m ethod. Therefore, by using ILC and process disturbance information to guide the pre -training process, this study effectively achieves safe 37 / 39 of fline pre-training and fast online transfer learning. This minimizes the significant safety risks posed by the trial- and-error nature of traditional DRL algorithms to the optimal control of complex industrial objects (represented by continuous batch pr ocesses). 5 Conclusion This study proposes an IL-CIRL framework that integrates ILC and process disturbance information guidance. The framework aims to address safety hazards and conver gence issues that RL may face du ring interaction with industrial plants. The key idea is to combine ILC with RL, leveraging the state estimation based on t he Kalman filter and batch- to -batch/within- batch optimization control in ILC to guide the training process of the RL controller . This ef fectively avoids potential risks caused by random exploration. Specifically , the IL -CIRL framework provides a stable c ontrol strategy through iterative learning a nd ensures the safety , stability , and asymptotic convergence of the control proc ess by real -time estimation of process disturbances and accurate state f eedback. Experimental results verify the ef fectiveness of the method in adaptive optimal control under variable-mode environments with multi-source disturbances. This approach offers a novel solution for the optimal control of batch processes, highlights the role of control -informed guidance information in the RL tr aining process, and exhibits broad application prospects in industrial automation. References [1] W .M. Hawkins, T .G. Fisher , Batch Control Systems: Design, Application, and Implementation, 2nd ed., International Society of Automation2006. [2] D. Bonvin, Optimal operation of batch reactors—a personal view , Journal of Process Control 8(5) (1998) 355 – 368. https://doi.org/https://doi.or g/10.1016/S0959-1524(98)00010- 9 . [3] F . Gao, Y . Y ang, C. Shao, Robust iterative learning control with ap plications to injection molding process, Chemical Engineering Science 56(24) (2001) 7025 –7034. https://doi.org/https://doi. org/10.1016/S0009-2509(01)00339-6 . [4] K. Alhazmi, F . Albalawi, S.M. Sarathy , A reinforcement learning-bas ed economic model predictive control framework for autonomous operation of chemical reactors, C hemical Engineering Journal 428 (2022) 130993. https://doi.org/https://doi. org/10.1016/j.ce j.2021.130993 . [5] J. Chen, M. Che n, L.L.T . Chan, Itera tive learning parameter estimation and design of SMB processes, Chemical Engineering Journal 161(1) (2010) 223 –233. https://doi.org/https://doi. org/10.1016/j.ce j.2010.04.027 . [6] K. Konakom, P . Kittisupakorn, I.M. Mujtaba, Batch control improvement by model predictive control bas ed on multiple reduced-mo dels, Chemical Engineeri ng Journal 145 (1) (2008) 129–134. https://doi.org/https://doi.or g/10.1016/j.cej.2008.07.043 . 38 / 39 [7] M. Ławryńczuk, Modelling and nonlinear predictive control of a yeast fermentation biochemical reactor usin g neural networks, Chemi cal Engineering Journ al 145(2) (2008) 290– 307. https://doi.org/https: //doi.org/10.1016/j.cej.2008.08.005 . [8] D.A. Bristow , M. Thara yil, A.G. Alleyne, A survey of iterative learning control, IEEE Control Systems Magazine 26(3) (2006) 96 –1 14. https://doi.org/10.1 109/MCS.2006.1636313 . [9] M. Uchiyama, Form ation of High-Speed Motion Pattern of a Mechanical A rm by T rial, Transa ctions of the Society of Instrument and Control Engineers 14(6) (1978) 706–712. https://doi.org/10.9746/si cetr1965.14.706 . [10] K.S. L ee, I.-S. Chin, H.J. Lee, J.H. Lee, Model predictive control technique combined with iterative learning for bat ch pro cesses, AIChE Journal 45(10) (1999) 2175 – 2187. https://doi.org/https://doi.or g/10.1002/aic.690451016 . [1 1] Y . W ang, F . Gao, F .J. Doyle, Survey on iterative learning control, repetitive control, and run- to -run control, Journal of Process Control 19(10) (2009) 1589–1600. https://doi.org/https://doi. org/10.1016/j.jprocont.2009.09.006 . [12] S. Arimoto, S. Kawamura, F . Miyazaki, Bettering operation of dynamic systems by learning: A new control theory for se rvomechanism or mechatronics systems, The 23rd IEEE Conference on Decision and Control, 1984, pp. 1064–1069. [13] R.W . Longman, Iterative/Repetitive Learning Control: Learning from Theory , Simulations, and Experiments, in: N.M. Seel (Ed.), Encyclopedia o f the Sciences o f Learning, Springer US, Boston, MA, 2012, pp. 1652–1657. https://doi.org/10.1007/978-1-4419-1428- 6_1640 . [14] J. R ichalet, A. Rault, J.L. T estud, J. Papon, Model predictive heuristi c control: Applications to industrial processes, Autom atica 14(5) (1978) 413–428. https://doi.org/https://doi. org/10.1016/0005-1098(78)90001-8 . [15] Y . S hi, R. Lin, X. W u, Z. Zhang, P . Sun, L. Xie, H. Su, Dual-mode fast DMC algorithm for the control of ORC based waste heat recovery system, Energy 244 (2022) 122664. https://doi.org/https://doi.or g/10.1016/j.ener gy .2021.122664 . [16] D. Shen, X. Cheng, S. Gao, X. He, Z. Li, Z. Zhang, Advance s in iterative learning control: A recent five-year literature review , ISA T ransac tions (2026). https://doi.org/https://doi. org/10.1016/j.isatra.2026.03.001 . [17] R. Nian, J. Liu, B. Huang, A review On reinforcement learning: Introduction and applications in industrial process control, Computers & Chemical Engine ering 139 (2020) 106886. https://doi.org/https://doi.or g/10.1016/j.compche meng.2020.106886 . [18] P . Petsagkourakis, I.O. Sandoval, E. Bradford, D. Zhang, E.A. del Rio -Chanona, Reinforcement learning for batch bioprocess optimization, Computers & Chemical Engineering 133 (2020) 106649. https://doi.org/https://doi. org/10.1016/j.compche meng.2019.106649 . [19] H. Y oo, H.E. Byun, D. Han, J.H. L ee, Rein forcement learning for b atch process control: Review and p erspectives, Annual Reviews in C ontrol 52 (2021) 108 –119. https://doi.org/https://doi. org/10.1016/j.arc ontrol.2021.10.006 . [20] R. Lin, J. Chen, L. Xie, H. Su, Accelerating reinforcement learning with case-based model-assisted experience augmentation for pro cess control, Neural Net works 158 (2023) 197–215. https://doi.org/ https://doi.org/10.1016/j.neune t.2022.10.016 . [21] R. Lin, Y . Luo, X. W u, J. Chen, B. Huang, H. Su, L. Xie, Surrogate empowered Sim2Real tra nsfer of deep reinforcement le arning for ORC superheat c ontrol, Applied Ener gy 356 (2024) 122310. https://doi.org/https://doi.or g/10.1016/j.apener gy .2023.122310 . [22] R . Lin, J. Chen, L. Xie, H. Su, B. Huang, Facilitating Reinforcement Learning for Process Control Using T ransfer Learning: Perspectives, 2024, p. arXiv:2404.00247. [23] R. Lin, J. Chen, B. Huang, L. Xie, H. Su, Developing P urely Data -Driven Multi - 39 / 39 Mode Process Controllers Using Inverse Reinforcement L earning, in: F . Manenti, G.V . Reklaitis (Eds.), Computer Aided Chemical Engineering, Elsevier2024, pp. 2731 –2736. https://doi.org/https://doi. org/10.1016/B978-0-443-28824-1.50456-7 . [24] Z. Li, R. Lin, H. Su, L. Xie, Reinforcement learning-driv en plant-wide refinery planning using model decomposition, Computers & Chemical Engineering 204 (2026) 109348. https://doi.org/https://doi. org/10.1016/j.compche meng.2025.109348 . [25] M. Bloor , A. Ahm ed, N. Kotecha, M. Mercangöz, C. T say , E.A. del Río -Chanona, Control-Informed Reinforcement Learning for Chemical Processes, Industrial & Engineering Chemistry Research 64(9) (2025) 4966–4978. https://doi.org/10.1021/acs.iec r .4c03233 . [26] R.E. Ka lman, A New Approach to Linear F iltering and Pre diction Pro blems, Journa l of Basic Engineering 82(1) (1960) 35–45. https://doi.org/10.1 1 15/1.3662552 . [27] R.J. Meinhold, N.D. Singpurwalla, Unde rstanding the Kalman Filte r , The American Statistician 37(2) (1983) 123–127. https://doi.org/10.1080/00031305.1983.10482723 . [28] K.S. Lee, J.H. Lee, Iterative learning control-based batch process control technique for integrated control of end produ ct properties and transient profiles o f process v ariables, Journal of Proce ss Control 13(7) (20 03) 607–621. https://doi.org/https://doi. org/10.1016/S0959-1524(02)00096-3 . [29] P .-C. Lu, J. Chen, L. Xie, Iterative Learning Control (ILC) -Based Economic Optimization for Batch P rocesses Using Helpful Dist urbance Information, Industrial & Engineering Chemistry Researc h 57(10) (2018) 3717 –3731. https://doi.org/10.1021/a cs.iecr .7b04691 . [30] Z. Xie, Z. Lin, J. Li, S. Li, D. Y e, Pretraining in Deep Reinforcement Learning: A Survey , 2022. https:/ /doi.or g/10.48550/arXiv .221 1.03959 . [31] J. S chulman, F . W olski, P . Dhariwal, A. Radford, O. Klimov , Pr oximal Policy Optimization Algorithms, Advances in Ne ural I nformation Processing Systems (NeurIPS 2017), 2017, p. arXiv:1707.06347.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment