조합 치료를 위한 순열 불변 표현과 직교 상승 학습
본 논문은 정책 형태의 조합 치료를 대상으로, 각 정책을 컨텍스트‑액션 혼합으로 표현하고 이를 순열 불변 집계로 임베딩한다. 임베딩을 로우‑랭크 직교 모델에 결합해 Robinson 분해를 확장함으로써, 치료 효과 추정이 교란 변수 추정 오류에 대해 2차 강건성을 갖도록 설계하였다. 대규모 랜덤화 실험에서 장기 꼬리 정책과 신규 정책에 대해 향상된 uplift 정확도와 안정성을 입증한다.
저자: Xinyan Su, Jiacan Gao, Mingyuan Ma
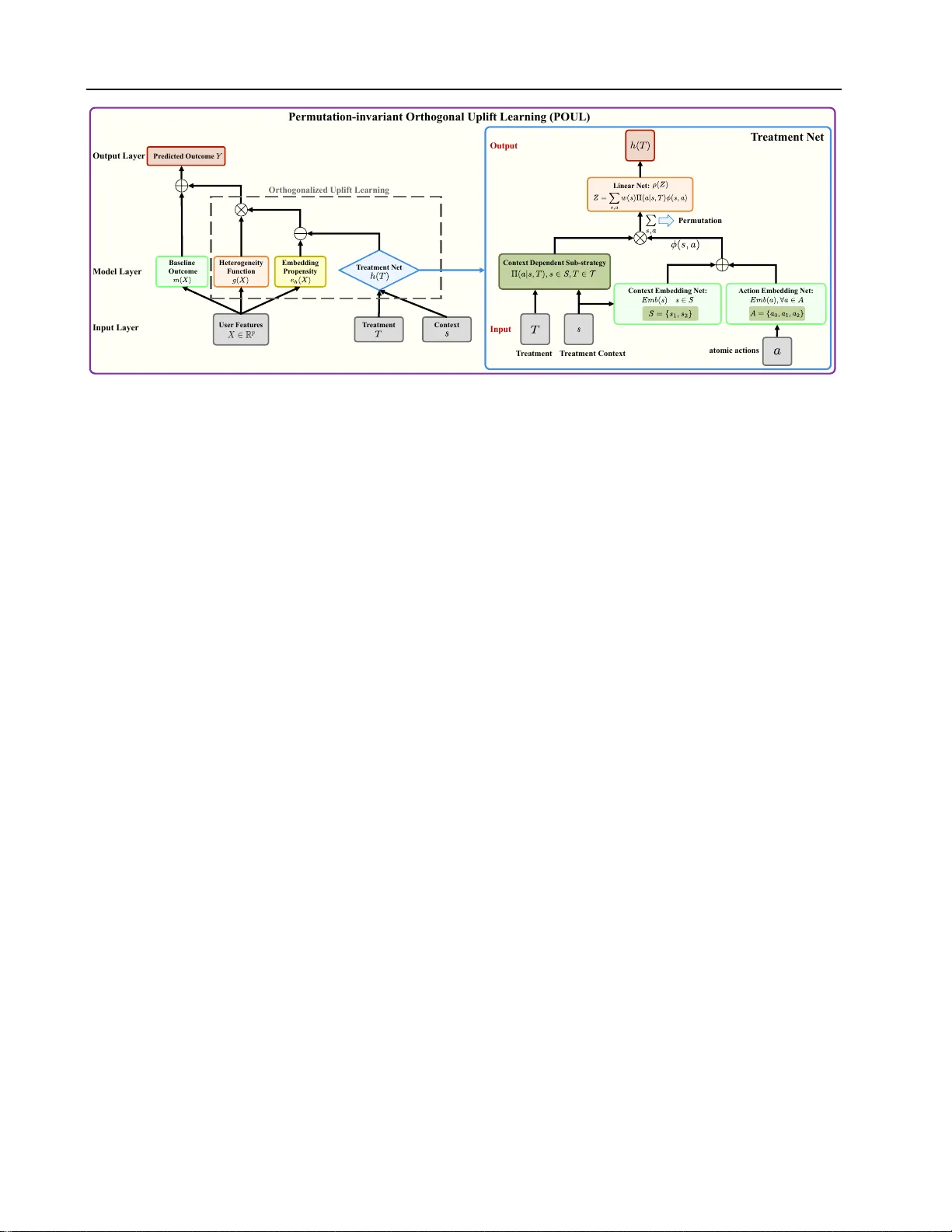
본 논문은 “조합 치료”(combinatorial treatments)라는 새로운 문제 설정을 제시한다. 전통적인 uplift(증분 효과) 추정은 이산형 혹은 저차원 치료를 전제로 하지만, 실제 산업 현장에서는 정책 형태의 복합 치료가 일반적이다. 예를 들어, 온라인 플랫폼이 사용자 세그먼트·시간·위치 등에 따라 서로 다른 쿠폰 금액을 제공하는 정책을 운영한다면, 각 정책은 여러 컨텍스트 S와 액션 A에 대한 확률 분포 Πₜ(a|s) 의 집합으로 정의된다. 이러한 정책은 재구성·재배열이 빈번하고, 새로운 정책이 기존 정책의 일부만 바꾸어 생성되는 경우가 많다. 따라서 정책을 단순히 고유 라벨이나 원-핫 인코딩으로 다루면 (1) 동일하거나 거의 동일한 정책이 서로 다른 라벨로 취급돼 통계적 효율이 떨어지고, (2) 라벨 순서 변화에 민감해 모델이 불안정해진다.
이를 해결하기 위해 저자들은 두 단계의 설계를 제안한다. 첫 번째 단계는 **순열 불변 치료 임베딩**이다. 정책 t 가 정의하는 모든 컨텍스트‑액션 원자 (s,a) 에 대해 공유 임베딩 ϕ(s,a)∈ℝᵈ를 학습한다. 정책이 각 원자에 부여하는 확률 가중치 w(s)·Πₜ(a|s) 를 이용해 선형 합 z(t)=∑_{s∈S}∑_{a∈A} w(s)Πₜ(a|s)ϕ(s,a) 를 만든다. 이 합은 순열(재인덱싱)과 순서에 대해 불변이며, 정책이 동일한 혼합을 만들면 z(t) 도 동일하다. 이어서 비선형 매핑 ρ:ℝᵈ→ℝᵈ를 적용해 최종 치료 임베딩 h(t)=ρ(z(t)) 을 얻는다. 구현상 ϕ 는 (s,a) 쌍에 대한 lookup table 혹은 s와 a에 대한 별도 임베딩의 합으로 구성될 수 있고, ρ 는 작은 MLP이다. 이 구조는 (i) 파라미터를 원자 수준에서 공유해 희소한 정책에도 통계적 힘을 전달하고, (ii) 정책 간 의미적 거리를 자연스럽게 정의한다는 장점을 가진다.
두 번째 단계는 **직교화된 로우‑랭크 uplift 모델**이다. 관측된 결과 Y 를
Y = m(X) + g(X)ᵀ
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기