불확실성 인식 배송 지연 기간 예측을 위한 다중과제 딥러닝 모델
** 본 논문은 배송 지연이 드물게 발생하는 고불균형 데이터 환경에서, 분류와 회귀를 하나의 네트워크로 결합한 다중과제 딥러닝 모델을 제안한다. 카테고리와 수치형 변수를 각각 임베딩하고, 지연 여부를 분류한 뒤 지연·정시 두 경우에 대해 별도 양자회귀 헤드를 두어 지연 기간을 예측한다. 또한 컨포멀 예측을 적용해 예측 구간을 교정함으로써 불확실성을 정량화한다. 1,000만 건 이상의 실제 물류 데이터를 이용한 실험에서 XGBoost·CatB…
저자: Stefan Faulkner, Reza Z, ehshahvar
**
본 논문은 현대 공급망에서 배송 지연을 정확히 예측하는 것이 운영 효율성과 고객 만족도에 핵심적인 역할을 함에도 불구하고, 복잡한 물류 네트워크와 지역별 변동성, 그리고 지연 건수가 전체의 극소수에 불과한 심각한 클래스 불균형으로 인해 기존 예측 모델이 한계에 봉착하고 있음을 지적한다. 이를 해결하기 위해 저자들은 ‘다중과제 딥러닝 모델’을 설계했으며, 주요 구성 요소는 다음과 같다.
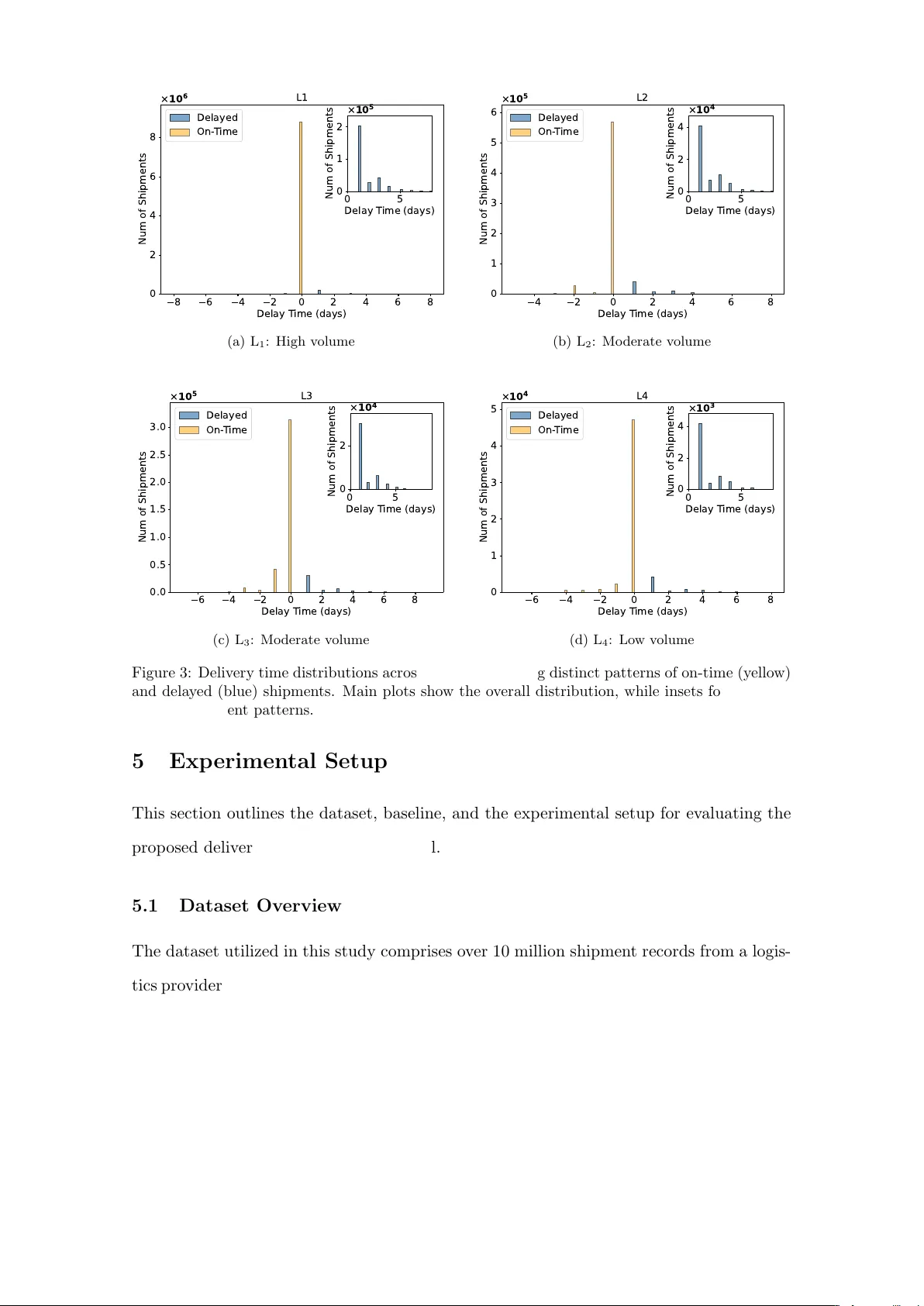
1. **임베딩 백본**: 배송 데이터는 수백 개의 카테고리형 변수(예: 출발지·도착지, 운송수단, 운송사)와 수십 개의 수치형 변수(무게, 부피, 아이템 수 등)로 이루어진 고차원 탭형 데이터이다. 각각의 카테고리형 변수는 별도 임베딩 레이어를 통해 저차원 밀집 벡터로 변환하고, 수치형 변수는 정규화 후 동일 레이어에 입력한다. 이렇게 얻어진 임베딩 벡터 hᵢ는 이후 모든 과제에 공유된다.
2. **분류 헤드**: hᵢ를 입력으로 지연 여부(dᵢ)를 0/1로 예측한다. 손실 함수는 불균형 데이터에 강인한 Sigmoid‑F1을 사용해 리콜을 높이고, 분류 정확도를 최대화한다.
3. **이중 양자회귀 헤드**: 분류 결과에 따라 두 개의 별도 회귀 헤드가 선택된다. ‘정시 헤드’는 yᵢ가 0에 가까운 경우(즉, 지연이 없거나 아주 짧은 경우)를 담당하고, ‘지연 헤드’는 yᵢ≥1인 경우를 담당한다. 각 헤드는 여러 분위수(α)‑ 수준(예: 0.1, 0.5, 0.9)의 조건부 양자값을 동시에 학습하도록 설계되었으며, 핀볼 손실(quantile loss)을 최소화한다. 이를 통해 평균값뿐 아니라 분포의 형태까지 추정한다.
4. **컨포멀 캘리브레이션**: 양자회귀만으로는 실제 커버리지를 보장하기 어렵다. 따라서 별도의 캘리브레이션 데이터셋을 이용해 각 샘플의 ‘컨포멀 점수’ Eᵢ = max_{α∈A} |yᵢ−ˆy_{α}(xᵢ)|를 계산하고, 목표 커버리지(예: 80%)에 해당하는 (1−α)‑분위수 ˆq_{1−α}를 구한다. 최종 예측 구간 ˜Cα(xᵢ) =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기