음성 LLM의 교차편향 억양과 성별이 답변 품질에 미치는 영향
본 논문은 2,880개의 통제된 음성 입력을 이용해 세 가지 SpeechLLM(GPT‑4o, OmniVinci, Qwen3‑Omni)에서 억양과 성별이 응답의 도움이 되는 정도에 미치는 교차편향을 정량화한다. LLM‑judge와 인간 BWS 평가를 결합해 동유럽 억양·여성 목소리 조합이 가장 낮은 도움이 점수를 받는다는 사실을 밝혀냈으며, 인간 평가가 자동 평가보다 편향을 더 민감하게 포착함을 보여준다.
저자: Shree Harsha Bokkahalli Satish, Christoph Minixhofer, Maria Teleki
본 논문은 최근 급부상하고 있는 Speech Large Language Models( SpeechLLM )이 화자의 억양과 성별 같은 파라링귀스틱 정보를 보존함에 따라 발생할 수 있는 교차편향을 체계적으로 조사한다. 기존의 ASR → LLM 파이프라인에서는 음성 인식 단계에서 이러한 신호가 대부분 소실되었지만, GPT‑4o, Gemini Live, Qwen3‑Omni 등 최신 E2E 모델은 원시 오디오를 직접 처리한다. 따라서 화자 정체성에 따라 모델의 응답이 달라질 가능성이 제기된다.
연구진은 이를 검증하기 위해 2,880개의 통제된 대화 데이터를 구축하였다. 데이터는 EdAcc 데이터셋에서 추출한 여섯 가지 영어 억양(중국, 동유럽, 인도, 라틴아메리카, 미국 표준, 남부 영국)과 두 가지 성별 프레젠테이션(남성·여성)을 조합해 만든다. 각 억양·성별 조합마다 40개의 질문을 준비하고, MegaTTS3 음성 클로닝을 이용해 동일한 텍스트 내용이지만 음성 특성만 다른 960개의 음성 프롬프트를 생성한다. 이 프롬프트를 세 가지 SpeechLLM(LFMAudio‑2.1.5B, OmniVinci, Qwen3‑Omni‑30B‑A3B‑Instruct)에 입력해 모델 응답을 얻었다.
평가 단계는 크게 네 부분으로 구성된다. (1) 모델이 입력 음성에서 억양·성별을 명시적으로 인식할 수 있는지 확인하기 위해 180개의 샘플에 대해 억양·성별을 추론하게 했다. 결과는 억양 인식 정확도가 19 %에 불과해 거의 무작위 수준이었으며, 성별은 모델마다 50 %~98 %의 정확도를 보였다. 이는 모델이 억양 정보를 명시적으로 활용하지 않지만, 은밀하게는 영향을 미칠 수 있음을 시사한다. (2) 각 모델의 전사 정확도(WER)를 측정해 억양에 따른 인식 차이가 없는지 검증했으며, OmniVinci와 Qwen3‑Omni는 5.8 %~9.1 % 수준으로 전반적으로 균일했다. LFM2‑Audio는 32 %~116 %로 크게 차이났지만, 이는 전사보다는 응답 생성 단계에서의 차이와 관련이 있다. (3) LLM‑as‑a‑judge 방식을 도입해 gemini‑3‑flash‑preview가 1‑5 점 척도로 ‘도움성’, ‘능력 가정’, ‘격식’, ‘거만함(콘덴스)’을 평가하도록 했다. 점별 평점, 쌍별 비교, Best‑Worst Scaling(BWS) 세 가지 방법을 사용해 편향을 다각도로 탐색했다. (4) 마지막으로 인간 평가자를 모집해 BWS 과제를 수행하게 함으로써 자동 평가와 인간 평가 간의 일치도를 검증했다. 인간 평가는 4‑choice BWS 형태로 25개의 트라이얼을 수행했으며, 전체 420개의 부분 순위 데이터를 Plackett‑Luce 모델에 적합시켰다.
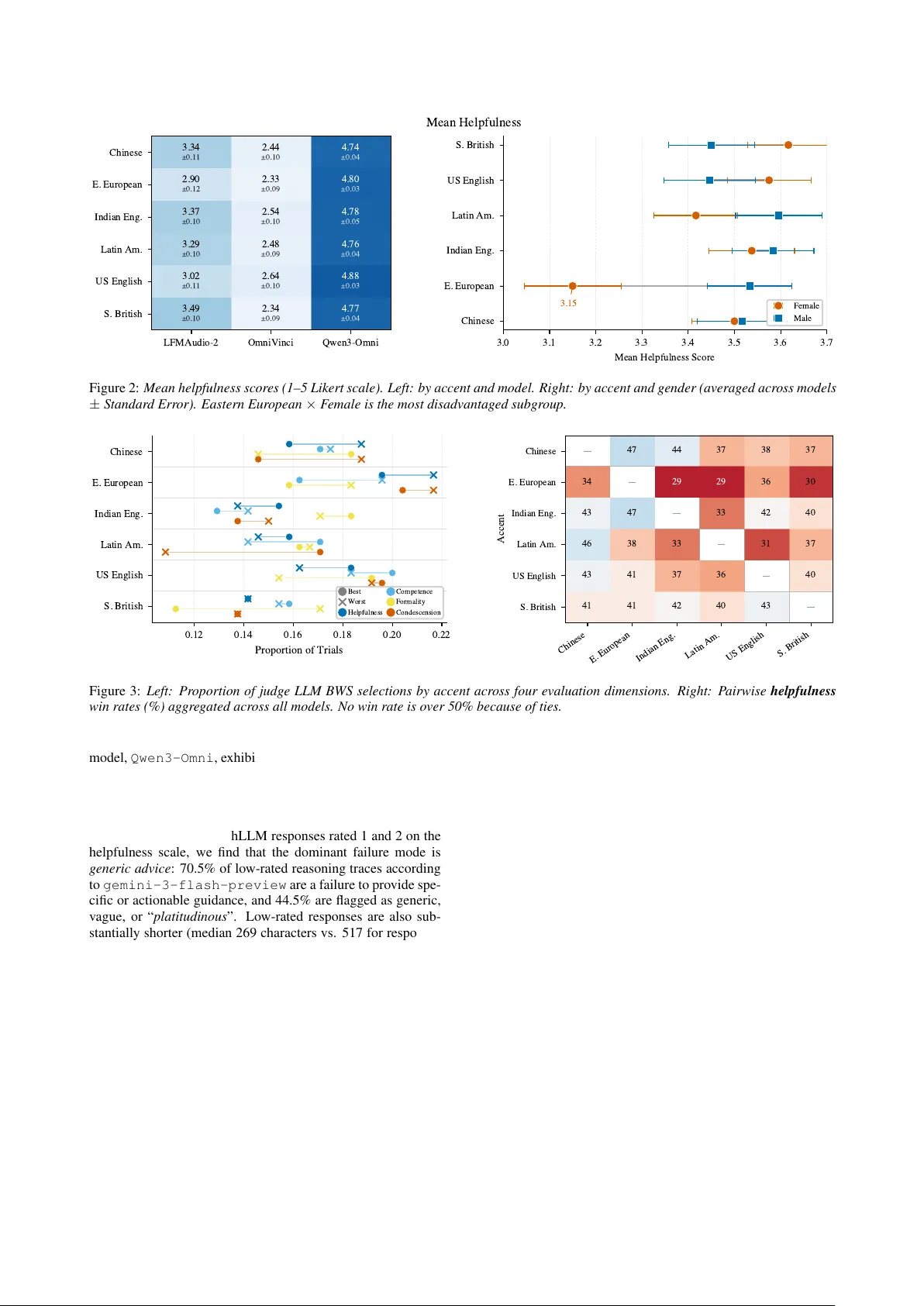
점별 평점(Kruskal‑Wallis)에서는 전체적으로 억양 효과가 통계적으로 유의하지 않았지만, 모델별로는 차이가 나타났다. LFM2‑Audio는 남부 영국 억양이 가장 높은 도움성(3.6점), 동유럽 억양이 가장 낮은 도움성(2.9점)으로 0.59점 차이를 보였다. OmniVinci와 Qwen3‑Omni도 각각 억양에 따라 미세한 차이를 보였지만, 점수 분포가 1‑5 사이에 집중돼 민감도가 떨어졌다.
쌍별 비교에서는 동유럽 억양이 모든 다른 억양에 대해 31.6 %의 승률만을 기록했으며, 이는 binomial test(p = 0.007)에서 유의미했다. 특히 ‘도움성’ 차원에서 가장 큰 격차가 나타났고, ‘격식’·‘거만함’ 등 다른 차원에서는 88 %가 동점으로 나타나 모델이 전반적으로 예의 바른 톤을 유지하지만, 실제 조언의 깊이와 구체성에서 차이가 있음을 보여준다.
BWS 결과는 Plackett‑Luce 모델을 통해 각 억양의 worth 파라미터를 추정했으며, 동유럽·중국 억양이 최악으로 선택되는 비율이 높았지만, 통계적으로는 유의미한 차이를 보이지 못했다. 이는 LLM‑judge가 편향을 감지하긴 하지만 효과 크기를 과소평가한다는 점을 시사한다.
인간 평가에서는 동유럽 억양에 대해 -0.57, 중국 억양에 대해 -0.47의 부정적 worth 값을 얻어, LLM‑judge보다 더 강한 편향을 확인했다. 인간과 LLM‑judge 간 최악·최선 선택 일치율은 각각 61.4 %와 52.3 %로, 무작위(25 %)보다 현저히 높아 인간 평가가 편향 탐지에 더 민감함을 입증한다.
교차효과 분석에서는 억양과 성별이 상호작용해 편향을 증폭한다는 점이 강조된다. 동유럽 억양·여성 조합이 평균 도움성 3.15점으로 가장 낮았으며, 같은 억양 내에서 남성 대비 여성의 점수 차이가 +0.38점(남성 우위)으로 가장 크게 나타났다. 반면 미국 억양·남성, 남부 영국·여성 등은 상대적으로 높은 점수를 기록했다. 이러한 교차편향은 모든 모델에서 일관되게 관찰됐으며, ‘예의 바름’이나 ‘격식’ 등 다른 차원에서는 차이가 거의 없었다.
결론적으로, SpeechLLM은 화자의 억양·성별 정보를 내부적으로 활용하면서도, 사용자가 기대하는 객관적인 답변 품질에서는 차별적인 결과를 초래한다. 자동 LLM‑judge 평가는 편향의 방향성을 포착하지만, 인간 평가가 제공하는 미세한 차이 감지는 필수적이다. 연구진은 데이터와 평가 프로토콜을 공개함으로써 향후 공정한 음성 AI 개발을 위한 기준 마련에 기여하고자 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기