리피도성 예측에서 이분산성 진단과 다중공선성 역설 해결
본 연구는 426 850개의 바이오액티브 분자를 이용해 XLOGP3 계산 로그P를 예측하는 선형 회귀 모델이 심각한 이분산성을 보이며, 가중 최소제곱과 Box‑Cox 변환으로도 해결되지 않음을 확인한다. 반면 랜덤 포레스트와 XGBoost 같은 트리 기반 앙상블은 이분산에 강인하면서 높은 R²(≈0.765)를 달성한다. SHAP 분석을 통해 분자량(MolWt)이 단변량 상관은 낮지만 다변량 모델에서는 가장 중요한 피처임을 밝혀, TPSA와의 다…
저자: Malikussaid, Septian Caesar Floresko, Ade Romadhony
본 논문은 약 43만 6천 850개의 바이오액티브 화합물을 대상으로, PubChem, ChEMBL, eMolecules 세 데이터베이스의 교차 교집합을 이용해 고품질 데이터셋을 구축하였다. 각 화합물에 대해 RDKit을 활용해 8가지 2차원 분자 기술자(분자량, TPSA, 수소 결합 제공자·수용체, 회전 결합 수, 방향족 고리 수, sp³ 탄소 비율, 무거운 원자 수)를 계산하고, 목표 변수는 PubChem이 제공하는 XLOGP3 계산 로그P값으로 설정하였다. 데이터는 로그P 분포를 유지하도록 층화 샘플링하여 80%를 학습, 20%를 테스트에 사용했으며, 피처는 표준화하였다.
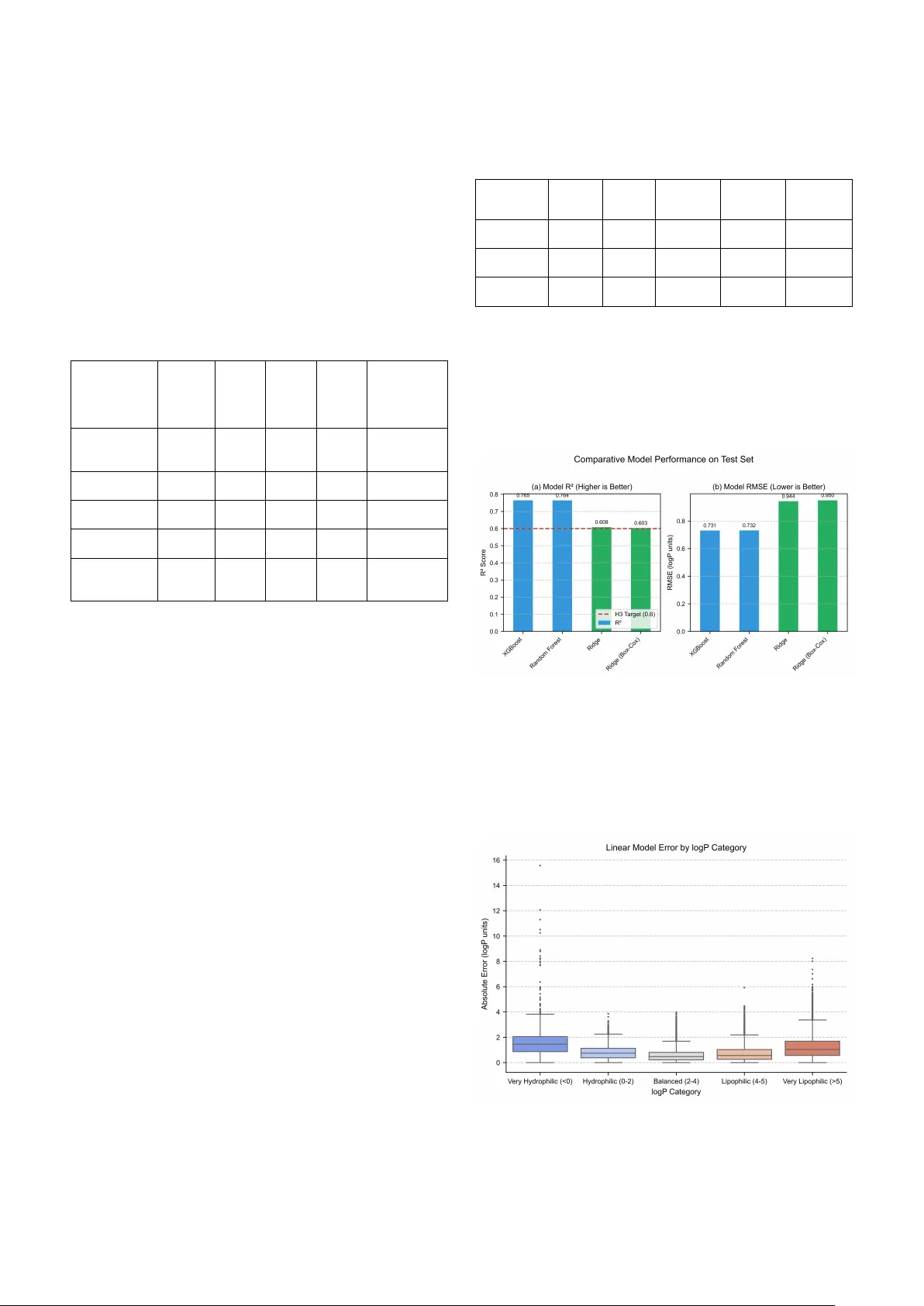
먼저 Ridge 회귀를 기본 선형 모델로 적용했을 때, R²=0.608, RMSE=0.944라는 겉보기 좋은 성능을 보였지만, 잔차 대 예측값 플롯에서 2~4 구간에서는 잔차가 작게 모여 있는 반면, logP가 5 이상이거나 0 이하인 구간에서는 잔차가 크게 퍼지는 ‘깔때기’ 현상이 관찰되었다. Breusch‑Pagan 검정 결과 통계량 19 566.7(p < 0.0001)로 이분산 가설을 강력히 기각하였다. 구간별 잔차 분산을 정량화한 결과, 가장 높은 logP 구간(>5)에서 잔차 분산이 균형 구간(2–4) 대비 4.13배, RMS E가 0.57→1.30으로 크게 증가하였다. 이는 회귀 계수의 표준 오차가 과소평가되어 가설 검정과 신뢰구간이 신뢰할 수 없게 만든다.
이분산을 완화하려는 전통적 방법으로 가중 최소제곱(WLS)과 Box‑Cox 변환을 적용하였다. WLS는 잔차 분산을 추정해 가중치를 부여했지만, Breusch‑Pagan 통계량이 35 024.2로 오히려 악화되었고, 모델 성능도 R²=0.562로 감소하였다. Box‑Cox 변환은 최적 λ=0.42를 찾아 정규성을 약간 개선했으나, 이분산 검정 p값은 여전히 <0.0001이었으며, 테스트 R²는 0.603으로 거의 변함이 없었다. 따라서 이분산은 단순한 가중치 조정이나 전력 변환만으로는 해결되지 않는, 로그P 계산 자체에 내재된 구조 다양성에 기인한 현상임을 확인했다.
다음으로 트리 기반 앙상블 모델인 Random Forest와 XGBoost를 적용하였다. 이들 모델은 데이터 분포 가정이 없고, 비선형 관계와 이분산에 자연스럽게 강인하다. Random Forest는 R²=0.764, RMSE=0.732, XGBoost는 R²=0.765, RMSE=0.731을 기록했으며, 선형 모델 대비 설명 변동량이 약 26% 향상되었다. 잔차 플롯은 무작위 흩어짐을 보여 이분산 문제가 사라졌음을 확인했다. 구간별 오류 분석에서는 logP 2–4 구간에서 MAE 0.540, logP>5 구간에서 MAE 0.836, logP<0 구간에서 MAE 1.043으로, 극단 구간에서도 비교적 안정적인 성능을 유지했다. 이는 XLOGP3 알고리즘이 실제 화학적 복잡성을 반영해 오류가 증가하는 것이며, 모델 자체의 한계가 아니라 목표 변수의 특성임을 시사한다.
다중공선성 역설에 대해서는 MolWt와 TPSA 사이의 높은 상관관계(r=0.712)와 MolWt의 VIF=281.7이 문제의 핵심이었다. 단변량 Pearson 상관은 MolWt와 logP가 +0.146에 불과해 중요도가 낮게 보였지만, SHAP 분석을 통해 Random Forest 모델에서 MolWt의 평균 절대 SHAP 값이 0.573으로 가장 큰 기여를 함을 밝혀냈다. TPSA는 음의 영향을 주어 MolWt의 순수 효과를 억제했으며, 다변량 모델이 이를 분리해낸 결과이다. 또한 NumRotatableBonds는 단변량에서는 거의 무시되지만 SHAP에서는 양의 기여를 보여, 유연성이 로그P에 미치는 복합적 효과를 포착한다는 점을 강조한다.
마지막으로 저자들은 전체 데이터셋을 ‘drug‑like’(Lipinski 규칙을 만족하는 91%)와 ‘extreme’(규칙 위반 9%) 두 서브셋으로 나누어 별도 모델을 학습했다. drug‑like 서브셋 모델은 R²=0.543, RMSE=0.838로 전체 XGBoost보다 낮지만, 이는 서브셋의 로그P 분산이 전체보다 작아진 데 따른 인위적 차이이며, 실제 예측 정확도는 전체 모델이 더 우수함을 보여준다.
결론적으로, 대규모 QSAR에서 선형 회귀는 이분산과 다중공선성 문제로 인해 통계적 해석이 위험함을 경고하고, 트리 기반 앙상블 모델과 SHAP을 활용한 피처 해석이 실용적이며 신뢰할 수 있는 대안임을 입증한다. 이러한 접근법은 향후 물성 예측, 특히 로그P와 같은 복합적인 화학적 특성을 다루는 모델링에 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기