산모 건강을 위한 LLM 활용: 정확성·안전성·가독성 종합 평가
본 연구는 인도 농촌 여성들의 임신·산후 정보 접근성을 개선하기 위해 ChatGPT‑4o, Perplexity AI, Gemini AI 세 모델을 17개의 임산부 질문에 적용하고, 의료 전문가 답변과의 의미 유사도, 명사 겹침, 가독성 지표를 비교하였다. 결과는 Perplexity가 의미 일치도가 가장 높았으며, ChatGPT‑4o가 가장 쉬운 언어와 정확한 의학 용어 사용으로 가독성이 우수함을 보여준다.
저자: V Sai Divya, A Bhanusree, Rimjhim
본 연구는 인도 농촌 지역 여성들의 임신·산후 정보 접근성을 디지털화된 대규모 언어 모델(LLM)로 보완하고자 하는 목적에서 출발하였다. 인구 13억 명 중 830 백만 명이 인터넷을 사용하고, 농촌 여성의 절반 이상이 온라인에 접속한다는 통계적 배경을 바탕으로, LLM이 의료 상담의 첫 번째 창구가 될 가능성을 탐색한다.
연구팀은 ChatGPT‑4o, Perplexity AI, Gemini AI 세 모델을 선정했으며, 각 모델에 17개의 임산부 질문을 제시하였다. 질문은 ‘임신 초기 증상’, ‘영양 섭취’, ‘전통적 미신(예: ‘태아가 배를 차면 출산이 빨라진다’ 등)’, ‘산후 우울증 징후’ 등 임신 전·중·후 단계와 문화적 오해를 포괄한다. 모델에게는 “현장 경험이 풍부한 산부인과 전문의 역할을 수행한다”는 프롬프트를 부여해 답변을 유도하였다.
동시에, 동일 질문에 대해 인도 내 산부인과·산후 관리 전문가 4명(각기 다른 의료기관)으로부터 답변을 수집해 ‘전문가 기준답안’으로 설정하였다. 모든 답변은 익명화하고, 윤리 위원회의 승인을 받아 진행되었으며, 데이터 신뢰성을 위해 두 차례 검증 절차를 거쳤다.
평가 방법은 세 가지 핵심 지표를 사용했다. 첫째, 가독성 평가는 Flesch Reading Ease(FRE), Flesch‑Kincaid Grade Level(FKGL), Gunning Fog Index(GFI), SMOG, Dale‑Chall Readability Score(DCRS), Automated Readability Index(ARI) 등 6가지 국제 표준을 적용했다. 높은 FRE와 낮은 FKGL·GFI·SMOG·DCRS·ARI 점수가 더 쉬운 텍스트를 의미한다. 결과는 ChatGPT‑4o가 FRE 64.63점, FKGL 7.53, GFI 9.86 등 모든 지표에서 가장 우수한 가독성을 보였으며, 이는 중학교 7~8학년 수준에 해당한다. Perplexity는 FRE 53.89, FKGL 9.67 등 다소 높은 난이도를 보였고, Gemini는 중간 수준에 머물렀다.
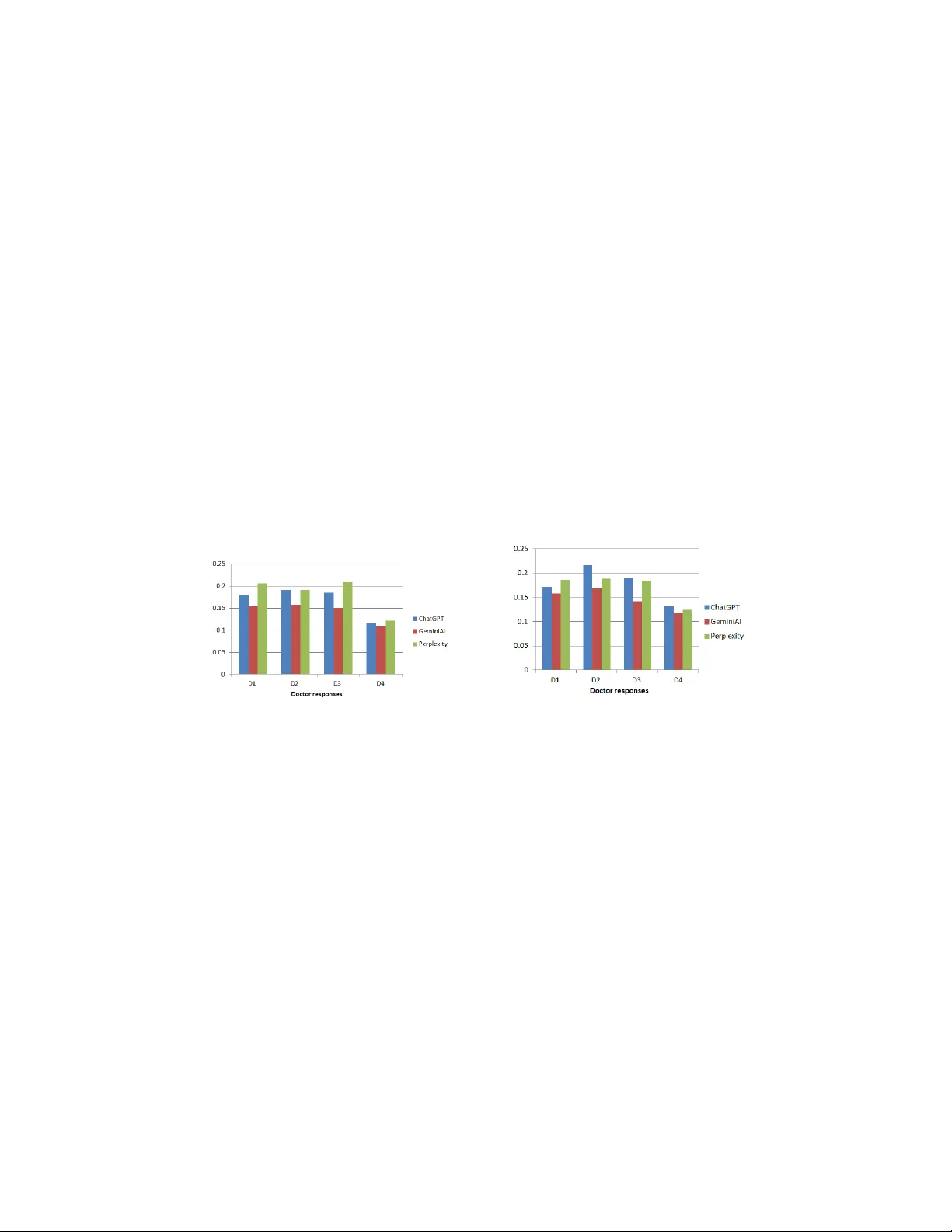
둘째, 의미 유사도는 코사인 유사도를 활용해 LLM 답변과 전문가 답변 간 의미적 일치를 정량화했다. Perplexity AI가 평균 0.206의 최고 점수를 기록했으며, 특히 D1(임신 초기 증상)·D2·D3에서 전문가와 가장 근접한 의미를 전달했다. ChatGPT‑4o는 D2에서 약간 높은 0.191 점수를 보였지만, 전반적으로 Perplexity와 비슷한 수준을 유지했다. D4(복합 임상 상황)에서는 세 모델 모두 유사도가 급격히 감소해, 고난이도 의료 판단에 대한 한계를 드러냈다.
셋째, 명사 엔티티 겹침은 Jaccard 유사도를 통해 핵심 의료 용어의 포함 여부를 측정했다. ChatGPT‑4o는 D2에서 0.216의 최고 점수를 받아 용어 정확도가 가장 높았으며, Perplexity는 D1·D2·D3 전반에 걸쳐 일관된 겹침을 보였다. Gemini는 전반적으로 낮은 점수를 기록했다.
연구 결과를 종합하면, ‘의미 정확도’와 ‘가독성’은 서로 독립적인 축이며, 한 모델이 두 축을 동시에 최적화하기는 어려운 것으로 나타났다. Perplexity는 의미 일치도가 가장 높아 의료 전문가와의 내용적 일관성을 제공하지만, 텍스트가 다소 복잡해 일반 사용자가 이해하기엔 어려울 수 있다. 반면 ChatGPT‑4o는 가장 쉬운 언어와 명확한 의학 용어 사용으로 가독성이 뛰어나지만, 의미 일치도는 Perplexity에 약간 뒤처진다. Gemini는 두 축 모두 중간 수준에 머물러, 현재 시점에서는 보조적인 역할에 그친다.
논문의 한계점으로는 질문 수가 제한적이며, 실제 현장 임산부가 제시하는 비표준 질문(예: 지역 방언, 개인적 상황)과의 차이가 있다. 또한 전문가 답변이 인도 내 특정 의료기관에 국한돼 문화·지역적 편향이 존재할 가능성이 있다. LLM 자체도 최신 버전(예: GPT‑4o 이후 모델)과의 비교가 이루어지지 않아, 기술 진화에 따른 성능 변화를 포착하지 못했다.
향후 연구 방향은 (1) 질문 풀을 확대해 다양한 임산부 상황을 포괄하고, (2) 다국적·다문화 전문가 집단을 포함해 보다 일반화된 골드 스탠다드를 구축하며, (3) 산부인과 전용 데이터셋으로 파인튜닝한 도메인 특화 LLM을 개발하고, (4) 실제 농촌 지역에서 모바일 앱이나 SMS 기반 서비스로 배포해 현장 사용성·신뢰성을 실증하는 것이다.
결론적으로, 본 연구는 LLM이 농촌 여성에게 신뢰성 있는 산모 교육을 제공할 잠재력을 입증하면서, ‘정확성 vs. 가독성’ 트레이드오프를 명확히 제시한다. 정책 입안자와 보건 당국은 이러한 정량적 지표를 활용해 지역 맞춤형 AI 헬스케어 전략을 설계하고, 지속적인 현장 검증과 피드백 루프를 통해 안전하고 효과적인 디지털 산모 지원 시스템을 구축해야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기