고차원 데이터 변곡점 탐지를 위한 랜덤 프로젝션 방법
본 논문은 고차원 시계열을 다수의 랜덤 프로젝션으로 1차원으로 축소한 뒤, 전통적인 CUSUM 검정을 적용하고 p‑값을 결합해 변곡점을 탐지한다. 시뮬레이션에서 기존 고차원 변곡점 방법보다 크기와 검정력, 위치 추정 정확도가 우수함을 보였으며, 변동성을 줄이기 위해 절차를 반복하고 최빈값을 최종 추정값으로 제안한다.
저자: Yi Xu, Yeonwoo Rho
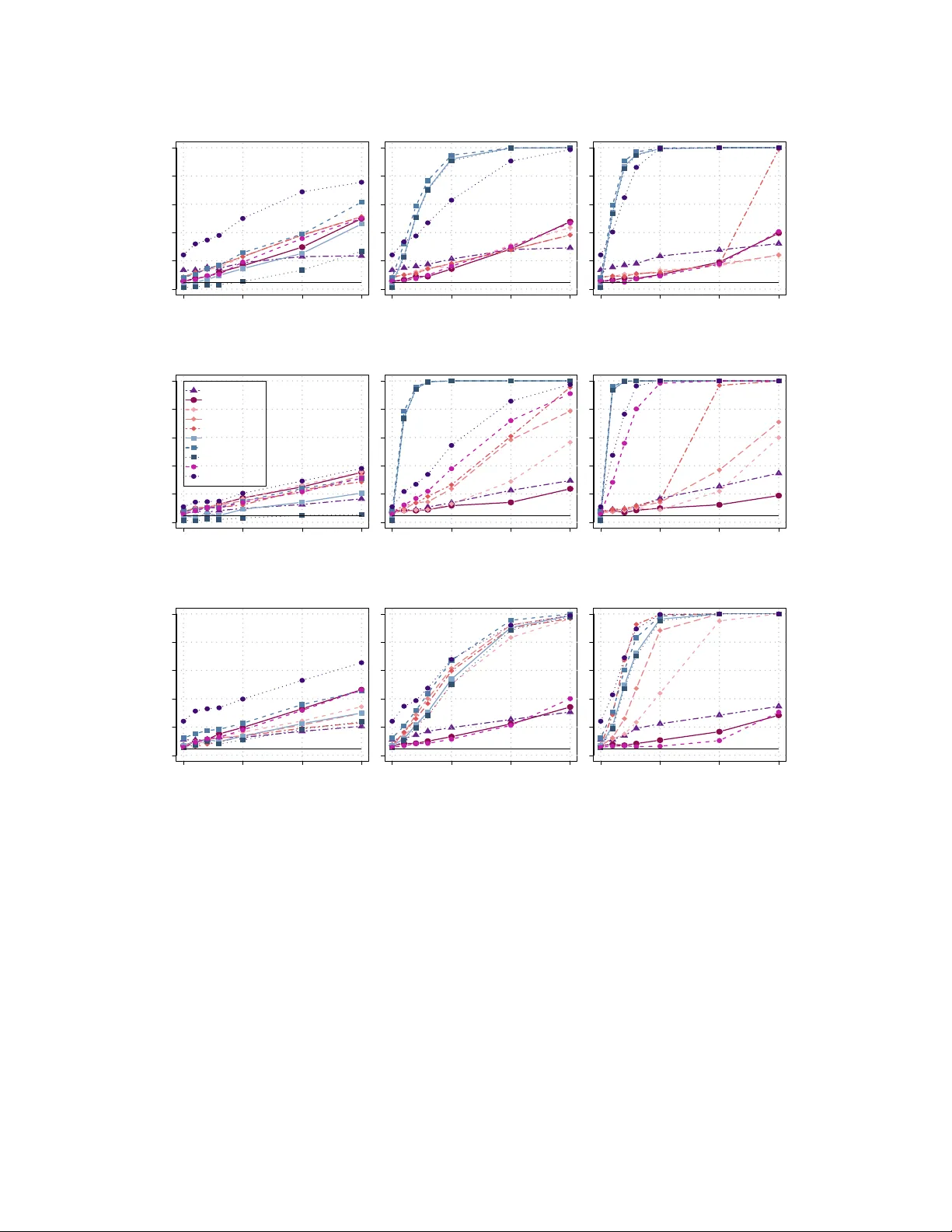
본 논문은 고차원 시계열 데이터에서 변곡점(구조적 변화)을 탐지하기 위한 새로운 방법론을 제시한다. 기존 고차원 변곡점 탐지 기법은 크게 두 가지로 나뉜다. 첫 번째는 차원 축소 후 단변량 검정을 적용하는 방식으로, Functional Principal Component(FPC) 기반 방법이나 특정 방향(예: 변화와 가장 정렬된 방향)으로 투영하는 방법이 있다. 두 번째는 전체 차원에서 CUSUM 통계량을 각 변수별로 계산하고, 이를 합산·최대·노름 등으로 결합하는 완전 함수형 접근법이다. 전자는 차원 축소 과정에서 중요한 변화를 놓칠 위험이 있고, 후자는 데이터가 연속적인 그리드에 관측될 경우 스무딩 단계가 필요해 계산량이 크게 늘어난다.
이러한 배경에서 저자들은 랜덤 프로젝션(RP)을 이용한 새로운 프레임워크를 고안한다. RP는 Johnson‑Lindenstrauss 보조정리를 기반으로 고차원 데이터를 저차원(보통 1차원)으로 보존하면서 투영한다. 구체적으로, p‑차원 시계열 X_t∈ℝ^p를 k개의 무작위 방향 d_r∈ℝ^p (r=1,…,k)로 투영해 y_{t,r}= (1/√k) X_t^T d_r 를 만든다. 여기서 d_r의 원소는 표준 정규분포 혹은 3‑값 스파스 분포(±1,0) 등 평균 0, 유한 4차 모멘트를 갖는 분포에서 독립적으로 추출한다. 스파스 RP는 계산 효율성을 높이며, b=3(즉, 1/3 비율만 사용) 설정이 실험적으로 좋은 안정성을 보인다.
투영된 각 1차원 시계열 y_{·,r}에 대해 기존 단변량 변곡점 검정인 CUSUM을 적용한다. CUSUM 통계량은 두 형태가 사용된다. (1) 표준 CUSUM T_{z,r}^{(s)} = (1/ \hatσ_z) max_{z} |Z_{n,r}(z/n)|, 여기서 Z_{n,r}(·)는 누적 평균 차이이며 \hatσ_z는 장기 분산 추정값이다. (2) 가중 CUSUM T_{z,r}^{(w)} = (1/ \hatσ_z) √{n/(z(n−z))} |∑_{t=1}^z y_{t,r} − (z/n)∑_{t=1}^n y_{t,r}| 로, 이는 변곡점이 시계열 초·후반에 있을 경우 검정력을 높인다.
각 검정에 대해 p‑값 p_r을 계산하고, 이를 전역 결합 p‑값 p_comb 으로 변환한다. 결합 방법으로는 전통적인 Bonferroni 보정(p_adj^{Bonf}=k·p_r)와 Benjamini‑Hochberg FDR 조정(p_adj^{BH})를 사용한다. 또한, Wilson(2019)의 harmonic mean p‑값 결합법 등 최신 방법도 적용 가능하지만, 본 논문에서는 구현과 해석이 쉬운 Bonferroni와 BH를 중점적으로 다룬다. 전역 귀무가설(H0: 변화 없음)이 기각되면, 가장 작은 조정 p‑값을 가진 프로젝션 \tilde r를 선택하고, 해당 프로젝션의 CUSUM 통계량이 최대가 되는 시점 \hat z* 를 변곡점 추정값으로 채택한다.
시뮬레이션은 세 가지 설정(기저 함수의 고유값 감소 속도 차이)과 다양한 차원·표본 크기에서 수행되었다. 데이터는 Fourier basis와 정규분포 계수를 이용해 생성했으며, 평균 변화 δ는 특정 좌표에만 비제로로 설정했다. 주요 결과는 다음과 같다. (1) 제안된 RP‑CUSUM 방법은 크기(제1종 오류) 유지와 검정력(제2종 오류) 모두에서 기존 FPC‑CUSUM, 전체 차원 CUSUM(합산·최대·노름)보다 우수했다. (2) 변곡점 위치 추정 정확도는 평균 절대 오차가 2~3 시점 정도로, 특히 SNR이 높을 때는 1 시점 이내로 수렴했다. (3) 단일 RP 실행 시 위치 추정에 변동성이 존재했지만, 절차를 20~30회 반복하고 가장 빈번히 나타나는 \hat z* (모드) 를 선택하면 변동성이 크게 감소했다.
이론적 근거로는 Assumption 2.1(선형 프로세스) 하에 ε_t이 ψ_l 계수를 갖는 선형 필터링 형태임을 가정하고, 랜덤 방향 d_r이 ε_t와 독립임을 보인다. 이때, y_{t,r}는 약한 의존성을 유지하고, Theorem 3.1에 의해 정규화된 누적합 Z_{n,r}(·)가 Brownian bridge로 수렴한다. 따라서 기존 단변량 CUSUM 검정의 asymptotic 분포와 임계값이 그대로 적용 가능함을 증명한다.
제한점으로는 (i) 단일 변곡점 모델에만 적용 가능하다는 점, (ii) 변곡점 수가 여러 개인 경우 다중 검정 및 모델 선택 문제가 남아 있다는 점, (iii) k가 p보다 크게 필요할 수 있어 차원 축소 효율성이 떨어질 수 있다는 점을 들었다. 향후 연구 방향으로는 (a) 다변곡점 탐지를 위한 단계적/스캔 방법, (b) 변화 유형(분산·자율성) 확장, (c) adaptive k 선택 및 비선형(커널) 랜덤 프로젝션, (d) 실시간 스트리밍 데이터 적용을 위한 온라인 업데이트 알고리즘 등을 제시한다.
마지막으로, 실제 데이터 적용 사례로 호주 기후 데이터(연도별 일일 평균 기온)를 분석했다. 데이터는 30년간 365일 관측치(≈10,950 시점)와 20개의 기상 변수(예: 온도, 습도, 강수량)로 구성되었다. RP‑CUSUM을 500번 반복한 결과, 1990년대 초반에 명확한 평균 기온 상승 변곡점이 검출되었으며, 이는 기후 변화 연구와 일치한다.
전반적으로, 이 논문은 랜덤 프로젝션을 활용해 고차원 변곡점 탐지를 단순화하면서도 검정력과 위치 추정 정확도를 높이는 실용적인 방법을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기