절차를 넘어선 실질적 공정성 컨포멀 예측
** 컨포멀 예측은 모델 예측에 대한 분포 자유 불확실성 구간을 제공하지만, 하위 의사결정 단계에서의 공정성 효과는 충분히 연구되지 않았다. 본 논문은 절차적 공정성에 머무르지 않고, 예측 집합 크기의 차이가 최종 결과에 미치는 영향을 분석한다. 이론적으로 예측 집합 크기 불균형을 여러 해석 가능한 항으로 분해한 상한을 제시하고, 라벨‑클러스터링 기반 컨포멀 방법이 방법론적 불공정성 기여도를 억제함을 보인다. 또한 인간 평가를 근사하는 LL…
저자: Pengqi Liu, Zijun Yu, Mouloud Belbahri
**
1. **연구 배경 및 동기**
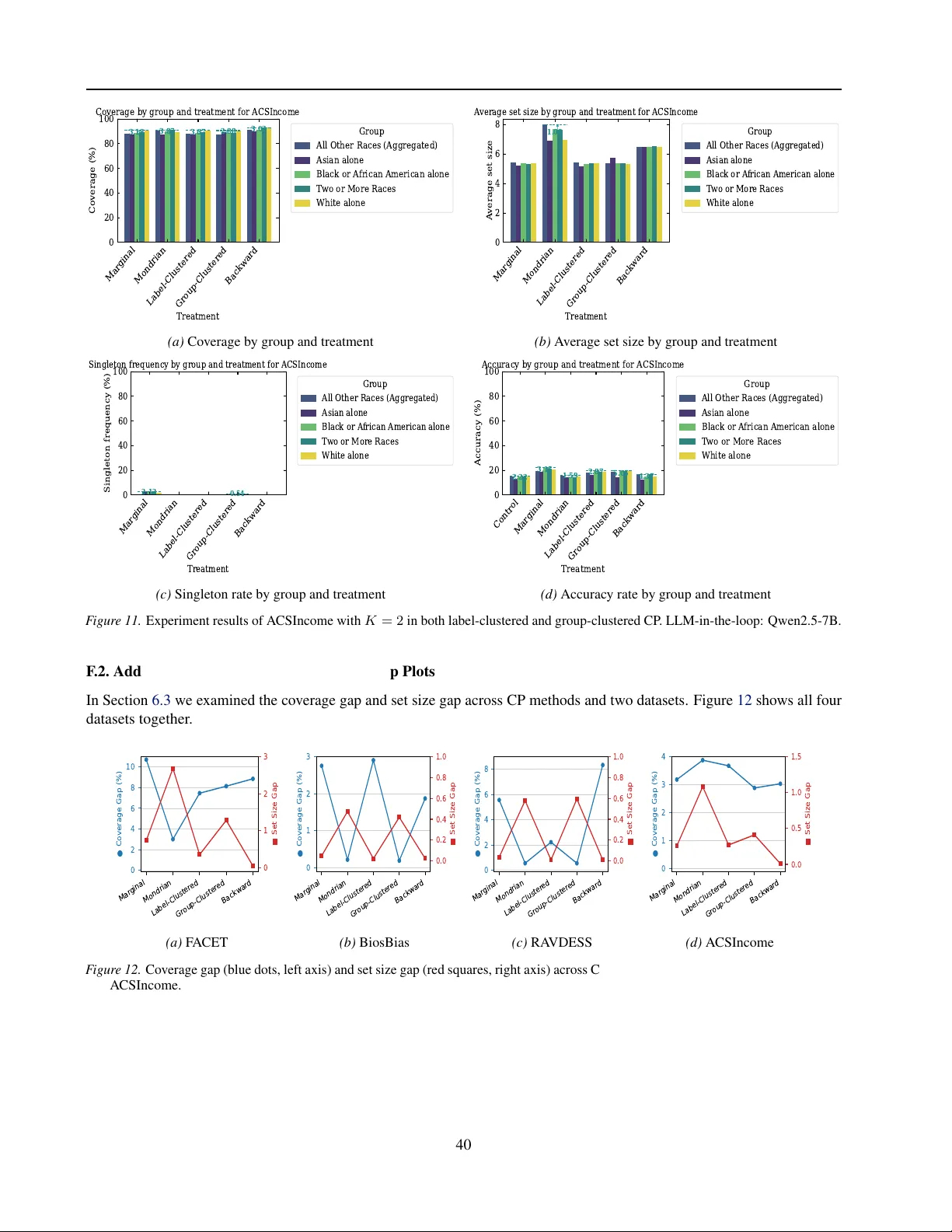
컨포멀 예측은 머신러닝 모델에 대해 사후 확률적 보장을 제공하는 기법으로, 주어진 신뢰 수준(예: 90%)에서 “예측 집합”을 생성한다. 이 집합은 실제 라벨을 포함할 확률이 이론적으로 보장되며, 데이터 분포에 대한 가정이 필요 없다는 점에서 널리 활용된다. 그러나 대부분의 기존 연구는 이러한 통계적 보장(절차적 공정성)에만 초점을 맞추고, 생성된 집합이 downstream 의사결정에 미치는 형평성(실질적 공정성)을 간과한다. 실제 현장에서는 예측 집합 크기가 크면 의사결정자가 보수적으로 행동하고, 작은 집합은 위험을 과소평가하게 되는 등, 집합 크기의 차이가 직접적인 결과 차별을 초래한다.
2. **문제 정의**
논문은 “실질적 공정성”을 “예측 집합을 이용한 최종 의사결정 결과의 형평성”으로 정의한다. 이를 정량화하기 위해 저자들은 두 가지 핵심 지표를 도입한다. (i) **집합 크기 불균형**: 그룹(예: 인종, 성별) 간 평균 예측 집합 크기의 차이. (ii) **실질적 공정성 점수**: LLM‑in‑the‑loop 평가자가 인간 평가와 유사하게 산출한 종합 점수.
3. **이론적 기여**
예측 집합 크기 차이를 분석하기 위해, 저자들은 다음과 같은 상한식을 증명한다.
|Δ| ≤ 𝔼
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기