From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without consi…
Authors: Marc Finzi, Shikai Qiu, Yiding Jiang
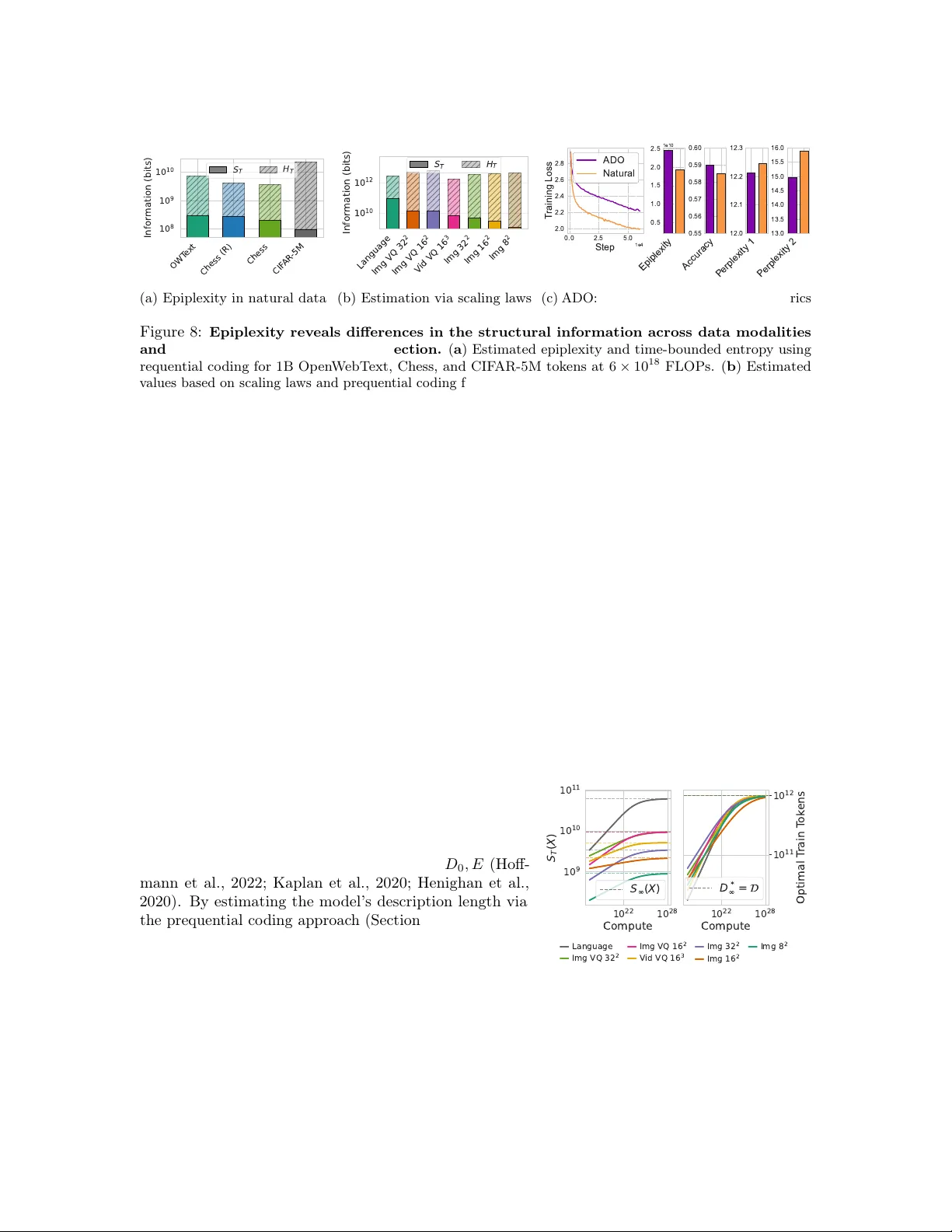
F rom En trop y to Epiplexit y: Rethinking Information for Computationally Bounded In telligence Marc Finzi ∗ 1 Shik ai Qiu ∗ 2 Yiding Jiang ∗ 1 P av el Izmailo v 2 J. Zico K olter 1 Andrew Gordon Wilson 2 1 Carnegie Mellon Universit y 2 New Y ork Univ ersity Abstract Can w e learn more from data than existed in the generating pro cess itself ? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable conten t in data b e ev aluated without considering a downstream task? On these questions, Shannon information and Kolmogoro v complexity come up nearly empty-handed, in part b ecause they assume observ ers with unlimited computational capacity and do not target the useful information con tent. In this work, w e identify and exemplify three seeming parado xes in information theory: (1) information cannot b e increased by deterministic transformations; (2) information is indep enden t of the order of data; (3) likelihoo d mo deling is merely distribution matching. T o shed ligh t on the tension b et ween these results and mo dern practice, and to quantify the v alue of data, w e introduce epiplexity † , a formalization of information capturing what computationally b ounded observ ers can learn from data. Epiplexity captures the structural conten t in data while excluding time-b ounded entrop y , the random unpredictable conten t exemplified b y pseudorandom num b er generators and chaotic dynamical systems. With these concepts, w e demonstrate how information can b e created with computation, how it dep ends on the ordering of the data, and how likelihoo d mo deling can pro duce more complex programs than present in the data generating pro cess itself. W e also presen t practical pro cedures to estimate epiplexit y which we show capture differences across data sources, track with downstream p erformance, and highlight dataset interv entions that impro ve out-of-distribution generalization. In contrast to principles of mo del selection, epiplexity pro vides a theoretical foundation for data sele ction , guiding how to select, generate, or transform data for learning systems. 1 In tro duction As AI research progresses tow ards more general-purp ose in telligent systems, cracks are b eginning to show in mec hanisms for grounding mathematical intuitions. Much of learning theory is built around controlling generalization error with respect to a giv en distribution, treating the training distribution as fixed and fo cusing optimization effort on the choice of mo del. Y et mo dern systems are exp ected to transfer across tasks, domains, and ob jectiv es that w ere not sp ecified at training time, often after large-scale pretraining on diverse and heterogeneous data. In this regime, success or failure frequently hinges less on architectural choices than on what data the mo del w as exp osed to in the first place. Pursuing broad generalization to diverse out-of-distribution tasks forces a shift in p erspective: instead of treating data as given and optimizing for in-distribution p erformance, we need to c ho ose and curate data to facilitate generalization to unseen tasks. This shift mak es the v alue of data itself a cen tral question—how muc h usable, transferable information can a mo del acquire from training? In other w ords, instead of mo del selection, how do w e p erform data sele ction ? On this question, existing theory offers little guidance and often naively contradicts empirical observ ations. * Equal contribution. † Code av ailable at https://github.com/shikaiqiu/epiplexity . 1 Entropy Epiplexity Computation Information can be created by computation Random vs structural information Structural information OOD generalization Entropy Epiplexity Entropy Epiplexity OOD performance Initial Condition Emergent Structure Apparent Randomness Deterministic Dynamics API_KEY = "sk_7aF2jK1ycP9LmvYzz34" USER_ID = "usr_4f8a2c1e9b7d3065" BUCKET = "s3://data-8a3f1b-west-prod" SAVE_DIR = "/mnt/marc/exp_7f2a/ckpts" SAVE_CKPT = True DEBUG = False SEED = 9284715 ... High random info, low structural info Low random info, low structural info def is_even ( n ): if n == 0 : return True elif n == 1 : return False elif n == 2 : return True elif n == 3 : return False elif n == 4 : return True elif n == 5 : return False ... Reuse shared circuits, subprograms, ... Moderate random info, high structural info def dijkstra ( g , s ): D = defaultdict ( lambda : float ( 'inf' )) D [ s ] = 0 ; q = [( 0 , s )] while q : d , u = pop ( q ) if d == D [ u ]: for v , w in g . get ( u , []): if ( nd := d + w ) < D [ v ]: D [ v ] = nd ; push ( q , ( nd , v )) return D Figure 1: Random vs structural information for computationally bounded observers. ( Left ) Illustration of random vs structural information of different data for computationally b ounded observers, whic h we formalize with time-b ounded entrop y and epiplexity (Section 3) and can be estimated from loss curv es of neural netw orks trained on that data (Section 4). ( T op Righ t ) Unlike other forms of information, time-b ounded entrop y and epiplexity can b e increased through computational pro cesses, suc h as simulating dynamical systems (cellular automation, Lorenz equations) and in terven tions like changing the data ordering, whic h can pro duce apparent randomness but also learnable, emergent structures like gliders and the Lorenz attractor inv ariant measure (Section 5). ( Bottom Right ) Whereas time-b ounded entrop y captures the in-distribution randomness and unpredictabilit y , epiplexity measures the amount of structural information the mo del extracts from the data to its weigh ts, which can b e useful for OOD tasks such as b y reusing learned circuits shared b et ween the in-distribution and OOD tasks. Consider syn thetic data, crucial for further de v eloping mo del capabilities (Ab din et al., 2024; Maini et al., 2024) when existing natural data are exhausted. Existing concepts in information theory lik e the data pro cessing inequality app ear to suggest that synthetic data adds no additional v alue. Questions ab out what information is transferred to a given mo del seem naturally within the purview of information theory , yet, quantifying this information with existing to ols pro ves to b e elusive. Even basic questions, such as the source of the information in the weigh ts of an AlphaZero game-playing mo del (Silver et al., 2018), are surprisingly tricky to answer. AlphaZero takes in zero human data, learning merely from the deterministic rules of the game and the AlphaZero RL algorithm, b oth of whic h are simple to describ e. Y et the resulting models achiev e superhuman p erformance and are large in size. T o assert that AlphaZero has learned little to no information in this pro cess is clearly missing the mark, and yet b oth Shannon and algorithmic information theory app ear to sa y so. In this paper, we argue that the amount of structural information a c omputational ly b ounde d observ er can extract from a dataset is a fundamental concept that underlies many observed empirical phenomena. As we will sho w, existing notions from Shannon and algorithmic information theory are inadequate when forced to quantify this type of information. These frameworks often lend intuitiv e or mathematical supp ort to b eliefs that, in fact, obscure imp ortant asp ects of empirical phenomena. T o highligh t the limitations of classical frameworks and motiv ate the role of computational constraints in quantifying information, we identify and demonstrate three app ar ent p ar adoxes : statements which can b e justified mathematically by Shannon and algorithmic information theory , and yet are in tension with in tuitions and empirical phenomena. 2 P aradox 1: Information cannot b e increased b y deterministic pro cesses. F or b oth Shannon en tropy and K olmogoro v complexit y , deterministic transformations cannot meaningfully increase the information con ten t of an ob ject. And y et, we use pseudorandom n umber generators to pro duce randomness, synthetic data improv es mo del capabilities, mathematicians can derive new knowledge by reasoning from axioms without external information, dynamical systems pro duce emergen t phenomena, and self-play lo ops like AlphaZero learn sophisticated strategies from games (Silver et al., 2018). P aradox 2: Information is indep enden t of factorization order. A property of b oth Shannon en tropy and Kolmogoro v complexity is that total information conten t is inv ariant to factoriza- tion: the information from observing first X and then Y is the same as observing Y follo wed b y X . On the other hand, LLMs learn b etter on English text ordered left-to-right than rev erse ordered text, picking out an “ arr ow of time ” (Papadopoulos et al., 2024; Bengio et al., 2019), and w e hav e cryptography built on the existence of functions that are computationally hard to predict in one direction and easy in another. P aradox 3: Lik eliho o d modeling is merely distribution matc hing. Maximizing the likelihoo d is often equated with matching the training data generating pro cess: the true data-generating pro cess is a p erfect mo del of itself, and no mo del can achiev e a higher exp ected likelihoo d. As a consequence, it is often assumed that a mo del trained on a dataset cannot extract more structure or learn useful features that w ere not used in generating the data. Ho wev er, w e sho w that a computationally-limited observer c an in fact unco ver m uch more structure than is in the data generating pro cess. F or example, in Con w ay’s game of life the data are generated via simple programmatic rules that op erate on tw o-dimensional arrays of bits. Applying these simple rules sequentially , we see emergent structures, such as different sp ecies of ob jects that mo ve and interact in a predictable wa y . While an unbounded observer can simply simulate the evolution of the en vironment exactly , a computationally b ounded observ er would make use of the emergent structures and learn the different types of ob jects and their b eha viors. The tension b etw een these theoretical statemen ts and empirical phenomena can b e resolv ed by imp os- ing computational constraints on the observer and separating the random conten t from the structural con tent. Dra wing on ideas from cryptograph y , algorithmic information theory , and these unexplained empirical phenomena, w e define a new information measure, epiplexit y (epistemic complexit y), whic h formally defines the amoun t of structural information that a computationally b ounded observer can extract from the data (Section 3, Definition 8). Briefly , epiplexity is the information in the mo del that minimizes the description length of data under computational constraints. A simple heuristic measuremen t is the area under the loss curve ab o ve the final loss, while a more rigorous approac h uses the cum ulative KL divergence b et ween a teacher and student mo del (Section 4, Figure 2). Our definitions capture the intuition that an ob ject contains b oth random, inherently unpredictable information (entrop y), and predictable structured information that enables observers to generalize b y identifying patterns (epiplexit y). In Figure 1 (left) w e illustrate this divide. In the top row, we ha ve highly redundant and rep etitive co de and simple color gradients, which hav e little information con tent, b e it structural or random. In the middle row, we hav e the inner workings of an algorithm and pictures of animals, showing complex, long-range interdependencies b et ween the elements from whic h a mo del can learn complex features and sub circuits that are helpful even for different tasks. In contrast, on the b ottom, we hav e random data with little structure: configuration files with randomly generated API keys, file paths, hashes, arbitrary b oolean flags hav e negligible learnable con tent and no long-range dep endencies or complex circuits that result from learning on this task. Similarly , uniformly shuffled pixels from the animal pictures hav e high entrop y but are fundamentally unpredictable, and no complex features or circuits arise from training on these data. 3 An essential prop erty of our form ulation is that information is observer dep endent : the same ob ject may app ear random or structured dep ending on the computational resources of the observer. F or instance, the output of a strong pseudorandom generator app ears indistinguishable from true randomness to any p olynomial-time observer lacking the secret key (seed), regardless of the algorithm or function class. In other situations, such as c haotic dynamical systems, b oth apparently random b eha vior is pro duced along with structure: the state of the system cannot b e predicte d precisely o ver long time-scales, but such observers may still learn meaningful predictive distributions, as shown by the in v ariant measure in Figure 1 (top righ t). Mo dels trained to represent these distributions are computer programs, and substructures within these programs, like circuits for p erforming sp ecific tasks, or induction heads (Olsson et al., 2022), can b e reused ev en for seemingly unrelated data. This view motiv ates selecting high epiplexity data that induces more structural information in the model, since these structures can then b e reused for unseen out-of-distribution (OOD) tasks, as illustrated in Figure 1 (b ottom right). W e emphasize, ho wev er, that epiplexit y is a measure of information, not a guaran tee of OOD generalization to sp ecific tasks. Epiplexit y quantifies the amount of structural information a mo del extracts, while b eing agnostic to whether these structures are relev ant to a sp e cific do wnstream task. T o build intuition, we explore a range of phenomena and provide exp erimental evidence for b eha viours that are p o orly accounted for b y existing information-theoretic to ols, y et naturally accommo dated b y epiplexity . W e sho w that information c an b e created purely through computation, giving insights in to synthetic data (subsection 5.1). W e examine how certain factorizations of the same data can increase structural information and downstream OOD p erformance—ev en as they result in worse training loss (subsection 5.2). W e show why likelihoo d mo deling is more than distribution matc hing, iden tifying induction and emergence as tw o settings where the observer can learn more information than was present in the data generating pro cess (subsection 5.3). By measuring epiplexity , we can b etter understand why pre-training on text data transfers more broadly than image data, and why certain data selection strategies for LLMs are empirically successful (Section 6). T ogether, our results provide clarity on the motiv ating questions: the information conten t of data can b e compared indep enden tly of a sp ecific task, new information can b e created b y computation, and mo dels can learn more information than their generating pro cesses contain. In short, we identify a disparity b etw een existing concepts in information theory and mo dern practice, em b o died b y three apparen t parado xes, and in troduce epiplexit y as a measuremen t of structural information acquired by a computationally bounded observ er to help resolve them. W e formally define epiplexity in Section 3 (Definition 8) and present measurement pro cedures in Section 4. In Section 5, w e show how epiplexity and time-b ounded entrop y shed light on these parado xes, including induction and emergent phenomena. Finally , in Section 6, we demonstrate that epiplexity correlates with OOD generalization, helping explain why certain data enable broader generalization than others. 2 Bac kground In order to define the in terestin g, structural, and predictiv e comp onent of information, w e must separate it out from random information—that which is fundamentally unpredictable given the computational constraints of the observer. Along the wa y , we will review algorithmic randomness as dev elop ed in algorithmic information theory as w ell as notions of pseudo-randomness used in cryptograph y , and how these concepts crucially dep end on the observer. 4 2.1 What Do es it Mean for An Ob ject to Be Random? Random V ariables and Shannon Information. Man y common intuitions ab out randomness start from random v ariables and Shannon information. A random v ariable defines a map from a giv en measurable probability space to different outcomes, with probabilities corresp onding to the measure of the space that lead to a certain outcome. Shannon information assigns to each outcome x a self-information (or surprisal) log 1 /P ( x ) based on the probability P , and an en tropy for the random v ariable H( X ) = E [ log 1 /P ( X )] , which provides a lo wer b ound on the av erage co de length needed to c ommunic ate samples to another party (Shannon, 1948). In Shannon’s theory , information comes only from distributions and random v ariables—ob jects that are not random must contain no information. As a result, non-random information is seemingly contradictory , and thus we must draw from a broader mathematical p ersp ective to describ e such concepts. In the mid 1900s, mathematicians were interested in formalizing precisely what it means for a given sample to be a random draw from a given distribution, to ground the theory of probability and random v ariables (Shafer and V o vk, 2006). A central consideration inv olves a uniformly sampled binary sequence u 1: ∞ from which other distributions of interest can b e constructed. This sequence can also b e interpreted as the binary expression of a num b er [0 , 1) . Intuitiv ely , one might think that all sequences should b e regarded as equally random, as they are all equally likely according to the probabilit y distribution: 1111111 . . . has the same probability mass as 10011101 . . . and also the same self-information. How ever, lo oking at statistics on these sequences reveals something missing from this p erspective; from the law of large num bers, for example, it must b e that lim N →∞ 1 N P N i =1 u i = 0 . 5 , whic h is clearly not satisfied by the first sequence of 1 s. Martin-Löf Randomness: No algorithm exists to predict the sequence. Initial attempts w ere made to formalize randomness as sequences which pass all statistical tests for randomness, such as the law of large num b ers for selected substrings. How ever, under such definitions all sequences fail to b e random since tests like u 1: ∞ = y 1: ∞ for any particular sequence y m ust also b e included (Do wney and Hirsc hfeldt, 2019). The solution to these issues was found by defining random sequences not as those that pass all tests of randomness, but those that pass all c omputable tests of randomness, in a formalization known as Martin-Löf randomness (Martin-Löf, 1966). As it turned out, this definition is equiv alent to a num b er of seemingly distinct definitions, such as the inability for any gam bler to exploit prop erties of the sequence to make a profit, or that all prefixes of the random sequence should b e nearly incompressible (T erwijn, 2016). F or this last definition, w e must inv ok e K olmogorov complexity , a notion of compressibility and a key concept in this pap er. Definition 1 (Prefix K olmogorov complexit y (K olmogorov, 1968; Chaitin, 1975)) Fix a universal pr efix-fr e e T uring machine U . The (pr efix) Kolmo gor ov c omplexity of a finite binary string x is K ( x ) = min { | p | : U ( p ) = x } . That is, K ( x ) is the length of the shortest self-delimiting pr o gr am (a pr o gr am which also enc o des its length) that outputs x and halts. The c onditional c omplexity K ( x | y ) is the length of the shortest pr o gr am that outputs x and halts when pr ovide d y as input. Due to the universalit y of T uring machines, the Kolmogoro v complexity for tw o T uring machines (or programming languages) U 1 and U 2 differ b y at most a constant, | K U 1 ( x ) − K U 2 ( x ) |≤ C , where the constan t C dep ends only on U 1 , U 2 , but not on x (Li et al., 2008). Definition 2 (Martin–Löf random sequence (Martin-Löf, 1966)) An infinite se quenc e x 1: ∞ ∈ { 0 , 1 } N is Martin–L öf r andom iff ther e exists a c onstant c such that for al l n , K ( x 1: n ) ≥ n − c . Using this criterion, al l c omputable r andomness tests ar e c ondense d into a single inc omputable r andomness test c onc erning Kolmo gor ov c omplexity. 5 One can extend Martin-Löf randomness to finite sequences. W e say that a sequence x ∈ { 0 , 1 } n is c -random if K ( x ) > n − c . Equiv alen tly , r andomness discr ep ancy is defined as δ ( x ) = n − K ( x ) , whic h measures how far a w ay x is from ha ving maxim um Kolmogoro v complexit y . A sequence x is c -random if δ ( x ) < c . High Kolmogoro v complexity , lo w randomness discrepancy , sequences are o verwhelmingly likely when sampled from uniform randomly sampled random v ariables. F rom Kraft’s inequalit y (Kraft, 1949; McMillan, 1956), there are at most 2 n − c (prefix-free) programs of length L ≤ n − c , therefore in the 2 n p ossibilities in uniformly sampling X ∼ U n , the probability that K ( X ) is size L or smaller is P ( K ( X ) ≤ n − c ) = P ( δ ( X ) ≥ c ) < 2 − c . The randomness discrepancy of a sequence can thus b e viewed as a test statistic for rejecting the null hypothesis that the ob ject X w as indeed sampled uniformly at random (Grünw ald et al., 2008). F or a sequence to ha v e low randomness discrepancy , it m ust exhibit no discernible pattern, and thus there is an ob jective sense in whic h 1001011100 is more random than 0101010101 . Giv en the Martin-Löf definition of infinite random sequences, every random sequence is incomputable; in other words, there is no program that can implement the function N → { 0 , 1 } whic h pro duces the bits of the sequence. One should contrast such random num b ers from those like π / 4 or e/ 3 , which though transcenden tal, are computable, as there exist programs that can compute the bits of their binary expressions. While the computable num bers in [0 , 1) form a countable set, algorithmically random num b ers in [0 , 1) are uncountably large in num b er. With the incomputability of random sequences in mind we can appreciate the V on Neumann quote “A nyone who c onsiders arithmetic al metho ds of pr o ducing r andom digits is, of c ourse, in a state of sin.” (V on Neumann, 1951) whic h anticipates the Martin–Löf formalization that came later. But this viewp oin t also misses some- thing essen tial, as evidenced by the success of pseudorandom num b er generation, derandomization, and cryptograph y . Cryptographic Randomness: No p olynomial time algorithm exists to predict the se- quence. An imp ortan t practical and theoretical developmen t of random num b ers has come from the cryptograph y communit y , by once again limiting the computational mo del of the observer. Rather than passing all computable tests as with Martin-Löf randomness, cryptographically secure pseudorandom num b er generators (CSPRNG or PR G) are defined as functions whic h produce sequences that pass all p olynomial time tests of randomness. Suc h functions are conjectured to b e constructible b y computer programs and are central to cryptographic research. Definition 3 (Non-uniform PR G (Blum and Micali, 1982; Goldreich, 2006)) A function G str etching k input bits into n output bits is a pseudor andom gener ator (PR G) if its outputs c annot b e distinguishe d fr om a r andom se quenc e by any p olynomial time algorithm mor e than a ne gligible fr action of the time. Mor e pr e cisely, G is a (non-uniform) PRG iff for every non-uniform pr ob abilistic p olynomial time algorithm D k : { 0 , 1 } n → { 0 , 1 } (making use of advic e strings { a k } k ∈ N of length p oly ( k ) ) has at most ne gligible advantage ϵ ( k ) distinguishing outputs of G fr om uniformly r andom se quenc es u ∼ U n : Pr s ∼ U k [ D n ( G ( s )) = 1] − Pr u ∼ U n [ D n ( u ) = 1] = ϵ ( k ) < negl( k ) . 1 (1) The definition of indistinguishability via p olynomial time tests is equiv alen t to a definition on the failure to predict the next element of a sequence given the previous elemen ts: no p olynomial time 1. Here negl ( k ) means that the function decays faster than the recipro cal of any p olynomial, i.e., negl ( k ) < 1 k c for all integers c > 0 and sufficiently large k . 6 predictor can predict the next bit of the sequence with probability negligibly b etter than random guessing (Y ao, 1982). F ollowing from the indistinguishabilit y definition, randomness of this kind can b e substituted for Martin-Löf randomness in the v ast ma jorit y of practical circumstances. 2 F or a concrete example, if a use-case of randomness that runs in p olynomial time like quicksort, and tak es more iterations to run with PRG sequences than with truly random sequences, and this difference could b e determined within p olynomial time suc h as b y measuring the quicksort runtime, then this construction could b e used as a p olynomial time distinguisher, whic h by the definition of PR G do es not exist. If PRGs exist, then quicksort must run nearly as fast using pseudorandom n um b er generation as it does with truly random s equences. The existence of PRGs hinges on the existence of one way functions (OWF), from whic h PR Gs and other cryptographic primitiv es are constructed, forming the basis of mo dern cryptography (Goldreic h and Levin, 1989). F or example, the backbone algorithm for parallel random num ber generation in Jax (Bradbury et al., 2018), w orks to create random n um b ers u 1 , u 2 , . . . u N b y simply encrypting the num b ers 1 , 2 , . . . , N : u k = E ( k , s ) where the encryption key s is the random seed and E is the threefish blo c k cypher (Salmon et al., 2011). Blo c k ciphers, like other primitives, are constructed using one w ay functions. Definition 4 (Non-uniform one-w ay function, O WF (Y ao, 1982; Goldreic h, 2006)) L et f : { 0 , 1 } n → { 0 , 1 } m (with m > n ) b e c omputable in time p oly ( n ) wher e n = | x | . W e say f is one-wa y against non-uniform PPT adversaries if for every non-uniform pr ob abilistic p olynomial time algorithm A n (i.e., a p olynomial-time algorithm A with advic e strings { a n } n ∈ N of length p oly( n ) ), Pr x ∼ U n A n ( f ( x )) ∈ f − 1 ( f ( x )) < negl( n ) , wher e the pr ob ability is over the uniform choic e of x (and any internal r andomness in A ). While cryptographers are most interested in the p olynomial versus nonp olynomial compute separations for security , cryptographic primitives with resp ect to less extreme compute separations hav e b een constructed and are b eliev ed to exist, for example for quadratic time (Merkle, 1978), quasip olynomial time (Liu and Pass, 2024), and ev en constrain ts on circuit depth (Applebaum, 2016). While the results w e prov e in this pap er are based on the p olynomial vs nonp olynomial separation in cryptographic primitiv es, it seems likely that a muc h wider array of compute separations are relev ant for information in the mac hine learning con text even if not as imp ortant for cryptograph y . F or example, the separations b etw een quadratic or cubic time and higher order p olynomials may b e relev ant to transformer self atten tion, or gaps b etw een fixed circuit depth and v ariable depth as made p ossible with c hain of thought or other mechanisms. 2.2 Random vs Structural Information With these notions of randomness in hand, we can use what is random to define what is not random. In algorithmic information theory , there is a lesser known concept that captures exactly this idea, kno wn as sophistic ation (Koppel, 1988), which has no direct analog in Shannon information theory . While sev eral v ariants of the definition exist, the most straigh tforward is p erhaps the following: Definition 5 (Naiv e Sophistication (Mota et al., 2013)) Sophistic ation, like Kolmo gor ov c om- plexity, is define d on individual bitstrings, and it uses the c ompr essibility criterion fr om Martin-L öf 2. Specifically , when the difference b etw een outcomes can b e measured in p olynomial time. 7 r andomness to c arve out the r andom c ontent of the bitstring. Sophistic ation is define d as the smal lest Kolmo gor ov c omplexity of a set S such that x is a r andom element fr om that set (at r andomness discr ep ancy of c ). nsoph c ( x ) = min S : { K ( S ) : K ( x | S ) > log | S |− c } (2) Informally , sophistication describ es the structural comp onent of an ob ject; how ev er, it is surprisingly difficult to give concrete examples of high sophistication ob jects. The difficulty of finding high sophistication ob jects is a consequence of Chaitin’s incompleteness theorem (Chaitin, 1974). This theorem states that in a given formal system there is a constant L for whic h there are no pro ofs that an y sp ecific string x has K ( x ) > L , even though nearly all strings hav e nearly maximal complexity . Since nsoph c ( x ) > L implies K ( x ) > L − O (1) , there can b e no pro ofs that the sophistication of a particular string exceeds a certain constant either. It is known that high sophistication strings exist b y a diagonalization argument (Antunes et al., 2005), but we cannot pinp oin t any sp ecific strings whic h hav e high sophistication. On typical T uring machines, L is often not more than a few thousand (Chaitin, 1998), far from the terabytes of information that frontier AI mo dels hav e enco ded. W e lo ok to wards complex systems and b ehaviors as likely examples of high sophistication ob jects; ho wev er in many of these cases the ob jects could conceiv ably b e pro duced by simpler descriptions giv en tremendous amounts of computation. The mixing of tw o fluids for example can pro duce extremely complex transient b ehavior due to the complexities of fluid dynamics; how ever, with access to unlimited computation and some appropriately chosen random initial data one should b e able to repro duce the exact dynamics (Aaronson et al., 2014). Owing to the un b ounded compute av ailable for the programs in sophistication, man y complex ob jects lose their complexity . A dditionally , for strings that do hav e high sophistication, the steps of computation required for the optimal program gro w faster than an y computable function with the sophistication conten t (A y et al., 2010). F or a computationally bounded observer, an encrypted message or a crypto gr aphic al ly se cur e pseudo- r andom numb er gener ator (CSPRNG) output is random, and measurements that do not recognize this randomness do not reflect the circumstances of this observer. These limitations of sophistication leads to a disconnect with real systems with observers that ha ve limited computation, and it is our con ten tion that this disconnect is an essen tial one, central to phenomena suc h as emergence, induction, c haos, and cryptography . 2.3 The Minim um Description Length Principle Finally , we review the minimum description length principle (MDL), used as a theoretical criterion for mo del selection, which we will use in defining epiplexity . The principle states that among mo dels for the data, the b est explanation minimizes the total description length of the data, including b oth the description of the data using the mo del and the description of the mo del itself (Rissanen, 2004). The most common instantiation of this idea is via the statistical tw o-part co de MDL. Definition 6 (T wo-part MDL (Rissanen, 2004; Grün w ald, 2007)) L et x ∈ { 0 , 1 } n × d b e the data and H b e a set of c andidate mo dels. The two-p art MDL is: L ( x ) = min H ∈H L ( H ) − log P ( x | H ) , wher e L ( H ) sp e cifies the numb er of bits r e quir e d to enc o de the mo del H , and − log P ( x | H ) is the numb er of bits r e quir e d to enc o de the data given the mo del. This formulation provides an in tuitive implementation of Occam’s Razor: complex mo dels (large L ( H ) ) are p enalized unless they pro vide a reduction in the data’s description length (large P ( x | H ) ). 8 If there are repeating patterns in the data, they can be stored in the mo del H rather than b eing duplicated in the co de for the data. W e review the mo dern developmen ts of MDL in App endix H. While MDL is a criterion for mo del selection given a fixed dataset, epiplexity , whic h we introduce next, can b e viewed as its dual: a criterion for data selection given a fixed computation budget. 3 Epiplexit y: Structural Information Extractable b y a Computationally Bounded Observer Keeping in mind the distinction b etw een structural and random information in the un b ounded compute setting, and the computational nature of pseudorandomness in cryptography , we now in tro duce epiplexity . Epiplexity captures the structural information present to a computationally b ounded observer. As the computational constraints of this observer c hange, so to o do es the division b et ween random and structured conten t. After introducing epiplexity here, we present wa ys of measuring epiplexity in Section 4. In Sections 5 and 6 w e show how epiplexity can shed light on seeming parado xes in information theory around the v alue of data, and OOD generalization. First w e will define what it means for a probability distribution to hav e an efficien t implementation, requiring that it b e implemented on a prefix-free universal T uring mac hine (UTM) and halt in a fixed n umber of steps. Definition 7 (Time-b ounded probabilistic mo del) L et T : N → N b e a non-de cr e asing time- c onstructible function and let U b e a fixe d pr efix-fr e e universal T uring machine. A (pr efix-fr e e) pr o gr am P is a T -time probabilistic mo del over { 0 , 1 } n if it supp orts b oth sampling and pr ob ability evaluation in time T ( n ) : Evaluation. On input (0 , x ) with x ∈ { 0 , 1 } n , U (P , (0 , x )) halts within T ( n ) steps and outputs an element in [0 , 1] (with a finite binary exp ansion), denote d Prob P ( x ) := U (P , (0 , x )) . Sampling. On input (1 , u ) wher e u ∈ { 0 , 1 } ∞ is an infinite r andom tap e, U (P , (1 , u )) halts within T ( n ) steps and outputs an element of { 0 , 1 } n , denote d Sample P ( u ) := U (P , (1 , u )) . These outputs must define a normalize d distribution matching the sampler: X x ∈{ 0 , 1 } n Prob P ( x ) = 1 and Pr u ∼ U ∞ [Sample P ( u ) = x ] = Prob P ( x ) ∀ x ∈ { 0 , 1 } n . L et P T b e the set of al l such pr o gr ams. T o simplify the notation, we wil l use italicize d P to denote the pr ob ability mass function Prob P in c ontr ast with the non-italicize d P , which denotes the pr o gr am. Here, n denotes the dimension of the underlying sample space (e.g., the length of the binary string.) This definition allows us to constrain the amount of computation the function class can use. Such a mo del class enforces that the functions of in terest are b oth efficiently sampleable and ev aluable, which include most sequence mo dels. While in this work we fo cus primarily on computational constraints whic h we consider most fundamental, other constraints such as m emory or within a given function class F can b e accommo dated by replacing P T with P F , and may b e imp ortan t for understanding 9 particular phenomena. 3 With these preliminaries in place, we can no w separate the random and structural comp onen ts of information. W e define epiplexit y and time-b ounded entrop y in terms of the program which achiev es the b est exp ected compression of the random v ariable X , minimizing the tw o-part co de length (mo del and data giv en mo del bits) under the given runtime constrain t. Definition 8 (Epiplexit y and Time-Bounded Entrop y) Consider a r andom variable X on { 0 , 1 } n . L et P ⋆ = arg min P ∈P T {| P | + E [log 1 /P ( X )] } (3) b e the pr o gr am that minimizes the time b ounde d MDL with ties br oken by the smal lest pr o gr am, and exp e ctations taken over X . | P | denotes the length of the pr o gr am P in bits, and lo garithms ar e in b ase 2 . W e define the T -b ounde d epiplexity S T and en tropy H T of the r andom variable X as S T ( X ) := | P ⋆ | , and H T ( X ) := E [log 1 /P ⋆ ( X )] . (4) The time-b ounded entrop y H T captures the amount of information in the random v ariable that is random and unpredictable, whereas the epiplexity S T captures the amoun t of structure and regularit y visible within th e ob ject at the given lev el of compute T . Uniform random v ariables ha ve trivial epiplexit y because a model (or equiv alen tly a program) as simple as the uniform distribution achiev es a small tw o-part code length, despite having large time-b ounded en tropy . Explicitly , for a uniform random v ariable U n on { 0 , 1 } n , and even a constant time b ound T ( n ) ≥ c 1 , S T ( U n ) + H T ( U n ) ≤ n + c 2 where c 2 is the length of a program for the uniform distribution running in time c 1 , and since H T ( U n ) ≥ H( U n ) = n , it must b e that S T ( U n ) ≤ c 2 . Random v ariables with simple patterns, like 0101010101 ... with probability 1 / 2 and 1010101010 ... with probability 1 / 2 , also ha ve lo w epiplexit y b ecause the time bounded MDL minimal mo del is simple. In this case with linear time T ( n ) = Θ( n ) , b oth S T ( X ) = O (1) and H T ( X ) = O (1) . Henceforth, we will abbreviate MDL T ( X ) := S T ( X ) + H T ( X ) , which is the total time-b ounded information conten t. W e will now en umerate a few basic consequences of these definitions. Basic Prop erties (1) S T ( X ) ≥ 0 , H T ( X ) ≥ 0 , (2) H( X ) ≤ S T ( X ) + H T ( X ) ≤ n + c 1 , (3) MDL T ′ ( X ) ≤ MDL T ( X ) whenev er T ′ ( n ) ≥ T ( n ) , (4) MDL T ′ ( f − 1 ( X )) ≤ MDL T ( X ) + | f | + c 2 , with T ′ ( n ) = T ( n ) + Time (f ) . Statemen t 4 (defined for programs f that run in a fixed time implementing a bijection) is an analog of the information non-increase prop erty K ( f ( x )) ≤ K ( x ) + K ( f ) + c . How ever, note that while the K olmogorov complexity for K ( f ) and K ( f − 1 ) are the same to within an additive constan t, in our setting of a fixed computational budget having a short program for f − 1 do es not imply one for f , 3. One such p ossibilit y is to constrain the function class to all mo dels reachable by a given optimization pro cedure with a given neural netw ork architecture. 10 and vice versa. This gap b et ween a function and its inv erse has imp ortan t consequences for the three parado xes as we will see in Section 5. Pseudorandom num b er sequences hav e high random con ten t and little structure. Unlike Shannon entrop y , Kolmogoro v complexity , or even resource b ounded forms of Kolmogoro v complexit y (Allender et al., 2011), we sho w that CSPRNGs hav e nearly maximal time-b ounded entrop y for p olynomial time observers. Additionally , while CSPRNGs pro duce random conten t, they do not pro duce structured conten t as the epiplexit y is negligibly larger than constant. F ormally , let U k b e the uniform distribution on k bits. Theorem 9 F or any G ∈ PRG that str etches the input to n = p oly ( k ) bits and al lowing for an advantage of at most ε ( k ) , the p olynomial time b ounde d entr opy is ne arly maximal: n − 2 − nε ( k ) < H Poly ( G ( U k )) ≤ n + c for a fixe d c onstant c , and epiplexity is ne arly c onstant S Poly ( G ( U k )) ≤ c + nε ( k ) . Pr o of: se e App endix A.1. In con trast, the Shannon entrop y is H( G ( U k )) = k , p olynomial time b ounded Kolmogoro v complexity will b e at most k + c (assuming n is fixed or sp ecified ahead of time) as there is a short and efficiently runnable program G whic h pro duces the output, and similarly with other notions such as Levin complexit y (Li and Vitányi, 2008) or time b ounded Kolmogoro v complexity (Allender et al., 2011). T aken together, these results show that epiplexity appropriately characterizes pseudorandom num b ers as carrying a large amount of time-b ounded randomness but essentially no learnable structure, exactly as in tuition suggests. Existence of Random V ariables with High Epiplexity . One may wonder whether any high epiplexit y random v ariables exist at all. Indeed, assuming the existence of one-w a y functions, we can show via a counting argument that there exists a sequence of random v ariables whose epiplexity gro ws at least logarithmically with the dimension. Theorem 10 Assuming the existenc e of one-way functions se cur e against non-uniform pr ob- abilistic p olynomial-time adversaries, ther e exists a se quenc e of r andom variables { X n } ∞ n =1 over { 0 , 1 } n such that S Poly ( X n ) = Ω(log n ) . Pr o of: se e App endix A.4. This result implies that epiplexity can b e unbounded; how ever, logarithmically growing information con tent only admits a very modest amount of structural information, still far from the p ow er law scaling w e see with some natural data. W e also note that the argument is nonconstructiv e and hence do es not compromise cryptographic security . Conditional En tropy and Epiplexit y . T o describ e situations like image classification, where we are only interested in a function which predicts the lab el from the image, and not the information in generating the images, we define c onditional time-b ounded entrop y and epiplexity . 11 Definition 11 (Conditional epiplexit y and time-b ounded entrop y) F or a p air of r andom variables X and Y , define P X T ( n ) as the set of pr ob abilistic mo dels P such that for e ach fixe d x , the c onditional mo del P Y | x is in P T ( n ) . The optimal c onditional mo del with ac c ess to X is: P ⋆ Y | X = arg min P ∈P X T | P | + E ( X,Y ) [ − log P ( Y | X )] . (5) The c onditional epiplexity and time-bounded entrop y ar e define d as: S T ( Y | X ) := P ⋆ Y | X , H T ( Y | X ) := E ( X,Y ) h − log P ⋆ Y | X ( y | x ) i . (6) These quantities ar e define d with r esp e ct to the time b ounde d MDL over pr o gr ams which take as input X, Y and output the pr ob abilities over Y (c onditione d on X ), and with exp e ctations taken over b oth X and Y . W e note that in gener al this definition is not e quivalent to the differ enc e of the joint and individual entr opies, H T ( Y , X ) − H T ( X ) = H T ( Y | X ) . Unlike Shannon entr opy, we c an also c ondition on deterministic strings, which wil l change the values on ac c ount of not ne e ding such a lar ge pr o gr am P . F or example, we may b e inter este d in the c onditional epiplexity S T ( X | m ) or entr opy H T ( X | m ) given a mo del m . F or a deterministic string d ∈ { 0 , 1 } ∗ we define the c onditional epiplexity via P ⋆ Y | d = min P ∈P { 0 , 1 } ∗ T {| P | + E Y [ − log P ( Y | d )] } , (7) wher e the minimization is over time b ounde d functions P ( · | · ) that take in the string d as the se c ond ar gument (which we r efer to as P { 0 , 1 } ∗ T ). F or the machine learning setting, we take the random v ariable X to refer to the entir e dataset of in terest, i.e. typically a collection X = [ X 1 , X 2 , . . . ] of many iid samples from a given distribution, rather than a lone sample from, and E [ log 1 /P ( X )] scales with the dataset size. Epiplexit y typically gro ws with the size of the dataset (see detailed arguments for why this is the case in Section B.4) as larger datasets allo w identifying and extracting more intricate structure and patterns, mirroring the practice of ML training. Moreov er, as we w ill see later, the epiplexity of a t ypical dataset is orders of magnitudes smaller than the random information conten t. While not a fo cus of this pap er, conditioning on deterministic strings op ens up the p ossibility to understand what additional data is most useful for a sp ecific machine learning mo del, such as on top of a pretrained LLM. 4 Measuring Epiplexity and Time-Bounded Entrop y W e ha v e now in tro duced epiplexity and time-bounded entrop y as measures of structural and random information of the data. In this section, we present practical pro cedures to estimate upp er b ounds and empirical pro xies for these quantities. Intuitiv ely , we wan t to find a probabilistic mo del P ( · ) of the data X that achiev es low exp ected loss E [ log 1 /P ( X )] , is describ ed by a short program P , and ev aluating P ( X ) takes time at most T ( | X | ) , whic h we will abbreviate as T . Using this mo del, we thereb y decomp ose the information of the data into its structural and random components, namely , (1) epiplexity S T ( X ) : the length of the program | P | , accoun ting for the bits required to mo del the data distribution, and (2) time-b ounded entrop y H T ( X ) : the expected length for entrop y co ding the data using this mo del, which accounts for the bits required to sp ecify the particular realization of X within that distribution. W e estimate conditional epiplexity analogously , providing random v ariable conditioning as input into the mo del. Since directly searching o ver the space of programs is intractable, we restrict atten tion to probabilistic mo dels parameterized by neural netw orks, as they achiev e strong empirical compression across data 12 # T rain T ok ens T rain NLL l o g 1 / P t D ( Z 0 , , Z D 1 ) l o g 1 / P t i ( Z i ) l o g 1 / P s i ( Z i ) | P p r e q | | P r e q | (a) Estimate information in mo del C o m p u t e ( T = 6 N D + 2 N ) | P | + E l o g 1 / P ( X ) H T ( X ) = E l o g 1 / P * ( X ) S T ( X ) = | P * | # P a r a m s ( N ) (b) Compute-optimal 2-part co de 0.0 0.5 1.0 0.0 2.5 5.0 ECA 0.1 0.5 0.9 4 5 6 Induct Easy 0.50 0.75 1.00 4 5 6 Induct Har d 10 30 50 10 50 90 Natural S p r e q ( M B ) S r e q ( M B ) (c) Requen tial vs Prequential Figure 2: Ho w to estimate epiplexity . ( a ) W e consider tw o approaches for efficiently co ding trained neural netw orks. Prequential estimation estimates information conten t as the area under the loss curve of a mo del ab ov e its final loss, with the training set matching the test data distribution. Requen tial co ding, whic h provides an explicit co de for P s with exp ected length as the cumulativ e KL b et ween a student mo del P s and the teacher P t that generates its synthetic training data, visualized approximately by their loss gap. W e t ypically choose P t to b e a mo del trained on the r e al training set, as in prequential co ding. ( b ) Using either app roac h, we optimize hyperparameters (model size N , training tokens D , etc.) to find the shortest t wo-part co de for each compute budget, which decomposes in to the estimated epiplexity and time-bounded en tropy . ( c ) Comparing prequential and requential co ding on four groups of datsets used in this work. The prequen tial estimate is typically larger, but the t wo correlate well, particularly within each group. mo dalities (MacKay, 2003; Goldblum et al., 2023; Delétang et al., 2023; Ballé et al., 2018) and capture the most relev an t ML phenomenology . While a naiv e approach is to let P b e a program that directly stores the architecture and weigh ts of a neural netw ork and ev aluates it on the giv en data, this approac h can significantly ov erestimate the information conten t in the weigh ts, particularly for large mo dels trained on relativ ely little data. Instead, w e will use a more efficien t approach that enco des the training pro cess that pro duces the weigh ts. W e will discuss tw o approaches for enco ding neural net work training pro cesses, based on pr e quential c o ding (Dawid, 1984) and r e quential c o ding (Finzi et al., 2026), resp ectively . The former is more straightforw ard to understand and ev aluate, but relies on a heuristic argume n t to separate structure bits from noise bits, while the latter is rigorous at the cost of b eing more difficult to ev aluate. F ortunately , b oth approac hes often yield comparable rankings of ep iplexit y across datasets (Section 4.3). Mo ving forward, w e will measure time b y the num b er of floating-point operations (FLOPs) and dataset size by num b er of tokens, so that training a mo del with N parameters on D tok ens takes time appro ximately 6 N D (Kaplan et al., 2020), while ev aluating it on X tak es time 2 N D with D = | X | the num b er of tokens in X. T o distinguish X from the training dataset, which we are free to choose, w e will refer to X as the test dataset, as it is the data we need to p erform inference on. 4.1 Appro ximating Mo del Description Length with Prequential Coding Prequen tial co ding provides a classic approach for compressing the training pro cess of a neural net work. W e assume a batc h size of one for simplicit y , but generalizing to batch sizes larger than one is straightforw ard. Starting with a randomly initialized netw ork P 0 (where the subscript indicates timestep), we pro ceed iteratively: at each step i , we entrop y enco de the current training token Z i using log 1 /P i ( Z i ) bits, then train the mo del on this token to pro duce P i +1 . Typically Z i ’s are drawn i.i.d. from the same distribution as X. On the side of the deco der, a synchronized mo del is maintained; the mo del deco des Z i using P i and then trains on it to pro duce the identical P i +1 . Omitting small constan t o verheads for specifying the random initialization, arc hitecture, and training algorithm, a total of L ( Z : M , P M ) = P M − 1 i =0 log 1 /P i ( Z i ) bits yields an explicit co de for b oth the training data Z : M = { Z 0 , . . . , Z M − 1 } and the final mo del weigh ts P M , which can b e deco ded in time 6 N D for a 13 mo del with N parameters trained on D tok ens (typically D > M as each example contains multiple tok ens). Despite having an explicit co de for Z, P M , we cannot easily separate this into a co de for P M alone for estimating epiplexity . T o isolate the description length of P M alone, w e adopt the heuristic in Zhang et al. (2020) and Finzi et al. (2025): w e first estimate the description length of the training data giv en P M as its en tropy code length under the final mo del, L ( Z : M | P M ) = P M − 1 i =0 log 1 /P M ( Z i ) . Then, app ealing to the symmetry of information, whic h states K ( P M ) = K ( Z : M , P M ) − K ( Z : M | P M ) up to constan t terms, w e estimate the description length of P M as the difference L ( Z : M , P M ) − L ( Z : M | P M ) : | P preq | ≈ M − 1 X i =0 (log 1 /P i ( Z i ) − log 1 /P M ( Z i )) . (8) If Z i is sampled i.i.d., as is t ypically the case, then the co de length for the mo del c an b e visualize d as the ar e a under the loss curve ab ove the final loss in Figure 2a. Intuitiv ely , the model absorbs a significant amount of information from the data if training yields a sustained and substantial reduction in loss. F or random data, log 1 /P i ( Z i ) nev er decreases, while for s imple data, log 1 /P i ( Z i ) drops rapidly and stabilizes, b oth leading to small | P preq | . W e note that the prequential loss v alues are effectively taken on estimates of the test loss , b ecause they ev aluate the log probabilities on a batc h b efore it is trained on, a cen tral detail to the co ding scheme. In cases where train and test div erge, such as when there is ov erfitting, this difference could b ecome imp ortant imp ortan t. Enco ding the test dataset X (not to b e confused with the training data) using this mo del, we obtain a tw o-part co de of exp ected length | P preq | + E [ log 1 /P M ( X )] that runs in time 6 N D + 2 N D . W e optimize the training hyperparameters (e.g., learning rate) and the trade-off b etw een N and D sub ject to the time bound 6 N D + 2 N D ≤ T to find the optimal P ⋆ that minimizes the t wo-part co de within this family , and estimate epiplexity and time-b ounded entrop y as S T ( X ) = | P ⋆ preq | and H T ( X ) = E [ log 1 /P ⋆ ( X )] . The b etter these hyperparameters are optimized, the more accurate our estimates b ecome. W e use the Maximal Update Parameterization ( µ P) (Y ang et al., 2022) to ensure the optimal learning rate and initialization are consistent across model sizes, simplifying tuning. W e estimate the exp ectation E [ log 1 /P M ( X )] by its empirical v alue on held-out v alidation data, i.e., the v alidation loss scaled by the size of X . W e detail the full pro cedure in Section B, such as how we c ho ose the hyperparameters and estimate the Pareto frontier of MDL vs compute. While conceptually simple, practically useful, and easy to ev aluate, this prequen tial approac h to appro ximating epiplexity is not rigorous for tw o reasons. First, b oth L ( Z : M , P M ) and L ( Z : M | P M ) can only upp er-b ound the resp ectiv e Kolmogoro v complexities, and thus their difference do es not yield an upp er b ound for K ( P M ) . 4 Second, even setting this issue aside, the argument only establishes the existence of a program that encodes P M with length | P preq | , but does not guarantee that its run time falls within 6 N D , since the symmetry of information do es not extend to time-b ounded K olmogorov complexity . Nevertheless, prequential co ding can serv e as a useful starting p oin t for crudely estimating epiplexity , particularly conv enient when one already has access to the loss curve from an e xisting training run. 4.2 Explicitly Co ding the Mo del with Requen tial Co ding T o address the shortcomings of the previous approac h based on prequen tial co ding, w e adopt requen tial co ding (Finzi et al., 2026) for constructing an explicit co de of the mo del with a kno wn run time. Rather than trying to co de a particular training dataset, with requential co ding one can use the insensitivit y to the exact data p oin ts sampled to co de for a sampled dataset that leads 4. W e hav e L ( Z : M , P M ) + O (1) ≥ K ( Z : M , P M ) , but not that L ( Z : M | P M ) + O (1) ≤ K ( Z : M | P M ) . 14 to a p erforman t model but without pa ying for the en trop y of the data. Sp ecifically , it enco des a training run where at step i a student mo del P s i is trained on a synthetic token sampled randomly from a teacher mo del P t i , where the sequence P t 0 , . . . , P t M − 1 are arbitrary teacher mo del chec kpoints. W e typically choose P t i to b e the chec kpoints from training on the original r e al training se t, as in prequen tial co ding. Using relative entrop y co ding (Theis and Ahmed, 2022), the synthetic tokens e Z i ∼ P t i can b e co ded given only the student P s i (sync hronized b etw een enco der and deco der) using KL ( P t i ∥ P s i ) + log( 1 + KL ( P t i ∥ P s i ) ) + 4 bits in exp ectation. Summing ov er all steps giv es the requential co de length for P s M : | P req | = M − 1 X i =0 KL( P t i ∥ P s i ) + log(1 + KL( P t i ∥ P s i )) + 4 + O (1) ≈ M − 1 X i =0 KL( P t i ∥ P s i ) , (9) where the logarithmic and constant ov erheads are typically negligible due to large sequence length and batch size, and as b efore we omit the small constant cost of specifying the random initialization, arc hitecture, and training algorithm. In addition to providing an explicit co de, a key adv an tage of requen tial coding is its flexibility in c ho osing the teac her sequence: by selecting teachers P t i that remain close to the student P s i while still p ointing tow ard the target distribution, w e keep the p er-step co ding cost KL( P t i ∥ P s i ) small while effectively guiding the student’s learning. Figure 2a connects requen tial co ding to the student’s and teacher’s loss curves: supp ose we take as teac hers the chec kp oin ts P t 0 , . . . , P t M − 1 from a mo del trained on real data Z 0 , . . . , Z M − 2 ∼ P X . F or visualization, w e can then estimate KL ( P t i ∥ P s i ) by the loss gap log 1 /P s i ( Z i ) − log 1 /P t i ( Z i ) , whic h is accurate when P t i ≈ P X . W e can thus visualize the co de length for the student as approximately the area b et ween the teacher’s and studen t’s loss curves on real data, as shown in Figure 2a. The tw o-part co de has exp ected length | P req | + E [ log 1 /P s M ( X )] , consisting of first deco ding P s M b y repla ying the training pro cess, whic h tak es time 6 N D for a total of D requen tial training tokens, and then ev aluating P s M on the test dataset X, taking an additional time 2 N D , for a total runtime of 6 N D + 2 N D . W e optimize the training hyperparameters, teacher choices, and the trade-off b etw een N and D sub ject to the sp ecified time b ound T to find the optimal mo del P ⋆ minimizing the tw o-part co de, and estimate S T ( X ) = | P ⋆ req | and H T ( X ) = E [log 1 /P ⋆ ( X )] . See details in Section B.1. 4.3 Comparison Bet ween the T wo Approac hes and Practical Recommendations Figure 2c compares the estimated epiplexit y obtained by the tw o approaches across four groups of datasets used in this work: ECA (Section 5.1), easy and hard induction (Section 5.3.1), and natural datasets (Section 6.2). While the prequential estimate is typically several times larger than the requential estimate, the t wo estimates correlate well, particularly within eac h group where the datasets yield similar learning dynamics. W e detail the datasets and time b ounds used in Section C.7. This general agreemen t is exp ected since the prequential estimate can b e viewed as an appro ximation of requential co ding with a static teacher (Section B.2). In general, how ever, the discrepancy b et ween the tw o estimates will dep end on particular datasets and training configurations, and a go od correlation b etw een the tw o is not guaranteed. While requential co ding is the more rigorous approach, it is typically 2 × to 10 × slo wer than prequen tial co ding, whic h requires only standard training. The ov erhead dep ends on batch size, sequence length, and inference implementation (smaller o v erhead for large batches and short sequences), as requential co ding requires rep eatedly sampling from the teacher, though it is p ossible that the ov erhead can b e reduced with more efficien t algorithms. Therefore, we recommend using prequen tial co ding for crudely estimating epiplexity and ranking the epiplexity of different datasets, particularly when one has access to the loss curve from an existing exp ensive training run (e.g., see an application in Section 6.2), and requential co ding for obtaining the most accurate estimates otherwise. 15 4.4 Ho w Epiplexity and Time-Bounded En trop y Scale with Compute and Data Under natural assumptions ab out neural net work training—namely , that larger models are more sample-efficien t and that there are diminishing returns to scaling mo del size or data alone—w e exp ect epiplexit y and time-b ounded en trop y to exhibit certain generic scaling b ehavior as a function of the compute budget T and dataset size D . In Section B.4, we show that, under these assumptions, the compute-optimal mo del size N ⋆ ( T ) and training data size D ⋆ ( T ) are generally increasing in the compute budget T , which implies that epiplexity S T ( X ) typically grows with T while time-b ounded en tropy H T ( X ) decreases. In the infinite-compute limit, epiplexity S ∞ ( X ) t ypically grows with the test set size D = | X | , while the p er-tok en time-b ounded entrop y H ∞ ( X ) / D decreases. These results align with our intuition that larger compute budgets and more data allow the mo del to extract more structural information from the dataset and reduce the apparent randomness remaining in eac h sample. How ever, they should b e understo o d only as typical trends, with a counterexample shown in Section 5.3.2 relating to the phenomenon of emergence. 5 Three Apparent Parado xes of Information T o illustrate the lacunae in existing information theory persp ectiv es, w e highligh t three app ar ent p ar adoxes of information: (1) information cannot b e created by deterministic transformations; (2) total information conten t of an ob ject is the same regardless of the factorization; and (3) likelihoo d mo deling can only learn to match the data-generating pro cess. Each statement captures some existing sen timent within the machine learning communit y , can b e justified mathematically by Shannon and algorithmic information theory , and y et seems to b e in conflict with intuitions and exp erimental observ ations. In this section, we will show with b oth theoretical results and empirical evidence that time b ounding and epiplexity help resolve these apparent paradoxes. 5.1 P aradox 1: Information Cannot b e Created by Deterministic T ransformations Both Shannon and algorithmic information theory state in some form that the total information cannot b e increased by applying deterministic transformations on existing data. The data pro cessing inequalit y (DPI) states that if some information source W pro duces natural data X that are collected, then no deterministic or sto chastic transformations used to pro duce Y from X can increase the m utual information with the v ariable of in terest W : I ( Y ; W ) ≤ I ( X ; W ) . Similarly , information non-increase states that a deterministic transformation f can only preserve or decrease the Shannon information, a prop erty that holds p oint wise − log P Y ( f ( x )) ≤ − log P X ( x ) and in exp ectation: H( f ( X )) ≤ H( X ) (we note X here is a discrete random v ariable). In algorithmic information theory , there is a corresp onding prop erty: K ( f ( x )) ≤ K ( x ) + K ( f ) + c for a fixed constant c . These inequalities app ear to rule out creating new information with deterministic computational pro cesses. Ho w can we reconcile this fact with algorithms like AlphaZero (Silver et al., 2018) that can b e run in a closed environmen t from a small deterministic program on the game of c hess, extracting insights ab out the game, different op enings, the relative v alues of pieces in different p ositions, tactics and high level strategy , and requiring megabytes of information stored in the weigh ts? Similarly we ha ve dynamical systems with simple descriptions of the underlying laws that pro duce ric h and unexp ected structures, from whic h we can learn new things ab out them and mathematics. W e also hav e evidence that synthetic data is helpful for mo del capabilities (Liu et al., 2024; Gerstgrasser et al., 2024; Maini et al., 2024; Op enAI, 2025). Moreo ver, if we believe that the pro cesses that create natural data could in principle hav e b een simulated to sufficient precision on a large computer, then all data could hav e b een equiv alently replaced with synthetic data. F or practical syn thetic 16 R ule 15 R ule 30 R ule 54 1 0 1 4 1 0 1 7 Compute 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 | P | + E l o g 1 / P ( Y | X ) × 1 0 8 1 0 1 4 1 0 1 7 Compute 0 1 2 3 4 5 S T ( Y | X ) × 1 0 6 1 0 1 4 1 0 1 7 Compute 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 H T ( Y | X ) × 1 0 8 R ule 15 30 54 Figure 3: Information created with cellular automata. ( Left ) Example rollouts from random initial conditions of the class II rule 15, class I II rule 30, and class IV rule 54. Time flo ws from up to down. ( Righ t ) Measuring epiplexity on data pro duced by these transformations, w e see that rule 15 pro duces little information (low H T , low S T ) , rule 30 pro duces lots of unpredictable random information (high H T , low S T ), and rule 54 pro duces b oth random and structural information (medium H T , high S T ). These observ ations are reflected in the training loss curve of LLMs, which saturates quickly for rule 15, makes no progress for rule 30, and makes contin ued progress with compute for rule 54. data pro duced from transformations of samples from a given mo del and prompt, this sampling is p erformed with pseudorandom num b er generators, making the entire transformation deterministic. If w e consider f as the transformations we use to pro duce synthetic data and x w as the limited real data we started with, these inequalities app ear to state v ery c oncretely that our syn thetic data adds no additional information b eyond the mo del and training data. Whatev er information it is that we mean when we say that AlphaZero has pro duced new and unexp ected insights in chess, or new theoretical results in mathematics, or with synthetic data, it is not Shannon or algorithmic information. W e argue that these unintuitiv e prop erties of information theory are a consequence of assuming unlimited computation for the observ er. With limited computation, a description of the AlphaZero algorithm and the result of running AlphaZero for thousands of TPU hours are distinct. T o build intuition, we start with the hum ble CSPRNG which also creates time-b ounded information through computation (alb eit random information). Theorem 12 L et G : { 0 , 1 } k → { 0 , 1 } n b e a PR G which admits advantage ε ( k ) and U k b e the uniform distribution. H Poly ( G ( U k )) − H Poly ( U k ) > n − k − nε ( k ) − c for a fixe d c onstant c . Pr o of: se e App endix A.2. Notably , we hav e a deterministic function which dramatically increases the time-b ounded information con tent of the input. It is worth contrasting this result with Equation 3, where the time-b ounded information conten t increase from a deterministic function c an b e b ounded if the inv erse function has a short program which can run efficien tly . The statement highligh ts an imp ortan t asymmetry b et ween the function G and its inv erse with fixed computation that do es not hold with unlimited computation (e.g. K ( G − 1 ) = K ( G ) + O (1) ). Simultaneously , it provides some useful guidance for syn thetic data: if we wan t to pro duce interesting information, we should mak e sure the functions we use do not hav e simple and efficiently computable inv erses. As an illustrativ e example, consider the iterated dynamics of elemen tary cellular automata (W ol- fram and Gad-el Hak, 2003; Zhang et al., 2024). An elementary cellular automaton (ECA) is a one - dimensional array of binary cells that evolv es in discrete time steps according to a fixe d rule mapping each cell’s curren t state and the states of its t w o immediate neighbors to its next state. Despite their simple formulation – only 256 p ossible rules—these systems can pro duce a rich v ariety of b eha viors, from stable and p eriodic patterns to chaotic and computationally universal dynamics. W e setup the problem of predicting Y i = F ( X i ) from random initial data X i for F b eing an ECA 17 iterated 48 times on a grid of size 64, and assemble these pairs into a dataset X = [ X 1 , . . . , X K ] and Y = [ Y 1 , . . . , Y K ] for a total dataset of D = 100 M tokens. W e measure the conditional information con tent Y | X (epiplexit y and entrop y) for ECA rules 15, 30, and 54 by training LLMs on this dataset. W e provide a visualization of these dynamics in Figure 3 (left). F or the class I I rule 15 in the W olfram hierarc hy (W olfram and Gad-el Hak, 2003), the pro duced behavior is p eriodic and has a simple in verse. Consequently , in Figure 3 (right), we see that training dynamics that rapidly conv erge to optimal predictions and with little epiplexity or time-b ounded entrop y . With the class I I I rule 30, the computation pro duces outputs that are inherently in tractable to predict with limited computation, and as a result w e see that there is maximal time-b ounded entrop y that is pro duced but no epiplexity . F or the class IV rule 54, we see that the dynamics are complex but also partly understandable: the loss decreases slo wly and muc h epiplexity is produced. These results highligh t the sensitivit y of epiplexit y to the generating pro cess. With the same compute sp ent and with a v ery similar program w e can ha ve drastically differen t outcomes, pro ducing simple ob jects, pro ducing only random conten t, and pro ducing a mix of random and structured conten t. 5.2 P aradox 2: Information Conten t is Indep enden t of F actorization An imp ortan t prop erty of Shannon’s information is the symmetry of information, which states that the amoun t of information conten t do es not change with factorization. The information we acquire when predicting x and then y is exactly equal to when predicting y and then x : S hannon entrop y satisfies H( Y | X ) + H( X ) = H( X, Y ) = H( X | Y ) + H( Y ) . An analogous prop erty also holds for K olmogorov complexit y , kno wn as the symmetry of information identit y: K ( y | x ) + K ( x ) = K ( x | y ) + K ( y ) + O (1) . On the other hand, multiple works hav e observed that natural text is b etter compressed (with final mo del achieving higher likelihoo ds) when mo deled in the left-to-right order (for English) than when mo deled in reverse order (P apadop oulos et al., 2024; Bengio et al., 2019), picking out an arr ow of time in LLMs where one direction of mo deling is preferred ov er the other. It seems lik ely that for man y do cuments, other orderings may lead to more information extracted by LLMs. Similarly , as w e will show later, small rearrangements of the data can lead to substantially different losses and do wnstream p erformance. Cryptographic primitives like one wa y functions and blo ck cyphers also pro vide examples where the order of conditioning can make all the difference to how entropic the data app ears, for example considering autoregressive mo deling of tw o prime n um b ers follow ed by their pro duct vs the rev erse ordering. These exp erimental results and cryptographic ideas indicate what can b e learned is dep enden t on the ordering of the data, which in turn suggests that different amoun ts of “information” are extracted from these different orderings. Our time-b ounded definitions capture this discrepancy . Under the existence of one wa y p ermutations, w e can prov e that a gap in prediction exists o ver different factorizations for time b ounded entrop y . Theorem 13 L et f b e a one-way p ermutation and let X = U n b e uniform and Y = f ( X ) . H Poly ( X | Y ) + H Poly ( Y ) > H Poly ( Y | X ) + H Poly ( X ) + ω (log n ) . Pr o of: se e App endix A.5. As a corollary , we show no p olynomial time probability mo del which can fit a one wa y function’s forw ard direction can satisfy Bay es theorem (see Theorem 26). Adding to these theoretical results, w e lo ok empirically at the gap in time-b ounded entrop y for one wa y functions, and the gap in b oth en tropy and epiplexity ov er t wo orderings of predicting chess data. In Figure 4(a), we choose f to b e given by the 8 steps of evolution of the ECA rule 30 with state size n and p erio dic b oundary conditions (W olfram and Gad-el Hak, 2003). Though distinct from the one wa y functions used in cryptography , rule 30 is b eliev ed to b e one wa y (W olfram and Gad-el 18 20 40 60 n (state size) 0 25 50 75 100 H T ( A B ) + H T ( B ) R andom Guess Entr opy forwar d r everse (a) One w ay functions "secret" "ehjzdv" OWF("secret")="ehjzdv" Forward Reverse W pawn to e4 B pawn to e5 1. e4 e5 ... "ehjzdv" "secret" W pawn to e4 B pawn to e5 1. e4 e5 ... Forward Reverse (b) F actorization order 1 0 1 6 1 0 1 8 Compute 4 5 6 7 8 H T ( X ) × 1 0 9 1 0 1 6 1 0 1 8 Compute 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 S T ( X ) × 1 0 8 Or der F orwar d R everse (c) Chess orderings Figure 4: F actorization matters. ( a ) W e compare the losses from mo deling a conjectured one wa y function in forward and reverse as the state size n is increased. The mo del reac hes Shannon entrop y in the forw ard direction, but with a p ersistent gap in the reverse direction. ( b ) The tw o orderings pro duce different outcomes. Analogous to the OWF, predicting the mov es follow ed by the final b oard state is the direction that can b e predicted with a straightfo ward computation. Predicting the b oard first and then the mov es requires more complex b ehaviors. ( c ) As compute increases, the same chess data presen ted in the reverse order leads to higher time-b ounded entrop y and epiplexity , showing it b ecomes more difficult to predict but allo ws more structure to b e learned. Hak, 2003) and unlike typical one wa y functions, the forw ard pass of rule 30 can b e mo deled by an autoregressiv e transformer, which we demonstrate by constructing an explicit RASP-L (Zhou et al., 2023; W eiss et al., 2021) program in App endix D. As shown in Figure 4(a), the mo del achiev es the Shannon en tropy (gray) in the forward direction, but has a consistent gap in the rev erse direction. Bey ond just ho w the random information can v ary with orderings, the structural information can also differ as we will show next. W e demonstrate this fact b y training autoregressive transformer mo dels on the Lic hess dataset, a large collection of c hess games where the mo v es are recorded in algebraic c hess notation. W e consider t wo v ariants of this dataset: (1) formatting eac h game as the mov e sequence follow ed by final board state in FEN notation, and (2) formatting each game as the final b oard state follow ed by the mo ve sequence, as illustrated in Figure 4b. W e pro vide full exp eriment details in Section C.4. While there is no clear p olynomial vs non-p olynomial time separation in this setup, the first ordering is analogous to the forw ard direction as the final b oard state can b e straightforw ardly mapp ed from the mov es with a simple function, while the latter ordering is analogous to the rev erse direction, where recov ering the mov es from the final b oard state requires the inv erse function that infers the intermediate mov es from the final state. W e hypothesize the rev erse direction is a more complex task and will lead the model to acquire more structural information, suc h as a deep er understanding of the b oard state. Figure 4c confirms this hypothesis, sho wing that the reverse order has b oth time-b ounded higher entrop y and epiplexity . This gap v anishes at small compute budgets where the mo del lik ely learns only surface statistics common to both orderings b efore the additional complexity of the reverse task forces it to dev elop ric her b oard-state representations. 5.3 P aradox 3: Likelihoo d Mo deling is Merely Distribution Matching There is a prev ailing view that from a particular training distribution, we can at best hop e to match the data generating pro cess. If there is a prop ert y or function that is not present in the data-generating pro cess, then we should not exp ect to learn it in our mo dels. As an extension, if the generating pro cess is simple, then so are mo dels that attempt to match it. This viewp oin t can b e supp orted b y considering the likelihoo d maximization pro cess abstractly , arg min P E X ∼ Q [ − log P ( X )] = Q ; the 19 0 1 Generation Prediction 1 1 0 0 1 1 1 0 1 0 ? ? ? ? (a) Data generating pro cess 1 0 1 4 1 0 1 5 1 0 1 6 Compute (flops) 1 0 0 1 0 1 T rain L oss (Bits) Hidden Bits h = 0 h = 1 h = 2 h = 3 h = 4 h = 5 0 1 2 3 4 5 Hidden Bits 0 1 2 3 4 5 Measur ed Epiple xity ×10 (b) Induction (hard) 1 0 1 3 1 0 1 4 1 0 1 5 Compute (flops) 1.3 1.4 1.5 1.6 T rain L oss (Bits) × 1 0 3 Hidden R ows h = 0 h = 2 h = 4 h = 6 h = 8 0 2 4 6 8 Hidden R ows 0 1 2 3 4 Measur ed Epiple xity × 1 0 6 (c) Induction (easy) Figure 5: Studying induction through epiplexity . (a) Our setup for creating induction problems. (b) Predicting Rule 30 ECA with hidden inputs. The LLM must induct on the h bits missing from the input, pa ying a cost exp onential in h . F or h small enough but > 0 , epiplexit y is increased. (c) Predicting Marko v c hain samples with hidden transition probabilities. Mo dels that need to b oth use the pro vided probabilities and induct on the missing ones acquire the most epiplexity . test NLL is minimized when the tw o distributions match. The extent to which the distributions differ is regarded as a failure either from to o limited a function class or insufficien t data for generalization. F rom these arguments we could reasonably b elieve that AI mo dels cannot surpass human intelligence when pretraining on human data. Here we provide tw o classes of phenomena that seem to contradict this viewp oint: induction, and emergence. In b oth cases, restricting the compute a v ailable to AI mo dels leads them to extract more structural information than what is required for implementing the generating pro cess itself. 5.3.1 Induction The generative mo deling comm unit y is often c hallenged with sim ultaneously w anting a tractable sampling pro cess and tractable likelihoo d ev aluation, with autoregressors, diffusion mo dels, V AEs, GANs, and normalizing flows each providing different approaches. F or natural generative pro cesses, it is often the case that one direction may b e muc h more straigh tforward than the other. Here we in vestigate generative pro cesses which can be constructed by transforming laten t v ariables such that computing lik eliho o ds requires inducting on the v alues of those latents. A windo w into the phenomenon can b e appreciated through this quote from Ily a Sutskev er: “ Y ou’r e r e ading a mur der mystery and at some p oint the text r eve als the identity of the criminal. ... If the mo del c an pr e dict [the name] then it must have figur e d out [who p erp etr ate d the mur der fr om the evidenc e pr ovide d]. ” (Sutsk ever, 2019) The author of the b ook on the other hand, need not hav e made that same induction. Instead, they ma y hav e chosen the murderer first and then pain ted a comp elling story of their actions. This example highlights a gap b etw een the generating pro cess and the requiremen ts of a predictive mo del, a gap w hic h we explore with the follo wing more mathematical setup. As we illustrate in Figure 5(a), consider a simple to model random v ariable Z o ver { 0 , 1 } n whic h w e transform with tw o functions m and f , which are b oth short in length and efficien t to compute, and pro duce the data Y = ( m ( Z ) , f ( Z )) . W e choose m : { 0 , 1 } n → { 0 , 1 } n − h as a masking function whic h remov es the bits at a total of h fixed lo cations in the input, leaving the rest unchanged. The generating pro cess is simple to implement and can b e executed efficiently . Now consider a likelihoo d generativ e mo del learning to mo del Y , under an y given factorization. With appropriate prop erties of the function f , in pro ducing the likelihoo ds the mo del must learn to induct on the missing information in the state Z , and then apply the transformation given by the data generating pro cess. W e consider 20 cases b oth where the function f is hard to in vert and those where f is not esp ecially hard to inv ert. In b oth cases, predictive circuits must b e learned that w ere not present in the data generating pro cess, but with hard f these circuits only app ear at exp onentially high compute. Induction Hard: Rule 30 ECA. F or the first setting we use uniform Z = U n and f as 4 steps of the rule 30 ECA on state size n = 32 , m simply remov es the first h bits, and we also compute the loss only on f ( Z ) (conditioned on m ( Z ) ) as the bits in m ( Z ) are uniform and only add noise. W e use an LLM , and the loss curves and measured epiplexities are sho wn in Figure 5b. The loss conv erges to the num b er of hidden bits − log P ( f ( Z ) | m ( Z )) = h , representing the 2 h p ossible inductions on the hidden state. How ev er, the total compute required for this loss to conv erge grows exp onen tially with h , an ov erall b ehavior consistent with a strategy of passing all 2 h candidates through f and then eliminating inconsisten t candidates as v alues of f ( Z ) i are observ ed with the autoregressive factorization. This complex learned function stands in con trast with the mere f ( Z ) and simple p ostprocessing removing bits with masking. This picture is mirrored by the measured epiplexity: as the mo del is forced to induct on the missing bits, the epiplexity grows. Induction Easy: Random Marko v Chains. In the second setting, we leverage the statistical induction heads setup (Edelman et al., 2024) with a few modifications. Z is giv en by a random Mark ov chain transition matrix with V = 8 sym bols, and m remo ves h columns of the matrix at fixed random lo cations. The function f ( Z ) computes a sampled sequence from the Marko v chain of length n = 512 . When h > 0 , the optimal solution inv olv es 1) using the provided rows Z to p erfectly predict next-token probabilities on V − h of the symbols, and 2) inducting on the missing rows of Z in-con text based on the empirically observed transitions to improv e remaining predictions. F or h = 0 , the first is sufficient, and for h = 8 the second is sufficient. In Figure 5c, we find evidence that b oth strategies are employ ed whenever 0 < h < 8 as the final loss achiev ed matches the theoretical loss of b oth (the low er of the t wo dotted lines). The higher horizontal line marks the loss achiev able using 1) along with a simple unigram strategy (Edelman et al., 2024), showing that the transformer learns 1) first and later the induction strategy 2). While the data generating program only only inv olv es strategy one follow ed by the p ostprocessing masking step, the mo del must learn b oth strategies to reac h these v alues. Measured epiplexit y matches this picture, with v alues 0 < h < 8 having higher epiplexit y than h = 0 or h = 8 . W e emphasize that the induction strategy was never present in the data-generating pro cess, y et it is learned by a generative mo del trained on that same data distribution. In Section G, we argue the induction phenomena are not sp ecific to autoregressive mo dels, but o ccur more generally for mo dels trained via Maximum Likelihoo d Estimation as they need to b e able to ev aluate the lik eliho o d P ( x ) for an arbitrary data p oin t x rather than merely sample random x from P . V AEs (Kingma et al., 2013) provide a clear example of explicitly p erforming induction in non-autoregressiv e models: the enco der is trained specifically to appro ximate the posterior P Z | X , enabling tractable likelihoo d estimation, yet this encoder is entirely unnecessary if the goal is merely to sample from the mo del. In b oth of the hard and easy induction examples, the size of the program needed to p erform the induction strategy is greater than the size of the program needed generate the data. W e can exp ect that with limited computational constraints, it will not b e generically p ossible to inv ert the generation pro cess using brute force, and thus, in cases where alternative inv erse strategies exist (like the easy induction example with the statistical induction heads), those additional strategies increase the epiplexit y . Given that there is lik ely no single generally applicable strategy for these computationally efficien t inv erses across problems, it is lik ely to b e p ossible as a source of epiplexit y . T o make these statemen ts more precise, it seems likely that there are no constants c 1 and c 2 for whic h the following prop erty holds: 21 Limited Epiplexity Increase Property: Given any program G : { 0 , 1 } k → { 0 , 1 } n running in time at most T 1 on random v ariable Z , the epiplexity of G ( Z ) is increased by at most a constan t more than the size of G : S T 2 ( G ( U k )) ≤ | G | + c 1 for T 2 ( n ) > T 1 ( k ) + c 2 . In other words, there is no b ound on how muc h larger the MDL optimal probability mo del will b e than the generating program even when the mo del is allow ed more compute than the generating program. W e presen t this phenomenon in contrast to Shannon information or Kolmogoro v complexit y , where a function and its inv erse can differ in complexit y by at most a fixed constant: K ( F − 1 ) = K ( F ) + O (1) . When the computational constraints are lifted, the brute force inv erse is p ossible, and there is no essen tial gap b etw een deduction and induction, or b etw een sampling and lik eliho o d computation. 5.3.2 Emergent Phenomena One of the most striking coun terexamples to the “distribution matching” viewp oint is emer genc e . Ev en when a system’s underlying dynamics admit a simple description, an observer with limited computation may need to learn a richer, and seemingly unrelated, set of concepts to predict or explain its b ehavior. As articulated b y Anderson (1972), reductionism—that a complex ob ject’s b eha vior follo ws from its p arts—does not guarantee that kno wing those parts lets us predict the whole. Across biology and physics, many-bo dy in teractions give rise to b ehaviors (e.g. bird flo c king, Con wa y’s Game of Life patterns, molecular c hemistry , sup erconductivit y) that are not apparent from the microscopic laws alone. Here we sketc h ho w emergence critically relates to the computational constrain ts of the observer, demonstrating how observ ers predicting future states may b e required to learn mor e than their unbounded counterparts who can execute the full generating pro cess. Consider T yp e-Ib emergence in the Carroll and Parola (2024) classification, in which higher-level patterns arise from lo cal rules yet resist prediction from those rules. A canonical example is Conw ay’s Game of Life (see App endix E for definition), where iterating a simple computational rule Φ on a 2 D grid leads to complex emergent b ehavior. F or observers that lack the computational resources to directly compute the iterated evolution Φ k , an alternate description must b e found. In the state ev olution, one can identify lo calized “sp ecies” (static blo c ks, oscillators, gliders, guns) whic h propagate through space and time. By classifying these sp ecies, learning their v elo cities, and how they are altered under collisions with other sp ecies, as well as the abilit y to identify their presence in the initial state, computationally more limited observers can make predictions ab out the future state of the system. Doing so, how ever, requires a more complex program in the sense of description length, and the epiplexit y will b e higher. W e can formalize this intuition into the follo wing definition of emergence. Definition 14 (Epiplexit y Emergent) L et { Φ n } n ≥ 1 b e a c omputable family Φ n : { 0 , 1 } n → { 0 , 1 } n and let { X n } n ≥ 1 b e r andom variables over { 0 , 1 } n . W e say (Φ , X ) is epiplexit y-emergent if ther e exist time b ounds T 1 , T 2 with T 1 ( n ) = o ( T 2 ( n )) and an iter ation sche dule k ( n ) such that as n → ∞ , S T 1 (Φ( X ) | X , n ) − S T 2 (Φ( X ) | X , n ) = Θ(1) , (10) S T 1 (Φ k ( X ) | X , n, k ) − S T 2 (Φ k ( X ) | X , n, k ) = ω (1) , wher e we have suppr esse d the dep endenc e of X n and Φ n on n for clarity. 22 In words, Φ , X displa ys emergent phenomena if t wo observers see equiv alent structural complexity in the one step map, but asymptotically more structural complexity in the multistep map for the observ er with fewer computational resources. Considering Φ from the Game of Life as an example, P (Φ( X ) | X , n ) could be w ell estimated by b oth T 1 and T 2 -b ounded observers using the exact time evolution rule, using constant bits for b oth. P (Φ k ( X ) | X , n, k ) could b e estimated by T 2 using the iterated rule, but not b y T 1 . Using kno wledge of the different pattern sp ecies improv es predictions of Φ k ( X ) | X , so they would need to b e learned; ho wev er, the num b er of patterns that needs to b e considered in the time-b ounded optimal solution is un b ounded, and grows with the size of the b oard n , and thus the gap in epiplexity for the tw o time b ounds grows with n . W e hav e not prov en that the Game of Life satisfies this definition, which is lik ely difficult as small changes to the evolution rule can destroy the emergent b ehavior; how ev er, we pro vide empirical evidence for this set b eing non-empty with the example b elo w. 1 0 1 5 1 0 1 7 Compute 0 . 0 0 0 . 2 5 0 . 5 0 0 . 7 5 1 . 0 0 | P | + E l o g 1 / P ( X ) × 1 0 9 1 0 1 5 1 0 1 7 Compute 0 . 0 0 . 5 1 . 0 1 . 5 S T ( X ) × 1 0 7 non-looped looped Figure 6: Emergence in ECA. Compute-constrained mo dels extract high epiplexity from data generated b y simple rules, trading increased pro- gram length for reduced computation. In Figure 6, we empirically demonstrate the emergence phe- nomenon b y training a transformer to predict the iterated dynamics of ECA rule 54, a class IV rule that pro duces complex patterns. As in Con w ay’s Game of Life, a mo del with sufficient computation can exactly simulate the dynamics by directly iterating the p er-step rule—a brute-force solution with a short description length. Ho wev er, a compute -limited mo del cannot afford this approac h and must instead learn emergent patterns (e.g., gliders and their collision rules) that approximately short- cut the infeasible exact sim ulation. The brute-force solution can b e naturally implemented by learning to autoregressively unroll in termediate ECA states rather than directly predicting the final state, resembling the use of chain-of-though t (W ei et al., 2022) or lo op ed transformers (Dehghani et al., 2018; Giannou et al., 2023; Saunshi et al., 2025). W e pro vide experiment details in Section C.8. While initially the non-lo op ed model (directly predicting final state) gradually achiev es b etter MDL and higher epiplexit y as compute increases, we identify a compute threshold b ey ond which the lo op ed mo del suddenly b ecomes fav orable, causing an abrupt drop in MDL and epiplexity , likely b y learning the simple, brute-force solution. Below this threshold, the lo op ed mo del underp erforms likely b ecause it lac ks the compute to fully unroll the dynamics. The non-lo op ed mo del, unable to rely on brute-force sim ulation, must instead learn increasingly sophisticated emergent rules, recognizing more sp ecies and their interactions, thus causing epiplexity to initially rise with compute before even tually falling. While this exp erimen t cleanly demonstrates how compute-limited mo dels can learn ric her structure from data, it is a more uncommon situation where the brute-force solution is accessible, and where training with more compute reveals a muc h simpler underlying structure. With natural data and compute b ounds that are not extraordinarily high, we exp ect that exp ending additional comp ute leads to increased rather than decreased observed structure. W e explore other kinds of emergence, such as in chaotic dynamical systems or in the optimal strategies of game playing agents in App endix F. Each of these examples presents clear evidence that in pursuit of the b est probability distribution to explain the data, observers with limited compute will require mo dels with greater description length than the minimal data generating pro cess in order to achiev e comparable predictive p erformance (Martínez et al., 2006; Redek er, 2010). Epiplexity provides a general to ol for understanding and quantifying these phenomena of emergence, and ho w simple rules can create meaningful, complex structures that AI mo dels can learn from, as recently demonstrated empirically b y Zhang et al. (2024). 23 6 Epiplexit y , Pre-T raining, and OOD Generalization Pre-training on in ternet-scale data has led to remark able OOD generalization, y et a thorough understanding of this phenomenon remains elusive. What kinds of data provide the b est signal for enabling broad generalization? Why do es pre-training on text yield capabilities that transfer across domains while image data do es not? As high-quality internet data b ecomes exhausted, what metric should guide the selection or syn thesis of new pre-training data? In this section, w e show how epiplexit y helps answer these foundational questions. OOD generalization is fundamentally ab out how m uch reusable structure the mo del acquires, not ho w well it predicts in-distribution. T wo mo dels trained on different corp ora can achiev e the same in-distribution loss, yet differ dramatically in their ability to transfer to OOD tasks. This happ ens b ecause loss captures only the residual unpredictability , corresp onding to the time-b ounded en tropy , not how muc h reusable structure the mo del has internalized to achiev e that loss. Epiplexit y measures exactly this missing comp onent: the amount of information in the learned program. Intuitiv ely , loss indicates how random the data lo oks to the mo del, while epiplexity indicates how muc h structure the mo del must acquire to explain a wa y the non-random part. If OOD generalization dep ends on reusing learned mechanisms rather than memorizing sup erficial statistics, then epiplexity is a natural lens through which to understand the relationship b etw een pre-training data and OOD transfer. As a motiv ating toy example, Zhang et al. (2024) observed that downstream task p erformance b enefits most from training on type IV ECA rules ov er the other ECA rules, aligned with Figure 3 where we sho wed that rule 54 (a type IV rule) induces muc h higher epiplexity compared to other rules. 6.1 Epiplexit y Correlates with OOD Generalization in Chess Epiple xity 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 × 1 0 8 P uzzle A cc 0.0 0.1 0.2 0.3 CP A cc 0.0 0.1 0.2 0.3 F orwar d R everse Figure 7: Epiplexit y and OOD p erformance in chess. Mo dels trained on the higher epi- plexit y reverse order performs b etter in OOD tasks. W e finetune mo dels trained on either ordering from Section 5.2 on t wo downstream tasks: (1) solving chess puzzles, where the mo del m ust predict the optimal next mov e given a b oard state (Burns et al., 2023), and (2) predicting centipa wn ev aluation, where the mo del ev aluates p ositional adv an tage from FEN notation—a more substan tial distribution shift from next-mov e prediction learned in pre-training. Exp eriment details are in Section C.4. As sho wn in Figure 7, the reverse (b oard-then-mov es) ordering yields higher epiplexit y and b etter do wnstream p erformance: matching accuracy on c hess puzzles but significantly higher accuracy on the centipa wn task. This result supp orts our h yp othesis: the rev erse order forces the mo del to develop richer b oard-state representations needed to infer the in termediate mov es, and these representations transfer to OOD tasks lik e centipa wn ev aluation that similarly require understanding the b oard state. This example reflects a more general principle: epiplexit y measures the learnable structural information a mo del extracts from data to its weigh ts, which is precisely the source of the information transferable to no vel tasks, making epiplexit y a plausible indicator for the p oten tial of OOD generalization. How ever, we emphasize that higher epiplexity do es not guarantee b etter generalization to any sp ecific task: epiplexity me asures the amount of structural information, irresp ectiv e of its con ten t. A mo del trained on high epiplexity data can learn a lot of structures, but these structures ma y or may not b e relev ant to the particular downstream task of interest. 6.2 Measuring Structural Information in Natural Data Among different mo dalities of natural data, language has prov en uniquely fruitful for pre-training, not only for improving in-distribution p erformance such as language understanding (Radford et al., 2019), 24 OWT e xt Chess (R) Chess CIF AR -5M 1 0 8 1 0 9 1 0 1 0 Infor mation (bits) S T H T (a) Epiplexit y in natural data Language I m g V Q 3 2 2 I m g V Q 1 6 2 V i d V Q 1 6 3 I m g 3 2 2 I m g 1 6 2 I m g 8 2 1 0 1 0 1 0 1 2 Infor mation (bits) S T H T (b) Estimation via scaling laws 0.0 2.5 5.0 Step 1e4 2.0 2.2 2.4 2.6 2.8 T raining Loss ADO Natural Epiplexity 0.5 1.0 1.5 2.0 2.5 1e10 Accuracy 0.55 0.56 0.57 0.58 0.59 0.60 Perplexity 1 12.0 12.1 12.2 12.3 Perplexity 2 13.0 13.5 14.0 14.5 15.0 15.5 16.0 (c) ADO: epiplexity and downstream metrics Figure 8: Epiplexit y rev eals differences in the structural information across data modalities and can guide pre-training data selection. ( a ) Estimated epiplexity and time-b ounded en tropy using requen tial co ding for 1B Op en W ebT ext, Chess, and CIF AR-5M tokens at 6 × 10 18 FLOPs. ( b ) Estimated v alues based on scaling laws and prequential co ding for 1T language, image, and video tokens at 10 25 FLOPs. ( c ) Selecting pre-training data using ADO (Jiang et al., 2025) leads to differen t loss curves than standard sampling (natural). Our measurement sho ws ADO selects data with higher epiplexity , in line with the impro ved downstream p erformance and OOD p erplexity on different text corp ora. but also for out-of-distribution tasks such as rob otics control (Ahn et al., 2022), formal theorem pro ving (Song et al., 2024), and time-series forecasting (Gruver et al., 2023). While equally abundant total information is av ailable in other mo dalities, such as images and videos, pre-training on those data sources typically do es not confer a similarly broad increase in capabilities. W e now show that epiplexit y helps explain this asymmetry by revealing differences in their structural information con tent. In Figure 8a, w e sho w the estimated decomp osition of the information in 5B tokens of data from Op en W ebT ext, Lichess, and CIF AR-5M (Nakkiran et al., 2020) in to epiplexit y (structural) and time-b ounded entrop y (random) with a time-b ound of 6 × 10 18 FLOPs, b y training mo dels of up to 160M parameters on at most 5B tokens using requen tial co ding. In all cases, epiplexity accounts for only a tiny fraction of the total information, with the Op en W ebT ext carrying the most epiplexity , follo wed by chess data. Despite ha ving the most total information, CIF AR-5M data has the least epiplexit y , as ov er 99% of its information is random (e.g., unpredictability of the exact pixels). 6.3 Estimating Epiplexit y from Scaling Laws 1 0 2 2 1 0 2 8 Compute 1 0 9 1 0 1 0 1 0 1 1 S T ( X ) S ( X ) 1 0 2 2 1 0 2 8 Compute 1 0 1 1 1 0 1 2 Optimal T rain T ok ens D * = Language I m g V Q 3 2 2 I m g V Q 1 6 2 V i d V Q 1 6 3 I m g 3 2 2 I m g 1 6 2 I m g 8 2 Figure 9: Epiplexity and optimal train- ing tokens for eac h fixed dataset con- v erge to predictable limits as compute increases. W e can estimate the epiplexities of larger datasets at higher compute budgets using reported scaling la ws, which de- scrib e the loss achiev ed by an N -parameter mo del trained on D tok ens as L ( N , D ) = E + ( N /N 0 ) − α + ( D /D 0 ) − β , for some dataset-sp ecific constants α, β , N 0 , D 0 , E (Hoff- mann et al., 2022; Kaplan et al., 2020; Henighan et al., 2020). By estimating the model’s description length via the prequential co ding approach (Section 4.3), we obtain estimates for the epiplexity and time-bounded entrop y for language, image, and video datasets, with v arying resolu- tions and tokenizations of size D = 10 12 (1T) tokens under a compute budget of 10 25 FLOPs (equiv alen t to the train- ing compute of Llama3 70B), illustrated in Figure 8b (see details in Section C.9). Consisten t with our smaller-scale exp erimen ts, we find that language data has the highest epiplexit y , while image data has the least. F or image data, applying VQ tok enization leads to a significan t increase in epiplexit y , likely as a result of allo wing the model to focus on higher-lev el 25 seman tic structures. Video data has less time-bounded entrop y and epiplexity than image data with the same resolution, likely due to significant redundancy across the temp oral dimension. Using this approach, we can also gain some analytical insights ab out epiplexity for data admitting scaling la ws of this form. As w e derive in Section B.3, for a fixed dataset X with D tok ens, the optimal split of the compute budget b et ween training and inference (ev aluating the trained mo del on X ) approaches a fixed ratio as compute increases, with the optimal asymptotic training tokens D ⋆ ∞ = D and asymptotic epiplexity S ∞ ( X ) = β 1 − β D β 0 D 1 − β , b oth illustrated in Figure 9. As exp ected, the maximum amount of extractable structural information is ultimately capp ed by the dataset size D when compute is not the b ottlenec k, and epiplexit y can increase further if w e also grow the dataset size. F or large D , the scale of the asymptotic epiplexit y is primarily determined by β and D 0 , with smaller β and larger D 0 leading to higher epiplexity , corresp onding to slow er improv emen t in loss and thus more (estimated) information absorb ed p er token. In line with our discussion on emergence in Section 5.3.2, it is p ossible that with significantly more compute muc h simpler programs can mo del these natural datasets, such as b y directly simulating the basic laws of physics from which the natural world emerges, but the amount of required computation is likely so high that such programs remain inaccessible to any physically realizable observer and we must treat natural data as having high epiplexit y for all practical purp oses. 6.4 Pre-T raining Data Selection and Curriculum for Language Mo dels A crucial step in pretraining a language mo del is designing the comp osition of the pretraining data, but there lack clear guidelines for this step. Existing data mixtures are designed through extensive trial-and-error and rely on heuristic guidelines such as “diversit y” or “high-quality”. More imp ortantly , the primary w ay of comparing different training data is via p erplexit y metrics of held-out datasets and do wnstream p erformance. These pro cedures are highly susceptible to data contamination, ov erfitting to a narrow set of downstream ev aluations, and Go o dhart’s law. After all, no suite of downstream ev aluations is extensive enough to faithfully capture the range of tasks that a general-purp ose language mo del will encounter in the real world. As we argued abov e, epiplexity measures the structural information learned by the mo del, whic h could b e affected by data selection strategies. Jiang et al. (2025) demonstrated that mo dels of the loss curves for differen t data subsets can b e used to dynamically adjust the data distribution online to fa vor data subsets whose training losses are de cr e asing faster 5 . Intuitiv ely , this ob jective aligns with increasing the prequential estimate of epiplexity describ ed in Section 4.1 by maximizing information absorb ed per token. W e hypothesize that the prop osed algorithm, Adaptiv e Data Optimization (ADO), inadverten tly achiev es higher epiplexity . Exp eriments of Jiang et al. (2025) are conducted on deco der-only transformers with 1.3B parameters trained on 125B tokens from the Pile dataset (Gao et al., 2020). The mo dels are ev aluated on a suite of 7 zero-shot downstream tasks and tw o OOD v alidation datasets, SlimPa jama (Sob olev a et al., 2023) and FineW eb (Penedo et al., 2024). In Figure 8c(c), we sho w the estimated epiplexity and the downstream p erformance as well as p erplexit y on tw o OOD datasets, adapted from Jiang et al. (2025). As shown in Jiang et al. (2025), ADO ac hieves higher downstream p erformance than a standard data sampling strategy that uniformly samples from the entire dataset (denoted by Natur al in Figure 8c), despite not b eing optimized for an y of these metrics. In terestingly , we see that ADO indeed achiev es higher epiplexity measured by prequen tial co ding. While these do wnstream ev aluations do not capture everything ab out a pretrained mo del, they do offer evidence that epiplexity is a p otentially useful concept for understanding the in trinsic v alue of pretraining data without particular do wnstream ev aluations. 5. It is worth noting that choosing data subsets with faster-decreasing loss do es not mean that the observed training loss would be smaller b ecause such data subsets tend to hav e higher loss v alues since there is more learnable information in them. Consequently , training on them often leads to a larger area under the training loss curve. 26 7 A dditional Related W ork Epiplexit y builds on a n umber of related ideas in algorithmic information theory and complexity science that attempt to theoretically characterize me aningful information . A group of closely related concepts are sophistication (subsection 2.2), effectiv e complexity , and logical depth. Similar to sophistication, effectiv e complexity aims to separate random from structural con tent (Gell-Mann and Llo yd, 1996). F rom a different starting p oint, Bennett (1988) introduced logical depth, measuring the n umber of time steps required by a nearly optimal program to pro duce a given string, and which w as later shown to be equiv alen t to sophistication through the busy beav er function (An tunes et al., 2005; A y et al., 2010). Sev eral other formal measures ha ve b een developed to quantify structured or meaningful complexity . Algorithmic statistics offers a principled decomp osition of data in to regular versus random comp onen ts by introducing the notion of an algorithmic sufficient statistic (V ereshchagin and Vitányi, 2004), a concept closely tied to sophistication. Relatedly , statistical complexit y in computational mechanics (Shalizi and Crutchfield, 2001) measures the entrop y of causal states in an optimally predictive mo del, capturing structure in time-series data. As we argued ab o ve, these existing notions of complexity do not account for the limited computation av ailable to the observer, which is essential for understanding machine learning algorithms. Being oblivious to computational limits means that they cannot characterize CSPRNGs or encrypted ob jects as b eing random. One migh t think that these failures are surface-level; for example, a plausible strategy would b e to upgrade sophistication by replacing Kolmogoro v complexity with time-b ounded Kolmogoro v complexit y in (Definition 5). Ho wev er, this approach do es not work for several reasons, the most ob vious b eing that CSPRNG outputs do hav e short and efficiently runnable generating programs and thus their time-b ounded Kolmogoro v complexities are small. A more subtle reason is that doing so results in trivial sophistication for all strings, which we discuss in more detail in App endix A.6. Our work is also closely related to several lines of work trying to c haracterize observer-dependent notions of information. In cryptography , Barak et al. (2003) and Hsiao et al. (2007) discuss several p ossible definitions for c omputational pseudo entr opy , an observ er-dep endent analogue of entrop y . HILL-pseudo en tropy (Håstad et al., 1999) is defined relative to a class of tests: a source is considered random if no test within the class can distinguish it from a high-en trop y distribution with nontrivial adv antage, and Y ao-pseudo entrop y is defined via compressing and decompressing an ob ject for example. Both definitions are closely related to time-b ounded entrop y , whic h measures the random con tent to a given computationally b ounded observer; how ever, our formulation directly maps on to mac hine learning practice and allows for separating out the structural information conten t, a key con tribution of our w ork. More recen tly , Xu et al. (2020) propose V -en tropy , a generalization of Shannon entrop y to the minimum exp ected negative log probability ov er a given family of probability mo dels, such as those with giv en computational constrain ts. With V -en tropy , the symmetry of information can b e violated, and so to o can the data pro cessing inequality , though neither is explicitly pro ven in the pap er. Unlike time-b ounded entrop y , the computational constraint in V -entrop y only limits the inference time, and do es not accoun t for the time to find such a mo del. Hence, the minimizer can b e far aw ay from the regime that is practically ev aluated (such as mo dels that are tr aine d on infinite data or with infinite compute). While these undesirable b ehaviors can b e ov ercome b y imp osing further data constrain ts, w e b elieve our form ulation of imp osing a single b ound on b oth training and inference time leads to few er complications. More importantly , both pseudoentrop y and V -en tropy , muc h like time-b ounded entrop y , capture only the random component of information since it still measures the unpredictability of the random v ariable under the b est feasible mo del. F or understanding what useful information a mo del has learned, we are more interested in the non-random comp onen t of information as measured by epiplexity . Using existing measures of complexity , suc h as the Lemp el-Ziv complexity and W olfram classification, Zhang et al. (2024) show ed that mo dels trained on complex data like Class IV ECA rules tend to p erform b etter on do wnstream tasks. 27 Other parts, suc h as the area under the curv e estimate of epiplexit y , hav e seen some related exploration in prior work. The concept of excess entrop y , indep endently introduced under v arious names (Crutchfield and Pac k ard, 1983; Shaw, 1984; Grassb erger, 1986) and review ed in F eldman (1998), is defined as the area b et ween finite-block en tropy densit y estimates and the asymptotic en tropy rate of a stationary pro cess, an analogous construction to our prequential estimate of epiplexit y . How ever, excess entrop y is defined for stationary pro cesses observ ed by computationally un b ounded agents, lac king the explicit dep endence on the observer’s compute budget that w e view as essential for the machine learning setting. More recently , Whitney et al. (2020) in tro duced surplus description length (SDL), which is the summed online loss of the training algorithm, with either the en tropy of the data or a fixed baseline p erformance subtracted out. The authors use this measuremen t to ev aluate pre-trained representations for solving a do wnstream task, arguing that smaller SDL is preferred as they lead to more efficient downstream learning. In contrast, we seek to create datasets and interv entions to the data which incr e ase epiplexit y . More analogous to the spirit of epiplexity is information transfer from Zhang et al. (2020), which sums a v arian t of a loss difference, adapted to held out test data and for the classification setting. In this work, the authors present information transfer to measure how muc h is learned from the data. Epiplexity is complemen tary to these works, clarifying the role of computation in defining information, and explicitly separating random and structural information. Sev eral works hav e also explored how to quantify data complexity . Dziugaite and Ro y (2025) su ggests that the complexit y of a minimal near-optimal reference mo del can b e viewed as a measure of data complexit y under the P A C-Bay es framework and how such data complexity gives rise to empirical scaling laws. This p ersp ectiv e is related to epiple xit y in that b oth asso ciate data complexity with the size of compact mo dels that explain the data w ell. Ho wev er, the tw o notions differ in imp ortan t wa ys. In particular, the P AC-Ba yes form ulation is concerned with the existence of some small reference mo del achieving go o d in-distribution p erformance, whereas epiplexity characterizes the amount of structural information extractable by a computationally b ounded observer, formalized through a t wo-part co de that explicitly accoun ts for the cost of obtaining such a mo del. F urther, our primary in terest is not in characterizing in-distribution generalization, but in using epiplexity to measure the in trinsic v alue of data in settings that extend b ey ond sup ervised learning. Relatedly , Hutter (2021) sho ws that pow er-la w learning curves can emerge under sp ecific assumptions on the data-generating distribution, illustrating how prop erties of the data itself can shap e empirical scaling b eha vior. While this line of work fo cuses on explaining observed learning dynamics rather than defining a complexity measure, it similarly emphasizes the role of data structure in determining learning outcomes. These p erspectives on data complexity can b e viewed as instances of c o arse gr aining , where one seeks a compressed representation that preserves some notion of “relev ant” structure. A canonical example is the information b ottlenec k framew ork, which formalizes coarse graining as a trade-off b etw een compression and retained information about a relev an t v ariable (Tish b y et al., 2000). Epiplexit y is aligned with this p erspective, but rather than defining relev ance through a task v ariable or through distinguishability to tests, it measures the amount of structural information extractable b y a computationally b ounded learner, while explicitly accounting for the cost of obtaining the mo del. More broadly , our work is related to several lines of work on how resource constraints fundamentally alter the notion of simplicity and learnability . In algorithmic information theory , Schmidh ub er (2002) prop oses the sp eed prior, which replaces Solomonoff ’s universal prior with a c omputable semimeasure that fav ors both shorter program length and smaller computation time, thereby incorp orating computational resources directly into the definition of simplicity . Ac hille and Soatto (2025) argue that in the transductive setting, the role of information from past data is to reduce the time needed to solve new tasks rather than to reduce uncertaint y , with the optimal sp eedup tightly characterized b y the amount of shared algorithmic information b et ween past data and future tasks. In this setting, lar ger information conten t is shown to b e more conducive to b etter p erformance. In learning theory , a related line of work shows that computational limitations can directly affect what can b e learned 28 from data. F or instance, in the problem of sparse PCA detection, Berthet and Rigollet (2013) sho w that although there exist pro cedures that succeed with an information-theoretically minimal num b er of samples, any algorithm that runs in p olynomial time necessarily requires more data under widely used a verage-case hardness assumptions. Memory and space constraints alone can also qualitatively c hange learnability . Steinhardt et al. (2016) show that restricting a learner’s memory can dramatically increase the amount of data required to learn, even when the target concept itself has a very concise description. They identify parity functions as a canonical example where this tension is conjectured to b e sharp. Raz (2018) later resolves this conjecture by proving that any learner with sub-quadratic memory requires exp onen tially many samples to learn parity from random examples. 8 Discussion Muc h of classical information theory is concerned with the represen tation and transmission of information, and abstracts aw a y key asp ects of the computational pro cesses by which information is extracted and used. While complexity theory and cryptography treat computation as fundamental, mac hine learning theory typically do es not. Y et learning, whether biological or artificial, is an inheren tly computational pro cess. What can b e learned from data dep ends not only on statistical feasibilit y , but on the a v ailable resources. This p ersp ectiv e calls for more theoretical to ols that place computation on an equal fo oting with information. This w ork reframes information as a prop ert y of data relative to a computationally b ounded observer, and demonstrates that information can b e decomp osed into time-b ounded entrop y and epiplexity , a formalization of structural information. It also sheds light on how p erceived information can b e changed through computation. This p erspective resolves several tensions b etw een information theory and empirical mac hine learning—including the usefulness of synthetic data, the dep endence of learning on factorization and ordering, and the emergence of structure b ey ond the data-generating pro cess itself. T echnically , epiplexity connects ideas from algorithmic statistics, cryptography , and learning theory , showing that standard assumptions (i.e., existence of one-wa y functions) suffice to pro duce distributions with high structural complexity for efficient learners. Our framework op ens several exciting directions for future work. On the theoretical side, it invites a systematic and more fine-grained understanding of ho w structural information changes with computational budget, mo del class, and data transformations, p otentially yielding new low er b ounds and impossibility results for representation learning and transfer. T aking information and computation as the fundamental resources may offer new explanations for the relative universalit y observed in large-scale training, including why scaling law exp onen ts dep end only weakly on architectural and optimizer details. There is also a p ossibility of a compute-a ware analogue of classical notions such as sufficien t statistics and information b ottlenec ks. More broadly , framing emergence, induction, and generalization through the lens of computationally b ounded observers may offer a unifying language across learning theory , algorithmic information theory , cryptography , and complexity theory . On the empirical side, epiplexit y pro vides a w a y to reason ab out why some data sources, formatting, and transformations can lead to more transferable mo dels than others, ev en when they do not impro ve training loss. The framework suggests that pretraining data should b e ev aluated not only by held-out p erplexity , but by ho w muc h reusable structural information it induces in a computationally b ounded mo del. This persp ective helps explain empirical successes of curriculum design, data ordering, augmen tation strategies, and even synthetic data that app ear counterin tuitive from a purely statistical viewp oin t. Our empirical estimator offers a concrete starting p oin t for comparing datasets and interv entions in data centric research. In the long run, we b elieve epiplexit y could provide guidance on ho w to generate new synthetic data from existing data. 29 Finally , representation learning can b e understo o d as the gradual accumulation of epiplexit y: the construction of increasingly rich internal programs that approximate a data distribution within a fixed time budget. While epiplexity in isolation is not a measure of generalization, or a complete theory of learning, this p ersp ectiv e raises the p ossibility of new notions of hardness for learning and transfer that are orthogonal to classical P AC-st yle measures, capturing not sample complexity but the size of the structure that m ust b e extracted. Such notions may help explain why certain tasks app ear to require disprop ortionately large mo dels or long training horizons despite admitting simple generativ e descriptions, and why improv emen ts in generalization sometimes correlate more strongly with training dynamics or data structure than with likelihoo d alone. A ckno wledgemen ts. W e thank NSF CAREER I IS-2145492, NSF CDS&E-MSS 2134216, and D ARP A AIQ HR00112590066 for supp ort, and Scott Aaronson, Alan Amin, Brandon Amos, Martin Marek, Zhili F eng, V aishnavh Nagara jan, Patric k Shafto, Charlie Chen, Alex Ozdemir, Andres P otap czynski, and Ethan Baron for helpful feedback. This work was supp orted by Go ogle’s TPU Researc h Cloud (TR C) program: https://sites.research.google/trc . YJ thanks the supp ort of the Go ogle PhD F ellowship, and SQ thanks the supp ort of the T wo Sigma F ellowship. References Scott Aaronson, Sean M Carroll, and Lauren Ouellette. Quan tifying the rise and fall of complexity in closed systems: the coffee automaton. arXiv pr eprint arXiv:1405.6903 , 2014. Marah Ab din, Jy oti Aneja, Harkirat Behl, Sébastien Bub eck, Ronen Eldan, Suriy a Gunasek ar, Mic hael Harrison, Russell J Hewett, Mo jan Jav aheripi, Piero Kauffmann, et al. Phi-4 tec hnical rep ort. arXiv pr eprint arXiv:2412.08905 , 2024. Alessandro A chille and Stefano Soatto. Ai agents as universal task solv ers. arXiv pr eprint arXiv:2510.12066 , 2025. Mic hael Ahn, Anthon y Brohan, Noah Brown, Y evgen Cheb otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan F u, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i c an, not as i say: Grounding language in rob otic affordances. arXiv pr eprint arXiv:2204.01691 , 2022. Eric Allender, Michal Kouc k` y, Detlef Ronneburger, and Sambuddha Roy . The p erv asive reac h of resource-b ounded kolmogoro v complexity in computational complexity theory . Journal of Computer and System Scienc es , 77(1):14–40, 2011. Philip W Anderson. More is different: Broken symmetry and the nature of the hierarchical structure of science. Scienc e , 177(4047):393–396, 1972. Luis An tunes, Lance F ortnow, Dieter v an Melkebeek, and N. V. Vino dc handran. Sophistication revisited. The ory of Computing Systems , 38(4):535–555, 2005. Benn y Applebaum. Cryptographic hardness of random lo cal functions: Survey . Computational c omplexity , 25(3):667–722, 2016. Nihat A y , Markus Müller, and Arleta Szk ola. Effectiv e complexity and its relation to logical depth. IEEE tr ansactions on information the ory , 56(9):4593–4607, 2010. Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. V ariational image compression with a scale hyperprior. arXiv pr eprint arXiv:1802.01436 , 2018. 30 Boaz Barak, Ronen Shaltiel, and A vi Wigderson. Computational analogues of entrop y . In International W orkshop on R andomization and Appr oximation T e chniques in Computer Scienc e , pages 200–215. Springer, 2003. Y oshua Bengio, T ristan Deleu, Nasim Rahaman, Rosemary Ke, Sébastien Lachapelle, Olexa Bilaniuk, Anirudh Go yal, and Christopher Pal. A meta-transfer ob jectiv e for learning to disentangle causal mec hanisms. arXiv pr eprint arXiv:1901.10912 , 2019. Charles H Bennett. Logical depth and ph ysical complexity . The Universal T uring Machine: A Half-Century Survey , 1:227–257, 1988. Quen tin Berthet and Philipp e Rigollet. Computational low er b ounds for sparse p ca. arXiv pr eprint arXiv:1304.0828 , 2013. Man uel Blum and Silvio Micali. Ho w to generate cryptographically strong sequences of pseudo random bits. In 23r d A nnual Symp osium on F oundations of Computer Scienc e (sfcs 1982) , pages 112–117, 1982. doi: 10.1109/SFCS.1982.72. James Bradbury , Roy F rostig, Peter Hawkins, Matthew James Johnson, Chris Leary , Dougal Maclaurin, George Necula, A dam Paszk e, Jake V anderPlas, Skye W anderman-Milne, and Qiao Zhang. JAX: comp osable transformations of Python+NumPy programs, 2018. URL http: //github.com/jax- ml/jax . Collin Burns, Pa v el Izmailov, Jan Hendrik Kirchner, Bow en Baker, Leo Gao, Leop old Aschen brenner, Yining Chen, Adrien Ecoffet, Manas Joglek ar, Jan Leike, et al. W eak-to-strong generalization: Eliciting strong capabilities with weak sup ervision. arXiv pr eprint arXiv:2312.09390 , 2023. Sean M Carroll and Ac hyuth P arola. What emergence can p ossibly mean. arXiv pr eprint arXiv:2410.15468 , 2024. Gregory J Chaitin. Information-theoretic limitations of formal systems. Journal of the ACM (JACM) , 21(3):403–424, 1974. Gregory J Chaitin. A theory of program size formally identical to information theory . Journal of the A CM (JA CM) , 22(3):329–340, 1975. Gregory J Chaitin. The limits of mathematics: A c ourse on information the ory and the limits of formal r e asoning . Springer, 1998. James P Crutchfield and NH719053 Pac k ard. Symbolic dynamics of noisy chaos. Physic a D: Nonline ar Phenomena , 7(1-3):201–223, 1983. A Philip Da wid. Presen t p osition and p otential dev elopments: Some p ersonal views statistical theory the prequential approach. Journal of the R oyal Statistic al So ciety: Series A (Gener al) , 147(2): 278–290, 1984. Mostafa Dehghani, Stephan Gouws, Oriol Vin yals, Jakob Uszkoreit, and Luk asz Kaiser. Universal transformers. arXiv pr eprint arXiv:1807.03819 , 2018. Grégoire Delétang, Anian Ruoss, Paul-Am broise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moy a, Li Kevin W enliang, Matthew Aitchison, Laurent Orseau, et al. Language mo deling is compression. arXiv pr eprint arXiv:2309.10668 , 2023. Nolan Dey , Bin Claire Zhang, Lorenzo No ci, Mufan Li, Blake Bordelon, Shane Bergsma, Cengiz P ehlev an, Boris Hanin, and Jo el Hestness. Don’t b e lazy: Completep enables compute-efficien t deep transformers. arXiv pr eprint arXiv:2505.01618 , 2025. 31 Ro d Downey and Denis R Hirschfeldt. Algorithmic randomness. Communic ations of the A CM , 62 (5):70–80, 2019. Gin tare Karolina Dziugaite and Daniel M Roy . The size of teachers as a measure of data complexity: P ac-bay es excess risk b ounds and scaling laws. In The 28th International Confer enc e on A rtificial Intel ligenc e and Statistics , 2025. Benjamin L Edelman, Ezra Edelman, Surbhi Go el, Eran Malach, and Nikolaos T silivis. The ev olution of statistical induction heads: In-context learning marko v chains. arXiv pr eprint arXiv:2402.11004 , 2024. Da vid F eldman. Information theory , excess entrop y . 1998. Marc Finzi, Sany am Kap oor, Diego Granziol, Anming Gu, Christopher De Sa, J Zico Kolter, and Andrew Gordon Wilson. Compute-optimal llms prov ably generalize b etter with scale. arXiv pr eprint arXiv:2504.15208 , 2025. Marc Finzi, et, and al. Requen tial co ding. F orthcoming, 2026. A viezri S F raenkel and David Lich tenstein. Computing a p erfect strategy for n × n chess requires time exp onential in n. In International Col lo quium on A utomata, L anguages, and Pr ogr amming , pages 278–293. Springer, 1981. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, T ra vis Hopp e, Charles F oster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of div erse text for language mo deling. arXiv pr eprint arXiv:2101.00027 , 2020. Martin Gardner. Mathematical games. Scientific americ an , 222(6):132–140, 1970. Murra y Gell-Mann and Seth Llo yd. Information measures, effective complexity , and total information. Complexity , 2(1):44–52, 1996. Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey , Rafael Rafailo v, Henry Sleight, John Hughes, T omasz Korbak, Ra jashree Agraw al, Dhruv Pai, Andrey Gromo v, et al. Is model collapse inevitable? breaking the curse of recursion by accumulating real and syn thetic data. arXiv pr eprint arXiv:2404.01413 , 2024. Angeliki Giannou, Shashank Ra jput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris P apailiop oulos. Loop ed transformers as programmable computers. In International Confer enc e on Machine L e arning , pages 11398–11442. PMLR, 2023. Micah Goldblum, Marc Finzi, Keefer Ro wan, and Andrew Gordon Wilson. The no free lunch theorem, k olmogorov complexity , and the role of inductive biases in machine learning. arXiv pr eprint arXiv:2304.05366 , 2023. Oded Goldreich. F oundations of Crypto gr aphy: V olume 1, Basic T o ols . Cambridge Universit y Press, 2006. Oded Goldreic h and Leonid A Levin. A hard-core predicate for all one-wa y functions. In Pr o c e e dings of the twenty-first annual A CM symp osium on The ory of c omputing , p ages 25–32, 1989. P eter Grassb erger. T ow ard a quantitativ e theory of self-generated complexity . International Journal of The or etic al Physics , 25(9):907–938, 1986. P eter D Grünw ald. The minimum description length principle . MIT press, 2007. P eter D Grünw ald, PM Vitányi, et al. Algorithmic information theory , 2008. 32 Nate Gruver, Marc Finzi, Shik ai Qiu, and Andrew G Wilson. Large language mo dels are zero-shot time series forecasters. A dvanc es in Neur al Information Pr o c essing Systems , 36:19622–19635, 2023. Alex Hägele, Elie Bakouc h, A tli Kosson, Leandro V on W erra, Martin Jaggi, et al. Scaling la ws and compute-optimal training b eyond fixed training durations. A dvanc es in Neur al Information Pr o c essing Systems , 37:76232–76264, 2024. Johan Håstad, Russell Impagliazzo, Leonid A Levin, and Michael Luby . A pseudorandom generator from an y one-wa y function. SIAM Journal on Computing , 28(4):1364–1396, 1999. T om Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heew o o Jun, T om B Brown, Prafulla Dhariwal, Scott Gray , et al. Scaling laws for autoregressiv e generativ e mo deling. arXiv pr eprint arXiv:2010.14701 , 2020. Jordan Hoffmann, Sebastian Borgeaud, Arth ur Mensc h, Elena Buc hatsk ay a, T revor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendric ks, Johannes W elbl, Aidan Clark, et al. T raining compute-optimal large language mo dels. arXiv pr eprint arXiv:2203.15556 , 2022. Ch un-Y uan Hsiao, Chi-Jen Lu, and Leonid Reyzin. Conditional computational entrop y , or tow ard separating pseudo en tropy from compressibility . In Annual International Confer enc e on the The ory and Applic ations of Crypto gr aphic T e chniques , pages 169–186. Springer, 2007. Marcus Hutter. Learning curve theory . arXiv pr eprint arXiv:2102.04074 , 2021. Yiding Jiang, Allan Zhou, Zhili F eng, Sadhik a Malladi, and J Zico Kolter. Adaptiv e data optimization: Dynamic sample selection with scaling laws. In The Thirte enth International Confer enc e on L e arning R epr esentations , 2025. URL https://openreview.net/forum?id=aqok1UX7Z1 . Jared Kaplan, Sam McCandlish, T om Henighan, T om B Brown, Benjamin Chess, Rewon Child, Scott Gray , Alec Radford, Jeffrey W u, and Dario Amo dei. Scaling laws for neural language mo dels. arXiv pr eprint arXiv:2001.08361 , 2020. Diederik P Kingma, Max W elling, et al. Auto-encoding v ariational bay es, 2013. A. N. Kolmogoro v. Three approaches to the quantitativ e definition of information *. International Journal of Computer Mathematics , 2(1-4):157–168, 1968. doi: 10.1080/00207166808803030. URL https://doi.org/10.1080/00207166808803030 . Moshe Koppel. Structure. In Rolf Herk en, editor, The Universal T uring Machine: A Half-Century Survey , pages 435–452. Oxford Universit y Press, 1988. Leon G. Kraft. A device for quan tizing, grouping, and coding amplitude-modulated pulses. S.m. thesis, Massach usetts Institute of T echnology , Cam bridge, MA, 1949. URL https://hdl.handle. net/1721.1/12390 . Ming Li and Paul Vitányi. An intr o duction to Kolmo gor ov c omplexity and its applic ations . Springer, New Y ork, NY, 2008. Ming Li, P aul Vitányi, et al. An intr o duction to Kolmo gor ov c omplexity and its applic ations , volume 3. Springer, 2008. Aixin Liu, Bei F eng, Bing Xue, Bingxuan W ang, Bochao W u, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical rep ort. arXiv pr eprint arXiv:2412.19437 , 2024. 33 Y anyi Liu and Rafael Pass. A direct prf construction from kolmogoro v complexity . In Annual International Confer enc e on the The ory and Applic ations of Crypto gr aphic T e chniques , pages 375–406. Springer, 2024. Da vid JC MacKay . Information the ory, infer enc e and le arning algorithms . Cam bridge universit y press, 2003. Prat yush Maini, Skyler Seto, He Bai, David Grangier, Yizhe Zhang, and Navdeep Jaitly . Rephras- ing the web: A recip e for compute and data-efficient language mo deling. arXiv pr eprint arXiv:2401.16380 , 2024. P er Martin-Löf. The definition of random sequences. Information and c ontr ol , 9(6):602–619, 1966. Genaro Juárez Martínez, Andrew Adamatzky , and Harold V McIntosh. Phenomenology of glider collisions in cellular automaton rule 54 and asso ciated logical gates. Chaos, Solitons & F r actals , 28 (1):100–111, 2006. Sean McLeish, John Kirchen bauer, David Y u Miller, Siddharth Singh, Abhinav Bhatele, Micah Goldblum, Ash winee P anda, and T om Goldstein. Gemstones: A mo del suite for m ulti-faceted scaling la ws. arXiv pr eprint arXiv:2502.06857 , 2025. Bro c kwa y McMillan. T w o inequalities implied by unique decipherability . IRE T r ansactions on Information The ory , 2(4):115–116, December 1956. doi: 10.1109/TIT.1956.1056818. Ralph C Merkle. Secure communications ov er insecure channels. Communic ations of the ACM , 21 (4):294–299, 1978. Roger J. Metzger. Sinai-ruelle-b ow en measures for contracting Lorenz maps and flows. Annales de l’I.H.P. A nalyse non liné air e , 17(2):247–276, 2000. URL https://www.numdam.org/item/AIHPC_ 2000__17_2_247_0/ . F rancisco Mota, Scott Aaronson, Luís Antunes, and André Souto. Sophistication as randomness deficiency . In Descriptional Complexity of F ormal Systems: 15th International W orkshop, DCFS 2013, L ondon, ON, Canada, July 22-25, 2013. Pr o c e e dings 15 , pages 172–181. Springer, 2013. Preetum Nakkiran, Behnam Neyshabur, and Hanie Sedghi. The deep b o otstrap framework: Go od online learners are go o d offline generalizers. arXiv pr eprint arXiv:2010.08127 , 2020. Catherine Olsson, Nelson Elhage, Neel Nanda, Nic holas Joseph, Nov a DasSarma, T om Henighan, Ben Mann, Amanda Askell, Y untao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv pr eprint arXiv:2209.11895 , 2022. Op enAI. GPT-5 System Card. https://cdn.openai.com/gpt- 5- system- card.pdf , August 2025. V ersion dated August 13, 2025. Accessed: 2026-01-05. V assilis Papadopoulos, Jérémie W enger, and Clément Hongler. Arro ws of time for large language mo dels. In F orty-first International Confer enc e on Machine L e arning , 2024. URL https:// openreview.net/forum?id=UpSe7ag34v . Tim P earce and Jiny eop Song. Reconciling k aplan and chinc hilla scaling laws. arXiv pr eprint arXiv:2406.12907 , 2024. Guilherme Penedo, Hynek Kydlíček, Anton Lozhko v, Margaret Mitchell, Colin A Raffel, Leandro V on W erra, Thomas W olf, et al. The fineweb datasets: Decanting the web for the finest text data at scale. A dvanc es in Neur al Information Pr o c essing Systems , 37:30811–30849, 2024. 34 Y a B Pesin. Characteristic lyapuno v exp onen ts and smo oth ergo dic theory . Russian Mathematic al Surveys , 32(4):55, 1977. Alec Radford, Jeffrey W u, Rewon Child, Da vid Luan, Dario Amo dei, Ilya Sutskev er, et al. Language mo dels are unsup ervised multitask learners. Op enAI blo g , 1(8):9, 2019. Ran Raz. F ast learning requires go o d memory: A time-space low er b ound for parity learning. Journal of the A CM (JA CM) , 66(1):1–18, 2018. Markus Redeker. A language for particle interactions in one-dimensional cellular automata. arXiv pr eprint arXiv:1012.0158 , 2010. Jorma Rissanen. Minimum description length principle. Encyclop e dia of statistic al scienc es , 7, 2004. John K Salmon, Mark A Moraes, Ron O Dror, and David E Shaw. Parallel random num bers: as easy as 1, 2, 3. In Pr o c e e dings of 2011 international c onfer enc e for high p erformanc e c omputing, networking, stor age and analysis , pages 1–12, 2011. Nikunj Saunshi, Nishan th Dikk ala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with laten t thoughts: On the p ow er of lo oped transformers. arXiv pr eprint arXiv:2502.17416 , 2025. Jürgen Sc hmidhuber. The sp eed prior: a new simplicity measure yielding near-optimal computable predictions. In International c onfer enc e on c omputational le arning the ory , pages 216–228. Springer, 2002. Glenn Shafer and Vladimir V ovk. The sources of kolmogoro v’s grundb egriffe. 2006. Cosma Rohilla Shalizi and James P Crutchfield. Computational mec hanics: Pattern and prediction, structure and simplicit y . Journal of Statistic al Physics , 104(3–4):817–879, 2001. Claude E Shannon. A mathematical theory of communication. The Bel l system te chnic al journal , 27 (3):379–423, 1948. Claude E. Shannon. Programming a computer for pla ying chess. Philosophic al Magazine , 41(314): 256–275, 1950. Rob ert Shaw. The dripping faucet as a mo del chaotic system. (No Title) , 1984. Da vid Silver, Thomas Hub ert, Julian Schritt wieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graep el, et al. A general reinforcement learning algorithm that masters c hess, shogi, and go through self-play . Scienc e , 362(6419):1140–1144, 2018. Daria Sob olev a, F aisal Al-Khateeb, Rob ert Myers, Jacob R Steeves, Jo el Hestness, and Nolan Dey . SlimP a jama: A 627B token cleaned and deduplicated version of RedPa jama. https://cerebras. ai/blog/slimpajama- a- 627b- token- cleaned- and- deduplicated- version- of- redpajama , 2023. URL https://huggingface.co/datasets/cerebras/SlimPajama- 627B . P eiyang Song, Kaiyu Y ang, and Anima Anandkumar. T ow ards large language mo dels as copilots for theorem pro ving in lean. arXiv pr eprint arXiv:2404.12534 , 2024. Jacob Steinhardt, Gregory V alian t, and Stefan W ager. Memory , communication, and statistical queries. In Confer enc e on L e arning The ory , pages 1490–1516. PMLR, 2016. Ily a Sutskev er. Gpt-2. Presented at the Scaled Machine Learning Conference 2019, Computer History Museum, 2019. https://www.youtube.com/watch?v=T0I88NhR_9M . 35 Sebastiaan A T erwijn. The mathematical foundations of randomness. In The Chal lenge of Chanc e: A Multidisciplinary Appr o ach fr om Scienc e and the Humanities , pages 49–66. Springer International Publishing Cham, 2016. Lucas Theis and Noureldin Y Ahmed. Algorithms for the communication of samples. In International Confer enc e on Machine L e arning , pages 21308–21328. PMLR, 2022. Naftali Tishb y , F ernando C P ereira, and William Bialek. The information b ottlenec k metho d. arXiv pr eprint physics/0004057 , 2000. Nik olay V ereshchagin and Paul M.B. Vitán yi. Kolmogoro v’s structure functions and model selection. IEEE T r ansactions on Information The ory , 50(12):3265–3290, 2004. John von Neumann. Zur theorie der gesellschaftsspiele. Mathematische A nnalen , 100(1):295–320, 1928. John V on Neumann. V arious techniques used in connection with random digits. Appl. Math Ser , 12 (36-38):3, 1951. Jason W ei, Xuezhi W ang, Dale Sch uurmans, Maarten Bosma, F ei Xia, Ed Chi, Quo c V Le, Denny Zhou, et al. Chain-of-though t prompting elicits reasoning in large language mo dels. A dvanc es in neur al information pr o c essing systems , 35:24824–24837, 2022. Gail W eiss, Y oa v Goldb erg, and Eran Y ahav. Thinking like transformers. In International Confer enc e on Machine L e arning , pages 11080–11090. PMLR, 2021. William F Whitney , Min Jae Song, Da vid Brandfon brener, Jaan Altosaar, and Kyungh yun Cho. Ev aluating represen tations b y the complexit y of learning low-loss predictors. arXiv pr eprint arXiv:2009.07368 , 2020. Stephen W olfram and M Gad-el Hak. A new kind of science. Appl. Me ch. R ev. , 56(2):B18–B19, 2003. Yilun Xu, Sheng jia Zhao, Jiaming Song, Russell Stewart, and Stefano Ermon. A theory of usable information under computational constraints. arXiv pr eprint arXiv:2002.10689 , 2020. Greg Y ang and Etai Littwin. T ensor programs ivb: A daptive optimization in the infinite-width limit. arXiv pr eprint arXiv:2308.01814 , 2023. Greg Y ang, Edw ard J Hu, Igor Babuschkin, Szymon Sidor, Xiao dong Liu, David F arhi, Nick Ryder, Jakub Pac ho c ki, W eizhu Chen, and Jianfeng Gao. T ensor programs v: T uning large neural netw orks via zero-shot hyperparameter transfer. arXiv pr eprint arXiv:2203.03466 , 2022. Andrew Chi-Chih Y ao. Theory and applications of trap door functions (extended abstract). In 23r d Ann ual Symp osium on F oundations of Computer Scienc e (F OCS) , pages 80–91. IEEE Computer So ciet y , 1982. doi: 10.1109/SFCS.1982.95. Shiy ang Zhang, Aak ash Patel, Sy ed A Rizvi, Nianchen Liu, Sizhuang He, Amin Karbasi, Emanuele Zappala, and David v an Dijk. In telligence at the edge of chaos. arXiv pr eprint arXiv:2410.02536 , 2024. Xiao Zhang, Xing jian Li, Dejing Dou, and Ji W u. Measuring information transfer in neural netw orks. arXiv pr eprint arXiv:2009.07624 , 2020. Hattie Zhou, Arwen Bradley , Etai Littwin, Noam Razin, Omid Saremi, Josh Susskind, Samy Bengio, and Preetum Nakkiran. What algorithms can transformers learn? a study in length generalization. arXiv pr eprint arXiv:2310.16028 , 2023. 36 App endix Outline This app endix provides the technical details, pro ofs, and exp erimen tal sp ecifications supp orting the main text. App endix A presents rigorous pro ofs of all theoretical results, including prop erties of cryptographi- cally secure pseudorandom num b er generators under time-bounded entrop y and epiplexity (Theorem 9), creation of information through deterministic transformations (Theorem 12), the existence of high-epiplexit y random v ariables (Theorem 10), the factorization dependence of information conten t (Theorem 13). App endix B details the practical metho dology for estimating epiplexity , cov ering b oth prequential and requen tial co ding implementations, hyperparameter optimization pro cedures for compute-optimal t wo-part co des, the connection b et ween prequential and requential estimates under a static teac her assumption, and a solv able analytical mo del combining neural scaling laws with prequential co ding. W e also establish general prop erties showing that optimal mo del size and training tokens increase monotonically with compute budget, that optimal training tokens for prequential co ding generally saturate at the test set size for large compute budgets, and that epiplexity and p er-token en tropy exhibit predictable monotonicit y with resp ect to dataset size. App endix C provides comprehensive exp erimental sp ecifications for all empirical results, includ- ing arc hitectural choices, h yp erparameters, and dataset details for elemen tary cellular automata exp erimen ts, easy and hard v ariants of induction tasks, chess exp erimen ts (with b oth pre-training data formatting and downstream ev aluation tasks), natural data exp eriments on Op en W ebT ext and CIF AR-5M, comparisons b etw een prequen tial and requential co ding estimates, and scaling la w estimation pro cedures. App endix D presents executable RASP-L co de demonstrating that elementary cellular automa- ton evolution rules can b e implemented within the transformer computational mo del, providing constructiv e evidence that autoregressive transformers are capable of solving these tasks. App endix E con tains definitions of elementary cell ular automata and Conw ay’s Game of Life, emergence examples referenced in the pap er. App endix F explores additional examples illustrating the relationship b et ween emergence and epiplexit y , including the Lorenz system as a case study in chaotic dynamics where entrop y is created at a rate determined by Ly apuno v exp onents, and c hess strategy as exemplified b y the contrast b et ween AlphaZero’s multi-million parameter netw orks solution at mo derate compute and the simple minimax algorithm a v ailable at very high compute. App endix G argues that induction phenomena o ccur not merely in autoregressive mo dels; instead, the key requirement is maximum likelihoo d estimation rather than autoregressive factorization sp ecifically . App endix H provides a more comprehensiv e review of MDL, in particular on tw o-part co de, one-part co de and the notion of regret, related to epiplexity . Compute Resources. A cluster of 6 2080Ti w as used for many of the smaller scale exp erimen ts. A cluster of 6 Titan R TX and 32 TPUv4 provided by the Go ogle TPU Research Cloud w as used for the more computationally exp ensiv e natural data exp eriments. W e refer the reader to Jiang et al. (2025) for computational resources required in ev aluating ADO. Licenses. The Chess data used in Section 5.2 is released under Creative Commons CC0 license ( database.lichess.org/ ). The Op en W ebT ext dataset used in Section 6.2 is released under Creative Commons CC0 license. 37 App endix A. Pro ofs First, we prov e t wo short lemmas ab out the basic prop erties of epiplexity and time-b ounded entrop y . Lemma 15 (Maxim um exp ected description length) F or any r andom variable X on { 0 , 1 } n ther e exists c onstants c 1 , c 2 , c 3 such that: S T ( X ) + H T ( X ) ≤ n + c 1 (11) for time b ounds T ( n ) ≥ c 2 n + c 3 . Pro of Let U n b e the uniform distribution Q unif ( x ) = 2 − n . Q unif can b e computed in linear time (just by outputting 2 − n for each input) and with a program of constant size c 1 and in time c 2 n + c 3 with constan ts dep ending on the T uring mac hine.. | Q ⋆ X | + E [ − log Q ⋆ X ( x )] ≤ | Q unif | + E [ − log Q unif ( x )] ≤ c + n. Lemma 16 (Time-b ounded en tropy of uniform distribution) L et X = U n b e the uni- form distribution on { 0 , 1 } n . The time-b ounde d entr opy of U n for T ( n ) ≥ c 2 n + c 3 is: n ≤ H T ( X ) ≤ n + c 1 . (12) Pro of F or the low er b ound, w e hav e E X [ − log Q ( X )] = H( X ) + D KL ( P X ∥ Q ) ≥ H( X ) = n giv en that the KL is alwa ys p ositiv e. F or the upp er b ound, we hav e that H T ( X ) ≤ MDL T ( X ) ≤ n + c . A.1 PR Gs/CSPRNGs ha ve (nearly) maximal time-bounded En tropy and lo w epiplexit y Theorem 17 L et X = U k and n = ℓ ( k ) for a non-uniform PR G G that admits advantage ε ( n ) . Then, for every p olynomial time b ound T ( n ) , H T ( G ( U k )) ≥ n − 2 − n ε ( k ) . (13) Pro of Fix P ∈ P T and let L ( x ) = − log P ( x ) . F or each precision level t ∈ { 1 , 2 , . . . , n } , we define the follo wing distinguisher: D t ( x ) = 1 { L ( x ) ≤ n − t } = 1 { P ( x ) ≥ 2 − ( n − t ) } . 38 F or an y solution P for MDL T , we hav e that MDL T ( X ) = | P | + E [ − log P ( X )] ≤ n + c . Since b oth quan tities are positive, it must b e the case that | P |≤ n + c , which means that | P |∈ p oly ( n ) . Since P b elongs in P T and cannot b e longer than n , each D t is a non-uniform PPT algorithm with polysized advice (i.e., P ) that PRGs are secure against. Uniform threshold b ound. Let U n b e uniform on { 0 , 1 } n and set A t := { x : D t ( x ) = 1 } . 1 ≥ X x P ( x ) ≥ X x ∈ A t P ( x ) ≥ | A t | 2 − ( n − t ) ⇒ | A t |≤ 2 n − t . Hence , Pr[ D t ( U n ) = 1] = | A t | 2 n ≤ 2 n − t 2 n = 2 − t . PR G transfers b ound to X := G ( U k ) . By the security of G , for each t , Pr[ D t ( X ) = 1] ≤ Pr[ D t ( U n ) = 1] + ε ( k ) ≤ 2 − t + ε ( k ) , F rom threshold probabilities to an entrop y low er b ound. F or any non-negativ e random v ariable Z , w e hav e the lay e rcak e representation: E [ Z ] = ∞ X u =0 (1 − P ( Z ≤ u )) (14) n − E [ Z ] = n − 1 X u =0 1 − ∞ X u =0 (1 − P ( Z ≤ u )) (15) = n − 1 X u =0 1 − n − 1 X u =0 (1 − P ( Z ≤ u )) − ∞ X u = n (1 − P ( Z ≤ u )) (16) = n − 1 X u =0 P ( Z ≤ u ) − ∞ X u = n (1 − P ( Z ≤ u )) (17) ≤ n − 1 X u =0 P ( Z ≤ u ) . (18) No w we change the b ounds to b e in terms of t with t = n − u . The low er b ound b ecomes t = n . The upp er b ound b ecomes t = 1 , which yields n − E [ Z ] ≤ n − 1 X u =0 P ( Z ≤ u ) = n X t =1 P ( Z ≤ n − t ) . Let Z = L ( X ) = − log P ( X ) : n − E [ Z ] ≤ n X t =1 P ( Z ≤ n − t ) = n X t =1 P ( D t ( X ) = 1) ≤ n X t =1 2 − t + ε ( k ) ≤ 1 + nε ( k ) . The last t wo steps come from the fact that X is a CSPRNG. This means that: n − E [ L ( X )] ≤ 1 + nε ( k ) ⇒ E [ − log P ( X )] ≥ n − nε ( k ) − 1 . Since this is true for any P ∈ P T , taking the minimum yields: H T ( X ) = H T ( G ( U n )) = min P ∈P T E [ − log P ( X )] ≥ n − nε ( k ) − 1 . 39 A.2 Deterministic transformation can increase time b ounded en tropy and epiplexit y Theorem 18 L et G : { 0 , 1 } k → { 0 , 1 } n b e a CSPRNG which admits advantage ε ( k ) and U k b e the uniform distribution. H Poly ( G ( U k )) > H Poly ( U k ) + n − k − nε ( k ) − c for a fixe d c onstant c . Pr o of: se e App endix A.1. Pro of By Lemma 15 applied to the uniform distribution on { 0 , 1 } k , there is an absolute constan t c suc h that H poly ( U k ) ≤ k + c. Rearranging gives k ≥ H poly ( U k ) − O (1) . Combining this with the assumed CSPRNG low er b ound (Lemma 17), H poly ( G ( U k )) ≥ n − 2 − nε ( k ) , w e obtain, H poly ( G ( U k )) − H poly ( U k ) ≥ n − 2 − nε ( k ) − ( k + c ) ⇒ H Poly ( G ( U k )) > H Poly ( U k ) + n − nε ( k ) − k − O (1) . A.3 CSPRNGs ha ve lo w epiplexit y Theorem 19 L et X = U k and n = ℓ ( k ) for CSPRNG G that admits advantange ε ( n ) . Then, for every p olynomial time b ound T ( n ) , the epiplexity of Y = G ( X ) is, S T ( Y ) ≤ c + nε ( k ) . (19) Pro of W e kno w from Theorem 17 that H T ( G ( U k )) ≥ n − nε ( k ) − 2 , which means: S T ( Y ) + H T ( Y ) ≥ S T ( Y ) + n − nε ( k ) − 2 . (20) W e also hav e from Lemma 15 that S T ( Y ) + H T ( Y ) ≤ n + c . Combining these tw o results yields: S T ( Y ) + n − nε ( k ) − 1 ≤ n + c ⇒ S T ( Y ) ≤ c + nε ( k ) . (21) A.4 Existence of High Epiplexit y random v ariables Definition 20 (Pseudorandom functions (PRF)) L et PRF b e the class of keye d functions F : { 0 , 1 } k × { 0 , 1 } n → { 0 , 1 } m that ar e c omputable in p olynomial time and satisfy the fol lowing pr op erty: F or any pr ob abilistic p olynomial-time distinguisher D with or acle ac c ess to the pr ovide d function, | Pr K ∼ U k [ D F K ( · ) ] − Pr f ∼F n [ D f ( · ) ] | < 1 n c , (22) for al l inte gers c > 0 and sufficiently lar ge n . Her e, F K ( · ) denotes the function F ( K, · ) with the key K fixe d, and F n is the set of al l functions mapping { 0 , 1 } n to { 0 , 1 } m . 40 Cryptographic assumptions. Assume one-wa y functions exist (secure against non-uniform PPT adv ersaries with inv ersion probability at most ε ( n ) ). By standard constructions (Håstad et al., 1999), this implies the existence of PRF s secure against non-uniform PPT distinguishers with adv antage p oly( ε ( n )) (and in particular negligible if ε ( n ) is negligible). Definition 21 (Hea vy set) F or a distribution Q on { 0 , 1 } n , m < n , and a fixe d thr eshold t ≥ 0 , the ( Q, t ) -he avy set is: A Q,t := { z : Q ( z ) ≥ 2 − 2( m + t ) } . (23) Lemma 22 L et P b e a distribution on { 0 , 1 } n with entr opy H( P ) = m . If KL ( P , Q ) ≤ t , then P ( A Q,t ) ≥ 1 2 . Pro of First, observe the standard inequality: E z ∼ P log 1 Q ( z ) = H( P ) + KL( P ∥ Q ) ≤ m + t. Applying Mark ov’s inequality , we get: Pr z ∼ P log 1 Q ( z ) ≥ 2( m + t ) ≤ E [ − log Q ( z )] 2( m + t ) ≤ 1 2 . (24) T aking the complement gives: Pr z ∼ P log 1 Q ( z ) ≤ 2( m + t ) = Pr z ∼ P h Q ( z ) ≥ 2 − 2( m + t ) i = P ( A Q,t ) ≥ 1 2 . (25) Lemma 23 L et U n b e the uniform distribution over { 0 , 1 } n , the weights of A Q,t under U n is U n ( A Q,t ) ≤ 2 − ( n − 2( m + t )) Pro of F or z ∼ U n , w e hav e E z ∼ U n [ Q ( z )] = P z 2 − n Q ( z ) = 2 − n . Applying Marko v’ inequaltiy: Pr z ∼ U n h Q ( z ) ≥ 2 − 2( m + t ) i ≤ E z ∼ U n [ Q ( z )] 2 − 2( m + t ) ≤ 2 − n +2( m + t ) = 2 − ( n − 2( m + t )) . (26) Theorem 24 If ther e exists a PRF family F K : { 0 , 1 } m → { 0 , 1 } k that is indexe d by K ∈ { 0 , 1 } m and se cur e against a non-uniform PPT distinguisher D m al lowing for an advantage of at most ε ( m ) , ther e exists n 0 such that for al l n = m + k ≥ n 0 , ther e exists a se quenc e of r andom variables { X k } n k =1 over { 0 , 1 } n such that S Poly ( X n ) = Ω(log n ) . Pro of W e will prov e the existence of suc h P via a counting argumen t. First, we define the family of distributions of in terest. Concretely , we draw a sample P K as follo ws: 41 1. Sample x ∼ U m 2. Output z = ( x, F K ( x )) ∈ { 0 , 1 } n Since F K is a deterministic function, H( P K ) = m . W e also defined a keye d mo del Q K that mo dels P K b y directly storing the key K and the program for generating PRF from K inside its program: Q K ( x, y ) = 2 − m 1 { y = F K ( x ) } . This mo del matches the density of P K so KL( P K ∥ Q K ) = 0 , and: L ( Q K , P K ) = | Q K | +H( P K ) ≤ m + c 1 + m = 2 m + c 1 . c 1 is the constant ov erhead to implement the PRF ev aluation and sampling wrapp er under a fixed enco ding (i.e., a UTM). Constructing distinguisher from Q . Given a mo del Q and its heavy set A Q,t (Definition 21), w e can turn Q into a single-query distinguisher D O : 1. Sample x ∼ U m and query the oracle y = O ( x ) and set z = ( x, y ) . 2. Output 1 if z ∈ A Q,t i.e., Q ( z ) ≥ 2 − 2( m + t ) else 0 . If O is a truly random function R , then ( x, R ( x )) follows U n and b y Lemma 23: Pr D R = 1 = Pr z ∼ U n [ z ∈ A Q,t ] ≤ 2 − ( n − 2( m + t )) (27) If O is the PRF F K for a K that satisfies KL( P K ∥ Q ) ≤ t , Lemma 22 gives: Pr D F K = 1 | KL( P K ∥ Q ) ≤ t ≥ 1 2 . (28) Let p Q,t = Pr K [ KL ( P K ∥ Q ) ≤ t ] . W e can av erage ov er all p ossible K and obtain the follo wing b ound: Pr D F K = 1 ≥ Pr K [KL( P K ∥ Q ) ≤ t ] Pr D F K = 1 | KL( P K ∥ Q ) ≤ t ≥ 1 2 p Q,t . (29) Therefore, the distinguishing adv antage of D O is: Adv ( D O ) = Pr D F K = 1 − Pr D R = 1 ≥ 1 2 p Q,t − 2 − ( n − 2( m + t )) . (30) Rearranging: p Q,t ≤ 2 Adv ( D O ) + 2 · 2 − ( n − 2( m + t )) . (31) Since F K is a PRF and D O is a PPT distinguisher, the adv antage is upp erb ounded by ε ( m ) : p Q,t ≤ 2 ε ( m ) + 2 · 2 − ( n − 2( m + t )) . (32) Union b ound o ver short models. Given a maximum program length s , there are at most 2 s +1 candidate programs Q with | Q |≤ s . Applying union b ound on all such Q ’s: Pr K [ ∃ Q : | Q |≤ s ∧ KL( P K ∥ Q ) ≤ t ] ≤ 2 s +1 p Q,t ≤ 2 s +1 2 ε ( m ) + 2 · 2 − ( n − 2( m + t )) . (33) No w, it suffices to c ho ose parameters suc h that the RHS of equation 33 is smaller than 1 , whic h implies there exists a hard key K ⋆ suc h that: KL( P K ⋆ ∥ Q ) > t, ∀ Q satisfying | Q |≤ s. (34) 42 MDL lo wer bound from K ⋆ . F or K ⋆ , ev ery | Q |≤ s satisfies: L ( Q, P K ⋆ ) = | Q | +H( P ⋆ ) + KL( P K ⋆ ∥ Q ) ≥ H( P ⋆ ) + KL( P K ⋆ ∥ Q ) ≥ m + t. Mean while, the key ed mo del Q K ⋆ satisfies: L ( Q K ⋆ , P K ⋆ ) ≤ 2 m + c 1 . If we set: t = m + c 1 + ∆ , w e get a margin of ∆ : L ( Q, P K ⋆ ) ≥ m + m + c 1 + ∆ > 2 m + c 1 ≥ L ( Q K ⋆ , P K ⋆ ) . (35) This implies that there exists at least one mo del that ac hiev es a low er description length than any Q with | Q |≤ s and the MDL minimizer must hav e | Q ⋆ | > s . Cho osing parameters. Set: • s = log m • ∆ = log m • t = m + c 1 + ∆ = m + c 1 + log m • k = 4 m + 4∆ + 2 c 1 W e no w plug these v alues into Equation 33. First, 2 s +1 = p oly ( m ) and lim m →∞ 2 s +1 · 2 ε ( m ) = 0 . F or the second term: 2 s +1 · 2 · 2 − ( n − 2( m + t )) =2 log m +1 · 2 · 2 − ( m +4 m +4∆+2 c 1 − 2( m + m + c 1 +log m )) =2 log m +2 · 2 − (5 m +4 log m +2 c 1 − 2(2 m + c 1 +log m )) =2 log m +2 · 2 − ( m +2 log m ) =2 − m − log m +2 . This term also approaches 0 as m increases. So for sufficiently large m the RHS of Equation 33 is less than 1 as desired. A.5 Information Con tent is not Independent of F actorization Theorem 25 (O WP induces entrop y asymmetry) L et f : { 0 , 1 } n → { 0 , 1 } n b e a p olynomial-time c omputable one-way p ermutation se cur e against non-uniform PPT inverters with ne gligible suc c ess pr ob ability. L et X = U n and Y = f ( X ) . L et H poly ( · ) and H poly ( · | · ) b e define d as in Definition 8. Then for every c onstant c > 0 ther e exists N such that for al l n ≥ N , H poly ( X | Y ) + H poly ( Y ) > H poly ( Y | X ) + H poly ( X ) + c log n. Pro of W e pro ve b ounds on each term. 43 Unconditional terms H poly ( X ) and H poly ( Y ) . Since X = U n and f is a p erm utation, Y = f ( X ) is also uniform on { 0 , 1 } n . By Lemma 15 (time-b ounded en tropy of the uniform distribution), there is a constan t c 0 suc h that n ≤ H poly ( X ) ≤ n + c 0 , n ≤ H poly ( Y ) ≤ n + c 0 . In particular, − c 0 ≤ H poly ( Y ) − H poly ( X ) ≤ c 0 , so H poly ( Y ) − H poly ( X ) = O (1) . F orward conditional term H poly ( Y | X ) . There is a deterministic conditional sampler that on input x outputs f ( x ) . F or this sampler, P ( Y | X ) = 1 , hence log(1 /P ( Y | X )) = 0 . Since H poly ( Y | X ) is the exp ected log-loss of the MDL-optimal conditional sampler, we obtain H poly ( Y | X ) = O (1) . Hard conditional term H poly ( X | Y ) . Let P ⋆ := P ⋆ X | Y b e the MDL-optimal conditional proba- bilistic mo del for X | Y ov er the class of non-uniform PPT mo del, and define ϕ ( y ) := Pr u ∼ U ∞ h Sample P ⋆ X | y ( u ) = f − 1 ( y ) i . Because Y = f ( X ) and f is a p erm utation, we hav e X = f − 1 ( Y ) , and th us P ⋆ ( X | Y ) = P ⋆ ( f − 1 ( Y ) | Y ) = ϕ ( Y ) a.s. Therefore H poly ( X | Y ) = E h log 1 P ⋆ ( X | Y ) i = E h log 1 ϕ ( Y ) i . By Jensen’s inequalit y for the conv ex function log(1 /t ) , E h log 1 ϕ ( Y ) i ≥ log 1 E [ ϕ ( Y )] . No w consider the inv erter I that on input y runs the sampler P ⋆ ( X | Y ) once and outputs the resulting x . Since P ⋆ is a non-uniform PPT sampler, I is a non-uniform PPT inv erter. Moreo ver, its in version success probability is exactly Pr I ( Y ) = f − 1 ( Y ) = E [ ϕ ( Y )] . Equiv alently (since Y = f ( X ) ), Pr X ∼ U n [ I ( f ( X )) = X ] = E [ ϕ ( Y )] . By one-wa yness, this success probability is negligible. In particular, for every constant c > 0 there exists N such that for all n ≥ N , E [ ϕ ( Y )] ≤ n − c . Plugging in to the Jensen b ound yields, for all n ≥ N , H poly ( X | Y ) ≥ log 1 E [ ϕ ( Y )] ≥ c log n. Com bine. F or n ≥ N , w e hav e H poly ( X | Y ) + H poly ( Y ) ≥ c log n + H poly ( Y ) (36) ≥ c log n + H poly ( X ) − O (1) (37) = H poly ( Y | X ) + H poly ( X ) + c log n − O (1) , (38) where w e used H poly ( Y | X ) = O (1) and H poly ( Y ) − H poly ( X ) ≥ − c 0 . 44 Corollary 26 L et f b e a one-way p ermutation and lef X = Unif ( { 0 , 1 } n ) , Y = f ( X ) . Define P as a family of pr ob abilistic gener ative mo del that al lows for multiple factorizations of the data, ie P ∈ P it c an make pr e dictions P 1 → 2 ( X, Y ) = P 1 ( X ) P 2 ( Y ; X ) and P 2 → 1 ( X, Y ) = P 2 ( Y ) P 1 ( X ; Y ) for the functions P 1 ( · ) , P 1 ( · ; · ) , P 2 ( · ) , P 2 ( · ; · ) that ar e normalize d pr ob ability distributions over the first variable. Supp ose that P fits the forwar d dir e ction of f (and the input uniform distributions) E [ − log P 1 ( X )] ≤ n + ε E [ − log P 2 ( f ( X ) | X )] ≤ ε then it must violate Bayes the or em P 1 → 2 = P 2 → 1 by a mar gin gr owing with n . Sp e cific al ly, for any value of c ther e exists N such that for al l n > N , ther e exists at le ast one x ∈ { 0 , 1 } n such that P 1 ( x ) P 2 ( f ( x ); x ) > n c 2 − 2 ε P 2 ( f ( x )) P 1 ( x ; f ( x )) (39) Pro of F rom Theorem 25 whic h applies also for each P , we hav e E [ − log P 2 ( X ; Y )] > c log n. The minimim v alue of E [ − log P 2 ( f ( X ))] is n since f is a bijection. Assembling these comp onents, E log P 1 ( X ) P 2 ( f ( X ); X ) P 2 ( f ( X )) P 1 ( X ; f ( X )) > c log n − 2 ε. (40) Since the inequality holds in exp ectation, it also must hold for at least one v alue of X . Exp onentiating pro vides the final result. A.6 Problems with time-b ounded sophistication Epiplexit y can b e seen as a time-b ounded and distributional generalization of sophistication. A natural question is whether we can directly define a time-b ounded version of sophistication for individual strings. W e show b elow that a naiv e time-b ounded generalization degenerates: it makes the “mo del” part essen tially constant for every string. Preliminaries. Fix a reference universal (prefix-free or plain) T uring machine U . F or a program p and auxiliary input d , we write U ( p, d ) for the output of running p on input d . The length of a binary string p is denoted | p | . A program p is total if U ( p, d ) halts for every input d (i.e., p computes a total func tion). W e write K ( x ) for Kolmogoro v complexity (plain or prefix; the choice only changes v alues by O (1) ). F or a time b ound t ( · ) , the time-b ounded Kolmogoro v complexity is K t ( x ) := min { | q | : U ( q ) outputs x within t ( | x | ) steps } . (An y standard time-constructible t suffices for the discussion.) W e adopt the definition of sophistication from Koppel (1988) and Antunes et al. (2005), phrased for finite strings as in later exp ositions. F or a significance level c ≥ 0 , the sophistication of x is 45 Definition 27 (Sophistication at significance c ) soph c ( x ) := min p n | p | : p is total and ∃ d such that U ( p, d ) = x and | p | + | d |≤ K ( x ) + c o . In tuitively , ( p, d ) is a near-optimal t w o-part description of x . The requirement that p b e total is crucial: it preven ts taking p to b e a tiny universal interpreter and pushing all information in to d (since a universal in terpreter is not total). One of the most intuitiv e attempts at “time-b ounded sophistication” is to simply replace K ( x ) by the time-b ounded complexity K t ( x ) in Definition 27. Definition 28 (Naiv e time-b ounded sophistication) Fix a time b ound t ( · ) and signific anc e level c ≥ 0 . Define soph t c ( x ) := min p n | p | : p is total and ∃ d such that U ( p, d ) = x and | p | + | d |≤ K t ( x ) + c o . The definition ab o ve c ol lapses , essentially b ecause time b ounds make it easy to “totalize” a universal in terpreter by adding a timeout. Lemma 29 (Naiv e time-b ounded sophistication is O (1) ) F or every time b ound t ( · ) and every c ≥ 0 , ther e exists a c onstant C t (dep ending only on t and the choic e of U ) such that for every string x , soph t c ( x ) ≤ C t . In p articular, soph t c ( x ) do es not me aningful ly distinguish structur e d strings fr om r andom- lo oking strings. Pro of [sk etch] Fix t . Let p tl b e a constant-size program that, on input d , simulates U ( d ) for at most t ( | x | ) steps (or more generally for the same time budget used in the definition of K t ( x ) ), and: (i) if the sim ulation halts within the budget, output the same result; otherwise (ii) output a fixed default string (sa y 0 ). By construction, p tl is total (it alw ays halts, b ecause it enforces a timeout). No w let d ⋆ b e a shortest program witnessing K t ( x ) , i.e., | d ⋆ | = K t ( x ) and U ( d ⋆ ) outputs x within the allo wed time. Then U ( p tl , d ⋆ ) = x . Moreov er, | p tl | + | d ⋆ | = | p tl | + K t ( x ) ≤ K t ( x ) + c for all c ≥ | p tl | . Th us p tl is feasible in Definition 28, giving soph t c ( x ) ≤ | p tl | = C t for all x . In the original (unbounded-time) Definition 27, totality preven ts a universal in terpreter from b eing used as the “mo del” part, b ecause such an interpreter cannot halt on inputs that enco de non-halting computations. Ho wev er, once w e commit to a time b ound in the optimality criterion (i.e., we compare against K t ( x ) ), the data part d can b e chosen to b e a short program that is guar ante e d to halt quickly . A constant-size clo cke d interpr eter p tl is then total and suffices for every x , pushing all of the description length into d . This is precisely the sense in whic h the naive time-b ounded generalization b ecomes degenerate. App endix B. Measuring Epiplexit y B.1 F urther details on estimating epiplexity Here w e provide further details on measuring epiplexity . 46 Ev aluating co de lengths and time b ounds. As describ ed in Section 4, ev aluating the co de length for the mo del b oils do wn to tracking the training losses (prequential) or teacher-studen t KL (requen tial) at each step i : | P preq | ≈ M − 1 X i =0 (log 1 /P i ( Z i ) − log 1 /P M ( Z i )) , (41) | P req | ≈ M − 1 X i =0 KL( P t i ∥ P s i ) . (42) F or prequential coding, we need to compute the loss of the final mo del summed ov er the entire training dataset, P M − 1 i =0 log 1 /P M ( Z i ) , which is time-consuming if done exactly . Since all of our exp erimen ts are in the one-ep och training regime without data rep eat and training data Z i are dra wn i.i.d. (except for the ADO exp eriment Section 6.4), we make the assumption that the generalization gap is small and estimate P M − 1 i =0 log 1 /P M ( Z i ) as M log 1 /P M ( Z M ) , where the latter is a rescaled loss for P M on unseen data Z M . The i.i.d. assumption breaks do wn for the ADO exp eriment Section 6.4, where w e instead compute P M − 1 i =0 log 1 /P M ( Z i ) exactly . F or requential co ding, we need to ev aluate the teacher-studen t KL, KL ( P t ∥ P s ) , at each training step. The KL div ergence ov er sequences decomp oses as a sum ov er token p ositions and is estimated as: KL( P t ∥ P s ) = L X j =1 E Z 0 , e D ≥ 2 D J ( N , e D ) s.t. N e D = T . (67) Assume that for e ach T in the r e gime of inter est ther e is a unique interior optimizer ( N ⋆ ( T ) , e D ⋆ ( T )) with e D ⋆ ( T ) > 2 D and N ⋆ ( T ) e D ⋆ ( T ) = T . W ork in lo garithmic c o or dinates µ := log N and ν := log e D , and by slight abuse of notation write J ( µ, ν ) = J ( e µ , e ν ) . Assume that for al l such T , the fol lowing c onditions hold at the c orr esp onding optimum ( µ ⋆ ( T ) , ν ⋆ ( T )) : 1. Complementarity (lar ger mo dels ar e mor e sample-efficient): ∂ 2 J ∂ µ∂ ν ≤ 0 . (68) 2. Diminishing r eturns in mo del size (in lo g c o or dinates): ∂ 2 J ∂ µ 2 > 0 . (69) 3. Diminishing r eturns in effe ctive data (in lo g c o or dinates): ∂ 2 J ∂ ν 2 > 0 . (70) Then b oth c ompute-optimal choic es ar e strictly incr e asing functions of T : T 2 > T 1 = ⇒ N ⋆ ( T 2 ) > N ⋆ ( T 1 ) and e D ⋆ ( T 2 ) > e D ⋆ ( T 1 ) . (71) Pro of W ork in logarithmic co ordinates µ := log N , ν := log e D , τ := log T . (72) The compute constrain t N e D = T b ecomes the affine constraint µ + ν = τ ⇐ ⇒ ν = τ − µ. (73) By slight abuse of notation, write J ( µ, ν ) := J ( e µ , e ν ) and denote its partial deriv ativ es by J µ , J ν , J µµ , J ν ν , J µν , etc., all taken with resp ect to the log-co ordinates ( µ, ν ) . 53 Define the r estricte d obje ctive along the compute frontier by f ( µ, τ ) := J ( µ, τ − µ ) . (74) F or each τ in the regime of in terest, let µ ⋆ ( τ ) denote the unique in terior minimizer of f ( · , τ ) , and set ν ⋆ ( τ ) := τ − µ ⋆ ( τ ) . Holding τ fixed and differentiating f with resp ect to µ gives f µ ( µ, τ ) = ∂ ∂ µ J ( µ, τ − µ ) = J µ ( µ, ν ) + J ν ( µ, ν ) ∂ ∂ µ ( τ − µ ) = J µ ( µ, ν ) − J ν ( µ, ν ) , (75) where ν = τ − µ . The optimality condition for µ ⋆ ( τ ) is therefore f µ ( µ ⋆ ( τ ) , τ ) = 0 ⇐ ⇒ J µ ( µ ⋆ ( τ ) , ν ⋆ ( τ )) = J ν ( µ ⋆ ( τ ) , ν ⋆ ( τ )) . (76) Differen tiating the identit y f µ ( µ ⋆ ( τ ) , τ ) = 0 with resp ect to τ yields 0 = d dτ f µ ( µ ⋆ ( τ ) , τ ) = f µµ ( µ ⋆ ( τ ) , τ ) dµ ⋆ dτ + f µτ ( µ ⋆ ( τ ) , τ ) . (77) Assuming f µµ ( µ ⋆ ( τ ) , τ ) = 0 (verified b elow), w e obtain dµ ⋆ dτ = − f µτ f µµ ev aluated at ( µ, τ ) = ( µ ⋆ ( τ ) , τ ) . (78) W e no w express f µτ and f µµ in terms of second partial deriv atives of J . F rom (75) and the c hain rule, using ∂ τ ( τ − µ ) = 1 , f µτ ( µ, τ ) = ∂ ∂ τ ( J µ ( µ, ν ) − J ν ( µ, ν )) = J µν ( µ, ν ) ∂ ν ∂ τ − J ν ν ( µ, ν ) ∂ ν ∂ τ = J µν ( µ, ν ) − J ν ν ( µ, ν ) , (79) with ν = τ − µ . Similarly , differen tiating (75) with resp ect to µ while holding τ fixed, and using ∂ µ ( τ − µ ) = − 1 together with symmetry J ν µ = J µν , yields f µµ ( µ, τ ) = ∂ ∂ µ ( J µ ( µ, ν ) − J ν ( µ, ν )) = J µµ ( µ, ν ) + J µν ( µ, ν ) ∂ ν ∂ µ − J ν µ ( µ, ν ) + J ν ν ( µ, ν ) ∂ ν ∂ µ = ( J µµ − J µν ) − ( J µν − J ν ν ) = J µµ ( µ, ν ) + J ν ν ( µ, ν ) − 2 J µν ( µ, ν ) . (80) Substituting (79)–(80) into (78) gives dµ ⋆ dτ = − J µν − J ν ν J µµ + J ν ν − 2 J µν = J ν ν − J µν J µµ + J ν ν − 2 J µν , (81) 54 with all second partial deriv atives of J ev aluated at ( µ, ν ) = ( µ ⋆ ( τ ) , ν ⋆ ( τ )) . By the assumptions J ν ν > 0 and J µν ≤ 0 at the optimum, the numerator in (81) satisfies J ν ν − J µν > 0 . By the assumptions J µµ > 0 , J ν ν > 0 , and J µν ≤ 0 , the denominator satisfies J µµ + J ν ν − 2 J µν > 0 . Hence dµ ⋆ dτ > 0 . (82) Since ν ⋆ ( τ ) = τ − µ ⋆ ( τ ) , we also hav e dν ⋆ dτ = 1 − dµ ⋆ dτ = J µµ − J µν J µµ + J ν ν − 2 J µν > 0 , (83) where p ositivit y follows from J µµ > 0 and J µν ≤ 0 together with the same p ositive denominator. Finally , N ⋆ ( T ) = exp( µ ⋆ (log T )) and e D ⋆ ( T ) = exp( ν ⋆ (log T )) , so dµ ⋆ /dτ > 0 and dν ⋆ /dτ > 0 imply that b oth N ⋆ ( T ) and e D ⋆ ( T ) are strictly increasing functions of T . Empirical plausibilit y of the assumptions. The three conditions in Theorem 30 reflect well- do cumen ted empirical phenomena in deep learning. The complementarit y condition ∂ 2 J /∂ µ∂ ν ≤ 0 captures the observ ation that larger mo dels are more sample-efficien t: increasing mo del size leads to faster learning (Kaplan et al., 2020; Y ang et al., 2022), which leads to a faster decrease in b oth the mo del description length and data code length (final loss), and th us ∂ J /∂ ν should decrease with µ . The diminishing returns conditions ∂ 2 J /∂ µ 2 > 0 and ∂ 2 J /∂ ν 2 > 0 simply state that there is diminishing return in successive doubling of the mo del size or training data size, holding the other quan tity fixed. Asymptotic gro wth of S T and monotone deca y of H T . The monotone growth of the compute- optimal N ⋆ ( T ) and D ⋆ ( T ) do es not by itself imply that S T ( X ) := | P | ( N ⋆ ( T ) , D ⋆ ( T )) is monotone for all T . Intuitiv ely , while we exp ect the mo del description length | P | ( N , D ) to grow with D , it need not increase with N : larger models can b e more sample-efficien t, whic h ma y reduce the effectiv e complexit y of the learned predictor under some co ding schemes. How ever, one should still exp ect S T ( X ) to grow with T , at least asymptotically , if we assume (1) the compute-optimal mo del size div erges while the optimal training horizon con v erges, as in the scaling-la w mo del of Section B.3, and (2) th e existence of infinite-mo del-size limits of the training dynamics. That is, assume that along the compute-optimal path, N ⋆ ( T ) → ∞ and D ⋆ ( T ) → D ∞ < ∞ as T → ∞ . (84) Assume moreov er that for b ounded training horizons, the description length admits a well-defined infinite-mo del-size limit: there exists a function | P | ∞ ( D ) such that for each fixed D , | P | ( N , D ) → | P | ∞ ( D ) as N → ∞ . (85) This assumption is motiv ated b y the existence of infinite-width and depth limits of neural netw orks under appropriate parameterizations (Y ang and Littwin, 2023; Dey et al., 2025), where scalar quan tities such as loss and teacher–studen t KL divergence that determine | P | ( N , D ) admit stable large-mo del limits for b ounded training durations. Under these conditions, an y non-monotonic dep endence of | P | on N is a finite-mo del effect; once N ⋆ ( T ) is large enough, | P | ( N ⋆ ( T ) , D ⋆ ( T )) is w ell-approximated b y the limiting curve | P | ∞ ( D ⋆ ( T )) . Since D ⋆ ( T ) is monotone increasing and con vergen t under our earlier assumptions, the large- T b eha vior of S T ( X ) is therefore gov erned 55 primarily by the b ehavior of D ⋆ ( T ) alone, which we hav e shown is increasing with T , so one exp ects S T ( X ) to increase at large T as | P | ∞ ( D ) should increase with D . F or the entrop y term H T ( X ) := D L ( N ⋆ ( T ) , D ⋆ ( T )) , the conclusion is simpler and do es not require taking N → ∞ . Assume only that the loss L ( N , D ) is nonincreasing in b oth N and D (more data and parameters cannot make the loss worse). Since N ⋆ ( T ) and D ⋆ ( T ) are increasing in T , we hav e T 2 > T 1 = ⇒ L ( N ⋆ ( T 2 ) , D ⋆ ( T 2 )) ≤ L ( N ⋆ ( T 1 ) , D ⋆ ( T 1 )) , (86) and therefore H T ( X ) is nonincreasing in T . In particular, whenever H T ( X ) has a finite large-compute limit H ∞ ( X ) , it approaches this limit from ab ov e. B.4.2 Monotonicity of S ∞ ( X ) and H ∞ ( X ) in D W e no w show that epiplexity and time-b ounded entrop y (after appropriate normalization) in the infinite-compute limit are monotonic in the test set size D = | X | , regardless of the co ding scheme. Fix a datase t X D of length D tok ens. F or a tw o-part co de of the form J ( N , D ; D ) = | P | ( N , D ) + D L ( N , D ) , (87) let ( N ⋆ T ( D ) , D ⋆ T ( D )) denote the compute-optimal choices. W e write S T ( X D ) := | P | ( N ⋆ T ( D ) , D ⋆ T ( D )) , (88) H T ( X D ) := D L ( N ⋆ T ( D ) , D ⋆ T ( D )) , (89) h T ( D ) := H T ( X D ) D = L ( N ⋆ T ( D ) , D ⋆ T ( D )) . (90) In the infinite-compute limit T → ∞ , the compute constraint b ecomes irrelev an t, so the limiting quan tities coincide with the optimum of the unconstrained problem ( N ⋆ ∞ ( D ) , D ⋆ ∞ ( D )) = arg min N > 0 , D ≥ 0 | P | ( N , D ) + D L ( N , D ) . (91) Th us S ∞ ( X D ) = | P | ( N ⋆ ∞ , D ⋆ ∞ ) , h ∞ ( X D ) = L ( N ⋆ ∞ , D ⋆ ∞ ) . (92) W e claim that S ∞ ( X D ) is nondecreasing in D , and h ∞ ( X D ) is nonincreasing in D , assuming that for eac h D > 0 the unconstrained problem (91) admits at least one minimizer. T o see this, fix D 2 > D 1 and let ( N i , D i ) b e minimizers of (91) at D = D i . W rite P i := | P | ( N i , D i ) and L i := L ( N i , D i ) . Optimality of ( N 2 , D 2 ) at D 2 implies P 2 + D 2 L 2 ≤ P 1 + D 2 L 1 . (93) Optimalit y of ( N 1 , D 1 ) at D 1 implies P 1 + D 1 L 1 ≤ P 2 + D 1 L 2 . (94) A dding (93) and (94) gives ( P 2 + D 2 L 2 ) + ( P 1 + D 1 L 1 ) ≤ ( P 1 + D 2 L 1 ) + ( P 2 + D 1 L 2 ) D 2 L 2 + D 1 L 1 ≤ D 2 L 1 + D 1 L 2 ( D 2 − D 1 )( L 2 − L 1 ) ≤ 0 , (95) hence L 2 ≤ L 1 since D 2 > D 1 , i.e., the ac hiev ed loss h ∞ ( X D ) is nonincreasing in D . Substituting L 2 ≤ L 1 bac k into (94) yields P 2 ≥ P 1 , i.e., S ∞ ( X D ) is nondecreasing in D . 56 B.4.3 D ⋆ ( T ) Generall y Appr oa ches D in Prequential Coding W e no w sho w that the compute-optimal training set size for prequential co ding generically saturates at D = D as T → ∞ , without assuming sp ecific scaling laws. In con tinuous time, the prequential mo del description length is the area ab o ve the final loss: | P preq ( N , D ) | := Z D 0 ( L ( N , u ) − L ( N , D )) du. (96) The corresp onding tw o-part co de length for a test set of size D is J preq ( N , D ; D ) = | P preq ( N , D ) | + D L ( N , D ) = Z D 0 L ( N , u ) du + ( D − D ) L ( N , D ) . (97) W e express N in terms of D for fixed T using the constraint 6 N D + 2 N D = T : N T ( D ) = T 6 D + 2 D . (98) Large-compute limit. Assume: (i) L ( N , D ) is nonincreasing in N and admits a p oin twise infinite- mo del-size limit L ∞ ( D ) := lim N →∞ L ( N , D ) ; 7 (ii) L ∞ is contin uously differentiable and strictly decreasing, i.e., L ′ ∞ ( D ) < 0 . Along the compute frontier (98) , for any fixed D w e hav e N T ( D ) → ∞ as T → ∞ , hence J preq ( N T ( D ) , D ; D ) → J ∞ ( D ) := Z D 0 L ∞ ( u ) du + ( D − D ) L ∞ ( D ) . (99) Differen tiating gives J ′ ∞ ( D ) = ( D − D ) L ′ ∞ ( D ) . (100) Since L ′ ∞ ( D ) < 0 , w e hav e J ′ ∞ ( D ) < 0 for D < D and J ′ ∞ ( D ) > 0 for D > D . Thus J ∞ is uniquely minimized at D = D , implying D ⋆ ( T ) → D as T → ∞ . (101) Approac h from b elow and linear growth of N ⋆ ( T ) . By Theorem 30, under the complemen tarity and diminishing-returns assumptions, the compute-optimal training set size D ⋆ ( T ) is strictly increasing in T . Combined with the conv ergence D ⋆ ( T ) → D , this yields D ⋆ ( T ) ↑ D , i.e., D ⋆ ( T ) approaches D from b elo w. Finally , since N ⋆ ( T ) = N T ( D ⋆ ( T )) , N ⋆ ( T ) = T 6 D ⋆ ( T ) + 2 D ∼ T 8 D , (102) so the compute-optimal mo del size grows linearly with T in the large-compute regime. 7. This limit prov ably exists under µ P , but is a reasonable assumption in general as it simply asserts diminishing returns in scaling mo del size without increasing data. 57 App endix C. Exp eriment Details Unless otherwise stated, we use the GPT-2 (Radford et al., 2019) transformer architecture trained with A dam optimizer. In exp eriments where we v ary the mo del size, we tune the base learning rate on a small mo del and transfer it to larger models using using µ P (Y ang et al., 2022) and CompleteP (Dey et al., 2025). In µ P , the p er-lay er learning rate is base learning rate divided by the input dimension, so our rep orted base learning rate is larger than t ypical learning rates used for Adam. The hyperparameters presented b elow are shared b etw een the teacher and the student for requen tial co ding (width, depth, learning rate, EMA time scale, etc.). As describ ed in Section B.1, the EMA for the teacher is used only for pro ducing the distillation target and do es not alter the raw teacher training dynamics, while the EMA for the student mo del do es alter its training dynamics and is used to replace a decaying learning rate schedule. C.1 ECA In Figure 3, we train the transformer to predict Y giv en X where X is the initial state with a state size of 64 cells and Y is obtained by evolving X for 48 steps. W e apply a burnin perio d of 1000 steps for sampling the initial state X to eliminate the less uninteresting transien t dynamics from random initialization. That is X is obtained by evolving the ECA on Z for 1000 steps where Z is a uniform random initial state. F or each rule, we train mo dels with width (embedding dimension) ∈ { 16 , 32 , 64 , 128 , 256 , 512 } and depth (num b er of transformer blo cks) ∈ { 1 , 2 , 4 , 6 , 9 } . W e train both teac her and studen t using batches of 1536 sequences (each an ( X, Y ) pair), a base learning rate of 0.03 with 100 w armup steps, and an EMA time scale of 50 steps (half-life divided by ln(2) ). W e did not set a max teacher-studen t KL as the studen t smoothly track es the teacher throughout training. The epiplexit y and time-b ounded entrop y is estimated for a test set of size D = 100 M tok ens (counting Y only). C.2 Easy induction F or this task, we use a sequence length of n = 512 (as describ ed in Section 5.3.1). The mo del has 3 lay ers and a width of 128, and is trained with a learning rate of 0.03 and a batch size of 384 sequences for 3000 steps with 15 w armup steps and an EMA time scale of 50 steps. W e found further increasing the mo del size led to negligible improv emen t in the loss, and Figure 5c shows that the mo del has nearly con verged by the end of training to the theoretical minimum loss, so there is no need to further increase the training data. As a result, we exp ect the epiplexity S T ( X ) to stabilize as T and D = | X | increases (in the relev an t regime where T is still muc h less than what is required for implemen ting the brute-force solution that enumerates all possible combinations of hidden en tries in the transition matrix), and our estimated epiplexity approximates this stabilized v alue. C.3 Hard induction W e mo dify the ECA exp eriment in Section C.1 to remov e the first h ∈ { 0 , 1 , . . . , 5 } bits in X when fed to the mo del as input. W e use a state size of 32, batch size of 1536 sequences, learning of 0.03, EMA time scale of 100 steps. W e set the max KL threshold b et ween the teac her and student as 0.03 (nats p er token). T o construct a forward function that is hard to in vert, we use rule 30 iterated for 4 steps. W e train mo dels with 3 lay ers and width 256 for 20000. F urther increasing mo del size or training data led to no improv emen t in the loss. As Figure 5b shows, the mo dels conv erge by the end of training (the loss curves sho wn are for the student mo dels, but the teacher mo dels also conv erge) to the theoretical minimum v alues. Therefore, like the case for Section C.2, we exp ect the epiplexity 58 S T ( X ) to stabilize as T and D = | X | increases, at least in the relev an t regime where T is still muc h less than what is required for implemen ting the brute-force solution that enumerates all possible com binations of hidden bits, and our estimated epiplexity approximates this stabilized v alue. C.4 Chess W e train mo dels of v arying sizes from 1M to 160M parameters with depth b etw een 3 and 24 lay ers. The base learning rate is set to 2 and the batch size is 256, with a sequence length of 512. W e set the EMA time scale to 50 steps and max KL to 0.1 nats per token. W e use character-lev el tokenization. The teacher mo dels are trained for 5B tokens in total, and the student mo dels are trained for slightly more due to hitting the max KL threshold during training. The test set size is set to 5 B tokens. Pre-T raining Data. W e use the Lichess dataset av ailable on Hugging F ace at https://huggingface. co/datasets/Lichess/standard- chess- games as pre-training data, formatted as either "|" or "|", where mov es are in algebraic chess notation and b oard is the final b oard state in FEN notation. W e use a slightly more concise version of the algebraic notation to further compress the mo ve sequence. An example input where the b oard app ears last is: e4,e5;Nf3,Nc6;Bb5,a6;Ba4,Nf6;O-O,Be7;Re1,b5;Bb3,d6;c3,O-O;h3,Nb8;d4,Nbd7; |r1bq1rk1/2pnbppp/p2p1n2/1p2p3/3PP3/1BP2N1P/PP3PP1/RNBQR1K1 w - - 0 10 F or do wnstream ev aluation, w e ev aluate p erformance on the following tw o datasets after fine-tuning on 50 k examples for a 10M-parameter mo del with depth 24. W e rep ort accuracy under greedy deco ding at zero temp erature. Chess Puzzles. W e use puzzles from the Lic hess puzzle database a v ailable at https://huggingface. co/datasets/EleutherAI/lichess- puzzles , filtering for puzzles with difficulty rating ab ov e 2000. The task is to predict the correct mov e sequence given the game context. Puzzles are formatted as mo ve sequences where the mo del must predict the next optimal mov e, following (Burns et al., 2023), with only the target mov es included in the loss computation via masking. This tests the mo del’s abilit y to recognize tactical patterns and calculate forced sequences. Cen tipawn Ev aluation. W e ev aluate p osition understanding using the Lichess chess p osition ev al- uations dataset at https://huggingface.co/datasets/Lichess/chess- position- evaluations , where mo dels classify p ositions into 9 ev aluation buck ets based on Sto c kfish centipa wn (cp) scores: class 0 ( ≤ − 800 cp), class 1 ( − 800 to − 400 cp), class 2 ( − 400 to − 200 cp), class 3 ( − 200 to − 50 cp), class 4 ( − 50 to +50 cp), class 5 ( +50 to +200 cp), class 6 ( +200 to +400 cp), class 7 ( +400 to +800 cp), and class 8 ( ≥ +800 cp). Examples are formatted as "|" where the mo del predicts the ev aluation class, with mate p ositions assigned to the extreme classes (0 or 8). Loss during fine-tuning is computed only for predicting the class. C.5 Op en W ebT ext W e use the Op en W ebT ext dataset at https://huggingface.co/datasets/Skylion007/openwebtext , k eeping only do cuments containing only 96 common alphanumeric symbols, and apply c haracter-level tok enization. The setup is otherwise identical to the chess exp eriment (Section C.4). 59 C.6 CIF AR-5M W e use the CIF AR-5M dataset at https://github.com/preetum/cifar5m . W e conv ert the 32 × 32 × 3 images to greyscale and flatten to a 1D sequence of 1024 in raster-scan order. The vocabulary is the set of pixel in tensities { 0 , . . . , 255 } . The setup is otherwise iden tical to the chess exp eriment (Section C.4). C.7 Prequen tial vs Requential Comparison ECA. The ECA exp erimen t include rules { 0 , 32 , 4 , 15 , 22 , 30 , 41 , 54 , 106 , 110 } , co vering all 4 classes. W e train mo dels with width ∈ { 16 , 32 , 64 , 128 } and depth ∈ { 1 , 2 , 3 } up to 10000 steps. W e use a base learning rate of 0.03 and batch size of 384. Other h yp erparameters are identical to Section C.1. W e set D = 250 M tok ens. F or each rule, we rep ort the maxim um epiplexity ov er the resulting compute range. Induction. Both the easy and hard induction results directly come from the exp eriments in Section 5.3.1. As explained in Section C.2 and Section C.3, the compute budget T and test set size D need not b e precisely sp ecified for these tw o tasks as the epiplexity stabilizes as T and D increase due to the conv ergent training dynamics. Natural data. W e rep ort the estimated epiplexity on each dataset at the maximum tested compute budget as describ ed in Section C.4, Section C.5, and Section C.6. C.8 ECA Emergence W e mo dify the setup in Section C.1 to include mo dels that predict intermediate states and the final state rather than the final state directly . Let X (0) denote the initial ECA state, and X ( s ) denote it evolv ed for s steps. F or an ℓ -lo op mo del, we train the mo del to predict ( X (∆) , X (2∆) , . . . , X ( t ) ) instead of X ( t ) only , where ∆ = t/ℓ. Its marginal probabilit y on the final state is low er-b ounded by its join t probability on the ground truth tra jectory: P ( X ( t ) ) = X X ′ (∆) ,...,X ′ ( t − ∆) P ( X ′ (∆) , . . . , X ′ ( t − ∆) , X ( t ) ) (103) So w e upp er-b ound its NLL as log 1 P ( X ( t ) ) ≤ log 1 P ( X (∆) , . . . , X ( t ) ) = ℓ X k =1 log 1 P ( X ( k ∆) | X (( k − 1)∆) , . . . , X (∆) ) , (104) W e account for the in termediate tokens when computing the time b ound and the co de length (they con tribute to the mo del co de length as well as the data entrop y co de length). In the experiment, we set the ECA steps to t = 64 . W e train mo dels with width { 16 , 32 , 64 , 128 } , depth ∈ { 1 , 2 , 4 , 8 , 16 , 32 } , and num b er of lo ops ℓ ∈ { 1 , 2 , 4 , 8 , 16 } . W e found ℓ ∈ { 2 , 4 , 8 } has no adv an tage ov er the non-lo op ed mo del ( ℓ = 1 ) in terms of the tw o-part co de, only ℓ = 16 do es. W e therefore refer to ℓ = 1 as non-lo oped and ℓ = 16 as loop ed. The fact that a small ℓ > 1 is not helpful is lik ely b ecause the o verhead of enco ding and generating intermediate states exceeds the savings from only slightly simplifying each prediction step, as the p er-step prediction horizon is still significant. W e train all mo dels with a base learning rate of 0.06, batch size of 147456 tok ens, w armup of 100 steps, and EMA time scale of 50 steps. W e did not set a max teacher-studen t KL. The test set size is set to D = 100 M final state tokens. 60 C.9 Scaling La ws W e estimate epiplexity and time-b ounded entrop y using the expressions derived in Section B.3 for prequen tial co ding using existing scaling laws for L ( N , D ) . W e solve for the optimal training tokens D ⋆ ( T ) as a function of compute using ro ot finding for Equation (56). F or language, we use the Chinc hilla scaling laws from Hoffmann et al. (2022), whic h were fit to total parameter counts. F or all other mo dalities (images and video), we use the scaling laws from Henighan et al. (2020), which follo w the metho dology of Kaplan et al. (2020) and rep ort non-embedding parameter counts. W e correct these to use total parameters following Pearce and Song (2024), as describ ed b elo w. Correcting for em b edding parameters. The scaling laws in Kaplan et al. (2020) and Henighan et al. (2020) are rep orted in terms of non-embedding parameters N \ E and non-em b edding compute C \ E , excluding em b edding and unembedding parameters. As sho wn b y P earce and Song (2024), this choice—com bined with smaller model scales—accoun ts for m uch of the discrepancy betw een the Kaplan and Chinchilla scaling laws. F ollo wing their approach, we relate total parameters N to non-em b edding parameters via N = N \ E + ω N 1 / 3 \ E , ω = ( V + L ctx ) A 12 1 / 3 , (105) where V is the vocabulary size, L ctx is the context length, and A is the asp ect ratio ( width / depth) . W e use A = 5 as Henighan et al. (2020) sho w ed the optimal asp ect ratio is around this v alue for non-language datasets. W e generate points ( C \ E , N \ E , L ) from the original scaling la ws, con vert to ( C, N , L ) using this relation (with total compute as C = C \ E · N /N \ E ), and refit the p ow er-la w exp onen ts and the irreducible loss. P arameterization con v ersion. The scaling la ws in Henighan et al. (2020) are reported in compute-cen tric form, expressing th e optimal loss L ⋆ ( C ) = ( C /C 0 ) − γ + E and optimal mo del size N ⋆ ( C ) = ( C / ˆ C ) δ as functions of compute budget C . W e conv ert these to the ( N , D ) parameterization used in this work: L ( N , D ) = N N 0 − α + D D 0 − β + E , (106) where the exp onents transform as α = γ /δ and β = γ / (1 − δ ) , and the token scale is given by D 0 = ˆ C 6 N α/β 0 ( β /α ) − 1 /β . Corrected parameters. T able 1 presents the corrected scaling law parameters used in our final calculations. T able 1: Final scaling law parameters used. Image and video domains from Henighan et al. (2020) are corrected for embedding parameters using asp ect ratio A = 5 following (Pearce and Song, 2024); Chinc hilla (language) from Hoffmann et al. (2022) was originally fit to total parameter coun ts and requires no correction. D 0 is measured in tokens and E is measured in nats. Domain α β N 0 D 0 E Image 8 × 8 0.331 0.566 8 . 0 × 10 1 2 . 66 × 10 6 3.14 Image 16 × 16 0.307 0.820 2 . 8 × 10 2 8 . 94 × 10 7 2.68 Image 32 × 32 0.258 0.399 6 . 3 × 10 1 1 . 95 × 10 6 2.30 Image V Q 16 × 16 0.322 0.441 2 . 7 × 10 4 4 . 44 × 10 7 4.23 Image V Q 32 × 32 0.287 0.560 1 . 9 × 10 4 1 . 63 × 10 8 3.32 Video V Q 16 3 0.428 0.718 3 . 7 × 10 4 1 . 79 × 10 8 1.15 Language (Chinc hilla) 0.339 0.285 4 . 91 × 10 7 1 . 49 × 10 9 1.69 61 App endix D. RASP-L for Elementary Cellular Automata Belo w we provide RASP-L co de (Zhou et al., 2023) demonstrating how the evolution rule of an ECA can b e implemen ted, providing evidence that the solution can b e expressed within an autoregressive transformer mo del. Listing 1: RASPL implementation of a cellular automaton evolution step f r o m n p _ r a s p i m p o r t * d e f i n t 2 b i t s ( x , b i t s = 8 ) : # r e t u r n s L S B f i r s t " " " H e l p e r f u n c t i o n t o g e n e r a t e f i x e d b i t s t r i n g r e p r e s e n t i n g a n u m b e r . N o t R A S P - L , c a n b e a s s u m e d c o n s t a n t . " " " b i t s _ s t r = b i n ( x ) [ 2 : ] . z f i l l ( b i t s ) r e t u r n n p . a r r a y ( l i s t ( m a p ( i n t , b i t s _ s t r [ : : - 1 ] ) ) , d t y p e = n p . u i n t 8 ) s e p = - 1 s e p 2 = - 2 d e f e v o l v e _ c a ( x , r u l e ) : " " " F u n c t i o n t o a u t o r e g r e s s i v e l y o u t p u t p r o d u c e t h e o u t p u t o f o n e s t e p o f t h e E C A r u l e . P r o b l e m e n c o d e d a s x = - - i n p u t s t a t e - - , s e p , s e p 2 , - - o u t p u t s t a t e - - . R u l e : i n t ( s p e c i f y i n g t h e E C A ) " " " l o o k u p = i n t 2 b i t s ( r u l e , 8 ) i n _ i n p u t = 1 - h a s _ s e e n ( x , f u l l ( x , s e p ) ) i n _ i n p u t 2 = 1 - h a s _ s e e n ( x , f u l l ( x , s e p 2 ) ) w i d t h = c u m s u m ( i n _ i n p u t ) # o n l y v a l i d a f t e r s e p i d x = i n d i c e s ( x ) c i r c _ x = w h e r e ( i n _ i n p u t , x , i n d e x _ s e l e c t ( x , i d x - w i d t h ) ) p r e v = s h i f t _ r i g h t ( x , 1 ) c p r e v = w h e r e ( i n _ i n p u t 2 , p r e v , i n d e x _ s e l e c t ( p r e v , i d x - w i d t h ) ) p r e v 2 = s h i f t _ r i g h t ( x , 2 ) n b h d = ( p r e v 2 < < 2 ) + ( c p r e v < < 1 ) + c i r c _ x s h i f t e d _ n e x t s t a t e = l o o k u p [ n b h d ] t o _ s e l e c t _ i d x = i d x - w i d t h t o _ s e l e c t _ i d x = w h e r e ( t o _ s e l e c t _ i d x < 3 , i d x , t o _ s e l e c t _ i d x ) o u t s t a t e = i n d e x _ s e l e c t ( s h i f t e d _ n e x t s t a t e , t o _ s e l e c t _ i d x ) r e t u r n o u t s t a t e App endix E. Cellular Automata and Game of Life Elemen tary cellular automata Elementary cellular automata (ECA) (W olfram and Gad-el Hak, 2003) are one-dimensional cellular automata defined on a finite or infinite line of cells, each in one of t wo states: 0 or 1. The system evolv es in discrete time steps according to lo cal rules: a cell’s next state dep ends only on its current state and those of its tw o immediate neighbors, yielding 2 3 = 8 p ossible neighborho o d configurations. Since each configuration can map to either 0 or 1, there are 2 8 = 256 p ossible rules, conv entionally num b ered 0–255 using W olfram’s notation, where the rule n umber’s binary representation sp ecifies the output for eac h neighborho o d. Despite their simplicity , ECAs exhibit diverse b ehaviors ranging from trivial (e.g., Rule 0) to complex and chaotic (e.g., Rule 30), with Rule 54 prov en to b e T uring-complete. These systems serve as minimal mo dels for studying emergence, computation, and the relationship b etw een lo cal rules and global b ehavior. Con wa ys Game of Life Con wa y’s Game of Life (Gardner, 1970) is a cellular automaton defined on an infinite tw o-dimensional grid of cells, each in one of t w o states: aliv e (1) or dead (0). The system evolv es in discrete time steps according to deterministic lo cal rules: a cell’s next state dep ends only on its current state and those of its eight neighbors. Specifically , a live cell survives if it has exactly 2 or 3 live neighbors (otherwise it dies), while a dead cell b ecomes alive if it has exactly 3 live neigh b ors (otherwise it remains dead). Despite the simplicity of these rules, the G ame of Life exhibits 62 (a) LLM modeled Distribution Invariant Measur e (b) Figure 11: LLMs can learn the inv arian t measure of chaotic systems despite unpredictable tra jectories. ( a ) Chaotic systems like the Lorenz equations displa y sensitive dep endence on initial conditions. Tin y p erturbations to the initial conditions (orange) diverge exp onentially , making long-term predictions imp ossible when simulating with limited computation and precision on a computer. ( b ) 3000 sampled p oints from the distribution mo deled by the LLM (left) and from the inv ariant measure of the Lorenz system (right). Color denotes k ernel density estimation of each densit y . remark ably complex emergent behavior, including stable structures (blo cks), p eriodic oscillators (blink ers), mobile patterns (gliders), and structures that generate infinite streams of gliders (glider guns). The system also happ ens to b e T uring-complete, with a sp ecific initial configuration sp ecifying the program, it is capable of universal computation. App endix F. Emergence Lorenz System and Chaotic Dynamics F or the Lorenz system, a canonical example of a chaotic ODE, we can observe a different kind of emergence (Type-0 in Carroll and Parola (2024)). There exists a canonical inv ariant measure in dynamical systems (under some regularity conditions) known as the SRB measure(Metzger, 2000). States ev olved for a long time in the Lorenz system will conv erge this measure. As the Lorenz system is c haotic, tiny p erturbations are exp onen tially amplified through time at a rate related to the largest Ly apunov exp onent λ 1 ≈ 0 . 9 . There is a precise sense in which en tropy is created in this system at a rate of λ 1 log 2 ( e ) bits p er second, formalized through Pesin’s theorem (P esin, 1977), despite the fact that it is a purely deterministic pro cess. Intuitiv ely one can see this picture when simulating the system using fixed precision num b ers, and seeing log 2 ( e ) bits of that description replaced with unpredictable random conten t after ev ery Lyapuno v time 1 /λ 1 . On the one hand randomness is pro duced, but it is not uniformly random. Rather, there is a stationary measure in the shap e of a butterfly , and an observer who has lost track of all previous bits due to c haos can still learn the shap e of the butterfly . Moreov er, the shap e of the stationary measure is not immediately ob vious from the ODE, it is emergen t and cannot easily b e understo od without intensiv e n umerical simulation of the system (hence why most of chaos theory was developed after computers). T o demonstrate this in terplay , we train a language model to predict the first B = 10 bits of the future state Φ t ( X ) from an initial state sampled uniformly from the b o x X ∼ U [ − 20 , 20] 3 + 20[0 , 0 , 1] quan tized to B bits, in comparison to directly mo deling Φ t ( X ) . F or b oth we set the time t to b e 30 Lyapuno v times into the future, t = 30 /λ 1 . The resulting mo del has a nearly identical loss and estimated epiplexity in the tw o settings. Despite b eing unable to distinguish the initial conditions, the LLM learns the inv ariant (SRB) measure to a reasonable approximation as sho wn in Figure 11b. 63 With very limited compute the stationary measure is not predictable apriori from the dynamics, but with more compute it is merely a consequence. The epiplexity of the attractor for limited compute ma y b e larger than a description of the dynamics S T (Φ t ( X )) > S T (Φ , t ) . Chess: AlphaZero and Minimax A qualitativ ely differen t kind of example can be had by considering the mo dels pro duced by AlphaZero (Silver et al., 2018) and the theoretically optimal minimax solution for these t w o pla yer zero sum perfect information games (von Neumann, 1928; Shannon, 1950). The minimax strategy can b e implemen ted by a short program, and with sufficient compute (exp onen tial in the size of the b oard (F raenkel and Lic htenstein, 1981)) the optimal strategy can b e found. On the other hand the CNN p olicy and v alue netw ork pro duced by AlphaZero con tain 10 s of millions of parameters. Giv en that the rules of chess can b e enco ded in just a few hundred b ytes, and the algorithm used to train the mo del can b e simply describ ed and also implemented by a short program, one may wonder wher e do es this information c ome fr om? With the other examples of emergent phenomena in mind, we can make sense of this information b eing pro duced by the computational pro cess of the AlphaZero system. In contrast, with un bounded compute, the best strategy con tains little information. T o summarize, due to the existence of emergen t phenomena, even systems that hav e simple generating pro cesses or simple descriptions can lead to large amounts of structural information to b e learned b y computationally constrained observ ers. App endix G. Induction is Not Sp ecific to Autoregressiv e F actorization One migh t get the impression that key constraint that leads to this induction phenomenon is the autoregressiv e factorization, as it is intuitiv e to see how such a mo del needs to p erform induction in-con text to achiev e minim um loss. How ev er, w e argue this phenomenon takes place with other classes of generativ e mo dels trained as long as they are trained with Maximum Likelihoo d Estimation (MLE) or i ts approximations. In MLE, a generative mo del allo wing explicit likelihoo d ev aluation is trained to maximize the lik eliho o d of the data. Computing the likelihoo d can b e significantly more computationally challenging than sampling from the distribution P . This distinction is particularly clear in the examples we ga ve where the ground-truth P is a mixture distribution represen ted by a latent v ariable mo del with the CA initial state or Marko v c hain transition matrix acting as the laten t v ariable Z . Given access to P X | Z (equiv alent to some easy to implemen t forw ard function F ), sampling is easy as long as P Z is a simple, but computing P X ( x ) for some input x requires ev aluating an intractable integral P X ( x ) = R P X | Z ( x | z ) P Z ( z ) dz due to the high-dimensionality of Z. As such, a mo del given a limited compute-budget is forced to learn a cheaper but more sophisticated algorithm for computing P X ( x ) , often inv olving approximating the inv erse P Z | X either explicitly as done in exp ectation–maximization- t yp e algorithms and V ariational Auto enco ders (Kingma et al., 2013), or implicitly as w e illustrated for the autoregres siv e transformer. App endix H. Minimum Description Legn th In tuitively , L ( H ) can be interpreted as the structural information, and − log P ( x | H ) can be understo od as the remaining random information that cannot b e predicted by the b est mo del in H . A main problem with the crude tw o-part co de is that it do es not prescrib e how one should design the co de for H (i.e., a pro cedure for describing H within H ). The description of a particular H can b e short under one co de but very large under another, which could require additional kno wledge to resolv e. T o circumv en t this issue, one can use a more refined one-part co de that describ es the data 64 with the entire mo del class H rather than any single mo del H . One of the most imp ortan t one-part co des is the normalized maximum likelihoo d co de. Definition 31 (Normalized maxim um likelhoo d co de (Grün wald, 2007)) The NML distri- bution P NML H : { 0 , 1 } n × d → [0 , 1] of a pr ob ablistic mo del class H is: P NML H ( x ) = P ( x | b H ( x )) P y ∈{ 0 , 1 } n × d P ( y | b H ( y )) , wher e b H ( x ) = arg max H ∈H P ( x | H ) is the maximum likeliho o d estimator for x . Crucially , notice that the NML co de only dep ends on H rather than any particular H ∈ H , so we do not ha ve to design a particular co de for H . Unfortunately , the NML co de requires integrating o ver the maximum likelihoo d estimator for all p ossible data, which is intractable for most practical mo dels such as deep neural netw orks. W e can instead use a more tractable v ariant of one-part co de based on sequen tial prediction called prequential co ding. Definition 32 (Prequen tial co de (Grünw ald, 2007)) The pr e quential distribution P PREQ H : { 0 , 1 } n × d → [0 , 1] of a pr ob abilistic mo del class H is: P PREQ H ( x ) = n Y k =1 P ( x k | b H ( x 1: k )) , wher e b H ( x 1: k ) = arg max H ∈H P ( x 1: k | H ) is the MLE for the first k elements of x . This definition ab o ve uses the MLE for up dating b H but there are in fact no constraints on how the up date is p erformed. W e may use an y up date metho d of our choice to pro duce the next mo del in the sequence, so long as it only dep ends on the previous data. This means that we can naturally adapt it for deep learning, where we use sto chastic gradient descent to up date the mo del sequentially . A co de cannot b e optimal simultaneously for all p ossible data x unless it has knowledge of the particular x . Therefore, it is useful to characterize how close a given co de is to the optimal mo del, whic h can b e formalized via the notion of r e gr et . Definition 33 (Regret (Grün wald, 2007)) The r e gr et of a c o de Q r elative to H for x is the additional numb er of bits ne e de d to enc o de x using Q c omp ar e d to the b est mo del in hindsight, Reg ( Q, H , x ) = − log Q ( x ) − min H ∈H {− log P ( x | H ) } . Under this notion of p enalty , the NML is optimal in the sense that it ac hieves the minimax regret. The regret pro vides a wa y to compare differen t co des. Consider the tw o-part regret of the crude t wo-part co de P 2P ( · ) with minimizer H ⋆ and asso ciated predictive distribution P ( · | H ⋆ ) , Reg ( P 2P , H , x ) = L ( H ⋆ ) + log 1 P ( x | H ⋆ ) − log 1 P ( x | b H ) . This means that for a tw o-part co de, the regret is an upp er b ound on the description length of the model. F or sufficien tly large n , the last tw o terms b ecome close to eac h other and Reg ( P 2P , H , x ) ≈ L ( H ⋆ ) . In the case of NML, the regret is the minimax regret that Reg ( P NML H , H , x ) = log P y ∈{ 0 , 1 } n P ( y | b H ( y )) . This quantit y is indep endent of x , which is also called p ar ametric c omplexity of H , b ecause it measures how expressive the en tire mo del class is b y counting the total amount of p ossible data sequences the mo del class can mo del well. 65
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment