Effects of Training Data Quality on Classifier Performance
We describe extensive numerical experiments assessing and quantifying how classifier performance depends on the quality of the training data, a frequently neglected component of the analysis of classifiers. More specifically, in the scientific cont…
Authors: Alan F. Karr, Regina Ruane
Ef fects of T raining Data Quality on Classifier Performance Alan F . Karr * Regina Ruane † February 26, 2026 Abstract W e describe extensiv e numerical experiments assessing and quantifying how classifier performance depends on the quality of the training data, a frequently neglected component of the analysis of classi- fiers. More specifically , in the scientific context of metagenomic assembly of short DN A reads into “con- tigs, ” we examine the effects of degrading the quality of the training data by multiple mechanisms, and for four classifiers—Bayes classifiers, neural nets, partition models and random forests. W e in vestigate both individual behavior and congruence among the classifiers. W e find breakdown-like behavior that holds for all four classifiers, as degradation increases and they mov e from being mostly correct to only coincidentally correct, because they are wrong in the same way . In the process, a picture of spatial het- erogeneity emer ges: as the training data mo ve f arther from analysis data, classifier decisions degenerate, the boundary becomes less dense, and congruence increases. 1 Intr oduction As articulated in Porter and Karr (2024), (supervised) classifiers should be construed as software systems with at least three components, the classifier itself, the training data on which it draws, and the analysis data to which it is applied. When diagnosing problems, all three of these components matter . In this paper , we focus on the training data, which we believe are (too) often neglected, since quality of the training data af fect performance on all analysis datasets. While there may be general acknowledgement that classifiers become less trustworthy the more the analysis data depart from the training data, there is little quantification of either “less trustworthy” or “depart from. ” T o address this neglect, we conducted and report here an extensi ve set of numerical experiments with • A single analysis dataset consisting of short DN A sequences; • F our classifiers: a Bayes classifier , a neural net, a partition model, and a random forest model; • A single parent training dataset whose quality is de graded in multiple w ays, especially , b ut not exclu- si vely , using the SNP degradation in Karr et al. (2022). * Department of Statistics, Operations and Data Science, T emple Uni versity , Philadelphia P A 19122 and Fraunhofer USA Center Mid-Atlantic, Riv erdale MD 20737; alan.karr@temple.edu † Computational Social Science Laboratory , University of Pennsylv ania, Philadelphia, P A 19104; jeanneruane@gmail.com 1 The experimental results include correctness, Boundary Status (Karr et al., 2026), congruence among the four classifiers, and Neighbor Similarity (Karr et al., 2026). It is important to understand the restriction to decreased data quality , the detailed rationale for which can be found in Karr et al. (2022). In reality , improving data quality is expensi ve and often statistically problematic. (Exceptions are imputation and editing in official statistics, for which there is strong theoretical and methodological basis.) By contrast, data quality can readily be decreased, pro vided that the mechanism is contextually credible, as it is in Karr et al. (2022). Here, we use both it and others that are equally credible. Finally , we note the important adversarial aspect of data quality degradation. While data quality prob- lems are typically conceiv ed as the result of uncontrollable but benign external forces, they may also result from actions deliberately intended to cause harm, such as attempts to “poison” genomic databases (F arbiash and Puzis, 2020; Porter and Karr, 2024). 2 Backgr ound and Problem F ormulation This section contains background on data quality , metagenomic assembly , classifiers, and classifier bound- aries. 2.1 Data Quality Attention to data quality has wax ed and waned o ver time (Karr et al., 2001, 2006; K eller et al., 2017). Giv en currently generated volumes of data, data quality effort per data element may be at an all-time low . There are exceptions, of course, especially official statistics, in which the total survey error (TSE) paradigm (Of fice of Management and Budget, 2002, 2006; Biemer et al., 2017; Karr, 2017) has perpetuated and to some degree codified longstanding attention to data quality . Other than data v olume, perhaps the most pressing issues are inability to quantify data quality at any lev el, from the data point to the dataset, and properly to incorporate data quality as a source of uncertainty in statistical analyses. Initial inv estigations in Karr et al. (2022) exploit the ease with which we can decrease (synonymously , “degrade”) data quality in ways that both are plausible scientifically and can be parameterized. This setting appears in Section 4.1. The effects of deliberately decreasing data quality can also be used to characterize and ev en quantify the quality of individual data points. Across a range of scientific settings, higher quality data points are more “fragile, ” and are af fected more by the same amount of degradation than low quality data points. This is illustrated graphically in Figure 1. There, 26,964 virus genomes are degraded by successi ve applications of the Mason_variator haplotype generation software (Holtgrewe, 2010). In the figure, there are 26,943 coronavirus genomes in green, pre viously degraded versions of 10 of these in red, and one adenovirus genome in blue. (F or reference, the parents of the 10 degraded genomes in red are in yellow .) The x -axis is the number of iterations of the Mason_variator . The y -axis is entropy , with the interpretation that higher v alues mean lower quality . Evidently , there are “decreasing returns to scale” from increased de gradation. The corona virus genomes fall into se veral classes with respect to initial entropy , which is argued in Karr et al. (2023) to reflect inherent quality . The ten previously degraded genomes be gin with the lo west quality (highest entropy) and are barely af fected by further degradation. This is the heart of our contention that “the higher the quality , the greater the vulnerability to degradation. ” 2 Figure 1: Ef fect of SNP degradation (Karr et al., 2022) on the entropy of 26964 virus genomes. 2.2 Scientific Context As in Karr et al. (2022) and Karr et al. (2026), the scientific problem underlying this paper is to clas- sify short (in our case, length 101) DN A sequences as having arisen from one of three candidate virus genomes. The broader context is reference-guided metagenomic assembly —piecing together fragments (reads) of DN A from multiple potential sources into longer sequences called contigs, as performed, for ex- ample, by MetaCompass (Cepeda et al., 2017; Pop, 2024), with the assistance of a (reference) database of sequenced candidate genomes. The role of the reference database is to reduce the computational burden of creating the contigs, which is formulated as finding an Eulerian path in a de Bruijn graph (Compeau et al., 2023). The medical setting inv olved samples from human digesti ve and reproducti ve tracts (Porter and Karr, 2024). 