Goal-Oriented Influence-Maximizing Data Acquisition for Learning and Optimization
Active data acquisition is central to many learning and optimization tasks in deep neural networks, yet remains challenging because most approaches rely on predictive uncertainty estimates that are difficult to obtain reliably. To this end, we propos…
Authors: Weichi Yao, Bianca Dumitrascu, Bryan R. Goldsmith
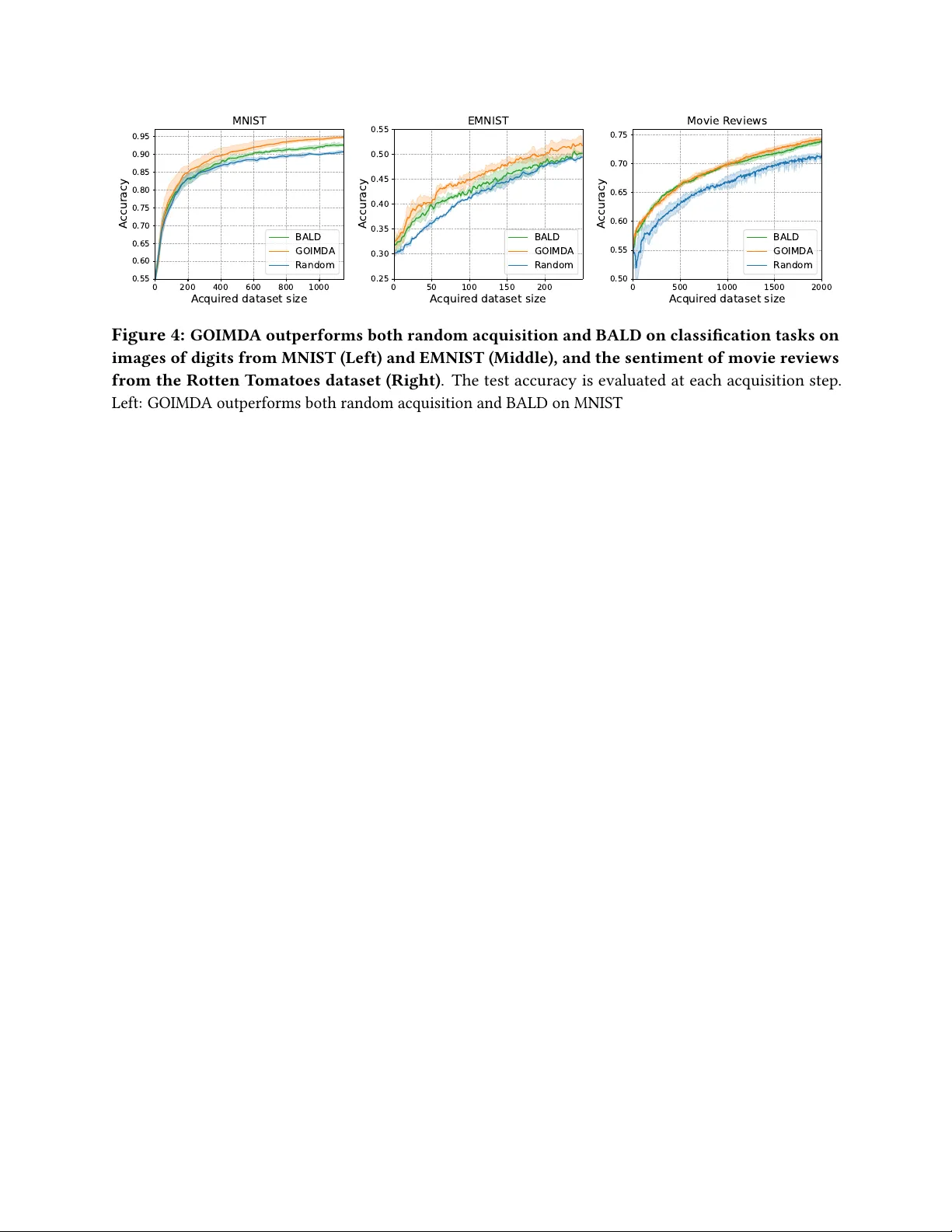
Goal-Oriented Inuence-Maximizing Data Acquisition for Learning and Optimization W eichi Y ao University of Michigan weichiy@umich.edu Bianca Dumitrascu Columbia University bmd2151@columbia.edu Bryan R. Goldsmith University of Michigan bgoldsm@umich.edu Yixin W ang University of Michigan yixinw@umich.edu February 24, 2026 Abstract Active data acquisition is central to many learning and optimization tasks in deep neural networks, yet r emains challenging because most approaches rely on predictive uncertainty estimates that are dicult to obtain reliably . T o this end, we propose Goal-Oriented Inuence- Maximizing Data Acquisition (GOIMD A ), an active acquisition algorithm that avoids explicit posterior inference while remaining uncertainty-aware through inverse curvature. GOIMD A selects inputs by maximizing their expected inuence on a user-specie d goal functional, such as test loss, predictive entrop y , or the value of an optimizer-recommended design. Leveraging rst-or der inuence functions, we derive a tractable acquisition rule that combines the goal gradient, training-loss cur vature, and candidate sensitivity to model parameters. W e show theoretically that, for generalized linear models, GOIMD A approximates predictive- entropy minimization up to a corr ection term accounting for goal alignment and prediction bias, thereby , yielding uncertainty-aware behavior without maintaining a Bayesian posterior . Empirically , across learning tasks (including image and text classication) and optimization tasks (including noisy global optimization benchmarks and neural-network hyperparameter tuning), GOIMD A consistently reaches target performance with substantially fewer labeled samples or function evaluations than uncertainty-base d active learning and Gaussian-process Bayesian optimization baselines. Ke ywords: De ep learning, Activ e acquisition, Bayesian optimization, A ctive learning, Inuence function 1 1 Introduction Active data acquisition is central to many learning and optimization problems in science and engineering, where evaluations or labels ar e costly , and budgets ar e limited. A prominent example arises in materials science, where the goal is to discover materials with exceptional properties dened over a vast design space of elemental compositions and atomic structures [ 1 , 2 ]. Evaluating a single candidate typically requires material synthesis followed by experimental testing, making each function evaluation expensive and time-consuming. Similar challenges appear in biological system identication, where researchers seek to characterize the response of a system to external stimuli [ 3 ]. In this setting, a predictive mo del—often a neural network—is trained on existing stimulus–response pairs and used to guide the selection of new stimuli that are expected to reduce prediction error . Each new response, howe ver , must be obtained through complex laboratory experiments, making data acquisition the primary b ottleneck. A third example is hyperparameter optimization for deep neural networks [ 4 ]. Hyperparameters govern both model architecture and training dynamics and have a large impact on performance. Evaluating a single conguration requires a full training and validation cy cle, which is computa- tionally expensive, especially for large-scale models. Across these domains, the common challenge is to optimize a task-specic obje ctive using as few evaluations as possible. A natural approach is iterativ e data acquisition: starting from an initial dataset D (which can be empty), one r epeatedly ts a model M to the curr ent data and selects the next input x to evaluate by maximizing an acquisition function a ( x ) that estimates the expected utility of labeling x . When neural networks are use d as the underlying model, most existing approaches, spanning Bayesian optimization and de ep active learning, rely on predictive uncertainty to guide data selection. For example , in materials design and hyperparameter tuning, Bayesian optimization methods often use posterior predictive uncertainty to balance exploration and exploitation [ 5 , 6 ], while in stimulus–response learning, uncertainty-based criteria dominate activ e learning prac- tice [ 7 – 10 ]. Uncertainty estimates ther ein are typically obtained via Bay esian neural networks [ 11 ] or ensemble-based methods [ 5 – 7 , 9 ]. Despite their popularity , reliable uncertainty estimation for deep neural networks r emains a major challenge. Exact Bayesian inference is intractable, and approximate methods are often compu- tationally expensive, sensitive to modeling choices, and poorly calibrated in high-dimensional regimes [ 11 – 13 ]. As a result, uncertainty-driven acquisition functions can b e unreliable or im- practical, limiting their eectiveness in modern deep learning pipelines. Main idea. T o address this challenge, we propose Goal-Oriente d Inuence-Maximizing Data Acquisition (GOIMD A) , an iterative acquisition algorithm that is uncertainty-aware without explicit posterior inference. Rather than quantifying predictive uncertainty , GOIMD A selects data points based on their expecte d inuence on a user-specie d goal objective function of the model parameters. 2 The goal can r epresent diverse scientic obje ctives, such as test loss, predictive entr opy , or the value of an optimizer-recommende d design. In other words, GOIMD A maximizes a goal objective function while minimizing data acquisition eorts. Using rst-order inuence functions, we deriv e a tractable acquisition rule that combines (i) the gradient of the goal objective, (ii) an inverse-curvature preconditioner given by the inverse Hessian of the empirical training loss, and (iii) each candidate’s sensitivity to the model parameters. The goal gradient and candidate sensitivity promote goal-directe d exploitation by favoring points whose induced parameter updates are most aligned with directions that improve the goal. At the same time, the inverse cur vature term acts as a local uncertainty proxy that encourages exploration by prioritizing updates in directions the current data constrains the least. This yields an exploration–exploitation trade-o without maintaining a Bay esian posterior [ 14 – 17 ]. More formally , let ( x, y ) denote a feature–label pair with x ∈ X and y ∈ Y , and let p 0 ( y | x ) be the unknown data-generating conditional distribution. W e assume that sampling inputs x is free, while observing lab els y is costly . Let M θ be a super vised model of p θ ( y | x ) with parameters θ , trained by minimizing the negative log-likelihood loss ℓ θ ; ( x, y ) = − log p θ ( y | x ) . The goal objective function G can be exibly dened for various scientic tasks that can be formulated as optimization problems. Without loss of generality , the following discussion focuses on minimizing G . W e consider the goal objective function G as a function of θ , which parametrizes and reects the best knowledge of the unknown distribution p 0 . Goal-Oriented Inuence-Maximizing Data Acquisition alternates between two steps: 1. At each step, we t a model p θ ( y | x ) with model parameters θ by minimizing the empirical risk function on the existing data set D θ ( D ) = arg min θ 1 |D | X ( u,v ) ∈D ℓ θ ; ( u, v ) . (1) 2. W e choose to lab el the next data point that maximizes the expecte d inuence I of any candidate x on the goal objective function G x next = arg max x E y I ◦ G θ ( D ∪ { ( x, y ) } ) , (2) where the inuence is measur ed by the instantaneous rate at which upw eighting x gives the maximum change in G I ◦ G θ ( D ∪ { ( x, y ) } ) := s · ∂ ∂ ϵ G θ ϵ ( D ∪ { ( x, y ) } ) ϵ =0 , (3) where s = ( +1 , maximization of G − 1 , minimization of G . 3 0 25 50 75 100 125 150 10 −4 10 −3 10 −2 10 −1 R egret Branin (d=2), var=0.01 0 20 40 60 80 100 10 −7 10 −5 10 −3 10 −1 10 1 Ackley (d=5), var=0.01 0 50 100 150 200 10 −4 10 −3 10 −2 10 −1 Dropwave (d=2), var=0.01 0 25 50 75 100 125 150 10 −4 10 −3 10 −2 10 −1 Branin (d=2), var=0.04 0 20 40 60 80 100 10 −7 10 −5 10 −3 10 −1 10 1 Ackley (d=5), var=0.04 0 50 100 150 200 10 −4 10 −3 10 −2 10 −1 Dropwave (d=2), var=0.04 GP+UCB GP+EI GP+PI GP+MES GP+KG GOIMDA 0.01 Figure 1: GOIMD A reaches lower imme diate regret with fewer acquisitions than Bayesian optimization baselines on noisy objective functions. The Bayesian optimization baselines are Gaussian Processes-based with acquisition functions: upper condence bound (GP+UCB), expected improvement (GP+EI), probability of improvement (GP+PI), max-value entropy search (GP+MES), and knowledge gradient (GP+K G). Immediate regret is reported at each acquisition step for the Branin, Ackley , and Dropwave benchmarks under two noise levels ( σ 2 = 0 . 01 , 0 . 04 ). Solid/dashed cur ves show the mean performance across runs, and shade d regions denote bootstrapp ed 95% condence intervals of the mean (computed across runs). Across all tasks, GOIMD A consistently achieves lower regret earlier in the acquisition process, with the advantage generally becoming more pronounced at higher noise levels. In this formulation, θ ϵ ( D ∪ { ( x, y ) } ) is the parameter estimate after x is adde d to the current dataset D with weight ϵ , and the output of any candidate x is approximated using resampling techniques such as Jackknife [ 18 ]. Contributions. W e introduce GOIMD A, a general active data acquisition framework that selects new queries by maximizing their expected rst-order inuence on a user-specied goal functional (e .g., test loss, predictive entropy , or the value of an optimizer-recommended design). W e derive a tractable inuence-base d acquisition rule that couples the goal gradient, training-loss curvature (via inverse-Hessian–vector products), and candidate sensitivity . W e provide a scalable implementation using a Jackknife/deep-ensemble surrogate to appro ximate unknown lab els and stochastic inverse- Hessian vector product solvers to handle modern neural networks. W e further develop theoretical results under e xponential-family models, showing that GOIMD A approximates predictive-entropy minimization up to a correction term that accounts for goal alignment and prediction bias. This result explains ho w GOIMD A captures uncertainty-r elated behavior through the same cur vature structure that underlies predictive entropy , while modulating it via goal alignment and prediction bias, but without maintaining a posterior over θ . 4 Finally , we demonstrate empirically across a range of learning and optimization tasks, including image and text classication, noisy global optimization benchmarks, and neural-network hyperpa- rameter tuning, that GOIMD A consistently achieves target performance with substantially fewer labeled samples or function evaluations than uncertainty-based activ e learning algorithms and Gaussian-process Bayesian optimization baselines. Se e Figure 1 for an example, wher e we bench- mark GOIMD A on noisy black-box function optimization from [ 19 ] with ve other commonly used Gaussian Processes (GP)-based Bayesian optimization methods with dierent acquisition functions, namely , probability of improv ement (PI) [ 20 ], expected improvement (EI) [ 21 ], upper condence bound (UCB) [ 22 ], max-value entr opy sear ch (MES) [ 23 ], and kno wledge gradient (K G) [ 24 – 26 ]; more details pro vided in Section 5 for empirical studies. Organization. The rest of the pap er is organized as follows: Section 2 presents the GOIMD A algorithm and its scalable implementation. Section 3 develops theory under exponential-family models and connects GOIMDA to predictive-entropy-based acquisition. Se ction 5 reports empirical results on learning and optimization benchmarks. It concludes with a discussion of related work in Section 6, along with the scope and limitations in Se ction 7. 2 Goal-Oriented Inuence-Maximizing Data Acquisition W e introduce goal-oriente d inuence-maximizing data acquisition (GOIMD A) . Unlike standard acquisition strategies that optimize pr oxy criteria ( e.g., predictive uncertainty alone), GOIMD A allows the user to specify an explicit goal objective G ( θ ( D )) , which encodes the scientic task of interest and depends on the model parameters θ ( D ) learned from the currently labeled dataset D . At each iteration, the objective is to acquire the data point whose label is expecte d to yield the largest improv ement in this goal. A naïve implementation would r etrain the model for e very candidate x to evaluate the p ost-update value of G , which is computationally infeasible. W e therefore develop an inuence-function-based approximation . Using classical inuence functions, w e estimate the rst-or der change in G induced by innitesimally upweighting a candidate example . This yields a tractable acquisition score that couples: (i) the goal gradient ∇ θ G , (ii) a cur vature preconditioner given by the inverse Hessian of the empirical training loss, and (iii) the candidate ’s parameter sensitivity ∇ θ ℓ ( θ ; ( x, y )) . T o handle unknown candidate labels and to scale to modern neural networks, we further intr oduce (a) a surrogate ensemble to approximate expe ctations over unknown labels and (b) scalable implicit inverse–Hessian–vector products, av oiding explicit construction of H − 1 θ . The remainder of this section species representative goal obje ctives G , derives the inuence-function-based acquisition rule, and presents practical algorithms for ecient implementation. 2.1 Goal Objective Function W e consider the goal objective G dened as a function of the current tted parameters θ := θ ( D ) , which summarize the most up-to-date model induced by the acquir ed dataset D . This formulation allows G to be exibly instantiated to match dierent scientic tasks. 5 Global optimization. Consider minimizing an unknown function f , whose observations take the form y = f ( x ) + ϵ . This setting covers applications such as materials design and neural-network hyperparameter tuning. Let x ∗ = arg min x f ( x ) denote the true minimizer , which is unknown. W e dene the goal obje ctive G as G opt ( θ ) := E y ∼ p 0 ( ·| ˆ x ∗ θ ) [ y ] , (4) the expected property value at the model’s recommended minimizer ˆ x ∗ θ , obtained by minimizing model’s predictive mean E y ∼ p θ ( ·| x ) [ y ] . T argeted supervise d learning. For super vised learning problems where performance is evaluated on an unlabeled target set U that shares the same conditional distribution p 0 ( y | x ) , we dene G as a utility function over U . A common choice is the negative log-likelihood: G nll ( θ ) := − X x ∈U E y ∼ p 0 ( ·| x ) [log p θ ( y | x )] . (5) When the objective places greater importance on reducing errors for hard or low-condence predictions, as opposed to uniformly penalizing all examples, we adopt the focal loss [ 27 ]: G foc ( θ ) := − X x ∈U E y ∼ p 0 ( ·| x ) (1 − p θ ( y | x )) γ log p θ ( y | x ) , (6) where γ is a predened focused parameter or the relaxation parameter . Entropy-based objectives. If the goal is to reduce pr edictive uncertainty on U , we use the Shannon entropy of the model’s predictive distribution: G ent ( θ ) := − X x ∈U E y ∼ p θ ( ·| x ) [log p θ ( y | x )] . (7) Although G ent and G nll share the same functional form, they dier in the underlying e xpectation: the former is taken with respect to the model distribution p θ , while the latter is evaluated under the true conditional distribution p 0 . Overall, these e xamples illustrate that the goal objective G can be adapted to a wide range of tasks. Without loss of generality , we focus on settings where the objective is to minimize G . 2.2 Inuence Function 2.2.1 Goal-based informativeness Given a goal minimization objective G , we call a candidate input x c informative if acquiring its label is expecte d to aect the model update and hence reduce G the most. Intuitively , a candidate data point is informative if its inclusion would substantially alter the learned model parameters and, as a result, lead to a signicant reduction in the goal obje ctive. This notion is formalized below . 6 Denition 1 (Informativeness) . Given a goal objective G and a current dataset D , the informativeness of a candidate input x c is measured by the change in the goal obje ctive after adding x c to D : ∆ G := G θ ( D ∪ { ( x c , y c ) } ) − G ( θ ( D )) . (8) Here, θ ( D ) and θ ( D ∪ { ( x c , y c ) } ) denote the parameters before and after acquiring x c , respectively . Although this denition is conceptually clear , directly e valuating ∆ G is computationally infeasible, as it requires retraining the model for every candidate x c and every possible label y c . In the following, we introduce an inuence-function-based approximation [ 28 ] that enables ecient estimation of informativeness without retraining the model. 2.2.2 Inuence function approximation W e dene the inuence of a candidate p oint ( x c , y c ) on the goal objective G as the instantaneous change in G induced by innitesimally upweighting this p oint in the training objective; se e (3). In the case of minimizing the goal objective G , the inuence dened takes the instantane ous rate with a negative sign I ◦ G θ ( D ∪ { ( x c , y c ) } ) = − ∂ ∂ ϵ G θ ϵ ( D ∪ { ( x c , y c ) } ) ϵ =0 , (9) where θ ϵ ( D ∪ { ( x c , y c ) } ) is the parameter estimate when x c is added to D with weight ϵ : θ ϵ ( D ∪ { ( x c , y c ) } ) = arg min θ 1 |D | X ( u,v ) ∈D ℓ θ ; ( u, v ) + ϵ ℓ θ ; ( x c , y c ) . (10) Maximizing the inuence score for maximizing informativeness. The following result shows that maximizing the reduction in G when candidate x c is added in the training set D can be linearly approximated by maximizing I ◦ G ( θ ( D ∪ { ( x c , y c ) } )) without retraining the model. Proposition 2. The inuence score of a candidate point ( x c , y c ) on the goal minimization obje ctive G , dened in (9), approximates the reduction in G after adding x c to D . Proof. By denition of ∆ G in (8), ∆ G is negative for minimization of the goal obje ctive G . T o maximize the reduction in G , we maximize − ∆ G . Since applying the rst-order T aylor expansion on the goal objective function G θ ϵ ( D ∪ { ( x c , y c ) } ) at ϵ = 0 gives G θ ϵ ( D ∪ { ( x c , y c ) } ) = G ( θ ( D )) + h ∂ ∂ ϵ G θ ϵ ( D ∪ { ( x c , y c ) } i ϵ =0 · ϵ + o( ϵ 2 ) , (11) we have − ∆ G ≈ − 1 |D | h ∂ ∂ ϵ G θ ϵ ( D ∪ { ( x c , y c ) } i ϵ =0 (9) = 1 |D | I ◦ G θ ( D ∪ { ( x c , y c ) } ) . (12) Therefore , we can linearly approximate the reduction in test loss due to adding x c without retraining the model by computing 1 |D| I ◦ G . 7 Under a minimization obje ctive, the most informative data point is the one that induces the greatest reduction in the goal obje ctive. Proposition 2 shows that the reduction can be linearly approximated via the inuence score. As a result, selecting the most informative data point reduces to cho osing the candidate with the maximum inuence [ 29 ]. In this precise sense, the inuence-score-based acquisition criterion is w ell justied: it corresponds to the greedy choice that most eectively decreases G under a rst-order inuence approximation. 2.2.3 Closed-form inuence score W e now derive a closed-form expression for the inuence score, which yields a tractable acquisition criterion. The explicit form of (9) can be derived by rst applying the chain rule: I ◦ G θ ( D ∪ { ( x c , y c ) } ) = − h ∇ θ G θ ( D ) i ⊤ · h ∂ ∂ ϵ θ ϵ D ∪ ( { x c , y c } ) i ϵ =0 , (13) T o evaluate the parameter sensitivity term, we apply standard inuence-function arguments. Using the rst-order optimality condition of θ ϵ ( D ∪ { ( x c , y c ) } ) and the fact that θ ϵ ( D ∪ { ( x c , y c ) } ) → θ ( D ) as ϵ → 0 [ 30 ], a classical T aylor expansion on ∂ ∂ ϵ θ ϵ ( D ∪ { ( x c , y c ) } ) in (13) at ϵ = 0 gives ∂ ∂ ϵ θ ϵ D ∪ ( { x c , y c } ) ϵ =0 ≈ − H − 1 θ h ∇ θ ℓ θ ; ( x c , y c ) i θ = θ ( D ) , (14) where H θ is the Hessian matrix H θ := 1 |D | X ( u,v ) ∈D ∇ 2 θ ℓ θ ; ( u, v ) . (15) Substituting (14) into (13) yields a closed-form appro ximation ˜ I ◦ G θ ( D ∪ { ( x c , y c ) } ) for (13). Since the candidate label y c is unknown at acquisition time, w e take expectation with respect to the true conditional distribution p 0 ( y | x c ) , obtaining the expected inuence score E y c ∼ p 0 ( ·| x c ) ˜ I ◦ G θ ( D ∪ { ( x c , y c ) } ) = h ∇ θ G θ ( D ) i ⊤ H − 1 θ h ∇ θ E y c ∼ p 0 ( ·| x c ) ℓ θ ; ( x c , y c ) i θ = θ ( D ) . (16) Equation (16) provides an explicit, rst-or der approximation to the inuence of a candidate p oint on the goal objective G , without requiring access to the r etrained parameters θ ( D ∪ { ( x c , y c ) } ) . Consequently , the most informative candidate can be sele cted by maximizing (16) . This yields an ecient goal-oriented data acquisition rule that directly targets reductions in G while avoiding the computational cost of retraining the model for every candidate. 2.3 Practical and Scalable Implementation By denition, the inuence score in (9) with a close d-form expression (16) traces how the optimiza- tion of the goal objective G propagates through the learned parameters θ and back to individual training data points, thereby identifying the point with the greatest potential to reduce G . Propo- sition 2 further shows that maximizing the inuence score provides an ecient approximation to maximizing the informativeness in terms of reduction in G . 8 Howe ver , computing the close d-form inuence score in (16) is nontrivial. First, evaluating the inuence of any candidate input on the goal objective typically requires expectations over the true conditional distribution p 0 ( y | x ) , which is unavailable in practice. Second, as the numb er of acquired data points |D | grows, directly computing the inverse Hessian H − 1 θ dened in (15) becomes prohibitively expensive, making naive inuence-based acquisition infeasible. In this section, we introduce practical and scalable algorithms that address both challenges and enable ecient computation of the inuence function in (16). Approximating the unknown output variable. Goal objectives G ( θ ) are often dene d on unknown target outputs, such as (4) for iterative global optimization and (5) for active learning. At the same time, the inuence score is e valuated at θ ( D ∪ { ( x c , y c ) } ) , where the candidate output y c is unknown prior to acquisition. Conse quently , computing the inuence score of any candidate x c requires an approximation of the goal objective G with potentially unknown target outputs and the corresponding output y c . Most existing work that applies inuence functions to iterative data acquisition operates within an active learning framew ork [ 31 , 32 ]. One line of work selects goal objectives, such as negative prediction entropy (7) or variants of the Fisher Information Ratio [ 33 ], which depend only on the current model p θ and do not explicitly target the test p erformance under the true data-generating distribution [ 31 ]. Another approach derives acquisition functions from upper bounds on the test loss, leading to criteria based on the gradient norm ∥∇ θ E y c ∼ p θ ( ·| x c ) [ ℓ ( θ ; ( x c , y c ))] ∥ [ 32 ]. In both cases, the unknown candidate outputs y c are appro ximated using the current model posterior p θ , relying solely on training information. In contrast, our objective is to directly optimize goal functions dened under the unknown true distribution p 0 , such as test loss in active learning or the minimal value in iterative global optimization. T o this end, we approximate the unknown output without r elying on the posterior of the primary mo del p θ . Specically , we introduce a surrogate mo del ˜ M ϕ with model parameter ϕ , implemente d as an ensemble of r neural networks with dierent random initializations and trained on dierent subsets of the training data. This approach is closely related to deep ensembles, which have been shown to improv e predictive accuracy , uncertainty estimation, and robustness to distributional shift [ 34 ]. T o further enhance predictive stability , we employ the Jackknife resampling te chnique [ 18 ]. Each ensemble memb er is trained on a Jackknife subsample of the available data, and the surrogate model outputs the average pr ediction across all r networks. The resulting Jackknife estimation has computational complexity O ( r m ) , where m is the numb er of model parameters. Computing the inverse Hessian–vector product. Evaluating (16) requires computing the inverse of the Hessian matrix dened in (15). For a model M with m trainable parameters and a dataset D of size n , explicitly forming and inv erting the Hessian incurs a computational cost of O ( nm 2 + m 3 ) , which is infeasible for modern neural networks with millions of parameters. T o avoid explicit Hessian inversion, we approximate inverse Hessian–vector products (H VPs), which can be compute d in linear time with respect to the numb er of parameters using automatic dierentiation frameworks such as PyTorch and JAX . A common approach is to use conjugate 9 Algorithm 1 Goal-Oriented Inuence-Maximizing Data Acquisition Input: The initial data set D 1: r epeat 2: Update both main mo del M θ and the ensemble model ˜ M ϕ on D 3: Select x next ← arg max x E y ∼ p ϕ ( ·| x ) ˜ I ◦ G ϕ θ ( D ∪ { ( x, y ) } ) {see approximation in (18)} 4: Query y next ← O BSERVE ( x next ) 5: A ugment D ← D ∪ { ( x next , y next ) } 6: until termination condition is met {e .g. budget exhausted or desired goal achieved} gradient (CG) methods [ 35 ], which solve min u u ⊤ ( H 2 + λI ) u − ( H v ) ⊤ u, where the solution u ∗ approximates H − 1 v . With L CG iterations, the computational cost is O ( nL ) , and in practice, convergence can often be achiev ed with a small number of iterations [ 36 ]. When the training dataset is very large, the linear dependence on n can still be costly . Alternatively , we adopt the LiSSA algorithm [ 37 ], which recursively estimates the inv erse H VPs via ˆ H − 1 j v = v + ( I − H ) ˆ H − 1 j − 1 v , ˆ H − 1 0 v = v . LiSSA stochastically approximates inverse H VPs using mini-batches of data at each iteration. With batch size B and L iterations, the computational complexity is O ( nm + B Lm ) . Both CG and LiSSA are well-suited to large-scale settings with limited memor y , and empirically , we obser ve no signicant dierence between them in terms of acquisition performance. Goal-Oriented Inuence-Maximizing Data Acquisition (GOIMDA ): A general ecient iterative acquisition algorithm. In practice, we select the next acquisition point by x next = arg max x c E y c ∼ p ϕ ( ·| x c ) ˜ I ◦ G ϕ θ ( D ∪ { ( x c , y c ) } ) , (17) where the inuence term admits the explicit appr oximation ˜ I ◦ G ϕ θ ( D ∪ { ( x c , y c ) } ) = h ∇ θ G ϕ θ ( D ) i ⊤ ˆ H − 1 θ h ∇ θ ℓ θ ; ( x c , y c ) i θ = θ ( D ) . (18) Here, G ϕ denotes the goal objective approximated using the surrogate model ˜ M ϕ with model parameter ϕ in the absence of direct access to p 0 , and ˆ H − 1 θ denotes a stochastic approximation of the inv erse Hessian obtained via implicit H VPs. Se e Algorithm 1 for the complete algorithm. 3 Theoretical Properties of GOIMD A under Exponential Family Models In this section, w e study goal-oriented inuence-maximizing data acquisition ( GOIMDA ) under ex- ponential family models. W e rst formalize the exponential-family setting and derive GOIMD A in closed form. W e then provide a ge ometric interpretation of the resulting inuence function, clarify the role of the bias term, and compare GOIMDA with predictive-entr opy–based acquisition. 10 Our study reveals that GOIMDA decomposes naturally into three interacting comp onents: (i) goal alignment , captured by the gradient ∇ θ G ; (ii) cur vature preconditioning , gov erned by the inverse Hessian H − 1 θ of the empirical training loss ; and (iii) a prediction-bias term that quanties the discrepancy between the model and the true data-generating mechanism. T ogether , these components dene an acquisition criterion that is uncertainty-aware in a local, cur vature-based sense : the inverse-curvature term prioritizes candidates that induce updates along parameter directions that are not yet w ell constrained by the current data. For canonical Generalized Linear Models (GLMs), w e make this connection explicit by sho wing that GOIMDA inherits the same H − 1 θ leverage factor that app ears in predictive-entropy acquisition, while rew eighted by goal alignment and prediction bias. Moreover , we derive a parameter-space surrogate for the bias term that replaces the unknown true conditional distribution with an estimable parameter discrepancy , yielding a fully tractable acquisition rule. Overall, these results position GOIMD A as an exploration-awar e, bias-focuse d improvement sur- rogate : it targets regions that are b oth inuential for the goal and informative about mo del misspecication, without requiring a posterior distribution over θ . Model setup. Let x ∈ R d and y ∈ R . W e model the conditional distribution y ∼ p θ ( · | x ) using an exponential family of the form p θ ( y | x ) = h ( y ) exp η θ ( x ) T ( y ) − A η θ ( x ) , (19) where T ( y ) is the sucient statistic and η θ ( x ) is the natural parameter , parameterized by θ . 1 Exponential family distributions enjoy several w ell-known statistical properties: (3.1) the log-partition function A ( η is convex; (3.2) E η [ T ( y )] = A ′ ( η ) ; (3.3) v ar η [ T ( y )] = A ′′ ( η ) . In this setting, the natural parameter η θ ( x ) is modeled by a deep neural network with parameters θ , trained via the negative log-likelihood loss ℓ ( θ ; ( x, y )) := − log p θ ( y | x ) , explicitly , ℓ θ ; ( x, y ) = − log h ( y ) − η θ ( x ) T ( y ) + A ( η θ ( x )) . (20) Inuence score. Using the loss denition for ℓ ( θ ; ( x, y )) in (20), the gradient of the expected loss at a candidate input x c under the true data-generating distribution p 0 ( · | x c ) is given by ∇ θ E y c ∼ p 0 ( ·| x c ) ℓ θ ; ( x c , y c ) = ∇ θ η θ ( x c ) A ′ η θ ( x c ) − A ′ η 0 ( x c )) . Substituting this expr ession into the closed-form inuence score (16) yields the following goal- oriented inuence (GOI) score: GOI ( x c ) = ∇ θ G ( θ ) ⊤ H − 1 θ ∇ θ η θ ( x c ) A ′ η θ ( x c ) − A ′ η 0 ( x c )) . (21) 1 W e do not explicitly distinguish between scalar and vector-valued parameters in the notation. 11 When T ( y ) = y , the term A ′ η θ ( x c ) − A ′ η 0 ( x c )) in (21) reduces to E θ [ y | x c ] − E 0 [ y | x c ] , which corresponds to the prediction bias at x c . Consequently , the next point to acquire is sele cted as x next = arg max x c GOI ( x c ) . Geometric interpretation of the inuence function. The acquisition criterion in (21) selects the candidate whose curvature-aware parameter p erturbation is most aligned with the direction that maximally decreases G , while prioritizing regions where the model is currently biased. Dene µ := H − 1 / 2 θ ∇ θ G ( θ ) , ν ( x c ) := H − 1 / 2 θ ∇ θ η θ ( x c ) , and b ( x c ) := A ′ ( η θ ( x c )) − A ′ ( η 0 ( x c )) . With these denitions, the goal-oriented inuence score can be written as GOI ( x c ) = ⟨ µ, ν ( x c ) ⟩ | {z } goal alignment in the H θ -geometry × b ( x c ) | {z } prediction bias E θ [ y | x c ] − E 0 [ y | x c ] , (22) where the rst factor quanties ho w str ongly a curvature-aware update in the dir ection suggested by x c is expected to de crease G , and then the second factor gates this directional ee ct by the magnitude of the local predictive bias. Concretely , µ acts as a sensitivity vector that encodes which parameter directions matter for im- proving G , whereas ν ( x c ) characterizes the candidate’s induced update direction after accounting for lo cal cur vature. The preconditioning by H − 1 θ transforms Euclidean gradients into se cond- order–aware directions, down-weighting parameter components that are already w ell-determined by existing data and amplifying directions where the model remains uncertain or weakly identied; this yields an approximately reparameterization-invariant notion of alignment and prioritizes candidates that can meaningfully rene the mo del in parts that are not yet well determined. Finally , the multiplicativ e bias factor b ( x c ) converts this leverage in parameter space into e xpected improv ement of the goal. That is, if the model is already well-calibrated at x c then b ( x c ) ≈ 0 and the predicted rst-order gain is negligible, whereas a larger | b ( x c ) | steers acquisition toward regions where the predictive mean deviates from the data-generating process and parameter updates translate into tangible reductions of G . The bias term. T o obtain a tractable approximation of the bias term, w e apply a rst-order T aylor expansion of A ′ η 0 ( x c ) around θ 0 = θ , yielding A ′ η θ ( x c ) − A ′ η 0 ( x c )) ≈ ∇ θ η θ ( x c ) ⊤ ( θ − θ 0 ) A ′′ η θ ( x c ) . (23) Substituting this approximation into (22) giv es GOI ( x c ) = ⟨ µ, ν ( x c ) ⟩ | {z } goal alignment in the H -geometry × ∇ θ η θ ( x c ) ⊤ ( θ − θ 0 ) | {z } directional parameter bias at x c A ′′ η θ ( x c ) . (24) which makes the dependence on the parameter bias θ − θ 0 explicit. The ge ometric decomp osition in (22) highlights prediction bias at the output level through the discrepancy in predictive means. In contrast, the approximation in (24) replaces the unobservable term A ′ ( η 0 ) with the estimable parameter bias ( θ − θ 0 ) . This re-expression attributes bias to 12 concrete directions in parameter space via ∇ θ η θ ( x ) and recovers the familiar structur e of GLMs, where b ( x ) ≈ A ′′ ( η θ ( x )) x ⊤ ( θ − θ 0 ) . This form will be leveraged in the subsequent comparison with predictive-entrop y–based acquisition. Connection to predictive entropy (PE) minimization. The most widely use d acquisition criteria in active learning are uncertainty-based. In contrast, inuence-maximizing acquisition does not explicitly require uncertainty estimates of the predictive model M θ . For neural networks, such uncertainty estimates ar e often computationally expensive to obtain and unr eliable in the early stages of data acquisition, when the training set is small. Despite this apparent dierence, ther e is a close connection between inuence maximization and predictive entropy minimization in Bayesian GLMs. In particular , for GLMs with a canonical link, inuence maximization can be interpreted as an approximation to predictive entropy minimization, as formalized in Proposition 3. Proposition 3. Inuence maximization approximates predictive entropy minimization in GLMs with a canonical link. Under mild assumptions, the two objectives dier by an additional term that calibrates the directional parameter bias up to a constant. Proof. Consider a generalized linear model in the form of (19) with a canonical link η θ ( x ) = x ⊤ θ and T ( y ) = y . The conditional entropy of model after acquiring ( x c , y c ) can be derived as H ( θ | D ∪ { ( x c , y c ) } ) = 1 2 E y c ∼ p 0 ( ·| x c ) log | H − 1 θ c | + const (25) where H θ c is the Hessian of negative log likelihoo d with model parameter θ c = θ ( D ∪ { ( x c , y c ) } ) . Under the canonical-link assumption and properties (3.2) and (3.3), minimizing (25) can be simpli- ed to minimize [ 38 ] E y c ∼ p 0 ( ·| x c ) log | H − 1 θ c | = log | H − 1 θ | − log 1 + x ⊤ c H − 1 θ x c A ′′ η θ ( x c ) . (26) Denote z = x ⊤ c H − 1 θ x c A ′′ η θ ( x c ) . Giv en that A ′′ η θ ( x c ) is bounded and x ⊤ c H − 1 θ x c → 0 as |D | → ∞ [ 39 ], if z is suciently small, the standard linear approximation log(1 + z ) = z + o( z ) further simplies the acquisition objective function as PE ( x c ) := − x ⊤ c H − 1 θ x c A ′′ η θ ( x c ) . (27) On the other hand, the acquisition score under GOIMD A (24) is GOI ( x c ) := ∇ θ G ( θ ) ⊤ H − 1 θ x c x ⊤ c ( θ − θ 0 ) | {z } prediction bias A ′′ η θ ( x c ) , (28) where the additional directional parameter bias term coincides with the prediction bias under the context of GLMs with a canonical link. By comparing objective in (27) with the one in (28), GOIMDA diers by multiplicative goal- alignment and bias weights: GOI ( x c ) ∝ PE ( x c ) · ⟨ H − 1 / 2 θ ∇ θ G ( θ ) , H − 1 / 2 θ x c ⟩ ∥ H − 1 / 2 θ x c ∥ 2 · x ⊤ c ( θ − θ 0 ) . (29) 13 This observation indicates that GOIMD A implicitly calibrates mo del uncertainty . The only distinc- tion is that GOIMD A weights each parameter dimension according to its current bias, wher eas predictive entrop y minimization treats all dimensions uniformly . Proposition 3 shows that, for canonical GLMs, GOIMD A inherits the same H − 1 θ leverage structur e A ′′ ( η θ ( x c )) x ⊤ c H − 1 θ x c that underlies predictive-entr opy selection. Crucially , GOIMDA calibrates this uncertainty signal through two additional factors: (i) a goal-alignment term that projects parameter updates onto the descent direction of G , and (ii) a prediction-bias term that emphasizes inputs where the model disagrees with the data-generating mechanism. As a result, GOIMDA is uncertainty-aware ; it preser ves the predictive-entrop y signal, while actively steering acquisition toward directions that most eectively reduce the stated goal and toward regions of systematic error , all without requiring a posterior distribution over θ . Consequently , although GOIMD A is derived as a goal-directed inuence maximization procedure and is therefore inherently exploitative, it remains exploration-aware : it prefer entially scores candidates in high-lev erage, high-variance r egions, thereby implicitly encouraging e xploration. This should be distinguished from Bayesian e xploration, which integrates over a p osterior on θ ; here, θ ( D ) is held xed. In active learning, where prediction calibration is rarely made explicit, the bias term focuses acquisition on mist or systematically mislabeled regions. Empirically , the results in Section 5.1 show that incorporating this bias achie ves target accuracy with substantially fewer labels than omitting it, conrming that calibrating bias materially improv es sample eciency . In global optimization, GOIMD A plays the role of an exploration-aware, exploitation-focused alternative that mirrors the exploitation component of Bayesian optimization without requiring a p osterior . 4 Example Applications of GOIMD A W e instantiate the GOIMD A framework for three repr esentative use cases: global optimization of noisy functions , where the goal is to identify the minimizer of a comple x, expensive-to-evaluate objective under noise; hyperparameter tuning , where the aim is to achieve optimal test performance while minimizing the number of costly training-and-validation evaluations; and deep active learning , where the objective is to train a classication model that generalizes well using as fe w labeled samples as p ossible. Owing to the exibility of the user-dened goal objective function, GOIMD A applies naturally across a wide range of problem settings. As introduce d in Se ction 2, the goal objective can be dened to address global optimization problems involving black-b ox objectives that lack analytical expressions and do not admit rst- or second-order derivatives; see (4). W e also presented the goal functions tailored to deep active learning, where the obje ctive is to optimize p erformance on a validation or test set under a limited labeling budget; se e (5) and (7). In this section, we focus on exponential family mo dels to illustrate how GOIMD A can b e instan- tiated in practice for both global optimization and active learning. For each example , we rst specify the corresponding goal objective G , and then derive the r esulting inuence-function–based acquisition rule (17) used in Algorithm 1. 14 4.1 Example Application I: Iterative Global Optimization with Noisy Observations W e consider a global optimization problem of the form x min = arg min x f ( x ) for an unknown objective function f . Direct evaluations of f are unavailable; instead, we observe noisy function values y = f ( x ) + ε , where ε is zero-mean noise . At each iteration, model M θ with parameters θ := θ ( D ) is traine d on the currently acquired dataset D = { ( u i , v i ) } n i =1 to approximate the underlying function f . W e dene the goal objective G as in (4), the expe cted value of the true function at the model’s recommended minimizer . Under the exponential family assumption with T ( y ) = y , this objective can be written as G ( θ ) := E y ∼ p 0 ( ·| ˆ x ∗ θ ) [ y ] (3 . 2) = A ′ η 0 ( ˆ x ∗ θ ) , (30) with the model’s recommended minimizer ˆ x ∗ θ = arg min x E y ∼ p θ ( ·| x ) [ y ] . (31) By construction, GOIMD A selects the candidate whose acquisition yields the largest instantaneous expected de crease in the true obje ctive evaluated at the model’s current r ecommendation. The gradient of the goal objective with respect to θ follows from the chain rule: ∇ θ G ( θ ) := A ′′ η 0 ( ˆ x ∗ θ ) ∂ ∂ θ ˆ x ∗ θ ∇ x η 0 ( ˆ x ∗ θ ) . (32) The derivative ∂ ∂ θ ˆ x ∗ θ can b e obtained via implicit dierentiation of the optimality conditions dening ˆ x ∗ θ (see Appendix A for details), yielding the approximation ∂ ∂ θ ˆ x ∗ θ ≈ h ∂ 2 ∂ θ ∂ x A ′ η θ ( ˆ x ∗ θ ) i ∇ 2 x A ′ η θ ( ˆ x ∗ θ ) − 1 . (33) Substituting these expressions into the inuence function (21) yields the following e xplicit decom- position of the Goal-Oriented Inuence score: GOI ( x c ) = A ′′ η 0 ( ˆ x ∗ θ ) ∇ x η 0 ( ˆ x ∗ θ ) ⊤ | {z } how the true objective drops if ˆ x ∗ θ moves ∇ 2 x A ′ ( η θ ( ˆ x ∗ θ )) − 1 ∂ 2 ∂ θ ∂ x A ′ ( η θ ( ˆ x ∗ θ )) | {z } how ˆ x ∗ θ moves when θ moves H − 1 θ ∇ θ η θ ( x c ) b ( x c ) | {z } how θ moves when adding ( x c ,y c ) , (34) where b ( x c ) := A ′ η θ ( x c ) − A ′ η 0 ( x c )) denotes the prediction-bias term introduced in (22). In practice, the unknown true natural parameter η 0 ( · ) is approximated using a Jackknife resampling strategy with the deep ensemble model ˜ M ϕ , and inverse H VPs are computed stochastically , as described in Se ction 2. 15 4.2 Example Application II: Hyperparameter Optimization W e next consider hyp erparameter tuning for neural networks under a transfer learning setup, which induces a more complex optimization problem. Hyperparameters determine the model architecture and training conguration, and dier ent choices of hyperparameters typically lead to dierent trained parameters and, consequently , dierent test performance. Evaluating even a single hyperparameter conguration requires training and validating a neural network, which is computationally expensive . The goal is therefor e to identify hyperparameters that yield strong test performance while minimizing the number of costly training and validation runs. Formally , let ξ ∈ Ξ denote the hyperparameters of a model trained on a xe d training dataset D tr = { ( x tr i , y tr i ) } n i =1 , and let ( x, y ) ∈ X × Y denote a test input–output pair , where y may be unobserved. 2 Denote the predictive test negative log-likelihoo d loss obtained by a model trained with hyperparameters ξ as h 0 ( x, ξ ) , which depends on b oth the test input x and the hyperparameters ξ . Due to stochastic ee cts such as random initialization and optimization noise, repeated training with the same ξ can yield dierent validation outcomes. As a result, w e only observe noisy evaluations of h 0 in its noisy form, r = h 0 ( x, ξ ) + ε , where ε denotes observation noise. The goal is to optimize h 0 with respect to ξ given x , as the “mean” test performance is indierent to stochastic variability in the model training. Let q 0 ( · | x, ξ ) denote the true conditional distribution of the noisy observation r given the concatenated input ( x, ξ ) , parameterized by θ 0 . W e train a mo del with parameters θ on the currently acquired dataset D , whose elements take the form ([ x, ξ ] , r ) . Under the exponential family assumption, the likelihood is q θ ( r | x, ξ ) = h ( r ) exp η θ ( x, ξ ) T ( r ) − A η θ ( x, ξ ) . (35) The search for the set of hyperparameters that yields optimal expected test performance is then formulated via the goal objective G ( θ ) := E r ∼ q 0 ( ·| x, ˆ ξ ∗ θ ) [ r ] , (36) where ˆ ξ ∗ θ denotes the minimizer of model M θ ’s predictive test negative log-likelihood loss ˆ ξ ∗ θ = arg min ξ E r ∼ q θ ( ·| x,ξ ) [ r ] . (37) The formulation in (36) mirrors the iterativ e global optimization with noisy observations in (30), with the decision variable spe cialized to hyperparameters for xed test inputs. Consequently , the inuence score for hyperparameter acquisition can be derived analogously to (34). 4.3 Example Application III: Deep Active Learning W e illustrate how Goal-Oriented Inuence-Maximizing Data Acquisition (GOIMD A) can be applied to deep active learning under exponential family distributions. W e rst dene a test-centric goal objective function G ( θ ) and then derive a closed-form inuence score for adding a candidate ( x c , y c ) . The resulting acquisition criterion couples the H − 1 θ geometr y with a prediction-bias weighting. 2 For ease of exposition, we consider a single test input x . 16 Formally , consider a classication task where x ∈ R d denotes the input features and y ∈ Z denotes the output label. This setting also captures the motivating biological e xample, wher e x corresponds to experimental stimuli and y to the measured system response, and where conducting experiments to read the system response is costly . At each iteration, a deep neural network M θ with parameters θ := θ ( D ) is trained on the currently lab eled dataset D to model the conditional distribution of the response y given the stimuli x . T est inputs ( x, y ) are drawn from the same unknown data-generating distribution p 0 , with y unobser ved at acquisition time. The objective of active learning is to iteratively select inputs x next for label acquisition such that the model achieves low test loss ℓ ( θ ; ( x, y )) using as few labeled samples as possible. T o optimize the mo del performance on test data ( x, y ) where y is unknown, a natural test-centric goal objective is G ( θ ) := E y ∼ p 0 ( ·| x ) ℓ θ ; ( x, y ) . (38) Using the explicit exponential-family loss in (20), the gradient of G takes the form ∇ θ G ( θ ) = A ′ η θ ( x ) − A ′ η 0 ( x )) ∇ θ η θ ( x ) . (39) Substituting this expression into the inuence function (21) yields the inuence score for a candidate x c : GOI ( x c ) = A ′ η θ ( x ) − A ′ η 0 ( x )) ∇ θ η θ ( x ) ⊤ H − 1 θ ∇ θ η θ ( x c ) A ′ η θ ( x c ) − A ′ η 0 ( x c )) ∝ ∇ θ η θ ( x ) ⊤ H − 1 θ ∇ θ η θ ( x c ) A ′ η θ ( x c ) − A ′ η 0 ( x c )) , (40) where the proportionality follows by discarding terms independent of x c . Consequently , the next point to acquire is x next = arg max x c ∇ θ η θ ( x ) ⊤ H − 1 θ ∇ θ η θ ( x c ) A ′ η θ ( x c ) − A ′ η 0 ( x c )) . (41) Under the canonical-link assumption with T ( y ) = y , this expression simplies to x next = arg max x c x ⊤ H − 1 θ x c x ⊤ c ( θ − θ 0 ) | {z } prediction bias A ′′ η θ ( x c ) , (42) which recovers (28) with the goal objective dened in (38) for the active learning setting. In practice, the prediction-bias term is estimated using a Jackknife resampling strategy via the deep ensemble surrogate ˜ M ϕ , and inverse HVPs are computed stochastically ( see Section 2). 5 Empirical Studies W e empirically evaluate GOIMD A on a diverse set of controlled and realistic learning and opti- mization tasks. 3 W e b egin with a synthetic logistic-regression study designed to isolate the ee ct of the parameter-bias term in the acquisition rule. Next, we evaluate GOIMD A for noisy global op- timization of black-box test functions, benchmarking against standard Gaussian-process Bayesian 3 Code to reproduce our experiments is available at github.com/w eichiyao/GOIMD A . 17 optimization methods with common acquisition functions [ 20 – 24 ]. W e also apply GOIMD A to hyperparameter tuning on CIF AR-10 under distribution shift, where the goal is to sele ct hy- perparameters that improve performance on a target test distribution using labels only from a dierent source distribution. Finally , we study predictive learning on image and text classication benchmarks [ 40 – 42 ], comparing GOIMD A against uncertainty-based active learning baselines such as BALD [ 43 – 45 ]. 5.1 On the importance of the parameter-bias term in (24) The approximation in (24) makes the dependence on the parameter bias θ − θ 0 explicit. This parameter-bias form is useful in tw o ways. Conceptually , it attributes prediction bias to sp ecic pa- rameter directions via ∇ θ η θ ( x ) , which supports diagnostics and motivates targeted regularization. Computationally , it enables a plug-in implementation using Jackknife/Bo otstrap surrogates of θ 0 , requiring a single solve for H − 1 θ ∇ θ G and per-candidate v ector–Jacobian ( or Jacobian–v ector) prod- ucts. Hence, the parameter-bias form is both interpretable and computationally practical. 0 200 400 600 800 1000 Acquisition step 0.70 0.73 0.76 0.79 0.82 0.85 0.88 Accuracy 1100 1150 1200 0.83 0.84 0.85 0.86 T rue Bias Jackknife One Bias Random Figure 2: The parameter-bias term is crucial for eective data acquisition, and a goo d approx- imation signicantly improves the acquisition performance. Using the true bias term ( blue) reaches high accuracy with fewer acquisitions, and a princi- pled approximation (orange) outp erforms ignoring the bias term (dark gray dashed). The inset zoom highlights the persistent gap. Shaded regions indicate variability across runs. T est accuracy is shown versus the number of acquired labels (averaged over 200 rep- etitions). Higher is b etter . In canonical GLMs (Proposition 3), GOIMDA shares the same H − 1 θ leverage structure as predictive-entrop y selection; the key dierence is GOIMD A ’s bias calibration, which re-weights parameter directions by their current bias in- stead of treating them uniformly . In particular , apart from goal alignment, the additional factor is the prediction-bias term x ⊤ c ( θ − θ 0 ) . If θ − θ 0 is replaced by a vector of ones, the inuence objective (28) r educes to the pr edictive-entropy objective (27) up to a scaling constant, recov- ering a bias-agnostic leverage rule . T o quantify the practical importance of θ − θ 0 , we run a controlled simulation that com- pares acquisition variants based on (28). Inputs x ∈ R d are generated from a low-rank latent- variable model z ∈ R l , l < d [ 46 ]: x = W z + ϵ , with z ∼ N (0 , I ) and ϵ ∼ N (0 , σ 2 I ) . W e set d = 20 , l = 3 , and σ = 0 . 1 . Outcomes are binary with p 0 ( y | x ) given by a Bernoulli GLM. For each of 200 repetitions, we generate 50 , 000 training p oints and 5 , 000 test p oints. At each acquisition step, we ret logistic regres- sion on the lab eled set and sele ct the ne xt point by maximizing (28) under dierent treatments of the bias term; random po ol sampling serves as a baseline. All runs start from two labeled points (one per class), and the remaining train- ing points form the candidate po ol. T est accuracy is recorded after each acquisition. 18 Figure 2 compares four acquisition strategies including (i) T rue Bias : inuence maximization using the true bias term θ − θ 0 ; (ii) Jackknife : inuence maximization using a Jackknife estimate of θ − θ 0 ; (iii) One Bias : inuence maximization with θ − θ 0 replaced by a vector of ones; and (iv ) Random : random acquisition from the pool. As expected, True Bias reaches high accuracy with the fewest acquisitions, and Jackknife closely tracks it. One Bias still improves over random sampling but consistently lags b ehind the bias-aware variants. Overall, ignoring the bias term reduces acquisition eciency: the better we approximate θ − θ 0 , the faster accuracy improv es, and the fewer labels are required. 5.2 Noisy black-box function optimization W e b enchmark GOIMD A on noisy Branin, Drop- W ave, and A ckley functions, the black-box test functions from [ 19 ], where each quer y returns y = f ( x ) + ε with ε ∼ N (0 , σ 2 ) . W e consider σ ∈ { 0 . 1 , 0 . 2 } and start each run with 5 initial observations. Se e full details in Appendix B.1. Figure 1 provides a performance comparison on 2D Branin and 5D Ackley functions b etween GOIMD A and ve other commonly used Gaussian Processes (GP)-based Bayesian optimization methods with dierent acquisition functions. In each of these plots, we sho w the immediate regret , which measures the dierence between the outcome of the best possible decision ( min x ∈S f ( x ) for some feasible set S ) and the outcome of the decision made by each activ e optimization method. Given its noisy nature, the regret value may go up in conse cutive acquisition steps, but should, in general, decline if solved by an eective optimization algorithm. Across all thr ee benchmarks, GOIMDA (blue dashed) reduces imme diate regret much faster than the GP baselines, typically reaching the lowest regr et within the rst few dozen acquisitions and then stabilizing. On Branin, GOIMD A quickly drops below the other methods for b oth noise lev els; when noise increases from σ 2 = 0 . 01 to σ 2 = 0 . 04 , the GP baselines plateau at noticeably higher regret while GOIMD A maintains a substantially lower plateau, widening the gap. On Ackle y , the contrast is even sharper: GOIMD A rapidly drives regr et down by or ders of magnitude, wher eas other GP baselines impr ove slo wly and remain far above GOIMD A throughout; this separation persists and eectively b ecomes more pronounced under the higher noise setting. On Dropwave , all methods are more competitive , but GOIMD A still achieves the lowest or near-lo west regr et earlier , and the advantage b ecomes clear er at σ 2 = 0 . 04 , where increased noise slows the baselines more than GOIMD A. O verall, higher noise degrades all methods, but GOIMDA is markedly more noise-robust, retaining rapid early gains and a lo wer nal regr et. 5.3 Hyperparameter tuning under distribution shift W e study hyperparameter optimization when training lab els are available only from a labeled source distribution ( X , Y ) , but performance is evaluated on an unlab eled target distribution under distribution shift ( ˜ X , ˜ Y ) with unknown ˜ Y . The marginals p X and p ˜ X may dier , while the conditional model is assumed to share the same form p 0 := p θ 0 ( Y | X ) for unkno wn θ 0 . Concretely , we instantiate this setting on CIF AR-10 with a Pre- Activation ResNet backbone. W e construct an imbalanced labeled source set and an unlabeled target set drawn from a restricted set of classes. Full details of the dataset construction and splits can be found in Appendix B.2. 19 0 2 4 6 8 10 12 Acquisition step −0.3 −0.2 −0.1 0.0 0.1 0.2 Δ T est Regr et (vs step 0) GOIMDA stays better GOIMDA GP+EI GP+KG GP+MES GP+UCB Figure 3: GOIMDA sele cts the hyperparameters that provide the b est prediction performance on the target test set compared to Bayesian optimiza- tion metho ds . The p erformance is evaluated in terms of the ∆ test regret relative to the initial congura- tion (step 0) across acquisition steps. Solid line shows GOIMD A; dashed lines show Bay esian optimization baselines. Shade d regions indicate 95% bootstrap con- dence intervals of the mean across 3 trials. Negative values correspond to improved target-set p erformance. In this setting, hyperparameter sele ction is driven only by sour ce training/validation per- formance can favor congurations that t the imbalanced source distribution, but transfer poorly to the target distribution. GOIMD A in- stead evaluates hyperparameters by their esti- mated inuence on the expected prediction loss on the target distribution, while still le veraging the labeled source data for training. Figure 3 shows that GOIMD A consistently iden- ties hyperparameter settings that improve tar- get performance under distribution shift more reliably than Bayesian optimization baselines. Measured by the ∆ test regret relative to the ini- tial conguration (step 0), GOIMD A quickly at- tains a stable negative improvement after only a few acquisitions and maintains the best mean regret across subsequent steps. In contrast, the Bayesian optimization baselines exhibit larger variance and less consistent progress, often os- cillating around smaller improv ements and oc- casionally reverting towar d worse target per- formance; this indicates that optimizing based on source-driven signals can select congura- tions that do not transfer well. Overall, the results suggest that explicitly scoring candi- dates by their estimated inuence on target loss makes hyperparameter search more sample-ecient and robust to distribution shift. 5.4 Predictive learning W e evaluate GOIMD A in standard active learning loops: at each iteration, the mo del is trained on the current labele d set and then selects the next point from a po ol S . Across datasets, w e use comparable feedfor ward architectures ( stacked linear-relu layers followed by somax ) for all methods. BALD adds dropout layers and uses MC dropout for approximate inference [ 44 ]. All models are trained with A dam [ 47 ] (learning rate 0 . 001 , β 1 = 0 . 9 , β 2 = 0 . 999 ) on a single GP U. T est accuracy is measured after each acquisition. Results are aggregated over four independent trials; error bars show the mean and the lo wer/upper quartiles. W e consider three b enchmarks spanning image and text classication: MNIST [ 40 ], EMNIST Letters [ 41 ], and binar y sentiment classication derived from the Rotten T omatoes phrase dataset [ 48 ]. For each benchmark, we follow a standard pool-based protocol with a small balanced initialization, a held-out validation set, and the remaining training points as the acquisition pool; see Appendix B.3 for exact split sizes and preprocessing choices. 20 T able 1: GOIMDA requires fewer samples than BALD and random acquisition to achieve high accuracy on MNIST . The table reports 25%-, 50%-, and 75%-percentiles for the number of required data points to reach 80%, 90%, and 95% accuracy on MNIST . Higher is better . Acquisition Methods % Accuracy GOIMD A BALD Random 80% 88 / 108 / 116 104 / 109 / 117 138 / 150 / 173 90% 374 / 422 / 441 432 / 445 / 475 846 / 901 / 977 95% 1060 / 1150 / 1206 1514 / 1589 / 1678 4265 / 4522 / 4731 MNIST W e follow the standard protocol of [ 44 ] with a small balanced initial labele d set and a xed validation hold-out; remaining points form the p ool (see Appendix B.3.1 for more details). GOIMD A and Random acquisitions are assessed with an architecture of three linear-relu layers with hidden widths 392 and 128. BALD uses a similar architecture with tw o linear-dropout-relu layers follow ed by the nal linear-softmax output layer , with the same hidden unit dimensions. W e use 100 MC dropout samples in BALD. The expected loss for the test data p oints and that for candidate data points in GOIMD A are approximated using 10 Jackknife samples. EMNIST Letters W e follow a similar pool/validation setup as in MNIST (see Appendix B.3.2 for more details). Similar to what is used in MNIST , GOIMD A, and Random have three linear-relu layers with hidden unit dimensions 392 and 128 , respectively , and BALD adds two additional dropout layers for inference . In addition, 50 MC dropout samples are used in BALD for acquisition. T o compute the expected loss for the test data points and the expecte d loss for candidate data points, 5 Jackknife samples ar e used to approximate the expected loss in GOIMD A. Movie reviews (Rotten T omatoes) For the Rotten T omatoes dataset, we form a binary task by mapping the original 5-level sentiment labels into { 0 , 1 } after removing neutral phrases, then apply a bag-of-wor ds pr eprocessing pipeline; see full details in Appendix B.3.3. The initial training set contains a balanced dataset of size 20. GOIMD A and Random have three linear-relu layers with hidden unit dimensions 64 and 64 , respectively . BALD again adds tw o additional dropout layers for inference. In addition, 50 MC dropout samples are used in BALD for acquisition. T o compute the expecte d loss for the test data points and the expe cted loss for candidate data points, 10 Jackknife samples are used to approximate the e xpecte d loss in GOIMD A. T able 1 and Figur e 4 show that GOIMDA is consistently more sample-ecient than BALD and random acquisition. On MNIST , GOIMDA reaches high accuracy with much fewer lab eled examples—often requiring only a small fraction of the labeling budget nee ded by random sampling— highlighting the value of targeted acquisition. The learning cur ves in Figure 4 reinforce this trend, with GOIMD A maintaining the highest test accuracy throughout the acquisition process. On EMNIST Letters, GOIMD A again achieves the best performance, delivering a clear accuracy ad- vantage over both BALD and random, while BALD provides only marginal improvement over 21 0 200 400 600 800 1000 A cquir ed dataset size 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 A ccuracy MNIST BALD GOIMD A R andom 0 50 100 150 200 A cquir ed dataset size 0.25 0.30 0.35 0.40 0.45 0.50 0.55 A ccuracy EMNIST BALD GOIMD A R andom 0 500 1000 1500 2000 A cquir ed dataset size 0.50 0.55 0.60 0.65 0.70 0.75 A ccuracy Movie R eviews BALD GOIMD A R andom Figure 4: GOIMD A outperforms both random acquisition and BALD on classication tasks on images of digits from MNIST (Left) and EMNIST (Middle), and the sentiment of movie reviews from the Rotten T omatoes dataset (Right) . The test accuracy is evaluated at each acquisition step. Left: GOIMD A outperforms b oth random acquisition and BALD on MNIST . Middle: GOIMDA outperforms both random acquisition and BALD on EMNIST , whereas BALD only performs slightly b etter than random acquisition. Right: Both GOIMD A and BALD outperform the random sampling in terms of the accuracy rate at a given acquired dataset size. While GOIMDA and BALD have similar performance, GOIMD A gives slightly higher accuracy rates after the total acquisition size reaches 1 , 000 . random acquisition. On Movie Reviews, GOIMDA and BALD b oth outp erform random sampling at essentially every acquisition step , with GOIMD A matching or slightly exceeding BALD; the tighter uncertainty bands for GOIMDA/BALD also suggest mor e stable gains than random selection. 6 Related work This work draws on three themes around iterative data acquisition under expensive evaluation or labeling costs. 6.1 Iterative data acquisition for optimization A standard approach to solving expensive black-b ox optimization problems is iterative data acquisition, in which a surrogate mo del is often t to observed evaluations, and an acquisition function is used to sele ct new inputs [ 49 – 52 ]. The most inuential instantiation of this paradigm is Bayesian optimization (BO) [ 5 , 6 , 53 ], which maintains a probabilistic surrogate M of the unknown objective and sele cts new evaluations by optimizing an acquisition function that balances exploration and exploitation. Classical BO methods typically rely on Gaussian process (GP) surrogates [ 54 ] together with acquisition criteria such as Probability of Impr ovement (PI) [ 20 , 55 ], Expected Improvement (EI) [ 21 , 56 ], Upper Condence Bound (UCB) [ 22 ], Entropy Search (ES) [ 57 , 58 ], Max-value Entrop y Search (MES) [ 23 ], and Knowledge Gradient (K G) [ 4 , 24 – 26 , 59 ]. Despite its empirical success, BO exhibits several practical limitations [ 5 , 6 , 52 , 53 ]. First, GP-based surrogates require forming and factorizing an n × n kernel matrix at each iteration, incurring O ( n 2 ) memory and O ( n 3 ) time complexity [ 52 , 54 ]. This rapidly b ecomes prohibitive as the 22 number of evaluations grows. T o address scalability or high-dimensional settings, prior work has proposed structured or high-dimensional GP variants, low-dimensional emb eddings, and localized trust-region methods such as T uRBO [ 60 – 65 ]. While eective in some regimes, these approaches often impose restrictive modeling assumptions, introduce additional posterior-maintenance over- head, and can b e sensitive to model miscalibration [ 6 , 66 ]. Se cond, replacing GPs with more scalable surrogates—such as tree- or density-based models [ 67 , 68 ] or Bayesian neural networks [ 12 , 69 ]—can alleviate computational costs, but frequently at the expense of uncertainty calibra- tion or robustness [ 11 , 66 ]. Third, many acquisition functions require expectations under the surrogate ’s posterior pr edictive distribution. Fully Bayesian treatments, involving hyperparameter marginalization and exact acquisition computation, are rarely tractable in practice. Consequently , BO typically relies on plug-in hyp erparameter estimates [ 21 , 64 ] or Monte Carlo approxima- tions [ 4 , 12 , 59 , 69 , 70 ], which respectively forgo proper marginalization and introduce additional computational overhead and estimator variance [ 11 , 52 , 53 , 66 , 71 ]. Motivated by these challenges, we pursue an alternativ e that avoids explicit p osterior inference altogether . The propose d GOIMD A algorithm scores candidate p oints by the rst-order eect that upweighting them w ould have on a task-lev el objective. This yields an exploration-aware yet bias-focused improvement strategy . Under exponential-family models, GOIMD A retains the inverse curvature and variance terms that underlie predictive-entropy-based acquisitions, thereby capturing uncertainty while modulating them through goal alignment and predictive bias to emphasize exploitation. As we show in subsequent sections, GOIMD A recovers the exploitation behavior of Bayesian optimization without maintaining a posterior , oering a practical alternative when Bayesian updates are computationally expensive or poorly calibrated [ 6 , 52 , 53 ]. 6.2 Iterative data acquisition for learning A closely related paradigm in super vised learning is active learning (AL), which aims to construct accurate predictive mo dels using as fe w labeled examples as possible [ 7 ]. AL addresses sup ervise d learning settings in which labeled data are e xpensive to obtain and the learner must adaptively decide which inputs to quer y . A canonical example arises in biological stimulus–response studies, where experimental cost limits the number of probes and careful selection of stimuli is crucial for learning accurate predictive models. Here, we focus on AL for deep learning (DL) models, which have achiev ed remarkable success across domains due to their expr essive repr esentations and strong function-appr oximation capa- bilities. Most deep AL metho ds have been developed for classication tasks, particularly in image and text domains [ 8 – 10 ], and are also co vered in broader surveys of activ e learning [ 7 ]. In pool-base d deep AL, an acquisition function assigns a utility score to each unlabele d data point, and the learner queries those with the highest scores at each iteration. Existing acquisition strategies for deep neural networks can b e broadly categorize d into three families [ 9 , 10 ]: (i) uncertainty-based metho ds, which query points about which the model is most uncertain [ 44 , 45 , 72 – 85 ]; (ii) representation-based methods, which sele ct points that are prototypical or diverse in a learned feature space [ 86 – 96 ]; and (iii) hybrid methods, which combine uncertainty with 23 diversity or representativeness in feature or gradient space [ 97 – 108 ]. The latter two categories are particularly common in batch-mode acquisition, where the goal is to select a set of informativ e yet non-redundant points in each AL round. Among these approaches, uncertainty-based criteria remain the most widely use d in both classical and deep active learning [ 7 , 8 ]. These methods are typically instantiate d via condence-, margin-, or entropy-based scores [ 73 – 75 , 109 , 110 ], Bayesian mutual-information objectives such as BALD and its batch extensions [ 44 , 45 , 72 , 84 ], or e xpecte d mo del-change criteria that appro ximate loss reduction [ 31 , 82 , 111 – 113 ]. A recent work proposed to score candidate queries by how much they are expected to reduce predictive uncertainty on target inputs, making the acquisition objective directly aligned with downstream predictive performance [ 114 ]. In deep learning, these strategies commonly rely on appro ximate Bayesian neural networks ( e.g., Monte Carlo dropout) [ 44 , 115 , 116 ] or de ep ensembles [ 79 , 80 ], and have also b een combined with discriminative or energy-based scoring functions [ 80 , 83 , 85 ]. Despite their empirical success, uncertainty-base d deep AL metho ds face fundamental challenges. Predictive probabilities from modern neural networks are often poorly calibrated, with models exhibiting over condence even when incorrect or under distribution shift [ 8 , 117 , 118 ]. Moreover , Bayesian neural networks require approximate inference procedures that are computationally expensive and can b e unreliable in the small-data regimes typical of early AL rounds [ 13 ]. As highlighted in recent surveys, obtaining reliable and well-calibrated uncertainty estimates in deep models remains an op en problem, which directly limits the robustness of uncertainty-driven deep active learning [ 8 – 10 ]. In contrast, GOIMD A avoids explicit posterior inference altogether while remaining uncertainty- aware. W e build on inuence functions as an alternativ e basis for data acquisition. Rather than explicitly modeling predictive uncertainty , inuence-base d methods estimate how upweighting a candidate point would aect the trained model or a downstream evaluation objective, without retraining from scratch [ 29 ]. By using inuence scores for quer y sele ction, GOIMD A av oids reliance on calibrated uncertainty estimates while still implicitly capturing asp ects of uncertainty and prediction bias. As we show in Section 3, under an exponential-family assumption, GOIMDA admits a connection to predictive entrop y minimization: it retains uncertainty-sensitiv e inverse curvature terms while explicitly incorp orating a prediction-bias comp onent, resulting in an exploration-aware y et exploitation-focused acquisition rule. 6.3 Inuence-function-based algorithms Inuence functions (IFs) originate in robust statistics as a principled tool for quantifying the in- nitesimal eect of perturbing a data p oint on an estimator . Seminal work by Cook and colleagues developed a comprehensive diagnostic framew ork for identifying inuential observations and as- sessing local inuence in regression models, encompassing single-point and groupe d perturbations, residual-based diagnostics, and empirical characterizations of inuence [ 119 – 121 ]. These ideas were later revived in the deep-learning literature to analyze complex, nonconvex models. In particular , [ 29 ] demonstrated that rst-order IFs can approximate the eect of up- weighting or remo ving a training example on a model’s predictions, enabling practical tools for debugging, dataset curation, and attributing test errors to individual training points. Subse quent 24 work extended IFs to group-level eects [ 122 ], scalable appro ximations [ 123 ], higher-order and group inuence [ 124 , 125 ], and uncertainty quantication via higher-order IF and jackknife-style estimators [ 17 ]. More broadly , IF-based analyses have been used to uncover spurious data artifacts [ 126 ], characterize memorization and long-tail behavior [ 127 ], and study representational bias in neural networks [ 128 ]. Most existing applications of IFs in deep learning are retrospective: given a xed, labeled training set—and often xe d test points—IFs are used to explain or diagnose existing predictions. In contrast, iterative data acquisition presents a fundamentally dierent setting. At selection time, the lab el of a candidate point is unknown , and acquisition must therefore be based on the expecte d inuence of the candidate under a predictive distribution p 0 ( y | x ) . Prior work that leverages inuence functions for iterative data acquisition has largely focused on active learning. An initial line of w ork proposes selecting data p oints base d on their inuence with respect to predened utility functions [ 31 , 129 , 130 ]. These utility functions encode the learning “goal, ” such as the training loss on an auxiliar y lab eled test set or predictive entropy computed from the current model. When test labels are unavailable, or when the candidate ’s label is unknown, these methods rely on approximations using the current model p θ , in the same spirit as standard uncertainty-based active learning. A related approach [ 32 ] avoids directly evaluating test loss by deriving an upper bound and selecting points based on the gradient norm of the candidate loss. Howe ver , terms involving unknown candidate outputs are again approximated using the current trained model alone. Dierent fr om these works, w e study the inuence of a candidate data point on a goal function that is exibly dene d to cover a broad range of tasks. These include, for example, iterative optimization of black-box functions and label acquisition to improve performance on an unlab eled test set in active learning. Rather than approximating unknown quantities solely through the current trained model, we estimate them using a separate ensemble constructed via resampling techniques such as the jackknife. This decouples acquisition from a single p otentially miscalibrate d predictor and enables inuence-based sele ction that remains eective when posterior uncertainty is expensive or unreliable to estimate . 7 Discussion In this work, w e introduce Goal-Oriented Inuence-Base d Data Acquisition (GOIMD A), a exible iterative data acquisition algorithm that can be adapte d to deep learning models over a wide range of tasks through user-dened, goal-oriented objective functions. By explicitly optimizing down- stream objectives, GOIMD A enables active data acquisition to substantially reduce the numb er of required data points, leading to more ecient and cost-eective learning and optimization. Several directions remain for future work. First, GOIMDA currently follows a fully sequential acquisition strategy , sele cting a single data point at each iteration and updating the mo del imme- diately . While this approach maximizes data eciency , it can increase overall training time. A natural acceleration strategy is to acquir e batches of the top b points with the lowest individual inuence scores. Howe ver , independent selection within a batch can reduce test performance due to redundancy and correlation among the acquired p oints, a limitation also observed in batch active 25 learning [ 44 ]. An imp ortant extension is ther efore to account for interactions among candidate points—such as mutual information—in order to identify maximally inuential acquisition batches while preserving computational eciency . Second, GOIMD A relies on super vised learning models as surrogates, using obser ved data to calibrate the current state of knowledge and to estimate both candidate r esponses and their impact on the target obje ctive. Its eectiveness thus depends on the accuracy of these predictions for unseen data. Given the abundance of unlab eled information typically available in b oth candidate and target sets, integrating semi-sup ervise d learning techniques may b etter capture the underlying structure of the feature space and further improv e predictive performance. W e leave the development of such semi-supervised extensions of GOIMD A to future work. Acknowledgements. This work was supported in part by funding from the Oce of Naval Research under grant N00014-23-1-2590, the National Science Foundation under grant No. 2310831, No. 2428059, No. 2435696, No. 2440954, a Michigan Institute for Data Science Propelling Original Data Science (PODS) grant, LG Management Development Institute AI Research, and T wo Sigma Investments LP . Any opinions, ndings, and conclusions or recommendations e xpressed in this material are those of the authors and do not necessarily reect the views of the sponsors. 26 References [1] T urab Lookman, Prasanna V . Balachandran, Dezhen Xue, and Ruihao Y uan. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. npj Computational Materials , 5(1):1–17, 2019. [2] Ghanshyam Pilania. Machine learning in materials science: From explainable predictions to autonomous design. Computational Materials Science , 193:110360, 2021. [3] Y . Sv erchkov and M. Craven. A review of active learning approaches to e xperimental design for uncovering biological netw orks. PLoS computational biology , 13(6), 2017. [4] Jian W u, Saul T oscano-Palmerin, P . Frazier , and Andrew Gor don Wilson. Practical multi- delity bayesian optimization for hyperparameter tuning. A rXiv , abs/1903.04703, 2019. [5] P . Frazier . A tutorial on bayesian optimization. A rXiv , abs/1807.02811, 2018. [6] Xilu W ang, Y ao chu Jin, Sebastian Schmitt, and Markus Olhofer . Recent advances in bayesian optimization. A CM Comput. Sur v . , 55(13s), 2023. [7] Burr Settles. Active learning literature sur vey . In University of Wisconsin, Madison , 2009. URL https://api.semanticscholar.org/CorpusID:324600 . [8] Christopher Schröder and Andreas Niekler . A sur vey of active learning for text clas- sication using de ep neural networks. A rXiv , abs/2008.07267, 2020. URL https: //api.semanticscholar.org/CorpusID:221139929 . [9] Pengzhen Ren, Y un Xiao, Xiaojun Chang, Po- Y ao Huang, Zhihui Li, Brij B. Gupta, Xiaojiang Chen, and Xin W ang. A sur vey of deep active learning. A CM Comput. Sur v . , 54(9), Octob er 2021. ISSN 0360-0300. doi: 10.1145/3472291. URL https://doi.org/10.1145/ 3472291 . [10] Dongyuan Li, Zhen W ang, Y ankai Chen, Renhe Jiang, W eiping Ding, and Manabu Okumura. A survey on deep active learning: Recent advances and new frontiers. IEEE Transactions on Neural Networks and Learning Systems , 36(4):5879–5899, 2025. doi: 10.1109/TNNLS.2024. 3396463. [11] Y ucen Lily Li, Tim G. J. Rudner , and Andrew Gordon Wilson. A study of bayesian neural network surrogates for bayesian optimization. In The T welfth International Conference on Learning Representations , 2024. [12] Jost T obias Springenb erg, Aaron Klein, Stefan Falkner , and Frank Hutter . Bayesian optimiza- tion with robust bayesian neural netw orks. In D . Lee, M. Sugiyama, U . Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 29. Curran Associates, Inc., 2016. [13] Julyan Arbel, Konstantinos Pitas, Mariia Vladimirova, and Vincent Fortuin. A primer on bayesian neural networks: Review and debates, 2023. [14] Bradley Efron. Frequentist accuracy of bayesian estimates. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 77(3):617–646, 2015. 27 [15] Ryan Giordano, T amara Broderick, and Michael I Jordan. Covariances, robustness, and variational bayes. arXiv preprint , abs/1709.02536, 2017. [16] Sanjib Basu, Sreenivasa Rao Jammalamadaka, and W ei Liu. Lo cal posterior robustness with parametric priors: maximum and average sensitivity . In Maximum Entropy and Bayesian Methods , pages 97–106. Springer , 1996. [17] Ahmed Alaa and Mihaela V an Der Schaar . Discriminative jackknife: Quantifying uncertainty in deep learning via higher-order inuence functions. In International Conference on Machine Learning , pages 165–174. PMLR, 2020. [18] John T ukey . Bias and condence in not quite large samples. A nn. Math. Statist. , 29:614, 1958. [19] Derek Bingham. Optimization test functions. http://www.sfu.ca/~ssurjano/ ackley.html , 2015. [20] A. Törn and A. Zilinskas. Global optimization, 1989. [21] Donald R. Jones, Matthias Schonlau, and William J. W elch. Ecient global optimization of expensive black-box functions. Journal of Global Optimization , 13(4):455–492, 1998. [22] N. Srinivas, A. Krause, S. Kakade, and M. Seeger . Gaussian process optimization in the bandit setting: No regret and experimental design. In Procee dings of the 27th International Conference on International Conference on Machine Learning , pages 1015–1022, 2010. [23] Zi W ang and Stefanie Jegelka. Max-value entrop y sear ch for ecient bayesian optimization. In Proceedings of the 34th International Conference on Machine Learning , volume 70, page 3627–3635. JMLR.org, 2017. [24] W arren Scott, Peter Frazier , and W arren Powell. The correlated knowledge gradient for simulation optimization of continuous parameters using gaussian process regression. SIAM Journal on Optimization , 21(3):996–1026, 2011. [25] Peter I. Frazier , W arren B. Powell, and Savas Dayanik. A knowledge-gradient policy for sequential information collection. SIAM J. Control Optim. , 47(5):2410–2439, 2008. [26] Peter I. Frazier , W arren B. Pow ell, and Savas Dayanik. The knowledge-gradient policy for correlated normal beliefs. INFORMS Journal on Computing , 21(4):599–613, 2009. [27] T sung- Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár . Focal loss for dense object detection. IEEE Transactions on Pattern A nalysis and Machine Intelligence , 42 (2):318–327, 2020. [28] Peter J. Huber . The 1972 wald le cture robust statistics: A revie w . The A nnals of Mathematical Statistics , 43(4):1041–1067, 1972. [29] Pang W ei Koh and Percy Liang. Understanding black-b ox predictions via inuence functions. arXiv preprint , abs/1703.04730, 2017. [30] R. Dennis Cook and Sanford W eisberg. Residuals and inuence in regression . Monographs on statistics and applied probability . Chapman and Hall, New Y ork, 1982. 28 [31] Minjie Xu and Gar y Kazantse v . Understanding goal-oriente d active learning via inuence functions. arXiv , abs/1905.13183, 2019. [32] Tianyang W ang, Xingjian Li, Pengkun Y ang, Guosheng Hu, Xiangrui Zeng, Siyu Huang, Cheng-Zhong Xu, and Min Xu. Boosting active learning via impro ving test performance. arXiv , abs/2112.05683, 2022. [33] T ong Zhang and Frank J. Oles. The value of unlab eled data for classication problems. In International Conference on Machine Learning , volume 20, page 1191–1198, 2000. [34] Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. De ep ensembles: A loss landscape perspe ctive . arXiv , abs/1912.02757, 2020. [35] R.K. Mehra. Computation of the inverse hessian matrix using conjugate gradient methods. Proceedings of the IEEE , 57(2):225–226, 1969. [36] James Martens. Deep learning via hessian-free optimization. In Proceedings of the 27th International Conference on International Conference on Machine Learning , page 735–742, 2010. [37] Naman Agarwal, Brian Bullins, and Elad Hazan. Second-order stochastic optimization for machine learning in linear time. The Journal of Machine Learning Research , 18(1):4148–4187, 2017. [38] Jeremy Lewi, Robert Butera, and Liam Paninski. Ecient active learning with generalized linear models. In A rticial Intelligence and Statistics , pages 267–274, 2007. [39] Liam Paninski. Asymptotic theory of information-theoretic experimental design. Neural Computation , 17(7):1480–1507, 07 2005. [40] Y ann LeCun, Corinna Cortes, and Christopher C. J. Burges. The mnist handwritten digit database. http://yann.lecun.com/exdb/mnist/ , 1998. [41] Gregory Cohen, Sae ed Afshar , Jonathan T apson, and André van Schaik. Emnist: an extension of mnist to handwritten letters. arXiv preprint , 2017. [42] Kaggle . Sentiment analysis on movie reviews: Classify the sentiment of sen- tences from the rotten tomatoes dataset. https://www.kaggle.com/c/ sentiment- analysis- on- movie- reviews/data , 2015. [43] Neil Houlsby , Ferenc Huszár , Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classication and preference learning. A rXiv , abs/1112.5745, 2011. [44] Y arin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In International Conference on Machine Learning , pages 1183–1192. PMLR, 2017. [45] Andreas Kirsch, Joost van Amersfoort, and Y arin Gal. Batchbald: Ecient and diverse batch acquisition for deep bayesian active learning. In H. W allach, H. Larochelle, A. Beygelzimer , F . d ' Alché-Buc, E. Fox, and R. Garnett, e ditors, Advances in Neural Information Processing Systems , volume 32. Curran Associates, Inc., 2019. 29 [46] Michael E. Tipping and Christopher M. Bishop. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 61(3):611–622, 1999. [47] Diederik P Kingma and Jimmy Ba. Adam: A metho d for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014. [48] Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment catego- rization with respect to rating scales. In Proceedings of the 43rd A nnual Meeting of the A CL , page 115–124, 2005. [49] A. J. Bo oker , J. E. Dennis, P. D . Frank, D . B. Serani, V . T orczon, and M. W . T rosset. A rigorous framework for optimization of expensive functions by surr ogates. Structural optimization , 17:1–13, 1999. [50] Rommel G. Regis and Christine A. Shoemaker . Improved strategies for radial basis function methods for global optimization. J. of Global Optimization , 37(1):113–135, Januar y 2007. ISSN 0925-5001. doi: 10.1007/s10898- 006- 9040- 1. URL https://doi.org/10.1007/ s10898- 006- 9040- 1 . [51] Rommel G. Regis and Christine A. Shoemaker . Parallel radial basis function methods for the global optimization of expensive functions. European Journal of Operational Re- search , 182(2):514–535, 2007. ISSN 0377-2217. doi: https://doi.org/10.1016/j.ejor .2006.08. 040. URL https://www.sciencedirect.com/science/article/pii/ S0377221706008800 . [52] Roman Garnett. Bayesian Optimization . Cambridge University Press, 2023. [53] Bobak Shahriari, Kevin Sw ersky , Ziyu W ang, Ryan P. Adams, and Nando de Freitas. T aking the human out of the loop: A review of bayesian optimization. Proce edings of the IEEE , 104 (1):148–175, 2016. [54] Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning . MI T Press, 2006. [55] Harold J. Kushner . A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise. Journal of Basic Engine ering , 86(1):97–106, 1964. [56] Jonas Močkus. On bayesian methods for seeking the extremum and their application. In Optimization T e chniques IFIP T e chnical Conference Novosibirsk , pages 400–404. Springer Berlin Heidelberg, 1975. [57] Philipp Hennig and Christian J. Schuler . Entropy search for information-ecient global optimization. Journal of Machine Learning Research , 13(6):1809–1837, 2012. [58] Lukas P . Fröhlich, Edgar D . Klenske, Julia Vinogradska, Christian Daniel, and Melanie N. Zeilinger . Noisy-input entropy search for ecient robust bayesian optimization. In Pro- ceedings of the 23rd International Conference on A rticial Intelligence and Statistics , volume 108, 2020. 30 [59] Jian W u and Peter I. Frazier . The parallel knowledge gradient method for batch bay esian optimization. In Proceedings of the 30th International Conference on Neural Information Processing Systems , page 3134–3142, Re d Hook, N Y , USA, 2016. [60] Zi W ang, Clement Gehring, Pushme et Kohli, and Stefanie Jegelka. Batched large-scale bayesian optimization in high-dimensional spaces. In Procee dings of the T wenty-First In- ternational Conference on A rticial Intelligence and Statistics , volume 84 of Proceedings of Machine Learning Research , pages 745–754, 2018. [61] ChangY ong Oh, Efstratios Gav ves, and Max W elling. BOCK : Bayesian optimization with cylindrical kernels. In Procee dings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research , pages 3868–3877. PMLR, 2018. [62] Amin Nayebi, Alexander Munteanu, and Matthias Poloczek. A framework for Bayesian optimization in embe dded subspaces. In Proceedings of the 36th International Conference on Machine Learning , volume 97 of Proceedings of Machine Learning Research , pages 4752–4761. PMLR, 2019. [63] Yihang Shen and Carl Kingsford. Computationally ecient high-dimensional bayesian optimization via variable selection. In Proce edings of the Se cond International Conference on A utomate d Machine Learning , volume 224, pages 1–27, 2023. [64] David Eriksson, Michael Pearce, Jacob R. Gardner , Ryan T urner , and Matthias Poloczek. Scalable global optimization via local bayesian optimization. In Proceedings of the 33rd Inter- national Conference on Neural Information Processing Systems , volume 493, page 5496–5507, 2019. [65] David Eriksson and Matthias Poloczek. Scalable constrained bayesian optimization. In Pro- ceedings of the 24th International Conference on A rticial Intelligence and Statistics (AIST A TS) , volume 130. PMLR, 2021. [66] Mickaël Binois and Nathan W yco. A sur vey on high-dimensional gaussian process mod- eling with application to bayesian optimization. A CM Trans. Evol. Learn. Optim. , 2(2), 2022. [67] James Bergstra, Rémi Bardenet, Y oshua Bengio, and Balázs Kégl. Algorithms for hyper- parameter optimization. In Proceedings of the 25th International Conference on Neural Information Processing Systems , NIPS’11, page 2546–2554, Red Hook, N Y , USA, 2011. Curran Associates Inc. ISBN 9781618395993. [68] Frank Hutter , Holger H. Hoos, and Kevin Le yton-Brown. Se quential model-base d optimiza- tion for general algorithm conguration. In Learning and Intelligent Optimization , pages 507–523, 2011. [69] Jasper Snoek, Oren Rippel, K evin Swersky , Ryan Kiros, Nadathur Satish, Narayanan Sun- daram, Md. Mostofa Ali Patwary , Prabhat Prabhat, and Ryan P . Adams. Scalable bayesian optimization using deep neural networks. In Procee dings of the 32nd International Conference on International Conference on Machine Learning , volume 37, page 2171–2180. JMLR.org, 2015. 31 [70] Samuel Kim, Peter Y . Lu, Charlotte Loh, Jamie Smith, Jasper Snoek, and Marin Soljačić’ . De ep learning for bayesian optimization of scientic problems with high-dimensional structure . arXiv , abs/2104.11667, 2022. [71] Eric Brochu, Vlad M. Cora, and Nando de Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv , abs/1012.2599, 2010. [72] Neil Houlsby , Ferenc Huszár , Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classication and preference learning. A rXiv , abs/1112.5745, 2011. URL https: //api.semanticscholar.org/CorpusID:13612582 . [73] D . W ang and Y . Shang. A new active labeling method for deep learning. In Proc. of IJCNN , pages 112–119, 2014. [74] Michael Bloo dgood. Support vector machine active learning algorithms with quer y-by- committee versus closest-to-hyperplane selection. In IEEE International Conference on Semantic Computing , pages 148–155, 2018. [75] W . Li, G. Dasarathy , K. N. Ramamurthy , and V . Berisha. Finding the homology of decision boundaries with activ e learning. In Advances in Neural Information Processing Systems , page 8355–8365, 2020. [76] Keze W ang, Dongyu Zhang, Y a Li, Ruimao Zhang, and Liang Lin. Cost-eective active learning for deep image classication. IEEE Transactions on Circuits and Systems for Video T echnology , 27(12):2591–2600, 2017. doi: 10.1109/TCSV T .2016.2589879. [77] Hiranmayi Ranganathan, Hemanth V enkateswara, Shayok Chakraborty , and Sethuraman Panchanathan. Deep active learning for image classication. In IEEE International Conference on Image Processing , pages 3934–3938, 2017. doi: 10.1109/ICIP.2017.8297020. [78] Lin Y ang, Yizhe Zhang, Jianxu Chen, Siyuan Zhang, and Danny Z Chen. Suggestive annotation: A deep active learning framework for biomedical image segmentation. In International conference on medical image computing and computer-assisted inter vention , pages 399–407. Springer , 2017. [79] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable pre- dictive uncertainty estimation using deep ensembles. In Procee dings of the 31st International Conference on Neural Information Processing Systems , NIPS’17, page 6405–6416, 2017. [80] William H Beluch, Tim Genew ein, Andreas Nürnberger , and Jan M Köhler . The power of ensembles for active learning in image classication. In Procee dings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 9368–9377, 2018. [81] Aditya Siddhant and Zachary C Lipton. De ep bayesian active learning for natural language processing: Results of a large-scale empirical study . arXiv preprint , abs/1808.05697, 2018. [82] T oan Tran, Thanh- T oan Do, Ian D. Reid, and G. Carneiro. Bayesian generative active deep learning. In International Conference on Machine Learning , 2019. URL https: //api.semanticscholar.org/CorpusID:135466220 . 32 [83] Y oon- Y eong Kim, K yungwoo Song, JoonHo Jang, and Il-chul Moon. Lada: Look-ahead data acquisition via augmentation for deep active learning. In M. Ranzato, A. Beygelzimer , Y . Dauphin, P .S. Liang, and J. W ortman V aughan, e ditors, Advances in Neural Information Processing Systems , volume 34, pages 22919–22930. Curran Associates, Inc., 2021. [84] J. Sun, H. Zhai, O . Saisho, and S. T akeuchi. Beam search optimized batch bay esian active learning. In Proceedings of the AAAI Conference on A rticial Intelligence , volume 37, pages 6084–6091, 2023. [85] Binhui Xie, Longhui Yuan, Shuang Li, Chi Harold Liu, Xinjing Cheng, and Guor en W ang. Active learning for domain adaptation: An energy-based approach. In Proc. of AAAI , page 8708–8716, 2022. [86] S. Chakraborty , V . Balasubramanian, Q . Sun, S. Panchanathan, and J. Y e. Activ e batch selection via convex relaxations with guaranteed solution bounds. IEEE Trans. Pattern A nal. Mach. Intell. , 37:1945–1958, 2015. [87] Ozan Sener and Silvio Savarese . Activ e learning for convolutional neural networks: A core-set approach. In International Confer ence on Learning Representations , 2018. URL https://openreview.net/forum?id=H1aIuk- RW . [88] Y . Zhao, Z. Shi, J. Zhang, D. Chen, and L. Gu. A nov el active learning framework for classication: Using weighted rank aggregation to achieve multiple query criteria. Pattern Recognition , 93:581–602, 2019. [89] C. Li, H. Ma, Z. Kang, Y . Y uan, X.- Y . Zhang, , and G. W ang. On deep unsupervised active learning. In Proc. 29th Int. Joint Conf. A rtif. Intell. , page 2626–2632, 2020. [90] M. Hasan, S. Paul, A. I. Mourikis, and A. K. Roy-Chowdhury . Context-aware query selection for active learning in event r ecognition. IEEE Trans. Pattern A nal. Mach. Intell. , 42:554–567, 2020. [91] Cody Coleman, Edward Chou, Julian Katz-Samuels, Sean Culatana, Peter Bailis, Alexander C. Berg, Robert Nowak, and I. Zeki Y alniz Roshan Sumbaly , Matei Zaharia. Similarity search for ecient active learning and search of rare concepts. In Procee dings of the AAAI Conference on A rticial Intelligence , page 804–812, 2022. [92] D . Gudovskiy , A. Hodgkinson, T . Y amaguchi, and S. T sukizawa. Deep active learning for biased datasets via sher kernel self-sup ervision. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR) , pages 9038–9046, 2020. [93] Y . Kim and B. Shin. In defense of core-set: A density-aware coreset selection for active learning. In Proc. 28th A CM SIGKDD Conf. Knowl. Discovery Data Mining , page 804–812, 2022. [94] Q . Jin, M. Y uan, Q . Qiao, and Z. Song. One-shot active learning for image segmentation via contrastive learning and diversity-based sampling. Knowl.-Based Syst. , 241, 2022. [95] S. Li, J. M. Phillips, X. Y u, R. M. Kirby , and S. Zhe. Batch multidelity active learning with budget constraints. In Procee dings of Advances in Neural Information Processing Systems , page 995–1007, 2022. 33 [96] A. Parvaneh, E. Abbasnejad, D. T eney , R. Haari, A. V an Den Hengel, and J. Q . Shi. Activ e learning by feature mixing. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Re cognit. (CVPR) , page 12227–12236, 2022. [97] P . Donmez, J. Carb onell, and P. N. Bennett. Dual strategy active learning. In Proceedings of European Conference on Machine Learning , page 116–127, 2007. [98] Changchang Yin, Buyue Qian, Shilei Cao, Xiaoyu Li, Jishang W ei, Qinghua Zheng, and Ian Davidson. Deep similarity-based batch mode active learning with exploration-exploitation. In Vijay Raghavan, Srinivas Aluru, Ge orge Karypis, Lucio Miele, and Xindong Wu, editors, 2017 IEEE International Conference on Data Mining , pages 575–584, 2017. [99] Fedor Zhdanov . Diverse mini-batch active learning. arXiv preprint , 2019. [100] Samarth Sinha, Sayna Ebrahimi, and Tre vor Darrell. V ariational adversarial active learning. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , pages 5971–5980, 2019. URL https://api.semanticscholar.org/CorpusID:90258881 . [101] Jordan T . Ash, Chicheng Zhang, Akshay Krishnamurthy , John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lo wer bounds. In International Conference on Learning Representations , 2020. [102] Changjian Shui, Fan Zhou, Christian Gagné, and Boyu W ang. Deep active learning: Unied and principled method for quer y and training. In Silvia Chiappa and Rob erto Calandra, editors, The 23rd International Conference on A rticial Intelligence and Statistics , volume 108 of Proceedings of Machine Learning Research , pages 1308–1318, 2020. [103] Gui Citovsky , Giulia DeSalvo, Claudio Gentile, Lazaros K ar ydas, Anand Rajagopalan, Afshin Rostamizadeh, and Sanjiv Kumar . Batch active learning at scale. In Procee dings of Advances in Neural Information Processing Systems , page 11933–11944, 2021. [104] B. Gu, Z. Zhai, C. Deng, and H. Huang. Ecient active learning by querying discriminative and repr esentative samples and fully exploiting unlabele d data. IEEE Trans. Neural Netw . Learn. Syst. , 32:4111–4122, 2021. [105] S. Huang, T . W ang, H. Xiong, J. Huan, and D . Dou. Semi-super vised active learning with temporal output discrepancy . In Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV) , pages 3447–3456, 2021. [106] Y . Geifman and R. El- Y aniv . Deep active learning with a neural architecture search. In Proceedings of Advances in Neural Information Processing Systems , page 5974–5984, 2019. [107] Jordan Ash, Surbhi Goel, Akshay Krishnamurthy , and Sham Kakade. Gone shing: Neural active learning with sher emb eddings. In Advances in neural information processing systems , volume 34, 2021. [108] Akanksha Saran, Safoora Y ouse, Akshay Krishnamurthy , John Langford, and Jordan T . Ash. Streaming active learning with deep neural networks. arXiv , abs/2303.02535, 2023. 34 [109] Greg Schohn and David Cohn. Less is more: Active learning with support vector machines. In Proceedings of the Seventeenth International Conference on Machine Learning , pages 839– 846, 2000. [110] D . Roth and K. Small. Margin-based active learning for structured output spaces. In Proc. Eur . Conf. Mach. Learn. , page 413–424, 2006. [111] Burr Settles, Mark Craven, and Soumya Ray . Multiple-instance active learning. In John C. Platt, Daphne Koller , Y oram Singer , and Sam T . Roweis, editors, A dvances in Neural Infor- mation Processing Systems 20 , pages 1289–1296, 2007. [112] Nicholas Roy and Andre w McCallum. T oward optimal active learning through monte carlo estimation of error reduction. In International Conference on Machine Learning , page 441–448, 2001. [113] Alexander Freytag, Erik Rodner , and Joachim Denzler . Selecting inuential examples: Active learning with expected model output changes. In Computer Vision - ECCV , volume 8692, pages 562–577, 2014. [114] Freddie Bickford Smith, Andreas Kirsch, Sebastian Farquhar , Y arin Gal, Adam Foster , and T om Rainforth. Prediction-oriente d bayesian active learning. In International Conference on A rticial Intelligence and Statistics (AIST A TS) , 2023. [115] Nitish Srivastava, Georey Hinton, Alex Krizhevsky , Ilya Sutskever , and Ruslan Salakhutdi- nov . Dropout: A simple way to prevent neural networks from overtting. Journal of Machine Learning Research , 15(56):1929–1958, 2014. URL http://jmlr.org/papers/v15/ srivastava14a.html . [116] Y arin Gal and Zoubin Ghahramani. Dropout as a bayesian appro ximation: Representing model uncertainty in deep learning. In Maria Florina Balcan and Kilian Q. W einb erger , editors, Proceedings of The 33rd International Conference on Machine Learning , volume 48 of Proceedings of Machine Learning Research , pages 1050–1059, New Y ork, New Y ork, USA, 20–22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48/gal16. html . [117] Chuan Guo, Geo Pleiss, Y u Sun, and Kilian Q. W einb erger . On calibration of modern neural networks. In Proce edings of the 34th International Conference on Machine Learning - V olume 70 , ICML’17, page 1321–1330. JMLR.org, 2017. [118] Moloud Abdar , Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U Rajendra Achar ya, et al. A revie w of uncertainty quantication in deep learning: T e chniques, applications and challenges. Information Fusion , 2021. [119] R Dennis Cook. Detection of inuential observation in linear regression. T echnometrics , 19 (1):15–18, 1977. [120] R Dennis Cook and Sanford W eisb erg. Characterizations of an empirical inuence function for detecting inuential cases in regression. T echnometrics , 22(4):495–508, 1980. 35 [121] R Dennis Cook. Assessment of local inuence. Journal of the Royal Statistical Society: Series B (Methodological) , 48(2):133–155, 1986. [122] Pang W ei Koh, Kai-Siang Ang, Hubert HK T eo, and Percy Liang. On the accuracy of inuence functions for measuring group eects. arXiv preprint , abs:1905.13289, 2019. [123] Han Guo, Nazneen Fatema Rajani, Peter Hase , Mohit Bansal, and Caiming Xiong. Fastif: Scalable inuence functions for ecient mo del interpretation and debugging. arXiv preprint , abs/2012.15781, 2020. [124] Samyadeep Basu, Philip Pope, and Soheil Feizi. Inuence functions in deep learning are fragile. arXiv , abs/2006.14651, 2020. [125] Samyadeep Basu, Xuchen Y ou, and Soheil Feizi. On second-order group inuence functions for black-box predictions. In International Conference on Machine Learning , pages 715–724. PMLR, 2020. [126] Xiaochuang Han, Byron C W allace, and Y ulia T svetkov . Explaining black box predictions and unveiling data artifacts through inuence functions. arXiv preprint , abs/2005.06676, 2020. [127] Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via inuence estimation. arXiv preprint , abs/2008.03703, 2020. [128] Marc-Etienne Brunet, Colleen Alkalay-Houlihan, Ashton Anderson, and Richard Zemel. Understanding the origins of bias in wor d embeddings. In International Conference on Machine Learning , pages 803–811. PMLR, 2019. [129] Zhuoming Liu, Hao Ding, Huaping Zhong, W eijia Li, Jifeng Dai, and Conghui He. Inuence selection for active learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2021. [130] Meng Xia and Ricardo Henao. Reliable active learning via inuence functions. Transactions on Machine Learning Research , 2023. [131] Victor Picheny , T obias W agner , and David Ginsb ourger . A b enchmark of kriging-based inll criteria for noisy optimization. Structural and Multidisciplinary Optimization , 48, 2013. [132] Alex Krizhevsky . Learning multiple layers of features fr om tiny images, 2009. [133] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European Conference on Computer Vision , 2016. 36 Supplementar y Material A Deriving the Jacobian of minimizer w .r .t. parameters By denition of ˆ x ∗ θ =: ˆ x min ( θ ) , the rst-order condition is 0 = ∇ x E y ∼ p θ ( ·| x ) [ y | x ] x = ˆ x min ( θ ) = ∇ x A ′ η θ ( x ) x = ˆ x min ( θ ) . (43) Dene g ( θ , x ) := ∇ x A ′ η θ ( x ) ∈ R d x . Then g ( θ , ˆ x min ( θ )) = 0 . Fix ˆ θ t and perturb θ = ˆ θ t + δ with ∆ x := ˆ x min ( ˆ θ t + δ ) − ˆ x min ( ˆ θ t ) . A rst-order T aylor expansion gives 0 = g ( ˆ θ t + δ, ˆ x min ( ˆ θ t + δ )) ≈ g ( ˆ θ t , ˆ x min ( ˆ θ t )) + h ∂ ∂ θ g ( θ , x ) i θ = ˆ θ t , x = ˆ x min ( ˆ θ t ) δ + h ∂ ∂ x g ( θ , x ) i θ = ˆ θ t , x = ˆ x min ( ˆ θ t ) ∆ x. Since g ( ˆ θ t , ˆ x min ( ˆ θ t )) = 0 , we obtain h ∂ ∂ x g ( θ , x ) i ∆ x = − h ∂ ∂ θ g ( θ , x ) i δ, hence ∆ x = − h ∂ ∂ x g ( θ , x ) i − 1 h ∂ ∂ θ g ( θ , x ) i δ θ = ˆ θ t , x = ˆ x min ( ˆ θ t ) . Noting that ∂ ∂ x g ( θ , x ) = ∇ 2 x A ′ ( η θ ( x )) , this becomes ˆ x min ( ˆ θ t + δ ) − ˆ x min ( ˆ θ t ) = − h ∇ 2 x A ′ η θ ( x ) i − 1 h ∂ ∂ θ ∇ x A ′ η θ ( x ) i δ θ = ˆ θ t , x = ˆ x min ( ˆ θ t ) . Sending δ → 0 yields the Jacobian (total derivative) ∂ ˆ x min ( θ ) ∂ θ = − h ∇ 2 x A ′ η θ ( x ) i − 1 h ∂ ∂ θ ∇ x A ′ η θ ( x ) i x = ˆ x min ( θ ) . B Experiment datasets B.1 Noisy black-box function 2D Branin. The rst function is the Branin function f ( x ) = a ( x 2 − bx 2 1 + cx 1 − r ) 2 + s (1 − t ) cos( x 1 ) − q where a = 1 / 51 . 95 , b = 5 . 1 / (4 π ) 2 , c = 5 /π , r = 6 , s = 10 , t = 1 / (8 π ) and q = 44 . 81 , a rescaled form by [ 131 ]. The function is evaluated on the square x 1 ∈ [0 ., 1 . ] , x 2 ∈ [0 ., 1 . ] . It has three global minima f ( x ∗ ) = − 1 . 0474 . 37 2D Dr op- W ave function. This two-dimensional, radially symmetric test function is highly multimodal due to its oscillator y cosine term. For x = ( x 1 , x 2 ) it is dened as f ( x ) = − 1 + cos 12 p x 2 1 + x 2 2 0 . 5 ( x 2 1 + x 2 2 ) + 2 , and is typically evaluated on x i ∈ [ − 5 . 12 , 5 . 12] . It attains the global minimum f ( x ∗ ) = − 1 at x ∗ = (0 , 0) . 5D Ackley function. The Ackley function is generally e xpressed in the form f ( x ) = − a exp − b q 1 d P i x 2 i − exp 1 d P i cos( cx i ) + a + exp(1) , wher e a = 20 , b = 0 . 2 , c = 2 π and σ = 0 . 5 . For the dimension d = 2 , the function leads some optimization algorithms, particularly hill-climbing algorithms, to b e trapp ed in one of its many local minima. The function is evaluated on the hypercube x i ∈ [ − 5 , 5] , for i = 1 , . . . , d . W e set the dimension d = 5 for higher dimensional analysis. The Global minimum f ( x ∗ ) = 0 is achiev ed at x ∗ = (0 , . . . , 0) . B.2 Hyperparameter tuning under distribution shift W e use CIF AR-10 [ 132 ], which contains 50 , 000 training images and 10,000 test images across 10 classes. The predictive model is a Pre- Activation Residual Network [ 133 ]. W e construct a target (unlab eled) evaluation set by selecting 3 , 000 CIF AR-10 test images whose (unknown-to-the- learner) lab els belong to a r estricted class set C := { C 1 , C 2 , C 3 } ( 1 , 000 images per class). W e also construct a labeled source dataset ( X , Y ) that is deliberately imbalanced: it contains 500 labeled instances from each class in C , and 5 , 000 labeled images from each of the remaining classes in Y \ C . Hyperparameter acquisition methods are evaluated by their impact on performance on the target subset, while training leverages the labeled source data. B.3 Predictive learning B.3.1 MNIST active learning b enchmark MNIST [ 40 ] contains 60 , 000 training images and 10 , 000 test images over 10 digit classes. Fol- lowing [ 44 ], we initialize the active learning loop with a random but class-balance d labeled set of 20 p oints (two p er class). W e hold out 1 , 024 training p oints as a validation set; the remaining training points form the acquisition pool. T est accuracy is reported on the standard MNIST test set after each acquisition step. B.3.2 EMNIST Letters active learning EMNIST Letters [ 41 ] is a balanced 26-class character recognition task with 124 , 800 training images and 20 , 800 test images. W e set aside the last portion of the training set—equal in size to the test set—as a validation set, and use the remaining training points as the acquisition pool. W e follow the same p ool-based acquisition lo op as in MNIST , starting from a small randomly initialized labele d set. 38 B.3.3 Rotten T omato es movie-review phrases W e evaluate binar y sentiment classication using the Rotten T omato es phrase dataset originally collected by Pang and Lee [ 48 ]. The original labels are ordinal with ve lev els (“negative ” , “some- what negative ” , “neutral” , “somewhat positive” , “positive”). T o construct a binar y task, we remove neutral phrases, map {“negative” , “somewhat negative ”} to 0 and {“somewhat positive ” , “positive”} to 1 , and then randomly split the resulting dataset into 59 , 070 training phrases, 1 , 024 validation phrases, and 16 , 384 test phrases. For text preprocessing, we use a bag-of-w ords repr esentation; we discard wor ds with total occurrence less than 10 , reducing the feature dimension from 15 , 186 to 7 , 004 . 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment