계산 제한 지능을 위한 새로운 정보 개념: 에피플렉시티
이 논문은 기존의 샤논 엔트로피와 콜모고로프 복잡도가 계산 자원이 무한한 관찰자를 전제로 하여 데이터의 구조적 가치를 제대로 평가하지 못한다는 점을 지적한다. 저자들은 “에피플렉시티(epiplexity)”라는 새로운 정보 측정값을 정의하고, 이를 통해 계산 제한된 관찰자가 데이터에서 추출할 수 있는 구조적(예측 가능한) 정보를 정량화한다. 에피플렉시티는 시간 제한 엔트로피와 구분되며, 데이터 순서와 결정적 변환에 의해 증가할 수 있다. 논문은 …
저자: Marc Finzi, Shikai Qiu, Yiding Jiang
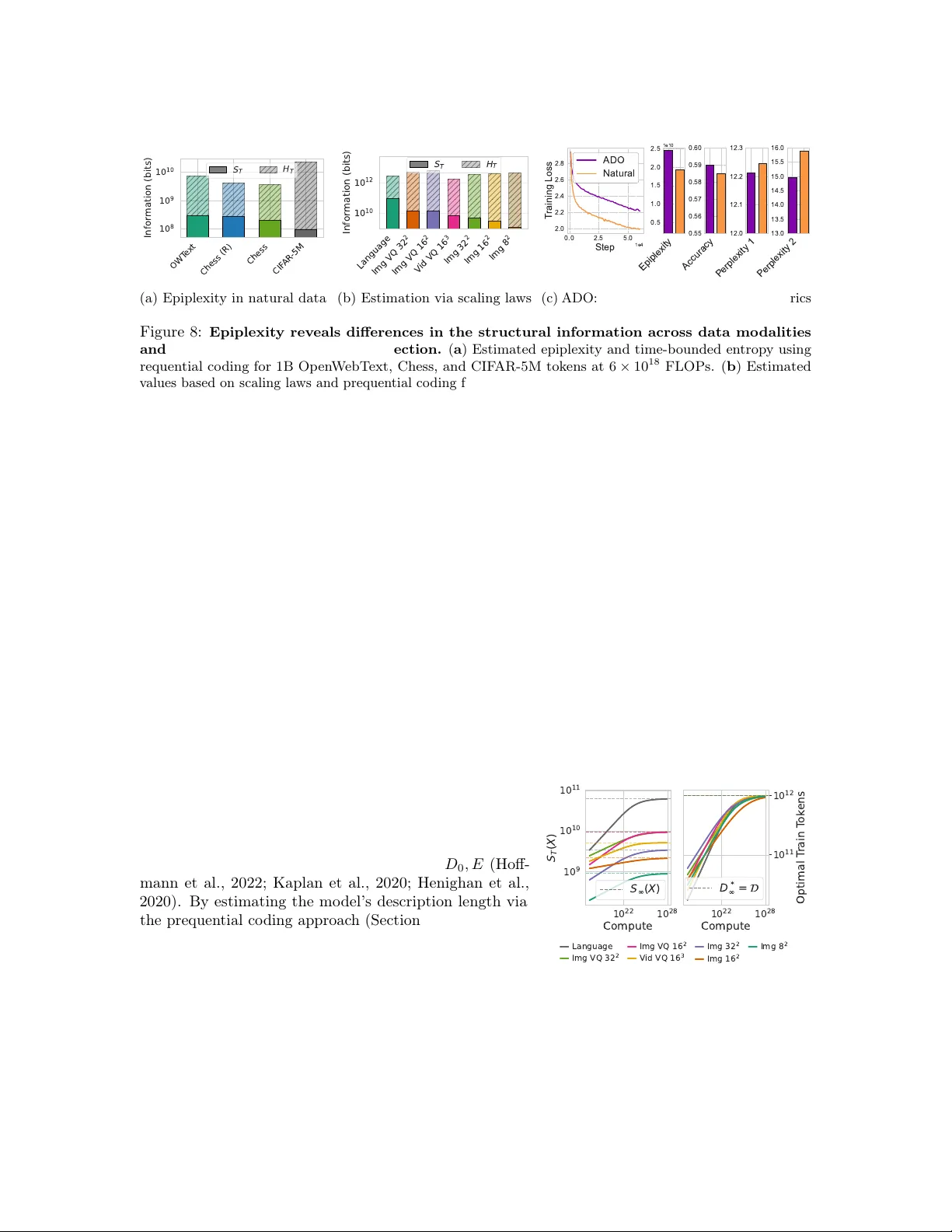
본 논문은 현대 인공지능 시스템이 데이터의 양과 질에 크게 의존한다는 사실을 출발점으로, 기존 정보 이론이 제공하는 샤논 엔트로피와 콜모고로프 복잡도가 계산 자원이 무한한 관찰자를 전제로 하기 때문에 실제 머신러닝 실무에서 관찰되는 현상을 설명하지 못한다는 문제를 제기한다. 저자들은 세 가지 “패러독스”를 제시한다. 첫 번째는 **결정적 변환이 정보를 증가시킬 수 없다는 정리**인데, 실제로 의사난수 생성, 합성 데이터, AlphaZero와 같은 자기 플레이 루프 등에서 새로운 구조적 정보가 생성되는 사례가 있다. 두 번째는 **데이터 순서가 정보량에 영향을 주지 않아야 한다는 가정**인데, LLM이 좌‑우 순서에 따라 학습 효율이 달라지고, 암호학적 일방향 함수가 존재한다는 점은 순서 의존성을 시사한다. 세 번째는 **최대우도 학습이 단순히 데이터 분포를 맞추는 것에 불과하다는 주장**인데, 실제로 모델은 데이터 생성 과정에 명시되지 않은 고차원 프로그램(예: 게임 오브 라이프의 emergent 패턴)을 학습한다.
이러한 모순을 해소하기 위해 논문은 **에피플렉시티(epiplexity)** 라는 새로운 정보 측정값을 도입한다. 에피플렉시티는 **시간‑제한 엔트로피(time‑bounded entropy)** 와 구분되어, 무작위성(예: PRNG, 혼돈 시스템의 예측 불가능한 부분)을 제외하고, 계산 제한된 관찰자가 데이터에서 추출할 수 있는 구조적(예측 가능한) 정보를 정량화한다. 정의 8에 따르면, 에피플렉시티는 “관찰자가 제한된 연산 자원 내에서 데이터의 압축 가능한 패턴을 얼마나 많이 발견했는가”를 의미한다. 이는 모델이 가중치에 내재화한 설명 길이(description length)를 최소화하는 정도와 직접 연결된다.
에피플렉시티를 실용적으로 추정하기 위해 두 가지 방법을 제시한다. 첫 번째는 **학습 곡선 손실 곡선 아래 면적(AUC‑loss)** 으로, 초기 손실 감소 속도가 빠를수록 더 많은 구조적 정보를 흡수한다는 가정이다. 두 번째는 **교사‑학생 모델 간 누적 KL 발산(cumulative KL)** 으로, 교사 모델이 제공하는 최적 분포와 학생 모델이 도달한 분포 사이의 차이를 적분해 에피플렉시티를 측정한다. 두 방법 모두 실제 실험에서 서로 높은 상관관계를 보이며, 에피플렉시티를 정량화하는 데 유용함을 입증한다.
실험 섹션에서는 세 가지 주요 현상을 확인한다. (5.1) **합성 데이터 생성** 실험에서는 셀룰러 오토마톤, Lorenz 시스템 등을 시뮬레이션함으로써 순수 계산 과정이 새로운 구조적 정보를 창출한다는 것을 보였다. (5.2) **데이터 순서 변형** 실험에서는 동일한 데이터셋을 다른 순서로 제공했을 때 에피플렉시티가 크게 변하지만 훈련 손실은 오히려 악화되는 현상을 관찰했다. 이는 순서가 메타정보로서 구조적 패턴을 드러내는 역할을 함을 의미한다. (5.3) **최대우도 학습** 실험에서는 단순 분포 매칭을 넘어 모델 내부에 새로운 프로그램(예: 게임 오브 라이프의 glider, Lorenz attractor의 불변 측도)이 형성되는 것을 확인했다. 이는 모델이 데이터 생성 과정에 명시되지 않은 복잡한 규칙을 학습할 수 있음을 보여준다.
마지막으로 (6)에서는 **대규모 텍스트와 이미지 데이터셋**에 대한 에피플렉시티 측정 결과가 OOD(Out‑of‑Distribution) 일반화 성능과 높은 상관관계를 보이며, **데이터 선택 전략**(예: 고에피플렉시티 샘플 우선 선택, 데이터 순서 재배열)이 실제 모델의 전이 학습 효율을 크게 향상시킴을 입증한다. 특히, 텍스트 데이터가 이미지 데이터보다 높은 에피플렉시티를 갖는 이유를 설명하고, 최근 LLM 훈련에 성공적인 데이터 필터링 기법이 에피플렉시티 기반이라는 점을 제시한다.
결론적으로, 에피플렉시티는 **계산 제한된 관찰자**가 데이터에서 얻을 수 있는 구조적 정보를 정량화함으로써, 기존 정보 이론이 설명하지 못한 현대 AI의 여러 현상을 일관되게 설명한다. 이는 데이터 선택·생성·변환을 위한 이론적 토대를 제공하고, 앞으로 데이터 중심 AI 연구에 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기