바이트 수준 토크나이저 없이 연속 구면 압축 모델링
HoloByte는 바이트 시퀀스를 고정 크기 청크로 나눈 뒤, 정규 직교 회전을 이용해 단위 구면에 투사함으로써 연속적인 저차원 표현으로 압축한다. 매크로 트랜스포머는 압축된 청크 시퀀스에만 주의를 기울여 시간·메모리 복잡도를 O(N²/W² · D + N · D²)로 감소시키고, 마이크로 디코더가 구면에서 복원해 정확한 바이트 확률을 얻는다. 이중 손실(크로스 엔트로피 + 잠재 MSE)로 학습 안정성을 보장하고, D ≥ Ω(W · ln|V|)라…
저자: Vladimer Khasia
본 논문은 자연어 및 코드와 같은 시퀀스 데이터를 모델링할 때, 기존에 널리 사용되는 서브워드 토크나이저가 초래하는 인위적 경계와 어휘 의존성을 근본적으로 제거하고자 한다. 토크나이저는 바이트 시퀀스를 압축해 어휘 V_BPE 를 형성하지만, 이는 형태소 경계와 무관한 임의의 구분을 만들고, O(N²) 복잡도를 완화하기 위해서만 존재한다. 저자들은 이러한 딜레마를 해결하기 위해 ‘HoloByte’라는 프레임워크를 제안한다. 핵심 아이디어는 바이트 시퀀스를 고정 용량 청크 W 로 나누고, 각 청크를 정규 직교 회전(Orthogonal Positional Rotation)을 통해 단위 구면 S^{D‑1} 위에 투사함으로써, 청크 전체를 하나의 D 차원 연속 벡터 zₜ 로 압축한다. 이 과정은 완전 가역적이며 차원을 보존한다.
압축된 청크 시퀀스 Z = (z₀,…,z_{T‑1}) 은 매크로 트랜스포머 f_θ 에 입력된다. 매크로 모델은 전통적인 인과적 셀프‑어텐션을 수행하지만, 입력 길이가 T = N/W 로 감소했기 때문에 어텐션 연산의 시간 복잡도가 O((N/W)²·D) 로 크게 줄어든다. 동시에 피드포워드 네트워크 비용은 O((N/W)·D²) 로 변한다. 청크 내부의 바이트를 복원하기 위해, HoloByte는 마이크로 디코더 g_ϕ 를 도입한다. 매크로 모델이 출력한 ẑₜ 에 대해 역회전 R⁻¹(·,i) 를 적용하면 각 위치 i 에 대한 구면 벡터 ũₜ,ᵢ 를 얻는다. 이 벡터에 오른쪽 시프트된 청크 시작 토큰 e_start 와 이전 바이트 임베딩을 더해 hₜ,ᵢ 를 만든 뒤, W 길이의 로컬 어텐션을 수행해 최종 바이트 로그잇을 산출한다. 마이크로 디코더는 청크 내에서만 연산하므로, 전체 메모리 사용량은 O(N·W) 로 제한된다.
학습 목표는 두 부분으로 구성된다. 첫 번째는 전통적인 크로스 엔트로피 L_CE 로 바이트 로그잇을 최적화하는 것이며, 두 번째는 잠재 공간에서의 평균 제곱 오차 L_Latent = λ·∑ₜ‖ẑₜ−z*ₜ‖² 를 추가한다. 여기서 z*ₜ 는 청크 c_{t+1} 를 동일한 인코딩 함수 E 로 변환한 ‘정답’ 구면 벡터이다. L_Latent 은 매크로 모델이 정확한 구면 위치에 수렴하도록 강제하고, 그래디언트 크기를 ‖ẑ−z*‖ 에 비례하게 제한함으로써 크로스 엔트로피가 초래할 수 있는 로그잇 폭발을 방지한다. 논문은 L_Latent 가 Lipschitz 상수를 4√W 로 제한한다는 정리를 제시한다.
이론적 기여는 크게 두 가지이다. 첫째, Lemma 1 은 회전과 슈퍼포지션 과정에서 발생하는 간섭 ϵₜ,ᵢ 의 기대 ‖·‖² 가 O(1) 로 차원 D 에 독립적임을 보인다. 둘째, Theorem 1 은 오류 없는 복원을 위해 필요한 최소 차원 D 가 D ≥ Ω(W·γ²·ln(|V|/δ)) 를 만족해야 함을 증명한다. 여기서 γ 는 마진, δ 는 복원 실패 확률이다. 따라서 충분히 큰 D 를 선택하면 청크 내 모든 256가지 바이트를 정확히 구분할 수 있다.
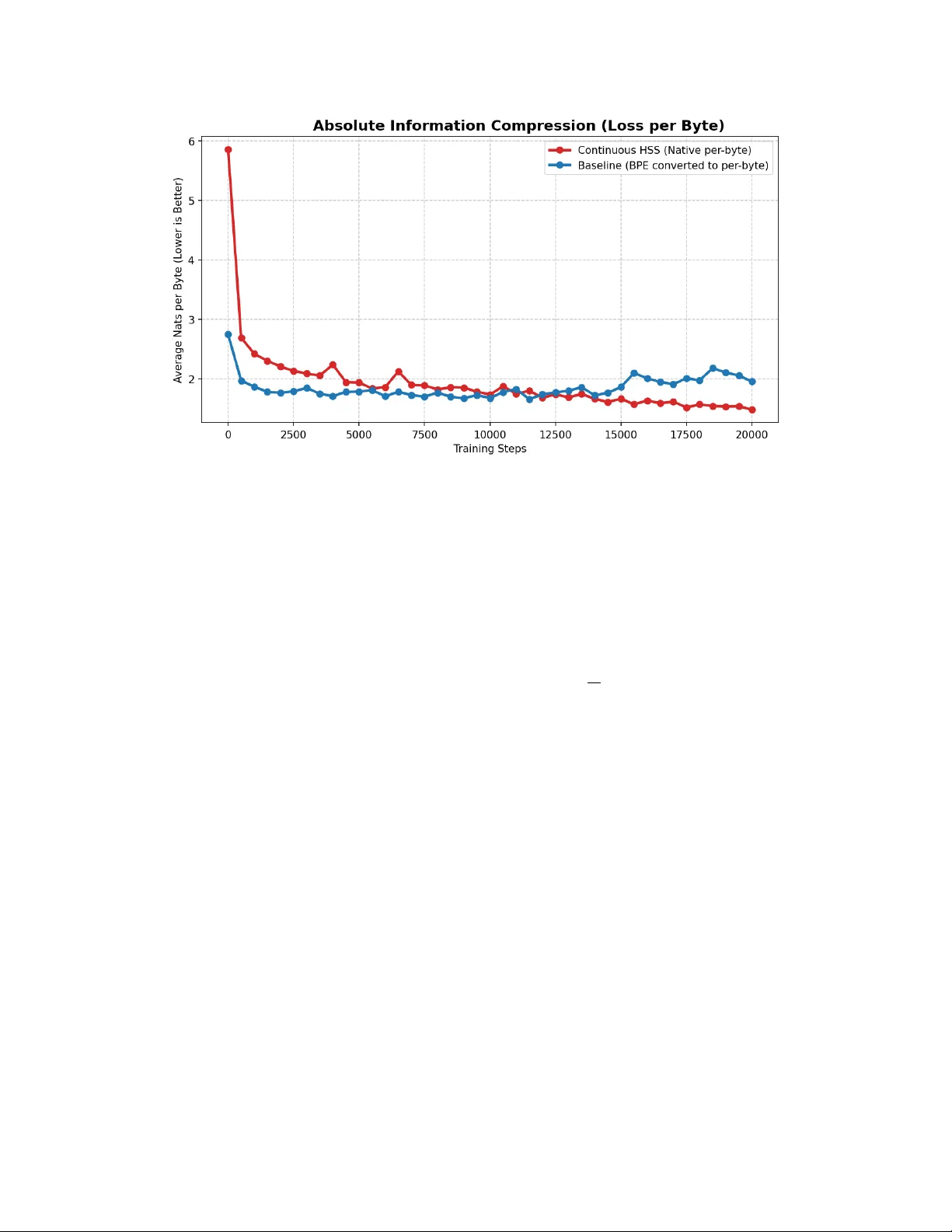
복잡도 측면에서, 전체 전방 패스의 시간 복잡도는 O(N²·W⁻²·D + N·D²) 로, 원래 바이트‑레벨 트랜스포머의 O(N²·D) 에 비해 W² 배의 절감 효과가 있다. 메모리 복잡도는 O(N²·W⁻² + N·W) 로, 특히 W=8 일 때 매크로 어텐션 메모리가 64배 감소한다. 실험에서는 파라미터 수를 82 M 로 맞춘 BPE 기반 베이스라인과 직접 비교했으며, HoloByte 가 바이트당 엔트로피 1.484 nats 를 달성해 1.954 nats 를 기록한 BPE보다 현저히 효율적임을 보였다. 또한, 동일 파라미터 조건에서 학습 안정성 및 수렴 속도에서도 우위를 보였다.
제한점으로는 청크 크기 W 의 선택이 모델 효율성에 큰 영향을 미친다. W 가 작으면 압축 효과가 감소하고, W 가 크면 차원 D 를 크게 늘려야 하므로 연산·메모리 비용이 급증한다. 또한 현재 구현은 정적 회전 행렬과 고정 청크 길이에 의존하므로, 가변 길이 시퀀스나 비정형 데이터에 대한 적응성이 제한적이다. 향후 연구에서는 동적 청크 스케줄링, 비선형 변환, 멀티모달 확장, 그리고 하드웨어 친화적 구현 등을 탐색할 여지가 있다. 전반적으로 HoloByte는 토크나이저 의존성을 없애면서도 계산 효율성을 유지하는 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기