목표 지향 영향력 극대화 데이터 획득: 학습과 최적화를 위한 새로운 접근법
본 논문은 딥러닝에서 비용이 큰 데이터 라벨링이나 함수 평가를 최소화하기 위한 새로운 능동적 획득 알고리즘인 GOIMDA를 제안한다. 기존 방법들이 신뢰하기 어려운 예측 불확실성 추정에 의존하는 한계를 극복하고, 사용자 지정 목표(예: 테스트 손실, 예측 엔트로피)에 대한 데이터 포인트의 영향력을 최대화하는 원리를 바탕으로 한다. 이론적으로 불확실성 인지 행동을 보이며, 다양한 학습 및 최적화 태스크에서 기존 방법보다 적은 샘플로 목표 성능에 …
저자: Weichi Yao, Bianca Dumitrascu, Bryan R. Goldsmith
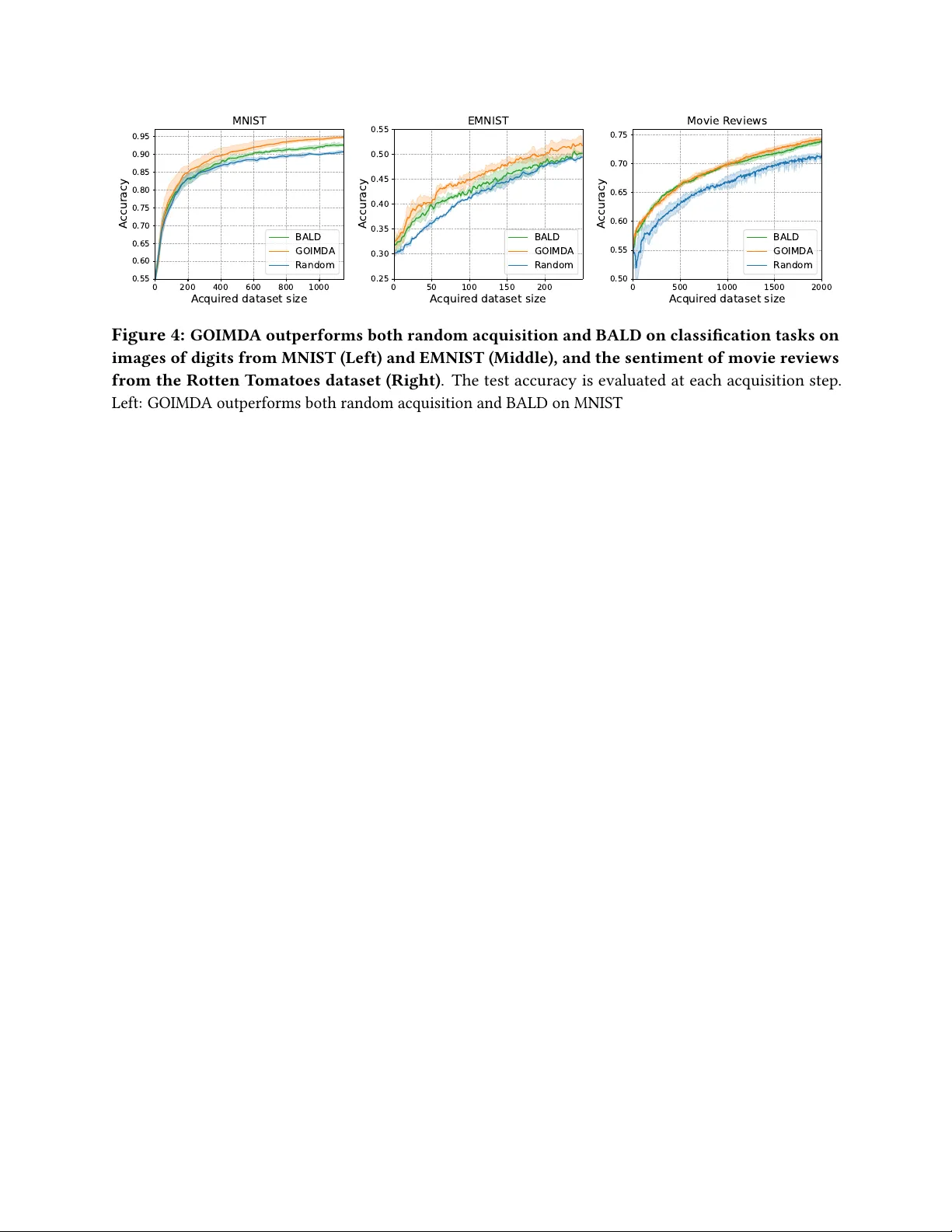
본 논문은 딥러닝 모델의 학습과 과학기술 최적화 문제에서 데이터 획득 비용을 획기적으로 줄이기 위한 새로운 능동적 획득 프레임워크인 GOIMDA(Goal-Oriented Influence-Maximizing Data Acquisition)를 소개한다. 연구의 동기는 신경망에 대한 신뢰할 만한 불확실성 추정의 어려움에 있다. 기존의 능동 학습이나 베이지안 최적화 방법들은 대부분 예측 분산이나 엔트로피 같은 불확실성 측정치에 의존하여 다음에 평가할 데이터 포인트를 선택한다. 그러나 딥러닝 모델에 대해 정확한 베이지안 추론은 계산적으로 불가능하며, 근사 방법들은 종종 부정확하거나 조정이 어려워 실제 적용에 한계가 있다.
GOIMDA는 이러한 문제를 '영향력(Influence)' 개념을 통해 우회한다. 핵심 아이디어는 다음에 획득할 데이터 포인트를 선택할 때, 그 포인트의 라벨이 현재 모델 파라미터에 미칠 '영향력'이 사용자가 지정한 '목표 함수(G)'를 얼마나 크게 개선시킬지에 기반하여 결정하는 것이다. 목표 함수 G는 테스트 데이터셋의 Negative Log-Likelihood, 예측 엔트로피, 최적화 문제에서는 모델이 추천하는 설계 지점의 예측값 등으로 유연하게 정의될 수 있다. 즉, GOIMDA는 "이 데이터를 추가하면 내 최종 목표가 얼마나 나아질까?"라는 질문에 답하는 방식으로 작동한다.
이 영향력을 계산하기 위해 논문은 통계학의 고전적 도구인 일차 영향 함수(First-Order Influence Function)를 활용한다. 이를 통해 모델을 재학습시키지 않고도, 특정 데이터 포인트를 학습 세트에 무한소만큼 가중치를 두어 추가했을 때 목표 함수 G의 변화율을 근사적으로 계산할 수 있는 닫힌 형식(Closed-Form)의 획득 점수를 유도한다. 이 점수는 세 부분의 곱으로 표현된다: 목표 함수의 파라미터에 대한 기울기(∇θG), 훈련 손실 함수의 역 헤시안(Hθ^-1), 그리고 후보 데이터 포인트의 손실 함수 기울기(∇θℓ(x_c, y_c)). 역 헤시안 항은 현재 데이터가 모델 파라미터를 얼마나 강하게 제약하는지(즉, 정보를 얼마나 제공하는지)를 나타내며, 불확실성의 대용 역할을 한다. 따라서 이 공식은 목표 개선을 위한 '활용'(Goal Gradient와 Candidate Sensitivity의 정렬)과 정보 부족 영역에 대한 '탐색'(Inverse Hessian)을 자연스럽게 결합한다.
이론적 분석 섹션에서는 일반화 선형 모델(Generalized Linear Models) 하에서 GOIMDA의 획득 규칙이 전통적인 예측 엔트로피 최소화 규칙과 근사적으로 일치함을 보인다. 다만 여기에 목표 함수의 기울기와 모델 예측의 편향(Bias)을 반영하는 보정 항이 추가된다. 이는 GOIMDA가 불확실성 최소화의 본질을 유지하면서도 사용자의 구체적 목표에 맞게 조정된 행동을 보인다는 것을 수학적으로 설명한다.
실험 평가는 광범위하다. 학습 태스크로는 CIFAR-10, AG News 데이터셋을 사용한 이미지 및 텍스트 분류를, 최적화 태스크로는 Branin, Ackley 함수와 같은 noisy 블랙박스 최적화 벤치마크와 신경망 하이퍼파라미터 튜닝을 수행했다. 비교 대상은 불확실성 샘플링, 베이지안 활성 학습 등 다양한 능동 학습 방법과, UCB, EI, PI, MES, KG 등 다양한 획득 함수를 사용한 가우시안 프로세스 베이지안 최적화 방법이다. 결과는 일관적이다: GOIMDA는 모든 태스크에서 기준선 방법들보다 더 빠른 수렴 속도, 즉 목표 성능 달성에 필요한 데이터 포인트나 함수 평가 횟수를 현저히 줄인다. 이는 제안된 방법이 이론적으로 타당할 뿐만 아니라 실질적인 효용성도 매우 높음을 입증한다. 논문은 결론에서 GOIMDA가 베이지안 추론의 복잡성 없이도 효과적인 탐색-활용 균형을 이루는 일반적 프레임워크로서, 계산 비용이 큰 과학기술 발견 및 엔지니어링 최적화 문제에 특히 유용할 것이라고 전망한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기