Trust, Safety, and Accuracy: Assessing LLMs for Routine Maternity Advice
Access to reliable maternal healthcare information is a major challenge in rural India due to limited medical resources and infrastructure. With over 830 million internet users and nearly half of rural women online, digital tools offer new opportunit…
Authors: V Sai Divya, A Bhanusree, Rimjhim
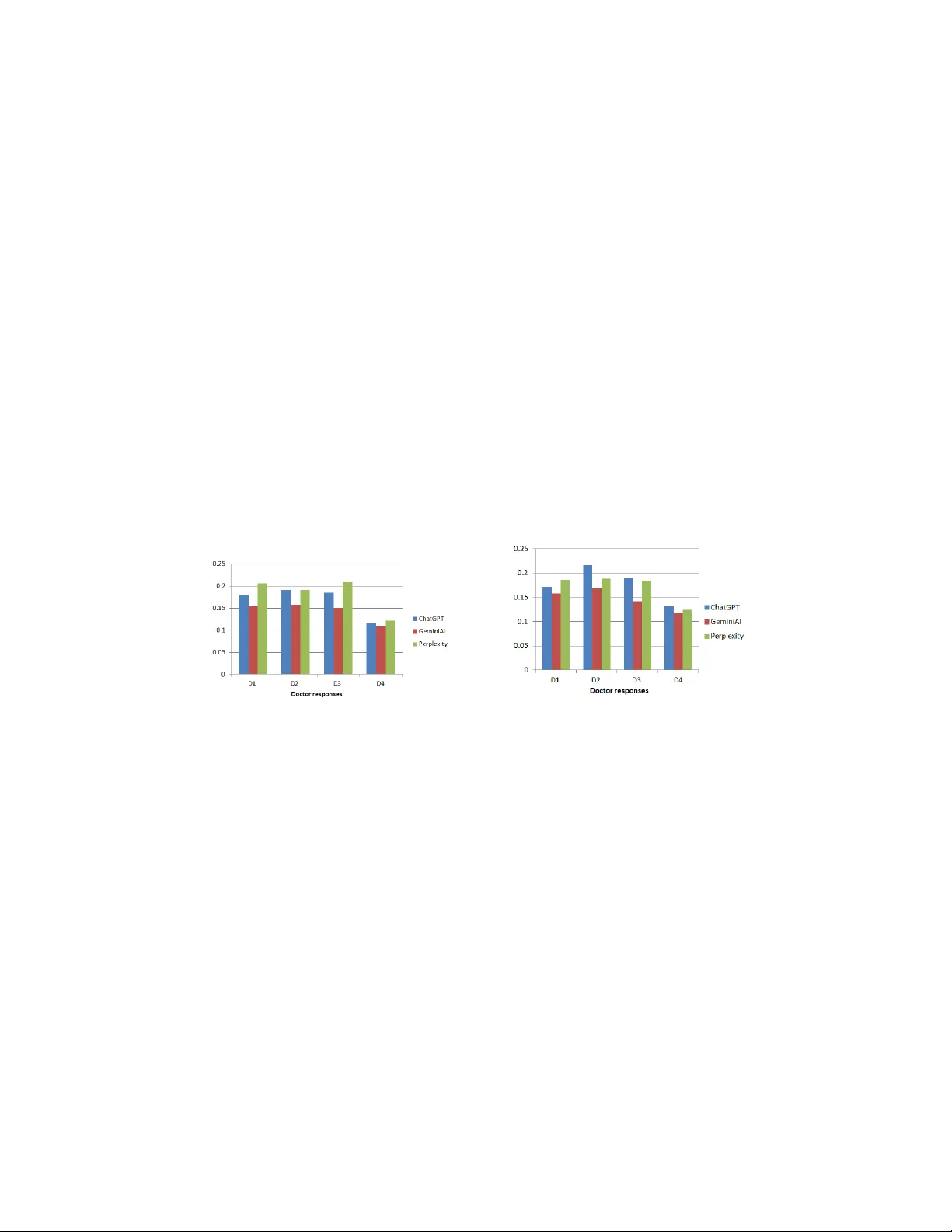
T rust, Safet y , and Accur acy: Assessing LLMs for Routine Maternit y Ad vice. Sai Divya Vissamsett y 1 , Anagani Bhanusree 1 , Rimjhim 1 , and K V enk ataKrishna Rao 1 National Institute of T echnology , W arangal, India vs25csr1p1 0@student. nitw.ac.in, ab25csr1 p11@studen t.nitw.ac. in, rimjhim@ni tw.ac.in, kvkrao@nit w.ac.in Abstract. Maternal health information accessibilit y remains a signif- ican t concern in In dia, where inadeq uate h ealthcare infrastructure and socio-cultural hesitations often delay medical consultation. Many w omen hesitate to discuss pregnancy related concerns with do ctors d ue to stigma or priv acy issues, increasingly turning to digital platforms like LLMs for everyda y health qu eries. This study ev aluates th ree leading LLMs: ChatGPT-4o, P erplexity AI, and GeminiAI for their ability to provide medically reliable, readable, and culturally sensitive responses to seven- teen pregnancy related questions, includin g prev alent myths and miscon- ceptions in the Indian context. Readabilit y of the LLMs resp onses wa s assessed using vari ous English readabilit y metrics to en sure that infor- mation is presented in simple, clear, and easily u n derstandable language, enabling women especially those from diverse educational backgrounds to comprehend and apply the health guidance effectively . Cosine similarit y w as used to eval uate semantic alignment with exp ert medical responses, and Jaccard similarity measured n oun-entit y ov erlap. Results show that ChatGPT generated the most readable and clinically coherent resp onses (FRE = 64.63; FKGL = 7.53), while Perplexit y AI achiev ed the highest seman tic similarit y (mean cosine = 0.206). F or noun ov erlap, ChatGPT exhibited stronger contextual alignmen t (Jaccard = 0.172–0.216). O ver- all, the findin gs underscore the p otential of LLMs, p articularly ChatGPT and Perplexit y AI, as supp ortive tools for addressing pregnancy related myths, enhancing maternal h ealth communication, and improving digital health literacy in underserved Indian communities. Keywords: Large Language Mod els · Maternal Health · Readability · Semantic Similarity · AI in H ealthcare · Cultural Myths. 1 In t ro duction The issue of maternal health in India p er sists a s a ma jor public health con- cern, largely due to unequa l healthcar e acce ss b etw ee n r ural and urban p opula- tions, which contributes to delays in essential medical car e. Socia l stigma, limited aw ar e ness, and cultural tab o os frequently dis c ourage women from discussing re- pro ductive or pregnancy r elated concerns o p enly with healthcare providers. At the sa me time, the increasing relia nce on digital platforms for ev er yday queries 2 Sai Divya et al. ranging fro m lifestyle advice to health information has led to growing engage- men t with LL Ms . T he s e mo dels a re incr easingly b eing used a s first line sour ces of informatio n, even on sens itive topics like pr egnancy . While digital accessibility has expanded ra pidly with over 830 million internet user s in India and nearly half of r ural w omen now online misinformation and c ulturally ingrained m yths related to preg nancy remain widespr e a d. In such a co ntext, LLMs hav e the po- ten tial to provide quick, empathetic, a nd priv acy pre serving r esp onses, but their reliability a nd cultural sensitivit y require s ystematic ev alua tion. Recent s tudies hav e explored the use o f LLMs in materna l and repro ductive healthcare, focus ing on reliability , rea dability , and practica l utility . Lima et a l. [1] ev alua ted LLMs for delivering maternal hea lth informa tion in resource limited settings, highlighting both pro mise and c hallenges. Khrom- chenk o et al. [2] compared ChatGPT-3.5 a nd Gemini on pregnancy questions, noting differences in accura cy and reliability . Onder et al. [3] a ssessed ChatGPT- 4’s resp onses o n hypothyroidism during pregnancy , str essing the need for co nt ext sp ecific ev a luation. Reck er et a l. [4] examined AI integration in g ynecologic a l care to aid pa tient decision making. Insuk et a l. [5] showed AI mo de ls match- ing hu man per formance in systematic rev iew scr eening. T a¸ skum et al. [6] found high scientific reliability but p o o r r eadability in prenatal screening conten t from LLMs. W an et al. [7] revealed limitations in accuracy a nd refer ence quality of ChatGPT resp ons e s. RimJhim et al. [8 ] sp e cifies digital platforms , including so- cial media and LLM interactions, hav e b een s hown to reflect how cultural nor ms influence health quer ies and the spr ead of misinformation. Here, we inv es tig ated the effectiveness o f leading LLMs ChatGPT, Gem- ini, and P erplexity in addr essing pr egnancy related quer ies within the Indian so cio-cultura l context. These queries covering early gesta tion to p ostnatal ca r e, including prev a le nt myths, were ev aluated for a ccuracy , readability , and con- textual understanding ag a inst exp er t medic a l opinions. Results indicated that LLMs can pr ovide reliable, culturally sens itive, and c o mprehensible information, suppo rting ma ternal health co mm unication in r ural and semi-ur ban regions. The findings emphasize the p otential of AI driven to o ls to complement he a lthcare ser- vices, br idge informa tion ga ps, and empower women to make informed decisions through access ible and co nfident ial digital platforms. 2 Data Collection W e conducted a struc tur ed tw o -phase metho dolog y to examine pr egnancy r e- lated informa tion from LLMs and qualified medica l pra c titio ne r s. Se venteen questions including pre v a lent m yths and misconceptions in the Indian context addressing topics fro m early gestatio n to p o s tnatal car e were de s igned for co m- prehensive cov e r age. In the first phase, res po nses were obtained by from lea ding LLMs to assess their gr asp of ma ternal health.The LLMs were instr ucted to mimic a s a lo cal exper ienced obstetric a nd ma ternal ca re ex pe r t . The second phase inv olved collecting corr esp onding answers from exp er ienced obstetr ic and maternal car e exp erts for co mparative a nalysis. All r esp onses were ev aluated LLMs for Maternal Health Education 3 using predefined s ta ndards for medica l accurac y , clarity , a nd clinical appr opri- ateness. Ethical proto cols were maint ained throughout the pro cess to ensure participant confidentialit y a nd da ta reliability . 3 Metho dology T o asses s the quality and reliability of LLM generated respo nses against those from healthcare pr ofessiona ls, a structured multi-lev el ev alua tion fr amework w as implemen ted. The metho dolo gy e mphasized c o re par ameters like readability , se- mantic similarity and noun entit y overlap. A) R eadabilit y Ass essment Using Linguisti c Metrics: Readability was analyzed to ensure a ccessibility for non-exp ert audiences using established lin- guistic metrics that ev aluate sentence complexity , word choice, and syllable count. These measures help ed determine the clarity and comprehensio n level of the generated re sp onses from the LLMs. The metrics use d in this study in- cluded: Flesc h Reading Ease (FRE ): This s core ev aluates ho w ea s y a passage is to rea d, using sentence le ng th and w ord syllable count. A higher score indica tes more accessible languag e. Flesc h-Kincaid Grade Lev el (FK GL): T he FKGL is computed to trans- lates text complexity into a U.S. grade level.A s core of 8.0 mea ns the co nten t is suitable for so meone at the 8 th -grade reading level. Lower scores are b etter for general audiences. Gunning F og Index (GFI): This index estimates the y ears of formal ed- ucation requir ed to understa nd the text. If the scor e are in the range 7–10 is suitable for gene r al a udiences and ab ov e 12 colleg e-level or higher. SMOG Index: Often used in public health, the SMOG for mula fo cuses on the num b er of p olysy llabic w ords. The result reflects the minimum grade lev el required to understand the text. Dale–Chall R eadability Score (DCRS): This metric co ns iders how many unfamiliar words app ea r in a passa ge. Scores b elow 5.0 sugg est high accessibility . Automated Readabil it y Index (ARI): It uses character co unt to e sti- mate g rade level. B y a pplying these metrics, w e w ere able to ob jectiv ely assess the reading difficulty of e ach resp onse . B) Sem an tic Similarity Analysi s Using Co sine Si milarity: This tec h- nique is used to compare the meaning of tw o text s a mples b y analyzing their vector representations. If the sco res are c lo se to 1 indicates high similar ity in meaning and a sco re nea r 0 indicates little o r no seman tic a lignment. C) Noun Entit y Recognition Overlap Usi ng Jaccard Simil arit y: T o quantify how m uch overlap existed b etw een the identified entities from b oth sources. A sco re o f 1 means c o mplete ov erlap (b oth resp o ns es mention the sa me concepts) and a sco r e of 0 means no shared terminolog y . 4 Sai Divya et al. 4 Results and Discussion 4.1 Readability Me trics W e conducted a thorough analysis o f the rea dability of r esp onses generated by each LLM. This step was crucial to asses s how acce s sible and understandable the resp onses w ould b e for non- exp ert readers, par ticula rly exp ecta nt mo thers and mothers seeking reliable infor mation ab out pregnancy . T o this end, six widely recognized rea dability metrics were employ ed. These metrics can b e broadly group ed based on how their scores sho uld b e in terpre ted: Group 1: Metrics Where a Higher Score Indicates Better Read- ability : FRE ass e s ses how easy a text is to r e a d, based on sentence leng th and syllables per word. A higher FRE sco r e indicates that the conten t is ea sier to understand. F rom T able. 1, we observe that Cha tGPT re c eived the highest FRE s core, suggesting that its outputs were the easiest to r ead among all mo dels. In this metric, a scor e be tw een 60 and 70 typically indicates that the text is understand- able to readers at a middle scho ol (13 –15 years old) reading level, which alig ns well with public hea lth c o mmunication standar ds . Group 2: Metrics Where a Low er Score Indicates Better Readabil- it y: This g roup includes metrics that estimate the minimum gra de level requir ed to comprehend the resp o nses fro m LLMs. A lower score is preferable, as it implies that the resp o nse is more acc e ssible to a wider audience. F rom T a ble. 1, we notice that ChatGPT pro duced the most ac c e ssible re- sp onses, suitable for middle sc ho ol rea ding levels. ChatGPT consistently out- per formed than Perplexit y and Gemini acro ss five reada bility metrics of Group 2, achieving the low est scores where simpler text is preferred. Perplexit y ’s re- T able 1: Average Reada bility Metr ics Across LLMs Group Metric ChatGPT P erplexity G eminiA I Group 1 FRE 64.63 53.89 58.11 Group 2 FKGL 7.53 9.67 8.24 GFI 9.86 12.35 10.59 SMOG Ind ex 10.04 12.00 10.83 DCRS 9.19 10.10 9.47 ARI 8.30 10.06 8.54 sp onses featured longe r sentences and mo r e co mplex vocabula ry , resulting in higher r eading levels. Gemini per formed mo derately but did not exce e d Chat- GPT. These results emphasize ChatGPT’s strength in pro ducing clear, acce s sible language, which is cruc ia l for sensitive medical topics lik e preg na ncy . 4.2 Seman ti c Simi larit y Ev aluation Using Co sine Simi larit y T o ev alua te the sema nt ic alignment be t ween the resp ons e s g enerated by different LLMs and those provided by do ctor’s res p o nses (D1, D2, D3, D4), we e mployed LLMs for Maternal Health Education 5 cosine s imilarity as a qua nt itative metric. It measures how s imila r tw o pieces of text are bas ed on their vector repres e ntations which capture the semantic con ten t of the text and allow for a comparis on that go es beyond simple word matching. Fig. 1 shows p erplexity achiev es the highest average similarity in three o f the four do ctor s resp onse s. All thr ee LLMs show a sig nificant drop in simila r ity with D4, mak ing it the least simila r o verall. ChatGP T p erforms sligh tly b etter than Perplexit y on D2 (0.1 91 v s. 0.190), though their sco res a re nearly identical. 4.3 Noun E n tity Recognition O v erlap Analysis Using Jaccard Similarity Here, in this metho d we ev a luated how w ell LLMs captured key noun entities such as medical terms, conditions, ana tomical r eferences, a nd procedur es when compared to r esp onses given by medica l exp erts.This metric he lps quan tify the extent to which an LLM includes the sa me cor e clinical concepts as a trained healthcare professional. Fig . 2 shows that ChatGP T prov ed the most effective ov era ll, b o osted by a high matc h on D2, while Perplexity was the most consis- ten tly strong model ac ross D1, D2, and D3. All three mo dels strugg le d to find noun ov erlap with D4. Fig. 1: Average Cosine Similarity b e- t ween LLM and Do ctor Resp ons es Fig. 2: Average Jaccard Similar- it y b etw een LLM and Do ctor Re- sp onses 5 Conclusion and F uture W ork This study asse s sed ChatGPT, Perplexit y , a nd Gemini in generating pr e gnancy related healthcar e infor mation using s emantic similarity , noun ov erla p, and read- ability metrics. Cha tGPT p erfo rmed b est, providing accura te, clear, a nd cultur- ally sensitive r esp onses that effectively addr essed common pregnancy myths. Overall, the res po nses produced b y the LLMs ma intained comparatively hig h readability levels, which may hinder comprehension a mo ng women from diverse backgrounds both in rur al and semi-urban reg ions. F uture research should ex- pand ev aluations to diverse medical domains and so cio- cultural contexts for greater inclusivity . Inco r p orating lo cal health guidelines and domain sp ecific tun- ing can further enhance accura cy and rele v a nce. Contin uous benchmarking and real world v alidation remain essen tia l fo r res p o nsible AI use in maternal health communication. 6 Sai Divya et al. References 1. H . A. Lima, P . H. T ro coli-Couto, Z. Moazzam, L. C. Ro cha, A . Paga no, F. F. Martins, L. T. Brab o, Z. S. Reis, L. Keder, A . Begum et al. , “Quality assessmen t of large language mo dels’ out p ut in maternal h ealth,” Scientific R ep orts , vol. 15, no. 1, p . 22474, 2025. 2. K. Khromc henko, S. Shaikh, M. Singh, G. V u rture, R . A. Rana, J. D. Baum, and R. R ana, “Chatgpt-3.5 versus go ogle bard: which large language model resp ond s b est to commonly asked pregnancy questions?” Cur eus , vol. 16, no. 7, 2024. 3. C. Onder, G. Koc, P . Gokbu lut, I. T ask aldiran, and S. Kuskonmaz, “Ev aluation of the reliabili ty and readabili ty of c hatgpt- 4 responses regarding hyp othyroidism during pregnancy ,” Scientific r ep orts , vol. 14, no. 1, p. 243, 2024. 4. F. Reck er, R. Neubauer, A. Wittek , and N. Scholten, “Large language m o dels and w omen’s health: a digital companion for informed d ecision-making,” A r chi ves of Gyne c olo gy and Obstetrics , pp. 1–8, 2025. 5. S . Insuk, K. Bo onpattharatthiti, C. Boonc haroen , P . Chai pitak, M. R ashid, S. K. V eettil, N. M. Lai, N. Chaiyakunapruk, and T. Dh ip p ay om, “How well do chatgpt and claude p erform in study selection for systematic review in obstetrics,” Journal of Me dic al Sys tems , vol. 49, no. 1, pp. 1–9, 2025. 6. ˙ I. T a¸ skum, S. S ın acı, F. Aslan, G. M. T a¸ sku m, and S. Sucu, “Assessmen t of readabil- it y , reliabilit y , and quality of large language models in addressing frequently asked questions regarding prenatal screening for fetal c h romosomal anomalies,” Interna - tional Journal of Gyne c olo gy & Obstetrics , 2025. 7. C. W an, A. Cadiente, K. K hromchenk o, N . F riedric ks, R . A. Rana, and J. D. Baum, “Chatgpt: an eva luation of ai-generated resp onses to commonly asked pregnancy questions,” Op en Journal of Obstetrics and Gyne c olo gy , vol. 13, no. 9, pp. 1528– 1546, 2023. 8. S . Dandapat et al. , “Is gend er-based violence a confluence of culture? empirical evidence from so cial media,” Pe erJ Computer Scienc e , vol. 8, p. e1051, 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment