학습 데이터 품질 저하가 분류기 성능에 미치는 영향 분석
본 연구는 메타게놈 조립을 위한 짧은 DNA 리드 데이터를 대상으로, 학습 데이터의 품질을 단계적으로 저하시키면서 베이즈, 신경망, 파티션 모델, 랜덤 포레스트 네 가지 분류기의 정확도, 경계 상태, 이웃 유사도 및 분류기 간 일치도를 평가한다. 품질이 낮아질수록 모든 분류기가 ‘우연히 맞는’ 상황으로 전환되는 붕괴 현상이 관찰되며, 데이터와 분석 대상 사이의 거리 증가가 경계 희소화와 일치도 상승을 초래한다는 공간적 이질성 패턴을 제시한다.
저자: Alan F. Karr, Regina Ruane
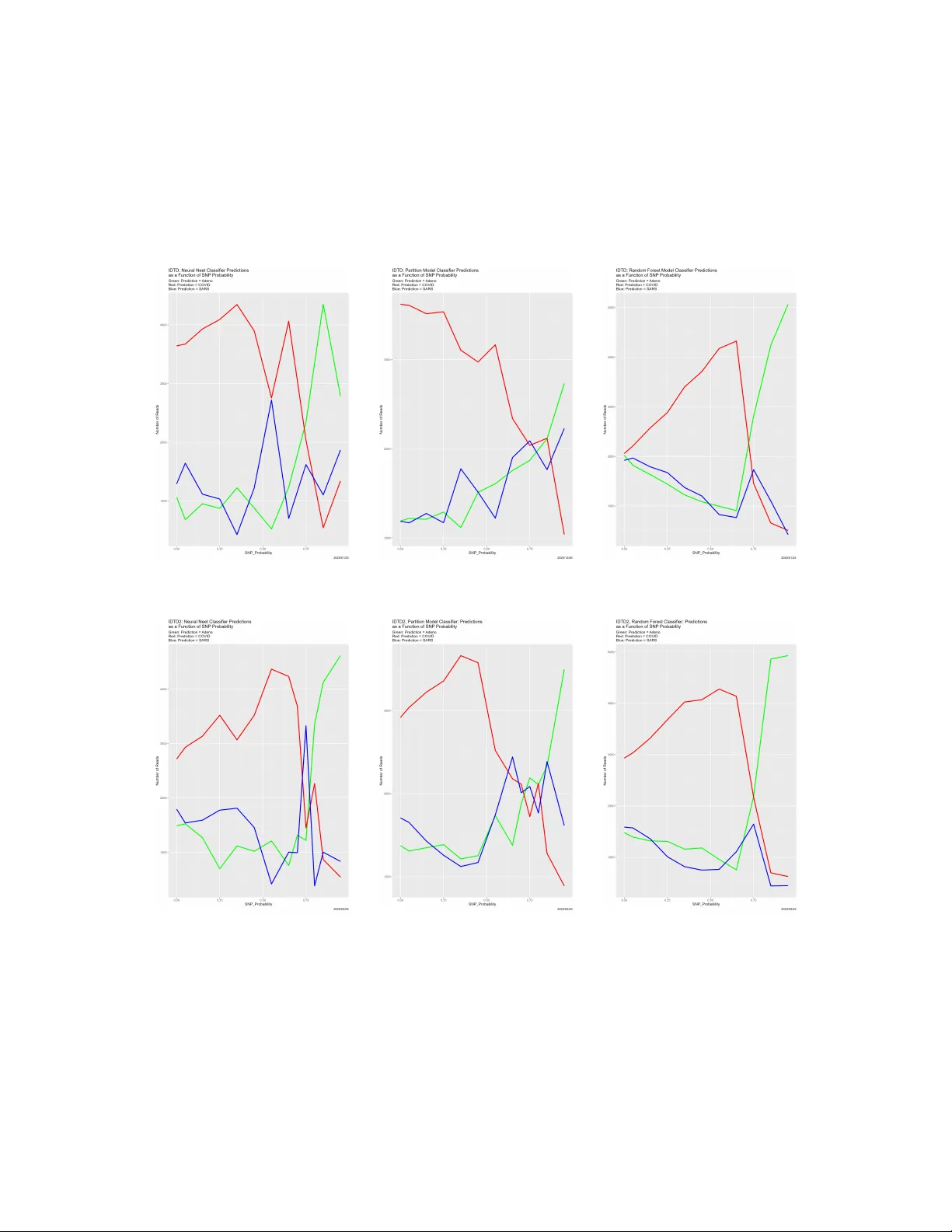
본 논문은 메타게놈 조립을 위한 짧은 DNA 리드(길이 101)의 분류 문제를 실험적 플랫폼으로 삼아, 학습 데이터 품질이 분류기 성능에 미치는 영향을 정량적으로 분석한다. 연구자는 5,869개의 시뮬레이션 리드(아데노바이러스, SARS‑CoV‑2, SARS‑CoV)로 구성된 ‘원본’ 학습 데이터 집합 T와, 동일한 조건으로 생성된 검증 데이터 V(각 2,000리드)를 사용한다. 네 가지 대표적인 지도 학습 모델—베이즈 분류기, 신경망, 파티션 모델(회귀 트리), 랜덤 포레스트—를 선택하고, 각 모델을 동일한 입력 특성(삼중체 분포)으로 학습시킨다.
**학습 데이터 품질 저하 방법**은 주로 SNP 변이 확률을 조정하는 방식이며, Karr et al. (2022)에서 제시된 ‘Mason_variator’ 시뮬레이터를 이용해 단계별로 변이를 삽입한다. 각 단계마다 변이 확률을 증가시켜 데이터 품질을 점진적으로 낮추고, 그때마다 네 모델을 재학습한다.
**평가 지표**는 전통적인 정확도 외에 두 가지 새로운 메트릭을 도입한다. 첫째, Boundary Status(BS)는 입력점 x의 이웃 N(x) 중 현재 클래스와 다른 클래스를 가진 이웃의 종류 수를 셈으로써 경계에 위치한 정도를 정량화한다. BS=0이면 완전한 내부점, BS=|O|‑1이면 이웃이 모두 다른 클래스로 구성된 극단적 경계점이다. 둘째, Neighbor Similarity(NS)는 입력점과 이웃들의 결정 분포 간 헬링거 거리 H를 이용해 1‑H 형태로 정의한다. NS=1이면 모든 이웃이 동일 클래스, NS=0이면 이웃 하나라도 다른 클래스로 바뀌면 불확실성이 최대가 된다.
**실험 결과**는 다음과 같이 요약된다.
1. **정확도 변화**: 원본 품질에서는 랜덤 포레스트가 91.78%로 가장 높은 정확도를 보였으며, 베이즈(81.58%), 신경망(76.20%), 파티션 모델(75.81%) 순이었다. 품질이 저하될수록 모든 모델의 정확도는 서서히 감소했으며, 변이 확률이 특정 임계값을 초과하면 급격히 30%대(무작위 추측 수준)로 붕괴했다. 베이즈와 랜덤 포레스트는 초기 저항성이 강했지만, 충분히 높은 변이에서는 다른 모델과 동일한 붕괴 패턴을 보였다.
2. **Boundary Status**: 저품질 단계에서는 BS가 0에 가까운 입력이 늘어나 경계가 희박해졌다. 이는 대부분의 입력이 동일 클래스에 몰려 경계가 얇아짐을 의미한다. 반대로 고품질에서는 다중 클래스가 섞여 BS가 높은 입력이 많이 나타났다.
3. **Neighbor Similarity**: NS 값은 전반적으로 저품질일수록 낮아졌지만, 변이 확률이 매우 높아지는 구간에서는 오히려 NS가 상승하는 현상이 관찰되었다. 이는 모든 입력이 동일(하지만 잘못된) 클래스로 할당되어 이웃 간 일관성이 높아지는 ‘확신하지만 오류’ 상황을 드러낸다.
4. **분류기 일치도(콘그루언스)**: 각 변이 단계마다 네 모델 간 예측이 얼마나 일치하는지를 측정한 결과, 초기 저품질에서는 일치도가 서서히 감소하다가 급격히 최소값에 도달한다. 이후 변이가 극단에 이르면 모든 모델이 동일한 오류 패턴을 보이며 일치도가 다시 상승한다. 이는 ‘공동 오류’가 발생하는 메커니즘을 시사한다.
5. **공간적 이질성**: 데이터와 분석 대상 사이의 ‘거리’(품질 차이)가 커질수록 경계가 희박해지고, 동시에 일치도가 증가한다. 이는 메타게놈 조립 단계에서 참조 데이터와 실제 시료 간 차이가 클 경우, 분류기의 결정이 불안정해지는 동시에 오류가 동일하게 발생한다는 실용적 교훈을 제공한다.
**의의와 활용**: 이 연구는 학습 데이터 품질을 의도적으로 저하시켜가며, 다양한 분류기의 내구성을 비교하고, 새로운 불확실성 지표를 통해 품질‑성능 관계를 정량화한다는 점에서 학계·산업계 모두에 중요한 통찰을 제공한다. 특히, 데이터 포이즈닝 공격(악의적 품질 저하) 시나리오에 대한 취약성을 드러내어, 데이터 품질 관리와 방어 메커니즘 설계에 기여할 수 있다. 향후 연구에서는 다른 품질 저하 메커니즘(삽입·삭제·N‑base)이나 더 복잡한 메타게놈 환경(다중 바이러스 혼합)에서도 동일한 분석 프레임을 적용해볼 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기