QV May Be Enough: Toward the Essence of Attention in LLMs
Starting from first principles and a linguistic perspective centered on part-of-speech (POS) and syntactic analysis, this paper explores and derives the underlying essence of the Query-Key-Value (QKV) mechanism within the Transformer architecture. Ba…
Authors: Zhang Edward
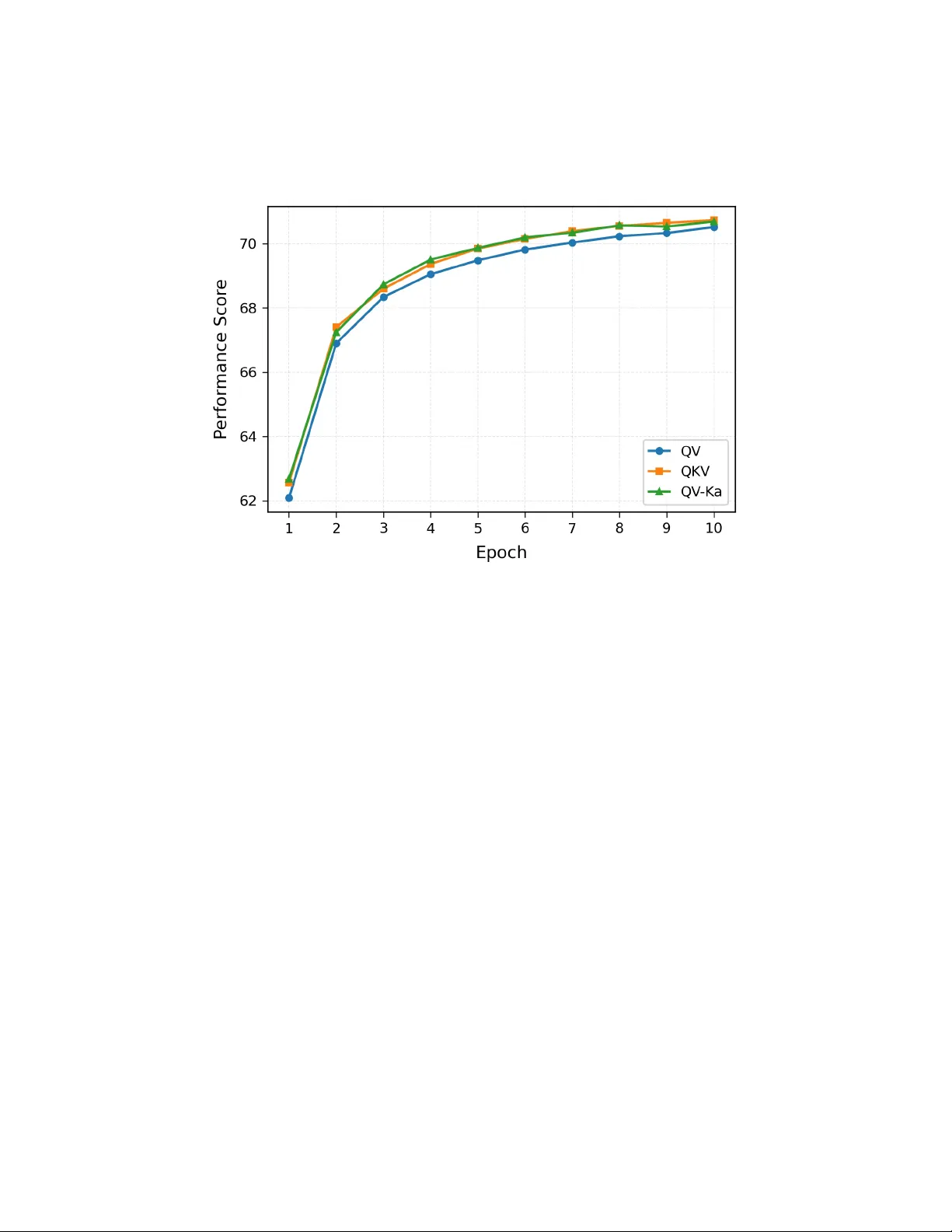
QV Ma y Be Enough: T o w ard the Essence of A tten tion in LLMs Edw ard Zhang ∗ Abstract Starting from first principles and a linguistic p ersp ectiv e centered on part-of-speech (POS) and syn tactic analysis, this paper explores and derives the underlying essence of the Query-Key-V alue (QKV) mec hanism within the T ransformer arc hitecture. Based on this the- oretical foundation, we pro vide a unified explanatory framew ork for the efficacy of con temp orary arc hitectures, including MQA, GQA, and MLA, while identifying their inherent trade-offs and potential opti- mization tra jectories. W e introduce the QV paradigm and provide empirical evidence for its v alidit y . Building up on this, we prop ose the QV-Ka (Key-after-v alue & ctx) optimization sc heme, whic h is further substan tiated through e xperimental v alidation. The interpretable the- oretical analysis of the QKV mechanism presented in this work estab- lishes a robust foundation for the future evolution of large language mo del arc hitectures. 1 In tro duction Since its inception, the Query-Key-V alue (QKV)[1] mechanism has b een ubiquitous as the arc hitectural cornerstone of the T ransformer mo del. How- ev er, the fundamen tal motiv ation behind suc h a conceptual abstraction—and the precise functional roles of Q, K, and V—remains an op en question. While the seminal work interprets these terms through the lens of retriev al systems (i.e., Query , Key , and V alue), suc h definitions align more closely with database management paradigms than with linguistic principles. This ∗ contact with:windyrobin@aliyun.com 1 prompts a critical inquiry: from the standp oin t of natural language pro cess- ing, what linguistic en tities do these comp onen ts represen t, and what is the in trinsic logic gov erning their in ternal dynamics? 2 Bac kground In the A GF pap er (Zhang [2]), we previously introduced the principles of the Atten tion mechanism. F rom the p ersp ectiv e of part-of-sp eech (POS) and syntactic analysis, consider the sentence: ”There is a b eautiful girl.” Within this structure, ”girl” serves as the noun (ob ject), while ”b eautiful” acts as an adjective mo difying ”girl.” Standard linguistic intuition suggests that adjectives hav e a natural affinity for sp ecific nouns; for instance, the seman tic compatibilit y b etw een ”b eautiful” and ”girl” is significantly higher than that b et ween ”b eautiful” and ”man.” Figure 1: Matching of Differen t T okens Consequen tly , for any given token embedding, a most-compatible set of re- lated tokens can b e iden tified based on common-sense or statistical heuris- tics. W e define this degree of correlation—or the probability of establishing a mo difier-head relationship—as Affinity or the Attention Sc or e . As estab- lished in the A GF framew ork, this affinit y follows a p ow er-law distribution 2 with respect to the relative distance b etw een tok ens, fundamen tally conform- ing to the logic of an “Atten tion’s Gravita tional Field.” 3 QKV Logic Next, we will conduct a deep er analysis to demonstrate ho w the aforemen- tioned A tten tion logic is implemented. In Atten tion calculations, Q, K , and V are deriv ed from the original T oken/Em b edding. The core functions of their corresp onding transformation matrices W q , W k , W v can b e divided into t wo categories (ignoring p ositional comp onents for now): • Shallow-Composing : This in v olves selecting, grouping, or com bining previously scattered features. F or example, if t w o dimensions represent “b eautiful” and “girl,” they might b e com bined in to a new temp orary feature to express a semantic meaning similar to “b eauty .” • Deep-Matching : (which implicitly includes shallo w-comp osing) This generates pairing or mo difying relationships. F or instance, when “girl” acts as a noun, it often forms a relationship with adjectiv es lik e “y oung” or “beautiful,” or with other v erbs and quantifiers. Common sense tells us this is en tirely ac hiev able; this step is the core problem w e explored in the A GF paper. Its essence is a probabilit y densit y issue, conforming to the logic of an “Atten tion-Gravitational Field.” T aking the T ransformer’s QK V abstraction as an example, if Q comes from T oken-Q, and K , V come from T oken-V, the resulting semantics can b e un- dersto o d as: • V v : The numerical result of Shal low-Comp osing on T oken-V, with its corresp onding feature/dimension group denoted as F v . • V k : The result of De ep-Matching T oken-V in a certain feature direction F k (e.g., “girl” mapping to the candidates [“b eautiful”, “young”]). • Q q : The pro jection result of Shal low-Comp osing T oken-Q on to the corresp onding feature dimension F k . Note : The ab o v e applies to the scenario where d k = d model /h . In scenar- ios where d k > d model /h , it can be considered that some dimensions in the 3 Figure 2: QKV Paradigm feature space F v undergo “feature splitting” within F k (similar to the logic of “b eauty” splitting into “b eautiful” and “girl”). This effectively improv es the “resolution” of the Atten tion correlation calculation, whic h theoretically enhances mo del accuracy . 4 QV P aradigm A critical question arises: can the standard QK V logic b e simplified? If w e aim to eliminate the sp ecific V k comp onen t, the framework transitions as follo ws: • V v : The semantic definition remains consistent with the QK V model, represen ting the result of shal low-c omp osing , with its corresp onding feature dimension still denoted as F v . • Q v : T ok en-Q p erforms a de ep-matching calculation along the F v di- rection. Logically , this is equiv alent to the inv erse pro cess of the V k calculation in the standard QK V mo del. The resulting mapping w ould resem ble: (’b eautiful’ → [’girl’, ’flow er’]). In this simplified architecture, b oth V v and Q v are grounded in the same feature dimension. Their numerical v alues similarly represent fact and ex- p e ctation , resp ectively . 4 Figure 3: QV Paradigm In other words, the original standard QK V logic essen tially follows the form of Q q V k V v , By simultaneously utilizing V to function as K , we deriv e a simplified mo de expressed as: Q v V v Consequen tly , the original A tten tion calculation formula: A ttention( Q, K, V ) = softmax QK T √ d k V (1) is no w transformed into: A ttention( Q, V ) = softmax QV T √ d k V (2) 5 Exp erimen tal Setup The exp erimental metho dology in this pap er remains consisten t with the A GF pap er. All experiments are conducted using the V anilla T ransformer as the baseline, sp ecifically emplo ying the T ransformer-BIG mo del archi- tecture. 5 T able 1: Summary of Exp erimental Configurations and Hardw are Environ- men t. Configuration Item V alue / Description Base Arc hitecture V anilla T ransformer (T ransformer-BIG) Dataset WMT 17 (T ranslation T ask, en-de) Num b er of Lay ers 3 (Reduced from default 6) Precision FP16 (Half-Precision) T raining Hardw are Single NVIDIA T esla V100-PCIE-32GB T raining Duration ≈ 15 hours p er run T o accelerate the training pro cess, w e employ ed FP16(Half-Precision)training, the n umber of lay ers(La y erNum) was set to 3, rather than the default 6. T raining framework 1 and A GF mo dule co de 2 is a v aiable no w. 6 V anilla-QV T esting and Analysis Under the baseline configuration of a V anilla-T ransformer with default Si- n usoidal P ositional Enco dings (PE) , we conducted a comparative anal- ysis b et ween the prop osed QV mo de and the original QKV me chanism . The v alidation accuracy results are summarized in T able 2. T able 2: Comparison of V alidation Accuracy b etw een QV and QKV Mo des Mo de V alid Accuracy (%) QV 70.0756 QKV 70.5911 As observ ed, the QV mo de incurs a p erformance degradation of approxi- mately 0.5% in accuracy compared to the standard QKV approach. W e hypothesize tw o primary factors con tributing to this 0.5% loss: 1. Intrinsic Structural Sup eriorit y : The standard QK V mec hanism ma y inheren tly p ossess a more robust representational capacity than the simplified QV mo de, naturally leading to higher accuracy . 1 OpenNMT-py: https://github.com/OpenNMT/OpenNMT- py 2 AGF git: https://github.com/windyrobin/AGF/tree/main 6 2. Impact of P ositional Enco ding (PE) Interference : In the tradi- tional QK V me c hanism, Q and K are injected with PE to compute relativ e p ositional relationships, while V remains relatively isolated or less affected by p ositional in terference. How ever, in the QV mo de , since V also assumes the role of the original K for p ositional calculations, it is sub jected to a greater degree of interference from the PE. This increased coupling b etw een semantic v alue and p ositional information p oten tially leads to the observed drop in final accuracy . Based on these observ ations, we p ose a critical researc h question: What is the r elative magnitude of these two imp acts? Sp e cific al ly, how signific ant is the interfer enc e c ause d by Positional Enc o ding (PE)? 7 In tro duction of A GF and Comparativ e Anal- ysis T o eliminate the interference related to p ositional calculations in the afore- men tioned comparison, we in tro duce the A GF (Atten tion’s Gravitational Field) relativ e p ositional framew ork. This approach completely decouples seman tic information from p ositional logic. F urthermore, we apply the stan- dard PCM-V optimization metho d. The original A ttention formulation: a m,n = exp q ⊤ m k n / √ d · PosCoeff P L i =1 exp q ⊤ m k i / √ d · PosCoeff , o m = L X n =1 a m,n · P osCo eff · v n (3) is no w transformed into the following QV structure: a m,n = exp q ⊤ m v n / √ d · PosCoeff P L i =1 exp q ⊤ m v i / √ d · PosCoeff , o m = L X n =1 a m,n · P osCo eff · v n (4) The exp erimen tal results are summarized in T able 3: The results clearly demonstrate that after in tro ducing the A GF relativ e posi- tional calculation, the QV-AGF mo de substantially matches the p erformance of the V anil la-QKV baseline. Moreo v er, the p erformance gap b et ween QV 7 T able 3: Comparative Experimental Results with AGF and PCM-V Opti- mization Mo de Crafts / Configuration V alid Accuracy (%) QV Default (Sin usoidal PE) 70.0756 QKV Default (Sin usoidal PE) 70.5911 QV A GF + PCM-V 70.5188 QKV A GF + PCM-V 70.7800 and QKV narro ws to approximately 0.26% . This indicates that of the origi- nal 0.5% accuracy gap, p ositional enco ding interference accounted for roughly half (appro ximately 0.2%–0.3%). These exp erimental findings align p erfectly with our exp ectations. The fact that the QV mo de can closely appro ximate the effectiveness of the QK V mo de provides robust empirical evidence supp orting our hypotheses regard- ing Shal low-Comp osing (SC) , De ep-Matching (DM) , and the underlying logic of QK V /QV abstractions. 8 Wh y QKV Outp erforms QV A pivotal question remains: wh y do es the QK V mec hanism consisten tly ac hieve higher accuracy than the QV mo de? According to our definition of De ep-Matching , the underlying logic inv olv es assessing the degree of correlation or matching within sp ecific directions or feature dimension groups. A single token, suc h as “girl,” ma y naturally form mo dification relationships with m ultiple appropriate adjectiv es (e.g., “b eauti- ful,” “y oung”). Consequen tly , the computational result tends to exhibit a dif- fusion effect, whic h we define as DODM (Diffusion of Deep-Matc hing) . The manifestation of DODM differs fundamentally b etw een the t wo mo des: • In the QKV mo de, the DODM phenomenon o ccurs within the V (V alue) tok en group. • In the QV mo de, DODM o ccurs within the Q (Query) comp onen t. Based on the Atten tion formulation, the process in volv es accum ulating the dot-pro duct results of Q · K and subsequen tly applying a softmax op eration 8 Figure 4: Diffusion of Deep-Matching across the scores of differen t V v ectors. In the QKV mo de, the DODM phenomenon allo ws the target matching words to b e further reinforced and highligh ted within the feature-dimensional context of the Query . Con versely , in the QV mo de, DODM causes the query direction to exhibit a certain degree of diver genc e effe ct . In a sense, the searc h inten t b ecomes diffused rather than concen trated. W e h yp othesize that this structural dif- ference—where QK V concentrates attention while QV inherently scatters the query fo cus—is the primary reason for the sup erior p erformance of the standard QK V mechanism. 9 9 MQA/GQA/MLA In recen t adv ancemen ts, KV-Shared arc hitectures suc h as GQA (Group ed- Query A ttention) [6]and MLA (Multi-head Latent Atten tion) [4]hav e ac hieved significan t success by drastically reducing the memory fo otprin t of the KV-cache. W e now seek to explain the underlying principles and essence of these mec hanisms through our theoretical framework. V-Shared T o simplify the analysis, we introduce a minimal mo del hyp othesis : supp ose eac h T oken/Em b edding p ossesses N = 6 semantic or syn tactic expression di- rections (e.g., verb, adjectiv e, adv erb, noun, etc.), denoted as { a, b, c, d, e, f } . The p otential mo difier-relationship com binations total N × N = 36. F or a mo del with 6 la y ers, this requires an av erage of 6 heads p er la yer. The core optimization problem is ho w to organize these heads to minimize the KV-cac he. In eac h lay er, w e can consolidate the V vectors. F or instance: • Scenario 1 : A single V is shared by 6 Queries: { a, b, c, d, e, f } → V a . • Scenario 2 : Two V s are shared, eac h corresp onding to 3 Queries: { a, b, c } → V a and { d, e, f } → V b . Compared to unconstrained matching, reusing V within eac h lay er signifi- can tly reduces the cache. V arian t of QV While the QV mo de naturally accommodates the ab o ve logic, a con tradiction arises in the standard QK V mode. According to our deriv ation, while V v (the v alue con tent) can b e shared, Q q and V k m ust main tain a one-to-one corresp ondence for precise matching. It is logically inconsistent for m ultiple Headers in the same lay er to share a single V k within the QK V framework. Ho w, then, do w e explain the success of MQA and GQA? W e p osit that there is only one p ossibility: the essence of MQA/GQA has s hifted from the original Q q · V k V v form to ward a v arian t of the QV mo de , sp ecifically: Q v · K v V v (5) 10 Figure 5: QV Mo de vs QKV Mo de In this context, K v can b e viewed as a version of V injected with p ositional enco dings. Its primary—and p erhaps only—functional significance is the computation of p ositional relationships (assuming D k = D v ). MLA: The Optimized Ev olution In industry practice, GQA often uses a fixed group size (e.g., 2, 4, or 8). Ho wev er, this is suboptimal; differen t seman tic features require v arying n um- b ers of Atten tion headers. MLA addresses this by applying a compres- sion/extraction lay er to K and V , dynamically adapting to each Header. By emplo ying this metho d, MLA outp erforms GQA in terms of mo del accuracy , whic h comes at the cost of increased computational complexity . Because MLA p erforms deep compression on b oth K and V , it cannot con- form to the rigid Q q · V k V v paradigm. Instead, MLA should b e understo o d as a soft , highly optimized version of GQA. F undamentally , it remains a man- ifestation of the QV mo de, where the compressed latent space facilitates a more flexible seman tic-matching-to-v alue-retriev al mapping. 11 F uture Optimization Directions Based on the preceding ana lysis, w e can deriv e sev eral potential optimization tra jectories for GQA and MLA: • The GQA/MLA-QvVv Arc hitecture : If w e adopt relativ e p osi- tional calculation metho ds suc h as A GF , T5 , or ALiBi [7], the K vec- tor can b e entirely discarded. W e designate this mo del as GQA/MLA- QvVv (assuming D k = D v ). In this configuration, the traditional dep endency on an explicit Key is eliminated, further streamlining the A ttention mechanism while main taining semantic integrit y via the QV logic. • T ransition from KV-Shared to V-Shared Mo de : A strategic shift can b e made from a KV-shar e d to a V-shar e d paradigm. Under this mo de, the V comp onen t remains maximally shared across heads to preserv e memory efficiency . Ho wev er, we retain a unique, one-to-one K for each Q , transitioning the mo del bac k to ward the original structural logic: ( Q k · V k ) V v . Although K will o ccupy additional storage space in the KV-cac he, this approac h provides a richer representation for matc hing, which theoretically leads to higher mo del accuracy . • Optimization of Compression Ratios in MLA : In current MLA implemen tations, the compression of K and V is highly aggressive. W e h yp othesize that low ering the compression ratio of K —for instance, aligning it more closely with the compression level of Q —could pre- serv e more global features. This would enable the mo del to b etter express the complex semantics inheren t in the standard ( Q q · V k ) V v mo de, p oten tially yielding significant gains in predictive precision. 10 Key-After-V alue Mo de (QV-Ka) Under the standard ( Q q · V k ) V v paradigm, particularly in KV-Cache scenarios, V theoretically offers significant p oten tial for compression and reuse. Ho w- ev er, since K m ust maintain a one-to-one corresp ondence with Q , a critical question arises: is there further ro om for compressing K ? According to our deriv ed definition of the QK V mechanism, a strong in trinsic correlation exists b etw een K and V . Sp ecifically , K can b e in terpreted as the 12 result of a De ep-Matching op eration p erformed on the features of V , guided b y the token-con text. This relationship can b e expressed as: K = DM( V , Context) (6) Consequen tly , it is theoretically feasible to reuse the information contained within V for the computation of K . Figure 6: QV-Ka Pro cess The traditional Multi-Head Atten tion logic is defined as: MultiHead( Q, K, V ) = Concat(head 1 , . . . , head h ) W O where head i = A tten tion( QW Q i , K W K i , V W V i ) (7) In our prop osed mo del, the computational logic for each individual header is 13 redefined as follo ws: Q i = QW Q i V i = V W V i G = K W ctx K i = [ G ; V i ] W K i head i = A tten tion( Q i , K i , V i ) (8) W e designate this architecture as the QV-Ka (Key-after-v alue&ctx) mo de. In our ev aluation, we main tained the default hyperparameter configuration: L = 3, d model = 1024, h = 16, and d head = d model /h = 64. W e tested the QV-Ka mo de b y setting the dimension of the con text vector ( d ctx ) to 1 × and 2 × the size of d head , resp ectively . The comparativ e results are summarized in T able 4. T able 4: P erformance Comparison under AGF and PCM-V F rameworks Mo de Crafts V alid Accuracy (%) QV Default (Sin usoidal PE) 70.0756 QKV Default (Sin usoidal PE) 70.5911 QV A GF + PCM-V 70.5188 QKV A GF + PCM-V 70.7305 QV-Ka ( d ctx = d head ) A GF + PCM-V 70.4998 QV-Ka ( d ctx = 2 d head ) AGF + PCM-V 70.6919 As illustrated b y the performance curv es under the AGF/PCM-V framew ork, the QV-Ka ( 2 · d head ) mo de achiev es results comparable to the original QKV mo de. Notably , this is accomplished with a significantly reduced parameter coun t and computational ov erhead. F urthermore, during the initial stages of training, the QV-Ka mo de exhibits sligh tly sup erior p erformance compared to the standard QKV . This observ a- tion aligns with our theoretical deriv ation of the Q, K, V factors: the QV-Ka mo de adheres more closely to the intrinsic logic of the problem, whereas the standard QKV mec hanism can b e viewed as a redundan t, appro ximate im- plemen tation. 14 Figure 7: Comparision of QV/QKV/QV-Ka 11 Conclusion Departing from traditional experiment-driv en or purely empirical approaches to mo del architecture design and optimization, this pap er first establishes a theoretical and interpretable framework to h yp othesize and demonstrate the intrinsic logic of the QK V Atten tion mechanism. Through this logical deriv ation, we prop ose the QV mo de as a fundamen tal abstraction. By analyzing and syn thesizing con temp orary architectures such as MQA, GQA, and MLA, w e conclude that these models are essentially v arian ts of the QV paradigm. Building up on this insight, w e pro vide strategic directions for future architectural optimizations and in tro duce the QV-Ka optimization mo de. Our exp erimen tal results pro vide robust empirical evidence supporting the v alidity of our theoretical conjectures. The QV and QV-Ka mo des prop osed in this study contribute directly to the enhancement of mo del efficiency and p erformance. F urthermore, w e b elieve that our in-depth analysis of the un- derlying logic of QK V A ttention offers a v aluable theoretical reference for 15 the ongoing ev olution of Large Language Mo del (LLM) architectures. 12 Limitations Due to constraints in the exp erimental en vironment, the data scale, model parameters, and the num b er of lay ers utilized in this study remain rela- tiv ely mo dest. While our findings provide strong theoretical and empirical supp ort for the prop osed mec hanisms, their p erformance and scalabilit y in pro duction-grade Large Language Mo dels (LLMs) with significantly larger parameter coun ts require further rigorous testing and v alidation. References [1] Ashish V asw ani, Noam Shazeer, Niki Parmar, Jakob Uszk oreit, Llion Jones, Aidan N Gomez, Luk asz Kaiser, and Illia Polosukhin. “Atten tion is all y ou need”. In: A dvanc es in neur al information pr o c essing systems . 2017, pp. 5998–6008. [2] Edw ard Zhang. “A tten tion’s Gra vitational Field: A Po w er-La w In terpre- tation of P ositional Correlation”. In: arXiv pr eprint (2026). [3] Srinadh Bho janapalli, Darshan Chakrabarti, Dimitris P apailiop oulos, Rama Krishna Siddhardh, and Nathan Srebro. “Low-rank b ottleneck in m ulti-head attention mo dels”. In: arXiv pr eprint (2020). [4] DeepSeek-AI and others co des others. “DeepSeek-V2: A Strong, Eco- nomical, and Efficient Mixture-of-Exp erts Language Mo del”. In: arXiv pr eprint arXiv:2405.04434 (2024). [5] Noam Shazeer. “F ast T ransformer Deco ding: One W rite-Head is All Y ou Need”. In: arXiv pr eprint arXiv:1911.02150 (2019). [6] Josh ua Ainslie, James Lee-Thorp, Michiel de Jong, Y ury Zemlyanskiy, F ederico F edus, Niklas Muennighoff, et al. “GQA: T raining Generalized Multi-Query T ransformer Mo dels from Multi-Head Chec kp oin ts”. In: arXiv pr eprint arXiv:2305.13245 (2023). 16 [7] Ofir Press, Noah A Smith, and Mik e Lewis. “T rain Short, T est Long: A ttention with Linear Biases Enables Input Length Extrap olation”. In: arXiv pr eprint arXiv:2108.12409 (2021). 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment