베이지안 신경망을 위한 디리클레 스케일 혼합 사전
본 논문은 베이지안 신경망(BNN)에서 사용되는 사전 분포의 한계를 극복하고자, 전역·그룹·개별 파라미터 수준의 3단계 구조를 갖는 디리클레 스케일 혼합(DSM) 사전을 제안한다. DSM 사전은 동일한 노드에 속하는 가중치를 그룹 스케일로 묶고, 디리클레 분포를 통해 그룹 내 가중치들의 분산을 경쟁적으로 할당함으로써 자연스러운 희소성을 유도한다. 이론적으로 의존 구조와 수축 특성을 분석하고, 실험을 통해 적은 유효 파라미터로도 경쟁력 있는 예측…
저자: August Arnstad, Leiv Rønneberg, Geir Storvik
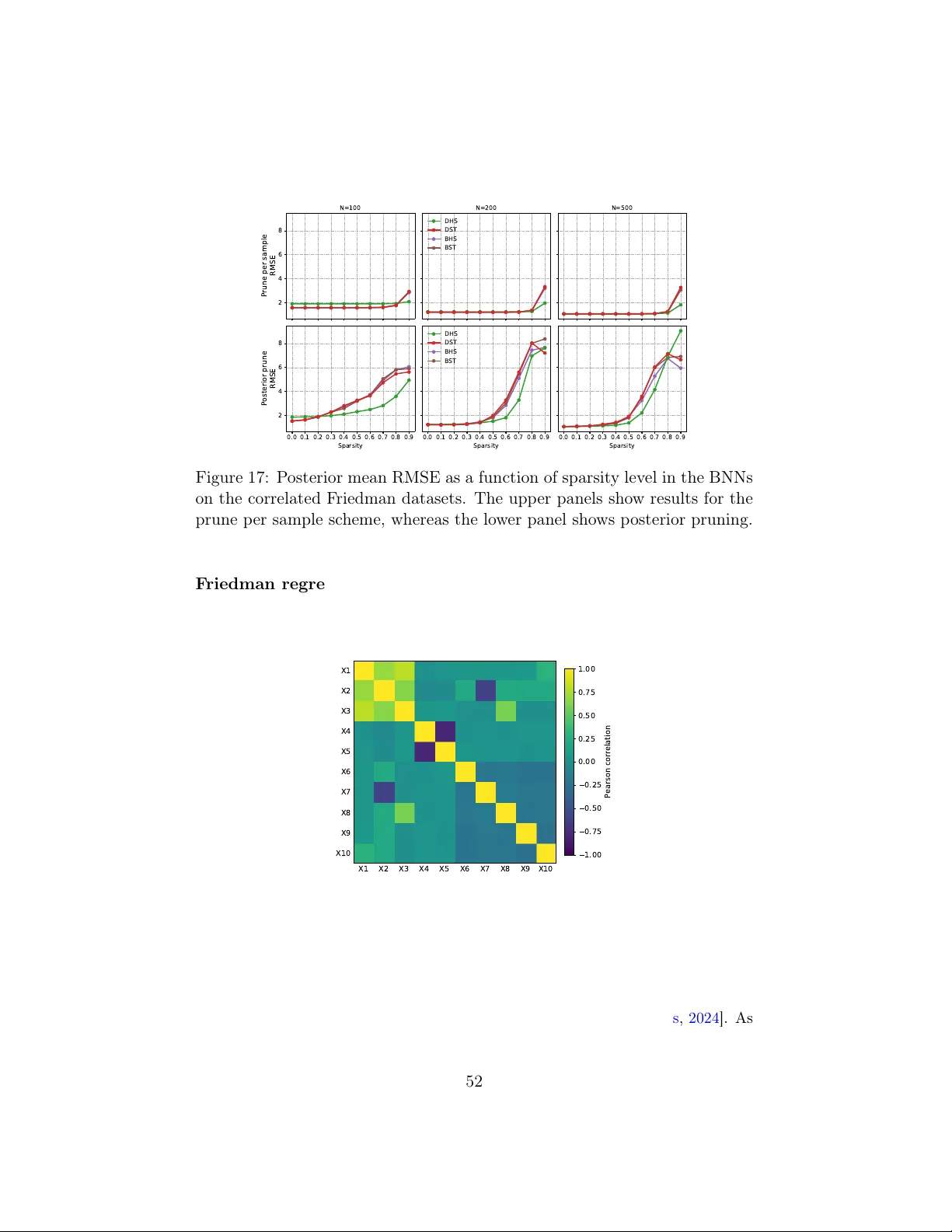
본 논문은 베이지안 신경망(BNN)에서 사전 분포 선택이 모델 성능과 불확실성 추정에 미치는 영향을 깊이 탐구하고, 이를 개선하기 위한 새로운 사전 클래스인 디리클레 스케일 혼합(DSM) 사전을 제안한다. 서론에서는 현대 딥러닝 모델이 해석 어려움, 과신, 적대적 공격에 취약함을 지적하고, BNN이 이러한 문제를 완화할 수 있으나 사전 선택이 종종 간과된다는 점을 강조한다. 특히, 단순한 동등분산 가우시안 사전이 콜드 포스터리어 현상 등 모델 불일치를 야기한다는 최근 연구들을 인용한다.
관련 연구 파트에서는 기존의 스케일 혼합 사전(예: horseshoe, Dirichlet‑Laplace)과 그룹‑레벨 구조를 도입한 스파스 사전(예: 그룹‑horseshoe, Louizos 등)을 정리한다. 이들 사전은 전역‑지역(글로벌‑로컬) 구조를 통해 대부분의 파라미터를 0에 강하게 수축시키면서 일부는 큰 스케일을 유지하도록 설계되었으나, 그룹 간 경쟁 메커니즘이 부족하거나 사전 의존성이 제한적이라는 한계가 있다.
본 논문의 핵심 기여는 이러한 한계를 보완하는 DSM 사전의 정의와 이론적 분석이다. DSM 사전은 세 단계의 계층적 구조를 갖는다. 첫 번째 단계는 전체 네트워크에 공유되는 전역 스케일 τ이며, 두 번째 단계는 각 노드(또는 그룹)별로 할당되는 그룹 스케일 λ_j이다. 세 번째 단계에서는 동일 노드에 속하는 가중치들의 분산을 디리클레 벡터 ξ_j=(ξ_{j1},…,ξ_{jp})에 의해 경쟁적으로 배분한다. 수식적으로는 w_{jk}│τ,λ_j,ξ_{jk}∼N(0,τ²λ_j²ξ_{jk})이며, ξ_j∼Dir(α,…,α)이다. α는 디리클레 농도 파라미터로, α가 작을수록 불균형 할당이 강화돼 강한 스파스를 유도하고, α가 크면 균등 할당에 가까워져 기존 전역‑지역 사전과 동일한 동작을 보인다.
이론 섹션에서는 DSM 사전이 유도하는 사전 공분산 구조를 상세히 도출한다. 그룹 내 가중치들의 공분산은 τ²λ_j²·(α/(α+p))·(I_p−(1/p)1·1ᵀ) 형태이며, 이는 디리클레 제약에 의해 음의 상관관계를 갖는다. 또한, α→0 한계에서 사전은 spike‑and‑slab 형태에 수렴하고, α→∞ 한계에서는 순수 Gaussian 사전으로 변한다는 연속성을 보인다. 이러한 특성은 사용자가 데이터의 희소성 정도에 맞춰 α를 조정함으로써 사전 강도를 미세하게 제어할 수 있게 한다.
실험 파트에서는 두 가지 주요 설정을 다룬다. 첫 번째는 시뮬레이션 데이터로, 피처 간 높은 상관관계와 제한된 샘플 수를 가진 상황에서 DSM 사전이 자동으로 불필요한 피처를 0에 가깝게 수축시켜 모델 복잡도를 크게 감소시켰다. 두 번째는 실제 데이터셋(CIFAR‑10, UCI 회귀, MNIST 등)에서 동일한 네트워크 아키텍처와 학습 예산을 사용해 DSM 사전을 기존 Gaussian, horseshoe, Dirichlet‑Laplace 사전과 비교했다. 결과는 다음과 같다. (1) 예측 정확도와 로그우도 측면에서 DSM 사전이 동등하거나 약간 우수했다. (2) 파라미터 프루닝 실험에서 DSM 기반 모델은 60‑80 % 가중치를 제거해도 성능 저하가 미미했으며, 이는 그룹‑레벨 수축이 ‘노드 전체’를 비활성화시키는 효과와 일치한다. (3) 적대적 공격(예: FGSM, PGD) 대비 강인성에서도 DSM 사전이 기존 사전보다 높은 정확도를 유지했다.
콜드 포스터리어 현상에 대한 별도 분석에서는 heavy‑tailed λ_j와 τ(반대칭 Cauchy 혹은 low‑df Student‑t)를 사용함으로써 사후 온도 조정 없이도 과도한 확신을 완화한다는 실험적 증거를 제시한다. 이는 기존 연구가 제안한 ‘Gaussian 사전이 얇은 꼬리를 가져 콜드 포스터리어를 유발한다’는 가설을 보완한다.
마지막으로 논문은 DSM 사전이 제공하는 세 가지 실용적 장점을 정리한다. 첫째, 그룹‑레벨 경쟁적 수축을 통해 구조적 스파스를 자연스럽게 달성한다. 둘째, heavy‑tailed 전역·그룹 스케일이 불확실성 추정과 적대적 강건성을 동시에 향상시킨다. 셋째, α 파라미터를 통해 사전 강도를 연속적으로 조절할 수 있어 다양한 데이터 환경에 유연하게 적용 가능하다. 향후 연구 방향으로는 비대칭 디리클레(Dirichlet‑process) 확장, 자동 α 학습, 그리고 대규모 딥러닝 프레임워크와의 통합을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기