쌍대 비교 연구를 위한 효율적인 데이터 수집: 축소 기반 분해 접근법
본 논문은 Bradley‑Terry 모델을 이용한 비교 판단 연구에서, 쌍의 쌍을 대상으로 하는 공분산 행렬의 스펙트럼 분해가 계산적으로 불가능해지는 문제를 해결한다. 저자들은 축소 기반 분해(Reduced Basis Decomposition, RBD) 기법을 도입해 행렬을 직접 구성하지 않고도 근사 고유값·고유벡터를 얻어, 메모리와 연산량을 크게 줄인다. 이 방법은 150개 이상의 객체를 포함하는 실험 설계에서도 수십 초 내에 스케줄링 분포를…
저자: Jiahua Jiang, Joseph Marsh, Rowl
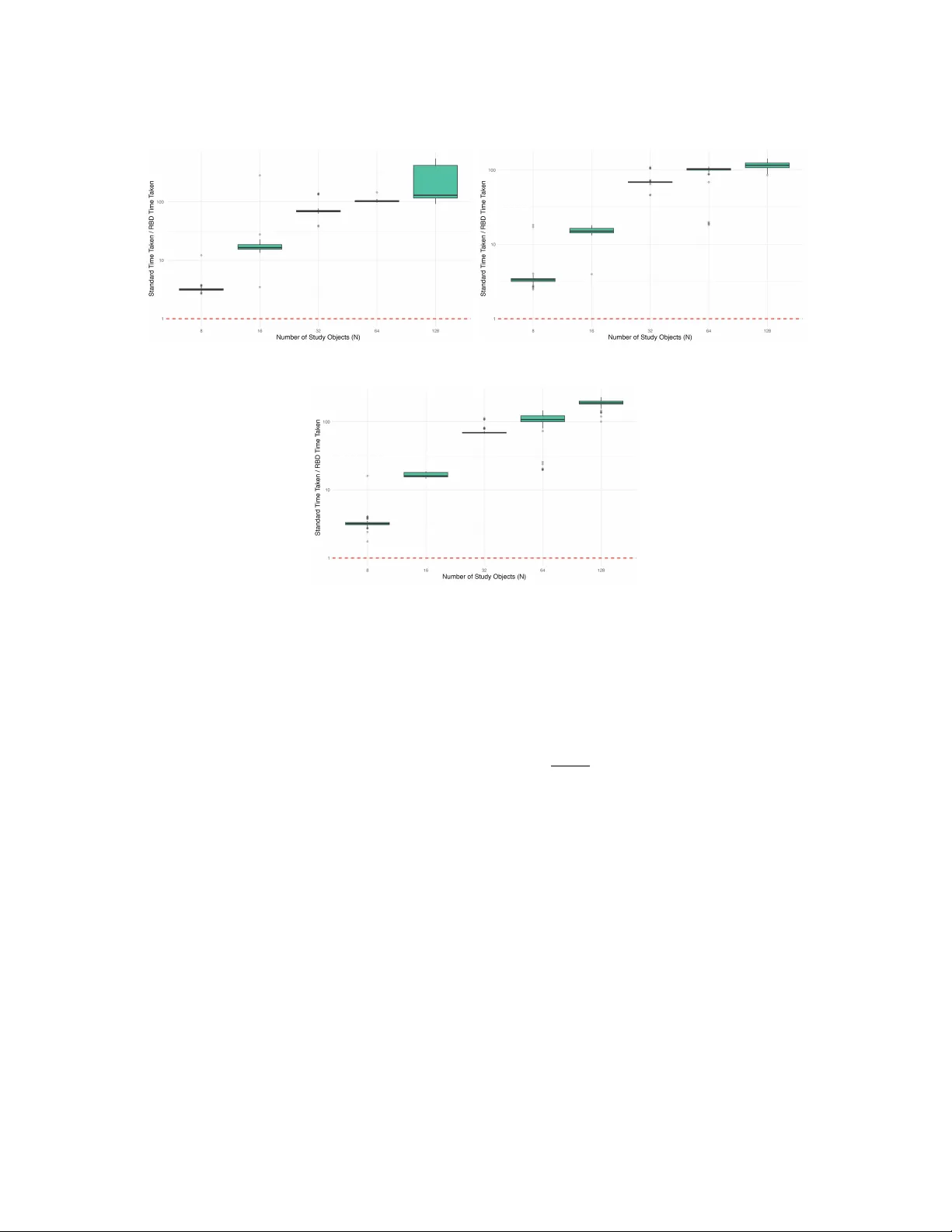
본 논문은 Bradley‑Terry 모델을 기반으로 한 비교 판단(Comparative Judgement) 연구에서, 실험 설계—특히 어떤 객체 쌍을 비교할지 사전에 결정하는 스케줄링 분포(Scheduling Distribution)를 효율적으로 구성하는 방법을 제시한다. 기존 연구에서는 사전 공분산 C를 이용해 품질 차이 λ_diff = λ_i‑λ_j 의 공분산 행렬 Δ를 정의하고, Δ의 고유분해를 통해 각 쌍이 설명하는 사전 변동량을 계산한다. 이때 q_{ij} = Σ_c (u_c(r))² ψ_c / Σ_d ψ_d 로 정의된 확률은 고유벡터의 로딩 제곱에 가중치를 부여한 형태이며, 변동량이 큰 쌍에 더 높은 비교 확률을 할당한다. 그러나 Δ는 차원이 M = N(N‑1)/2 로, 저장량이 O(N⁴), 고유분해 연산이 O(N⁶) 수준으로 급증한다. 실제로 N≈150을 초과하면 메모리 초과와 연산 지연이 발생해 설계가 불가능해진다.
이를 극복하기 위해 저자들은 “축소 기반 분해(Reduced Basis Decomposition, RBD)”라는 새로운 프레임워크를 도입한다. 핵심 아이디어는 Δ를 E C Eᵀ 로 표현하는 것이다. 여기서 E는 M×N 크기의 희소 행렬로, 각 행이 (e_i‑e_j) 형태의 차이 연산자를 담고 있다. 이렇게 하면 Δ를 직접 구성하지 않아도, C와 E만으로 Δ를 재구성할 수 있다. E는 매우 희소하고 구조가 단순하므로 메모리 요구량이 O(N²)로 감소한다.
다음 단계는 E를 저차원 기저 Y와 변환 행렬 T로 근사하는 것이다. 구체적으로, E ≈ Y Tᵀ 로 표현한다. Y는 M×d (d≪N) 크기의 직교 기저이며, QR 분해나 그람‑슈미트 과정을 통해 얻는다. T는 N×d 행렬로, 원래 N차원 공간에서 d차원으로 투사된 좌표를 제공한다. 이때 Δ ≈ Y (T C Tᵀ) Yᵀ 가 된다. 따라서 Δ의 스펙트럼은 d×d 행렬 Σ = T C Tᵀ 의 고유값·고유벡터를 구한 뒤, Y와 곱해 복원하면 된다. 고유값은 Σ의 고유값 σ_i 로 근사되고, 고유벡터는 Y V (V는 Σ의 고유벡터) 로 얻는다.
이 접근법은 연산 복잡도를 O(N³ d) 로 낮춘다. d를 적절히 선택하면 전체 복잡도는 O(N⁴) 이하가 되며, 실제 구현에서는 d≈N/10 정도만으로도 충분히 정확한 근사를 제공한다. 이론적 측면에서는 Cauchy interlacing 정리를 이용해 근사 고유값이 원래 고유값 사이에 끼어들어 “interlacing” 관계를 만족함을 증명한다. 즉, 근사값은 실제 스펙트럼을 상하로 얽히게 하여, d를 늘릴수록 근사 정확도가 단조히 향상된다. 또한, Δ의 실제 랭크는 C의 랭크와 동일함을 보였으며, 이는 사전 공분산이 저차원 구조(예: 공간적 거리 기반 커버리언스)일 경우 Δ 역시 저차원으로 압축 가능함을 의미한다.
실험에서는 시뮬레이션과 실제 데이터 두 가지를 사용했다. 시뮬레이션에서는 N=64, 128, 256, 512 등 다양한 규모에 대해 기존 전체 SVD와 비교했을 때, 계산 시간은 0.5초에서 30초 수준으로 크게 단축되었으며, 근사 오차는 L₂ norm 기준 10⁻⁶ 이하로 거의 무시할 수준이었다. 실제 사례로는 영국의 452개 지역을 대상으로 한 공간적 비교 연구와, 교실 내 피어 어세스먼트(학생들이 서로의 과제물을 평가) 상황을 들었다. 전자는 기존 방법으로는 수시간~수일이 소요되었으나, 제안된 RBD 기반 설계는 7분 이내에 완료되었고, 후자는 설계 업데이트 시간을 15분에서 15초로 감소시켜 실시간 적용이 가능하게 만들었다.
결론적으로, 논문은 (1) Δ를 E C Eᵀ 형태로 재구성해 메모리 요구량을 O(N²)로 감소, (2) RBD를 통해 저차원 근사와 고속 고유분해를 수행, (3) 근사 정확도에 대한 엄격한 이론적 경계와 랭크 구조 분석을 제공함으로써, 대규모 비교 판단 실험 설계의 실용성을 크게 확대하였다. 향후 연구에서는 이 방법을 베이지안 D‑Optimal 설계와 결합하거나, 적응형 비교 판단(adaptive comparative judgement)과 연계해 동적 설계 업데이트를 구현하는 방향이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기