필기 인식에서 토큰화와 데이터 증강의 효과 비교
본 연구는 IMU 기반 온라인 필기 인식에서 작가 간 변동성(인터라이터)과 작가 내 변동성(인트라라이터)을 각각 완화하는 방법으로 서브워드 토큰화와 연결 기반 데이터 증강을 체계적으로 평가한다. 작가 독립(WI) 설정에서는 빅그램 토큰화가 단어 오류율(WER)을 15.40%에서 12.99%로 15.65% 감소시켰으며, 작가 종속(WD) 설정에서는 토큰화가 오히려 성능을 악화시키는 반면, 두 번의 연결 증강이 문자 오류율(CER)을 34.5%, …
저자: Jindong Li, Dario Zanca, Vincent Christlein
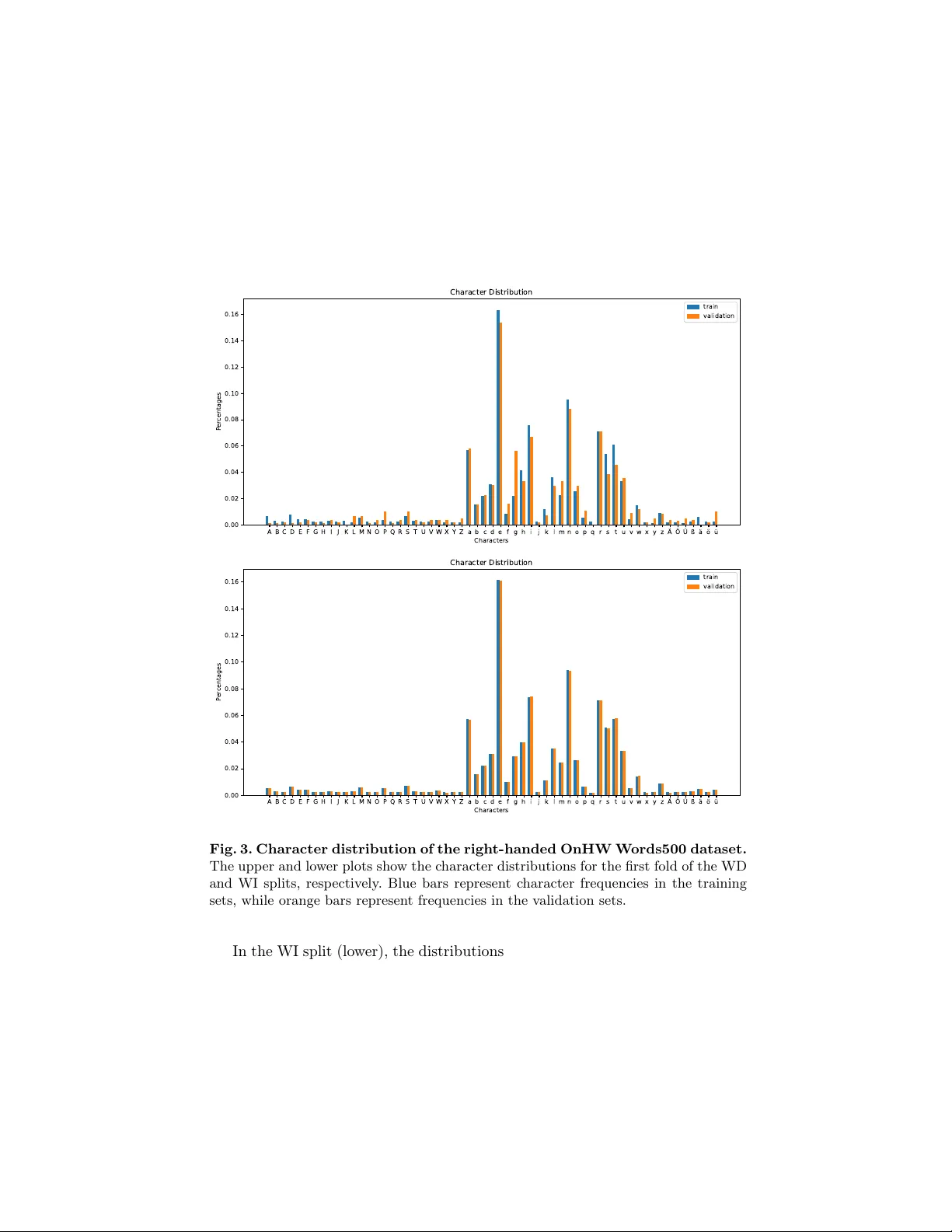
본 논문은 IMU 기반 온라인 손글씨 인식(Online Handwriting Recognition, OnHWR) 분야에서 흔히 발생하는 두 가지 문제, 즉 문자 빈도 불균형과 작가 간 스타일 차이를 해결하기 위한 두 가지 방법—서브워드 토큰화와 연결 기반 데이터 증강—을 체계적으로 비교·분석한다. 연구 배경으로, IMU 센서는 터치스크린이 아닌 자유로운 환경에서도 손글씨를 캡처할 수 있어 활용도가 높지만, 데이터가 작가마다 크게 달라지고 드물게 등장하는 문자(특히 모음·자음 비율 차이) 때문에 일반화가 어렵다. 기존 연구에서는 기하학적 변형이나 GAN 기반 합성으로 데이터를 늘리는 데이터 증강과, 텍스트 라벨을 토큰화해 문자 수준의 변동성을 완화하는 방법을 제시했지만, 이 두 접근법이 각각 어떤 변동성에 효과적인지는 명확히 규명되지 않았다.
**연구 목표**
1. 빅그램, Byte‑Pair Encoding(BPE), Unigram 세 가지 서브워드 토큰화 기법을 다양한 어휘 크기(100~500)로 적용해 성능 변화를 측정한다.
2. 같은 작가의 여러 샘플을 시간축상으로 연결(concatenation)하고 라벨을 이어 붙이는 새로운 데이터 증강 방식을 제안한다.
3. 두 방법을 작가 독립(WI)과 작가 종속(WD) 두 가지 평가 프로토콜에 적용해 각각의 변동성(인터라이터 vs. 인트라라이터)에 대한 효과를 정량화한다.
**실험 설정**
- 데이터셋: OnHW‑Words500의 오른손 서브셋, 53명 작가, 13채널 IMU 데이터.
- 모델: REWI 아키텍처(13‑채널 CNN + Bi‑LSTM + CTC) 기반, 300 epoch 학습, AdamW 옵티마이저, 배치 64.
- 평가 지표: 문자 오류율(CER)과 단어 오류율(WER).
- 토큰화: 각 토큰화 기법을 학습 데이터 라벨에만 피팅하고, 테스트 시 동일 토크나이저로 디코딩.
- 증강: 배치당 동일 작가의 샘플 N=2개를 무작위 선택해 원본 시퀀스 뒤에 연결, 라벨도 순차적으로 이어 붙임.
**주요 결과**
1. **토큰화 효과**
- WI(작가 독립) 분할에서는 빅그램 토큰화가 가장 큰 개선을 보였다. 어휘 크기 500일 때 WER이 15.40% → 12.99%로 15.65% 상대 감소했다. 이는 2‑글자 고정 토큰이 스타일 변동성을 추상화해 모델이 전이 확률에 집중하도록 만든 결과이다.
- Unigram은 어휘가 400 이상일 때 약간의 개선을 보였지만, 빅그램에 비해 뒤처졌다. 토큰 길이가 길어지면서 시계열 연속성에 맞지 않는 복합 토큰이 늘어나 CTC 학습이 불안정해졌다.
- BPE는 전반적으로 성능이 저하되었으며, 특히 WD(작가 종속)에서 어휘 500에서는 수렴 실패(>99% WER)라는 극단적인 현상이 나타났다. 이는 데이터가 제한된 상황에서 빈번히 등장하지 않는 긴 토큰이 과도하게 병합돼 희소성이 급증한 결과이다.
2. **연결 기반 데이터 증강 효과**
- WD 분할에서 두 번의 연결(C2) 적용 시, 문자 수준에서 14.86% → 10.04% (‑34.5%), 단어 수준에서 45.10% → 34.52% (‑25.4%)로 큰 개선을 기록했다. 이는 같은 작가 내에서 드물게 나타나는 문자 조합을 인위적으로 늘려 모델이 희소 데이터에 과적합되는 것을 방지했기 때문이다.
- 토큰화와 결합했을 때는 증강 효과가 감소했으며, 어휘가 커질수록 이 감소 폭이 커졌다. 이는 긴 토큰이 이미 희소성을 내포하고 있어, 추가적인 시퀀스 길이 증가가 큰 도움이 되지 않기 때문이다.
- WI 분할에서는 증강이 거의 영향을 주지 않거나 빅그램 토큰화와 충돌해 성능이 약간 악화되는 현상이 관찰되었다. 이는 WI 상황에서 주요 과제가 스타일 일반화이며, 입력 길이 확대가 스타일 변동성을 완화하는 데 한계가 있음을 의미한다.
3. **토큰 사용량 분석**
- Table 1에서 빅그램 토큰의 1‑글자 사용 비율이 42.98%로 가장 낮았다(다른 토크나이저는 47~55% 수준). 이는 모델이 짧고 일관된 토큰을 선호한다는 증거이며, 짧은 토큰이 시계열 연속성 유지와 CTC 정렬에 유리함을 시사한다.
- BPE와 Unigram은 다중 글자 토큰 비중이 높아질수록 성능 변동성이 커졌다. 특히 BPE는 어휘가 커질수록 토큰이 과도하게 세분화돼 학습이 불안정해졌다.
**시사점 및 한계**
- 인터라이터 변동성(다양한 작가)에는 구조적 추상화가 핵심이며, 빅그램과 같은 짧은 서브워드 토큰이 가장 효과적이다.
- 인트라라이터 변동성(같은 작가 내 데이터 희소)에는 데이터 다양성을 인위적으로 늘리는 연결 기반 증강이 강력한 정규화 역할을 한다.
- 두 방법을 동시에 적용하면 서로 간섭할 위험이 있으므로, 적용 대상이 되는 데이터 분할(작가 독립 vs. 종속)에 따라 전략을 선택해야 한다.
- 본 연구는 IMU 기반 시계열 데이터에 특화된 증강 방법을 제시했지만, 다른 센서 종류(예: 가속도·자이로 외에 압력 센서)나 다중 작가·다중 언어 상황에 대한 일반화는 추가 검증이 필요하다.
**결론**
본 논문은 IMU 기반 온라인 손글씨 인식에서 “스타일 변동성 → 토큰화(빅그램) → 일반화”와 “데이터 희소성 → 연결 증강 → 정규화”라는 두 축의 상호 보완적 접근법을 제시한다. 실험 결과는 각각의 전략이 특정 변동성에 특화되어 있음을 명확히 보여주며, 향후 시스템 설계 시 작가 분포와 데이터 특성을 고려한 맞춤형 전처리·학습 파이프라인 구축의 필요성을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기