2.3 Classifiers In this paper , a classifier is a function C from a finite input space I to a finite output space O . Elements of I are inputs or data , and C ( x ) ∈ O is the decision or result for input x . Although it is not a logical necessity , almost always |I | >> |O | , where |S | is the cardinality of the set S . Follo wing Karr et al. (2026), we assume that the input space I is an loopless, undir ected graph , whose edgeset E defines neighboring inputs: x, y ∈ I are neighbors if and only x = y and { x, y } ∈ E . W e denote by N ( x ) = { y : { x, y } ∈ E } the set of neighbors, or neighborhood, of x . For ease of interpretation, we further assume that I is connected : for any x, y ∈ I , there is a path ( x 1 = x, . . . , x k = y ) that connects them: { x j , x j +1 } ∈ E for each j . In this paper, I consists of all Next Generation Sequencers (NGS)-generated DNA sequences of length 101. W ith fiv e possible values for each nucleotide (see belo w for an explanation of the fifth value), |I | = 5 101 . With three candidate genomes, |O | = 3 . Neighboring reads differ in exactly one of 101 bases, which is kno wn as a single nucleotide polymorphism (SNP). 3 2.4 Classifier Boundaries The boundary B associated with C is the set of elements of I at least one of whose neighbors is classified dif ferently: B C = { x ∈ I : C ( x ′ ) = C ( x ) for some x ′ ∈ N ( x ) } . (1) For DNA reads, this means that there are points differing at only one base that are classified differently . Crucially , whenev er two inputs are classified differently , any path in I connecting them must contain at least two (neighboring) boundary points. Belo w we focus on Hamming paths , which are the shortest. Giv en reads R = R ′ with Hamming distance k (They differ in k locations.), a Hamming path from R to R ′ replaces one differing nucleotide in R at a time by the corresponding nucleotide in R ′ . Therefore, each successi ve pair on the path are neighbors. Such a path R 0 = R , . . . , R k = R ′ has length k + 1 ; there are k ! of them. The “simplest” of these paths simply mov es left to right in the character strings. Because C ( R ) = C ( R ′ ) , there is at least one v alue of j for which C ( R j ) = C ( R j +1 ) , in which case, the neighbors R j and R j +1 both belong to B C . 2.5 Surrogate Uncertainty Measur es The boundary engenders tw o measures of uncertainty that are applicable to any classifier whose input space is a graph Karr et al. (2026). For x ∈ I , both are functions of the distribution on O of { C ( x ′ ) : x ′ ∈ N ( x ) } . W e define them in generality . The Boundary Status , of x ∈ I is the number of points in O other than that assigned to x itself appearing among the decisions for its neighbors: BS C ( x ) = X z ∈O ,z = C ( x ) 1 z ∈ { C ( x ′ ) : x ′ ∈ N ( x ) } , (2) where 1( · ) is an indicator function, equal to one if its argument is true and zero otherwise. In particular , BS C ( x ) = 0 means that all neighbors are classified the same as x , i.e., x is not on the boundary . At the other extreme, BS C ( x ) = |O | − 1 means that all of the other possible decisions appear among the neighbors. Note that BS C ( x ) does not depend on whether C ( x ) ∈ { C ( x ′ ) : x ′ ∈ N ( x ) } . The second measure, Neighbor Similarity , quantifies the extent to which the neighbors of a point have the same decision it does. The Neighbor Similarity for an input point x is NS C ( x ) = 1 − H ( q x , q N ( x ) ) , (3) where H denotes Hellinger distance (Nikulin, 2001), q x is the degenerate probability distribution on O concentrated on C ( x ) , and q N ( x ) is the probability distribution on O of { C ( x ′ ) : x ′ ∈ N ( x ) } . Therefore, B C = { x ∈ I : NS C ( x ) < 1 } . (4) Unlike BS C , NS C takes account only of how many neighbors dif fer , not their values. Our principal proposed interpretation of NS C ( x ) is as uncertainty regarding the classification of x . If NS C ( x ) = 1 , all neighbors of x hav e the same decision as R , and, intuitiv ely , we would be more certain of the decision for x . At the other extreme, if NS C ( x ) were zero, moving to any neighbor of x changes the decision, in which case we would be highly uncertain about C ( x ) . In the case study in Karr et al. (2026), this does not occur: the maximum number of dif ferently classified neighbors is 393 (of 404). 4 Ho wev er—and this is important, as discussed further in Section 4, we must distinguish certainty from correctness. In some regions of I , Neighbor Similarity may be high because “ev erything” is assigned the same, but incorrect, v alue. 3 Experimental Pr otocol Here we present the protocol for our numerical experiments, 3.1 Mathematical Preliminaries T o establish notation, a DNA sequence S is a character string chosen from the nucleotide (base) alphabet { A, C, G, T } , where A is adenine, C is cytosine, G is guanine and T is thiamine. At one extreme, S may be an entire genome–for instance, a virus or a human chromosome. At another , it may be a read generated by a NGS. Giv en a sequence S , its length is | S | ; the i th base in S is S ( i ) ; and the bases from location i to location j > i are S ( i : j ) . W e focus on triplets, whose distrib utions are 64-dimensional summaries of sequences.The triplet distri- bution P 3 ( ·| S ) of a sequence S is defined as P 3 ( b 1 b 2 b 3 | S ) = Prob S ( k : k + 2) = b 1 b 2 b 3 (5) for each choice of b 1 b 2 b 3 , where b 1 , b 2 and b 3 are elements of { A, C , G, T } , and k is chosen at random from 1 , . . . , | S | − 2 . An equi valent perspecti ve is that of a second-order Mark ov chain (Karr et al., 2023). That triplets suf fice in this setting is ar gued at length in Karr et al. (2026) and Karr et al. (2023). Briefly , the Hellinger distances between the triplet distributions for the three genomes are so large (Karr et al., 2026) that the triplet distributions dif ferentiate the genomes. And, of course, triplets are fundamental biologically because they encode amino acids. Other cases appear in the literature, especially quartets, also referred to as tetranucleotides (Pride et al., 2003; T eeling et al., 2004a,b). In our experience, quartets are more burdensome computationally than triplets without being more useful. 3.2 T raining and V alidation Datasets As the “root” training dataset T for all four classifiers (Section 3.3), we use the same dataset employed in Karr et al. (2022) and Karr et al. (2026). It consists of 5869 simulated NGS reads of length 101: Adeno: 1966 reads from an adeno virus genome of length 34,125, do wnloaded with the read simulator Art ; CO VID: 1996 reads from a SARS-CoV -2 genome of length 29,926 contained in a coronavirus dataset do wnloaded from National Center for Biotechnology Information (NCBI) in November , 2020; SARS: 1907 reads from a SARS-CoV genome of length 29,751 from the same database as CO VID. Thus, O = { Adeno , CO VID , SARS } . W e employed the Mason_simulator software (Holtgrewe, 2010) to simulate Illumina NGS reads from each genome, with approximate 6X cov erage. (Illumina manufactures NGSs that employ an optical technology; see https://www.illumina.com/ .) Mason_simulator introduces errors in the form of transpositions (SNPs), insertions, deletions and undetermined bases. The latter are cases in which the 5 sequencer detects a nucleotide, but is unable to determine whether it is A, C, G or T . Follo wing con vention, these appear in the simulated reads as “N, ” and must be accommodated in computations. Parameters of the Mason_simulator were set at default v alues. The validation dataset V , which we earlier also termed the analysis dataset, is ef fectiv ely a clone of the training dataset, consisting of 2000 reads from each of the three genomes generated using the Mason_simulator . It is used to e valuate classifier performance. 3.3 The F our Classifiers Here we introduce the four classifiers inv estigated in this paper, as well as compare their performance on the training dataset. Throughout, the response is the read source and the predictors are the triplet distribution for the read. 3.3.1 Bayes Classifier The first classifier is that in Karr et al. (2026). Three likelihood functions, denoted by L ( ·| Adeno ) , L ( ·| CO VID ) , and L ( ·| SARS ) , are calculated from the triplet distributions. W e assume a uniform prior π R = (1 / 3 , 1 / 3 , 1 / 3) on O for each read. W e then use Bayes’ theorem and the three likelihoods to calculate posterior probabili- ties p ( ·| R ) ov er O , which yield the classifier decisions C ( R ) = arg max x ∈O p ( x | R ) . T able 1 contains the resultant confusion matrix for training dataset, which shows that the Bayes classifier performs well, albeit not spectacularly . T able 1: Confusion matrix for the Bayes classifier and unde graded training data T . The correct classification rate is 81.58%. Decision Source Adeno CO VID SARS Sum Adeno 1580 114 272 1966 CO VID 58 1738 200 1996 SARS 253 184 1470 1907 Sum 1891 2036 1942 5869 3.3.2 Neural Net Classifier Our neural net is an “out-of-the box” version of the neuralnet package in R with default settings. The algorithm is resilient backpropagation with weight backtracking (Riedmiller, 1994), the activ ation function is logistic, and there is one hidden neuron per layer . The confusion matrix for T is in T able 2. 3.3.3 Partition Model Classifier W e employ a regression tree (Hastie et al., 2001), as implemented in the rpart package in R. Standard heuristics for pruning, which select a complexity parameter on the basis of 10-fold cross-validation, lead to 6 T able 2: Confusion matrix for the neural net classifier and undegraded training data T . The correct classifi- cation rate is 76.20%. Adeno CO VID SARS Sum Adeno 1626 40 300 1966 CO VID 51 1724 221 1996 SARS 532 253 1122 1907 Sum 2209 2017 1643 5869 a tree with 549 terminal nodes, which is still clearly ov er-fitted. Instead, we pruned to a tree with 61 terminal nodes. The confusion matrix appears in T able 3. T able 3: Confusion matrix for the partition model classifier and undegraded training data T . The correct classification rate is 75.81%. 0 1 2 Adeno CO VID SARS Sum Adeno 1491 93 382 1966 CO VID 130 1640 226 1996 SARS 333 256 1318 1907 Sum 1954 1989 1826 5869 3.3.4 Random F orest Classifier This classifier is the R package randomforest with no modifications. T able 4 contains the confusion matrix. T able 4: Confusion matrix for the random forest classifier and undegraded training data T . The correct classification rate is 91.78%. 0 1 2 Sum Adeno 1815 62 89 1966 CO VID 57 1896 43 1996 SARS 117 114 1676 1907 Sum 1989 2072 1808 5869 3.4 Structure of an Experiment All of the experiments reported in Section 4 ha ve the same structure, which we describe here. 7 T raining data: Begin with training dataset T from Section 3.2. T raining data quality degradation: Select a degradation method, which in most cases is parameterized in a way that represents increasing degradation, and apply it to the training dataset. For instance, in Section 4.1, we use the SNP probability-parameterized method employed in Karr et al. (2022). Classifier execution: F or each value of the degradation parameter , re-train all four classifiers on the de- graded training dataset, and apply it to the (ne ver altered) v alidation dataset V . Classifier perf ormance evaluation: For each case (as defined abov e), summarize classifier behavior for the v alidation dataset V in terms of • Predictions, including the correct classification rate, and • Boundary Status distrib ution. In Section 4.1, these appear in Figures 3–5. Classifier congruence: F or each v alue of the de gradation parameter , calculate the e xtent to which the clas- sifiers concur , ex emplified by Figure 6. As discussed below , one recurrent finding is that congruence often degenerates slo wly as the data quality decreases, drops precipitously , then rises again. 4 Results and Findings Before exploring details, we emphasize the clear message that tr aining data quality matters . For comparison with results belo w , Figure 2 contains the confusion matrices for V for the four classifiers trained on the undegraded training dataset. Decision Source Adeno CO VID SARS Sum Adeno 1566 96 338 2000 CO VID 58 1734 208 2000 SARS 253 232 1515 2000 Sum 1877 2062 2061 6000 Decision Source Adeno CO VID SARS Sum Adeno 1649 42 309 2000 CO VID 98 1741 200 2000 SARS 533 300 1167 2000 Sum 2241 2083 1676 6000 Decision Source Adeno CO VID SARS Sum Adeno 1581 110 309 2000 CO VID 117 1567 316 2000 SARS 399 281 1320 2000 Sum 2097 1958 1945 6000 Decision Source Adeno CO VID SARS Sum Adeno 1744 65 191 2000 CO VID 74 1831 95 2000 SARS 212 207 1581 2000 Sum 2020 2103 1867 6000 Figure 2: Confusion matrices for the validation dataset V for the four classifiers trained on the undegraded training data T . T op left: Bayes classifier . T op right : neural net. Bottom left: partition model. Bottom right: random forest 8 4.1 SNP Degradation As mentioned pre viously , the de gradation mechanism here is that of Karr et al. (2022). There is a parameter called SNP_Probability belonging to (0 , 1) , and each base in a DN A sequence is changed to another value with that probability , independently of the others. The software used here and in Karr et al. (2022) is the Mason_variator (Holtgre we, 2010). The mechanism mimics nature because the changes are SNPs. In most cases, the v aiues of SNP_Probability are { 0 , 0 . 01 , 0 . 05 , 0 . 10 , 0 . 25 , 0 . 50 , 0 . 60 , 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 , 0 . 85 , 0 . 90 , 0 . 95 } , and the randomization is done independently at each step, as opposed to successiv ely degrading additional reads. The results appear in Figures 3–6. They are at once unsurprising and unexpected. Starting with Figure 3, that correctness decreases as SNP_Probability increases is completely expected. Until SNP_Probability is approximately 0.75, the decrease is linear , and the rate of decrease is essentially the same for all four clas- sifiers. What happens in the vicinity of SNP_Probability = 0.75 is, to least to us, unforeseen. Performance of all four classifiers drops precipitously , and nev er recovers. This breakdown behavior appears in other cases below , again uniformly across the four classifiers, so it seems not to be a function of the classifier or the mode of degradation. Figure 4 begins to illuminate the situation. Starting at the breakdown, almost all predictions become Adeno, again for all four classifiers. That is, once the training data are degraded sufficiently , the classifiers lose predicti ve po wer . This also explains why the number of correctly classified reads does not become zero in Figure 3, because those from the Adeno genome are classified correctly . It is not clear why Adeno, rather than CO VID or SARS, becomes the default prediction for classifiers trained on what is effecti vely noise. In Figure 5, things become more complex, and the four classifiers no longer beha ve identically . The be- haviors for the Bayes classifier , the neural net and the random forest are qualitati vely similar . The Boundary Status distrib ution is relativ ely stable when SNP_Probability < 0.75, with a slight increase in the proportion of v alidation dataset reads with BS = 0 , then there is a sharp drop in the number of validation dataset reads with BS = 0 (with most of the compensating increase being BS = 1 ). Past SNP_Probability = 0.75, the increase in the proportion with BS = 0 resumes. Among these three, the random forest stands out because of the sharp increase in BS = 2 , and corresponding decrease in BS = 0 . The behavior in these three cases is consistent with the preceding paragraph. For SNP_Probability < 0.75, the boundary composition is rel- ati vely constant. At SNP_Probability = 0.75, it changes dramatically , with BS v alues of 1 and 2 becoming much more prev alent. Once SNP_Probability > 0.75, as ev erything is predicted to be Adeno, the boundary starts to disappear . Not that the boundary is ev er small. The fraction of v alidation dataset reads for which BS = 0 is essentially nev er abov e .8 until the classifiers degenerate into predicting e verything to be Adeno. The partition model dif fers from the other three classifiers in that its boundary is much larger . The proportion of validation dataset reads with BS = 0 is the smallest of the three, and never exceeds 0.3. This means that of 70% v alidation dataset reads lie on the boundary . But still something happens in the vicinity of SNP_Probability = 0.75, followed by a return to the behavior for SNP_Probability < 0.75. The partition model is also an outlier in other cases belo w . Figure 6 completes the story . It shows that six pairwise congruences between the classifiers—the num- bers of reads for which they agree, as well as the four -way congruence. The dif ferences among the pairwise congruences are meaningful, and we return to them momentarily . The ov erall message reinforces the pre- ceding discussion. For SNP_Probability < 0.75, congruences are high, and because all four of the classifiers 9 are generally correct. Around SNP_Probability = 0.75, the congruences go haywire. For SNP_Probability > 0.75, they become high again, but because the four classifiers are incorrect in the same way: each clas- sifier is predicting “all Adeno. ” There results an interesting implication regarding ensemble methods. For SNP_Probability < 0.75 (higher quality training data), ensembling may not help because the four classifiers may generally be correct, whereas for SNP_Probability > 0.75 (lo wer quality training data), it may not help because all hav e degenerated in the same way . The pairwise congruences in Figure 6, while qualitativ ely similar , are not identical quantitativ ely . More- ov er , they are ordered numerically in a way that is largely independent of SNP_Probability . That for Bayes–random forest is highest, followed by Bayes–neural net, then neural net–random forest, then par- tition model–random forest, Bayes–partition model, and neural net–partition model. Although we do not pursue the issue here, the partition model seems to be the most de viant. For this case only , results for Neighbor Similarity appear in Figures 32–35, which we hav e placed in Appendix A because of their size. There is one figure for each classifier , and within each, one panel per v alue of SNP_Probability . The graphs are of densities of the associated values of Neighbor Similarity . Blank panels correspond to cases where Neighbor Similarity is identically one, so that there is no density function. Figure 32, for the Bayes classifier , is consistent with other interpretations. For low and high v alues of SNP_Probability , Neighbor Similarity is high, for different reasons. In the vicinity , of SNP_Probability . it deteriorates. Behavior for the neural net (Figure 33) is similar , with less pronounced deterioration. By contrast, for the random forest (Figure 35), the deterioration becomes true breakdown. The partition model (Figure 34) is truly different. W e simply cannot explain, or e ven hypothesize a reason for , the persistent trimodality in the distribution of Neighbor Similarity . The deterioration as SNP_Probability increases, which appears as a leftward shift in the modes, remains. Finally , an interesting complementarity for the Bayes classifier appears in Karr et al. (2026), but there with respect to the quality of the validation dataset with the training dataset held constant and undegraded. If V is replaced by random reads, or reads from bacterial or human genomes, the more distant those are from the training data, the more the decisions for it degenerate into “all Adeno. ” The big question, of course, is “Why SNP_Probability = 0.75?” W e defer this to Section 5. 4.2 V ariants of SNP Degradation Here we discuss sev eral variants of the degradation in Section 4.1. Before doing so, we note that the experiment in that section was replicated in its entirety , with results that were virtually identical. For brevity , we include the resultant analog of Figure 6, namely Figure 7. The two are virtually identical. Nor is an ything about the preceding results associated with the read length. Changing the read length to 200 makes no difference. The three panels in Figure 8 are virtually identical to the corresponding panels in Figure 4, even the to shapes of the plotted lines. Breakdo wn occurs at SNP_Probability = 0.75. Figure 9, ho wev er , presents complications. While the breakdown is e vident, and reproduces Figure 6, the early decline in all congruences inv olving the random field classifier is nov el. There is recov ery as SNP_Probability approaches 0.5, b ut we lack an explanation. It simply be random variation, because none of our experiments other than the first one has yet been replicated, and e ven for that one, there are only two replicates. T o control the length of the paper , for the other v ariants in this section, we include only the figures for predictions and classifier congruence. Also, because of the computational b urden associated with the Bayes classifier and since it is treated in detail in Karr et al. (2026), we hav e omitted it. 10 Figure 3: SNP degradation: number of correctly classified elements of V as a function of SNP_Probability . 4.2.1 Initially Degraded T raining Data Especially in light of Figure 1, it is natural to wonder what happens if the initial training data are degraded. Especially , does the breakdown move to the left, meaning that it depends on the absolute degradation? Or, does it remain at 0.75, meaning that degradation is relati ve? W e ran tw o e xperiments. In the first, the initial training data are the original training dataset T degraded with SNP_Probability = 0.9. In the second, the initial training data are the original training data T degraded with SNP_Probability = 0.5. Predictions from them are in Figure 10 and congruence for the neural net, partition model and random forest in Figure 11. Figure 10 should be compared to Figure 4, ignoring the Bayes classifier results in the upper left-hand panel of the latter . Qualitativ ely , they are very similar . Unambiguously , the breakdo wn is still present, and remains at SNP_Probability = 0.75. The same is true in Figure 11, whose parallel is Figure 6. That is, the answer to the question in the first paragraph of this section is definitively that breakdown is relativ e. This is, we believe, as it should be. Whatev er the training data are, the classifiers treat it as truth. If truth is wrong, they are wrong. Classifiers cannot be aware of an y unobserved “prior truth. ” 4.2.2 Selective SNP Degradation This experiment can be viewed as addressing the interpretations put forth in Section 4.1. If a random set of reads in T are selected for degradation, say with probability Sel_Probability , and each is degraded with probability SNP_Probability , what happens? This scenario differs from that in Section 4.1 in sense that there, once SNP_Probability is ev en moderately lar ge, all reads are altered, whereas here, the de gradation is confined to a subset of reads. 11 Figure 4: SNP degradation: classifier predictions as a function of SNP_Probability . Upper left: Bayes classifier . Upper right: neural net. Lower left: partition model. Lower right: random forest. So there are no w two parameters, Sel_Probability and SNP_Probability , both ranging ov er { 0 . 05 , 0 . 15 , 0 . 25 , 0 . 35 , 0 . 45 , 0 . 55 , 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 , 0 . 85 , 0 . 95 } in a full factorial design. For brevity , we consider only the three-way congruence among the neural net, partition model and random forest. Figure 12 contains both a heatmap and a 3-dimensional surface showing it. The most striking feature is that breakdown persists, but only when both probabilities reach 0.75. There is degeneration when one is small and the other large (the upper left-hand and lower right-hand corners in the heatmap), b ut it is relati vely minor . There is also asymmetry between Sel_Probability and SNP_Probability , but it is subtle and requires further in vestigation before we assert its existence with confidence. W e find only limited e vidence of a return to congruence following breakdo wn, but we suspect that this is due to our not including probabilities greater than 0.95. Can congruence be modeled as a function of Sel_Probability and SNP_Probability? The minor asym- metry notwithstanding, by a symmetric function, from Figure 12, a plausible candidate is the minimum of the two, and indeed the adjusted R 2 for the model is 0.8256. Howe ver , which is crucial, the model dra- matically ov erpredicts congruence once the minimum exceeds 0.75. Put differently , it cannot predict the post-breakdo wn decline in congruence. 12 Figure 5: SNP degradation: Boundary Status distribution as function of SNP_Probability . Upper left: Bayes classifier . Upper right: neural net. Lower left: Partition model. Lower right: random forest. In each of these, BS = 0 is the green line, BS = 1 is the yellow line, and BS = 2 is the red line. 4.2.3 Protecting Some Read Sour ces Here we explore the effect of ex empting reads from particular sources from degradation. One motiv ation is to accommodate laboratory effects, in the sense that the quality of gene sequence data may depend on the laboratory that generated them, a phenomenon that is demonstrably present in Karr et al. (2023). Such protection can be done in six ways, of course: protect reads whose source is one genome, or protect all reads except those whose source is one genome. The central question is whether the effects, especially prediction, are localized in the same way . Nor is “full protection” necessary: the experiment in Section 4.1 could instead ha ve three SNP_Probabilities, one for each genome. This is a direction we be gin to explore in Section 4.3.5. Figures 13–15 show predictions from the “protect one genome” scenario, with congruence in Figure 16. Here the story differs from previous (and subsequent) experiments. In none of Figures 13–15 is there more than mild evidence of breakdo wn, although what evidence there is, for example in Figure 15, continues to point to SNP_Probability = 0.75 as the location. The stronger message is that as reads from two of the 13 Figure 6: SNP degradation: classifier congruence as a function of SNP_Probability . genomes are degraded, predictions all become the undegraded genome. This is true for all three genomes and all three classifiers. This is sobering: when there is differ ential data quality in T , predictions may be incorrectly “forced” onto higher quality results because the real validation data look more like high quality training data than like noise. Figures 17–19 sho w predictions from the “degrade only one genome” scenario. Congruence is in Figure 20. The results reinforce those for “protecting one genome. ” Uniformly across genomes and classifiers, predictions are increasingly di verted from the one af fected genome to the tw o genomes. Evidence of break- do wn is, interestingly , different and not uniform. In Figure 18, something is happening in the vicinity of SNP_Probability = 0.25 for all three classifiers. There is no hint of this in Figures 17 and 19. Whether something is happening in Figure 19 for values of SNP_Probability in the vicinity of 0.8 is ev en less clear , because in any ev ent, it is not happening for random forests. But, then is something happening for random forests at SNP_Probability = 0.60? 4.3 Other Quality Problems Here we address the question of whether the behavior described in Section 4.1 is specific to SNP-degradation, or holds as well for ways of decreasing data quality . 4.3.1 Mislabeled Reads All four of the classifiers depend on labeled training data. What happens if there are problems with the labeling process, as there ine vitably are in reality? In the experiment described next, randomly selected elements of T ha ve their labels changed. The Mislabel_Probability v aries over { 0 , 0 . 05 , 0 . 15 , 0 . 25 , 0 . 35 , 0 . 45 , 0 . 55 , 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 , 0 . 85 , 0 . 95 } . The results, in Figures 21 and 22, are ambiguous compared to those in previous sections. Starting with the former , predictions by the partition model are largely insensitiv e to Mislabel_Probability . Those for the 14 Figure 7: SNP degradation: classifier congruence as a function of SNP_Probability for the r eplicated version of the experiment from Section 4.1. random forest begin to di verge when Mislabel_Probability reaches approximately 0.75 (again!). The neural net seems inexplicably erratic. The disappearance of SARS from its predictions mirrors random forests, but is much more extreme and begins for much smaller values of Mislabel_Probability . The two extreme oscillations between predictions of Adeno and predictions of CO VID have no analogues elsewhere in our experiments. And yet, Figure 22 echoes its predecessors, although the minimum values congruence appear to be for Mislabel_Probability less than 0.75. 4.3.2 Rev ersed Reads This is one case where we correctly expected nothing to happen. Recalling that DNA molecules are double helices (W atson, 2001), there is inherent uncertainty in NGS reads regarding which strand they come from. (Sequenced genomes hav e a well-determined 5’ end, characterized by a free phosphate, and 3’ end, char- acterized by a free hydroxyl.) Therefore, reversing some reads, as character strings, should hav e minimal ef fect. Figures 23 and 24 confirm this expectation. 4.3.3 Reduced T raining Data Here we explore the effect of a more global quality characteristic of training data—their size and balance. Recall from Section 3.2 that T contains approximately equal numbers of Adeno, CO VID and SARS reads. so does V , both of which may matter . In each run of this experiment, reads with a specified source are deleted at random from T , so that the experiment is parameterized by a Removal_Probability taking v alues in { 0 , 0 . 05 , 0 . 15 , 0 . 25 , 0 . 35 , 0 . 45 , 0 . 55 , 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 , 0 . 85 , 0 . 95 } . There is no reason to expect that, if there is breakdown-lik e behavior , it will occur at Remov al_Probability = 0.75. There is, of course, reason to suspect that as reads from one source are remov ed, the number of 15 Figure 8: Length 200 reads: classifier predictions as a function of SNP_Probability . Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. elements in V predicted to be from that source will decrease. Prediction results appear in Figures 25–27, and congruence in Figure 28. Regarding predictions, the disappearance of prediction associated with remov ed reads happens smoothly and uniformly across remo val source and classifiers. For the neural net, it disappears entirely for all three genomes in the vicinity of Remov al_Probability = 0.70. W e have no explanation for the oscillation of the neural net with remo ved Adeno reads at Remov al_Probability = 0.75. which is also reflected in the congruences that in volve the neural net. W e find no other evidence of breakdo wn. 4.3.4 Superfluous T raining Data It may seem paradoxical that too much data can be a data quality problem, especially if they are of high quality , but here we demonstrate that this is so. Moreover , our proposed explanation gibes perfectly with the ov erall themes of the paper . Intuitiv ely and surely ov er-simplistically , a classifier that is trained to recognize data not in V is wasting its finite potential. The experiment is as follows: we create a superfluous dataset S containing 12,000 E. coli reads, 785 reads from the A vian flu virus H5N1, 475 reads from Human Papilloma virus (HPV), 453 reads from Norovirus, and 477,357 reads from P . Gingivalis , a bacterium associated with chronic periodontitis. Its total size is 491,070. The “laundry list” feel reflects the varying sizes of the genomes with which we have worked. None of these is a close relati ve of the three virus genomes in T . The validation data V remain unchanged. As suggested above and confirmed belo w , training a classifier to recognize reads present are not in V is actually counterproductiv e, and not simply wasteful. The experiment is parameterized by an Add_Probability taking v alues in { 0 , 0 . 001 , 0 . 005 , 0 . 01 , 0 . 05 , 0 . 1 , 0 . 2 , 0 . 3 , 0 . 4 , 0 . 5 , 0 . 6 , 0 . 7 , 0 . 8 , 0 . 9 , 1 } , which is applied each element of S is added to T before re-training the classifiers. The classifiers are applied to the unaltered v alidation data. 16 Figure 9: Length 200 reads: classifier congruence as a function of SNP_Probability . They usual results appear in Figures 29–31. There is mixed evidence, at best, of breakdown, but seem- ingly evidence of another form of instability entirely . Once there is any additional of superfluous reads (for Add_Probability = 0.001, an average of 491 elements of S are added to T , which seems relativ ely innocu- ous), Adeno and SARS vanish from the predictions for the neural net. They vanish almost as rapidly for the random forest, and more slowly for the partition model. For these latter two, CO VID also ultimately disappears from the predictions, but more slowly . It does not disappear for the neural net. This may be another instance of being right for the wrong reason. Figure 29 shows, quite expectedly , that as more and more superfluous reads are added to T , the ov er- whelming majority of which are P . Gingivalis , they overwhelm the predictions for V . Howe ver , ev en for relati vely small v alues of Add_Probability , predictions are “siphoned off. ” For instance, for the partition model, which seems to be the most vulnerable of the three, even at Add_Probability = 0.001, 107 (of 6000) predictions are shifted to P . Gingivalis . The Boundary Status distributions in Figure 30 are equally intriguing. For all three classifiers, once there are superfluous reads, the boundary virtually disappears—and rapidly . Combined with the prediction results, we see a false sense of security from the superfluous data, at least if Neighbor Similarity were used as a confidence measure. Regarding congruence, there is a breakdown for Add_Probability = 0.01, but with no recovery for the neural net. The partition model–random forest congruence, the breakdo wn is mild, and recovery occurs. Clearly there is much more to be learned about this case, but the message to “be very afraid” of using a classifier when T and V are far apart is unmistakable. It is, of course, not a new message, but our work provides a more nuanced understanding of it. 4.3.5 Mixed Data Quality Problems Finally , as we have intimated pre viously , there is no reason to consider only one form of data quality degra- dation per e xperiment. Indeed the spirit of total surve y error demands so. Here, we mix the SNP degradation of Section 4.1 with the mislabeling of Section 4.3.1. There are, then, three parameters: 17 • Sel_Probability , the probability that each read in T is selected for degradation; • SNP_Fraction, the conditional probability that a read selected for degradation is subject to SNP degradation—otherwise it is subjected to mislabeling; • SNP_Probability , with the same meaning as previously: gi ven that a read is selected for SNP degra- dation, the probability with which each nucleotide in it is changed. Potential v alues are { 0 . 05 , 0 . 15 , 0 . 25 , 0 . 35 , 0 . 45 , 0 . 55 , 0 . 65 , 0 . 70 , 0 . 75 , 0 . 80 , 0 . 85 , 0 . 95 } for Sel_Probability and SNP_Probability , and { 0 . 05 , 0 . 15 , 0 . 25 , 0 . 35 , 0 . 45 , 0 . 55 , 0 . 65 , 0 . 75 , 0 . 85 , 0 . 95 } for SNP_Fraction. And we introduce one further consideration, which whether we can model the contributions of the pa- rameters to congruence. A priori , based on results abov e, congruence should decrease as either Sel_Probability or SNP_Probability increases. Whether it increases with SNP_Fraction sheds light on which of the two forms of degradation is more injurious. A full factorial design of 1440 cases was not feasible computation- ally , so we instead used a 25-point Fedorov design explicitly meant to support fitting linear models (Fedorov , 1972; Wheeler, 2004). It and the associated results appear in T able 5. W e then fitted linear models with each of the four congruences as the response and the three parameters of the experiment as predictors. This is not a modeling decision informed by science, but is a reasonable place to begin. Addition of quadratic terms, as might be proposed based on the modeling discussion in Section 4.2.2, does not improve model fit. The four models are consistent with one another , and with the exception of that for NN_RF , all fit the data comparably . The intercepts, which are the congruences in the absence of degradation, are consistent with those in previous sections. For all four models, the coefficient of Sel_Probability is strongly negati ve and highly significant: the more ov erall degradation, the lower the congruence. While in no case is the coefficient of SNP_Probability significant, it is always negati ve: more SNPs mean less congruence. And finally , the coefficient of SNP_Fraction, while again not significant, is always positi ve and of the same order to magnitude. The interpretation is that shifting from Mislabeling to SNP degradation incr eases congruence, meaning that the former is more disruptiv e. 18 T able 5: Mixed degradation: experimental design and congruence among neural net, partition model and random forest. Sel_Prob SNP_Frac SNP_Prob NN_PM NN_RF PM_RF NN_PM_RF 0.050 0.050 0.050 4165 4809 4549 3822 0.150 0.050 0.050 4191 4695 4541 3770 0.850 0.050 0.050 2334 2770 2410 1135 0.950 0.050 0.050 2722 3171 2777 1555 0.950 0.150 0.050 2582 3734 2569 1704 0.050 0.850 0.050 4229 4872 4623 3917 0.950 0.850 0.050 3910 4652 4441 3561 0.050 0.950 0.050 4363 4882 4728 4032 0.850 0.950 0.050 4028 4833 4485 3735 0.950 0.950 0.050 4257 4792 4602 3886 0.050 0.050 0.150 4202 4849 4578 3866 0.050 0.950 0.150 4243 4826 4653 3912 0.950 0.050 0.850 2956 3970 2821 2031 0.050 0.950 0.850 4228 4778 4679 3893 0.950 0.950 0.850 2247 3017 2400 1188 0.050 0.050 0.950 4268 4787 4704 3938 0.150 0.050 0.950 3982 4730 4394 3644 0.850 0.050 0.950 2626 3409 2714 1602 0.950 0.050 0.950 3076 3841 3167 2179 0.050 0.150 0.950 4240 4866 4625 3923 0.050 0.850 0.950 4166 4835 4642 3874 0.950 0.850 0.950 3299 4716 3072 2711 0.050 0.950 0.950 4175 4809 4591 3860 0.850 0.950 0.950 2535 2835 3082 1632 0.950 0.950 0.950 2569 3632 2825 1746 T able 6: Estimated coefficients and adjusted R 2 -v alues for linear models of congruence as a function of Sel_Pobability , SNP_Fraction and SNP_Probability . Labels for statistical significance are the standard ones. Response Predictors Adjusted R 2 Intercept Sel_Prob SNP_Frac SNP_Prob NN_PM 4305.3 (***) -1383.1 (***) 336.6 -365.6 0.6403 NN_RF 4818.8 (***) -1157.4 (***) 344.1 -232.8 0.4468 PM_RF 4670.7 (***) -1669.5 (***) 515.6 -418.9 0.6794 NN_PM_RF 3964.7 (***) -1934.0 (***) 576.3 (.) -462.3 0.6374 19 Figure 10: Initially degraded training data: classifier predictions as a function of SNP_Probability . T op: SNP_Probability for initial degradation is 0.9. Bottom: SNP_Probability for initial degradation is 0.5. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. 20 Figure 11: Initially degraded training data: classifier congruence as a function of SNP_Probability . Left: SNP_Probability for initial degradation is 0.9. Right: SNP_Probability for initial degradation is 0.5. Figure 12: Selecti ve SNP degradation: 3-way classifier congruence as a function of Sel_Probability and SNP_Probability . Left: heatmap. Right: 3D surface. 21 Figure 13: SNP degradation not applied to Adeno reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 14: SNP degradation not applied to CO VID reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. 22 Figure 15: SNP degradation not applied to SARS reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 16: SNP degradation not applied to one set of reads: classifier congruence as a function of SNP_Probability . Left: not applied to Adeno reads in training data. Center: not applied to CO VID reads in training data. Right: not applied to SARS reads in training data. 23 Figure 17: SNP degradation applied only to Adeno reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 18: SNP degradation applied only to CO VID reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. 24 Figure 19: SNP degradation applied only to SARS reads: classifier predictions as a function of SNP_Probability . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 20: SNP degradation applied only to one set of reads: classifier congruence as a function of SNP_Probability . Left: applied only to Adeno reads in training data. Center: applied only to CO VID reads in training data. Right: applied only to SARS reads in training data. 25 Figure 21: Mislabeled training data: classifier predictions as a function of Mislabel_PR OB ABILITY . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 22: Mislabeled training data: classifier congruence as a function of Mislabel_PR OB ABILITY . 26 Figure 23: Reversed training data: classifier predictions as a function of the probability of re versing reads in the training dataset T . Left: neural net. Center: partition model. Right: random forest. Gr een: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 24: Rev ersed training data: classifier congruence as a function of probability of reversing reads in the training dataset T . 27 Figure 25: Reduced Adeno reads: classifier predictions as a function of Remov al_Probability . Left: neural net. Center: partition model. Right: random forest. Green: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 26: Reduced: CO VID reads: classifier predictions as a function of Remov al_Probability . Left: neural net. Center: partition model. Right: random forest. Green: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. 28 Figure 27: Reduced SARS reads: classifier predictions as a function of Remov al_Probability . Left: neural net. Center: partition model. Right: random forest. Green: prediction = Adeno. Red: prediction = CO VID. Blue: prediction = SARS. Figure 28: Reduced training data reads: classifier congruence as a function of Remov al_Probability . Left: reduced Adeno reads. Center: reduced CO VID reads. Right: reduced SARS reads. 29 Add_Probability Pred_Adeno Pred_CO VID Pred_SARS Pred_EColi Pred_H5N1 Pred_HPV Pred_Norovirus Pred_PGingiv alis 0.000 2015 2232 1753 0 0 0 0 0 0.001 1945 2192 0 0 0 1863 0 0 0.005 279 2249 0 0 0 867 2605 0 0.010 0 2467 0 0 0 0 1335 2198 0.050 0 2873 0 0 0 0 2923 204 0.100 0 2610 0 0 0 0 3390 0 0.200 0 2027 0 0 0 0 3973 0 Add_Probability Pred_Adeno Pred_CO VID Pred_SARS Pred_EColi Pred_H5N1 Pred_HPV Pred_Norovirus Pred_PGingiv alis 0.000 2097 1958 1945 0 0 0 0 0 0.001 1864 2006 2023 0 0 0 0 107 0.005 1507 1986 1787 0 0 0 0 720 0.010 1081 2003 1708 0 0 0 0 1208 0.050 0 2098 707 0 0 0 0 3195 0.100 0 1653 450 0 0 0 0 3897 0.200 0 1459 0 0 0 0 0 4541 0.300 0 931 0 0 0 0 0 5069 0.400 0 788 0 0 0 0 0 5212 0.500 0 932 0 0 0 0 0 5068 0.600 0 0 0 0 0 0 0 6000 0.700 0 0 0 0 0 0 0 6000 0.800 0 0 0 0 0 0 0 6000 Add_Probability Pred_Adeno Pred_CO VID Pred_SARS Pred_EColi Pred_H5N1 Pred_HPV Pred_Norovirus Pred_PGingiv alis 0.000 2033 2119 1848 0 0 0 0 0 0.001 2024 2081 1889 0 0 0 0 6 0.005 1552 2110 1844 0 0 0 0 494 0.010 793 2173 1640 0 0 0 0 1394 0.050 0 1745 250 0 0 0 0 4005 0.100 3 972 0 0 0 0 0 5025 0.200 2 256 0 0 0 0 0 5742 0.300 1 0 0 0 0 0 0 5999 0.400 0 0 0 0 0 0 0 6000 0.500 3 0 0 0 0 0 0 5997 0.600 0 0 0 0 0 0 0 6000 0.700 0 0 0 0 0 0 0 6000 0.800 0 0 0 0 0 0 0 6000 0.900 0 0 0 0 0 0 0 6000 1.000 0 0 0 0 0 0 0 6000 Figure 29: Superfluous training data: classifier predictions as a function of Add_Probability . T op: neural net. Center: partition model. Bottom: random forest. Figure 30: Superfluous training data: boundary status distributions as a function of Add_Probability . In each of these, BS = 0 is the green line, BS = 1 is the yellow line, and BS = 2 is the red line. 30 Figure 31: Superfluous training data: classifier congruence as a function of Add_Probability . 31 5 Discussion Despite its length, this paper leav es many questions unanswered. 5.1 Scientific Generalizability W e hav e examined one scientific context, with one input graph I and one output space O , four classifiers, and a handful of context-specific data quality characteristics. Of course, we have no evidence-based claim that what hav e observed occurs more generally . W e conjecture that it does, but asserting that breakdown is an inherent characteristics of classifiers, even those whose input space is a graph, let alone for all forms of data quality degradation, is simply silly . Nev ertheless, our tools apply and our explanations make sense in virtually any context. And the world is full of discontinuities, including classifier boundaries, which are local discontinuities with respect to the analysis data, and are omnipresent. Generalizability issues are of at least three v arieties: with respect to scientific conte xt/nature of datasets, classifiers, and data quality measures. In this paper we hav e addressed the latter two to some extent, b ut the first not at all. Doing so is most urgent question, and we plan to in vestigate it. 5.2 Theory vs. Empirical Evidence W e turn no w to the question with which Section 4.1 ended “Why SNP_Probability = 0.75?” Can there be theory that explains this? Gi ven that our experiments are simulations in which we examined a limited set of possible values of SNP_Probability , it seems sensible to believ e that 0.75 is the mean (or another characteristic) of some random variable that varies depending on exactly which bases in which reads are altered. While the same breakdown phenomenon may exist in other settings, the numerical value is setting- and data quality measure-specific. There may be a deeper issue here, which is the role of empirical analyses in understanding computational tools that lack theory capable of predicting their behavior in reality , especially for datasets sampled from no describable population. T o the extent that it is an issue for the classifiers here, it is a much more profound issue for large language models (LLMs) and other AI tools. 5.3 Actionable Implications And no w the really big question: so what? With slightly more precision, our high-le vel path to impact is that: • Classifier performance depends on training data, which we ha ve demonstrated in one context. • In today’ s world, man y datasets are collected with limited attention to quality , and little-to-no charac- terization or quantification of it. • The principled way to deal with these two phenomena is via uncertainties associated with classifier decisions, as measured by Neighbor Similarity , for instance. Doing so without changing the training data quality is not possible. W e also note that one of us (AFK) has argued that data quality is for aficionados, and that it is really decision quality that matters (Karr, 2013). T o this end, combining this paper with findings in Karr et al. 32 (2026) and Porter and Karr (2024), what may be the central data quality issue emerges—be yond the quality of T (addressed here) and that of V , there is the quality of relationship between the training data and analysis data. “Everyone kno ws” that if they are too diver gent, performance suffers. This paper and Karr et al. (2026) are steps to quantifying both the div ergence and the performance consequences. Is there a paradigm, probably iterativ e and therefore necessarily Bayesian, that addresses the problem? For instance, start with a large training dataset T , run the classifier(s) and see whether there are unused elements of T that can be removed. Assess quality of elements T to see if there are lo w quality elements whose remov al would improv e performance. Then, re-run the process. And at some point, assess whether there are elements of V that may be misclassified because they are of low quality . The role of Bayes in such a paradigm is to track uncertainties properly . 6 Conclusion In this paper , we ha ve shown that in one context, decreasing the quality of data used to train classifiers impairs their performance, in some cases causing it to break down entirely . W e hav e examined multiple mechanisms for effecting the quality decrease, which behave similarly . The consequences for decisions based on classifier output are beginning to be e xplored. Acknowledgements Precursor research by AFK was supported in part by NIH grant 5R01AI100947–06, “ Algorithms and Soft- ware for the Assembly of Metagenomic Data, ” to the Uni versity of Maryland College Park (Mihai Pop, PI). He thanks Professor Pop for numerous insightful discussions. Both authors gratefully acknowledge ongoing support and collaboration from Professor Adam Porter of the Uni versity of Maryland College P ark. This paper flows directly from Karr et al. (2022), Porter and Karr (2024), and Karr et al. (2026), of which he is a co-author . Declarations • Both authors contrib uted equally to the paper . • The authors declare no conflicts of interest or competing interests. • Data and R code for the analyses in this paper are a vailable at https://doi.org/TBD . 33 A Neighbor Similarity f or SNP Degradation See Section 4.1 for discussion. Figure 32: SNP degradation, Bayes classifier: Neighbor Similarity as a function of SNP_Probability . Figure 33: SNP degradation, neural net classifier: Neighbor Similarity as a function of SNP_Probability . 34 Figure 34: SNP degradation, partition model classifier: Neighbor Similarity as a function of SNP_Probability . Figure 35: SNP degradation, random forest classifier: Neighbor Similarity as a function of SNP_Probability . 35 Refer ences Biemer , P . P ., Leeuw , E. D., Eckman, S., Edwards, B., Kreuter , F ., L yberg, L., T ucker , C., and W est, B., editors (2017). T otal Survey Err or in Practice . W iley , New Y ork. Cepeda, V ., Liu, B., Almeida, M., Hill, C. M., T reangen, T . J., and Pop, M. (2017). MetaCompass: Reference-guided assembly of metagenomes. Preprint, bioRxiv, https://doi.org/10.1101/212506 . Compeau, P . E. C., Pe vzner , P . A., and T esler , G. (2023). Why are de Bruijn graphs useful for genome assembly? Nat. Biotechnol. , 29(11):987–991. Farbiash, D. and Puzis, R. (2020). Cyberbiosecurity: DN A injection attack in synthetic biology . arX- i vL2911,13444v1 [cs.CR]. Fedorov , V . V . (1972). Theory of Optimal Experiments . Academic Press, Ne w Y ork. Hastie, T ., T ibshirani, R., and Friedman, J. (2001). The Elements of Statistical Learning: Data Mining, Infer ence, and Pr ediction . Springer–V erlag, Ne w Y ork. Holtgre we, M. (2010). Mason: A read simulator for second generation sequencing data. T echnical Report FU Berlin . Karr , A. F . (2013). Discussion of fiv e papers on “Systems and Architectures for High-Quality Statistics Production”. J ournal of Official Statistics , 29(1):157–163. Karr , A. F . (2017). The role of statistical disclosure limitation in total surve y error . In Biemer , P . P ., Leeuw , E. D., Eckman, S., Edwards, B., Kreuter , F ., L yberg, L., T ucker , C., and W est, B., editors, T otal Survey Err or in Practice , pages 71–94. W iley , New Y ork. Karr , A. F ., Hauzel, J., Porter , A. A., and Schaefer , M. (2022). Measuring quality of DNA sequence data via degradation. PLoS ONE , 2022:0221459. DOI: 10.1371/journal.pone.0221459. Karr , A. F ., Hauzel, J., Porter , A. A., and Schaefer , M. (2023). Application of Markov structure of genomes to outlier identification and read classification. Preprint. arXi v:2112.13117. Karr , A. F ., Porter, A. A., Bo wen, Z., and Ruane, R. (2026). Structure of classifier boundaries: Case study for a Bayes classifier . J . Classification . Under revision; arXi v:2212.04382. Karr , A. F ., Sanil, A. P ., and Banks, D. L. (2006). Data quality: A statistical perspectiv e. Statistical Methodology , 3(2):137–173. Karr , A. F ., Sanil, A. P ., Sacks, J., and Elmagarmid, E. (2001). W orkshop Report: Affiliates W ork- shop on Data Quality . T echnical Report, National Institute of Statistical Sciences. A vailable online at www.niss.org/affiliates/dqworkshop/report/dq-report.pdf . K eller , S., Korkmaz, G., Orr , M., Schroeder , A., and Shipp, S. (2017). The ev olution of data quality: understanding the transdisciplinary origins of data quality concepts and approaches. Annu. Rev . Stat. Appl. , 4:85–108. 36 Nikulin, M. S. (2001). Hellinger distance. In Encyclopedia of Mathematics . EMS Press, Berlin. Of fice of Management and Budget (2002). Guidelines for Ensuring and Maximizing the Quality , Ob- jecti vity , Utility , and Integrity of Information Disseminated by Federal Agencies. A vailable online at www.whitehouse.gov/omb/fedreg/reproducible.html . Of fice of Management and Budget (2006). Standards and Guidelines for Statisti- cal Surve ys; Statistical Policy Directiv e No. 2. Downloaded on 9/2/2021 from https://www.whitehouse.gov/omb/information-regulatory-affairs/statistical-programs-standards/ . Pop, M. (2024). MetaCompass: Comparative assembly of metagenomic sequences. Information av ailable at https://metacompass.cbcb.umd.edu/ . Porter , A. A. and Karr, A. F . (2024). Activ e model learning for software interrogation and diagnosis. ICSE 2024 W orkshop on Advances in Model-Based Softw are T esting (A-MOST). Pride, D. T ., Meinersmann, R. J., W assenaar, T . M., and Blaser , M. J. (2003). Evolutionary implications of microbial genome tetranucleotide frequency biases. Genome Resear ch , 13:145–158. Riedmiller , M. (1994). Rprop - Description and Implementation Details. T echnical report, University of Karlsruhe. T eeling, H., Meyerdierks, A., Bauer , M., Amann, R., and Glöckner , F . O. (2004a). Application of tetranu- cleotide frequencies for the assignment of genomic fragments. En vir onmental Micr obiology , 6(9):938– 947. T eeling, H., W aldmann, J., Lombardot, T ., Bauer, M., and Glöckner , F . O. (2004b). TETRA: a web-service and a stand-alone program for the analysis and comparison of tetranucleotide usage patterns in DN A sequences. BMC Bioinformatics , 5(163). W atson, J. D. (2001). The Double Helix: A P ersonal Account of the Discovery of the Structur e of DNA . T ouchstone, New Y ork. Wheeler , R. E. (2004). AlgDesign: Algorithmic Experimental Design . R package. 37
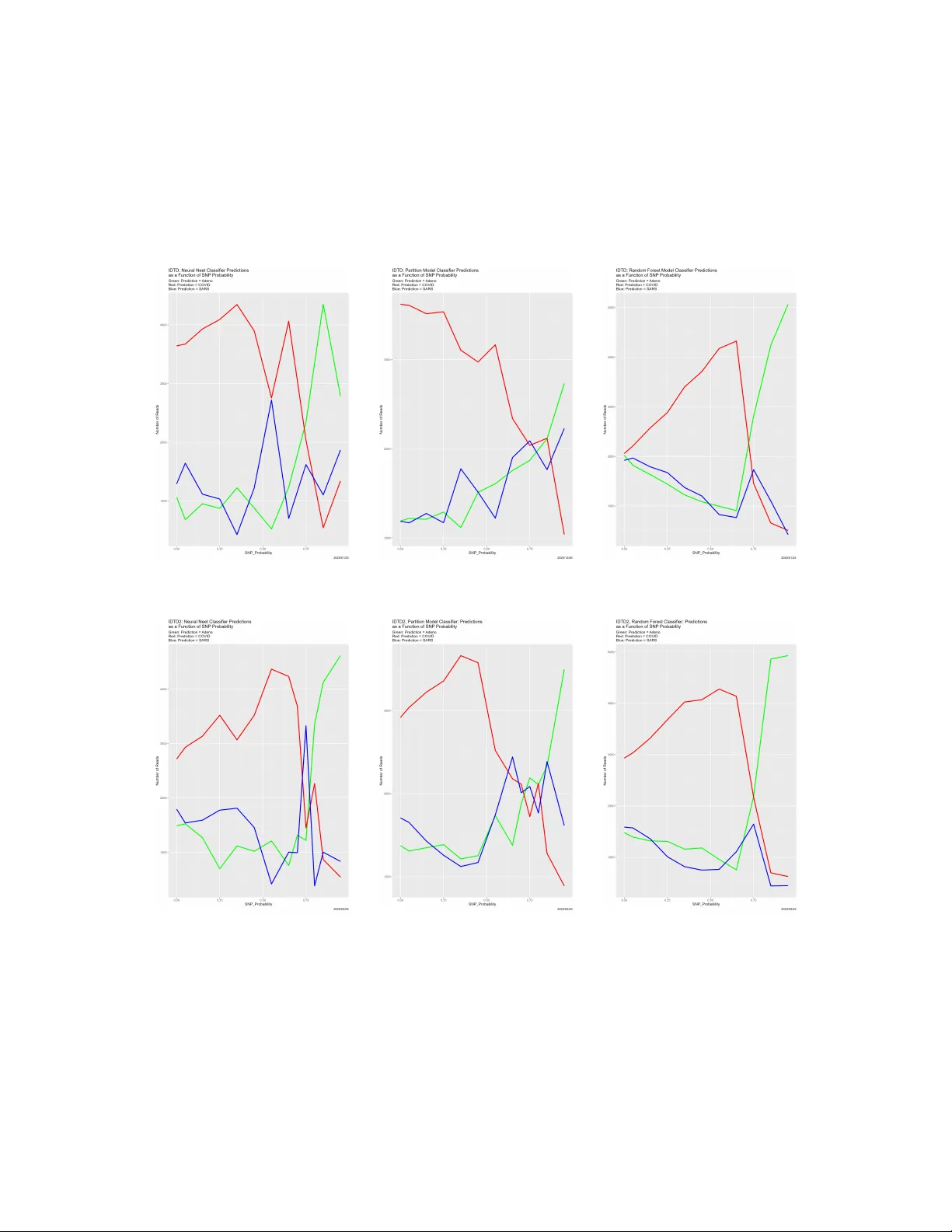
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment