HoloByte: Continuous Hyperspherical Distillation for Tokenizer-Free Modeling
Sequence modeling universally relies on discrete subword tokenization to circumvent the $\mathcal{O}(N^2)$ computational intractability of native byte-level attention. However, this heuristic quantization imposes artificial morphological boundaries, …
Authors: Vladimer Khasia
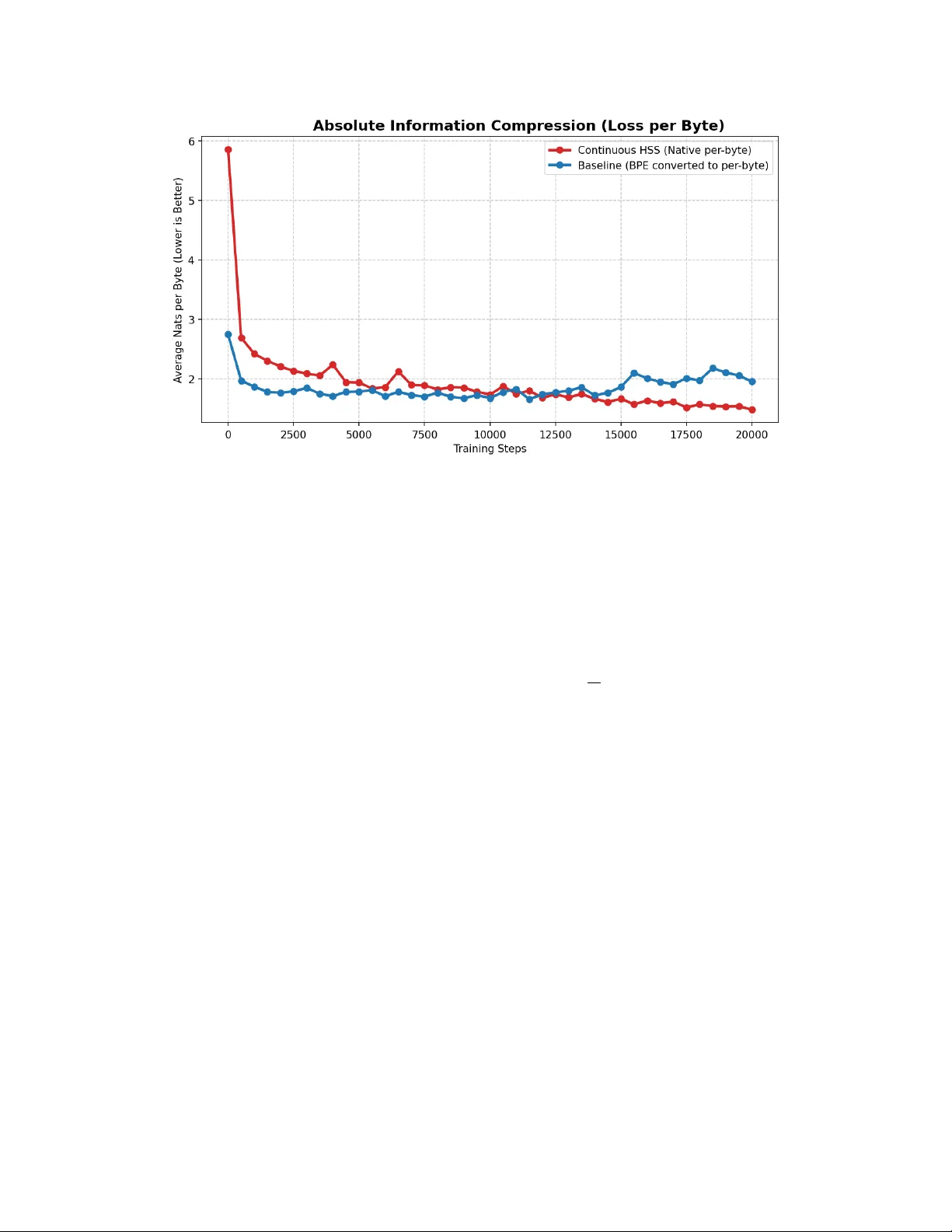
H O L O B Y T E : C O N T I N U O U S H Y P E R S P H E R I C A L D I S T I L L A T I O N F O R T O K E N I Z E R - F R E E M O D E L I N G Vladimer Khasia Independent Researcher vladimer.khasia.1@gmail.com A B S T R AC T Autoregressi ve sequence modeling uni versally relies on discrete subword tokenization to circumvent the O ( N 2 ) computational intractability of nativ e byte-level attention. Howe ver , this heuristic quanti- zation imposes artificial morphological boundaries, enforces v ocabulary dependence, and fractures the continuity of the optimization landscape. T o resolve this dichotomy , we introduce HoloByte : a strictly tokenizer -free framework utilizing Continuous Hyperspherical Distillation. HoloByte partitions discrete byte sequences into fixed-capacity chunks and projects them into a continuous, strictly bounded hyperspherical manifold via an in vertible, dimension-preserving orthogonal rotation operator . This spatial superposition allows a macroscopic transformer to operate exclusiv ely on compressed continuous representations, formally reducing the exact attention time complexity from O ( N 2 D ) to O N 2 W 2 D + N D 2 . A localized causal micro-decoder subsequently unbinds these representations to compute e xact byte-lev el distributions. T o gov ern this continuous trajectory , we propose a dual-objecti ve formulation incorporating a mathematically precise Holographic Latent Mean Squared Error , which strictly bounds the gradient and guarantees asymptotic stability . Theoreti- cally , we deri ve the minimal embedding dimension D = Ω( W ln |V | ) required to ensure error -free discrete recovery from the continuous manifold. Empirically , under strictly matched parameter constraints ( O ( P ) ≈ 82 × 10 6 ), HoloByte is systematically outperforming a comparable discrete Byte-Pair Encoding (BPE) baseline. These results establish Continuous Hyperspherical Distillation as a mathematically rigorous and computationally tractable foundation for vocab ulary-in variant sequence modeling. The code is av ailable at https://github.com/VladimerKhasia/HoloByte 1. Continuous Hyperspherical Distillation & Macroscopic A utoregression 2. Localized Causal Micro-Decoding (Byte-Level Recovery) Chunk t c t ∈ V W Holographic Encoding E 1 √ W P R z t ∈ R D Macro-Model f θ ˆ z t ∈ R D Chunk t + 1 c t +1 Holographic Encoding E 1 √ W P R T ar get z ∗ t L Latent Hyperspherical Unbinding R − 1 Micro-Decoder g ϕ Byte Logits ∼ P ( V ) L CE T arget Bytes b t,i + Causal Prefix p t,i + Pos Enc ˆ u t,i h t,i 1 Introduction The prev ailing paradigm in autoregressi ve sequence modeling maps an input sequence from a discrete categorical space to a probability distribution ov er subsequent states. T o circumv ent the high asymptotic time complexity of processing sequences at the fundamental byte or character le vel [ 1 , 2 , 3 , 4 ], modern architectures univ ersally employ sev eral types of tokenization algorithms [ 5 , 6 ], most notably Byte-Pair Encoding (BPE) [ 7 , 5 ]. T okenization operates as a heuristic data compression mechanism, aggregating contiguous byte sequences into a finite vocab ulary V B P E where typically |V B P E | ∼ 5 × 10 4 . While computationally expedient, this discrete quantization introduces sev ere representational pathologies: it imposes rigid, artificial boundaries on morphologically contiguous data, enforces out-of-vocab ulary (OO V) truncation, and forces the optimization trajectory of continuous neural manifolds to operate o ver an arbitrary , combinatorial mapping. Con versely , formulating the sequence modeling objecti ve natively over the fundamental byte alphabet V by te = { 0 , 1 , . . . , 255 } guarantees strict topological continuity and vocab ulary in variance. Ho wev er , this approach introduces a prohibitiv e computational bottleneck. Giv en a sequence of N raw bytes, standard attention mechanisms require O ( N 2 D ) asymptotic time complexity , where D is the embedding dimension. If a standard tokenization heuristic compresses sequences by an av erage factor of µ ≈ 4 , substituting it with nativ e byte-level processing inflates the attention complexity by a factor of µ 2 ≈ 16 . Consequently , purely discrete byte-le vel modeling remains mathematically intractable for extended conte xt windows. T o resolve the dichotomy between token-induced quantization artifacts and the O ( N 2 ) complexity bound of nati ve byte processing, this manuscript presents HoloByte : a frame work for Continuous Hyperspherical Distillation. Instead of enforcing discrete vocab ulary clustering, HoloByte projects raw byte sequences into a continuous, strictly bounded hyperspherical manifold. By partitioning the discrete byte sequence into fixed-capacity chunks of size W , the frame work employs a mathematically in v ertible, unitary rotation operator to superimpose sequence positional information into a single continuous vector z ∈ R D . This deterministic mapping translates the auto-regressi ve objecti ve from discrete token prediction into the temporal ev olution of a continuous geometric space. The macroscopic architecture operates exclusiv ely on these continuous compressed representations, strictly bounding the macro-attention complexity to O ( N 2 W 2 D ) . T o recover the e xact byte configurations, a localized causal micro-decoder dynamically unbinds the spatial superpositions in O ( N W D ) time, thereby computing the conditional probability distribution o ver V by te without vocab ulary expansion. T o optimize this continuous trajectory , we introduce a dual-objecti ve loss formulation. Beyond standard maximum likelihood estimation via Cross-Entropy , the framework inte grates a Holographic Latent Distillation signal. Because the encoding function is continuous and deterministic, the ground-truth tar get vector for the subsequent sequence chunk is kno wn a priori . This allows the macro-model to directly minimize the latent Mean Squared Error (MSE) between its predicted state and the true hyperspherical projection, forcing the continuous optimization landscape to con v erge mathematically prior to the discrete decoding step. The primary contributions of this w ork are formalized as follows: • Hyperspherical Orthogonal Binding: W e formulate an in vertible, dimension-preserving encoding mechanism utilizing orthogonal spatial rotations, allowing multiple discrete variables to be mathematically superimposed onto a single continuous vector without representational collapse. • Asymptotic Complexity Reduction: W e provide a formal proof demonstrating that the integration of continuous chunking and autoregressi ve micro-decoding reduces the exact attention memory constraints from O ( N 2 ) to O ( N 2 W 2 + N · W ) . • Absolute Inf ormation Compression: Through strictly controlled empirical ev aluations under parameter- matched constraints ( ≈ 82 × 10 6 parameters), we demonstrate that the continuous HoloByte architecture con ver ges to a theoretical entropy bound of 1 . 484 nats per byte, systematically outperforming the baseline discrete subword architecture ( 1 . 954 nats per byte). • Theoretical Bounds on Superposition Capacity: W e deri ve a strict mathematical lower bound for the embedding dimension D = Ω W γ 2 ln |V | , proving that the inv erse unitary rotation guarantees error-free discrete recov ery of the unbound signal. Furthermore, we establish that the Holographic Latent distillation objectiv e strictly bounds the Lipschitz constant to 4 √ W , guaranteeing optimization stability independent of vocab ulary cardinality as parameter counts scale asymptotically . 2 The remainder of this manuscript is structured as follows. Section 2 deri ves the underlying mathematical formulation of the hyperspherical manifold and constructs the algorithm from first principles. Section 3 defines the ev aluation metrics and documents the empirical con ver gence boundaries. 2 Methodology The fundamental objectiv e of the HoloByte framework is to map a discrete sequence of bytes into a continuous, highly compressed hyperspherical manifold, thereby bypassing the necessity of subword tokenization while circumventing the quadratic scaling bottlenecks of nativ e byte-lev el models. 2.1 Problem F ormulation and Mathematical F oundation Let V = { 0 , 1 , . . . , 255 } denote the fundamental byte alphabet. Gi ven a sequence of bytes b = ( b 0 , b 1 , . . . , b N − 1 ) ∈ V N , we partition b into contiguous chunks of fixed capacity W . Let T = ⌊ N/W ⌋ denote the number of chunks. W e represent the t -th chunk as a vector of bytes c t = ( b t, 0 , b t, 1 , . . . , b t,W − 1 ) ∈ V W . W e define a learnable byte manifold matrix M ∈ R 256 × D , where D is the embedding dimension. The projection of a byte v ∈ V onto the unit hypersphere is gi ven by ˜ m v = m v ∥ m v ∥ 2 . Definition 1 (Orthogonal Positional Rotation) . T o pr eserve positional information within a chunk W without e xpanding the spatial dimension, we define an orthogonal r otation transformation R ( x , i ) for a vector x ∈ R D at intra-chunk position i ∈ { 0 , 1 , . . . , W − 1 } . Let the dimension D be even, suc h that x = [ x ⊤ 1 , x ⊤ 2 ] ⊤ . The r otation matrices are defined using fr equency bases ω j = 10000 − 2 j /D . The r otated vector is: R ( x , i ) = x 1 ⊙ cos( θ i ) − x 2 ⊙ sin( θ i ) x 1 ⊙ sin( θ i ) + x 2 ⊙ cos( θ i ) , (1) wher e θ i = [ iω 0 , iω 1 , . . . , iω D/ 2 − 1 ] ⊤ . Since R r elies on orthogonal r otation, it is a strict isometry , and its in verse is exactly R − 1 ( x , i ) = R ( x , − i ) . 2.2 Continuous Hyperspherical Distillation (HoloByte) 2.2.1 Holographic Encoding The encoding function E : V W → R D compresses a chunk of bytes c t into a single continuous v ector z t . By projecting the bytes onto the unit hypersphere and applying the unitary rotation, the chunk embedding is: z t = E ( c t ) = 1 √ W W − 1 X i =0 R ( ˜ m b t,i , i ) . (2) The sequence of continuous vectors Z = ( z 0 , . . . , z T − 1 ) is injected with learned absolute positional embeddings and processed by a causal self-attention macro-model f θ , yielding predicted continuous representations ˆ Z = ( ˆ z 0 , . . . , ˆ z T − 1 ) . 2.2.2 Hyperspherical Unbinding and Micro-Decoding T o extract individual bytes from the predicted macroscopic vector ˆ z t , we apply the inv erse rotation to unbind the spatial superpositions. The geometrically unbound signal for position i is ˆ u t,i = R − 1 ( ˆ z t , i ) . T o guarantee strict causality during teacher-forced autoregression without leaking future chunk information, the tar get embeddings are right-shifted. Specifically , the final target byte is truncated, and the sequence is prefix ed with a learnable chunk-start vector e start . This exact matrix concatenation ensures the micro-decoder g ϕ predicts position i conditioned strictly on the unbound signal and b t,
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment