Orthogonal Uplift Learning with Permutation-Invariant Representations for Combinatorial Treatments
We study uplift estimation for combinatorial treatments. Uplift measures the pure incremental causal effect of an intervention (e.g., sending a coupon or a marketing message) on user behavior, modeled as a conditional individual treatment effect. Man…
Authors: Xinyan Su, Jiacan Gao, Mingyuan Ma
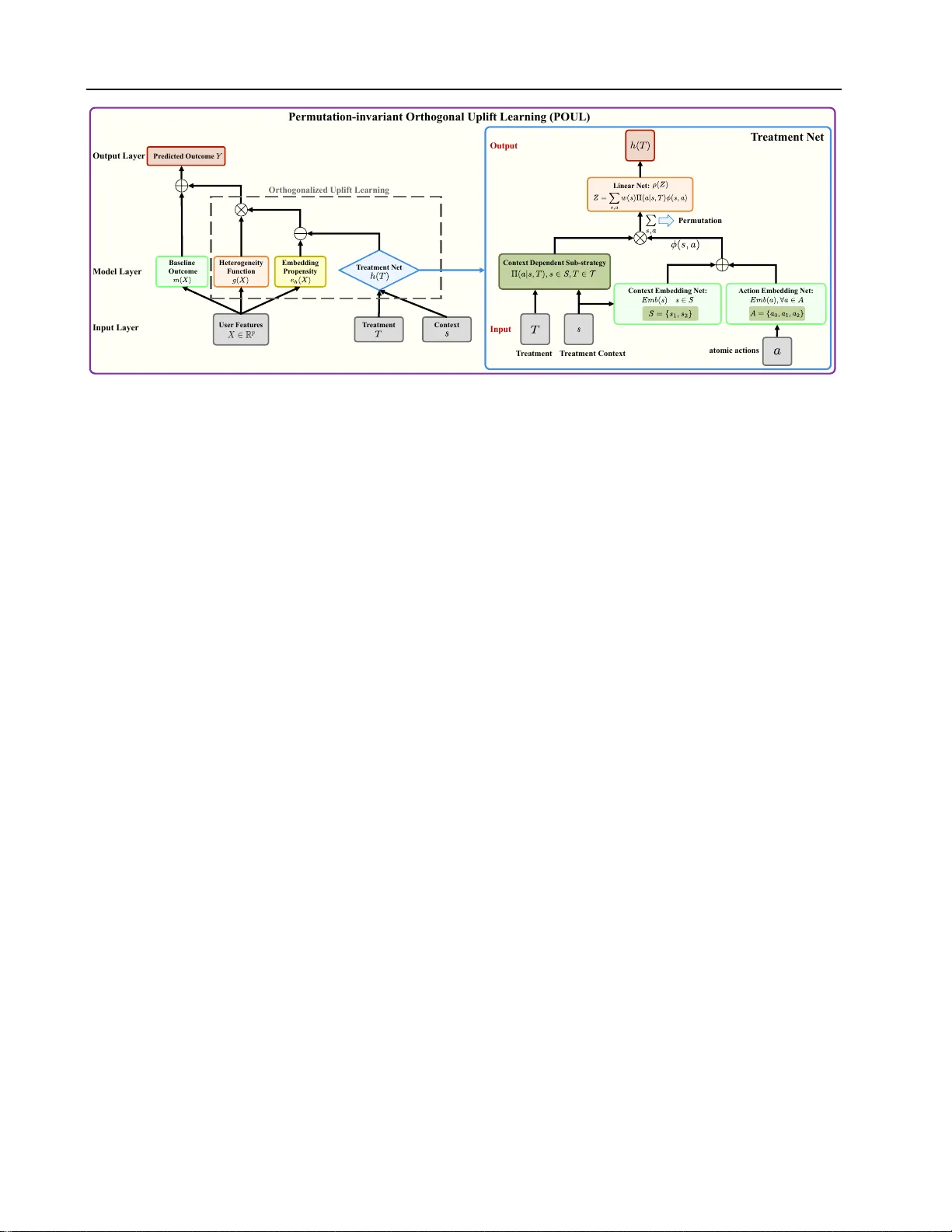
Orthogonal Uplift Learning with P ermutation-In variant Repr esentations f or Combinatorial T r eatments Xinyan Su * 1 Jiacan Gao * 2 Mingyuan Ma 3 Xiao Xu 1 Xinrui W an 1 Tianqi Gu 1 Enyun Y u 1 Jiecheng Guo 1 Zhiheng Zhang 4 5 Abstract W e study uplift estimation for combinatorial treat- ments. Uplift measures the pure incremental causal effect of an interv ention (e.g., sending a coupon or a marketing message) on user beha v- ior , modeled as a conditional individual treatment effect. Many real-world interventions are com- binatorial : a treatment is a policy that specifies context-dependent action distrib utions rather than a single atomic label. Although recent work con- siders structured treatments, most methods rely on categorical or opaque encodings, limiting rob ust- ness and generalization to rare or newly deployed policies. W e propose an uplift estimation frame- work that aligns treatment representation with causal semantics. Each policy is represented by the mixture it induces over context–action compo- nents and embedded via a permutation-in v ariant aggregation. This representation is integrated into an orthogonalized lo w-rank uplift model, extend- ing Robinson-style decompositions to learned, vector -valued treatments. W e show that the re- sulting estimator is expressi ve for policy-induced causal ef fects, orthogonally rob ust to nuisance estimation errors, and stable under small policy perturbations. Experiments on large-scale ran- domized platform data demonstrate improv ed up- lift accurac y and stability in long-tailed polic y regimes. * Equal contribution 1 Didi Chuxing, Beijing, China 2 School of Statistics, East China Normal Univ ersity , Shanghai, China 3 School of Mathematics and Statistics, Beijing Jiaotong Uni versity , Beijing, China 4 School of Statistics and Data Science, Shanghai Univ ersity of Finance and Economics, Shanghai 200433, P .R. China 5 Institute of Data Science and Statistics, Shanghai University of Finance and Economics, Shanghai 200433, P .R. China. Correspondence to: Zhiheng Zhang < zhangzhiheng@mail.shufe.edu.cn > . Pr eprint. F ebruary 24, 2026. 1. Introduction Estimating individualized causal ef fects plays a central role in data-driv en decision-making, enabling practitioners to compare alternativ e interventions and select those that max- imize expected incremental outcomes. This problem is commonly formalized through the conditional av erage treat- ment effect (CA TE), which has been extensi vely studied in statistics, econometrics, and machine learning ( Rubin , 1974 ; Imbens & Rubin , 2015 ; Athey & Imbens , 2016 ). A rich body of work has dev eloped estimation strategies for CA TE under binary or low-cardinality treatments, including meta-learners, doubly robust methods, and orthogonalized estimators ( Chernozhukov et al. , 2018 ; K ¨ unzel et al. , 2019 ; Kennedy , 2020 ). These approaches have achie ved notable success in classical A/B testing and personalization tasks. In many modern applications, ho wever , a treatment is rarely a single atomic action. Instead, it is a policy that speci- fies ho w actions are chosen across multiple treatment-side contexts, such as user segments, locations, or stages of a workflo w . For instance, an online platform may deploy a policy that assigns different incenti ve le vels depending on spatiotemporal demand conditions. Such interventions natu- rally induce a structur ed or combinatorial treatment space, where high-level treatments are composed of reusable lower - lev el components. A practical dif ficulty is that these policies are constantly recombined: a new policy is often created by changing only a fe w rules (e.g., swapping the action for one se gment). This setting differs fundamentally from standard multi-treatment problems, where treatments are modeled as unrelated categorical labels. Recent work has begun to explore structured treatments using embeddings or graph-based representations ( Bica et al. , 2020 ; Guo et al. , 2021 ), but these methods typically rely on opaque encodings that do not explicitly reflect the compositional semantics of policies. A ke y challenge in combinatorial treatment settings is that the statistical representation of treatments often fails to align with their causal meaning. In practice, policies are fre- quently iterated and implemented by dif ferent teams, lead- ing to variations in indexing, ordering, or internal identifiers. Naiv ely encoding each policy as a one-hot label treats such 1 Permutation-In variant Representations for Combinatorial T reatments Co nt ext Depend ent Sub - strat egy T r eatment T r eatment Con text Input Co ntex t E mbeddi ng Net: Act ion Embeddi ng Net : Out put Li near Net : Perm uta tio n Out put Layer Model L ayer Input Layer User Feat ur es Baseli ne Out come Heter og enei ty Functio n Embeddi ng Pr op ensity T r eat ment Co nt ext Ort hogonaliz ed Up li ft Learning T r eat ment Net T r ea tment Net Permu tation - in variant Ortho gonal Uplif t Learnin g (P OUL) Pr edic ted Out come at omic actio ns F igure 1. T reatment Net: permutation-in variant embedding of combinatorial treatments. A treatment T is observed through its policy specification: for each context s ∈ S (instantiated here as { s 1 , s 2 } ), the treatment induces a distribution ov er atomic actions a ∈ A (instantiated as { a 0 , a 1 , a 2 } ). The network first learns embeddings for contexts and actions to form atom representations ϕ ( s, a ) . These atoms are then reweighted by policy probabilities and aggregated via a permutation-inv ariant sum z ( T ) , ensuring the representation depends only on the induced mixture. Finally , a learnable map produces the treatment embedding h ( T ) , which is used by the orthogonalized uplift model (left panel) to estimate the causal effect τ ( x ) . variants as unrelated, ev en when they induce identical or nearly identical interventions or dif fer only by minor local modifications. This mismatch has two critical consequences. First, it pre vents statistical strength from being shared across related policies, exacerbating variance in long-tailed treat- ment regimes. Second, it destroys any meaningful notion of proximity between treatments, making it impossible to reason about smooth policy perturbations or to generalize to new strate gies. These issues arise simultaneously in theory and practice, and cannot be resolv ed by simply increasing model capacity . Motiv ated by these observ ations, we adopt the perspectiv e that a polic y af fects outcomes primarily through the mixture it induces o ver conte xt–action components. Under this vie w , the identity or ordering of internal identifiers is irrele vant; what matters is ho w often, and under which contexts, each atomic action is realized in the population. This perspec- tiv e suggests that treatment representations should respect natural symmetries of policies, including in variance to re- indexing and ordering, while enabling principled parameter sharing across reusable components. Formally , each policy induces a probability measure over context–action atoms, and causal effects depend on this induced mixture rather than on arbitrary labels or orderings. This idea resonates with recent adv ances in in variant and equi variant learning, where respecting known symmetries is essential for gen- eralization ( Zaheer et al. , 2017 ; K ondor & Tri vedi , 2018 ). Howe ver , its implications for causal effect estimation under structured policy treatments ha ve not been fully explored. Building on this principle, we propose a framew ork for up- lift estimation under combinatorial treatments that combines two ke y ingredients. First, we introduce a permutation- in variant treatment embedding that represents a policy by aggregating learned embeddings of its conte xt–action com- ponents via a commutati ve sum. This construction ensures in variance to re-inde xing and ordering, while enabling pa- rameter sharing across a large treatment space. Second, we embed this representation into an orthogonalized lo w- rank uplift model, extending the Robinson decomposition to vector -valued treatments. Orthogonalization removes first- order sensitivity to nuisance components, yielding robust- ness properties analogous to those in double/debiased ma- chine learning ( Robins & Rotnitzk y , 1994 ; Chernozhukov et al. , 2018 ). Our analysis establishes that the proposed embedding family is expressi ve enough to approximate any continuous causal functional of the policy-induced mixture. Moreov er, the orthogonalized formulation guarantees that errors in base- line outcome re gression and treatment propensity estimation enter the CA TE estimator only at second order . Crucially , the representation induces a natural metric on policy space under which both the embedding and the implied uplift are stable. This provides a principled explanation for empirical generalization to rare or pre viously unseen policy variants, a phenomenon that categorical treatment representations cannot capture. From a practical perspectiv e, these prop- erties are essential in lar ge-scale experimentation systems characterized by frequent policy iteration and severe data imbalance. Our main contrib utions are as follo ws: 1) W e for- malize individualized uplift estimation under combinatorial tr eatments , modeling each treatment as a context-dependent policy composed of reusable context–action components. 2) 2 Permutation-In variant Representations for Combinatorial T reatments W e propose a permutation-inv ariant treatment embedding that aligns statistical representation with causal semantics and enables information sharing and generalization across large policy spaces. 3) W e integrate this representation with an orthogonalized lo w-rank uplift model and estab- lish second-order robustness to nuisance estimation errors. 4) W e validate the framew ork on large-scale randomized experiments, demonstrating impro ved uplift accurac y and stability , including strong performance in long-tailed and held-out treatment regimes. 2. Problem Setup and Method W e hav e i.i.d. data D = { ( X i , T i , Y i ) } n i =1 , where X i ∈ R p are unit co variates, T i ∈ T is a structured treatment (polic y) drawn from a finite (possibly large) set, and Y i ∈ R is the outcome. Let Y ( t ) denote the potential outcome under treatment t ∈ T . For an y x and any pair ( t 1 , t 0 ) , we define the individualized uplift as the conditional treatment ef fect τ ( x ; t 1 , t 0 ) := E [ Y ( t 1 ) − Y ( t 0 ) | X = x ] . (1) At the unit lev el, the (unobservable) individual treatment ef- fect is τ i ( t 1 , t 0 ) := Y i ( t 1 ) − Y i ( t 0 ) . Throughout, τ ( x ; t 1 , t 0 ) is the estimand (the standard CA TE); in experiments we refer to the pointwise prediction ˆ τ ( X i ; t 1 , t 0 ) as an “ITE” score for brevity . Assumption 2.1. (SUTV A for RCT) Our main setting is ran- domized assignment. W e assume (i) consistency/SUTV A, (ii) randomized treatment assignment conditional on X , and (iii) overlap. Under these conditions, τ ( x ; t 1 , t 0 ) is identi- fied from D . 2.1. Structured T reatment Representation T reatment-side contexts and atomic actions. W e assume each policy operates through a finite set of treatment-side contexts S and a finite set of atomic actions A . A policy t ∈ T is specified by a collection of context-dependent sub- strategies { Π t ( · | s ) } s ∈S , where each sub-strategy Π t ( · | s ) is a distribution o ver actions in A . W e treat { Π t ( · | s ) } s ∈S as the observ able specification of a structured treatment. W e also allow nonnegati ve context weights w ( s ) ≥ 0 that capture the relati ve exposure frequency or importance of context s (e.g., segment pre valence), w ( · ) can be fixed from logs, domain knowledge or estimated. Permutation-in variant treatment embedding. Let ϕ : S × A → R d be an embedding of a context–action atom and let ρ : R d → R d be a learnable map. W e define an intermediate aggregated representation h ( t ) ∈ R d : z ( t ) = X s ∈S X a ∈A w ( s ) Π t ( a | s ) ϕ ( s, a ) , (2) h ( t ) = ρ ( z ( t )) . (3) This construction is in variant to any re-indexing or re- ordering of the underlying context–action components, and enables parameter sharing across policies through the shared atom embedding ϕ . Implementation of the tr eatment network. In practice, ϕ ( s, a ) is parameterized as a lookup table ov er ( s, a ) (or a sum of separate embeddings for s and a ), and ρ ( · ) is a small MLP (optionally with normalization). The cost of computing h ( t ) is O ( |S ||A| d ) per policy if done directly , and can be reduced by caching { ϕ ( s, a ) } and exploiting sparsity in Π t ( · | s ) . 2.2. Orthogonalized Factorized Uplift Model Model class. W e consider Neyamen decomposition fol- lowing ( Kaddour et al. , 2021 ): Y = m ( X ) + g ( X ) ⊤ h ( T ) − e h ( X ) + ε, e h ( X ) := E [ h ( T ) | X ] , (4) where m : R p → R is a baseline outcome regression model and g : R p → R d captures treatment effect heterogeneity . Under ( 4 ), the implied uplift is τ ( x ; t 1 , t 0 ) = g ( x ) ⊤ h ( t 1 ) − h ( t 0 ) . (5) W e refer to this as “factorized” (or rank- d ) since the ef fect depends on ( x, t ) only through the inner product between g ( x ) and h ( t ) . Learning objecti ve. Let m θ , g η , ϕ ω , and ρ ν parameterize m, g , ϕ, ρ , and define h ω ,ν by ( 2 ) – ( 3 ) . W e estimate parame- ters by empirical risk minimization: min θ,η ,ω ,ν 1 n n X i =1 ℓ Y i , m θ ( X i ) + g η ( X i ) ⊤ h ω ,ν ( T i ) − ˆ e h ( X i ) + λ Ω( θ , η , ω , ν ) , (6) where ℓ is a prediction loss (e.g., squared loss or negativ e log-likelihood) and Ω is a re gularizer . Computing ˆ e h ( x ) . A ke y term in ( 4 ) is e h ( x ) = E [ h ( T ) | X = x ] , which we approximate by ˆ e h ( x ) . Let the propen- sity of treatment t be π 0 ( t | x ) := P ( T = t | X = x ) . T wo cases are considered. 1) RCT Study . In the common case of complete randomization, treatment assignment is independent of cov ariates, i.e., T ⊥ X . Then e h ( x ) is a constant vector: e h ( x ) = E [ h ( T ) | X = x ] = E [ h ( T )] . Accordingly , we estimate it by the empirical mean of h ( T ) ov er the experiment data (or by a running mean in mini- batch SGD, as in Algorithm 1 ). More generally , under strati- fied or co variate-adapti ve randomization, π 0 ( t | x ) is known and may depend on x through the stratum; in that case we 3 Permutation-In variant Representations for Combinatorial T reatments Algorithm 1 Permutation - in variant Orthogonal Uplift Learning (POUL) Require: Full data D all = { ( X i , Y i ) } ; Experiment data D exp = { ( X i , T i , Y i ) } ; treatment-side contexts S ; atomic actions A ; Policy specification { Π t ( a | s ) } t ∈T , s ∈S , a ∈A ; weights w ( · ) ; loss ℓ ; regularizer Ω and weight λ ; learning rate γ 1: Stage 1: fit outcome regr ession model. 2: Initialize m θ and train m θ on D all by minimizing 1 |D all | P ℓ m θ ( X i ) , Y i 3: Freeze ˆ m ( · ) ← m θ ( · ) 4: Stage 2: train orthogonalized uplift model. 5: Initialize ( η , ω , ν ) for g η , ϕ ω , ρ ν 6: Initialize running mean ¯ h ∈ R d ← 0 , counter c ← 0 7: for each SGD step do 8: Sample a mini-batch B ⊂ D exp 9: for each ( X i , T i , Y i ) ∈ B do 10: Compute treatment embedding (permutation- in variant aggre gation): z i ← P s ∈S P a ∈A w ( s ) Π T i ( a | s ) ϕ ω ( s, a ) , h i ← ρ ν ( z i ) 11: Compute tw o nets: ˆ m i ← ˆ m ( X i ) , g i ← g η ( X i ) 12: Update ˆ e h ( x ) (replace this term by the correspond- ing cases described in Sec. 2.2 ): ˆ e h ( X i ) ← ¯ h 13: Predict: ˆ Y i ← ˆ m i + g ⊤ i h i − ˆ e h ( X i ) 14: end for 15: Get loss: L ← 1 |B| P ( X i ,T i ,Y i ) ∈B ℓ ( ˆ Y i , Y i ) + λ Ω( η , ω , ν ) 16: SGD update: ( η , ω , ν ) ← ( η , ω , ν ) − γ ∇L 17: Update ¯ h using current batch embeddings: ¯ h ← c ¯ h + P ( X i ,T i ,Y i ) ∈B h i c + |B| , c ← c + |B | 18: end for 19: retur n ˆ τ ( x ; t 1 , t 0 ) = g ˆ η ( x ) ⊤ h ˆ ω, ˆ ν ( t 1 ) − h ˆ ω, ˆ ν ( t 0 ) set ˆ e h ( x ) = P t ∈T π 0 ( t | x ) h ( t ) . 2) Observational Study . When treatment assignment is not randomized, e h ( x ) gen- erally varies with x and π 0 ( t | x ) is unknown. W e estimate a propensity model ˆ π ( t | x ) ≈ π 0 ( t | x ) and plug it in: ˆ e h ( x ) = P t ∈T ˆ π ( t | x ) h ( t ) . When |T | is large, the sum can be approximated by sampling treatments from ˆ π ( · | x ) . T raining Procedur e W e train POUL via a two-stage or - thogonal learning procedure (Algorithm 1 ). In stage 1 (lines 1-3), we fit a base predictor m ( x ) ≈ E [ Y | X = x ] using all av ailable data, which can be a DNN network, or Dragonet ( Shi et al. , 2019 ). This stage lev erages the largest possible sample to obtain a stable estimate of the main outcome sig- nal, independent of treatment structure. After training, we treat ˆ m ( · ) as fixed in the second stage. In stage 2 (lines 4-18), we learn the heterogeneous uplift component on the experiment population where policies are actually assigned and observed. Given a policy t , we compute its treatment embedding h ( t ) by aggregating context–action atoms in- duced by its context-specific sub-str ategies { Π t ( · | s ) } s ∈S and context weights w ( s ) : we first form the mixture rep- resentation z ( t ) = P s ∈S P a ∈A w ( s )Π t ( a | s ) ϕ ( s, a ) and then apply a learnable map h ( t ) = ρ ( z ( t )) (line 10). The aggregation is permutation-in variant to any re-inde xing or re-ordering of contexts/actions, ensuring that two seman- tically identical policies (i.e., inducing the same mixture ov er atoms) hav e the same representation and preventing spurious dependence on arbitrary IDs or ordering. W e fit the heterogeneity function g ( x ) and the treatment embedding parameters by minimizing an orthogonalized loss based on the residualized outcome Y − ˆ m ( X ) and the residualized treatment representation h ( T ) − ˆ e h . In our main RCT setting with complete randomization, treatment assignment is inde- pendent of cov ariates ( T ⊥ X ), so we estimate e h by the em- pirical mean of h ( T ) ov er the experiment population (or an equiv alent running estimate during training). This yields the final uplift estimator ˆ τ ( x ; t 1 , t 0 ) = ˆ g ( x ) ⊤ ˆ h ( t 1 ) − ˆ h ( t 0 ) . 2.3. T echnical Challenges Semantic in variance under re-indexing of structur ed policies. In practice, a policy is specified by a collection of context-specific sub-strate gies { Π t ( · | s ) } s ∈S , where the in- dexing and ordering of contexts/actions can be arbitrary and may change across deployments. A treatment representation that depends on such ordering can introduce spurious dif- ferences and hurt robustness when policies are re-serialized, updated, or composed from the same b uilding blocks. Our mixture-based construction in ( 2 ) is permutation-in variant, so the embedding depends only on the induced mixture o ver context–action atoms, aligning representation with causal semantics. Long-tailed policies, limited overlap, and cold-start vari- ants. In large combinatorial treatment spaces, full overlap ov er complete policies is unrealistic: many policies are rare, newly created, or observed only in a few strata. T reating each policy as a cate gorical label leads to high-variance ef- fect estimates and poor generalization in long-tailed regimes. POUL mitigates this by sharing parameters across reusable context–action components through the shared atom embed- ding ϕ ( s, a ) and the in variant aggre gation in ( 2 ) , so estima- tion depends more on component coverage than repeated exposure to identical full policies. This parameter sharing enables rare or new policies to borrow statistical strength from frequent ones and improv es stability under small pol- icy perturbations. In practice, we further improv e stability using standard techniques such as propensity clipping (for observational data), restricting ev aluation to regions with sufficient support, and re gularizing the treatment embedding to av oid extrapolation from extremely sparse components. Noisy weights and scalable computation of mixture em- 4 Permutation-In variant Representations for Combinatorial T reatments beddings. Context weights w ( s ) may be noisy proxies of exposure frequenc y or importance, and directly computing ( 2 ) scales with |S ||A| per polic y . In practice, w ( · ) can be es- timated from logs or domain knowledge, and we empirically assess robustness under imperfect weights. For efficienc y , we cache ϕ ( s, a ) and exploit sparsity in Π t ( · | s ) to reduce computation, making training feasible at scale. 3. Theoretical Analysis Combinatorial policies induce high-dimensional treatments: each t ∈ T specifies a collection of context-wise action distributions { Π t ( · | s ) } s ∈S . Our analysis answers three questions that are fundamental for making causal inference tractable in this regime: 1. Expressi veness (representation). Can the proposed permutation-in variant embedding h ( t ) capture a broad class of polic y effects that depend on t only through its induced context–action mixture? (Theorem 3.3 .) 2. Orthogonal robustness (estimation). When uplift is learned via the orthogonalized lo w-rank model ( 4 ) , how do nuisance estimation errors (e.g., baseline and embedding propensity) enter the final CA TE error? W e sho w a second-order (product-form) dependence typical of double/debiased ML. (Theorem 3.6 .) 3. Stability (generalization). If a ne w/rare policy t ′ dif- fers only slightly in its specification Π t ′ ( · | s ) , does the learned embedding (and hence predicted uplift) vary smoothly rather than jumping arbitrarily? W e prove a Lipschitz-type stability bound in a natural distance ov er policy specifications. (Proposition 3.7 .) T ogether , these results formalize why (i) the embedding is not ad-hoc, (ii) orthogonalization protects uplift learning from nuisance errors, and (iii) the method can generalize across combinatorial treatments beyond those frequently observed. For preparation, we introduce policy-induced mixtures as a suf ficient causal interface. Recall the context weights w ( s ) ≥ 0 with P s ∈S w ( s ) = 1 and define α t ( s, a ) := w ( s ) Π t ( a | s ) , ( s, a ) ∈ S × A . (7) The collection { α t ( s, a ) } s,a is a probability mass function ov er S × A . W e denote by µ t the corresponding discrete probability measure on S × A , i.e., µ t ( { ( s, a ) } ) = α t ( s, a ) . Assumption 3.1 (Polic y-induced mixture suf ficiency) . There exist measurable functions m 0 : R p → R , g 0 : R p → R d , and a (possibly unkno wn) functional F mapping mea- sures on S × A to R d such that for all x ∈ R p and all t ∈ T , E [ Y ( t ) | X = x ] = m 0 ( x ) + g 0 ( x ) ⊤ F ( µ t ) . (8) Moreov er, F is continuous on { µ t : t ∈ T } under the ℓ 1 /total-variation topology , i.e., if ∥ µ − µ ′ ∥ 1 → 0 then ∥ F ( µ ) − F ( µ ′ ) ∥ → 0 . Assumption 3.1 says that a policy affects outcomes only through the mixtur e it induces ov er context–action atoms. This matches the reality of many platform interventions. For example, in ride-hailing marketplaces, a policy may specify (for each spatiotemporal context s ) a distribution o ver incen- ti ve actions a (e.g., bonus le vels or pricing multipliers). The realized user experience aggregates o ver contexts according to exposure weights w ( s ) ; thus it is the induced mixture µ t —not an arbitrary index ordering of contexts/actions— that governs the causal response. Also, Assumption 3.1 implies our orthogonalized model class ( 4 ) is well-specified as follows (up to reparametrization). Proposition 3.2 (W ell-specified orthogonalized low-rank representation) . Under Assumption 3.1 and consistency Y = Y ( T ) , define the oracle treatment r epr esentation h 0 ( t ) := F ( µ t ) and e 0 ( x ) := E [ h 0 ( T ) | X = x ] . Then ther e exists a function m ( · ) such that the conditional mean satisfies E [ Y | X , T ] = m ( X ) + g 0 ( X ) ⊤ h 0 ( T ) − e 0 ( X ) , m ( x ) := m 0 ( x ) + g 0 ( x ) ⊤ e 0 ( x ) , (9) and the CA TE defined in ( 1 ) obeys τ ( x ; t 1 , t 0 ) = g 0 ( x ) ⊤ h 0 ( t 1 ) − h 0 ( t 0 ) . (10) Proposition 3.2 clarifies a ke y boundary: the orthogonalized decomposition ( 4 ) is not an additional restriction beyond ( 8 ) ; it is a reparametrization that is con venient for debi- ased/orthogonal learning. In particular , the causal estimand depends on ( g 0 , h 0 ) but not on the nuisance pair ( m, e 0 ) . 3.1. Expressi veness of the Permutation-In variant P olicy Embedding W e no w show that the embedding family ( 2 ) – ( 3 ) is ex- pressiv e enough to approximate any continuous functional F ( µ t ) of the policy-induced mixture. Given maps ϕ : S × A → R r and ρ : R r → R d , define z ϕ ( t ) = X s ∈S X a ∈A α t ( s, a ) ϕ ( s, a ) , h ϕ,ρ ( t ) = ρ ( z ϕ ( t )) . (11) This construction is permutation-in variant to any re- indexing of S × A because it depends on { ( s, a, α t ( s, a )) } only through a weighted sum. Lemma 3.3 (Expressi veness of permutation-in variant em- beddings) . Under Assumption 3.1 , conditioning that S and A ar e finite and let M := { µ t : t ∈ T } ⊂ ∆( S × A ) . Let F : M → R d be continuous. Then for any ε > 0 , ther e exist an inte ger r and functions ϕ : S × A → R r 5 Permutation-In variant Representations for Combinatorial T reatments and ρ : R r → R d (such that ρ can be implemented by a standar d universal appr oximator , e.g ., a ReLU MLP) for which sup t ∈T F ( µ t ) − h ϕ,ρ ( t ) ≤ ε. (12) Theorem 3.3 justifies the representation choice in ( 2 ) – ( 3 ) : if the causal response of a policy depends on t only through the induced mixture over context–action atoms, then our embedding family can approximate that dependence arbi- trarily well. In other words, the proposed h ( t ) is a principled “policy featurization” rather than a heuristic encoding. For example, consider a policy that assigns high incentives in peak Beijing and zero incentives in of f-peak Shanghai. T wo engineering implementations may store this policy using dif- ferent context orderings or action identifiers. A categorical policy-ID representation would treat them as unrelated treat- ments, while our permutation-in variant embedding maps both specifications to the same representation, as they in- duce the same context–action mixture. Consequently , the implied uplift is identical, as required by causal semantics. Notew orthy , such a representation capacity statement does not claim: (i) causal identification without Assumption 3.1 and the usual causal conditions (SUTV A/o verlap), (ii) that the required dimension r is always small, or (iii) that op- timization will always find the approximating parameters. These are separate issues (identification, statistical rates, and optimization) from expressi veness. Also, the skepti- cism arises that “If S × A is finite , isn’ t this just a fancy way of learning F ( α ) with an MLP? Why do we need the embed- ding structur e at all?” It highlights what our contrib ution r eally is: we are not merely encoding α t ; we are enforcing a compositional inductive bias (shared atom embeddings ϕ ( s, a ) and permutation-inv ariant aggregation). This bias is what enables (i) parameter sharing across policies, (ii) meaningful continuity in policy space (formalized in Propo- sition 3.7 ), and (iii) practical scaling when T is huge but S × A has structure. Having established that the embedding family can represent the causal policy ef fect under Assumption 3.1 , we now turn to estimation: how does orthogonalization protect uplift learning from nuisance estimation errors? 3.2. Orthogonal Robustness Let π 0 ( t | x ) := P ( T = t | X = x ) be the (known or estimable) assignment/propensity . Let h 0 be the oracle representation from Proposition 3.2 and define e 0 ( x ) := E [ h 0 ( T ) | X = x ] = P t ∈T π 0 ( t | x ) h 0 ( t ) . The orthogo- nalized regression form ( 4 ) suggests learning g ( · ) and h ( · ) from residualized signals ( Y − m ( X )) and ( h ( T ) − e h ( X )) . For theory , we analyze the standard cross-fitted variant that isolates nuisance estimation. (In experimental design with known π 0 , the propensity step is omitted; the same analy- sis applies with smaller nuisance error .) Let { I k } K k =1 be a partition of { 1 , . . . , n } . Define the Neyman orthogonality score ψ ( W ; g , h, m, e ) := Y − m ( X ) − g ( X ) ⊤ ( h ( T ) − e ( X )) ( h ( T ) − e ( X )) where W := ( X, T , Y ) . W e recall its first-order inv ariance as follows. Lemma 3.4 (Neyman orthogonality w .r .t. nuisance ( m, e ) ) . Assume the model ( 4 ) holds with some ( m 0 , g 0 , h 0 , e 0 ) and E [ ε | X , T ] = 0 , where e 0 ( x ) = E [ h 0 ( T ) | X = x ] . Then E ψ ( W ; g 0 , h 0 , m 0 , e 0 ) = 0 , and the Gateaux derivative of E [ ψ ( W ; g 0 , h 0 , m, e )] in the direction of perturbations ( δ m, δ e ) vanishes at ( m, e ) = ( m 0 , e 0 ) : d dr r =0 E h ψ ( W ; g 0 , h 0 , m 0 + r δ m, e 0 + r δ e ) i = 0 . Lemma 3.4 is the formal statement of “nuisance errors do not affect the target to first order . ” It is exactly the property exploited by debiased/double machine learning. Additionally , considering its second-order , we now state a pointwise robustness guarantee in the spirit of DML er- ror expansions. Below , for a (vector -valued) function f we use ∥ f ∥ 2 := ( E ∥ f ( W ) ∥ 2 ) 1 / 2 , and for h ( · ) we use ∥ h − ˜ h ∥ ∞ := sup t ∈T ∥ h ( t ) − ˜ h ( t ) ∥ . Assumption 3.5 (Regularity for orthogonal rob ustness) . 1. (Bounded moments) E [ Y 2 ] < ∞ and sup t ∈T ∥ h 0 ( t ) ∥ < ∞ , and E [ ∥ g 0 ( X ) ∥ 2 ] < ∞ . 2. (Overlap) There exists c > 0 s.t. π 0 ( t | x ) ≥ c for all t ∈ T and a.e. x . 3. (Cross-fitting) Nuisance estimates ( ˆ m ( − k ) , ˆ π ( − k ) ) are fit on data independent of fold I k . 4. (Estimation errors) Define δ m := ∥ ˆ m − m 0 ∥ 2 , δ e := ∥ ˆ e − e 0 ∥ 2 , δ g ( x ) := ∥ ˆ g ( x ) − g 0 ( x ) ∥ , and δ h := ∥ ˆ h − h 0 ∥ ∞ . Assume these quantities are o p (1) . Theorem 3.6 (Orthogonal robustness: nuisance er- rors enter at second order) . Suppose Assumption 3.5 holds. Let ˆ τ ( x ; t 1 , t 0 ) = ˆ g ( x ) ⊤ ( ˆ h ( t 1 ) − ˆ h ( t 0 )) be the estimator r eturned by Algorithm 1 . Then for any fixed x and ( t 1 , t 0 ) , ˆ τ ( x ; t 1 , t 0 ) − τ ( x ; t 1 , t 0 ) = error(g)+error(h)+error(second order) , wher e error(g) := ( ˆ g ( x ) − g 0 ( x )) ⊤ h 0 ( t 1 ) − h 0 ( t 0 ) , error(h) := g 0 ( x ) ⊤ ( ˆ h − h 0 )( t 1 ) − ( ˆ h − h 0 )( t 0 ) and error(second order) := O p ( δ m + δ h + sup x δ g ( x )) δ e . In particular , the nuisance pair ( m, e ) affects the CA TE only thr ough the pr oduct term ( δ m + δ h + sup x δ g ( x )) δ e , i.e., ther e is no first-or der (linear) sensitivity to δ m or δ e . Theorem 3.6 explains why orthogonalization is essential in large-scale polic y learning: ev en when baseline regression m and embedding propensity e are estimated with complex 6 Permutation-In variant Representations for Combinatorial T reatments ML models, their errors do not linearly bias the uplift es- timator; they only contrib ute as a product (second-order term). This is precisely the regime where DML is powerful: nuisance learners can be high-capacity without destabilizing the target. As a concrete special case, if δ m = o p ( n − 1 / 4 ) and δ e = o p ( n − 1 / 4 ) , then δ m δ e = o p ( n − 1 / 2 ) and the nuisance con- tribution becomes ne gligible compared with typical 1 / √ n sampling fluctuations (mirroring classical DML conditions). Expressiv eness (Theorem 3.3 ) and orthogonal robustness (Theorem 3.6 ) address what we can represent and how we can estimate it robustly . W e next address why this represen- tation supports generalization across rare/unseen combina- torial policies: small changes in policy specification lead to small changes in h ( t ) and thus in uplift. 3.3. Stability Under Policy P erturbations A natural metric on policy specifications. Define the weighted ℓ 1 distance between policies by d Π ( t, t ′ ) := X s ∈S w ( s ) Π t ( · | s ) − Π t ′ ( · | s ) 1 . (13) This distance measures ho w much the context-wise action distributions change, averaged by context exposure w ( s ) . Note that d Π ( t, t ′ ) = ∥ µ t − µ t ′ ∥ 1 under the identification µ t ( s, a ) = w ( s )Π t ( a | s ) . Proposition 3.7 (Stability of the embedding and uplift) . As- sume ρ is L ρ -Lipschitz, i.e., ∥ ρ ( u ) − ρ ( v ) ∥ ≤ L ρ ∥ u − v ∥ for all u, v , and the atom embedding is bounded: sup ( s,a ) ∥ ϕ ( s, a ) ∥ ≤ B . Then for any t, t ′ ∈ T , ∥ h ( t ) − h ( t ′ ) ∥ ≤ L ρ ∥ z ( t ) − z ( t ′ ) ∥ ≤ L ρ B d Π ( t, t ′ ) . (14) If mor eover ∥ g 0 ( x ) ∥ ≤ G for the x of inter est, then the (oracle) uplift satisfies τ ( x ; t, t ′ ) = g 0 ( x ) ⊤ ( h 0 ( t ) − h 0 ( t ′ )) ≤ G ∥ h 0 ( t ) − h 0 ( t ′ ) ∥ ≤ G L ρ B d Π ( t, t ′ ) . Proposition 3.7 turns an empirical phenomenon into a princi- pled statement: in combinatorial treatment problems, tr eat- ments ar e not isolated labels ; they come with a structured specification Π t . Our embedding respects this structure and yields a continuity guarantee: if a new polic y t ′ differs from a kno wn policy t only slightly (in d Π ), then both the learned representation and the implied uplift change only slightly . This provides a theoretical e xplanation for why the method can extrapolate to rare/unseen policies that are nearby in specification space . A common misconception is that “Any neural network can be made Lipschitz; isn’t this trivial?” The nontrivial part is which input space the Lipschitzness is defined on . Here it is defined on the policy specification distance d Π , which is meaningful for combinatorial policies and unav ailable to methods that treat t as a categorical ID. A categorical- ID model has no reason to behav e smoothly as a policy is perturbed, because “nearby” has no definition in that representation. Concluding above, Assumption 3.1 provides a structural interface: policies act through induced context–action mix- tures. Theorem 3.3 then guarantees that our permutation- in variant embedding f amily is rich enough to approximate the corresponding causal functional F ( µ t ) . Giv en such an embedding, Theorem 3.6 sho ws that orthogonalized learn- ing yields a CA TE estimator whose dependence on nuisance errors is second order , aligning with the core promise of dou- ble machine learning. Finally , Proposition 3.7 explains how the representation supports generalization across combina- torial policies: small specification perturbations translate to controlled changes in embeddings and uplift. 4. Experiments In this section, we conduct comprehensive e xperiments to validate the effecti veness of our proposed POUL frame- work. Through rigorous ev aluations on large-scale indus- trial datasets, we demonstrate that POUL achiev es superior Individual T reatment Effect (ITE) estimation and enhanced robustness ag ainst selection bias compared to competiti ve baselines. All comprehensiv e implementation details and experimental setups are pro vided in Appendix C . 4.1. Experimental Design Datasets. W e ev aluate our framework on a large-scale ride-hailing dataset with user features ( p = 723 ). The analy- sis spans two population scopes: a Global pool of 3,820,637 users and a Core Eligible subset of 897,946 users satisfying the inclusion criteria for service class upgrades. The treat- ment space comprises T 1 ( Economy-to-Expr ess ) and a com- posite T 2 ( Discount-to-Economy + Economy-to-Expr ess ). Crucially , treatment triggering is contingent upon the inter- section of user opt-ins and specific operational scenario con- straints. Upon satisfying these conditions, v alid Economy- to-Expr ess requests are stochastically assigned to T 1 or T 2 , whereas Discount-to-Economy requests exclusi vely trigger T 2 , introducing structural dependencies between user intent, en vironmental context, and treatment assignments. Fur - thermore, we simultaneously model two distinct outcomes. Monthly Gr oss Mer chandise V alue ( GM V ) serves as an observable m o nthly surrogate for the user’ s Lifetime V alue ( LT V ), while Monthly Cost ( C ost ) e xplicitly quantifies the monthly operational expenditure incurred by the class upgrade treatment. Baselines. W e compare our proposed method against rep- resentativ e baselines, including the non-parametric Causal For est ( W ager & Athey , 2018 ), and three deep learn- 7 Permutation-In variant Representations for Combinatorial T reatments T able 1. Combined Estimation Performance. Comparison of A UUC ( ↑ ) and MAPE ( ↓ ) for both GMV (Panel A) and Cost (Panel B) estimation tasks. The results are reported across Global ( D G ) and Core ( D C ) populations. Best results are bolded . D AT A S E T G L O B A L P O P U L A T I O N ( D G ) C O R E P O P U L A T I O N ( D C ) M E T R I C S T R E AT M E N T 1 ( T 1 ) T R E AT M E N T 2 ( T 2 ) T R E AT M E N T 1 ( T 1 ) T R E AT M E N T 2 ( T 2 ) AU U C ↑ M A P E ↓ AU U C ↑ M A P E ↓ AU U C ↑ M A P E ↓ AU U C ↑ M A P E ↓ P A N E L A : G M V ( L T V ) E S T I M ATI O N R A N D O M 0 . 5 0 0 – 0 . 5 0 0 – 0 . 5 0 0 – 0 . 5 0 0 – C AU S A L F O R E S T 0 . 6 1 1 1 . 0 0 0 0 . 6 3 2 1 . 8 5 0 0 . 5 3 6 1 . 0 8 6 0 . 5 3 6 0 . 8 3 6 D E S C N 0 . 5 1 4 2 . 1 5 6 0 . 5 9 7 0 . 9 7 7 0 . 5 9 6 1 . 2 5 6 0 . 5 9 1 1 . 1 6 7 D R C F R 0 . 6 6 0 0 . 7 7 9 0 . 6 1 2 3 . 3 8 9 0 . 6 2 2 0 . 8 8 8 0 . 5 6 6 0 . 7 1 3 T - L E A R N E R 0 . 5 8 1 3 . 3 1 0 0 . 6 3 9 2 . 7 1 1 0 . 5 8 5 2 . 4 8 7 0 . 5 6 3 1 . 4 2 6 P O U L ( O U R S ) 0 . 8 2 6 1 . 3 3 3 0 . 6 3 5 1 . 3 8 6 0 . 7 9 2 1 . 5 7 0 0 . 6 9 0 2 . 0 2 3 P A N E L B : C O S T E S T I M ATI O N R A N D O M 0 . 5 0 0 – 0 . 5 0 0 – 0 . 5 0 0 – 0 . 5 0 0 – C AU S A L F O R E S T 0 . 6 9 2 0 . 7 9 2 0 . 6 9 7 0 . 8 8 1 0 . 5 7 6 0 . 9 4 6 0 . 5 9 6 0 . 9 6 9 D E S C N 0 . 7 3 5 0 . 1 1 3 0 . 7 7 7 0 . 4 0 9 0 . 6 0 8 0 . 1 0 3 0 . 6 4 1 0 . 4 5 6 D R C F R 0 . 7 1 5 0 . 3 6 4 0 . 7 5 3 0 . 6 0 7 0 . 5 8 6 0 . 1 7 7 0 . 6 4 1 0 . 3 4 4 T - L E A R N E R 0 . 7 3 9 0 . 2 2 1 0 . 7 7 7 0 . 3 1 6 0 . 6 1 6 0 . 1 9 1 0 . 6 4 5 0 . 4 4 5 P O U L ( O U R S ) 0 . 7 3 5 0 . 8 3 8 0 . 9 1 7 0 . 7 5 5 0 . 7 3 6 0 . 8 4 4 0 . 9 1 6 0 . 7 6 9 ing methods implemented with an MLP backbone: T - Learner ( K ¨ unzel et al. , 2019 ) (implemented via distinct DNN heads to separately ev aluate and optimize the re- gression loss for the treatment and control groups), DE- SCN ( Zhong et al. , 2022 ), and DRCFR ( Cheng et al. , 2022 ). Evaluation Metrics. T o ev aluate the ef fectiveness of POUL, we employ two standard metrics on a randomized test set: normalized Area Under the Uplift Cur ve (A UUC) to assess uplift ranking capability , and Mean Absolute Per - centage Error (MAPE) to quantify ITE estimation accu- racy . W e refer details to Appendix D . 4.2. Experiment results W e optimize hyperparameters via grid search and obtain the following optimal results in T able 1 . For further details, please refer to Appendix E . As shown in T able 1 , POUL achiev es state-of-the-art performance across both Global ( D G ) and Core ( D C ) populations, surpassing baselines by 25.2% in the high-v ariance GMV task ( T 1 ). Crucially , our model exhibits dominant superiority in the combinatorial strategy setting ( T 2 ), achie ving an A UUC of 0.916 in Cost estimation and exceeding baseline by 42.0% in the Core population. This empirical gap directly corroborates our theoretical analysis: unlike traditional baselines, POUL rep- resents the policy as an induced mixtur e over conte xt–action atoms , guaranteeing stability under perturbations and en- abling the capture of complex polic y interactions in T 2 . 5. Conclusion This work studies uplift estimation for combinatorial poli- cies, representing treatments via the mixtures they induce ov er context–action components. W e establish the expres- si veness of permutation-in variant polic y embeddings, the or - thogonal robustness of the resulting lo w-rank estimator , and stability under policy perturbations. These results confirm that respecting policy structure and in variance is crucial for reliable causal learning in large, e volving treatment spaces. Future work should extend the framework both theoretically and practically . Theoretical analysis could address settings with unobserved confounding, non-stationarity , or ev olv- ing context–action sets. Methodologically , integration with meta-learning, Bayesian inference, or sequential decision- making models could enhance adaptability and uncertainty quantification. Applying the approach to broader domains— such as dynamic pricing or personalized healthcare—and dev eloping standardized benchmarks would further validate its utility and robustness. In all, combining causality with structured representation learning offers a principled path to ward generalizable and in- terpretable decisions. Further exploration of its connections to causal discov ery , programmatic policies, partial identifi- cation, and reinforcement learning represents a promising and crucial frontier for intelligent decision-making. 8 Permutation-In variant Representations for Combinatorial T reatments References Athey , S. and Imbens, G. W . Recursiv e partitioning for heterogeneous causal effects. Pr oceedings of the National Academy of Sciences , 113(27):7353–7360, 2016. Bica, I., Alaa, A. M., Jordon, J., and van der Schaar , M. Estimating counterfactual treatment outcomes o ver time through adversarially balanced representations. Interna- tional Confer ence on Learning Representations , 2020. Cheng, M., Liao, X., Liu, Q., Ma, B., Xu, J., and Zheng, B. Learning disentangled representations for counterfac- tual regression via mutual information minimization. In Pr oceedings of the 45th International A CM SIGIR Con- fer ence on Researc h and Development in Information Retrieval , pp. 1802–1806, 2022. Chernozhukov , V ., Chetverik ov , D., Demirer, M., Duflo, E., Hansen, C., Ne wey , W ., and Robins, J. Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal , 21(1):C1–C68, 2018. Guo, R., Li, J., and Liu, H. Estimating individual treatment effects under treatment spillover with graph neural net- works. Proceedings of the AAAI Confer ence on Artificial Intelligence , 2021. Imbens, G. W . and Rubin, D. B. Causal Infer ence for Statistics, Social, and Biomedical Sciences . Cambridge Univ ersity Press, 2015. Kaddour , J., Zhu, Y ., Liu, Q., Kusner , M. J., and Silva, R. Causal effect inference for structured treatments. Ad- vances in Neural Information Processing Systems , 34: 24841–24854, 2021. Kennedy , E. H. Optimal doubly robust estimation of het- erogeneous causal ef fects. Biometrika , 107(2):275–290, 2020. K ondor , R. and T rivedi, S. On the generalization of equiv ari- ance and con volution in neural netw orks to the action of compact groups. International Conference on Mac hine Learning , 2018. K ¨ unzel, S. R., Sekhon, J. S., Bickel, P . J., and Y u, B. Met- alearners for estimating heterogeneous treatment ef fects using machine learning. Pr oceedings of the National Academy of Sciences , 116(10):4156–4165, 2019. Liu, D., T ang, X., Gao, H., L yu, F ., and He, X. Explicit fea- ture interaction-aw are uplift network for online marketing. In Pr oceedings of the 29th A CM SIGKDD Confer ence on Knowledge Discovery and Data Mining , pp. 4507–4515, 2023. Radclif f e, N. J. and Surry , P . D. Real-world uplift modelling with significance-based uplift trees. T echnical report, Stochastic Solutions, 2011. Robins, J. M. and Rotnitzky , A. Estimation of re gression co- efficients when some re gressors are not always observed. Journal of the American Statistical Association , 89(427): 846–866, 1994. Rubin, D. B. Estimating causal ef fects of treatments in randomized and nonrandomized studies. J ournal of Edu- cational Psychology , 66(5):688–701, 1974. Rzepako wski, P . and Jaroszewicz, S. Decision trees for up- lift modeling with single and multiple treatments. Knowl- edge and Information Systems , 32(2):303–327, 2012. Schwab, P ., Linhardt, L., Bauer , S., Buhmann, J. M., and Karlen, W . Learning counterfactual representations for estimating indi vidual dose-response curves. In Pr oceed- ings of the AAAI Conference on Artificial Intelligence , volume 34, pp. 5612–5619, 2020. Shalit, U., Johansson, F . D., and Sontag, D. Estimating individual treatment effect: generalization bounds and algorithms. In Pr oceedings of the 34th International Con- fer ence on Machine Learning , volume 70 of Pr oceedings of Machine Learning Resear ch , pp. 3076–3085, 2017. Shi, C., Blei, D. M., and V eitch, V . Adapting neural net- works for the estimation of treatment effects. In Advances in Neural Information Pr ocessing Systems , volume 32, 2019. van der Laan, M. J. and Rose, S. T arg eted Learning: Causal Infer ence for Observational and Experimental Data . Springer, 2011. W ager , S. and Athey , S. Estimation and inference of hetero- geneous treatment effects using random forests. Journal of the American Statistical Association , 113(523):1228– 1242, 2018. Zaheer , M., Kottur , S., Ravanbakhsh, S., Poczos, B., Salakhutdinov , R., and Smola, A. Deep sets. In Advances in Neural Information Pr ocessing Systems , 2017. Zhong, K., Xiao, F ., Ren, Y ., Liang, Y ., Y ao, W ., Y ang, X., and Cen, L. Descn: Deep entire space cross networks for individual treatment effect estimation. In Pr oceed- ings of the 28th ACM SIGKDD confer ence on knowledge discovery and data mining , pp. 4612–4620, 2022. 9 Permutation-In variant Representations for Combinatorial T reatments A. Related W ork CA TE and uplift estimation. A large literature studies heterogeneous treatment effect estimation under the potential outcomes framework, with both classical and modern ML approaches ( Rubin , 1974 ; Imbens & Rubin , 2015 ; Athey & Imbens , 2016 ; W ager & Athey , 2018 ). For binary treatments, meta-learners such as the T -/S-/X-learners provide practical plug-in strategies and are widely used in industrial uplift modeling ( K ¨ unzel et al. , 2019 ). In parallel, uplift modeling has dev eloped ev aluation protocols centered around incremental gain and Qini-type curves, as well as specialized tree learners for direct uplift estimation ( Radcliffe & Surry , 2011 ; Rzepakowski & Jaroszewicz , 2012 ). Despite substantial progress, most of these methods implicitly assume a small and fixed treatment set. When the treatment space becomes large and long-tailed—as in combinatorial policies—treating each treatment as an unrelated category leads to poor sample ef ficiency and unstable ranking, because there is no mechanism to share information across related interventions. Orthogonalization, doubly rob ust learning, and debiased ML. Orthogonal / doubly robust ideas are a cornerstone of modern causal estimation, mitigating sensitivity to nuisance estimation through Neyman orthogonality and cross-fitting ( Robins & Rotnitzky , 1994 ; v an der Laan & Rose , 2011 ; Chernozhukov et al. , 2018 ; Kennedy , 2020 ). These works provide a principled recipe: learn flexible nuisance components (outcome regression, propensity) while guaranteeing that their errors enter the target estimator only at second order . Howe ver , the majority of the DML/TMLE literature treats the treatment as low-dimensional (binary or small discrete), and the nuisance objects are designed accordingly . In our setting, the primary bottleneck is not only nuisance estimation, but also how to r epresent a high-cardinality , structured policy in a way that preserves causal semantics. Our contribution is complementary: we retain the orthogonal robustness adv antages of DML- style learning ( Chernozhuko v et al. , 2018 ) while introducing a structured, permutation-inv ariant treatment representation that enables parameter sharing and stable generalization across a combinatorial policy space. Representation learning for treatment effects. Deep representation learning has been widely adopted for CA TE/ITE estimation, often aiming to reduce distribution shift between treated and control groups in observational data. Notable examples include T ARNet and its balancing variants ( Shalit et al. , 2017 ), as well as architectures that explicitly incorporate propensity information such as DragonNet and targeted re gularization ( Shi et al. , 2019 ). Extensions to multi-treatment and dose-response settings ha ve also been de veloped, e.g., DRNet for multiple treatments with continuous dosage ( Schw ab et al. , 2020 ). These methods primarily focus on learning a good representation of unit covariates X (and nuisance functions of X ) to improv e counterfactual generalization. By contrast, our focus is orthogonal: we study how to represent structured tr eatments (policies) themselves. In particular , ev en with randomized assignment (where ignorability is ensured), naiv e treatment encodings can destroy equiv alences between policies and prevent information sharing across related policies, leading to systematic instability in long-tailed regimes. Our permutation-in variant treatment embedding targets precisely this failure mode. Structured and compositional tr eatments. There is increasing interest in causal estimation under nonstandard treatments, including multiple treatments, continuous treatments, and structured interventions ( K ¨ unzel et al. , 2019 ; Schwab et al. , 2020 ). In many real systems, a “treatment” is naturally a policy mapping treatment-side contexts to action distributions, inducing a compositional structure. Most existing multi-treatment architectures model treatments via one-hot or learned embeddings tied to treatment IDs. While recent approaches like EFIN ( Liu et al. , 2023 ) mitigate this by explicitly encoding treatment attrib utes (e.g., coupon values) to capture inter-treatment correlations, the y fundamentally rely on fixed feature interactions rather than enforcing in variances implied by policy semantics. As a result, two implementations of the same policy (dif fering only by re-indexing or ordering) may still be treated as unrelated, and nearby policies in specification space need not be nearby in representation space. Our work addresses this gap by representing a policy through its induced mixture over conte xt–action atoms and by proving stability under small policy perturbations, which is absent from cate gorical-ID and feature-interaction paradigms. Permutation in variance and symmetry-aware lear ning. Permutation-in variant architectures such as Deep Sets ( Zaheer et al. , 2017 ) and more general symmetry-a ware framew orks ( Kondor & T rivedi , 2018 ) pro vide a powerful inducti ve bias when the target depends only on a multiset of components. While such in variances are standard in set-structured prediction, their role in causal estimation with structured treatments has not been systematically dev eloped. Our treatment representation can be vie wed as a causal instantiation of this principle: the treatment embedding is a function of the multiset of context– action components weighted by policy-induced mixture probabilities, and is therefore inv ariant to re-indexing and ordering. Crucially , this is not merely an architectural con venience: the induced in variance aligns the statistical representation with causal semantics and enables both theoretical stability guarantees and practical generalization to rare or unseen policy 10 Permutation-In variant Representations for Combinatorial T reatments variants. In short, prior w ork has made significant progress on (i) CA TE estimation for lo w-cardinality treatments, (ii) orthogonal robustness to nuisance estimation, and (iii) representation learning over co variates. Nevertheless, under combinatorial policy tr eatments with frequent iteration and long-tailed exposure, existing methods that rely on categorical treatment IDs remain systematically biased in the repr esentation step: they fail to respect policy equi valences and provide no meaningful notion of proximity in polic y space. W e depart from this paradigm by combining (A) a permutation-in variant, compositional treatment embedding with (B) an orthogonalized uplift objectiv e, thereby obtaining a framew ork that (1) contains standard DML-style robustness as a special case, (2) generalizes across structured treatments through parameter sharing, and (3) admits e xplicit expressi veness and stability guarantees tailored to policy perturbations. B. Proofs and Additional T echnical Details B.1. Notation and basic identities Recall that each policy t ∈ T is specified by context-wise action distrib utions { Π t ( · | s ) } s ∈S ov er a finite action set A and finite context set S . Let w : S → [0 , ∞ ) be context weights with P s ∈S w ( s ) = 1 and define the induced atom weights α t ( s, a ) := w ( s )Π t ( a | s ) , ( s, a ) ∈ S × A , and the induced discrete measure µ t on S × A by µ t ( { ( s, a ) } ) = α t ( s, a ) . Throughout the appendix, for a scalar (or vector) random variable Z we write ∥ Z ∥ 2 := ( E ∥ Z ∥ 2 ) 1 / 2 . For a function h : T → R d , we use ∥ h ∥ ∞ := sup t ∈T ∥ h ( t ) ∥ and ∥ h − ˜ h ∥ ∞ := sup t ∈T ∥ h ( t ) − ˜ h ( t ) ∥ . For a function g : R p → R d , we will occasionally write ∥ g − ˜ g ∥ ∞ ,x := sup x ∥ g ( x ) − ˜ g ( x ) ∥ when the supremum is taken ov er the domain of interest. A basic identity that will be used repeatedly is the “centering” property E [ h 0 ( T ) − e 0 ( X ) | X ] = 0 , e 0 ( X ) := E [ h 0 ( T ) | X ] . (15) This is the main mechanism behind Neyman orthogonality and the second-order nature of nuisance ef fects. B.2. Proof of Pr oposition 3.2 Pr oof of Pr oposition 3.2 . Fix any x ∈ R p and t ∈ T . By Assumption 3.1 , there exist measurable m 0 and g 0 and a functional F such that E [ Y ( t ) | X = x ] = m 0 ( x ) + g 0 ( x ) ⊤ F ( µ t ) . Define h 0 ( t ) := F ( µ t ) . Under consistency Y = Y ( T ) and randomized assignment (so that conditioning on ( X, T ) selects the corresponding potential outcome), we hav e E [ Y | X = x, T = t ] = E [ Y ( t ) | X = x ] = m 0 ( x ) + g 0 ( x ) ⊤ h 0 ( t ) . Let e 0 ( x ) := E [ h 0 ( T ) | X = x ] and define m ( x ) := m 0 ( x ) + g 0 ( x ) ⊤ e 0 ( x ) . Then, for any ( x, t ) , m 0 ( x ) + g 0 ( x ) ⊤ h 0 ( t ) = m 0 ( x ) + g 0 ( x ) ⊤ e 0 ( x ) + g 0 ( x ) ⊤ h 0 ( t ) − e 0 ( x ) = m ( x ) + g 0 ( x ) ⊤ h 0 ( t ) − e 0 ( x ) . Thus the conditional mean obeys ( 9 ). Finally , the CA TE for any pair ( t 1 , t 0 ) satisfies τ ( x ; t 1 , t 0 ) := E [ Y ( t 1 ) − Y ( t 0 ) | X = x ] = m 0 ( x ) + g 0 ( x ) ⊤ h 0 ( t 1 ) − m 0 ( x ) + g 0 ( x ) ⊤ h 0 ( t 0 ) = g 0 ( x ) ⊤ h 0 ( t 1 ) − h 0 ( t 0 ) , which is ( 10 ). 11 Permutation-In variant Representations for Combinatorial T reatments B.3. Proof of Lemma 3.3 (Expr essiveness) Pr oof of Lemma 3.3 . Because S and A are finite, the product set S × A is finite as well. Let m := |S ||A| and fix any bijection (index map) ι : S × A → { 1 , 2 , . . . , m } . For any measure µ supported on S × A , define its coordinate vector α ( µ ) ∈ R m by α ( µ ) ι ( s,a ) := µ ( { ( s, a ) } ) . In particular , for µ t induced by policy t , we have α ( µ t ) ι ( s,a ) = α t ( s, a ) = w ( s )Π t ( a | s ) and α ( µ t ) ∈ ∆ m − 1 (the probability simplex). The map µ 7→ α ( µ ) is a linear homeomorphism between the space of measures on the finit e set S × A and R m restricted to ∆ m − 1 . Define e F : α ( M ) → R d by e F ( α ( µ )) := F ( µ ) for µ ∈ M . Since F is continuous on M under the ℓ 1 /TV topology and the identification ∥ µ − µ ′ ∥ 1 = ∥ α ( µ ) − α ( µ ′ ) ∥ 1 holds on finite supports, e F is continuous on the set α ( M ) = { α ( µ t ) : t ∈ T } ⊂ ∆ m − 1 . Moreov er, ∆ m − 1 is compact and α ( M ) is compact as a closed subset of a compact set. By the univ ersal approximation theorem for ReLU MLPs on compact sets, for any ε > 0 there exists an integer r (in fact we may take r = m ) and an MLP ρ : R r → R d such that sup t ∈T e F ( α ( µ t )) − ρ ( α ( µ t )) ≤ ε. (16) It remains to realize α ( µ t ) as a permutation-in variant weighted sum. Let { e j } m j =1 denote the standard basis of R m and choose r = m and ϕ ( s, a ) := e ι ( s,a ) ∈ R m . Then z ϕ ( t ) = X s ∈S X a ∈A α t ( s, a ) ϕ ( s, a ) = X s,a α t ( s, a ) e ι ( s,a ) = α ( µ t ) . Therefore, defining h ϕ,ρ ( t ) := ρ ( z ϕ ( t )) yields h ϕ,ρ ( t ) = ρ ( α ( µ t )) . Combining this with ( 16 ) giv es sup t ∈T ∥ F ( µ t ) − h ϕ,ρ ( t ) ∥ = sup t ∈T ∥ e F ( α ( µ t )) − ρ ( α ( µ t )) ∥ ≤ ε, which prov es the claim. Remark (why this is not vacuous). While the above construction uses the “basis embedding” ϕ ( s, a ) = e ι ( s,a ) and thus shows uni versality in a straightforward way , it is precisely the shar ed atom map ϕ together with permutation- in variant aggr e gation that constitutes the inductiv e bias of our approach. This bias is what yields stability in policy space (Proposition 3.7 ) and practical statistical strength-sharing when T is huge but S × A has reusable structure. B.4. Proof of Lemma 3.4 (Neyman orthogonality) Pr oof of Lemma 3.4 . Recall the orthogonalized model ( 4 ): Y = m 0 ( X ) + g 0 ( X ) ⊤ h 0 ( T ) − e 0 ( X ) + ε, E [ ε | X , T ] = 0 , and the score ψ ( W ; g , h, m, e ) := Y − m ( X ) − g ( X ) ⊤ ( h ( T ) − e ( X )) ( h ( T ) − e ( X )) , W := ( X, T , Y ) . 12 Permutation-In variant Representations for Combinatorial T reatments Step 1: Unbiasedness at the truth. At the true functions ( g 0 , h 0 , m 0 , e 0 ) , Y − m 0 ( X ) − g 0 ( X ) ⊤ ( h 0 ( T ) − e 0 ( X )) = ε, so ψ ( W ; g 0 , h 0 , m 0 , e 0 ) = ε ( h 0 ( T ) − e 0 ( X )) . T aking expectation and using iterated e xpectation gives E [ ψ ( W ; g 0 , h 0 , m 0 , e 0 )] = E E [ ε ( h 0 ( T ) − e 0 ( X )) | X , T ] = E ( h 0 ( T ) − e 0 ( X )) E [ ε | X , T ] = 0 , proving E [ ψ ( W ; g 0 , h 0 , m 0 , e 0 )] = 0 . Step 2: Gateaux deriv ative in nuisance directions vanishes. Fix perturbations δ m and δ e such that all expressions below are integrable (e.g., δ m ( X ) and δ e ( X ) square-integrable). Define the nuisance path m r := m 0 + r δm and e r := e 0 + r δe . Consider Ψ( r ) := E ψ ( W ; g 0 , h 0 , m r , e r ) . Using the model for Y and expanding the residual, Y − m r ( X ) − g 0 ( X ) ⊤ ( h 0 ( T ) − e r ( X )) = m 0 ( X ) − m r ( X ) + g 0 ( X ) ⊤ e r ( X ) − e 0 ( X ) + ε = − r δ m ( X ) + r g 0 ( X ) ⊤ δ e ( X ) + ε. Also, h 0 ( T ) − e r ( X ) = h 0 ( T ) − e 0 ( X ) − r δ e ( X ) . Hence ψ ( W ; g 0 , h 0 , m r , e r ) = ε − r δ m ( X ) + r g 0 ( X ) ⊤ δ e ( X ) ( h 0 ( T ) − e 0 ( X )) − r δ e ( X ) . Expanding and collecting the terms linear in r yields Ψ( r ) = E ε ( h 0 ( T ) − e 0 ( X )) | {z } =0 + r E h − δ m ( X ) ( h 0 ( T ) − e 0 ( X )) + ( g 0 ( X ) ⊤ δ e ( X )) ( h 0 ( T ) − e 0 ( X )) − ε δe ( X ) i + O ( r 2 ) , where the O ( r 2 ) term is justified by integrability and dominated con vergence. W e no w show each linear term has zero expectation. For the first two terms, condition on X and use ( 15 ): E δ m ( X ) ( h 0 ( T ) − e 0 ( X )) = E δ m ( X ) E [ h 0 ( T ) − e 0 ( X ) | X ] = 0 , E ( g 0 ( X ) ⊤ δ e ( X )) ( h 0 ( T ) − e 0 ( X )) = E ( g 0 ( X ) ⊤ δ e ( X )) E [ h 0 ( T ) − e 0 ( X ) | X ] = 0 . For the third term, condition on ( X, T ) and use E [ ε | X , T ] = 0 : E [ ε δ e ( X )] = E δ e ( X ) E [ ε | X , T ] = 0 . Therefore the coefficient of r in Ψ( r ) is zero, implying Ψ ′ (0) = 0 , i.e., d dr r =0 E ψ ( W ; g 0 , h 0 , m 0 + r δ m, e 0 + r δ e ) = 0 . This prov es Neyman orthogonality with respect to ( m, e ) . 13 Permutation-In variant Representations for Combinatorial T reatments B.5. Proof of Theor em 3.6 (Orthogonal robustness) B . 5 . 1 . A D E T E R M I N I S T I C S E C O N D - O R D E R B O U N D F O R N U I S A N C E P E RT U R BAT I O N S The core technical step is to control how the orthogonal score changes when we replace the true nuisances ( m 0 , e 0 ) by estimators ( ˆ m, ˆ e ) , while simultaneously allowing the learned ef fect components ( ˆ g , ˆ h ) to deviate from ( g 0 , h 0 ) . This coupling is nontrivial in our setting because (i) the regressor h ( T ) − e ( X ) is vector-v alued, (ii) e ( X ) is itself an X -conditional expectation of h ( T ) , and (iii) ˆ e may be constructed through a propensity model and hence is another high-dimensional nuisance. Lemma B.1 (Second-order control of score perturbation) . Assume the model ( 4 ) holds with ( m 0 , g 0 , h 0 , e 0 ) and E [ ε | X, T ] = 0 . Let ( g , h, m, e ) be (possibly random) candidates such that all quantities below are integr able. Define ∆ g := g − g 0 , ∆ h := h − h 0 , ∆ m := m − m 0 , and ∆ e := e − e 0 . Then E ψ ( W ; g , h, m, e ) − ψ ( W ; g , h, m 0 , e 0 ) ≤ C 1 ∥ ∆ m ∥ 2 + ∥ ∆ h ∥ ∞ + ∥ ∆ g ∥ ∞ ,x ∥ ∆ e ∥ 2 + C 2 ∥ ∆ e ∥ 2 2 , (17) for constants C 1 , C 2 depending only on moment bounds of ( Y , g 0 , h 0 ) and on the domain of ( X , T ) . Pr oof of Lemma B.1 . Write the score difference as ψ ( W ; g , h, m, e ) − ψ ( W ; g , h, m 0 , e 0 ) = R m,e ( W ) − R m 0 ,e 0 ( W ) ( h ( T ) − e ( X )) + R m 0 ,e 0 ( W ) ( h ( T ) − e ( X )) − ( h ( T ) − e 0 ( X )) , where R m,e ( W ) := Y − m ( X ) − g ( X ) ⊤ ( h ( T ) − e ( X )) . Noting ( h ( T ) − e ( X )) − ( h ( T ) − e 0 ( X )) = − ( e ( X ) − e 0 ( X )) = − ∆ e ( X ) , we hav e ψ ( W ; g , h, m, e ) − ψ ( W ; g , h, m 0 , e 0 ) = R m,e ( W ) − R m 0 ,e 0 ( W ) ( h ( T ) − e ( X )) − R m 0 ,e 0 ( W ) ∆ e ( X ) . (18) W e next e xpand the residual difference. A direct calculation gives R m,e ( W ) − R m 0 ,e 0 ( W ) = − ∆ m ( X ) − g ( X ) ⊤ h ( T ) − e ( X ) + g ( X ) ⊤ h ( T ) − e 0 ( X ) = − ∆ m ( X ) + g ( X ) ⊤ ∆ e ( X ) . Plugging into ( 18 ) yields ψ ( W ; g , h, m, e ) − ψ ( W ; g , h, m 0 , e 0 ) = − ∆ m ( X ) + g ( X ) ⊤ ∆ e ( X ) h ( T ) − e ( X ) − R m 0 ,e 0 ( W ) ∆ e ( X ) . (19) Now we e xpress R m 0 ,e 0 ( W ) under the true model: R m 0 ,e 0 ( W ) = Y − m 0 ( X ) − g ( X ) ⊤ ( h ( T ) − e 0 ( X )) = Y − m 0 ( X ) − g 0 ( X ) ⊤ ( h 0 ( T ) − e 0 ( X )) | {z } = ε + g 0 ( X ) ⊤ ( h 0 ( T ) − e 0 ( X )) − g ( X ) ⊤ ( h ( T ) − e 0 ( X )) = ε − ∆ g ( X ) ⊤ h 0 ( T ) − e 0 ( X ) − g ( X ) ⊤ ∆ h ( T ) , where we used h ( T ) = h 0 ( T ) + ∆ h ( T ) and ∆ h ( T ) := h ( T ) − h 0 ( T ) . Substitute this into ( 19 ) and take expectation. The expectation of the term ε ∆ e ( X ) v anishes by iterated expectation: E [ ε ∆ e ( X )] = E ∆ e ( X ) E [ ε | X , T ] = 0 . Moreov er, the k ey centering identity ( 15 ) implies that whenev er A ( X ) is measurable in X , E A ( X ) ( h 0 ( T ) − e 0 ( X )) = E A ( X ) E [ h 0 ( T ) − e 0 ( X ) | X ] = 0 . This kills the first-or der terms in ∆ m and in ∆ e that would otherwise appear in the score bias. 14 Permutation-In variant Representations for Combinatorial T reatments What remains after cancellations are only products of perturbations, which we bound by Cauchy–Schwarz. Concretely , from ( 19 ) and the abov e expansions, we obtain E ψ ( W ; g , h, m, e ) − ψ ( W ; g , h, m 0 , e 0 ) = E ∆ m ( X ) ∆ e ( X ) + E ( g ( X ) ⊤ ∆ e ( X )) ∆ e ( X ) + E Γ( X, T ) ∆ e ( X ) , where Γ( X, T ) collects terms in volving ∆ g and ∆ h multiplied by bounded random quantities (e.g., h 0 ( T ) − e 0 ( X ) and g ( X ) ). Using ∥ g ( X ) ∥ ≤ ∥ g 0 ( X ) ∥ + ∥ ∆ g ∥ ∞ ,x and ∥ ∆ h ( T ) ∥ ≤ ∥ ∆ h ∥ ∞ , we bound E [∆ m ( X ) ∆ e ( X )] ≤ ∥ ∆ m ∥ 2 ∥ ∆ e ∥ 2 , E [( g ( X ) ⊤ ∆ e ( X )) ∆ e ( X )] ≤ E [ ∥ g ( X ) ∥ ∥ ∆ e ( X ) ∥ 2 ] ≤ ( E ∥ g ( X ) ∥ 2 ) 1 / 2 ∥ ∆ e ∥ 2 2 , E [Γ( X, T ) ∆ e ( X )] ≤ ∥ ∆ g ∥ ∞ ,x + ∥ ∆ h ∥ ∞ ∥ ∆ e ∥ 2 · C , for a constant C depending only on bounded moments of g 0 ( X ) and h 0 ( T ) (cf. Assumption 3.5 ). Collecting the terms yields ( 17 ). B . 5 . 2 . P R O O F O F T H E O R E M 3 . 6 Pr oof of Theor em 3.6 . W e separate the argument into a n algebraic decomposition (capturing the effect-component errors) and a nuisance-induced remainder (capturing orthogonal robustness). Step 1: Algebraic decomposition of the plug-in CA TE. Recall τ ( x ; t 1 , t 0 ) = g 0 ( x ) ⊤ ( h 0 ( t 1 ) − h 0 ( t 0 )) from Proposi- tion 3.2 and ˆ τ ( x ; t 1 , t 0 ) = ˆ g ( x ) ⊤ ( ˆ h ( t 1 ) − ˆ h ( t 0 )) . Add and subtract ˆ g ( x ) ⊤ ( h 0 ( t 1 ) − h 0 ( t 0 )) : ˆ τ ( x ; t 1 , t 0 ) − τ ( x ; t 1 , t 0 ) = ( ˆ g ( x ) − g 0 ( x )) ⊤ h 0 ( t 1 ) − h 0 ( t 0 ) | {z } =: error(g) + ˆ g ( x ) ⊤ ( ˆ h − h 0 )( t 1 ) − ( ˆ h − h 0 )( t 0 ) . (20) Decompose the second term further by writing ˆ g ( x ) = g 0 ( x ) + ( ˆ g ( x ) − g 0 ( x )) : ˆ g ( x ) ⊤ ( ˆ h − h 0 )( t 1 ) − ( ˆ h − h 0 )( t 0 ) = g 0 ( x ) ⊤ ( ˆ h − h 0 )( t 1 ) − ( ˆ h − h 0 )( t 0 ) | {z } =: error(h) + R g h ( x ; t 1 , t 0 ) , (21) where the remainder R g h ( x ; t 1 , t 0 ) := ( ˆ g ( x ) − g 0 ( x )) ⊤ ( ˆ h − h 0 )( t 1 ) − ( ˆ h − h 0 )( t 0 ) is second or der in the effect-component errors and obe ys the deterministic bound | R g h ( x ; t 1 , t 0 ) | ≤ 2 ∥ ˆ g ( x ) − g 0 ( x ) ∥ ∥ ˆ h − h 0 ∥ ∞ ≤ 2 δ g ( x ) δ h . (22) In many asymptotic re gimes, δ g ( x ) δ h = o p ( δ g ( x ) + δ h ) ; we keep it explicit here for completeness. Combining ( 20 )–( 21 ) giv es ˆ τ ( x ; t 1 , t 0 ) − τ ( x ; t 1 , t 0 ) = error(g) + error(h) + R g h ( x ; t 1 , t 0 ) . (23) Step 2: Orthogonal rob ustness isolates nuisance effects. The central claim of Theorem 3.6 is about the additional impact of nuisance estimation beyond the effect-component errors. T o make this precise, note that the orthogonalized learning procedure (Algorithm 1 ) is driven by the score ψ and its cross-fitted empirical counterpart. Under cross-fitting (Assumption 3.5 (3)), we may condition on the nuisance estimates ( ˆ m ( − k ) , ˆ e ( − k ) ) and treat them as fixed when taking expectation o ver the ev aluation fold. Lemma B.1 then yields the deterministic second-order control E ψ ( W ; ˆ g , ˆ h, ˆ m, ˆ e ) − ψ ( W ; ˆ g , ˆ h, m 0 , e 0 ) ≤ C 1 ( δ m + δ h + ∥ ˆ g − g 0 ∥ ∞ ,x ) δ e + C 2 δ 2 e . By Assumption 3.5 (4), δ e = o p (1) , so δ 2 e = o p ( δ e ) and can be absorbed into the product term without changing the order (by enlarging constants). Thus, E ψ ( W ; ˆ g , ˆ h, ˆ m, ˆ e ) − ψ ( W ; ˆ g , ˆ h, m 0 , e 0 ) = O p ( δ m + δ h + ∥ ˆ g − g 0 ∥ ∞ ,x ) δ e . (24) 15 Permutation-In variant Representations for Combinatorial T reatments Equation ( 24 ) is the formal mathematical expression of the statement “nuisance errors enter only at second order”: the perturbation in the orthogonal score induced by ( ˆ m, ˆ e ) is proportional to a pr oduct inv olving δ e rather than a sum of first-order terms. This is exactly where orthogonality matters; without centering ( 15 ) , the bound would contain linear (first-order) terms in δ m and δ e . Finally , the CA TE functional depends on the learned effect components through ˆ τ ( x ; t 1 , t 0 ) = ˆ g ( x ) ⊤ ( ˆ h ( t 1 ) − ˆ h ( t 0 )) . The learning procedure targets ( ˆ g , ˆ h ) through the orthogonal score, so the nuisance-induced perturbation in the target is controlled by the same second-order quantity appearing in ( 24 ). This yields the remainder term stated in Theorem 3.6 : error(second order) = O p ( δ m + δ h + sup x δ g ( x )) δ e , where we used ∥ ˆ g − g 0 ∥ ∞ ,x = sup x δ g ( x ) by definition. Combining with ( 23 ) completes the proof. Remark (where the technical difficulty lies). Compared to the classical partially linear model and standard DML analyses, two aspects require extra care here: (i) the “treatment regressor” h ( T ) − e ( X ) is vector -valued and learned (hence the appearance of δ h ), and (ii) the nuisance e ( X ) = E [ h ( T ) | X ] is an embedding pr opensity and may be constructed via a propensity model (hence δ e couples representation learning and nuisance estimation). Lemma B.1 makes this coupling explicit, and sho ws that orthogonalization controls it at second order . B.6. Proof of Pr oposition 3.7 (Stability) Pr oof of Pr oposition 3.7 . Recall z ( t ) = X s ∈S X a ∈A w ( s )Π t ( a | s ) ϕ ( s, a ) , h ( t ) = ρ ( z ( t )) . For an y t, t ′ ∈ T , we hav e z ( t ) − z ( t ′ ) = X s ∈S X a ∈A w ( s ) Π t ( a | s ) − Π t ′ ( a | s ) ϕ ( s, a ) . T aking norms and using the triangle inequality , ∥ z ( t ) − z ( t ′ ) ∥ ≤ X s ∈S X a ∈A w ( s ) | Π t ( a | s ) − Π t ′ ( a | s ) | ∥ ϕ ( s, a ) ∥ ≤ sup ( s,a ) ∥ ϕ ( s, a ) ∥ X s ∈S w ( s ) X a ∈A | Π t ( a | s ) − Π t ′ ( a | s ) | ≤ B X s ∈S w ( s ) ∥ Π t ( · | s ) − Π t ′ ( · | s ) ∥ 1 = B d Π ( t, t ′ ) . If ρ is L ρ -Lipschitz, then ∥ h ( t ) − h ( t ′ ) ∥ = ∥ ρ ( z ( t )) − ρ ( z ( t ′ )) ∥ ≤ L ρ ∥ z ( t ) − z ( t ′ ) ∥ ≤ L ρ B d Π ( t, t ′ ) , which is ( 14 ). For the uplift bound, recall τ ( x ; t, t ′ ) = g 0 ( x ) ⊤ ( h 0 ( t ) − h 0 ( t ′ )) and assume ∥ g 0 ( x ) ∥ ≤ G . Then Cauchy–Schwarz yields | τ ( x ; t, t ′ ) | ≤ ∥ g 0 ( x ) ∥ ∥ h 0 ( t ) − h 0 ( t ′ ) ∥ ≤ G ∥ h 0 ( t ) − h 0 ( t ′ ) ∥ . Applying the already-prov ed embedding stability bound to h 0 completes the proof. T o reduce overfitting bias when flexible learners are used for nuisance components, we optionally adopt cross-fitting: estimate nuisance functions on held-out folds, and train the main model using fold-specific nuisance predictions. C. Experimental Implementation Details In this appendix, we provide a comprehensive description of the experimental setup. W e detail the training protocols used in our study . 16 Permutation-In variant Representations for Combinatorial T reatments Algorithm 2 Permutation-in variant orthogonal uplift learning (POUL) Require: Data { ( X i , T i , Y i ) } n i =1 , policy specs { Π t ( · | s ) } t,s , weights w ( · ) , folds K (optional) 1: Split indices into folds I 1 , . . . , I K (set K = 1 to disable cross-fitting) 2: for k = 1 , . . . , K do 3: Fit nuisance ˆ m ( − k ) ( · ) ≈ E [ Y | X = · ] using { i / ∈ I k } 4: (Observational only) Fit propensity ˆ π ( − k ) ( t | x ) ≈ P ( T = t | X = x ) using { i / ∈ I k } 5: end for 6: Initialize parameters ( ω , ν ) for ϕ ω , ρ ν and ( η ) for g η ; optionally initialize m θ 7: repeat 8: Sample a mini-batch B ⊂ { 1 , . . . , n } 9: for each i ∈ B do 10: Compute h ω ,ν ( T i ) via ( 2 )–( 3 ) 11: Let k ( i ) be the fold inde x such that i ∈ I k ( i ) 12: Set ˆ e h ( X i ) ← P t ∈T ˆ π ( − k ( i )) ( t | X i ) h ω ,ν ( t ) { use known π in RCT } 13: Predict ˆ Y i ← ˆ m ( − k ( i )) ( X i ) + g η ( X i ) ⊤ h ω ,ν ( T i ) − ˆ e h ( X i ) 14: end for 15: Update ( η , ω , ν ) (and optionally θ ) by SGD on 1 |B| P i ∈B ℓ ( ˆ Y i , Y i ) + λ Ω 16: until con vergence 17: retur n ˆ τ ( x ; t 1 , t 0 ) = g ˆ η ( x ) ⊤ h ˆ ω, ˆ ν ( t 1 ) − h ˆ ω, ˆ ν ( t 0 ) C.1. T raining Protocol T o guarantee experimental consistenc y , all deep learning models are implemented in PyT orch and trained on NVIDIA T esla P40 GPUs. W e employ the Adam optimizer with a fix ed learning rate of 1 × 10 − 4 , a batch size of 512 , and a random seed set to 3407 . While these foundational settings remain constant, we v ary the training epochs and the training strate gy (single-stage v ersus two-stage) to identify the optimal configuration for each model v ariant. The training epoch configuration is denoted by the tuple ( i, j ) , where i represents the epochs for the first stage (e.g., Global pre-training) and j for the second stage (e.g., Core fine-tuning): • Single-stage training: Denoted as ( i, 0) or (0 , j ) , indicating the model is trained exclusi vely on the global population D G (for i epochs) or the core population D C (for j epochs), respecti vely . • T wo-stage training: Denoted as ( i, j ) , which comprises an initial training phase on the global population D G for i epochs, followed by fine-tuning on the core population D C for j epochs. In contrast, for the Causal For est baseline, the model performance is predominantly governed by the ensemble size. Consequently , we maintained fixed settings for secondary hyperparameters (e.g., maxDepth = 10 , subsamplingRate = 0 . 8 , minInstancesP erNode = 500 ) and exclusi vely tuned the number of trees ( numT r ees ) to optimize the estimation stability and accuracy . D. Ev aluation Metrics As ground-truth uplift is unobservable, we assess our models on a randomized test set, focusing on uplift ranking and ITE estimation accuracy . D.1. Uplift Ranking Capability (A UUC) W e ev aluate ranking performance using the normalized Area Under the Uplift Curve (A UUC) , which quantifies the cumulativ e incremental gain achiev ed when targeting samples sorted by predicted Indi vidual Treatment Ef fect (ITE). Formally , let D = { ( x i , t i , y i ) } n i =1 denote the test dataset, where x i is the feature vector , t i ∈ { 0 , 1 } indicates the treatment assignment, and y i represents the observed outcome. Let ˆ τ ( x i ) be the predicted ITE. W e sort the samples in descending order of ˆ τ ( x i ) . Let i 1 , . . . , i n be the indices of the sorted samples such that ˆ τ ( x i 1 ) ≥ · · · ≥ ˆ τ ( x i n ) . For the top k samples, we define the cumulative counts ( n t , n c ) and outcome sums ( y t , y c ) for the treated and 17 Permutation-In variant Representations for Combinatorial T reatments control groups as: n t ( k ) = k X j =1 I ( t i j = 1) , n c ( k ) = k X j =1 I ( t i j = 0) , (25) y t ( k ) = k X j =1 y i j I ( t i j = 1) , y c ( k ) = k X j =1 y i j I ( t i j = 0) . (26) The Lift at rank k estimates the average treatment ef fect within the top k units: Lift ( k ) = y t ( k ) n t ( k ) − y c ( k ) n c ( k ) , (27) The Cumulative Gain , G ( k ) , is defined as the total estimated uplift up to rank k : G ( k ) = Lift ( k ) × k . (28) T o facilitate comparison across different settings, we calculate the Normalized Cumulative Gain ˜ G ( k ) by scaling G ( k ) with the absolute global gain at k = n : ˜ G ( k ) = G ( k ) | G ( n ) | . (29) Finally , the Normalized A UUC is computed as the average of these normalized g ains across the entire test dataset: A UUC = 1 n n X k =1 ˜ G ( k ) . (30) D.2. ITE Estimation Accuracy (MAPE) T o assess the accuracy of the predicted ITE v alues, we employ the Mean Absolute Per centage Error (MAPE) . Giv en the unobservability of indi vidual effects, we compute this metric o ver M = 10 bins (deciles) grouped by predicted ITE. Let ˆ τ m and τ m denote the av erage predicted ITE and the observed A verage T reatment Effect (A TE) within the m -th bin, respectiv ely . The MAPE is calculated as the average relati ve de viation across all bins: MAPE = 1 M M X m =1 ˆ τ m − τ m τ m . (31) A lower MAPE indicates that the predicted uplift magnitudes align more closely with the observ ed treatment effects. E. Detailed Experimental Results T o rigorously assess robustness, we employ an Out-of-T ime (OO T) ev aluation protocol, where models are trained on historical data (e.g., March) and ev aluated on non-overlapping future data (e.g., June). W e report the Area Under the Uplift Curve (A UUC) and Mean Absolute Percentage Error (MAPE) across two distinct test sets within the ev aluation period: the Global Population ( D G ) and the Core Population ( D C ) . The detailed performance comparisons are summarized in T able 2 and T able 3 . 18 Permutation-In variant Representations for Combinatorial T reatments T able 2. Detailed performance ev aluation of L TV (GMV) prediction on the J une T est Set . The T raining Config column specifies the training data source and tree count ( n tree ) for Causal Forest, and the training epoch tuple ( i, j ) for deep learning models (Global, Core). Model T raining Config T est Set: Global ( D G ) T est Set: Core ( D C ) T reatment 1 ( T 1 ) T reatment 2 ( T 2 ) T reatment 1 ( T 1 ) T reatment 2 ( T 2 ) A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ Random — 0.500 — 0.500 — 0.500 — 0.500 — Causal Forest D G ( n tree =300 ) 0.539 0.898 0.542 0.686 0.451 7.075 0.525 0.503 D G ( n tree =500 ) 0.575 2.213 0.550 2.917 0.536 1.086 0.536 0.836 D G ( n tree =600 ) 0.611 1.000 0.632 1.850 0.483 1.005 0.489 0.979 D C ( n tree =300 ) 0.547 6.236 0.568 2.118 0.339 1.811 0.529 1.556 D C ( n tree =500 ) 0.470 5.537 0.623 7.342 0.472 1.216 0.505 0.746 D C ( n tree =600 ) 0.515 3.632 0.525 2.774 0.452 6.905 0.531 0.612 T -Learner (DNN) (10 , 0) 0.581 3.310 0.639 2.711 0.488 2.763 0.574 3.311 (15 , 0) 0.545 3.139 0.656 1.906 0.482 2.428 0.551 1.486 (20 , 0) 0.550 4.270 0.618 2.760 0.581 1.953 0.556 1.528 (25 , 0) 0.495 3.581 0.617 1.297 0.585 2.487 0.563 1.426 (10 , 1) 0.342 18.368 0.607 2.562 0.348 3.703 0.498 3.311 (10 , 2) 0.330 13.188 0.592 2.464 0.347 2.900 0.500 4.023 (10 , 5) 0.342 6.694 0.594 2.711 0.365 4.419 0.504 1.330 DESCN (15 , 0) 0.305 2.219 0.640 1.930 0.555 0.815 0.594 1.162 (20 , 0) 0.514 2.156 0.597 0.977 0.553 0.945 0.540 0.682 (25 , 0) 0.494 1.086 0.588 0.919 0.502 1.273 0.523 0.825 (15 , 1) 0.367 27.667 0.579 14.850 0.596 1.256 0.591 1.167 (15 , 2) 0.457 2.268 0.585 3.192 0.593 1.712 0.592 2.819 (15 , 5) 0.463 2.065 0.570 3.208 0.614 1.181 0.563 0.788 DRCFR (15 , 0) 0.642 0.982 0.605 0.961 0.622 0.888 0.566 0.713 (25 , 0) 0.560 6.723 0.580 1.494 0.593 12.603 0.558 1.086 (5 , 1) 0.660 0.779 0.612 3.389 0.518 1.065 0.549 0.729 (10 , 1) 0.473 3.010 0.557 2.173 0.520 1.065 0.561 0.715 (15 , 1) 0.505 19.976 0.458 2.443 0.534 2.257 0.588 0.676 (15 , 2) 0.500 2.845 0.472 2.065 0.545 14.302 0.586 0.735 (15 , 5) 0.496 1.497 0.495 1.379 0.532 1.298 0.573 1.098 POUL (Ours) (1 , 1) 0.720 1.578 0.596 1.363 0.723 1.525 0.681 1.823 (1 , 3) 0.826 1.333 0.635 1.386 0.734 1.887 0.617 1.861 (1 , 5) 0.661 1.430 0.620 1.468 0.750 1.271 0.670 1.700 (2 , 1) 0.668 1.485 0.610 1.428 0.747 1.468 0.657 1.746 (5 , 1) 0.699 1.284 0.675 1.480 0.792 1.570 0.690 2.023 (5 , 2) 0.659 1.232 0.656 1.423 0.767 1.572 0.699 59.500 (5 , 5) 0.636 1.342 0.627 1.593 0.656 1.693 0.699 1.610 (5 , 10) 0.672 1.300 0.627 1.532 0.777 1.401 0.693 1.770 19 Permutation-In variant Representations for Combinatorial T reatments T able 3. Detailed performance ev aluation of Cost prediction on the June T est Set . The T raining Config column specifies the training data source and tree count ( n tree ) for Causal Forest, and the training epoch tuple ( i, j ) for deep learning models (Global, Core). Model T raining Config T est Set: Global ( D G ) T est Set: Core ( D C ) T reatment 1 ( T 1 ) T reatment 2 ( T 2 ) T reatment 1 ( T 1 ) T reatment 2 ( T 2 ) A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ A UUC ↑ MAPE ↓ Random — 0.500 — 0.500 — 0.500 — 0.500 — Causal Forest D G ( n tree =300 ) 0.440 0.971 0.412 0.962 0.576 0.946 0.596 0.969 D G ( n tree =500 ) 0.692 0.792 0.697 0.881 0.550 1.018 0.549 0.993 D G ( n tree =600 ) 0.701 0.954 0.707 0.916 0.566 0.994 0.498 0.999 D C ( n tree =300 ) 0.390 0.664 0.537 0.873 0.518 0.887 0.549 0.936 D C ( n tree =500 ) 0.610 0.618 0.599 0.807 0.527 0.964 0.552 0.984 D C ( n tree =600 ) 0.629 0.599 0.552 0.790 0.460 0.912 0.555 0.967 T -Learner (DNN) (10 , 0) 0.739 0.254 0.775 0.376 0.608 0.553 0.648 0.752 (15 , 0) 0.739 0.221 0.777 0.316 0.603 0.548 0.646 0.720 (20 , 0) 0.737 0.236 0.776 0.341 0.602 0.555 0.646 0.765 (25 , 0) 0.735 0.275 0.776 0.421 0.601 0.541 0.646 0.769 (10 , 1) 0.731 2.131 0.768 0.670 0.616 0.191 0.645 0.445 (10 , 2) 0.728 2.391 0.763 0.911 0.613 0.172 0.645 0.435 (10 , 5) 0.725 2.615 0.759 1.062 0.609 0.149 0.644 0.425 DESCN (15 , 0) 0.735 0.113 0.777 0.409 0.599 0.555 0.643 0.680 (20 , 0) 0.732 0.204 0.775 0.310 0.596 0.534 0.643 0.722 (25 , 0) 0.733 0.157 0.777 0.494 0.593 0.618 0.643 0.752 (15 , 1) 0.710 2.795 0.768 1.110 0.608 0.103 0.641 0.456 (15 , 2) 0.723 2.856 0.767 1.319 0.608 0.096 0.642 0.448 (15 , 5) 0.718 2.750 0.763 1.589 0.603 0.150 0.644 0.468 DRCFR (15 , 0) 0.715 0.364 0.753 0.607 0.591 0.598 0.632 0.674 (25 , 0) 0.703 0.361 0.744 0.568 0.576 0.724 0.617 0.848 (5 , 1) 0.715 2.800 0.758 1.829 0.586 0.177 0.641 0.344 (10 , 1) 0.705 2.926 0.755 1.275 0.581 0.159 0.637 0.363 (15 , 1) 0.687 2.698 0.749 1.085 0.584 0.206 0.634 0.414 (15 , 2) 0.690 2.709 0.746 1.330 0.588 0.202 0.632 0.379 (15 , 5) 0.681 2.721 0.723 1.484 0.590 0.225 0.626 0.396 POUL (Ours) (1 , 1) 0.735 0.838 0.917 0.755 0.737 0.854 0.917 0.782 (1 , 3) 0.737 0.847 0.917 0.760 0.738 0.847 0.917 0.775 (1 , 5) 0.733 0.837 0.916 0.761 0.735 0.847 0.917 0.774 (2 , 1) 0.735 0.845 0.917 0.756 0.736 0.852 0.916 0.782 (5 , 1) 0.736 0.847 0.916 0.759 0.735 0.853 0.917 0.780 (5 , 2) 0.734 0.854 0.916 0.767 0.733 0.844 0.916 0.777 (5 , 5) 0.734 0.845 0.916 0.757 0.735 0.846 0.917 0.774 (5 , 10) 0.735 0.845 0.917 0.758 0.736 0.844 0.916 0.769 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment