Tokenization vs. Augmentation: A Systematic Study of Writer Variance in IMU-Based Online Handwriting Recognition
Inertial measurement unit-based online handwriting recognition enables the recognition of input signals collected across different writing surfaces but remains challenged by uneven character distributions and inter-writer variability. In this work, w…
Authors: Jindong Li, Dario Zanca, Vincent Christlein
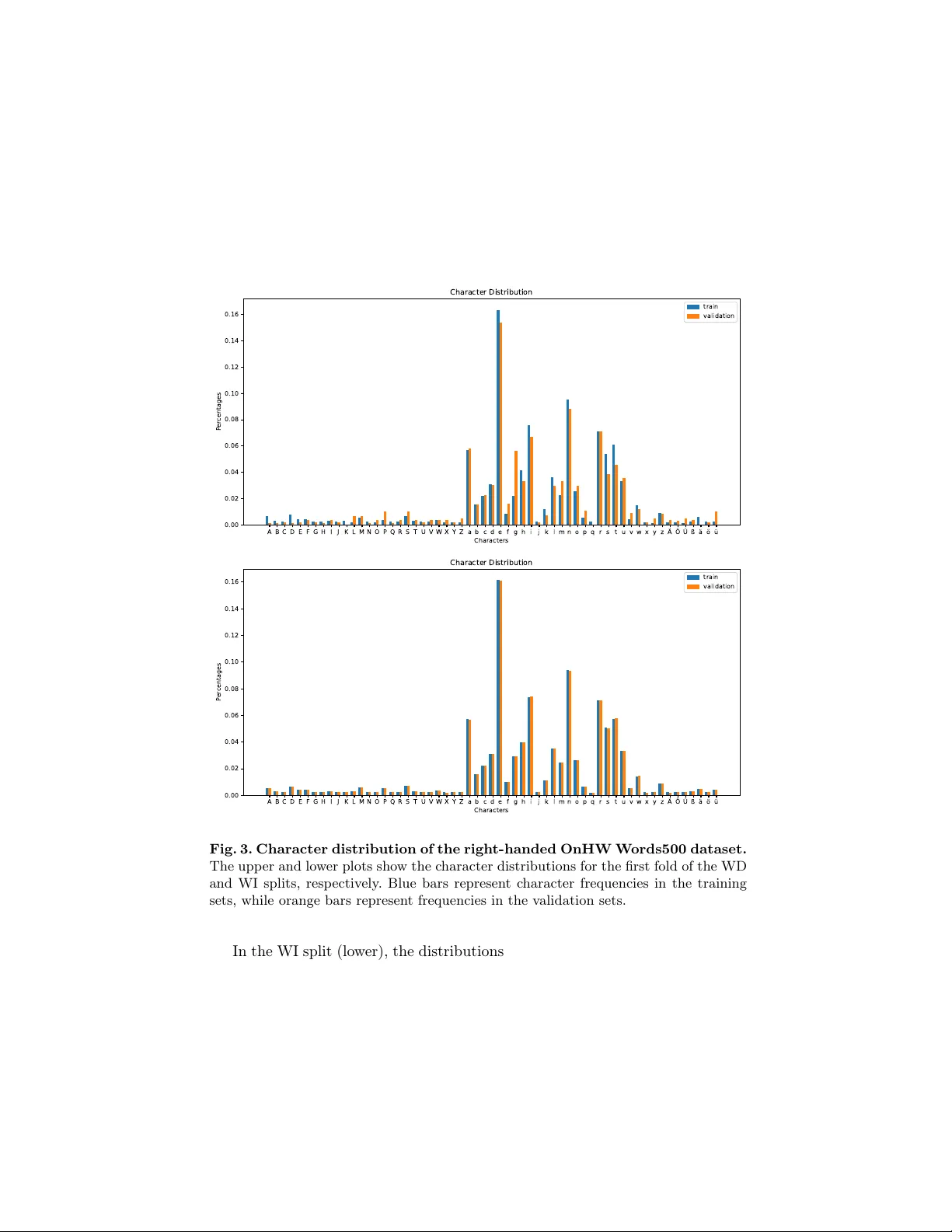
T ok enization vs. Augmen tation: A Systematic Study of W riter V ariance in IMU-Based Online Handwriting Recognition Jindong Li 1 , 4 [0000 − 0002 − 3550 − 1660] , Dario Zanca 1 [0000 − 0001 − 5886 − 0597] , Vincen t Christlein 1 [0000 − 0003 − 0455 − 3799] , Tim Hamann 2 [0000 − 0003 − 3562 − 6882] , Jens Barth 2 [0000 − 0003 − 3967 − 9578] , P eter Kämpf 2 , and Björn Esk ofier 1 , 3 , 4 , 5 [0000 − 0002 − 0417 − 0336] 1 F riedric h-Alexander-Universität Erlangen-Nürn b erg, Erlangen, Germany 2 ST ABILO International Gm bH, Heroldsb erg, German y 3 Ludwig-Maximilians-Univ ersität Münc hen, Munich, German y 4 Munic h Cen ter for Mac hine Learning, Munic h, Germany 5 Helmholtz Zen trum München - German Researc h Center for Environmen tal Health, Neuherb erg, Germany Abstract. Inertial measuremen t unit-based online handwriting recog- nition enables the recognition of input signals collected across differ- en t writing surfaces but remains c hallenged by unev en c haracter dis- tributions and in ter-writer v ariability . In this work, w e systematically in vestigate t wo strategies to address these issues: sub-word tok eniza- tion and concatenation-based data augmentation. Our exp erimen ts on the OnHW-W ords500 dataset rev eal a clear dic hotomy betw een han- dling in ter-writer and intra-writer v ariance. On the writer-indep enden t split, structural abstraction via Bigram tokenization significan tly im- pro ves p erformance to unseen writing styles, reducing the word error rate (WER) from 15.40% to 12.99%. In con trast, on the writer-dependent split, tok enization degrades p erform ance due to v o cabulary distribu- tion shifts b et w een the training and v alidation sets. Instead, our pro- p osed concatenation-based data augmen tation acts as a p o werful reg- ularizer, reducing the character error rate by 34.5% and the WER b y 25.4%. F urther analysis shows that short, low-lev el tokens b enefit model p erformance and that concatenation-based data augmentation perfor- mance gain surpasses those achiev ed b y prop ortionally extended train- ing. These findings rev eal a clear v ariance-dep enden t effect: sub-word tok enization primarily mitigates in ter-writer st ylistic v ariability , whereas concatenation-based data augmen tation effectiv ely comp e nsates for intra- writer distributional sparsity . Co de is av ailable at: https://anon ymous. 4op en.science/r/TV A- OnHWR/ . Keyw ords: Online Handwriting Recognition · Time-Series Analysis · T ok enization · Data Augmentation 2 J. Li et al. 1 In tro duction Online Handwriting Recognition (OnHWR) has long b een a cornerstone of nat- ural user in terfaces. It enables the digitization of human language through the analysis of temporal stroke tra jectories [7,3]. Unlik e offline recognition, whic h pro cesses static images of completed text, OnHWR leverages the dynamic se- quence of writing to deco de in tent. Inertial Measuremen t Unit (IMU)-based metho ds extend this capability beyond touc hscreens by emplo ying wearable sen- sors to capture motion in un tethered environmen ts [21,15]. Ho wev er, robust implemen tation faces t wo main c hallenges: unev en c haracter distribution and high v ariabilit y in writing styles. In natural languages, character frequency v aries significantly . F or example, v ow els typically app ear more often than consonants [20]. This skew ed distribution limits the samples av ailable for rare characters and leads to p oor generalization. F urthermore, individual writ- ing st yles differ among users. The same shap e can be interpreted as differen t c haracters dep ending on the writer [8,2]. Consequen tly , training a mo del that generalizes w ell across diverse writing styles remains a difficult task. T o address these challenges, data augmen tation and tok enization are em- plo yed to enhance mo del stability and generalization. Data augmentation syn- thetically expands the training set and artificially balances the data distribution. By generating v ariations of infrequent c haracters through geometric transforma- tions [1] or generative mo deling [14], this strategy helps the classifier learn the in v ariant features of rare characters despite their natural scarcity . Simultane- ously , applying tokenization to text lab els shifts the learning ob jective from raw c haracter classification to a more flexible linguistic mapping. This approach mit- igates the impact of style v ariations by allowing the netw ork to learn a robust represen tation of the underlying language structure. It reduces dep endence on individual character features and effectively decouples motion recognition from the constrain ts of a fixed character set [17]. While tokenization is highly effective in natural language pro cessing, its applicabilit y to IMU-based OnHWR is un- clear, as linguistic co-o ccurrence statistics may not align with kinematic strok e con tinuit y . This raises the question whether sub-word abstraction aids or impairs generalization under differen t v ariance regimes. In this work, we systematically inv estigate the distinct roles of sub-word tok- enization and concatenation-based data augmentation in mitigating inter-writer and in tra-writer v ariance for IMU-based OnHWR. T o this end, our primary con tributions and insights are as follows: – W e systematically assess sub-w ord tok enization metho ds (Bigram, Byte-Pair Enco ding (BPE), and Unigram) for text lab els. W e demonstrate that struc- tural abstraction via Bigram tok enization effectively mitigates in ter-writer st ylistic v ariabilit y , reducing the W ord Error Rate (WER) b y 15.65% (from 15.40% to 12.99%) on the W riter-Indep enden t (WI) split using a v o cabulary size of 500. – W e propose a concatenation-based data augmen tation metho d tailored for IMU time-series data. W e sho w that it acts as a pow erful regularizer to T ok enization vs. Augmen tation 3 alleviate in tra-writer data sparsity . On the W riter-Dep enden t (WD) split, this approach reduces the Character Error Rate (CER) b y 34.5% and the WER b y 25.4%. W e establish a clear empirical dichotom y for generalization in OnHWR. Our findings prov e that scenarios with diverse writers require structural abstraction to manage st yle v ariabilit y , whereas p ersonalized, single-writer recognition relies on data synthesis (concatenation) to o vercome the scarcity of rare c haracter samples. 2 Related W orks 2.1 IMU-Based OnHWR The field of IMU-based handwriting recognition has shifted from engineered features to deep representation learning. Early methods relied on sensor fu- sion and complementary filters for tra jectory reconstruction, utilizing Dynamic Time W arping [5] or Hidden Marko v Mo dels [4] for temp oral alignmen t. How- ev er, these statistical mo dels were sensitive to sensor noise and st ylistic v ariabil- it y . T o address these limitations, contemporary approaches leverage end-to-end deep learning. By com bining Conv olutional Neural Netw orks (CNNs) and Long Short-T erm Memory (LSTM) netw orks with Connectionist T emp oral Classifi- cation (CTC) loss, mo dern systems map unsegmented raw sensor data directly to text sequences [21,15]. Recent w ork has fo cused on computational efficiency , prop osing light weigh t arc hitectures that main tain accuracy while reducing re- source demands [11]. 2.2 T okenization for OnHWR While tok enization is standard in natural language pro cessing [16,18,10], it is rarely applied directly to OnHWR. Previous studies hav e either tokenized input signals [19] or used token-based language mo dels to assist recognition [13]. How- ev er, recognizing multi-c haracter tokens offers distinct adv antages. In natural language, sp ecific characters frequently app ear together, and cursive writing of- ten connects multiple c haracters in a single stroke. T okenization enables OnHWR mo dels to learn these frequen t combinations, whic h improv es p erformance on complex handwriting st yles. 2.3 Data Augmentation for OnHWR Data augmen tation is an effective strategy for impro ving generalization when training with limited data. V arious approaches hav e b een introduced for hand- writing recognition. F or example, [1] used elastic distortions and affine trans- formations to enhance the robustness of CNN-LSTM architectures. Similarly , [22] prop osed a stroke-based metho d utilizing morphological transformations to 4 J. Li et al. sim ulate realistic stylistic v ariations. Beyond geometric transformations, other studies employ generative models. [14] leveraged laten t diffusion mo dels to gener- ate style-conditioned handwritten text as an alternativ e to traditional metho ds. A dditionally , [6] emplo yed generativ e adv ersarial netw orks to synthesize new training samples, whic h improv ed classification accuracy for handwritten digits. Ho wev er, these approaches are often vision-based and are difficult to adapt for OnHWR. They also frequently rely on complex generators to synthesize addi- tional data. While concatenation-based data augmen tation has b een introduced in sp eec h recognition [12] to address the issue of v arying input lengths, the ef- fectiv eness of this approach for OnHWR has not b een in vestigated. 3 Metho ds W e adopt the REWI architecture [11], a robust CNN-LSTM baseline designed for IMU-based OnHWR. While we retain the core neural architecture, w e mo dify the text-to-class mapping pip eline using adv anced tokenization strategies. Addition- ally , we enhance the data pre-pro cessing stage b y implementing concatenation- based data augmen tation. 3.1 T okenization W e ev aluate the efficacy of sub-w ord mo deling b y exp erimen ting with three distinct tokenization algorithms: Bigram, BPE, and Unigram [9]. T o analyze the trade-off b et ween granularit y and sequence length, we train each tok enizer with v arying vocabulary sizes V ∈ { 100 , 200 , 300 , 400 , 500 } . T o ensure a rigorous ev aluation, tokenizers are fitted exclusively on the ground-truth text lab els of the training set for each fold. These trained tok- enizers are then used to enco de the ground-truth sequences during training and deco de the mo del’s predicted logits into text during inference. Bigram T ok enization The Bigram tokenizer constructs a vocabulary based on o ccurring pairs of adjacent characters. This approach maintains a fixed windo w size of 2, capturing lo cal context through a uniform segmentation pro cess. Byte P air Encoding T okenization BPE is an iterativ e merge-based algo- rithm. Starting with a c haracter-lev el v ocabulary , it adopts a b ottom-up ap- proac h b y iterativ ely merging the most frequent pair of adjacen t symbols. By relying on deterministic frequency coun ts, BPE forms v ariable-length tokens based strictly on observ ed statistics. Unigram T okenization Unigram [9] implements a top-do wn, probabilistic strategy , in contrast to the b ottom-up merging of BPE. The algorithm initializes with a large sup erset of p oten tial tokens and systematically prunes them based on their contribution to the global likelihoo d of the training data. By optimizing T ok enization vs. Augmen tation 5 a loss function o ver the entire vocabulary , this global approach allows for flexible segmen tation where sub-word retention is determined b y probabilistic weigh ts. 3.2 Concatenation-Based Data Augmentation W e implement a concatenation-based data augmen tation strategy to increase data v ariability and impro ve generalization. F or each sample in a batc h, we randomly select N additional samples from the same writer within the training set. W e concatenate these to the original sample and join the corresp onding text labels in the same sequence. When tok enization is activ e, w e apply it to the individual lab els prior to concatenation. Subsequently , the standard REWI prepro cessing and data augmentation pip eline is applied to the com bined data. 4 Exp erimen ts 4.1 Datasets W e utilize the right-handed subset of the OnHW-W ords500 dataset [15], which con tains 13-c hannel handwriting data collected from 53 sub jects using a sensor- enhanced p en developed by ST ABILO International Gm bH. This dataset is pro- vided with tw o distinct ev aluation proto cols: WD and WI, which represent splits b y words and by writers, resp ectiv ely , using 5-fold cross-v alidation. W e employ b oth splits to ev aluate the mo del against distribution shifts in c haracters and individual handwriting styles b et ween the training and test s ets, as illustrated in App x. A. 4.2 Implemen tation Details F ollowing the REWI setup, we train the mo del for 300 ep ochs with a batc h size of 64. The learning rate schedule consists of a 30-ep och linear w armup follow ed b y cosine annealing. W e use the A dam W optimizer with a weigh t deca y of 10 − 2 and a learning rate of 10 − 3 . The framework is implemen ted in PyT orch 2.9.1 on an NVIDIA R TX 3090 GPU with 24 GB of VRAM. W e ev aluate p erformance using CER and WER. These metrics measure errors at the character and word lev els, resp ectiv ely , by quan tifying the substitutions, deletions, and insertions required to align the predictions with the ground truth. 4.3 T okenization Analysis The ev aluation of tokenization strategies reveals a stark con trast b et w een WD and WI scenarios, as illustrated in Fig. 1. In the WD split, the primary challenge is the imbalance of character distri- bution rather than unseen writing st yles, as shown in Appx. A. Consequently , tok enizers trained solely on training lab els fail to generalize to the v alidation set, which frequently lacks sp ecific character sequences presen t in the training 6 J. Li et al. 15 20 25 30 Error Rates (%) CER on the WD Split Character Bigram Unigram 45 50 55 60 WER on the WD Split 100 200 300 400 500 7 . 5 8 8 . 5 9 #T ok ens Error Rates (%) CER on the WI Split Character Bigram BPE Unigram 100 200 300 400 500 13 14 15 16 #T ok ens WER on the WI Split Fig. 1. T ok enization Ev aluation. Performance comparison across v arying vocabu- lary sizes for differen t tok enizers. The b lac k dashed line represents the character-lev el baseline. Solid lines with blue squares, red triangles, and green circles denote the Bi- gram, BPE, and Unigram tokenizers, resp ectiv ely . Complete results are pro vided in App x. B. data. As sho wn in the top row of Fig. 1, all mo dels using tokenizers p erform significan tly worse than the c haracter-based baseline, which ac hieves a CER of 14.86% and a WER of 45.10%. While most tokenizers degrade p erformance, the BPE tokenizer fails completely . F urthermore, as the v o cabulary size increases, recognition accuracy decreases for b oth CER and WER across all tokenization metho ds. On the WI split, where the mo del must generalize to unseen writers, struc- tural abstraction through tokenization pro ves b eneficial. The Bigram tokenizer consisten tly outp erforms the character-lev el baseline on WER. As sho wn in the b ottom ro w of Fig. 1, larger vocabulary sizes generally impro ve recognition ac- curacy . With a v o cabulary size of 500 tokens, the Bigram model reduces the WER from 15.40% to 12.99%, achieving a relative improv ement of 15.65%. This suggests that learning fixed transition pairs helps the mo del stabilize predictions against the st ylistic idiosyncrasies of unknown writers. Among all tokenization approaches, Bigram tokenization is the most robust strategy for the WI split. While Unigram ev entually surpasses the character baseline at higher v o cabulary sizes ( V ≥ 400 ), reducing the WER to 13.29%, it consistently trails b ehind Bigram (12.99%). This suggests that the complex T ok enization vs. Augmen tation 7 long tok ens generated by top-down metho ds may b e less suitable for OnHWR. BPE, mean while, demonstrates severe instability , suffering a catastrophic failure at V = 500 , where the error rate explo des ( > 99% WER) and the model fails to con verge entirely on the WD split. W e attribute this collapse to agglomerative tok enization in low-data regimes: at V ≥ 500 , the BPE algorithm exhaust fre- quen t sub-words and b egins ov er-segmen ting, generating highly sp ecific and rare tok ens. This introduces severe bias during training, causing CTC loss to diverge. 4.4 Concatenation-Based Data Augmentation Analysis W e analyze the impact of concatenation-based data augmentation, as shown in Fig. 2. The res ults demonstrate that the effectiv eness of this metho d is highly con text-dep enden t. 10 15 20 25 30 Error Rates (%) CER on the WD Split Char (C0) Bigram (C0) Unigram (C0) Char (C2) Bigram (C2) Unigram (C2) 40 50 60 WER on the WD Split 100 200 300 400 500 7 8 9 10 #T ok ens Error Rates (%) CER on the WI Split Char (C0) Bigram (C0) BPE (C0) Unigram (C0) Char (C2) Bigram (C2) BPE (C2) Unigram (C2) 100 200 300 400 500 13 14 15 16 17 #T ok ens WER on the WI Split Fig. 2. Concatenation-Based Data Augmen tation Ev aluation. Performance comparison without augmentation (C0) and with tw o extra concatenations (C2) across v arying v o cabulary sizes. Dashed lines represent character-lev el baselines, where gray indicates no augmentation and black indicates augmented data. Solid lines with square, triangle, and circle markers denote the Bigram, BPE, and Unigram tokenizers, resp ec- tiv ely . Lighter, semi-transparen t colors represent mo dels without augmentation (C0), whereas darker, opaque colors indicate mo dels with augmen tation (C2). Complete re- sults are provided in App x. B. 8 J. Li et al. On the WD split, concatenation-based data augmentation acts as a p o w erful regularizer. As shown in the top row of Fig. 2, applying tw o concatenations (C2) to the character-lev el mo del drastically reduces the CER from 14.86% to 10.04% and the WER from 45.10% to 34.52%. Although the results with tok enizers re- main worse than the baseline, they improv e compared to the non-augmen ted v ersions. F or instance, the Bigram mo del’s CER drops from the 22–25% range (C0) to 13–21% (C2), and the WER decreases from 49–54% to 41–51%. Notably , when tokenizers are applied, the b enefit of concatenation-based data augmenta- tion diminishes as the v o cabulary size increases. Con versely , on the WI split, concatenation-based data augmen tation yields negligible or slightly negativ e effects. As seen in the b ottom row of Fig. 2, the Character (C2) curv e closely mirrors the baseline (C0), while Bigram (C2) p er- forms worse than Bigram (C0) across most v o cabulary sizes. This suggests that concatenation-based data augmentation cannot effectively address the challenge of writing st yle v ariation in OnHWR. 4.5 T oken Usage Analysis T o explain the observ ations regarding tokenization stabilit y and the v arying impact of concatenation-based data augmen tation, we ev aluate the tok en usage statistics presen ted in T able 1. T able 1. T ok en Usage Analysis. Distribution of token usage standard deviation on the v alidation set on the first fold across splits, tokenizers (with a vocabulary size of 200) and augmentation settings ( ✓ indicates concatenation with tw o additional samples). Split T ok enizer Concat T ok en Usage p er Size (%) 1 2 3 4 5+ WD Bigram 42.98 57.02 — — — ✓ 43.12 56.88 — — — BPE 47.58 33.80 13.82 3.50 1.30 ✓ 49.42 32.22 13.95 3.19 1.21 Unigram 51.43 23.39 12.67 8.59 3.93 ✓ 53.10 22.85 12.56 7.82 3.68 WI Bigram 39.91 60.09 — — — ✓ 40.44 59.56 — — — BPE 47.85 33.64 13.70 4.06 0.76 ✓ 48.12 33.44 13.61 4.11 0.71 Unigram 55.79 23.28 11.44 5.37 4.12 ✓ 56.40 23.08 11.41 5.21 3.90 In the absence of concatenation-based data augmentation, the Bigram tok- enizer exhibits significantly low er single-character usage (42.98%) compared to BPE (47.58%) and Unigram (51.43%). Given that the maximum length of Bi- gram tok ens is strictly limited to 2, this preference suggests that the model T ok enization vs. Augmen tation 9 fa vors the consistent, simple structure of short tokens ov er v ariable-length and p oten tially complex tok ens. A dditionally , the Unigram tok enizer relies more on single-c haracter tok ens than BPE across all settings. Although Unigram is a top-down metho d capable of generating long, complex tokens, this high fallback rate implies greater fle xibilit y . This mechanism likely explains why Unigram p erforms b etter and more stably than the b ottom-up BPE approach; it can revert to character-lev el recognition when confidence in complex tokens is low, thereby av oiding the ov erfitting issues observ ed with BPE. The in tro duction of concatenation consisten tly encourages the usage of single- c haracter tokens across all models. This shift elucidates the divergen t impact of concatenation-based data augmentation. On the WD split, where c haracter distribution shifts o ccur, relying on robust character-lev el recognition is adv an- tageous, leading to p erformance gains. Conv ersely , on the WI split, where distri- butions are matched, reverting to single characters causes the mo del to lose the b enefit of learned structural information, resulting in p erformance degradation. 4.6 Sequence Length Analysis Previous exp erimen ts demonstrate that concatenation-based metho ds signifi- can tly impro ve p erformance, particularly for c haracter-level recognition. Ho w- ev er, since concatenation results in longer input sequences, the observ ed gains migh t b e attributed to the increased training duration asso ciated with pro cess- ing more c haracters p er ep och. T o isolate the effect of sequence length, w e com- pare p erformance across different num b ers of concatenated sequences against c haracter-equiv alent extended training ep ochs in T able 2. T able 2. Concatenation Length Analysis. This table compares the p erformance of adding extra samples via concatenation-based data augmentation (#Concat) against simply extending the training duration by a corresp onding n umber of epo c hs (#Ep och). A v alue of 0 for #Concat indicates that no augmen tation was applied. #Concat #Ep och CER (%) WER (%) Baseline 0 300 14.86 45.10 0 2 × 13.86 42.03 1 1 × 11.44 38.65 0 3 × 13.26 40.57 2 1 × 10.04 34.52 0 4 × 12.90 39.59 3 1 × 9.73 33.63 0 5 × 12.90 39.08 4 1 × 9.97 34.70 10 J. Li et al. The results confirm that sequence length is the decisive factor. While ex- tending the training duration of the baseline (e.g., 3 × ep ochs) reduces the WER to 40.57%, utilizing 2 concatenations (with 1 × ep och) achiev es a significantly lo wer WER of 34.52% with equiv alent data throughput. The optimal configura- tion is achiev ed with 3 concatenations, which reduces the CER by 34.5% and the WER by 25.4% compared to the baseline. This significan tly outperforms purely extended training strategies. 5 Conclusion & Outlo ok In this study , we in vestigated the distinct roles of sub-word tok enization and concatenation-based data augmen tation in addressing the challenges of IMU- based online handwriting recognition. Our results establish a clear dichotom y for mo del generalization: the optimal strategy dep ends entirely on whether the system is tackling st yle v ariation betw een different users or data sparsit y within a single user’s profile. Structural abstraction via Bigram tokenization pro ved to b e the most effec- tiv e metho d for managing inter-writer v ariance on the WI split. In contrast, on the WD scenarios where the main hurdle is an imbalanced character distribu- tion, our prop osed concatenation-based augmentation acted as a p o werful regu- larizer. Although these tec hniques exhibit contrasting p erformance profiles, b oth offer highly v aluable applications. When dealing with imbalanced datasets where mo dels struggle to generalize to unseen v o cabularies, concatenation-based data augmen tation effectively mitigates skew ed c haracter distributions. Con versely , when deploying system s across a diverse user base, sub-word tok enization enables the mo del to abstract stylistic v ariations and recognize c hallenging handwriting robustly without requiring user-sp ecific fine-tuning. Ho wev er, there remains significant ro om for impro vemen t and exploration. The tokenization strategies ev aluated in this w ork (Bigram, BPE, Unigram) are fundamen tally derived from natural language statistics. They do not explicitly accoun t for the kinematic or temp oral realities of handwriting. Developing a handwriting-a ware tokenizer that merges characters based on con tinuous stroke tra jectories or sensor-signal transition frequencies rather than mere linguistic co- o ccurrence—could yield more representativ e tokens and further enhance recog- nition accuracy . Moreov er, our ev aluation is currently constrained to a relatively small-scale dataset ( ≈ 50 sub jects and 500 words). In this controlled en vironment, the character and writing style distribution shifts represen ted by the WD and WI splits resp ectiv ely are highly isolated. The joint contribution and p oten tial synergies of sim ultaneous tokenization and concatenation-based data augmenta- tion on a larger, unconstrained dataset with b oth high vocabulary diversit y and high writer v ariance hav e yet to b e thoroughly ev aluated. T ok enization vs. Augmen tation 11 A Visualization of Character Distribution As demonstrated in Fig. 3, the character distributions of the WD and WI splits in the OnHWR-W ords500 dataset differ significantly . A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z Ä Ö Ü ß ä ö ü Characters 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 P er centages Character Distribution train validation A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z Ä Ö Ü ß ä ö ü Characters 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 P er centages Character Distribution train validation Fig. 3. Character distribution of the right-handed OnHW W ords500 dataset. The upp er and low er plots show the character distributions for the first fold of the WD and WI splits, resp ectiv ely . Blue bars represent character frequencies in the training sets, while orange bars represen t frequencies in the v alidation sets. In the WI split (low er), the distributions b et ween the training and v alidation sets matc h almost perfectly . F urthermore, each character is represented by at least a few data samples in b oth sets. In con trast, the distributions for the WD split (upp er) v ary greatly b et w een the training and v alidation sets. Certain c haracters, such as “q” and “ä”, do not app ear in the v alidation set at all. 12 J. Li et al. B Complete Results T able 3. Results of different tokenizers and num bers of tokens concatenated samples. T ok enizer #T okens #Concat WD CER% WD WER(%) WI CER(%) WI WER(%) Character — 0 14.86 45.10 7.41 15.40 2 10.04 34.52 7.14 15.41 Bigram 100 0 22.36 52.37 7.72 14.15 2 13.91 41.18 7.56 14.47 200 0 24.77 53.48 7.48 13.33 2 18.60 46.97 7.86 14.14 300 0 24.39 52.66 7.36 13.27 2 20.62 49.86 7.91 14.26 400 0 23.46 51.85 7.30 13.01 2 20.95 50.27 9.08 16.73 500 0 22.44 49.67 7.20 12.99 2 20.15 49.44 7.83 14.43 BPE 100 0 64.86 100.00 7.64 13.97 2 66.23 100.00 7.57 14.57 200 0 59.86 100.00 7.97 13.48 2 62.38 100.00 7.73 13.70 300 0 59.06 100.00 7.95 13.45 2 61.40 100.00 8.66 14.54 400 0 58.97 100.00 8.08 13.57 2 61.91 100.00 10.31 17.30 500 0 59.43 100.00 45.34 99.81 2 61.13 100.00 53.12 100.00 Unigram 100 0 20.37 51.57 8.02 15.16 2 13.67 39.86 7.73 14.81 200 0 26.90 56.83 8.71 14.99 2 19.78 47.95 7.95 14.46 300 0 28.10 57.42 8.46 14.16 2 24.87 54.76 8.18 14.31 400 0 27.94 55.98 8.22 13.47 2 26.96 57.57 9.04 15.37 500 0 28.22 56.95 7.90 13.29 2 28.50 59.08 9.15 15.67 T ok enization vs. Augmen tation 13 References 1. A yy o ob, M.P ., Muhamed Ily as, P .: Strok e-based data augmen tation for enhanc- ing optical character recognition of ancient handwritten scripts. IEEE Access 12 , 186794–186802 (2024). https://doi.org/10.1109/A CCESS.2024.3505238 2. Bh unia, A.K., Ghose, S., Kumar, A., Chowdh ury , P .N., Sain, A., Song, Y.Z.: Metah tr: T ow ards writer-adaptive handwritten text recognition. In: 2021 IEEE/CVF Conference on Computer Vision and P attern Recognition (CVPR). pp. 15825–15834 (2021). https://doi.org/10.1109/CVPR46437.2021.01557 3. Carbune, V., Gonnet, P ., Deselaers, T., Ro wley , H.A., Daryin, A., Calvo, M., W ang, L.L., Keysers, D., F euz, S., Gerv ais, P .: F ast multi-language lstm-based online hand- writing recognition. Int. J. Doc. Anal. Recognit. 23 (2), 89–102 (Jun 2020). https:// doi.org/10.1007/s10032- 020- 00350- 4 , h ttps://doi.org/10.1007/s10032- 020- 00350- 4 4. Choi, S.d., Lee, A.S., Lee, S.y .: On-line handwritten character recognition with 3d accelerometer. In: 2006 IEEE International Conference on Information Acquisition. pp. 845–850 (2006). https://doi.org/10.1109/ICIA.2006.305842 5. Hsu, Y.L., Chu, C.L., T sai, Y.J., W ang, J.S.: An inertial p en with dynamic time w arping recognizer for handwriting and gesture recognition. IEEE Sensors Journ a l 15 (1), 154–163 (2015). https://doi.org/10.1109/JSEN.2014.2339843 6. Jha, G., Cecotti, H.: Data augmen tation for handwritten digit recognition us- ing generativ e adv ersarial netw orks. Multimedia T o ols Appl. 79 (47-48), 35055– 35068 (Dec 2020). h ttps://doi.org/10.1007/s11042- 020- 08883- w , https://doi.org/ 10.1007/s11042- 020- 08883- w 7. Keysers, D., Deselaers, T., Rowley , H.A., W ang, L.L., Carbune, V.: Multi-language online handwriting recognition. IEEE T ransactions on Pattern Analysis and Ma- c hine Intelligence 39 (6), 1180–1194 (2017). https://doi.org/10.1109/TP AMI.2016. 2572693 8. K ohút, J., Hradiš, M., Kišš, M.: T ow ards writing style adaptation in handwriting recognition. In: Fink, G.A., Jain, R., Kise, K., Zanibbi, R. (eds.) Do cumen t Anal- ysis and Recognition - ICDAR 2023. pp. 377–394. Springer Nature Switzerland, Cham (2023) 9. Kudo, T.: Subw ord regularization: Improving neural net work translation mo dels with m ultiple sub w ord candidates. In: Gurevyc h, I., Miy ao, Y. (eds.) Pro ceed- ings of the 56th Ann ual Meeting of the Asso ciation for Computational Linguis- tics (V olume 1: Long Papers). pp. 66–75. Association for Computational Lin- guistics, Melb ourne, Australia (Jul 2018). https://doi.org/10.18653/v1/P18- 1007 , h ttps://aclanthology .org/P18- 1007/ 10. Kudo, T., Richardson, J.: SentencePiece: A simple and language indep enden t sub- w ord tokenizer and detok enizer for neural text processing. In: Blanco, E., Lu, W. (eds.) Pro ceedings of the 2018 Conference on Empirical Metho ds in Natural Language Pro cessing: System Demonstrations. pp. 66–71. Asso ciation for Compu- tational Linguistics, Brussels, Belgium (Nov 2018). https://doi.org/10.18653/v1/ D18- 2012 , https://aclan thology .org/D18- 2012/ 11. Li, J., Hamann, T., Barth, J., Kämpf, P ., Zanca, D., Esk ofier, B.: Robust and efficien t writer-indep enden t imu-based handwriting recognition. In: Durmaz Incel, Ö., Qin, J., Bieb er, G., Kuijp er, A. (eds.) Sensor-Based Activit y Recognition and Artificial Intelligence. pp. 261–286. Springer Nature Switzerland, Cham (2026) 12. Lin, Y., Han, T., Xu, H., Pham, V., Khassanov, Y., Chong, T., He, Y., Lu, L., Ma, Z.: Random utterance concatenation based data augmen tation for improving 14 J. Li et al. short-video sp eec h recognition. Pro ceedings of the Annual Conference of the In- ternational Sp eec h Communication Asso ciation, INTERSPEECH 2023-August , 904–908 (2023). https://doi.org/10.21437/In tersp eec h.2023- 1272 , publisher Copy- righ t: © 2023 In ternational Speech Comm unication Association. All rights re- serv ed.; 24th International Speech Communication Asso ciation, In tersp eec h 2023 ; Conference date: 20-08-2023 Through 24-08-2023 13. Marti, U.V., Bunke, H.: On the influence of vocabulary size and language mo dels in unconstrained handwritten text recognition. In: Pro ceedings of Sixth International Conference on Document Analysis and Recognition. pp. 260–265 (2001). h ttps: //doi.org/10.1109/ICD AR.2001.953795 14. Nik olaidou, K., Retsinas, G., Christlein, V., Seuret, M., Sfik as, G., Smith, E.B., Mok a yed, H., Liwicki, M.: W ordstylist: St yled verbatim handwritten text genera- tion with latent diffusion mo dels. In: Fink, G.A., Jain, R., Kise, K., Zanibbi, R. (eds.) Document Analysis and Recognition - ICDAR 2023. pp. 384–401. Springer Nature Switzerland, Cham (2023) 15. Ott, F., Rügamer, D., Heublein, L., Hamann, T., Barth, J., Bisc hl, B., Mutschler, C.: Benc hmarking online sequence-to-sequence and character-based handwriting recognition from imu-enhanced pens. Int. J. Doc. Anal. Recognit. 25 (4), 385– 414 (Dec 2022). https://doi.org/10.1007/s10032- 022- 00415- 6 , https://doi.org/10. 1007/s10032- 022- 00415- 6 16. Sennric h, R., Haddow, B., Birc h, A.: Neural mac hine translation of rare words with subw ord units. In: Erk, K., Smith, N.A. (eds.) Pro ceedings of the 54th An- n ual Meeting of the Asso ciation for Computational Linguistics (V olume 1: Long P ap ers). pp. 1715–1725. Asso ciation for Computational Linguistics, Berlin, Ger- man y (Aug 2016). https://doi.org/10.18653/v1/P16- 1162 , https://aclan thology . org/P16- 1162/ 17. Singh, S., Gupta, A., Maghan, A., Gowda, D., Singh, S., Kim, C.: Comparative study of different tokenization strategies for streaming end-to-end asr. In: 2021 IEEE Automatic Sp eec h Recognition and Understanding W orkshop (ASRU). pp. 388–394 (2021). https://doi.org/10.1109/ASR U51503.2021.9687921 18. Song, X., Salcianu, A., Song, Y., Dopson, D., Zh o u, D.: F ast W ordPiece tokeniza- tion. In: Mo ens, M.F., Huang, X., Sp ecia, L., Yih, S.W.t. (eds.) Pro ceedings of the 2021 Conference on Empirical Metho ds in Natural Language Pro cessing. pp. 2089– 2103. Association for Computational Linguistics, Online and Pun ta Cana, Do- minican Republic (Nov 2021). https://doi.org/10.18653/v1/2021.emnlp- main.160 , h ttps://aclanthology .org/2021.emnlp- main.160/ 19. Sw aileh, W., P aquet, T., Soullard, Y., T ranouez, P .: Handwriting recognition with m ultigrams. In: 2017 14th IAPR International Conference on Do cumen t Analysis and Recognition (ICDAR). vol. 01, pp. 137–142 (2017). https://doi.org/10.1109/ ICD AR.2017.31 20. T ran Tien, H., Ngo, T.D.: Unsup ervised domain adaptation with imbalanced char- acter distribution for scene text recognition. In: 2023 IEEE International Confer- ence on Image Pro cessing (ICIP). pp. 3493–3497 (2023). https://doi.org/10.1109/ ICIP49359.2023.10222310 21. W eh bi, M., Hamann, T., Barth, J., Kaempf, P ., Zanca, D., Esk ofier, B.: T ow ards an imu-based pen online handwriting recognizer. In: Lladós, J., Lopresti, D., Uc hida, S. (eds.) Do cumen t Analysis and Recognition – ICD AR 2021. pp. 289– 303. Springer In ternational Publishing, Cham (2021). https://doi.org/10.1007/ 978- 3- 030- 86334- 0_19 T ok enization vs. Augmen tation 15 22. Wigington, C., Stewart, S., Davis, B., Barrett, B., Price, B., Cohen, S.: Data aug- men tation for recognition of handwritten words and lines using a cnn-lstm netw ork. In: 2017 14th IAPR International Conference on Do cumen t Analysis and Recogni- tion (ICDAR). vol. 01, pp. 639–645 (2017). https://doi.org/10.1109/ICD AR.2017. 110
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment