자연스러운 억양 변환을 위한 지속시간 제어형 CosyAccent 모델
본 논문은 실제 L2 발음 데이터를 전혀 사용하지 않고, 고품질 L1 음성을 기반으로 합성된 L2 소스를 이용해 학습 데이터를 구성하는 “source‑synthesis” 방식을 제안한다. 이를 바탕으로 비자율(non‑autoregressive) 모델인 CosyAccent를 설계하여 리듬을 암묵적으로 학습하면서도 전체 출력 길이를 명시적으로 제어할 수 있게 하였다. 실험 결과, 실제 L2 데이터를 사용해 학습한 기존 강력한 베이스라인 대비 내용 …
저자: Qibing Bai, Shuhao Shi, Shuai Wang
본 논문은 억양 정규화(Accent Normalization, AN) 시스템이 직면한 두 가지 주요 문제—비자연적인 출력과 내용 왜곡—를 해결하기 위해 새로운 데이터 생성 전략과 모델 구조를 제안한다.
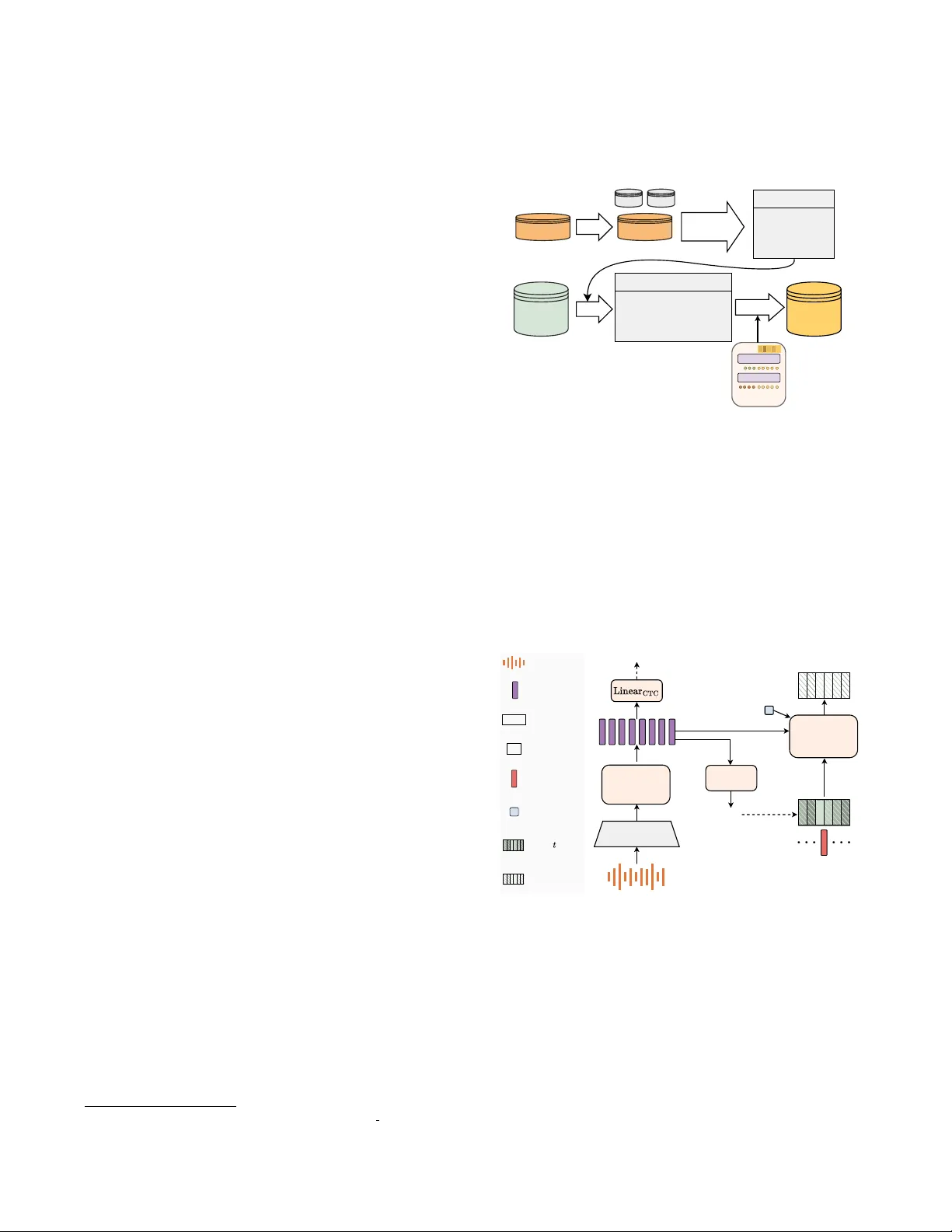
첫 번째 기여는 “source‑synthesis” 방식이다. 기존 AN 연구는 L1 목표 음성을 TTS로 합성하거나, L1·L2 모두를 합성하는 방법에 의존했으며, 이 경우 합성된 목표 음성에 내재된 인공적인 프로소디와 음질 결함이 AN 모델에 그대로 전이돼 성능 상한을 형성했다. 저자들은 고품질 L1 코퍼스인 LibriTTS‑R을 그대로 사용하고, 최신 프롬프트 기반 TTS인 CosyVoice2를 활용해 L2 억양을 부여한 소스를 합성한다. 구체적으로 L2‑ARCTIC 데이터베이스에서 추출한 억양 프롬프트와 L1 원본 텍스트를 동시에 입력해, 화자의 음색은 L1을 그대로 유지하면서 억양만 L2 스타일로 변환한다. 이렇게 생성된 데이터 쌍은 “진짜 L1 목표 / 인공 L2 소스” 형태가 되며, 목표 음성은 전혀 인공적인 왜곡이 없고, 소스는 다양한 억양 특성을 갖는다. 또한 실제 L2 데이터가 전혀 필요 없으므로 데이터 수집 비용을 크게 절감할 수 있다.
두 번째 기여는 비자율(non‑autoregressive) 모델 CosyAccent의 설계이다. 기존 프레임‑투‑프레임 모델은 소스 타이밍을 그대로 복제해 지속시간 제어는 가능하지만 프로소디 유연성이 떨어진다. 반면 시퀀스‑투‑시퀀스(seq2seq) 모델은 리듬을 자유롭게 생성하지만 전체 길이를 명시적으로 조절하기 어렵다. CosyAccent는 Whisper‑medium을 frozen encoder로 사용해 언어적 콘텐츠를 추출하고, CTC 손실을 추가해 텍스트 정렬을 강화한다. 디코더는 DiT 기반의 흐름 모델이며, RoPE와 “position scaling” 기법을 통해 소스 콘텐츠의 위치 인덱스를 목표 길이에 맞게 정규화한다. 이는 전체 길이가 달라져도 시작·중간·끝이 일관되게 매핑되도록 하여, 사용자가 원하는 총 지속시간을 정확히 지정하거나, 별도의 총 지속시간 예측기(스케일링 비율)로 자동 결정하게 만든다. 또한 화자 임베딩을 별도 스피커 인코더(Resemblyzer)로 추출해 디코더에 조건으로 제공함으로써 화자 고유성 보존을 강화한다. 추론 시 두 단계의 Classifier‑Free Guidance(w₁, w₂)를 적용해 무조건적 출력과 콘텐츠 조건을 적절히 조합, 자연스러우면서도 내용 왜곡을 최소화한다.
실험에서는 7개 언어 억양을 포함한 L2‑ARCTIC 테스트 셋을 사용해, 기존 FrameAN(프레임‑레벨 흐름 모델)과 TokAN(SSL 토큰 기반 모델)과 비교하였다. CosyAccent‑2(소스 길이 그대로 유지)와 CosyAccent‑1(예측된 스케일링 비율 사용) 모두 자연스러움(NAT), 화자 유사도(SIM), 내용 보존(WER) 등에서 프레임‑레벨 베이스라인을 크게 앞섰으며, 특히 TokAN‑2와 비교했을 때 WER이 12.96%에서 16.21%로 현저히 낮아 내용 왜곡이 적었다. 또한 UTMOS와 SECS 같은 객관적 지표에서도 우수성을 확인했다. 이러한 결과는 “source‑synthesis” 데이터가 목표 음성의 품질을 보장하고, CosyAccent의 총 지속시간 제어 메커니즘이 실제 응용(예: 더빙)에서 요구되는 시간 일관성을 제공함을 입증한다.
결론적으로, 본 논문은 (1) 실제 L2 데이터 없이도 고품질 병렬 학습 데이터를 자동 생성하는 방법을 제시하고, (2) 리듬의 자유로움과 전체 지속시간 제어를 동시에 만족하는 비자율 AN 모델을 설계함으로써, 기존 방법들의 한계를 뛰어넘는 성능을 달성하였다. 이는 억양 정규화뿐 아니라, 다양한 음성 변환·합성 작업에서 데이터 효율성과 제어 가능성을 크게 향상시킬 수 있는 중요한 진전으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기