CosyAccent: Duration-Controllable Accent Normalization Using Source-Synthesis Training Data
Accent normalization (AN) systems often struggle with unnatural outputs and undesired content distortion, stemming from both suboptimal training data and rigid duration modeling. In this paper, we propose a "source-synthesis" methodology for training…
Authors: Qibing Bai, Shuhao Shi, Shuai Wang
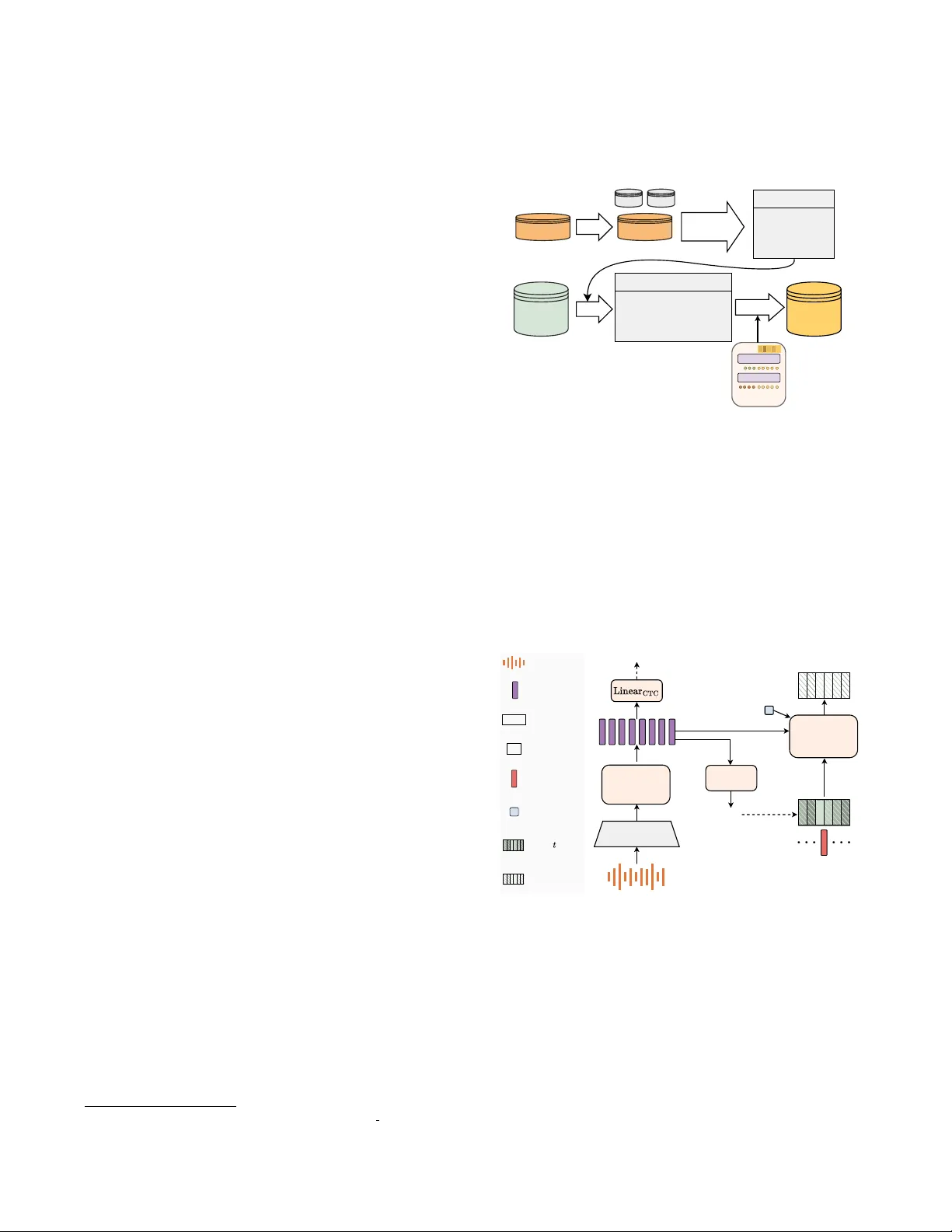
COSY A CCENT : DURA TION-CONTROLLABLE A CCENT NORMALIZA TION USING SOURCE-SYNTHESIS TRAINING DA T A Qibing Bai 1 , 2 , 5 , Shuhao Shi 1 , Shuai W ang 4 , 6 † , Y ukai J u 5 , Y annan W ang 5 , Haizhou Li 1 , 2 , 3 , 6 1 SDS, 2 SRIBD, and 3 SAI, The Chinese Uni versity of Hong K ong, Shenzhen, China 4 School of Intelligence Science and T echnology , Nanjing Univ ersity , Suzhou, China 5 T encent Ethereal Audio Lab, T encent, Shenzhen, China 6 Shenzhen Loop Area Institute, Shenzhen, China ABSTRA CT Accent normalization (AN) systems often struggle with unnatu- ral outputs and undesired content distortion, stemming from both suboptimal training data and rigid duration modeling. In this pa- per , we propose a “source-synthesis” methodology for training data construction. By generating source L2 speech and using authentic nativ e speech as the training tar get, our approach av oids learning from TTS artifacts and, crucially , requires no real L2 data in train- ing. Alongside this data strategy , we introduce CosyAccent, a non- autoregressi ve model that resolv es the trade-of f between prosodic naturalness and duration control. CosyAccent implicitly models rhythm for flexibility yet offers explicit control over total output duration. Experiments sho w that, despite being trained without an y real L2 speech, CosyAccent achiev es significantly improv ed content preservation and superior naturalness compared to strong baselines trained on real-world data. 1 Index T erms — Accent con version, speech synthesis, voice con- version, duration control 1. INTR ODUCTION Accent normalization (AN) 2 seeks to remo ve the accent from a non- nativ e (L2) speech to obtain a native sounding (L1) speech while pre- serving the speaker’ s unique vocal identity and the original linguis- tic content. The practical applications of this technology are wide- ranging, from impro ving pronunciation for language learners [1] to enhancing the authenticity of dubbed media [2] and enabling per- sonalized text-to-speech (TTS) systems [3]. A primary challenge in accent normalization is the scarcity of large-scale, parallel L1-L2 corpora where the same speaker utters the same content in two dif- ferent accents. This data bottleneck has forced the field to evolv e, moving from early methods that required reference speech during inference [4–7] or were trained on limited content-paired data [8, 9]. T o o vercome these constraints, the dominant paradigm has shifted tow ards the use of synthetic data to construct training pairs. Current synthetic data strategies predominantly focus on tar get synthesis , which generates L1 speech using TTS models and trains a con version model on these synthetic pairs [10–13]. Another strategy in volv es synthesizing both the source and target speech using multi- accent TTS models, often le veraging discrete representations to mit- igate error accumulation [14]. Other methods have used voice con- † : Corresponding author 1 Samples: https://p1ping.github.io/CosyAccent- Demo . Code & data: https://github.com/P1ping/CosyAccent . 2 Also referred to as Foreign Accent Con version (F AC). version to e xpand small L2 corpora [15, 16] or transliteration to cre- ate pairs [17], though these often face limitations in scale. Howe ver , these methods share a vulnerability: the model’ s quality is capped by the authenticity of the synthesized L1 target. Artifacts or unnatural prosody from the TTS system are inherited by the AN model, creat- ing a performance ceiling that persists e ven when using intermediate SSL token representations [14, 18]. In this paper , we propose to synthesize the speech in a different way by synthesizing the source L2 speech from a large-scale, high- quality native L1 corpus. This “source-synthesis” approach ensures that our model is trained on genuine, high-quality native speech as its target, with natural prosody and voice quality , and without artifacts that come with target-synthesis methods. Furthermore, in contrast to dual-synthesis methods that require fine-tuning a TTS model on limited L2 data [14], our method le verages a powerful, prompt-based TTS [19]. This makes our data generation process highly scalable and much less dependent on real L2 data collection. T ogether with the new data strategy , we also propose a novel model, CosyAccent . It is a non-autoregressiv e (N AR) system de- signed to resolve the common trade-off between prosodic flexibility and duration control. Unlike frame-to-frame methods [11–13, 20] that rigidly copy source timing or sequence-to-sequence models that lack control, CosyAccent implicitly models rhythm for naturalness while of fering explicit control o ver the total output duration, making it adept for tasks like dubbing where the duration of output speech needs to be preserved. Our contributions are three-fold: • W e introduce a novel data generation strategy that synthesizes L2 source speech from high-quality L1 corpora, eliminating the dependency on real accent data while ensuring training on authentic, artifact-free nati ve tar gets. • W e propose CosyAccent, a N AR accent normalization model capable of generating high-quality speech with a specified to- tal duration, resolving the trade-off between prosodic flexibil- ity and duration control for applications like dubbing. • W e empirically sho w that, by training e xclusiv ely on our source-synthesized data, our model achie ves superior content preservation and naturalness, matching or exceeding strong baselines that were trained on real-world accented data. 2. RELA TED-WORK 2.1. Synthetic Data for Accent Con version The scarcity of parallel L1-L2 data has driven the field towards synthetic data generation. The dominant strategy is tar get-synthesis , where a TTS model generates the L1 target speech [11–13, 18]. Howe ver , this approach is limited, as any TTS artif acts are inherited by the AN model. T o mitigate this, some methods synthesize both source and target speech [14], often using discrete tokens to reduce error accumulation [14, 18]. Other approaches, such as using voice con version [16] or transliteration [17], often struggle to scale. In contrast, our source-synthesis approach in verts this paradigm. W e use a powerful prompt-based TTS, CosyV oice2 [19], to generate the L2 source, ensuring the model trains on authentic, artifact-free L1 targets. This strate gy is highly scalable and a v oids the perfor - mance ceiling of target-synthesis methods. 2.2. Duration Modeling in Speech Con version Duration modeling in speech conv ersion presents a trade-off be- tween the rigid timing of frame-to-frame models [11, 12] and the flexibility of sequence-to-sequence (seq2seq) models, which lack explicit duration control [21]. T o bridge this gap, recent non-autoregressi ve methods have introduced explicit, phoneme- or token-le vel duration predictors [22–24]. This is crucial for AN, as mismatched temporal patterns are a key component of an accent. While some AN models maintain the source’ s total duration [18], our work takes a different approach. CosyAccent implicitly models rhythm for naturalness—akin to seq2seq—while still allowing explicit control over the total output duration, offering a no vel solution to this trade-of f. 3. METHOD 3.1. Construction of T raining data W e construct our paired dataset by synthesizing L2 source audio for the nativ e LibriTTS-R corpus [25]. Our source-synthesis approach method lev erages CosyV oice2 [19], a dual-prompt TTS model that empirically allows separate control over speaking style and timbre. W e synthesize each L2 source sample by providing two prompts: an L2 utterance from L2-ARCTIC [26] to set the accent, and the original L1 target utterance to preserv e the speaker’ s timbre. This process yields a synthetic L2 source that is perfectly aligned with its authentic L1 target in both content and speaker identity . The data pipeline is illustrated in Figure 1. It consists of four steps below . Subset split. W e first partition the L2-ARCTIC dataset into training, validation, and testing subsets. Since L2-ARCTIC uses the same prompt sentences across speakers, we construct the split: 50 sen- tences for validation and 80 for testing. So the testing sentences are not indirectly seen during training, guaranteeing a fair e valuation. Accentedness scoring . T o ensure high-quality L2 characteristics, we filter the L2-ARCTIC samples. W e use a pre-trained accent clas- sifier 3 to score each sample’ s non-nativ e accent strength. W e retain all samples with a score abov e 0.5. W e select at least the top 200 utterances per speaker to ensure speaker di versity . Pairing L1 and L2 Data. Each native utterance in LibriTTS-R is randomly assigned an L2 prompt from the filtered set. The assign- ment process is balanced to ensure that all L2 speakers are used a similar number of times. Synthesis. In the final step, we generate the synthetic L2 speech. For each L1 utterance from LibriTTS-R, we use its text as input to CosyV oice2. The paired L2 sample serves as the LM prompt to impart the non-native accent, while the original L1 utterance itself serves as the Flo w prompt to preserve the speak er’ s timbre. 3 https://huggingface.co/Jzuluaga/accent-id-commonaccent xlsr-en-english The result of this process is a parallel L2-accented corpus aligned with the original LibriTTS-R data in content and speaker identity , ready for training our model. Due to accentedness, the total duration is approximately 1 . 3 × that of the nativ e counterparts. LibriTTS-R L2ARCTIC split accentedness scoring train valid test non-native scores ABA_arctic_a0001 7.5% SVBI_arctic_a0145 100% TL V_arctoc_b0535 95.23% ... paring sort & filter target & content prompt 730_358_000016_000004 ABA_arctic_a0236 6123_59186_000015_000000 LXC_arctic_a0365 4572_64670_000001_000001 HKK_arctic_b0152 ... synthesize L2-accented LibriTTS-R LM Flow CosyV oice2 Fig. 1 : Construction pipeline of the paired training data. 3.2. Model Architectur e The architecture of CosyAccent is illustrated in Figure 2. It is a N AR system composed of four main modules: a speech encoder , a CTC projection head, a duration predictor , and a speech decoder . Speech encoder and content repr esentations. The con version pro- cess be gins with the L2 source audio, which is first processed by a frozen Whisper medium [27] encoder frontend. The output is then passed to the Transformer speech encoder to extract high-level fea- tures. T o ensure these features robustly represent linguistic content, we attach a linear projection head follo wed by a Connectionist T em- poral Classification (CTC) [28] loss to the encoder’ s output. Speech Encoder Whisper Encoder m aɪ _ n ˈeɪ m z _ f ˈɜː ɡ ə s ə n source speech content feature m aɪ _ ... auxiliary text s 0.75 dur . scaling ratio t ODE time Mel velocity Mel at speaker embed. Speech Decoder Duration Predictor 0.75 s t length scaling Fig. 2 : CosyAccent architecture. It implicitly models rhythm for prosodic flexibility , while allo wing the total duration to be either specified or predicted. Speech decoder . The DiT [29] speech decoder is trained using flo w matching [30] to generate the velocity of the Mel-spectrogram. As illustrated in Figure 3, each decoder layer comprises three modules: self-attention, cross-attention, and a feed-forward network (FFN). Each of these modules is followed by adaptiv e layer normalization (AdaLN), modulated by the time embedding. The encoder output, which provides the content representations, acts as the content con- dition and is incorporated through cross-attention. T otal-duration control via position scaling . A key challenge in non-autoregressi ve conv ersion is aligning source and tar get se- quences of different lengths. Our cross-attention decoder addresses this using Rotary Positional Encodi ng (RoPE) [31] combined with a “position scaling” technique, inspired by ARDiT TTS [32]. Self Attention w/ AdaLN Cross Attention w/ AdaLN FFN w/ AdaLN t 0.0 0.6 1.2 1.8 2.4 3.0 0 1 2 3 Decoder Layer content feature processed Mel t time embed. 0 1 ... RoPE positions Fig. 3 : Speech decoder’ s alignment mechanism. Positional indices for the source content features are scaled to match the target’ s length, creating a coarse alignment within RoPE-based cross attention. Instead of using absolute indices for positional encoding, we normalize the positions of the source content features. As shown in Figure 3, the positional indices of the source encoder features are scaled so that their endpoint aligns perfectly with the endpoint of the target Mel-spectrogram’ s length. This technique establishes a coarse alignment between the source and target, ensuring the decoder cor- rectly maps the start, middle, and end of the content regardless of the absolute length. Consequently , the model can robustly generate coherent output ev en when the target length is manually specified, a crucial feature for duration-constrained tasks like dubbing. T otal-duration prediction . In accent normalization, the source speech has a known length that can be directly inherited for gen- eration. This is a practical approach for applications lik e dubbing where duration must be strictly preserved. T o provide flexibility for scenarios where the length can be modified without manual specifi- cation, we introduce a total-duration predictor . This module learns to predict a single total-duration scaling ratio , defined as the target length di vided by the source length, as depicted in Figure 3. For example, if an 8-frame input corresponds to a 6-frame target, the ratio is 0.75. During inference, this predicted ratio can be optionally used to determine the output length. The predictor is constructed with a DiT backbone followed by an attentiv e pooling layer and is trained via flow matching. Timbr e Conditioning. While the frozen Whisper encoder [27] pro- vides robust linguistic features, it may suppress timbre information from the source audio. T o ensure high-fidelity v ocal mimicry , we augment the model with an explicit timbre condition by e xtracting a speaker embedding using a pre-trained speaker encoder . The total- duration predictor also uses the speaker embedding as input; this connection is omitted from the figure for clarity . The decoder’ s velocity field is therefore conditioned on three in- puts: the noisy sample x t at time t , a sequence of content features c , and a single speaker embedding vector s . W ith parameteriza- tion θ , the model’ s output is denoted as v θ ( x t , t, c , s ) . T o control the influence of these two distinct conditions, we emplo y a two-way Classifier-Free Guidance (CFG) [33] scheme in inference: ¯ v θ ( x t , t, c , s ) = v θ ( x t , t, c , s ) + w 1 ( v θ ( x t , t, c , s ) − v θ ( x t , t, ∅ , ∅ )) + w 2 ( v θ ( x t , t, c , s ) − v θ ( x t , t, ∅ , s )) (1) where w 1 and w 2 are guidance strengths, and ∅ denotes a dropped condition. The w 1 term pro vides general guidance, steering the gen- eration a way from the fully unconditional output. The w 2 term addi- tionally strengthens the model’ s adherence to the linguistic content. 4. EXPERIMENT AL SETUP 4.1. Datasets Our experiments utilize sev eral datasets. The nativ e target corpus, LibriTTS-R [25], is utilized by all systems. For training the base- line models, we use real-world L2 source speech from two datasets: the publicly available 20-hour L2-ARCTIC corpus [26] and an in- ternal 300-hour Chinese-accented English dataset. For our proposed method, we use the source-synthesized L2 accent dataset constructed in Section 3.1, which is deriv ed from LibriTTS-R and L2-ARCTIC. 4.2. Compared Systems W e evaluate our model ag ainst two strong baselines: • F ramAN [13]: A frame-to-frame flow-matching model. • T okAN [18]: A model based on discrete SSL tokens. W e test two modes: T okAN-1 , which predicts token durations directly , and T okAN-2 , which predicts with total-duration awareness and preserves the total duration. Both baseline systems were trained on paired data consisting of real L2 speech (from L2-ARCTIC and the Chinese-accented set) and their corresponding L1 targets from LibriTTS-R. For our proposed model, we also e v aluate two configurations: • CosyAccent-1 : Uses the predicted total duration scaling ratio. • CosyAccent-2 : Inherits the source total duration. Crucially , CosyAccent is trained only on our source-synthesized dataset. This means that, unlik e the baselines, our model is never exposed to real L2-accented speech during training. For the CosyAccent architecture, we use the official Whisper- medium model [27] as the frozen speech frontend and Resemblyzer 4 for speaker embedding extraction. The final wa veform is generated using the HiFTNet vocoder [34] from CosyV oice2. During infer - ence, the CFG weights w 1 and w 2 are both set to 1.0, and we use a 32-step Euler sampler for generation. 4.3. Evaluation Data & Metrics Evaluation Set. Our test set is built from an extended L2-ARCTIC dataset [26, 35], cov ering sev en accents: Arabic, Chinese, Hindi, K orean, Spanish, V ietnamese, and nati ve American English. The set contains 80 sentences. This partitioning is consistent with our training data construction (Section 3.1). Subjective Evaluation. W e conducted listening tests with 24 raters to assess three qualities: Naturalness (NA T) and Accentedness (ACT) were measured via MUSHRA tests. The nati ve accent was e xcluded from the A CT ev aluation. Speaker Similarity (SIM) was measured via Best-W orst Scaling (BWS), with scores aggregated using a stan- dard counting algorithm [36]: ( N best − N worst ) / N occurrence . Objective Evaluation. W e use four objectiv e metrics to assess con version quality automatically . Intelligibility: W ord Error Rate (WER) from a nativ e-only ASR model 5 to simulate listener percep- tion. Naturalness: The UTMOSv2 score 6 from a neural naturalness 4 https://github .com/resemble-ai/Resemblyzer 5 https://huggingface.co/facebook/s2t-medium-librispeech-asr 6 https://github .com/sarulab-speech/UTMOSv2 T able 1 : Evaluation results of the accent normalization systems System Source-length Subjectiv e Objectiv e N A T ( ↑ ) A CT ( ↓ ) SIM ( ↑ ) WER (% ↓ ) UTMOS ( ↑ ) SECS ( ↑ ) ∆ PPG ( ↓ ) Source ✓ 65.78 ± 2.18 50.45 ± 2.22 - 15.86 2.81 - 0.51 FramAN [13] ✓ 58.13 ± 2.19 44.08 ± 2.19 − 0.075 21.54 2.56 0.8065 0.49 T okAN-1 [18] × 63.63 ± 1.97 29.44 ± 1.87 0.060 16.21 2.86 0.8563 0.30 T okAN-2 [18] ✓ 57.25 ± 2.19 31.98 ± 2.00 − 0.027 16.71 2.76 0.8613 0.30 CosyAccent-1 × 64.62 ± 1.92 31.04 ± 1.91 0.033 12.96 3.04 0.8213 0.38 CosyAccent-2 ✓ 60.98 ± 2.05 35.19 ± 2.09 0.008 13.26 2.97 0.8291 0.37 predictor . T imbre Pr eservation: Speaker Encoding Cosine Simi- larity (SECS) using the accent-rob ust Resemblyzer . Accentedness Reduction: The phonetic posteriorgram distance ( ∆ PPG) [37]. 5. RESUL TS 5.1. Comparison with Frame-to-Frame Baseline The subjective and objective ev aluation results are presented in T a- ble 1. CosyAccent significantly outperforms the frame-to-frame baseline, FramAN, across all subjectiv e and objective metrics. W e attribute this broad superiority to our model’ s holistic spectrogram generation. In contrast, FramAN’ s reliance on explicit, frame- lev el pitch and energy predictors proves brittle, especially when encountering the unseen rhythmic patterns of L2 speech, leading to degraded naturalness and speaker similarity . 5.2. Comparison with T oken-Based Baseline The comparison with the token-based T okAN is more nuanced and rev eals ke y trade-offs in accent con version. Intelligibility/Content Preservation (WER). CosyAccent achie ves significantly better content preservation, with a WER of 12.96% compared to T okAN’ s 16.21%. Our analysis of the generated sam- ples suggests that T okAN performs an overly aggressive pronunci- ation modification. While this can aid in accent reduction, it fre- quently alters the underlying content, resulting in higher WER. As shown in T able 2, CosyAccent’ s adv antage holds consistently across nearly all accents, though performance is similar for Chinese and V ietnamese. This similarity may stem from shared prosodic traits (e.g., syllable-timed rhythm) and the f act that T okAN’ s training data included additional Chinese-accented speech. Naturalness and Speaker Similarity (N A T , UTMOS, SIM, SECS). In terms of speech quality , CosyAccent demonstrates supe- rior naturalness ov er T okAN in both duration-preserving ( -2 ) and duration-predicting ( -1 ) modes, as confirmed by both subjectiv e N A T and objectiv e UTMOS scores. Howe ver , T okAN achieves higher speaker similarity (SECS). W e hypothesize this is due to the fusion method: T okAN employs AdaLN to inject speak er in- formation, a technique often more ef fective than the simple input concatenation. A notable discrepancy arises between the objec- tiv e and subjective similarity scores: despite T okAN-2’ s superior objectiv e SECS score, it is outperformed by CosyAccent on SIM. W e attribute this to prosodic artifacts; the exaggerated rhythm in T okAN-2’ s output likely penalizes the human perception of speaker identity , ev en if the underlying vocal timbre is matched. Accentedness Reduction (A CT , ∆ PPG). In terms of accentedness reduction, CosyAccent performs on-par with T okAN, demonstrat- ing the effectiv eness of our source-synthesis approach. The slight performance difference can be attributed to the training data: while T okAN was trained on real L2-ARCTIC samples, CosyAccent was trained exclusi vely on our source-synthesized data. This domain gap highlights the challenge of bridging synthetic and real L2 speech, yet our results demonstrate that source-synthesized training data is not only viable but highly effecti ve. The strong accentedness reduction achiev ed by CosyAccent validates our paradigm shift and eliminates the dependency on real L2 data collection. T able 2 : Accent-wise WERs with native-only ASR System Zh Hi V i Ar Es K o Source 20.82 11.75 31.40 15.09 15.79 13.78 FramAN 26.76 19.98 34.36 22.96 22.28 18.91 T okAN-1 17.18 18.53 24.51 17.25 16.68 13.81 T okAN-2 17.80 18.95 25.20 17.36 17.52 14.43 CosyAccent-1 16.95 7.55 25.53 13.97 13.22 10.15 CosyAccent-2 17.77 7.52 24.41 13.97 14.40 11.03 5.3. Ablation Study W e conduct an ablation study on CosyAccent-2, with results shown in T able 3. CTC auxiliary loss : removing the CTC loss results in a significant increase in WER; this confirms that the auxiliary loss is crucial for guiding the model’ s content encoder and ensuring ac- curate content preservation during conv ersion. Speaker embeddings : ablating the speaker embedding leads to a sharp drop in speaker sim- ilarity; this finding validates our hypothesis that the frozen Whisper encoder largely suppresses timbre information, making an e xplicit speaker condition essential in the current model design. Content po- sition scaling : removing position scaling from the content features caused immediate training instability , leading to model collapse; this demonstrates that the technique is beneficial for stabilizing the train- ing process of our proposed architecture. T able 3 : Ablation results of CosyAccent-2 System WER ( % ↓ ) SECS ( ↑ ) ∆ PPG ( ↓ ) Source 15.86 - 0.51 CosyAccent-2 13.26 0.8291 0.37 w/o CTC loss 15.61 0.8324 0.41 w/o speaker embedding 13.51 0.6524 0.37 w/o position scaling Model Collapse 6. CONCLUSION, LIMIT A TIONS, & FUTURE WORK In this paper , we introduced CosyAccent, a duration-controllable ac- cent normalization model, and a novel source-synthesis data strat- egy . Our method largely reduces the need for real L2 training data by synthesizing the source speech and using authentic nati ve speech as targets. This approach allows the model to avoid learning from TTS artifacts, leading to superior content preservation and natural- ness. Key limitations include robustness to acoustic noise and con- trol over paralinguistics, as the synthetic data is very clean. Future work will focus on these issues. 7. A CKNO WLEDGEMENT This work was supported by National Natural Science F oundation of China (Grant No. 62271432), Shenzhen Science and T echnol- ogy Research Fund (Fundamental Research Ke y Project, Grant No. JCYJ20220818103001002), Program for Guangdong Introducing Innov ati ve and Entrepreneurial T eams (Grant No. 2023ZT10X044), and Y angtze Riv er Delta Science and T echnology Innov ation Com- munity Joint Research Project (2024CSJGG1100). 8. REFERENCES [1] Daniel Felps, Heather Bortfeld et al., “Foreign accent con- version in computer assisted pronunciation training, ” Speech communication , vol. 51, no. 10, pp. 920–932, 2009. [2] Oytun T ¨ urk, Lev ent M Arslan, “Subband based voice conv er- sion., ” in Proc. Interspeech , 2002, pp. 289–292. [3] Lifa Sun, Hao W ang et al., “Personalized, cross-lingual tts using phonetic posteriorgrams., ” in Pr oc. Interspeech , 2016. [4] Zhao Guanlong, Sonsaat Sinem et al., “ Accent con version us- ing phonetic posteriorgrams, ” in Pr oc. ICASSP , 2018. [5] Guanlong Zhao, Shaojin Ding et al., “Foreign accent con ver - sion by synthesizing speech from phonetic posteriorgrams., ” in Pr oc. Interspeech , 2019, pp. 2843–2847. [6] W enjie Li, Benlai T ang et al., “Improving accent con version with reference encoder and end-to-end text-to-speech, ” arXiv pr eprint arXiv:2005.09271 , 2020. [7] Shaojin Ding, Guanlong Zhao et al., “ Accentron: Foreign ac- cent conv ersion to arbitrary non-native speakers using zero- shot learning, ” Computer Speech & Language , vol. 72, pp. 101302, 2022. [8] Songxiang Liu, Disong W ang et al., “End-to-end accent con- version without using nati ve utterances, ” in ICASSP , 2020. [9] Zhijun Jia, Huaying Xue et al., “Conv ert and speak: Zero-shot accent con version with minimum supervision, ” in Multimedia , 2024. [10] Y i Zhou, Zhizheng W u et al., “Tts-guided training for accent con version without parallel data, ” Signal Processing Letters , vol. 30, pp. 533–537, 2023. [11] Xi Chen, Jiakun Pei et al., “Transfer the linguistic representa- tions from tts to accent conv ersion with non-parallel data, ” in Pr oc. ICASSP , 2024. [12] T uan Nam Nguyen, Seymanur Akti et al., “Improving pronun- ciation and accent con version through kno wledge distillation and synthetic ground-truth from nativ e tts, ” in ICASSP , 2025. [13] Qibing Bai, Shuai W ang et al., “Diffusion-based method with tts guidance for foreign accent conv ersion, ” in Pr oc. ISCSLP , 2024, pp. 284–288. [14] T uan-Nam Nguyen, Quan Pham et al., “ Accent con version us- ing discrete units with parallel data synthesized from control- lable accented tts, ” in Synthetic Data’s T ransformative Role in F oundational Speech Models , 2024, pp. 51–55. [15] Guanlong Zhao, Shaojin Ding et al., “Con verting foreign ac- cent speech without a reference, ” T ASLP , vol. 29, pp. 2367– 2381, 2021. [16] T uan-Nam Nguyen, Ngoc-Quan Pham et al., “ Accent con ver - sion using pre-trained model and synthesized data from voice con version., ” in Pr oc. Interspeech , 2022, pp. 2583–2587. [17] Sho Inoue, Shuai W ang et al., “Macst: Multi-accent speech synthesis via text transliteration for accent con version, ” in ICASSP , 2025. [18] Qibing Bai, Sho Inoue et al., “ Accent normalization using self- supervised discrete tokens with non-parallel data, ” in Inter - speech 2025 , 2025, pp. 1618–1622. [19] Zhihao Du, Y uxuan W ang et al., “Cosyvoice 2: Scalable streaming speech synthesis with lar ge language models, ” arXiv pr eprint arXiv:2412.10117 , 2024. [20] Mumin Jin, Prashant Serai et al., “V oice-preserving zero-shot multiple accent con version, ” in Pr oc. ICASSP , 2023. [21] W en-Chin Huang, Y i-Chiao W u et al., “ Any-to-one sequence- to-sequence voice conv ersion using self-supervised discrete speech representations, ” in Proc. ICASSP , 2021. [22] Sang-Hoon Lee, Hyeong-Rae Noh et al., “Duration control- lable voice conv ersion via phoneme-based information bottle- neck, ” TASLP , v ol. 30, pp. 1173–1183, 2022. [23] Felix Kreuk, Adam Polyak et al., “T extless speech emotion con version using discrete & decomposed representations, ” in Pr oc. EMNLP , 2022. [24] Hyung-Seok Oh, Sang-Hoon Lee et al., “Durflex-e vc: Duration-flexible emotional v oice con version lev eraging dis- crete representations without text alignment, ” IEEE T ransac- tions on Affective Computing , 2025. [25] Y uma Koizumi, Heiga Zen et al., “LibriTTS-R: A Restored Multi-Speaker T ext-to-Speech Corpus, ” in Inter speech , 2023. [26] Guanlong Zhao, Sinem Sonsaat et al., “L2-ARCTIC: A Non- nativ e English Speech Corpus, ” in Pr oc. Interspeech , 2018. [27] Alec Radford, Jong W ook Kim et al., “Robust speech recog- nition via large-scale weak supervision, ” in ICML , 2023, pp. 28492–28518. [28] Alex Graves, Santiago Fern ´ andez et al., “Connectionist tem- poral classification: labelling unsegmented sequence data with recurrent neural networks, ” in ICML , 2006. [29] W illiam Peebles, Saining Xie, “Scalable dif fusion models with transformers, ” in Proc. ICCV , 2023, pp. 4195–4205. [30] Y aron Lipman, Rick y T . Q. Chen et al., “Flow matching for generativ e modeling, ” in ICLR , 2023. [31] Jianlin Su, Murtadha Ahmed et al., “Roformer: Enhanced transformer with rotary position embedding, ” Neur ocomput- ing , vol. 568, pp. 127063, 2024. [32] Zhijun Liu, Shuai W ang et al., “ Autoregressiv e diffusion transformer for text-to-speech synthesis, ” arXiv preprint arXiv:2406.05551 , 2024. [33] Jonathan Ho, Tim Salimans, “Classifier-free diffusion guid- ance, ” in NeurIPS 2021 W orkshop on Deep Generative Models and Downstr eam Applications , 2021. [34] Y inghao Aaron Li, Cong Han et al., “Hiftnet: A fast high-quality neural vocoder with harmonic-plus-noise filter and in verse short time fourier transform, ” arXiv preprint arXiv:2309.09493 , 2023. [35] John K ominek, Alan W Black, “The cmu arctic speech databases, ” in F ifth ISCA workshop on speech synthesis , 2004. [36] A. M. V . Ravillion, “ A comparison of best-worst scaling and rating scale for timbre characterisation, ” 2020. [37] Cameron Churchwell, Max Morrison et al., “High-fidelity neu- ral phonetic posteriorgrams, ” in ICASSP 2024 W orkshop on Explainable Machine Learning for Speech and Audio , 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment