QV만으로 충분한가 대형 언어 모델 주의 메커니즘의 본질 재조명
본 논문은 언어학적 POS·구문 분석을 기반으로 Transformer의 Query‑Key‑Value(QKV) 구조를 재해석하고, Query와 Value만을 이용하는 QV 패러다임을 제안한다. 실험적으로 QV가 QKV와 거의 동등한 성능을 보이며, Positional Encoding에 의한 간섭이 정확도 차이의 주요 원인임을 확인한다. 또한 MQA·GQA·MLA와 같은 KV‑공유 변형을 QV 관점에서 설명하고, Key‑After‑Value(QV‑…
저자: Zhang Edward
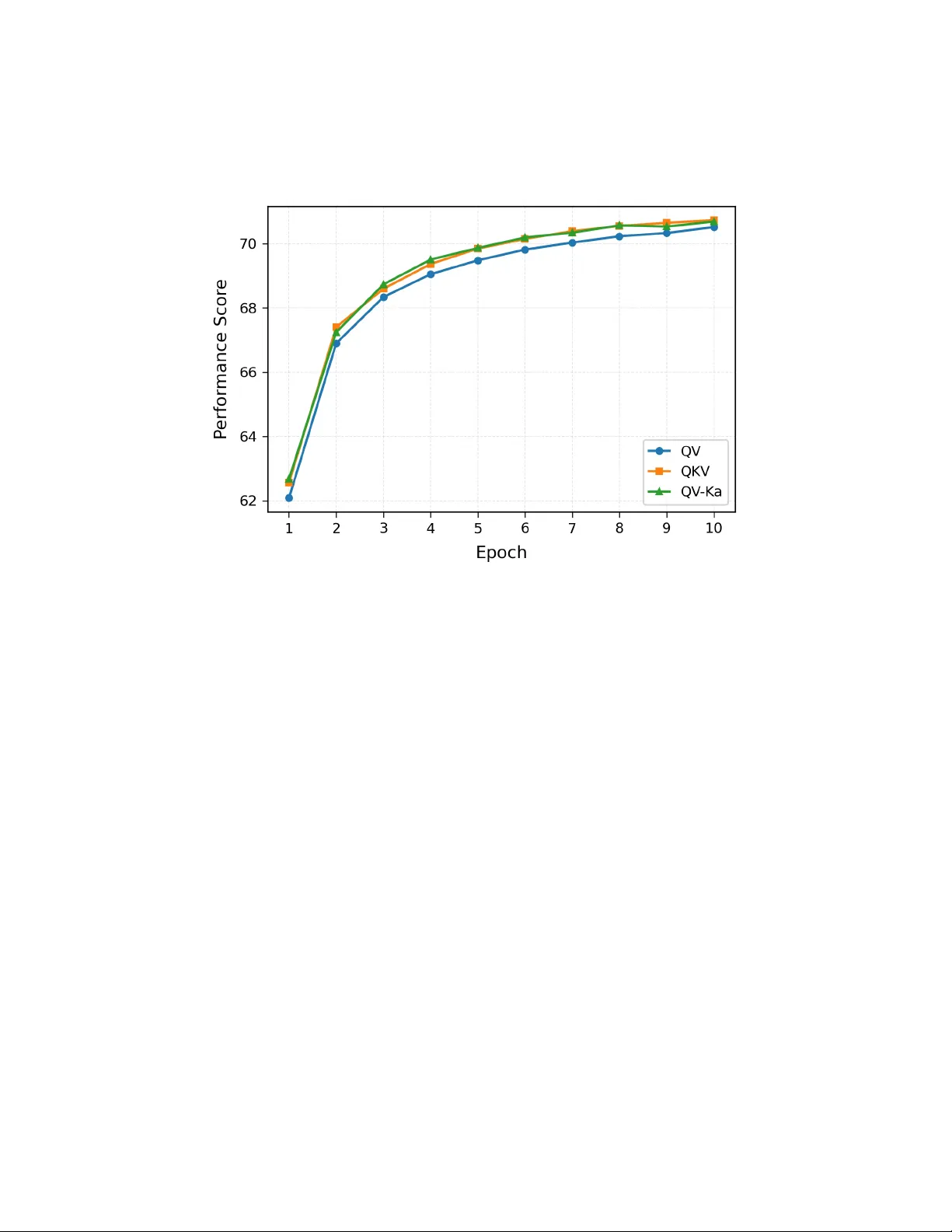
본 논문은 Transformer 기반 대형 언어 모델(LLM)의 핵심 구성 요소인 Query‑Key‑Value(QKV) 메커니즘을 언어학적 관점에서 근본적으로 재해석하고, 이를 단순화한 QV 패러다임과 그 확장형인 QV‑Ka 최적화 스킴을 제안한다.
1. **이론적 배경 및 동기**
- 기존 QKV는 데이터베이스의 질의‑키‑값 구조에 비유되지만, 자연어 처리에서는 토큰 간 의미적 친화성(affinity)과 구문 관계가 더 근본적인 역할을 한다고 주장한다.
- POS(품사)와 구문 분석을 통해 “beautiful‑girl”처럼 형용사‑명사 간 높은 친화성을 정의하고, 이를 확률적 파워‑법칙을 따르는 ‘주의의 중력장’으로 모델링한다.
2. **QKV 로직의 세분화**
- **Shallow‑Composing (SC)**: 토큰 임베딩의 저차원 특징을 결합해 새로운 의미 벡터를 만든다(예: “beautiful”+“girl”→“beauty”).
- **Deep‑Matching (DM)**: 특정 특징 차원(F_k)에서 토큰 간 매칭 관계를 찾는다. 여기서 K는 V의 DM 결과이며, Q는 SC 결과를 K 차원에 투사한다.
- 이러한 두 단계는 서로 보완적으로 작동하며, K와 V는 동일한 의미 공간(F_v)에서 서로 변환되는 관계임을 수식적으로 증명한다.
3. **QV 패러다임 도출**
- K를 완전히 제거하고 Q와 V만 사용해도 동일한 매칭 로직을 구현할 수 있음을 보인다.
- 기존 Attention 식을
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기