생성형 검색을 위한 공정 기여도 평가 MAXSHAPLEY 알고리즘
MAXSHAPLEY는 검색‑증강 생성(RAG) 파이프라인에서 각 문서가 최종 답변에 기여한 정도를 샤플리 값 개념을 기반으로 효율적으로 산출하는 알고리즘이다. 문서 수에 대해 선형적인 LLM 호출만으로 기여도를 계산하도록 설계된 분해 가능한 max‑sum 유틸리티 함수를 도입해 기존 샤플리 값의 지수적 비용을 크게 낮추었다. HotPotQA, MuSiQUE, MS MARCO 등 3개 멀티홉 QA 데이터셋에서 정확도는 기존 완전 샤플리와 거의 동…
저자: Sara Patel, Mingxun Zhou, Giulia Fanti
본 논문은 대규모 언어 모델(LLM) 기반 생성형 검색 엔진이 전통적인 검색 모델을 대체하면서, 원본 콘텐츠 제공자들의 트래픽 감소와 수익 손실 문제를 야기한다는 사회·경제적 배경에서 출발한다. 이러한 상황에서 콘텐츠 제공자에게 공정한 보상을 제공하기 위해, 저자들은 “MAXSHAPLEY”라는 새로운 기여도 평가 알고리즘을 제안한다.
**1. 문제 정의 및 기존 연구**
생성형 검색 파이프라인은 (i) 사용자 질의 q에 대해 대규모 코퍼스에서 관련 문서 집합 S={s₁,…,s_m}를 검색하고, (ii) 검색된 문서들을 컨텍스트로 사용해 LLM Ψ가 간결한 답변 a를 생성한다. 목표는 각 문서 s_i가 최종 답변 a에 얼마나 기여했는지를 정량화하여, 이후 금전적 보상 등 인센티브에 활용할 수 있는 점수 φ_i를 산출하는 것이다. 기존 연구에서는 데이터셋 설명성, 모델 해석 등을 위해 Shapley 값, LIME, KernelSHAP 등 다양한 기여도 추정 방법을 사용했지만, 대부분이 훈련 데이터에 대한 기여도나 피처 수준 설명에 초점을 맞추었으며, 검색‑증강 생성(RAG) 상황에서의 효율적인 적용은 미비했다. 특히 Shapley 값은 모든 부분집합에 대한 유틸리티 평가가 필요해 O(2^m) 복잡도를 갖고, 실시간 검색 서비스에 적용하기 어렵다.
**2. MAXSHAPLEY 알고리즘 설계**
MAXSHAPLEY는 두 가지 핵심 아이디어를 결합한다.
- **LLM‑as‑a‑Judge 유틸리티**: 답변 품질을 평가하는 함수 Judge_Ψ_A(q, a; p)를 정의한다. 이 함수는 별도 LLM을 프롬프트(p)와 함께 호출해 0~1 점수를 반환한다. 내부 로짓에 접근할 필요가 없으며, 정확성·관련성·유용성 등 다양한 기준을 프롬프트로 지정할 수 있다.
- **분해 가능한 max‑sum 유틸리티**: U(S′)=Judge_Ψ_A(q, Ψ(q, S′); p) 를 max‑sum 형태로 가정한다. 즉, 전체 유틸리티는 각 문서가 제공하는 “최대 기여도”의 합으로 표현될 수 있다. 이 구조 덕분에 Shapley 값의 한계 기여도( marginal contribution )를 각 문서별로 독립적으로 계산할 수 있다.
알고리즘 흐름은 다음과 같다.
1. 전체 문서 집합 S에 대해 U(S) 를 측정한다.
2. 각 문서 s_i에 대해 U(S \ {s_i}) 를 별도 호출한다.
3. 차이 Δ_i = U(S) – U(S \ {s_i}) 를 구하고, max‑sum 특성을 이용해 Δ_i 를 정규화하여 φ_i 로 변환한다.
이 과정에서 필요한 LLM 호출 횟수는 O(m) 로, 문서 수에 선형적으로 증가한다.
**3. 이론적 특성**
MAXSHAPLEY는 전통적인 Shapley 값이 만족하는 효율성(전체 유틸리티가 점수에 완전히 분배), 대칭성(동등 기여자는 동일 점수), 무공헌자(null player), 가법성(additivity) 네 가지 공리를 그대로 유지한다. 추가로 “계산 효율성”이라는 실용적 공리를 만족하도록 설계되었다.
**4. 실험 설정 및 결과**
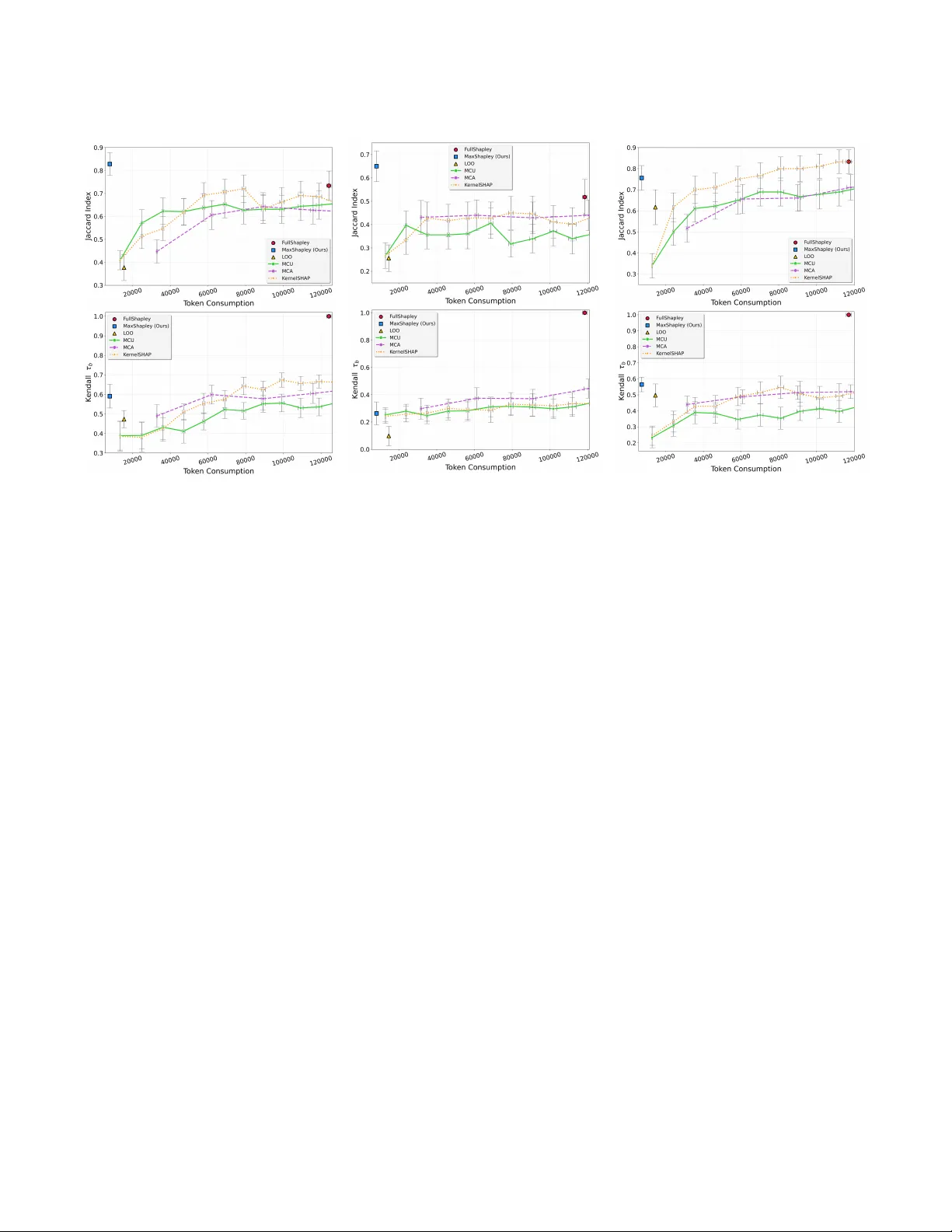
- **데이터셋**: HotPotQA, MuSiQUE, MS MARCO 세 멀티홉 QA 데이터셋을 사용했으며, 각 데이터셋에 대해 인간 주석자가 제공한 정답 문서 집합을 기준으로 평가했다.
- **베이스라인**: FullShapley(완전 샤플리), Leave‑One‑Out(LOO), Monte‑Carlo Shapley, KernelSHAP 등을 비교 대상으로 삼았다.
- **평가 지표**: Jaccard Index(정답 문서와 추정 문서 간 겹침), Kendall‑tau(순위 상관), 토큰 소비량(LLM 호출 비용) 등을 사용했다.
주요 결과는 다음과 같다.
- 정확도 측면에서 MAXSHAPLEY는 FullShapley와 0.76~0.83 Jaccard, 0.79~0.84 Kendall‑tau 를 기록해 거의 동등한 성능을 보였다.
- 토큰 소비량은 FullShapley 대비 평균 7 % 수준, KernelSHAP 대비 27 % 수준으로 크게 절감했으며, MuSiQUE에서는 8배까지 감소했다.
- LOO는 효율성은 좋지만 효율성(속성 1)을 만족하지 못해 전체 유틸리티를 충분히 분배하지 못하는 문제가 확인되었다.
- Monte‑Carlo Shapley는 샘플 수에 따라 정확도와 비용이 트레이드오프되었으며, MAXSHAPLEY가 동일 정확도에서 훨씬 적은 비용을 요구했다.
**5. 인센티브 메커니즘 제안**
MAXSHAPLEY에서 도출된 φ_i 를 기반으로 다음과 같은 보상 모델을 논의한다.
- **비례 보상**: φ_i 비율에 따라 금액을 직접 할당.
- **최소 보장금**: 모든 제공자에게 일정 수준의 최소 보상을 보장해 기여 의욕을 유지.
- **동적 가격 조정**: 시간·쿼리 빈도·문서 신뢰도 등을 고려해 φ_i 를 가중치 조정, 장기적인 콘텐츠 품질 향상을 유도.
**6. 구현 및 공개**
저자들은 MAXSHAPLEY의 파이썬 구현을 오픈소스로 공개하고, HotPotQA·MuSiQUE·TREC의 일부를 재주석화해 연구 커뮤니티가 바로 실험을 재현할 수 있도록 지원한다.
**7. 결론 및 향후 연구**
MAXSHAPLEY는 생성형 검색 환경에서 공정하고 실용적인 기여도 평가를 가능하게 하는 첫 번째 알고리즘으로, 샤플리 값의 계산 복잡성을 구조적 유틸리티 설계로 극복했다. 향후 연구에서는 (1) 다양한 도메인(법률·의료 등)에서의 Judge 프롬프트 설계, (2) 실시간 스트리밍 검색 시나리오에 대한 지연 최소화, (3) 보상 메커니즘과 법적·윤리적 프레임워크의 연계 등을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기